You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2021/03/16 19:25:42 UTC
[GitHub] [spark] twoentartian opened a new pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
twoentartian opened a new pull request #31827:
URL: https://github.com/apache/spark/pull/31827
<!--
Thanks for sending a pull request! Here are some tips for you:
1. If this is your first time, please read our contributor guidelines: https://spark.apache.org/contributing.html
2. Ensure you have added or run the appropriate tests for your PR: https://spark.apache.org/developer-tools.html
3. If the PR is unfinished, add '[WIP]' in your PR title, e.g., '[WIP][SPARK-XXXX] Your PR title ...'.
4. Be sure to keep the PR description updated to reflect all changes.
5. Please write your PR title to summarize what this PR proposes.
6. If possible, provide a concise example to reproduce the issue for a faster review.
7. If you want to add a new configuration, please read the guideline first for naming configurations in
'core/src/main/scala/org/apache/spark/internal/config/ConfigEntry.scala'.
-->
### What changes were proposed in this pull request?
<!--
Please clarify what changes you are proposing. The purpose of this section is to outline the changes and how this PR fixes the issue.
If possible, please consider writing useful notes for better and faster reviews in your PR. See the examples below.
1. If you refactor some codes with changing classes, showing the class hierarchy will help reviewers.
2. If you fix some SQL features, you can provide some references of other DBMSes.
3. If there is design documentation, please add the link.
4. If there is a discussion in the mailing list, please add the link.
-->
Fix [SPARK-34492], add Scala examples to read/write CSV files.
### Why are the changes needed?
<!--
Please clarify why the changes are needed. For instance,
1. If you propose a new API, clarify the use case for a new API.
2. If you fix a bug, you can clarify why it is a bug.
-->
Fix [SPARK-34492].
### Does this PR introduce _any_ user-facing change?
<!--
Note that it means *any* user-facing change including all aspects such as the documentation fix.
If yes, please clarify the previous behavior and the change this PR proposes - provide the console output, description and/or an example to show the behavior difference if possible.
If possible, please also clarify if this is a user-facing change compared to the released Spark versions or within the unreleased branches such as master.
If no, write 'No'.
-->
No
### How was this patch tested?
<!--
If tests were added, say they were added here. Please make sure to add some test cases that check the changes thoroughly including negative and positive cases if possible.
If it was tested in a way different from regular unit tests, please clarify how you tested step by step, ideally copy and paste-able, so that other reviewers can test and check, and descendants can verify in the future.
If tests were not added, please describe why they were not added and/or why it was difficult to add.
-->
Build the document with "SKIP_API=1 bundle exec jekyll build", and everything looks fine.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804454166
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40948/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812765782
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r597158881
##########
File path: examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala
##########
@@ -247,6 +248,50 @@ object SQLDataSourceExample {
// $example off:json_dataset$
}
+ private def runCsvDatasetExample(spark: SparkSession): Unit = {
+ // $example on:csv_dataset$
+ val path = "examples/src/main/resources/people.csv"
+
+ val df = spark.read.csv(path)
+ df.show()
+ // +------------------+
+ // | _c0|
+ // +------------------+
+ // | name;age;job|
+ // |Jorge;30;Developer|
+ // | Bob;32;Developer|
+ // +------------------+
+
+ // Read a csv with delimiter, the default delimiter is ","
+ val df2 = spark.read.option("delimiter", ";").csv(path)
+ df2.show()
+ // +-----+---+---------+
+ // | _c0|_c1| _c2|
+ // +-----+---+---------+
+ // | name|age| job|
+ // |Jorge| 30|Developer|
+ // | Bob| 32|Developer|
+ // +-----+---+---------+
+
+ // Read a csv with delimiter and a header
+ val df3 = spark.read.option("delimiter", ";").option("header", "true").csv(path)
+ df3.show()
+ // +-----+---+---------+
+ // | name|age| job|
+ // +-----+---+---------+
+ // |Jorge| 30|Developer|
+ // | Bob| 32|Developer|
+ // +-----+---+---------+
+
+ // You can also use options() to use multiple options
+ val df4 = spark.read.options(Map("delimiter"->";", "header"->"true")).csv(path)
+
+ df3.write.csv("output")
+ // "output" is a folder which contains multiple csv files and a _SUCCESS file.
Review comment:
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-802242817
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r603915655
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
+
+{% include_example csv_dataset scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala %}
+
+</div>
+
+<div data-lang="java" markdown="1">
+
+Spark SQL provides `spark.read().csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write().csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
+1 for the comment from @srowen .
@twoentartian, How about write the contents without language-specific part such as
"Spark SQL support read and write methods for CSV file, to read a CSV file into Spark DataFrame and to write the Spark DataFrame to the CSV file. `option()` can be used to customize behavior of reading or writing, such as controlling behavior of the header, delimiter character, character set, and so on."
outside of the language-specific block, after then maybe we can just simply show the code example for each language.
Refer to the "Hive Tables" page for the reference.
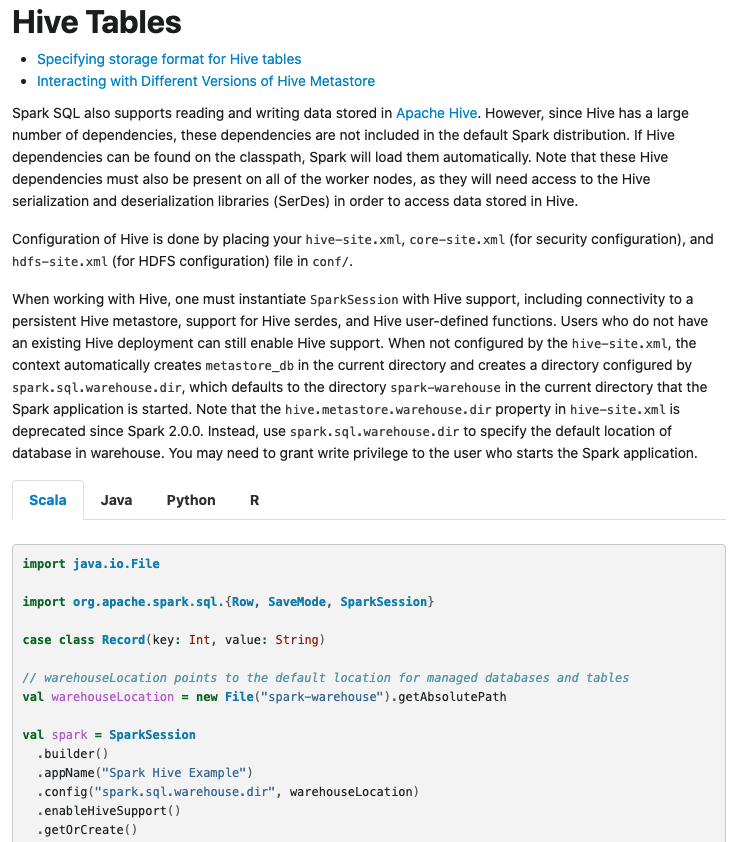
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-798822113
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
srowen commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-803461571
Yes that's right, it is not paying attention to the suffix if you tell Spark that the files in the dir are CSV files. That's fine to add to the docs here, but is expected behavior IMHO.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812768016
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-801651091
@itholic can you review this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-813146064
@twoentartian do you mind adding a comment in the JIRA so I can identify your JIRA id and assign SPARK-34492 to you?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r596583299
##########
File path: examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala
##########
@@ -247,6 +248,50 @@ object SQLDataSourceExample {
// $example off:json_dataset$
}
+ private def runCsvDatasetExample(spark: SparkSession): Unit = {
+ // $example on:csv_dataset$
+ val path = "examples/src/main/resources/people.csv"
+
+ val df = spark.read.csv(path)
+ df.show()
+ // +------------------+
+ // | _c0|
+ // +------------------+
+ // | name;age;job|
+ // |Jorge;30;Developer|
+ // | Bob;32;Developer|
+ // +------------------+
+
+ // Read a csv with delimiter, the default delimiter is ","
+ val df2 = spark.read.option("delimiter", ";").csv(path)
+ df2.show()
+ // +-----+---+---------+
+ // | _c0|_c1| _c2|
+ // +-----+---+---------+
+ // | name|age| job|
+ // |Jorge| 30|Developer|
+ // | Bob| 32|Developer|
+ // +-----+---+---------+
+
+ // Read a csv with delimiter and a header
+ val df3 = spark.read.option("delimiter", ";").option("header", "true").csv(path)
+ df3.show()
+ // +-----+---+---------+
+ // | name|age| job|
+ // +-----+---+---------+
+ // |Jorge| 30|Developer|
+ // | Bob| 32|Developer|
+ // +-----+---+---------+
+
+ // You can also use options() to use multiple options
+ val df4 = spark.read.options(Map("delimiter"->";", "header"->"true")).csv(path)
+
+ df3.write.csv("output")
+ // "output" is a folder which contains multiple csv files and a _SUCCESS file.
Review comment:
ditto ?
##########
File path: examples/src/main/python/sql/datasource.py
##########
@@ -234,6 +234,52 @@ def json_dataset_example(spark):
# $example off:json_dataset$
+def csv_dataset_example(spark):
+ # $example on:csv_dataset$
+ # spark is from the previous example
+ sc = spark.sparkContext
+
+ path = "examples/src/main/resources/people.csv"
+
+ df = spark.read.csv(path)
+ df.show()
+ # +------------------+
+ # | _c0|
+ # +------------------+
+ # | name;age;job|
+ # |Jorge;30;Developer|
+ # | Bob;32;Developer|
+ # +------------------+
+
+ # Read a csv with delimiter, the default delimiter is ","
+ df2 = spark.read.option(delimiter=';').csv(path)
+ df2.show()
+ # +-----+---+---------+
+ # | _c0|_c1| _c2|
+ # +-----+---+---------+
+ # | name|age| job|
+ # |Jorge| 30|Developer|
+ # | Bob| 32|Developer|
+ # +-----+---+---------+
+
+ # Read a csv with delimiter and a header
+ df3 = spark.read.option("delimiter", ";").option("header", True).csv(path)
+ df3.show()
+ # +-----+---+---------+
+ # | name|age| job|
+ # +-----+---+---------+
+ # |Jorge| 30|Developer|
+ # | Bob| 32|Developer|
+ # +-----+---+---------+
+
+ # You can also use options() to use multiple options
+ df4 = spark.read.options(delimiter=";", header=True).csv(path)
+
+ df3.write.csv("output")
+ # "output" is a folder which contains multiple csv files and a _SUCCESS file.
Review comment:
nit: Can we move this comment line to the above of the `df3.write.csv("output")` to keep consistency with other comments?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812760081
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136872/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804366410
**[Test build #136364 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136364/testReport)** for PR 31827 at commit [`4105973`](https://github.com/apache/spark/commit/41059730b89a4a523d87475d086f0daa8eea8d87).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r594486232
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,69 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Spark supports reading pipe, comma, tab, or any other delimiter/seperator files.
+
+{% highlight scala %}
+import spark.implicits._
+val path = "src/main/resources/people.csv"
+
+val df = spark.read.csv(path)
+df.show()
+// +------------------+
+// | _c0|
+// +------------------+
+// | name;age;job|
+// |Jorge;30;Developer|
+// | Bob;32;Developer|
+// +------------------+
+
+// Read a csv with delimiter
+val df2 = spark.read.options(Map("delimiter"->";")).csv(path)
+// +-----+---+---------+
+// | _c0|_c1| _c2|
+// +-----+---+---------+
+// | name|age| job|
+// |Jorge| 30|Developer|
+// | Bob| 32|Developer|
+// +-----+---+---------+
+
+// Read a csv with delimiter and a header
+val df3 = spark.read.options(Map("delimiter"->";","header"->"true")).csv(path)
+df.show()
Review comment:
@twoentartian . What I mean is that this example is wrong. If you do `df.show`, you will get line 34 ~ 40.
> Using `df` seems better because of saving memory. But I think as an example, it doesn't matter.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-813145631
Merged to master.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812761452
**[Test build #136873 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136873/testReport)** for PR 31827 at commit [`f71f12c`](https://github.com/apache/spark/commit/f71f12c56b71b5529dea190ddd08950e86388936).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812778318
**[Test build #136875 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136875/testReport)** for PR 31827 at commit [`b60ba7e`](https://github.com/apache/spark/commit/b60ba7e2f749b331d9649ce1806a81a36b8eced3).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
srowen commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r602909491
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
Review comment:
Rather than call this out separately, maybe just say above "read a file or directory of files in CSV format"
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
Hm, rather than refer to spark-csv, which is outdated (because it is long since merged into Spark), we should inline some important docs from that site. I'd prefer to do some of that here, but, if you're short on time, we can leave this as a minimal placeholder for now.
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
Some edits:
save or write -> write
`option()` can be used to customize behavior of reading or writing, such as controlling behavior of the header, delimiter character, character set, and so on.
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
+
+{% include_example csv_dataset scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala %}
+
+</div>
+
+<div data-lang="java" markdown="1">
+
+Spark SQL provides `spark.read().csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write().csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
Don't duplicate this, I think? it's not language-specific. Keep it outside the language-specific blocks, once.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r598753955
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,40 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage can be found in [spark-csv](https://github.com/databricks/spark-csv).
Review comment:
Yeah, we should fix it. Spark CSV is in Apache Spark and we should document it in more details :-).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-799893491
Sure, let me address.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-802221172
I can also write a Java page if necessary. Give me several days because I have some courses to do.
By the way, from this [page](https://sparkbyexamples.com/pyspark/pyspark-read-csv-file-into-dataframe/#Read%20all%20CSV%20files%20in%20a%20directory). It says we can read all csv files in a folder: `df = spark.read.csv("Folder path")`. But when I try it in spark-shell like this:
`val path = "examples/src/main/resources"`
`val df3 = spark.read.option("delimiter", ";").option("header", "true").csv(path)`
The size of `df3` is 539 and seems it reads all files in that folder rather than csv file only. Is this API obsolete?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804448597
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40948/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r594080746
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,69 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Spark supports reading pipe, comma, tab, or any other delimiter/seperator files.
+
+{% highlight scala %}
+import spark.implicits._
+val path = "src/main/resources/people.csv"
+
+val df = spark.read.csv(path)
+df.show()
+// +------------------+
+// | _c0|
+// +------------------+
+// | name;age;job|
+// |Jorge;30;Developer|
+// | Bob;32;Developer|
+// +------------------+
+
+// Read a csv with delimiter
+val df2 = spark.read.options(Map("delimiter"->";")).csv(path)
+// +-----+---+---------+
+// | _c0|_c1| _c2|
+// +-----+---+---------+
+// | name|age| job|
+// |Jorge| 30|Developer|
+// | Bob| 32|Developer|
+// +-----+---+---------+
+
+// Read a csv with delimiter and a header
+val df3 = spark.read.options(Map("delimiter"->";","header"->"true")).csv(path)
+df.show()
Review comment:
Hi, @twoentartian . Did you want to use `df3` instead of `df`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
srowen commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-803444347
I think it's expected that it reads all files in the folder you specify?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-801108580
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40746/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r606508497
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
+
+{% include_example csv_dataset scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala %}
+
+</div>
+
+<div data-lang="java" markdown="1">
+
+Spark SQL provides `spark.read().csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write().csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
I changed it to this :

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-800545000
> @twoentartian. are you still working on this? I assumed so because the PR was dropped (normally you can just push some more commits to this branch).
Oh ok, I will continue working on it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492]Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-798822113
Can one of the admins verify this patch?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-799893052
@itholic would you like to pick the commits here and proceed further since the PR is dropped?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r594092324
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,69 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Spark supports reading pipe, comma, tab, or any other delimiter/seperator files.
+
+{% highlight scala %}
+import spark.implicits._
Review comment:
In addition, can we create examples files and link it here like we do in JSON? https://github.com/apache/spark/blob/7a4313ebf99d639c847a65361d32c1a031498cb0/docs/sql-data-sources-json.md
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812786946
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-800542182
> @twoentartian. are you still working on this? I assumed so because the PR was dropped (normally you can just push some more commits to this branch).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804395714
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136364/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812799534
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r602979088
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
+
+{% include_example csv_dataset scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala %}
+
+</div>
+
+<div data-lang="java" markdown="1">
+
+Spark SQL provides `spark.read().csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write().csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
Yeah, I think we don't need to mention about spark-csv here. Also, the options will be documented later via SPARK-34494
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812776944
**[Test build #136875 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136875/testReport)** for PR 31827 at commit [`b60ba7e`](https://github.com/apache/spark/commit/b60ba7e2f749b331d9649ce1806a81a36b8eced3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-803460487
> I don't understand - it seems like it is doing what the documentation says then?
I think the page is indicating Spark will check whether it's a CSV file, if yes then read it, otherwise not. But in fact, Spark just reads all files without caring it's a CSV file or not.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-802242816
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
MaxGekk commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r598708489
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,40 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage can be found in [spark-csv](https://github.com/databricks/spark-csv).
Review comment:
I am not sure that we should refer to the outdated https://github.com/databricks/spark-csv . Does anybody maintain it? For example,
```
dateFormat: specifies a string that indicates the date format to use writing dates or timestamps. Custom date formats follow the formats at java.text.SimpleDateFormat. This applies to both DateType and TimestampType. If no dateFormat is specified, then "yyyy-MM-dd HH:mm:ss.S".
```
is incorrect.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812776944
**[Test build #136875 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136875/testReport)** for PR 31827 at commit [`b60ba7e`](https://github.com/apache/spark/commit/b60ba7e2f749b331d9649ce1806a81a36b8eced3).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-800820670
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136142/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804366410
**[Test build #136364 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136364/testReport)** for PR 31827 at commit [`4105973`](https://github.com/apache/spark/commit/41059730b89a4a523d87475d086f0daa8eea8d87).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804049267
k, that would be great. It would be great if we can add SQL and R examples too to make it consistent with JSON file examples though. I am okay with separating it for this one if you're not used to R or SQL.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492]Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-798821429
cc @itholic
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-799556250
cc @MaxGekk , too.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812799534
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812758231
**[Test build #136872 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136872/testReport)** for PR 31827 at commit [`2431c61`](https://github.com/apache/spark/commit/2431c61487ea4aeef8534c63e133f011b557cb8f).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon closed pull request #31827:
URL: https://github.com/apache/spark/pull/31827
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-810051318
LGTM except the https://github.com/apache/spark/pull/31827#discussion_r603915655.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804395714
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136364/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812760081
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136872/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-799893491
Sure, let me address.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r594248510
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,69 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Spark supports reading pipe, comma, tab, or any other delimiter/seperator files.
+
+{% highlight scala %}
+import spark.implicits._
Review comment:
good point, I haven't noticed it before. I will try to work on that. Should I close this pull request?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-803459377
> I think it's expected that it reads all files in the folder you specify?

This [page](https://sparkbyexamples.com/pyspark/pyspark-read-csv-file-into-dataframe/#Read%20all%20CSV%20files%20in%20a%20directory) says it should read all CSV files. Then it seems to be an error for this page.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-801107385
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136164/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804376657
**[Test build #136364 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136364/testReport)** for PR 31827 at commit [`4105973`](https://github.com/apache/spark/commit/41059730b89a4a523d87475d086f0daa8eea8d87).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804047148
> Yeah, It is expected behavior but maybe we can describe more specifically to avoid such a confusion, such as "If path is specified as a directory, make sure that only CSV files exist in the directory because it reads all files other than CSV in the directory".
>
> IMO it looks fine as it is now, but it would be better if a java page could be added.
>
> But if you're busy, I can work with a follow-up if you want.
>
> I'll leave it to the choice of you or other committers,
>
> cc @HyukjinKwon @dongjoon-hyun and @srowen .
I will work on the Java document tomorrow. By the way, add a description about reading the directory.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-801652920
Sure, let me take a look
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r596028391
##########
File path: examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala
##########
@@ -246,6 +247,47 @@ object SQLDataSourceExample {
// +---------------+----+
// $example off:json_dataset$
}
+
+ private def runCsvDatasetExample(spark: SparkSession): Unit = {
+ // $example on:csv_dataset$
+ val path = "examples/src/main/resources/people.csv"
+
+ val df = spark.read.csv(path)
+ df.show()
+ // +------------------+
+ // | _c0|
+ // +------------------+
+ // | name;age;job|
+ // |Jorge;30;Developer|
+ // | Bob;32;Developer|
+ // +------------------+
+
+ // Read a csv with delimiter, the default delimiter is ","
+ val df2 = spark.read.options(Map("delimiter"->";")).csv(path)
+ df2.show()
+ // +-----+---+---------+
+ // | _c0|_c1| _c2|
+ // +-----+---+---------+
+ // | name|age| job|
+ // |Jorge| 30|Developer|
+ // | Bob| 32|Developer|
+ // +-----+---+---------+
+
+ // Read a csv with delimiter and a header
+ val df3 = spark.read.options(Map("delimiter"->";","header"->"true")).csv(path)
Review comment:
I add `.option()` and `.options()` to both Scala and Python examples.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r594244267
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,69 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Spark supports reading pipe, comma, tab, or any other delimiter/seperator files.
+
+{% highlight scala %}
+import spark.implicits._
+val path = "src/main/resources/people.csv"
+
+val df = spark.read.csv(path)
+df.show()
+// +------------------+
+// | _c0|
+// +------------------+
+// | name;age;job|
+// |Jorge;30;Developer|
+// | Bob;32;Developer|
+// +------------------+
+
+// Read a csv with delimiter
+val df2 = spark.read.options(Map("delimiter"->";")).csv(path)
+// +-----+---+---------+
+// | _c0|_c1| _c2|
+// +-----+---+---------+
+// | name|age| job|
+// |Jorge| 30|Developer|
+// | Bob| 32|Developer|
+// +-----+---+---------+
+
+// Read a csv with delimiter and a header
+val df3 = spark.read.options(Map("delimiter"->";","header"->"true")).csv(path)
+df.show()
Review comment:
Using `df` seems better because of saving memory. But I think as an example, it doesn't matter.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812758824
**[Test build #136873 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136873/testReport)** for PR 31827 at commit [`f71f12c`](https://github.com/apache/spark/commit/f71f12c56b71b5529dea190ddd08950e86388936).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r606506702
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
Review comment:
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804398750
> k, that would be great. It would be great if we can add SQL and R examples too to make it consistent with JSON file examples though. I am okay with separating it for this one if you're not used to R or SQL.
We have never touched R or SQL, so I am afraid we will not write further examples. We would like to write a summary here for `option()`, but we cannot locate where is the CSV source code. It would be great if you can help us.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian closed pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian closed pull request #31827:
URL: https://github.com/apache/spark/pull/31827
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812758824
**[Test build #136873 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136873/testReport)** for PR 31827 at commit [`f71f12c`](https://github.com/apache/spark/commit/f71f12c56b71b5529dea190ddd08950e86388936).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r606511432
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
+
+{% include_example csv_dataset scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala %}
+
+</div>
+
+<div data-lang="java" markdown="1">
+
+Spark SQL provides `spark.read().csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write().csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
> Yeah, I think we don't need to mention about spark-csv here. Also, the options will be documented later via [SPARK-34494](https://issues.apache.org/jira/browse/SPARK-34494)
In addition, it seems the `option()` will be documented separately in the future, so I leave a comment in the markdown file like this:

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804454166
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40948/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-799893052
@itholic would you like to pick the commits here and proceed further since the PR is dropped?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-799894512
@twoentartian. are you still working on this? I assumed so because the PR was dropped (normally you can just push some more commits to this branch).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r597158695
##########
File path: examples/src/main/python/sql/datasource.py
##########
@@ -234,6 +234,52 @@ def json_dataset_example(spark):
# $example off:json_dataset$
+def csv_dataset_example(spark):
+ # $example on:csv_dataset$
+ # spark is from the previous example
+ sc = spark.sparkContext
+
+ path = "examples/src/main/resources/people.csv"
+
+ df = spark.read.csv(path)
+ df.show()
+ # +------------------+
+ # | _c0|
+ # +------------------+
+ # | name;age;job|
+ # |Jorge;30;Developer|
+ # | Bob;32;Developer|
+ # +------------------+
+
+ # Read a csv with delimiter, the default delimiter is ","
+ df2 = spark.read.option(delimiter=';').csv(path)
+ df2.show()
+ # +-----+---+---------+
+ # | _c0|_c1| _c2|
+ # +-----+---+---------+
+ # | name|age| job|
+ # |Jorge| 30|Developer|
+ # | Bob| 32|Developer|
+ # +-----+---+---------+
+
+ # Read a csv with delimiter and a header
+ df3 = spark.read.option("delimiter", ";").option("header", True).csv(path)
+ df3.show()
+ # +-----+---+---------+
+ # | name|age| job|
+ # +-----+---+---------+
+ # |Jorge| 30|Developer|
+ # | Bob| 32|Developer|
+ # +-----+---+---------+
+
+ # You can also use options() to use multiple options
+ df4 = spark.read.options(delimiter=";", header=True).csv(path)
+
+ df3.write.csv("output")
+ # "output" is a folder which contains multiple csv files and a _SUCCESS file.
Review comment:
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-813144918
LGTM.
Thanks, @twoentartian .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-801107385
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136164/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812758231
**[Test build #136872 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136872/testReport)** for PR 31827 at commit [`2431c61`](https://github.com/apache/spark/commit/2431c61487ea4aeef8534c63e133f011b557cb8f).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812768016
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r606507022
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
Fixed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r606507673
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
> Hm, rather than refer to spark-csv, which is outdated (because it is long since merged into Spark), we should inline some important docs from that site. I'd prefer to do some of that here, but, if you're short on time, we can leave this as a minimal placeholder for now.
I leave a comment (`<!--TODO: add `option()` document reference--> `) in the markdown file as the placeholder for `option()`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-804414192
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40948/
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r603915655
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,54 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
+
+`spark.read.csv()` also can be used to read all files in a directory by passing a directory path. Please notice that Spark will not check the file name extension and all files will be read into dataframe.
+
+{% include_example csv_dataset scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala %}
+
+</div>
+
+<div data-lang="java" markdown="1">
+
+Spark SQL provides `spark.read().csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write().csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage about `option()` can be found in [spark-csv](https://github.com/databricks/spark-csv), notice that some contents might be outdated in spark-csv.
Review comment:
+1 for the comment from @srowen .
@twoentartian, How about write the contents simply such as
"Spark SQL support read and write methods for CSV file, to read a CSV file into Spark DataFrame and to write the Spark DataFrame to the CSV file. `option()` can be used to customize behavior of reading or writing, such as controlling behavior of the header, delimiter character, character set, and so on."
outside of the language-specific block, after then maybe we can just simply show the code example for each language.
Refer to the "Hive Tables" page for the reference.

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-812760065
**[Test build #136872 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136872/testReport)** for PR 31827 at commit [`2431c61`](https://github.com/apache/spark/commit/2431c61487ea4aeef8534c63e133f011b557cb8f).
* This patch **fails to build**.
* This patch merges cleanly.
* This patch adds no public classes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-801108580
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40746/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-800542182
> @twoentartian. are you still working on this? I assumed so because the PR was dropped (normally you can just push some more commits to this branch).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r594490104
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,69 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Spark supports reading pipe, comma, tab, or any other delimiter/seperator files.
+
+{% highlight scala %}
+import spark.implicits._
+val path = "src/main/resources/people.csv"
+
+val df = spark.read.csv(path)
+df.show()
+// +------------------+
+// | _c0|
+// +------------------+
+// | name;age;job|
+// |Jorge;30;Developer|
+// | Bob;32;Developer|
+// +------------------+
+
+// Read a csv with delimiter
+val df2 = spark.read.options(Map("delimiter"->";")).csv(path)
+// +-----+---+---------+
+// | _c0|_c1| _c2|
+// +-----+---+---------+
+// | name|age| job|
+// |Jorge| 30|Developer|
+// | Bob| 32|Developer|
+// +-----+---+---------+
+
+// Read a csv with delimiter and a header
+val df3 = spark.read.options(Map("delimiter"->";","header"->"true")).csv(path)
+df.show()
Review comment:
Oh, I see that. I will correct this in the next pull request.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r595724792
##########
File path: examples/src/main/scala/org/apache/spark/examples/sql/SQLDataSourceExample.scala
##########
@@ -246,6 +247,47 @@ object SQLDataSourceExample {
// +---------------+----+
// $example off:json_dataset$
}
+
+ private def runCsvDatasetExample(spark: SparkSession): Unit = {
+ // $example on:csv_dataset$
+ val path = "examples/src/main/resources/people.csv"
+
+ val df = spark.read.csv(path)
+ df.show()
+ // +------------------+
+ // | _c0|
+ // +------------------+
+ // | name;age;job|
+ // |Jorge;30;Developer|
+ // | Bob;32;Developer|
+ // +------------------+
+
+ // Read a csv with delimiter, the default delimiter is ","
+ val df2 = spark.read.options(Map("delimiter"->";")).csv(path)
+ df2.show()
+ // +-----+---+---------+
+ // | _c0|_c1| _c2|
+ // +-----+---+---------+
+ // | name|age| job|
+ // |Jorge| 30|Developer|
+ // | Bob| 32|Developer|
+ // +-----+---+---------+
+
+ // Read a csv with delimiter and a header
+ val df3 = spark.read.options(Map("delimiter"->";","header"->"true")).csv(path)
Review comment:
Can you use `option` instead of `options(Map(...))` to be consistent with other examples?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-800809115
ok to test
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
itholic commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-803705454
Yeah, It is expected behavior but maybe we can describe more specifically to avoid such a confusion, such as "If path is specified as a directory, make sure that only CSV files exist in the directory because it reads all files other than CSV in the directory".
IMO it looks fine as it is now, but it would be better if a java page could be added.
But if you're busy, I can work with a follow-up if you want.
I'll leave it to the choice of you or other committers,
cc @HyukjinKwon @dongjoon-hyun and @srowen .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
srowen commented on pull request #31827:
URL: https://github.com/apache/spark/pull/31827#issuecomment-803460076
I don't understand - it seems like it is doing what the documentation says then?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] twoentartian commented on a change in pull request #31827: [SPARK-34492][DOCS] Add "CSV Files" page for Data Source documents.
Posted by GitBox <gi...@apache.org>.
twoentartian commented on a change in pull request #31827:
URL: https://github.com/apache/spark/pull/31827#discussion_r599049158
##########
File path: docs/sql-data-sources-csv.md
##########
@@ -0,0 +1,40 @@
+---
+layout: global
+title: CSV Files
+displayTitle: CSV Files
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+<div class="codetabs">
+
+<div data-lang="scala" markdown="1">
+
+Spark SQL provides `spark.read.csv("file_name")` to read a CSV file into Spark DataFrame and `dataframe.write.csv("path")` to save or write to the CSV file. Function `option()` provides customized behavior during reading csv files. The customized behavior includes but not limit to configuring header, delimiter, charset. The detailed usage can be found in [spark-csv](https://github.com/databricks/spark-csv).
Review comment:
I add a warning that some contents might be outdated in the [spark-csv](https://github.com/databricks/spark-csv).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org