You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@spark.apache.org by do...@apache.org on 2021/04/08 20:36:15 UTC
[spark] branch branch-3.0 updated: [SPARK-34970][3.0][SQL] Redact
map-type options in the output of explain()
This is an automated email from the ASF dual-hosted git repository.
dongjoon pushed a commit to branch branch-3.0
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/branch-3.0 by this push:
new ee264b1 [SPARK-34970][3.0][SQL] Redact map-type options in the output of explain()
ee264b1 is described below
commit ee264b1ef1823cf90671c9565c7420da1ee7ba5d
Author: Gengliang Wang <lt...@gmail.com>
AuthorDate: Thu Apr 8 13:35:30 2021 -0700
[SPARK-34970][3.0][SQL] Redact map-type options in the output of explain()
### What changes were proposed in this pull request?
The `explain()` method prints the arguments of tree nodes in logical/physical plans. The arguments could contain a map-type option that contains sensitive data.
We should map-type options in the output of `explain()`. Otherwise, we will see sensitive data in explain output or Spark UI.
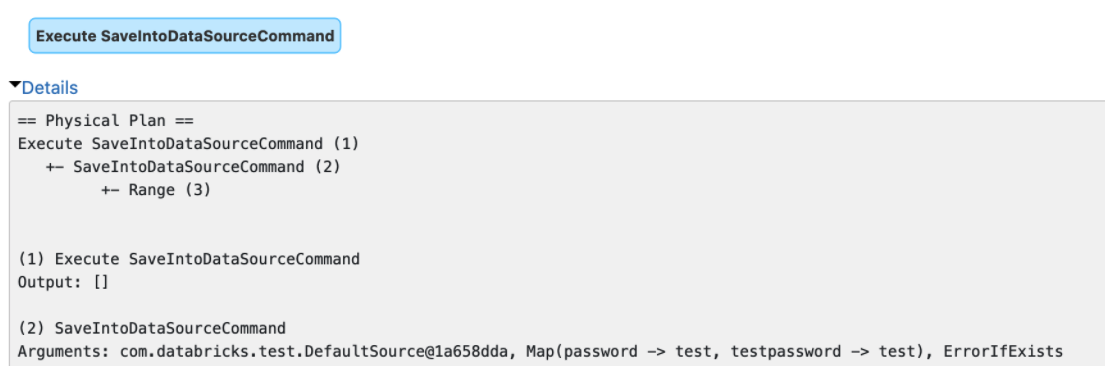
### Why are the changes needed?
Data security.
### Does this PR introduce _any_ user-facing change?
Yes, redact the map-type options in the output of `explain()`
### How was this patch tested?
Unit tests
Closes #32085 from gengliangwang/redact3.0.
Authored-by: Gengliang Wang <lt...@gmail.com>
Signed-off-by: Dongjoon Hyun <dh...@apple.com>
---
.../apache/spark/sql/catalyst/trees/TreeNode.scala | 16 +++++++
.../resources/sql-tests/results/describe.sql.out | 2 +-
.../scala/org/apache/spark/sql/ExplainSuite.scala | 52 ++++++++++++++++++++++
3 files changed, 69 insertions(+), 1 deletion(-)
diff --git a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
index 4dc3627..0ec2bbc 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
@@ -20,6 +20,7 @@ package org.apache.spark.sql.catalyst.trees
import java.util.UUID
import scala.collection.{mutable, Map}
+import scala.collection.JavaConverters._
import scala.reflect.ClassTag
import org.apache.commons.lang3.ClassUtils
@@ -39,6 +40,7 @@ import org.apache.spark.sql.catalyst.util.StringUtils.PlanStringConcat
import org.apache.spark.sql.catalyst.util.truncatedString
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.types._
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
import org.apache.spark.storage.StorageLevel
import org.apache.spark.util.Utils
@@ -532,6 +534,16 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]] extends Product {
private lazy val allChildren: Set[TreeNode[_]] = (children ++ innerChildren).toSet[TreeNode[_]]
+ private def redactMapString[K, V](map: Map[K, V], maxFields: Int): List[String] = {
+ // For security reason, redact the map value if the key is in centain patterns
+ val redactedMap = SQLConf.get.redactOptions(map.toMap)
+ // construct the redacted map as strings of the format "key=value"
+ val keyValuePairs = redactedMap.toSeq.map { item =>
+ item._1 + "=" + item._2
+ }
+ truncatedString(keyValuePairs, "[", ", ", "]", maxFields) :: Nil
+ }
+
/** Returns a string representing the arguments to this node, minus any children */
def argString(maxFields: Int): String = stringArgs.flatMap {
case tn: TreeNode[_] if allChildren.contains(tn) => Nil
@@ -548,6 +560,10 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]] extends Product {
case None => Nil
case Some(null) => Nil
case Some(any) => any :: Nil
+ case map: CaseInsensitiveStringMap =>
+ redactMapString(map.asCaseSensitiveMap().asScala, maxFields)
+ case map: Map[_, _] =>
+ redactMapString(map, maxFields)
case table: CatalogTable =>
table.storage.serde match {
case Some(serde) => table.identifier :: serde :: Nil
diff --git a/sql/core/src/test/resources/sql-tests/results/describe.sql.out b/sql/core/src/test/resources/sql-tests/results/describe.sql.out
index a7de033..36118f8 100644
--- a/sql/core/src/test/resources/sql-tests/results/describe.sql.out
+++ b/sql/core/src/test/resources/sql-tests/results/describe.sql.out
@@ -571,7 +571,7 @@ struct<plan:string>
-- !query output
== Physical Plan ==
Execute DescribeTableCommand
- +- DescribeTableCommand `default`.`t`, Map(c -> Us, d -> 2), false
+ +- DescribeTableCommand `default`.`t`, [c=Us, d=2], false
-- !query
diff --git a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
index 158d939..e8833b8 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/ExplainSuite.scala
@@ -19,8 +19,10 @@ package org.apache.spark.sql
import org.apache.spark.sql.execution._
import org.apache.spark.sql.execution.adaptive.{DisableAdaptiveExecutionSuite, EnableAdaptiveExecutionSuite}
+import org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand
import org.apache.spark.sql.functions._
import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.sources.TestOptionsSource
import org.apache.spark.sql.test.SharedSparkSession
import org.apache.spark.sql.types.StructType
@@ -69,6 +71,18 @@ trait ExplainSuiteHelper extends QueryTest with SharedSparkSession {
protected def checkKeywordsExistsInExplain(df: DataFrame, keywords: String*): Unit = {
checkKeywordsExistsInExplain(df, ExtendedMode, keywords: _*)
}
+
+ /**
+ * Runs the plan and makes sure the plans does not contain any of the keywords.
+ */
+ protected def checkKeywordsNotExistsInExplain(
+ df: DataFrame, mode: ExplainMode, keywords: String*): Unit = {
+ withNormalizedExplain(df, mode) { normalizedOutput =>
+ for (key <- keywords) {
+ assert(!normalizedOutput.contains(key))
+ }
+ }
+ }
}
class ExplainSuite extends ExplainSuiteHelper with DisableAdaptiveExecutionSuite {
@@ -332,6 +346,44 @@ class ExplainSuite extends ExplainSuiteHelper with DisableAdaptiveExecutionSuite
Nil: _*)
}
+ test("SPARK-34970: Redact Map type options in explain output") {
+ val password = "MyPassWord"
+ val token = "MyToken"
+ val value = "value"
+ val options = Map("password" -> password, "token" -> token, "key" -> value)
+ val cmd = SaveIntoDataSourceCommand(spark.range(10).logicalPlan, new TestOptionsSource,
+ options, SaveMode.Overwrite)
+
+ Seq(SimpleMode, ExtendedMode, FormattedMode).foreach { mode =>
+ checkKeywordsExistsInExplain(cmd, mode, value)
+ }
+ Seq(SimpleMode, ExtendedMode, CodegenMode, CostMode, FormattedMode).foreach { mode =>
+ checkKeywordsNotExistsInExplain(cmd, mode, password)
+ checkKeywordsNotExistsInExplain(cmd, mode, token)
+ }
+ }
+
+ test("SPARK-34970: Redact CaseInsensitiveMap type options in explain output") {
+ val password = "MyPassWord"
+ val token = "MyToken"
+ val value = "value"
+ val tableName = "t"
+ withTable(tableName) {
+ val df1 = spark.range(10).toDF()
+ df1.write.format("json").saveAsTable(tableName)
+ val df2 = spark.read
+ .option("key", value)
+ .option("password", password)
+ .option("token", token)
+ .table(tableName)
+
+ Seq(SimpleMode, ExtendedMode, CodegenMode, CostMode, FormattedMode).foreach { mode =>
+ checkKeywordsNotExistsInExplain(df2, mode, password)
+ checkKeywordsNotExistsInExplain(df2, mode, token)
+ }
+ }
+ }
+
test("Dataset.toExplainString has mode as string") {
val df = spark.range(10).toDF
def assertExplainOutput(mode: ExplainMode): Unit = {
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@spark.apache.org
For additional commands, e-mail: commits-help@spark.apache.org