You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/10/21 12:17:13 UTC
[GitHub] [hudi] spyzzz opened a new issue #2193: [SUPPORT] Optimise MOR file size and upsert
spyzzz opened a new issue #2193:
URL: https://github.com/apache/hudi/issues/2193
**_Tips before filing an issue_**
Hello, here is my use case : i've to read millions of message from kafka and then write into hudi table on hdfs.
I use structured streaming to do it, with the option maxOffsetsPerTrigger to 500000.
500K records represents 50MB
<img width="1395" alt="Capture d’écran 2020-10-21 à 14 16 22" src="https://user-images.githubusercontent.com/5584892/96718272-0e488800-13a8-11eb-9974-d837c9106acb.png">
The kafka topic got 6 partitions, so i use 6 executor core to read in //
Every 'micro batch' (i set it to 120s for now, but it can be change) hudi is write 5 files of approx 5MB.
I tried multiple config to avoid writing to much small files but i didnt managed to make it work now.

The things is, every next batch the processing time is bigger and bigger because hudi has to read and parse saved data i thinks. Every batch has 50s to pull data from kafka (this is stable) and then the hudi work is going bigger and bigger, especially in the step : Obtain key ranges for file slices (range pruning=on)
<img width="1413" alt="Capture d’écran 2020-10-20 à 10 10 45" src="https://user-images.githubusercontent.com/5584892/96718126-d7727200-13a7-11eb-83d0-1f899ecc5141.png">
Here is my hudi MOR configuration :
```
TABLE_TYPE_OPT_KEY -> "MERGE_ON_READ",
PRECOMBINE_FIELD_OPT_KEY -> "ts_ms",
RECORDKEY_FIELD_OPT_KEY -> table.pk,
OPERATION_OPT_KEY -> "upsert",
KEYGENERATOR_CLASS_OPT_KEY-> "org.apache.hudi.keygen.NonpartitionedKeyGenerator",
TABLE_NAME_OPT_KEY -> ("hudi_" + table.name),
"hoodie.table.name" -> ("hudi_" + table.name),
"hoodie.upsert.shuffle.parallelism"-> "6",
"hoodie.insert.shuffle.parallelism"-> "6",
"hoodie.bulkinsert.shuffle.parallelism"-> "6",
//"hoodie.parquet.small.file.limit" -> "4194304",
//"hoodie.index.bloom.num_entries" -> "1200000",
"hoodie.bulkinsert.sort.mode" -> "NONE"
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" -> "10",
"hoodie.cleaner.commits.retained" -> "10",
"hoodie.cleaner.fileversions.retained" -> "10",
"hoodie.keep.min.commits" -> "12",
"hoodie.keep.max.commits" -> "13"
//"hoodie.clean.async" -> "false",
//"hoodie.clean.automatic" ->"true",
//"hoodie.parquet.compression.codec" -> "snappy"
```
Thanks for reading.
**Environment Description**
* Hudi version : 0.6.0
* Spark version : 2.4.6
* Hive version : 1.2
* Hadoop version : 2.7
* Storage (HDFS/S3/GCS..) : HDFS
* Running on Docker? (yes/no) : no
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-713557657
First batch => 10min
Second batch => 20min
![Uploading Capture d’écran 2020-10-21 à 15.09.54.png…]()
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-714095249
@spyzzz : Few questions:
1. Does your record key have any ordering or is it UUID ?
2. Your average record size seems to be around 100 bytes. So, you can try setting hoodie.copyonwrite.record.size.estimate=100. This needs to be done the first time you write.
3. Can you attach .commit file in .hoodie folder corresponding to the commits where you observed the difference.
4. Is the file listing that you attached in the description complete ? From what I read, it looks like small file handling did not kick in and there were only inserts.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-716814642
Yes you're right, the metadata i gave you was from the initial boostraps.
So yes, i've two differents workloads, you sum'up it pretty cleary. Except that, for the (1) it might be possible to get update in the initial bootstrap (its wasnt the case for the files i gave you) but that's why i can't use BULK_INSERT mode.
With the fews configuration tips you gave me, i'm able to keep pretty linear time for each 5Millions rows batch so yes its better.
I'm around 500K rows/min (i don't really know if its correct or not) with a 6 partitions kafka topics.
For the (2), in CDC mode yes, i've a lot less rows, but i've to do update pretty often (let says every 10min), I tried this afternoon, and i'm able to handle a 10min micro batch in 2min or so. (and the hudi output stay pretty acceptable, not too many files, every 10 delta file, hudi create a -40/70Mb parquet file
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-713538871
Even if i increase the record number per batch from 500K to 5M, hudi is still writing 5mb parquet file. But with 5M hudi write more files
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-713557657
First batch => 10min
Second batch => 20min
<img width="1414" alt="Capture d’écran 2020-10-21 à 15 09 54" src="https://user-images.githubusercontent.com/5584892/96723982-8ebeb700-13af-11eb-8604-4a028550ddc6.png">
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-715125484
For this POC use case i only had insert, but in production use i'll get update too, even if insert represent 99% of transaction , i've to assure that hudi table didn't get any duplicates for key.
To sum up the situation : i'll get multiple kafka topics filled by CDC débézium events (from mysql mainly). Its a kafka 2.6 with compaction, so at any time, i'll get at least one row per key so that at every moment all the mysql table row are avaible in this topics kafka.
The first synchronisation will be very heavy (that's what i'm trying to do with 10 or 100M records), but once the first big synchronisation done, i'll juste have to catch freshly new CDC events from each topics ( and here its like 10000 events per day mainly detele/update)
Maybe i can try a first job with specific configuration to do the first big synchronisation, and then switch to another job to handle only CDC upsert/delete events, its possible because i'm using structured streaming with checkpooints.
I tried to do a insert only job, but i've several micro batches, so i can't be sure there will be unique key in hudi table. If i do one big batch with all events and then use deduplicate with hudi its could be possible, but if i've table with 300M+ records, i'm not sure its the good way to go with a huge unique batch.
Hope the situation is clear.
-> With hoodie.parquet.small.file.limit=104857600 no changes still 4 files of 74.4Mb per 5M records
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-716713865
@spyzzz : Sorry for the delay. I guess the commit metadata that you pasted was part of the initial bootstrap of the rows sent by debezium. You have 2 kinds of workloads -
1. Snapshot of the mysql table where there won't be duplicates but this will be throughput intensive.
2. CDC of your mysql table containing new inserts/updates and deletes.
Those are very different workloads with (1) happening only once (or whenever you need to re-bootstrap) and then (2) being the steady state. They need different different configurations for optimal performance Insert vs upsert. In the steady state (after initial snapshot), Are you able to see steady performance. Your last comment seems to indicate that the write time is holding up and not increasing. Is this correct ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-713553054
Here some metrics with 5.000.000 rows batch
<img width="1400" alt="Capture d’écran 2020-10-21 à 15 02 34" src="https://user-images.githubusercontent.com/5584892/96723144-7ef2a300-13ae-11eb-8479-63704e84e654.png">
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-714314739
Thanks @bvaradar , here are my answer :
1. The PK is an INT ID
2. Does hoodie.copyonwrite param has an effect on MOR Table ? cause i'm using MOR table
3.
-> file :
[20201022073003.deltacommit.log](https://github.com/apache/hudi/files/5421245/20201022073003.deltacommit.log)
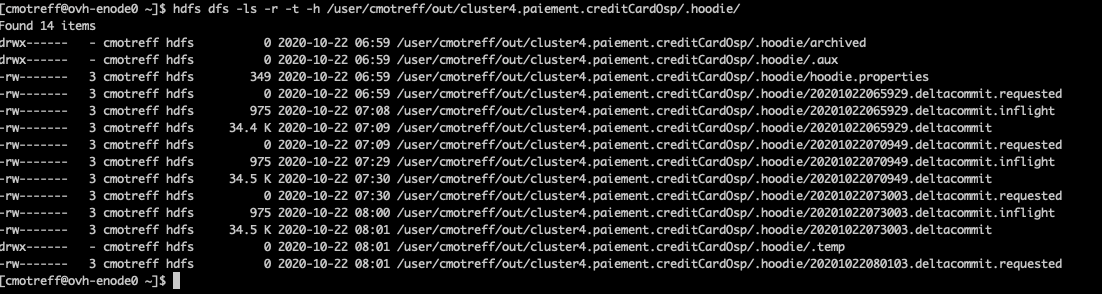
This is the .hoodie state while third batch is running
4. No its just a sample. There is more files, but they all close to 5MB. If i raise the record number in batch, the file size is not growing, but only the file number
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-715125484
For this POC use case i only had insert, but in production use i'll get update too, even if insert represent 99% of transaction , i've to assure that hudi table didn't get any duplicates for key.
To sum up the situation : i'll get multiple kafka topics filled by CDC débézium events (from mysql mainly). Its a kafka 2.6 with compaction, so at any time, i'll get at least one row per key so that at every moment all the mysql table row are avaible in this topics kafka.
The first synchronisation will be very heavy (that's what i'm trying to do with 10 or 100M records), but once the first big synchronisation done, i'll juste have to catch freshly new CDC events from each topics ( and here its like 10000 events per day mainly detele/update)
Maybe i can try a first job with specific configuration to do the first big synchronisation, and then switch to another job to handle only CDC upsert/delete events, its possible because i'm using structured streaming with checkpooints.
I tried to do a insert only job, but i've several micro batches, so i can be sure there will be unique key in hudi table. If i do one big batch with all events and then use deduplicate with hudi its could be possible, but if i've table with 300M+ records, i'm not sure its the good way to go with a huge unique batch.
Hope the situation is clear.
-> With hoodie.parquet.small.file.limit=104857600 no changes still 4 files of 74.4Mb per 5M records
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-714314739
Thanks @bvaradar , here are my answer :
1. The PK is an INT ID
2. Does hoodie.copyonwrite param has an effect on MOR Table ? cause i'm using MOR table
3.

This is the .hoodie state while third batch is running
4. No its just a sample. There is more files, but they all close to 5MB. If i raise the record number in batch, the file size is not growing, but only the file number
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bvaradar commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-714801051
@spyzzz : I do see from the attached commit log that the input batch has only inserts. Do you expect this to be the case ? If so, you can use "INSERT" operation type which will skip the index lookup completely. Also, it looks like you are doing inline compaction, you can try enabling async compaction but if this is pure inserts only, you can simply use COW mode
Regarding file size, I dont see small file handling kicking in : Can you explicity set "hoodie.parquet.small.file.limit=104857600" ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-714356313
I tried with hoodie.copyonwrite.record.size.estimate=100.
And its a little bit better, file size are now close de 60Mo instead of 5Mo
And batch are faster :
1 -> 10min (same)
2 -> 11 min
3 -> 17min
<img width="1414" alt="Capture d’écran 2020-10-22 à 11 17 46" src="https://user-images.githubusercontent.com/5584892/96851511-66d75e00-1458-11eb-85e5-157cb40f6fad.png">
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-715125484
For this POC use case i only had insert, but in production use i'll get insert too, even if insert represent 99% of transaction , i've to assure that hudi table didn't get any duplicates for key.
To sum up the situation : i'll get multiple kafka topics filled by CDC débézium events (from mysql mainly). Its a kafka 2.6 with compaction, so at any time, i'll get at least one row per key so that at every moment all the mysql table row are avaible in this topics kafka.
The first synchronisation will be very heavy (that's what i'm trying to do with 10 or 100M records), but once the first big synchronisation done, i'll juste have to catch freshly new CDC events from each topics ( and here its like 10000 events per day mainly detele/update)
Maybe i can try a first job with specific configuration to do the first big synchronisation, and then switch to another job to handle only CDC upsert/delete events, its possible because i'm using structured streaming with checkpooints.
I tried to do a insert only job, but i've several micro batches, so i can be sure there will be unique key in hudi table. If i do one big batch with all events and then use deduplicate with hudi its could be possible, but if i've table with 300M+ records, i'm not sure its the good way to go with a huge unique batch.
Hope the situation is clear.
-> With hoodie.parquet.small.file.limit=104857600 no changes still 4 files of 74.4Mb per 5M records
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz commented on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz commented on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-715295493
Perf are little bit better with async compaction to true
<img width="1315" alt="Capture d’écran 2020-10-23 à 13 52 03" src="https://user-images.githubusercontent.com/5584892/97000396-f2bfb780-1536-11eb-9c67-c362f05fc592.png">
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] spyzzz edited a comment on issue #2193: [SUPPORT] Optimise MOR file size and upsert
Posted by GitBox <gi...@apache.org>.
spyzzz edited a comment on issue #2193:
URL: https://github.com/apache/hudi/issues/2193#issuecomment-713557657
First batch => 10min
Second batch => 20min
Third one => 30min
<img width="1411" alt="Capture d’écran 2020-10-21 à 16 13 29" src="https://user-images.githubusercontent.com/5584892/96732260-6c7d6700-13b8-11eb-9a65-224cb6eb1169.png">
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org