You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by cloud-fan <gi...@git.apache.org> on 2018/08/15 20:02:52 UTC
[GitHub] spark pull request #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() da...
GitHub user cloud-fan opened a pull request:
https://github.com/apache/spark/pull/22112
[WIP][SPARK-23243][Core] Fix RDD.repartition() data correctness issue
## What changes were proposed in this pull request?
An alternative fix for https://github.com/apache/spark/pull/21698
RDD can take arbitrary user function, but we have an assumption: the function should produce same data set for same input, but the order can change.
Spark scheduler must take care of this assumption when fetch failure happens, otherwise we may hit correctness issue as the JIRA ticket described.
Generall speaking, when a map stage gets retried because of fetch failure, and this map stage is not idempotent(produce same data set but different order each time), and the shuffle partitioner is sensitive to the input data order(like round robin partitioner), we should retry all the reduce tasks.
TODO: document and test
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/cloud-fan/spark repartition
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/22112.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #22112
----
commit 1f9f6e5b020038be1e7c11b9923010465da385aa
Author: Wenchen Fan <we...@...>
Date: 2018-08-15T18:38:24Z
fix repartition+shuffle bug
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2633/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95607/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212616787
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
--- End diff --
I see a TODO above `// TODO: Cancel running tasks in the failed stage -- cf. SPARK-17064`. Do you mean we are able to do it now?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95597 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95597/testReport)** for PR 22112 at commit [`9a3b8f4`](https://github.com/apache/spark/commit/9a3b8f42c6f9f992fa870e0c7e35ef4be533b561).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
also thanks for adding the test cases, did you have to run that many times to reproduce?
One thing to note for others is you have to have external shuffle off. I haven't been able to reproduce with that so perhaps there are other confs I have on that you don't that makes it happen more often.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #4298 has started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4298/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2658/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95210/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
@mridulm so just to clarify are you agreeing that we need to decide on what we do with zip and others or are you agreeing that we should document these as unordered actions thus retries might be different and only fix repartition?
We can certainly add other options later but I don't want to change what we say the core zip behavior is.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95421 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95421/testReport)** for PR 22112 at commit [`7001656`](https://github.com/apache/spark/commit/7001656f0bd2819241ec40affa3d224e44fd87c0).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212633788
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,60 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.outputRandomLevel == RandomLevel.INDETERMINATE) {
+ // It's a little tricky to find all the succeeding stages of `failedStage`, because
+ // each stage only know its parents not children. Here we traverse the stages from
+ // the leaf nodes (the result stages of active jobs), and rollback all the stages
+ // in the stage chains that connect to the `failedStage`. To speed up the stage
+ // traversing, we collect the stages to rollback first. If a stage needs to
+ // rollback, all its succeeding stages need to rollback to.
+ val stagesToRollback = scala.collection.mutable.HashSet(failedStage)
--- End diff --
@mridulm Thanks for your suggestion about memorization! I think this approach should work like you expected.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95420 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95420/testReport)** for PR 22112 at commit [`7001656`](https://github.com/apache/spark/commit/7001656f0bd2819241ec40affa3d224e44fd87c0).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95359 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95359/testReport)** for PR 22112 at commit [`c7da508`](https://github.com/apache/spark/commit/c7da5083ac0aba949c55965aad49213a1f13f6ec).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds the following public classes _(experimental)_:
* `class MyCheckpointRDD(`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212451081
--- Diff: core/src/main/scala/org/apache/spark/rdd/ZippedPartitionsRDD.scala ---
@@ -95,6 +99,18 @@ private[spark] class ZippedPartitionsRDD2[A: ClassTag, B: ClassTag, V: ClassTag]
rdd2 = null
f = null
}
+
+ private def isRandomOrder(rdd: RDD[_]): Boolean = {
+ rdd.computingRandomLevel == RDD.RandomLevel.UNORDERED
--- End diff --
`isRandomOrder` gives the impression that both cases (INDETERMINATE and UNORDERED) are 'random'.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212705976
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1865,6 +1871,57 @@ abstract class RDD[T: ClassTag](
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean =
dependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())
+
+ /**
+ * Returns the random level of this RDD's output. Please refer to [[RandomLevel]] for the
+ * definition.
+ *
+ * By default, an reliably checkpointed RDD, or RDD without parents(root RDD) is IDEMPOTENT. For
+ * RDDs with parents, we will generate a random level candidate per parent according to the
+ * dependency. The random level of the current RDD is the random level candidate that is random
+ * most. Please override [[getOutputRandomLevel]] to provide custom logic of calculating output
+ * random level.
+ */
+ // TODO: make it public so users can set random level to their custom RDDs.
+ // TODO: this can be per-partition. e.g. UnionRDD can have different random level for different
+ // partitions.
+ private[spark] final lazy val outputRandomLevel: RandomLevel.Value = {
+ if (checkpointData.exists(_.isInstanceOf[ReliableRDDCheckpointData[_]])) {
+ RandomLevel.IDEMPOTENT
+ } else {
+ getOutputRandomLevel
+ }
+ }
+
+ @DeveloperApi
+ protected def getOutputRandomLevel: RandomLevel.Value = {
+ val randomLevelCandidates = dependencies.map {
+ case dep: ShuffleDependency[_, _, _] =>
--- End diff --
`dep.rdd.partitioner` sorry
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95359/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on the issue:
https://github.com/apache/spark/pull/22112
@tgravescs:
> The shuffle simply transfers the bytes its supposed to. Sparks shuffle of those bytes is not consistent in that the order it fetches from can change and without the sort happening on that data the order can be different on rerun. I guess maybe you mean the ShuffledRDD as a whole or do you mean something else here?
By shuffle, I am referring to the output of shuffle which is be consumed by RDD with `ShuffleDependency` as input.
More specifically, the output of `SparkEnv.get.shuffleManager.getReader(...).read()` which RDD (user and spark impl's) uses to fetch output of shuffle machinery.
This output will not just be shuffle bytes/deserialize, but with aggregation applied (if specified) and ordering imposed (if specified).
ShuffledRDD is one such usage within spark core, but others exist within spark core and in user code.
> All I'm saying is zip is just another variant of this, you could document it as such and do nothing internal to spark to "fix it".
I agree; repartition + shuffle, zip, sample, mllib usages are all variants of the same problem - of shuffle output order being inconsistent.
> I guess we can separate out these 2 discussions. I think the point of this pr is to temporarily workaround the data loss/corruption issue with repartition by failing. So if everyone agrees on that lets move the discussion to a jira about what to do with the rest of the operators and fix repartition here. thoughts?
Sounds good to me.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
> I'm proposing an option 3:
> Retry all the tasks of all the succeeding stages if a stage with repartition/zip failed. All RDD actions should tell Spark if it's "repeatable", which becomes a property of the result stage. When we retry a result stage that has several tasks finished, if the result stage is "repeatable" (e.g. collect), retry it. If the result stage is not "repeatable", fail the job with the error message to ask users to checkpoint the RDD before repartition/zip.
how does the user then tell spark that the result stage becomes repeatable because they did the checkpoint? Add an option to the api? Or does Spark automatically try to figure that out? I'm still a bit hesitant about making our long term solution that these operations aren't resilient, but I as long as the user can make them resilient perhaps its ok.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
is it ready to go? cc @mridulm @tgravescs @jiangxb1987
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95248 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95248/testReport)** for PR 22112 at commit [`81bd74a`](https://github.com/apache/spark/commit/81bd74ae132c9ec89cfaeeb1f2f8cba20cab3f9e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
haven't look at code yet, does it just fail with ResultTask then?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95697 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95697/testReport)** for PR 22112 at commit [`8952d08`](https://github.com/apache/spark/commit/8952d082b7b9082d38f5b332ccded2d2d7c96b08).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95713/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
> 2. ask the output committer to be able to overwrite a committed task. Note that, the output committer here is the FileCommitProtocol interface in Spark, not the hadoop output committer. We don't have to make all the hadoop output committers work.
I disagree with this. Spark works with any hadoop output committer via RDD api. Spark writing to HBASE is a perfect example of this. You can't do moves in hbase. PairRDDfunctions.saveAsHadoopDataset can be used with hbase, this uses the SparkHadoopWriter.write function that uses the FileCommitProtocol in Spark. If that is assuming moves are possible for all output committers then in my opinon its a bug.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95208 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95208/testReport)** for PR 22112 at commit [`97688cc`](https://github.com/apache/spark/commit/97688ccf809dcf0e4cdb88ef8fa4b89b46b164bd).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r210967814
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1441,6 +1441,44 @@ class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is not idempotent(produces data in a different order when retry)
+ // and the shuffle partitioner is order sensitive, we have to retry all the tasks of
+ // the failed stage and its succeeding stages, because the input data of the failed
+ // stage will be changed after the map tasks are re-tried.
+ if (!mapStage.rdd.isIdempotent && mapStage.shuffleDep.orderSensitivePartitioner) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ if (mapStage.findMissingPartitions().length < mapStage.numPartitions) {
--- End diff --
This is making an assumption that all partitions of a stage are getting computed - which is not necessarily true in a general case (see numTasks vs numPartitions).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94898/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
Thanks for the clarification, but I guess my point is with your last statement:
> - with assumption that we will expand solution to cover all later.
If we document this and say we support unordered operations with the caveat that failures could result in different results, my assumption is we don't necessarily have to do anything else ever (this is what I am proposing). We could decide to for instance add an option to sort, or if its not a result stage fail more tasks to try handle the situation, but strictly speaking we wouldn't have to.
If you think we have to fix those operations that can result in unordered then I think it comes back to we just don't support unordered operations at all and we should say that and probably force the sort on all these operations and possibly on all operations where user could cause it to be different order on rerun.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95400/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by squito <gi...@git.apache.org>.
Github user squito commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r213010846
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1918,3 +1980,19 @@ object RDD {
new DoubleRDDFunctions(rdd.map(x => num.toDouble(x)))
}
}
+
+/**
+ * The random level of RDD's output (i.e. what `RDD#compute` returns), which indicates how the
+ * output will diff when Spark reruns the tasks for the RDD. There are 3 random levels, ordered
+ * by the randomness from low to high:
+ * 1. IDEMPOTENT: The RDD output is always same (including order) when rerun.
--- End diff --
here too, idempotent is the wrong word for this ... deteminstic? partition-ordered? (I guess "ordered" could make it seem like the entire data is ordered ...)
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95096 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95096/testReport)** for PR 22112 at commit [`2a88a47`](https://github.com/apache/spark/commit/2a88a473f036c2da3612f3e53e17d1c05dff4458).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95332 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95332/testReport)** for PR 22112 at commit [`dc45157`](https://github.com/apache/spark/commit/dc45157d1a49ed8145a421422e68bcf9c32faa17).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2550/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
@tgravescs @mridulm @squito @markhamstra Any more comemnts? This blocks 2.4 and I'm going to merge it in the next one or two days, if none of you objects. Thanks!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2465/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212701804
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1865,6 +1871,57 @@ abstract class RDD[T: ClassTag](
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean =
dependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())
+
+ /**
+ * Returns the random level of this RDD's output. Please refer to [[RandomLevel]] for the
+ * definition.
+ *
+ * By default, an reliably checkpointed RDD, or RDD without parents(root RDD) is IDEMPOTENT. For
+ * RDDs with parents, we will generate a random level candidate per parent according to the
+ * dependency. The random level of the current RDD is the random level candidate that is random
+ * most. Please override [[getOutputRandomLevel]] to provide custom logic of calculating output
+ * random level.
+ */
+ // TODO: make it public so users can set random level to their custom RDDs.
+ // TODO: this can be per-partition. e.g. UnionRDD can have different random level for different
+ // partitions.
+ private[spark] final lazy val outputRandomLevel: RandomLevel.Value = {
+ if (checkpointData.exists(_.isInstanceOf[ReliableRDDCheckpointData[_]])) {
+ RandomLevel.IDEMPOTENT
+ } else {
+ getOutputRandomLevel
+ }
+ }
+
+ @DeveloperApi
+ protected def getOutputRandomLevel: RandomLevel.Value = {
+ val randomLevelCandidates = dependencies.map {
+ case dep: ShuffleDependency[_, _, _] =>
--- End diff --
@mridulm I didn't add
```
// if same partitioner, then shuffle not done.
case dep: ShuffleDependency[_, _, _] if dep.partitioner == partitioner => dep.rdd.computingRandomLevel
```
IIUC this condition is always true for `ShuffledRDD`?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95208/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r213387147
--- Diff: core/src/main/scala/org/apache/spark/rdd/LocalCheckpointRDD.scala ---
@@ -37,11 +37,12 @@ import org.apache.spark.storage.RDDBlockId
private[spark] class LocalCheckpointRDD[T: ClassTag](
sc: SparkContext,
rddId: Int,
- numPartitions: Int)
+ numPartitions: Int,
+ deterministicLevel: DeterministicLevel.Value)
--- End diff --
Add `@param` for `deterministicLevel`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95577 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95577/testReport)** for PR 22112 at commit [`63b3eb6`](https://github.com/apache/spark/commit/63b3eb649cfc642d1d62706b4d9a1f3c66f8102e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95128/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #4299 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4299/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95213 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95213/testReport)** for PR 22112 at commit [`17dc144`](https://github.com/apache/spark/commit/17dc1445566ed3d53cf4b815664a9a7f8fef9aa8).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
Any more comments? cc @tgravescs @mridulm @markhamstra
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95242/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on the issue:
https://github.com/apache/spark/pull/22112
ping @tgravescs @mridulm @squito @markhamstra
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95210 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95210/testReport)** for PR 22112 at commit [`6ff55a0`](https://github.com/apache/spark/commit/6ff55a00b0d7fa1543178029a7c884aa46151b2a).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
> assuming the ordering from the source RDD is preserved
This is the problem we are resolving here. This assumption is incorrect, and the RDD closure should handle it, or use what I proposed in this PR: the retry strategy.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on the issue:
https://github.com/apache/spark/pull/22112
I am not sure what the definition of `isIdempotent` here is.
For example, from MapPartitionsRDD :
```
override private[spark] def isIdempotent = {
if (inputOrderSensitive) {
prev.isIdempotent
} else {
true
}
}
```
Consider:
`val rdd1 = rdd.groupBy().map(...).repartition(...).filter(...)`.
By definition above, this would make rdd1 idempotent.
Depending on what the definition of idempotent is (partition level, record level, etc) - this can be correct or wrong code.
Similarly, I am not sure why idempotency or ordering is depending on `Partitioner`.
IMO we should traverse the dependency graph and rely on how `ShuffledRDD` is configured - whether there is a key ordering specified (applies to both global sort and per partition sort), whether it is from a checkpoint or marked for checkpoint, whether it is from a stable input source, etc.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2600/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95248/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94858/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/22112
Thanks! Merged to master.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2464/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212195284
--- Diff: core/src/main/scala/org/apache/spark/rdd/ZippedPartitionsRDD.scala ---
@@ -95,6 +99,18 @@ private[spark] class ZippedPartitionsRDD2[A: ClassTag, B: ClassTag, V: ClassTag]
rdd2 = null
f = null
}
+
+ private def isRandomOrder(rdd: RDD[_]): Boolean = {
+ rdd.computingRandomLevel == RDD.RandomLevel.UNORDERED
--- End diff --
Instead of this, check if order is not IDEMPOTENT.
In both unordered and indeterminate case, we should return indeterminate for this zip rdd from computingRandomLevel.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95607 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95607/testReport)** for PR 22112 at commit [`9a3b8f4`](https://github.com/apache/spark/commit/9a3b8f42c6f9f992fa870e0c7e35ef4be533b561).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94856 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94856/testReport)** for PR 22112 at commit [`6f5d5e9`](https://github.com/apache/spark/commit/6f5d5e96cc82b890c9995b92f2b41bc027151c55).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212385688
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1865,6 +1876,39 @@ abstract class RDD[T: ClassTag](
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean =
dependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())
+
+ /**
+ * Returns the random level of this RDD's computing function. Please refer to [[RDD.RandomLevel]]
+ * for the definition of random level.
+ *
+ * By default, an RDD without parents(root RDD) is IDEMPOTENT. For RDDs with parents, the random
+ * level of current RDD is the random level of the parent which is random most.
+ */
+ // TODO: make it public so users can set random level to their custom RDDs.
+ // TODO: this can be per-partition. e.g. UnionRDD can have different random level for different
+ // partitions.
+ private[spark] def computingRandomLevel: RDD.RandomLevel.Value = {
+ val parentRandomLevels = dependencies.map {
+ case dep: ShuffleDependency[_, _, _] =>
+ if (dep.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ RDD.RandomLevel.INDETERMINATE
--- End diff --
RE: checkpoint.
I wanted to handle two cases.
* Checkpoint is being done as part of the current job (and not a previous job which forced materialization of checkpoint'ed RDD).
* Checkpoint is happening to reliable store, not local - where we are subject to failures on node failures.
Looks like `dep.rdd.isCheckpointed` is the wrong way to go about it (relying on `dependencies` is insufficient for both cases).
A better option seems to be:
```
// If checkpointed already - then always same order
case dep: Dependency if dep.rdd.getCheckpointFile.isDefined => RDD.RandomLevel.IDEMPOTENT
```
> Actually we know. As long as the shuffle map stage RDD is IDEMPOTENT or UNORDERED, the reduce RDD is UNORDERED instead of INDETERMINATE.
It does not matter what the output order of map stage was, after we shuffle the map output, it is always indeterminate order except for the specific cases I referred to above.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95369/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95701/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95597/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
To confirm, is everyone OK with merging this PR, or we are just OK with the direction and need more time to review this PR?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95713 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95713/testReport)** for PR 22112 at commit [`8952d08`](https://github.com/apache/spark/commit/8952d082b7b9082d38f5b332ccded2d2d7c96b08).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94898 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94898/testReport)** for PR 22112 at commit [`f672c12`](https://github.com/apache/spark/commit/f672c120ad3e9b7208004e8b963f0e818f6e0358).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2782/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #4300 has started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4300/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on the issue:
https://github.com/apache/spark/pull/22112
> So in order to fix that we would need a way to tell the executors to remove that older committed shuffle data
@tgravescs It is also hard to implement such a robust solution for removing the older committed shuffle data due to the network partitioning issues, right?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by squito <gi...@git.apache.org>.
Github user squito commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r213017779
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1865,6 +1871,62 @@ abstract class RDD[T: ClassTag](
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean =
dependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())
+
+ /**
+ * Returns the random level of this RDD's output. Please refer to [[RandomLevel]] for the
+ * definition.
+ *
+ * By default, an reliably checkpointed RDD, or RDD without parents(root RDD) is IDEMPOTENT. For
+ * RDDs with parents, we will generate a random level candidate per parent according to the
+ * dependency. The random level of the current RDD is the random level candidate that is random
+ * most. Please override [[getOutputRandomLevel]] to provide custom logic of calculating output
+ * random level.
+ */
+ // TODO: make it public so users can set random level to their custom RDDs.
+ // TODO: this can be per-partition. e.g. UnionRDD can have different random level for different
+ // partitions.
+ private[spark] final lazy val outputRandomLevel: RandomLevel.Value = {
+ if (checkpointData.exists(_.isInstanceOf[ReliableRDDCheckpointData[_]])) {
--- End diff --
hmm, so I took another look at the checkpoint code, and it seems to me like it doesn't checkpointing will actually help. IIUC, checkpointing doesn't actually take place until the *job* finishes, not just the stage:
https://github.com/apache/spark/blob/6193a202aab0271b4532ee4b740318290f2c44a1/core/src/main/scala/org/apache/spark/SparkContext.scala#L2061-L2063
So when you have a failure in the middle of a job with a long pipeline, when you go back to an earlier stage, you're not actually going back to checkpointed data.
But maybe I'm reading this wrong? doesn't seem like what checkpointing _should_ be doing, actually ...
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95420/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2873/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212368000
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -812,11 +813,13 @@ abstract class RDD[T: ClassTag](
*/
private[spark] def mapPartitionsWithIndexInternal[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
- preservesPartitioning: Boolean = false): RDD[U] = withScope {
+ preservesPartitioning: Boolean = false,
+ orderSensitiveFunc: Boolean = false): RDD[U] = withScope {
--- End diff --
nit: add param comment for `orderSensitiveFunc`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2773/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95369 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95369/testReport)** for PR 22112 at commit [`f8ad1e7`](https://github.com/apache/spark/commit/f8ad1e7247a3f33f50a8e2e2d92927ddf2713efc).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212632746
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala ---
@@ -305,17 +306,19 @@ object ShuffleExchangeExec {
rdd
}
+ // round-robin function is order sensitive if we don't sort the input.
+ val orderSensitiveFunc = isRoundRobin && !SQLConf.get.sortBeforeRepartition
if (needToCopyObjectsBeforeShuffle(part)) {
- newRdd.mapPartitionsInternal { iter =>
+ newRdd.mapPartitionsWithIndexInternal((_, iter) => {
--- End diff --
I agree it's clearer, the problem is we need to build a framework to set the property of map functions, e.g.
1. FORCE_ORDER: even the input order changed, the output data set and order will not change. (e.g. sort)
2. SAME_SET: even the input order changed, the output data set will not change. (e.g. i => i + 1)
3. ORDER_SENSITIVE: if the input order change, the output data set will be different. (e.g. round robin)
There may be more types, I haven't dug into it yet. Since it's only used here, maybe not worth to do it now?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95248 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95248/testReport)** for PR 22112 at commit [`81bd74a`](https://github.com/apache/spark/commit/81bd74ae132c9ec89cfaeeb1f2f8cba20cab3f9e).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #4301 has started](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4301/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212209237
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
+ failedStages += mapStage
+ }
+
+ case resultStage =>
+ val numMissingPartitions = resultStage.findMissingPartitions().length
+ if (numMissingPartitions < resultStage.numTasks) {
+ // TODO: support to rollback result tasks.
+ val errorMessage = "A shuffle map stage with random output was failed and " +
+ s"retried. However, Spark cannot rollback the result stage $resultStage " +
+ "to re-process the input data, and has to fail this job. Please " +
+ "eliminate the randomness by checkpointing the RDD before " +
+ "repartition/zip and try again."
+ abortStage(failedStage, errorMessage, None)
+ }
+ }
+
+ def rollbackSucceedingStages(stageChain: List[Stage]): Unit = {
+ if (stageChain.head.id == failedStage.id) {
+ stageChain.foreach { stage =>
+ if (!failedStages.contains(stage)) rollBackStage(stage)
+ }
+ } else {
+ stageChain.head.parents.foreach(s => rollbackSucceedingStages(s :: stageChain))
+ }
+ }
--- End diff --
On the other hand, this branch will not be hitten very offten. We only hit it when a FetchFailure happens and the map stage has random output.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95371 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95371/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95332/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95210 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95210/testReport)** for PR 22112 at commit [`6ff55a0`](https://github.com/apache/spark/commit/6ff55a00b0d7fa1543178029a7c884aa46151b2a).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by markhamstra <gi...@git.apache.org>.
Github user markhamstra commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r213061324
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1918,3 +1980,19 @@ object RDD {
new DoubleRDDFunctions(rdd.map(x => num.toDouble(x)))
}
}
+
+/**
+ * The random level of RDD's output (i.e. what `RDD#compute` returns), which indicates how the
+ * output will diff when Spark reruns the tasks for the RDD. There are 3 random levels, ordered
+ * by the randomness from low to high:
--- End diff --
Again, please remove "random" and "randomness". The issue is not randomness, but rather determinism. For example, the output of `RDD#compute` could be completely non-random but still dependent on state not contained in the RDD. That would still make it problematic in terms of recomputing only some partitions and aggregating the results.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212206542
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
+ failedStages += mapStage
+ }
+
+ case resultStage =>
+ val numMissingPartitions = resultStage.findMissingPartitions().length
+ if (numMissingPartitions < resultStage.numTasks) {
--- End diff --
when run `first()`, I think `numTasks` will be 1, but `numPartitions` can be much larger.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212205748
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1876,6 +1920,22 @@ abstract class RDD[T: ClassTag](
*/
object RDD {
+ /**
+ * The random level of RDD's computing function, which indicates the behavior when rerun the
+ * computing function. There are 3 random levels, ordered by the randomness from low to high:
+ * 1. IDEMPOTENT: The computing function always return the same result with same order when rerun.
+ * 2. UNORDERED: The computing function returns same data set in potentially a different order
+ * when rerun.
+ * 3. INDETERMINATE. The computing function may return totally different result when rerun.
+ *
+ * Note that, the output of the computing function usually relies on parent RDDs. When a
+ * parent RDD's computing function is random, it's very likely this computing function is also
+ * random.
+ */
+ object RandomLevel extends Enumeration {
--- End diff --
You are right about this unclearness. What Spark cares about is the output of an RDD partition(what `RDD#compute` returns) when rerun, the RDD may be a root RDD that don't have a closure, or may be a mapped RDD, or something else, but this doesn't matter.
When Spark executes a chain of RDDs, it only cares about the `RandomLevel` of the last RDD, and RDDs are responsible to propagate this information from the root RDD to the last RDD.
In general, an RDD should have a property to indicate its output behavior when rerun, and some RDDs can define some other methods to help to propagate the `RandomLevel` property. (like the `orderSensitiveFunc` flag in MappedRDD).
How about
```
object OutputDifferWhenRerun extends Enumeration {
val EXACTLY_SAME, DIFFERENT_ORDER, TOTALLY_DIFFERENT = Value
}
```
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95404 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95404/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
* This patch **fails due to an unknown error code, -9**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
To clarify your last few comments, I think you are saying if you were to fail all the reduce tasks, the shuffle write data is still there and doesn't get removed and since first write wins on rerun it might still use the older already shuffled data?
So in order to fix that we would need a way to tell the executors to remove that older committed shuffle data
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r213397293
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -32,12 +32,16 @@ import org.apache.spark.{Partition, TaskContext}
* doesn't modify the keys.
* @param isFromBarrier Indicates whether this RDD is transformed from an RDDBarrier, a stage
* containing at least one RDDBarrier shall be turned into a barrier stage.
+ * @param orderSensitiveFunc whether or not the function is order-sensitive. If it's order
+ * sensitive, it may return totally different result if the input order
+ * changed. Mostly stateful functions are order-sensitive.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false,
- isFromBarrier: Boolean = false)
+ isFromBarrier: Boolean = false,
+ orderSensitiveFunc: Boolean = false)
--- End diff --
`orderSensitiveFunc` -> `isOrderSensitive`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95701 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95701/testReport)** for PR 22112 at commit [`8952d08`](https://github.com/apache/spark/commit/8952d082b7b9082d38f5b332ccded2d2d7c96b08).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
I only see 2 options:
1. force a sort on these operations
2. do nothing and require users to sort or handle someway (checkpoint) if they care.
You can possibly make optimizations to the above and try to do the failure thing if you know the output format ahead of time and conditionally use save to temp location based on output format and if you do an operations like zip.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94855 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94855/testReport)** for PR 22112 at commit [`d187de8`](https://github.com/apache/spark/commit/d187de804b72ecd71bcd6c04af38af1e6c483ab6).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
@mridulm shuffled RDD will never be deterministic unless the shuffle key is the entire record and key ordering is specified. The reduce task fetches multiple remote shuffle blocks at the same time, so the order is always random. In Addition, Spark SQL never specifies key ordering.
Checkpointing will cut down the RDD lineage, and change the RDD dependency to a `OneToOneDependency` of `CheckpointRDD`, so we don't need to care about it.
@tgravescs Forget to mention that it's a temporary workaround to fail with result task. I looked into it and we need to change the semantics of `FileCommitProtocol` to fix it. Maybe it's better to do it in Spark 3.0?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212192600
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -855,16 +858,17 @@ abstract class RDD[T: ClassTag](
* a map on the other).
*/
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
- zipPartitions(other, preservesPartitioning = false) { (thisIter, otherIter) =>
- new Iterator[(T, U)] {
- def hasNext: Boolean = (thisIter.hasNext, otherIter.hasNext) match {
- case (true, true) => true
- case (false, false) => false
- case _ => throw new SparkException("Can only zip RDDs with " +
- "same number of elements in each partition")
+ zipPartitionsInternal(other, preservesPartitioning = false, orderSensitiveFunc = true) {
+ (thisIter, otherIter) =>
+ new Iterator[(T, U)] {
+ def hasNext: Boolean = (thisIter.hasNext, otherIter.hasNext) match {
+ case (true, true) => true
+ case (false, false) => false
+ case _ => throw new SparkException("Can only zip RDDs with " +
+ "same number of elements in each partition")
+ }
+ def next(): (T, U) = (thisIter.next(), otherIter.next())
}
- def next(): (T, U) = (thisIter.next(), otherIter.next())
- }
--- End diff --
Bulk of the change here is simply indentation right (except for zipPartitions -> zipPartitionsInternal and flag) ? I want to make sure I did not miss something here.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95366 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95366/testReport)** for PR 22112 at commit [`24f8cb2`](https://github.com/apache/spark/commit/24f8cb27a45c4c16612fb209db2e1b1ebcd58134).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95219 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95219/testReport)** for PR 22112 at commit [`abec7d7`](https://github.com/apache/spark/commit/abec7d7741e1a379fff586b281bb9c22f2ec4237).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95577 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95577/testReport)** for PR 22112 at commit [`63b3eb6`](https://github.com/apache/spark/commit/63b3eb649cfc642d1d62706b4d9a1f3c66f8102e).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2533/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95420 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95420/testReport)** for PR 22112 at commit [`7001656`](https://github.com/apache/spark/commit/7001656f0bd2819241ec40affa3d224e44fd87c0).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95023 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95023/testReport)** for PR 22112 at commit [`4f8e24d`](https://github.com/apache/spark/commit/4f8e24d33e6df2c60740a6c4d0ebec4db4123f5b).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2625/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
BTW, I think a cleaner fix is to make shuffle files reliable(e.g. put them on HDFS), so that Spark will never retry a task from a finished shuffle map stage. Then all the problems go away, the randomness is materialized with shuffle files and we will not hit correctness issues. This is a big project and maybe we can consider it in Spark 3.0.
For now(2.4) I think failing and asking users to checkpoint is better than just documenting that `repartition`/`zip` may return wrong results. We also have a plan to reduce the possibility of failing later, by marking RDD actions as "repeatable".
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94857/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95129 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95129/testReport)** for PR 22112 at commit [`93f37fa`](https://github.com/apache/spark/commit/93f37fa585462b9ee2fb9e179eab736fbc416d3e).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2535/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95574 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95574/testReport)** for PR 22112 at commit [`37acdcc`](https://github.com/apache/spark/commit/37acdccb1336acdce317d611858259744bea4ec2).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
nevermind see you have an abortStage in there for ResultTask
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #4302 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4302/testReport)** for PR 22112 at commit [`7001656`](https://github.com/apache/spark/commit/7001656f0bd2819241ec40affa3d224e44fd87c0).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95404 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95404/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212332473
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1865,6 +1876,39 @@ abstract class RDD[T: ClassTag](
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean =
dependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())
+
+ /**
+ * Returns the random level of this RDD's computing function. Please refer to [[RDD.RandomLevel]]
+ * for the definition of random level.
+ *
+ * By default, an RDD without parents(root RDD) is IDEMPOTENT. For RDDs with parents, the random
+ * level of current RDD is the random level of the parent which is random most.
+ */
+ // TODO: make it public so users can set random level to their custom RDDs.
+ // TODO: this can be per-partition. e.g. UnionRDD can have different random level for different
+ // partitions.
+ private[spark] def computingRandomLevel: RDD.RandomLevel.Value = {
+ val parentRandomLevels = dependencies.map {
+ case dep: ShuffleDependency[_, _, _] =>
+ if (dep.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ RDD.RandomLevel.INDETERMINATE
--- End diff --
> If checkpointed already - then always same order
`RDD#dependencies` is defined as
```
final def dependencies: Seq[Dependency[_]] = {
checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {
if (dependencies_ == null) {
dependencies_ = getDependencies
}
dependencies_
}
}
```
So we don't need to handle checkpoint here.
> All other shuffle cases, we dont know the output order in spark.
Actually we know. As long as the shuffle map stage RDD is IDEMPOTENT or UNORDERED, the reduce RDD is UNORDERED instead of INDETERMINATE.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95366/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r211065925
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1864,6 +1877,22 @@ abstract class RDD[T: ClassTag](
// From performance concern, cache the value to avoid repeatedly compute `isBarrier()` on a long
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean = dependencies.exists(_.rdd.isBarrier())
+
+ /**
+ * Whether the RDD's computing function is idempotent. Idempotent means the computing function
+ * not only satisfies the requirement, but also produce the same output sequence(the output order
+ * can't vary) given the same input sequence. Spark assumes all the RDDs are idempotent, except
+ * for the shuffle RDD and RDDs derived from non-idempotent RDD.
+ */
--- End diff --
yes, that is expected, unless the computing function sorts the input data. For this case, we can override the `isIdempotent`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95219 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95219/testReport)** for PR 22112 at commit [`abec7d7`](https://github.com/apache/spark/commit/abec7d7741e1a379fff586b281bb9c22f2ec4237).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95574/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2527/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94857 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94857/testReport)** for PR 22112 at commit [`2407328`](https://github.com/apache/spark/commit/2407328ff61db0938eedff7c005bff380ff05878).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r215070653
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1513,37 +1513,34 @@ private[spark] class DAGScheduler(
}
}
+ def generateErrorMessage(stage: Stage): String = {
+ "A shuffle map stage with indeterminate output was failed and retried. " +
+ s"However, Spark cannot rollback the $stage to re-process the input data, " +
+ "and has to fail this job. Please eliminate the determinism by checkpointing " +
--- End diff --
`determinism ` -> `indeterminism `
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2282/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95419 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95419/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95386 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95386/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
* This patch **fails from timeout after a configured wait of \`400m\`**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
I'm preparing a PR for 2.3, thanks for reminding!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2677/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2861/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212190267
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -32,12 +32,16 @@ import org.apache.spark.{Partition, TaskContext}
* doesn't modify the keys.
* @param isFromBarrier Indicates whether this RDD is transformed from an RDDBarrier, a stage
* containing at least one RDDBarrier shall be turned into a barrier stage.
+ * @param orderSensitiveFunc whether or not the zip function is order-sensitive. If it's order
--- End diff --
remove 'zip'
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r210963665
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1864,6 +1877,22 @@ abstract class RDD[T: ClassTag](
// From performance concern, cache the value to avoid repeatedly compute `isBarrier()` on a long
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean = dependencies.exists(_.rdd.isBarrier())
+
+ /**
+ * Whether the RDD's computing function is idempotent. Idempotent means the computing function
+ * not only satisfies the requirement, but also produce the same output sequence(the output order
+ * can't vary) given the same input sequence. Spark assumes all the RDDs are idempotent, except
+ * for the shuffle RDD and RDDs derived from non-idempotent RDD.
+ */
--- End diff --
This will mean all rdd's which are directly or indirectly reading from an unsorted shuffle output are not 'idempotent'.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/spark/pull/22112
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94988 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94988/testReport)** for PR 22112 at commit [`4f8e24d`](https://github.com/apache/spark/commit/4f8e24d33e6df2c60740a6c4d0ebec4db4123f5b).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94856 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94856/testReport)** for PR 22112 at commit [`6f5d5e9`](https://github.com/apache/spark/commit/6f5d5e96cc82b890c9995b92f2b41bc027151c55).
* This patch **fails MiMa tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by mengxr <gi...@git.apache.org>.
Github user mengxr commented on the issue:
https://github.com/apache/spark/pull/22112
If "always return the same result with same order when rerun." is the definition of "idempotent", then yes, MLlib RDD closures always returns the same result if the input doesn't change. We use pseudo-randomness to achieve deterministic behavior.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212376990
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1865,6 +1876,39 @@ abstract class RDD[T: ClassTag](
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean =
dependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())
+
+ /**
+ * Returns the random level of this RDD's computing function. Please refer to [[RDD.RandomLevel]]
+ * for the definition of random level.
+ *
+ * By default, an RDD without parents(root RDD) is IDEMPOTENT. For RDDs with parents, the random
+ * level of current RDD is the random level of the parent which is random most.
+ */
+ // TODO: make it public so users can set random level to their custom RDDs.
+ // TODO: this can be per-partition. e.g. UnionRDD can have different random level for different
+ // partitions.
+ private[spark] def computingRandomLevel: RDD.RandomLevel.Value = {
+ val parentRandomLevels = dependencies.map {
+ case dep: ShuffleDependency[_, _, _] =>
+ if (dep.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ RDD.RandomLevel.INDETERMINATE
--- End diff --
> > All other shuffle cases, we dont know the output order in spark.
>
> Actually we know. As long as the shuffle map stage RDD is IDEMPOTENT or UNORDERED, the reduce RDD is UNORDERED instead of INDETERMINATE.
IIUC shuffle map itself works as follows:
- If Aggregator and key ordering are specified:
- output becomes idempotent;
- If Aggregator or key ordering are not specified:
- If input is indeterminate, then output becomes indeterminate;
- If input is idempotent or unordered, then output becomes unordered.
We have to also include the case @mridulm raised that shuffle map may be skipped.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95242 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95242/testReport)** for PR 22112 at commit [`81bd74a`](https://github.com/apache/spark/commit/81bd74ae132c9ec89cfaeeb1f2f8cba20cab3f9e).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94988 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94988/testReport)** for PR 22112 at commit [`4f8e24d`](https://github.com/apache/spark/commit/4f8e24d33e6df2c60740a6c4d0ebec4db4123f5b).
* This patch **fails due to an unknown error code, -9**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2858/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2647/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94988/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r210963213
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -853,6 +861,11 @@ abstract class RDD[T: ClassTag](
* second element in each RDD, etc. Assumes that the two RDDs have the *same number of
* partitions* and the *same number of elements in each partition* (e.g. one was made through
* a map on the other).
+ *
+ * Note that, `zip` violates the requirement of the RDD computing function. If the order of input
+ * data changes, `zip` will return different result. Because of this, Spark may return unexpected
+ * result if there is a shuffle after `zip`, and the shuffle failed and retried. To workaround
+ * this, users can call `zipPartitions` and sort the input data before zip.
--- End diff --
All zip method are affected by it, not just this one.
I added a list of other methods I have used from memory (though unfortunately it is not exhaustive)
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212192772
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1865,6 +1876,39 @@ abstract class RDD[T: ClassTag](
// RDD chain.
@transient protected lazy val isBarrier_ : Boolean =
dependencies.filter(!_.isInstanceOf[ShuffleDependency[_, _, _]]).exists(_.rdd.isBarrier())
+
+ /**
+ * Returns the random level of this RDD's computing function. Please refer to [[RDD.RandomLevel]]
+ * for the definition of random level.
+ *
+ * By default, an RDD without parents(root RDD) is IDEMPOTENT. For RDDs with parents, the random
+ * level of current RDD is the random level of the parent which is random most.
+ */
+ // TODO: make it public so users can set random level to their custom RDDs.
+ // TODO: this can be per-partition. e.g. UnionRDD can have different random level for different
+ // partitions.
+ private[spark] def computingRandomLevel: RDD.RandomLevel.Value = {
--- End diff --
We will need to expose this with `@Experimental` tag - cant keep it `private[spark]` given the implications for custom RDD's.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2250/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94856/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #4298 has finished](https://amplab.cs.berkeley.edu/jenkins/job/NewSparkPullRequestBuilder/4298/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2252/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
> Without making shuffle output order repeatable, we do not have a way to properly fix this.
Perhaps I'm missing it, but you are saying shuffle here, but just shuffle itself can't fix this. Your map output has to be consistent and the partitioning function has to be consistent. The shuffle simply transfers the bytes its supposed to. Sparks shuffle of those bytes is not consistent in that the order it fetches from can change and without the sort happening on that data the order can be different on rerun. I guess maybe you mean the ShuffledRDD as a whole or do you mean something else here?
> shuffled RDD will never be deterministic unless the shuffle key is the entire record and key ordering is specified.
This is why I say a sort of the entire record (on the bytes themselves if they aren't comparable in the RDD case like we talked about in the other pr) before the partitioning is about the only true solution to this I've thought of. That can have a big performance impact. I haven't looked to see how hard it is to insert that so I guess I should do that. Note I'm actually not advocating sort for all the operations we are talking about, I'm just saying that is the only option I see that "fixes" this reliably without having the user. I think eventually we should do that for repartition or others using the round robin type partitioning.
> What I mentioned was not specific to spark, but general to any MR like system.
> This applies even in hadoop mapreduce and used to be a bug in some of our pig udf's :-)
> For example, if there is random output generated in mapper and there are node failures during reducer phase (after all mapper's have completed), the exact same problem would occur with random mapper output.
> We cannot, ofcourse, stop users from doing it - but we do not guarantee correct results (just as hadoop mapreduce does not in this scenario).
We are actually in agreement then.
All I'm saying is zip is just another variant of this, you could document it as such and do nothing internal to spark to "fix it". The user has to handle by sorting, checkpointing, etc. We could be user friendly by doing something like @cloud-fan is mentioning with failing all reducers when possible or just failing if a resultTask has finished unless they specify some config that says they know what they are doing.
I guess we can separate out these 2 discussions. I think the point of this pr is to temporarily workaround the data loss/corruption issue with repartition by failing. So if everyone agrees on that lets move the discussion to a jira about what to do with the rest of the operators and fix repartition here. thoughts?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2363/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
yeah we should file a separate jira to look at the shuffle output. I'm running a few stress tests and will let you know how those go.
could you file a jira for that and link to this jira? Did we file one for finding a longer term solution for this?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95386 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95386/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on the issue:
https://github.com/apache/spark/pull/22112
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95005 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95005/testReport)** for PR 22112 at commit [`4f8e24d`](https://github.com/apache/spark/commit/4f8e24d33e6df2c60740a6c4d0ebec4db4123f5b).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212206864
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
+ failedStages += mapStage
+ }
+
+ case resultStage =>
+ val numMissingPartitions = resultStage.findMissingPartitions().length
+ if (numMissingPartitions < resultStage.numTasks) {
+ // TODO: support to rollback result tasks.
+ val errorMessage = "A shuffle map stage with random output was failed and " +
+ s"retried. However, Spark cannot rollback the result stage $resultStage " +
+ "to re-process the input data, and has to fail this job. Please " +
+ "eliminate the randomness by checkpointing the RDD before " +
+ "repartition/zip and try again."
+ abortStage(failedStage, errorMessage, None)
--- End diff --
Yea, like we discussed this is left for the next release.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on the issue:
https://github.com/apache/spark/pull/22112
I agree @tgravescs, I was looking at the implementation to understand what the expectations are wrt newly introduced methods/fields and whether they make sense : I did not see any details furnished.
I don’t think we can hack our way out of this.
I would expect a solution for repartition to also be applicable to other order dependent closures as well - though we might choose to fix them later, the basic approach ideally should be transferable.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
retest this please
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95242 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95242/testReport)** for PR 22112 at commit [`81bd74a`](https://github.com/apache/spark/commit/81bd74ae132c9ec89cfaeeb1f2f8cba20cab3f9e).
* This patch **fails due to an unknown error code, -9**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2348/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95426 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95426/testReport)** for PR 22112 at commit [`7001656`](https://github.com/apache/spark/commit/7001656f0bd2819241ec40affa3d224e44fd87c0).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2636/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #94858 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/94858/testReport)** for PR 22112 at commit [`a43acdc`](https://github.com/apache/spark/commit/a43acdc608789fd03f86a30c3dd473117558c79d).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on the issue:
https://github.com/apache/spark/pull/22112
> IMO we should traverse the dependency graph and rely on how ShuffledRDD is configured
A trivial point here - Since `ShuffleDependency` is also a DeveloperAPI, it's possible for users to write a customized RDD that behaves like `ShuffleRDD`, so we may want to depend on dependencies rather than RDDs.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95327 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95327/testReport)** for PR 22112 at commit [`dc45157`](https://github.com/apache/spark/commit/dc45157d1a49ed8145a421422e68bcf9c32faa17).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2522/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95386/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
we should pull this back into spark 2.3 at least, I don't think this is a clean cherry pick due to barrier scheduling stuff, would you be willing to put up PR?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on the issue:
https://github.com/apache/spark/pull/22112
Catching up on discussion ...
@cloud-fan
> shuffled RDD will never be deterministic unless the shuffle key is the entire record and key ordering is specified.
Let me rephrase that - key ordering with aggregator specified.
Unfortunately this will then mean it is applicable only to custom user code - since default spark api's do not set both.
> The reduce task fetches multiple remote shuffle blocks at the same time, so the order is always random.
This is not a characteristics of shuffle in MR based systems, but an implementation detail of shuffle in spark.
In hadoop mapreduce, for example, shuffle output is always ordered and this problem does not occur.
> In Addition, Spark SQL never specifies key ordering.
Spark SQL has re-implemented a lot of the spark core primitives - given this, I would expect spark sql to :
* When there is a rdd view gets generated off a dataframe, a local sort be introduced where appropriate - as has already been done in SPARK-23207 for repartition case. and/or
* appropriately expose IDEMPOTENT, UNORDERED and INDETERMINATE in RDD view.
@tgravescs
> I don't agree that " We actually cannot support random output". Users can do this now in MR and spark and we can't really stop them other then say we don't support and if you do failure handling will cause different results.
What I mentioned was not specific to spark, but general to any MR like system.
This applies even in hadoop mapreduce and used to be a bug in some of our pig udf's :-)
For example, if there is random output generated in mapper and there are node failures during reducer phase (after all mapper's have completed), the exact same problem would occur with random mapper output.
We cannot, ofcourse, stop users from doing it - but we do not guarantee correct results (just as hadoop mapreduce does not in this scenario).
> I don't want us to document it away now and then change our mind in next release. Our end decision should be final.
My current thought is as follows:
Without making shuffle output order repeatable, we do not have a way to properly fix this.
My understanding from @jiangxb1987, who has looked at it in detail with @sameeragarwal and others, is that this is a very difficult invariant to achieve in current spark codebase for shuffle in general.
(Please holler if I am off base @jiangxb1987 !)
With the assumption that we cannot currently fix this - explicitly warn'ing user and/or reschedule all tasks/stages for correctness might be a good stop gap.
User's could mitigate the performance impact via checkpoint'ing [1] - I would expect this to be the go-to solution; for any non trivial job, the perf characteristics and SLA violations are going to be terrible after this patch is applied when failures occur : but we should not have any data loss.
In future, we might resolve this issue in a more principled manner.
[1] As @cloud-fan's pointed out [here|https://github.com/apache/spark/pull/22112#issuecomment-414034703] sort is not gaurantee'ed to work - unless key's are unique : since ordering is defined only on key and not value (and so value re-order can occur).
@cloud-fan
> This is the problem we are resolving here. This assumption is incorrect, and the RDD closure should handle it, or use what I proposed in this PR: the retry strategy.
I would disagree with this - this is an artifact of implementation detail of spark shuffle - and is not the expected behavior for a MR based system.
Unfortunately, this has been the behavior since beginning IMO (atleast since 0.6)
IMO this was not a conscious design choice, but rather an oversight.
> IIRC @mridulm didn't agree with it. One problem is that, it's hard for users to realize that Spark returns wrong result, so they don't know when to handle it.
Actually I would expect user's to end up doing either of these two - the perf characteristics and lack of predictability in SLA after this patch are going to force users to choose one of the two.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() da...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r210450123
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1441,6 +1441,18 @@ class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ if (!mapStage.rdd.isIdempotent) {
+ // The map stage is not idempotent, we have to rerun all the tasks for the
+ // failed stage to get expected result.
+ failedStage match {
+ case s: ShuffleMapStage =>
--- End diff --
We may also have to update the logic in `removeExecutorAndUnregisterOutputs`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95574 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95574/testReport)** for PR 22112 at commit [`37acdcc`](https://github.com/apache/spark/commit/37acdccb1336acdce317d611858259744bea4ec2).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95419 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95419/testReport)** for PR 22112 at commit [`a4e6639`](https://github.com/apache/spark/commit/a4e6639ea098eebe4a06dc9ca27c4386f59bf413).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212651948
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/exchange/ShuffleExchangeExec.scala ---
@@ -305,17 +306,19 @@ object ShuffleExchangeExec {
rdd
}
+ // round-robin function is order sensitive if we don't sort the input.
+ val orderSensitiveFunc = isRoundRobin && !SQLConf.get.sortBeforeRepartition
if (needToCopyObjectsBeforeShuffle(part)) {
- newRdd.mapPartitionsInternal { iter =>
+ newRdd.mapPartitionsWithIndexInternal((_, iter) => {
--- End diff --
sounds good
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95577/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by jiangxb1987 <gi...@git.apache.org>.
Github user jiangxb1987 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212381036
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
+ failedStages += mapStage
+ }
+
+ case resultStage =>
+ val numMissingPartitions = resultStage.findMissingPartitions().length
+ if (numMissingPartitions < resultStage.numTasks) {
+ // TODO: support to rollback result tasks.
+ val errorMessage = "A shuffle map stage with random output was failed and " +
+ s"retried. However, Spark cannot rollback the result stage $resultStage " +
+ "to re-process the input data, and has to fail this job. Please " +
+ "eliminate the randomness by checkpointing the RDD before " +
+ "repartition/zip and try again."
+ abortStage(failedStage, errorMessage, None)
+ }
+ }
+
+ def rollbackSucceedingStages(stageChain: List[Stage]): Unit = {
+ if (stageChain.head.id == failedStage.id) {
+ stageChain.foreach { stage =>
+ if (!failedStages.contains(stage)) rollBackStage(stage)
+ }
+ } else {
+ stageChain.head.parents.foreach(s => rollbackSucceedingStages(s :: stageChain))
+ }
+ }
+
+ rollBackStage(failedStage)
--- End diff --
We may need some comment to explain the tricky corner case here.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212462874
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
+ failedStages += mapStage
+ }
+
+ case resultStage =>
+ val numMissingPartitions = resultStage.findMissingPartitions().length
+ if (numMissingPartitions < resultStage.numTasks) {
+ // TODO: support to rollback result tasks.
+ val errorMessage = "A shuffle map stage with random output was failed and " +
+ s"retried. However, Spark cannot rollback the result stage $resultStage " +
+ "to re-process the input data, and has to fail this job. Please " +
+ "eliminate the randomness by checkpointing the RDD before " +
+ "repartition/zip and try again."
+ abortStage(failedStage, errorMessage, None)
+ }
+ }
+
+ def rollbackSucceedingStages(stageChain: List[Stage]): Unit = {
+ if (stageChain.head.id == failedStage.id) {
+ stageChain.foreach { stage =>
+ if (!failedStages.contains(stage)) rollBackStage(stage)
+ }
+ } else {
+ stageChain.head.parents.foreach(s => rollbackSucceedingStages(s :: stageChain))
+ }
+ }
--- End diff --
Something like this sketch was what I meant :
```
def rollbackSucceedingStages(stageChain: List[Stage], alreadyProcessed: Set[Int]): Set[Int] = {
var processed = alreadyProcessed
val stage = stageChain.head
if (stage.id == failedStage.id) {
stageChain.foreach { stage =>
if (!failedStages.contains(stage)) rollBackStage(stage)
}
} else {
stage.parents.foreach(s =>
if (! processed.contains(s.id)){
processed = rollbackSucceedingStages(s :: stageChain, processed)
})
}
processed + failedStage.id
}
```
(or perhaps with mutable Set to make it simpler ?)
This will reduce need to reprocess stages we have already handled in large dag's; where a stage subtree figures out in multiple places in the dag.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95327 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95327/testReport)** for PR 22112 at commit [`dc45157`](https://github.com/apache/spark/commit/dc45157d1a49ed8145a421422e68bcf9c32faa17).
* This patch **fails due to an unknown error code, -9**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by markhamstra <gi...@git.apache.org>.
Github user markhamstra commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212395101
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -1876,6 +1920,22 @@ abstract class RDD[T: ClassTag](
*/
object RDD {
+ /**
+ * The random level of RDD's computing function, which indicates the behavior when rerun the
+ * computing function. There are 3 random levels, ordered by the randomness from low to high:
+ * 1. IDEMPOTENT: The computing function always return the same result with same order when rerun.
+ * 2. UNORDERED: The computing function returns same data set in potentially a different order
+ * when rerun.
+ * 3. INDETERMINATE. The computing function may return totally different result when rerun.
+ *
+ * Note that, the output of the computing function usually relies on parent RDDs. When a
+ * parent RDD's computing function is random, it's very likely this computing function is also
+ * random.
+ */
+ object RandomLevel extends Enumeration {
--- End diff --
I'm not completely wedded to the IDEMPOTENT, UNORDERED, INDETERMINATE naming, so if somebody has something better or less likely to lead to confusion, I'm fine with that.
I'd like to not use "random" in these names, though, since that implies actually randomness at some level, entropy guarantees, etc. What is key is not whether output values or ordering are truly random, but simply that we can't easily determine what they are or that they are fixed and repeatable. That's why I'd prefer that things like `RDD.RandomLevel.INDETERMINATE` be, I would suggest, `RDD.Determinism.INDETERMINATE`, and `computingRandomLevel` should be `computeDeterminism` (unless we want the slightly cheeky `determineDeterminism` :) ).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212206280
--- Diff: core/src/main/scala/org/apache/spark/rdd/ZippedPartitionsRDD.scala ---
@@ -95,6 +99,18 @@ private[spark] class ZippedPartitionsRDD2[A: ClassTag, B: ClassTag, V: ClassTag]
rdd2 = null
f = null
}
+
+ private def isRandomOrder(rdd: RDD[_]): Boolean = {
+ rdd.computingRandomLevel == RDD.RandomLevel.UNORDERED
--- End diff --
The result is the same. `super.computingRandomLevel` will return `INDETERMINATE` if either `rdd1` or `rdd2` is `INDETERMINATE`.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
> The FileCommitProtocol is an internal API, and our current implementation does store task-level data temporary in a staging directory (See HadoopMapReduceCommitProtocol). That said, we can fix the FileCommitProtocol to be able to rollback a committed task, as long as the job is not committed.
>
> As an example, we can change the semantic of FileCommitProtocol.commitTask, and say that this may be called multiple times for the same task, and the later should win. And change HadoopMapReduceCommitProtocol to support it.
Hmm I wasn't aware that option was added, looks like its only if you use the dynamicPartitionOverwrite which looks like its for very specific output committers for sql. I don't see how that works with all output committers. I can write an output committer that never writes anything to disk, it might write it to a DB, Hbase, or any custom one. Some of these moves don't make sense in.
Note that its also a performance impact, that is why the mapreduce output committers stopped doing this, see the v2 algorithm set via mapreduce.fileoutputcommitter.algorithm.version . (https://issues.apache.org/jira/browse/SPARK-20107). I realize the performance might need to be impacted in certain cases but wanted to point this out at least, my main concern is really the above statement I don't see how this works for all output committers
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
need to look at in more detail but if its straight forward could at least do this short term for the repartition case.
I guess I question whether we really want to do it for zip and other things, see my comment here though: https://github.com/apache/spark/pull/21698
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95208 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95208/testReport)** for PR 22112 at commit [`97688cc`](https://github.com/apache/spark/commit/97688ccf809dcf0e4cdb88ef8fa4b89b46b164bd).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on the issue:
https://github.com/apache/spark/pull/22112
@tgravescs I was specifically in agreement with
> Personally I don't want to talk about implementation until we decide what we want our semantics to be around the unordered operations because that affects any implementation.
and
> I would propose we fix the things that are using the round robin type partitioning (repartition) but then unordered things like zip/MapPartitions (via user code) we document or perhaps give the user the option to sort.
IMO a fix in spark core for repartition should work for most (if not all) order dependent closures - we might choose not to implement for others due to time constraints; but basic idea should be fairly similar.
Given this, I am fine with documenting the potential issue for others and fix for a core subset - with assumption that we will expand solution to cover all later.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
Sorry to be late, as this bug is really hard to reproduce. We need fetch failure to happen after an indeterminate map stage, we also need a large cluster, so that a fetch failure doesn't lose all the executors and retry the entire job.
I created 2 test cases to verify the fix: one is having fetch failure happen in the result stage, so with this fix the job should fail. one is having fetch failure happen in a map stage, so this fix can properly retry the stages and get the correct result.
The tests are run in Databricks cloud with a 20-nodes Spark cluster. The following is the result for the master branch without this PR:


In the tests, we first do a shuffle to produce unordered data, then do a repartition to trigger the bug, finally collect the result and distinct it to see if it's corrected, or call `RDD#distinct` to add another shuffle.
The result for the master branch with this PR:
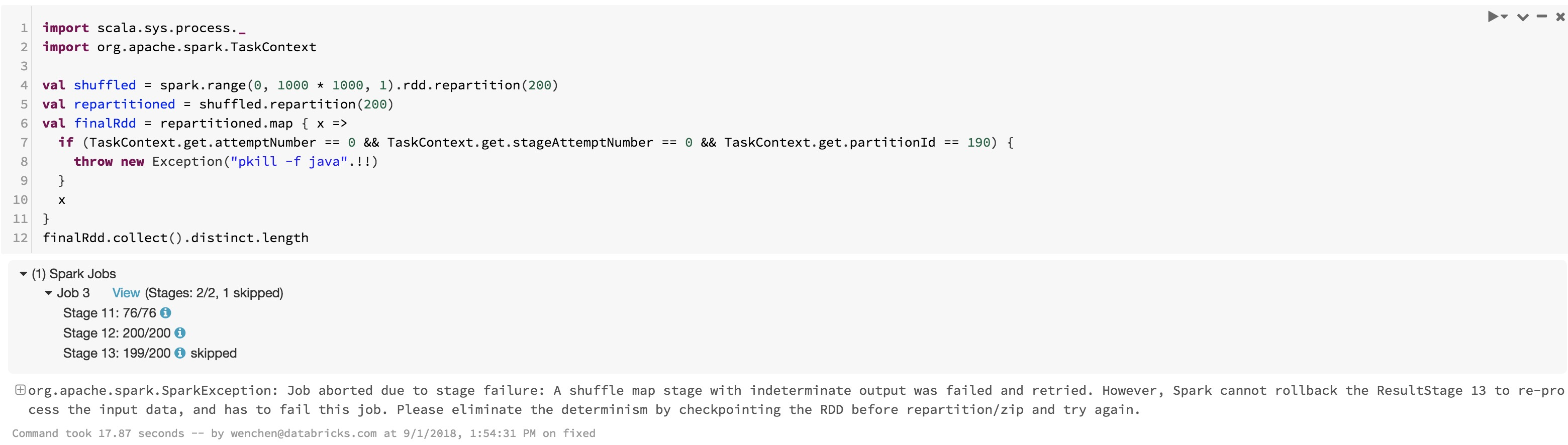

The first job fails, because we detect this bug but are not able to rollback the result stage currently. The second job finishes with corrected result.
If you look into the number of tasks of the stages, you can see that with this fix, the stage hitting fetch failure is entirely retried(200 tasks), while without this fix, only the failed tasks are retried and produce wrong answer.
The last thing: I have to revert https://github.com/apache/spark/pull/20422 to make this fix work. It seems like a dangerous optimization to me: we skip the shuffle writing if the size of the existing shuffle file is same with the size of data we are writing. Same size doesn't mean same data, and my tests exposed it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by mridulm <gi...@git.apache.org>.
Github user mridulm commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212196598
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
+ failedStages += mapStage
+ }
+
+ case resultStage =>
+ val numMissingPartitions = resultStage.findMissingPartitions().length
+ if (numMissingPartitions < resultStage.numTasks) {
--- End diff --
IIRC this can be a valid case - for example if result stage is being run on only a subset of partitions (first() for example) : so number of missing partitions can be legitimately > numTasks and still have missing relevant partitions.
I might be a bit rusty here though, +CC @markhamstra
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
Actually we can extend the solution later and I've mentioned it in my PR description.
Basically there are 3 kinds of closures:
1. totally random
2. always output same data set in a random order
3. always output same data sequence (same order)
Spark is able to handle closure 1, the cost is, whenever a fetch failure happens and a map task gets retried, Spark needs to rollback all the succeeding stages and retry them, because their input has changed. `zip` falls in this category, but due to time constraints, I think it's ok to document it and fix it later.
For closure 2, Spark can treat it as closure 3 if the shuffle partitioner is order insensitive like range/hash partitioner. This means, when a map task gets retried, it will produce the same data for the reducers, so we don't need to rollback all the succeeding stages. However, if the shuffle partitioner is order insensitive like round-robin, Spark has to treat it like closure 1 and rollback all the succeeding stages if a map task gets retried.
Closure 3 is already handled well by the current Spark.
In this PR, I assume all the RDDs' computing functions are closure 3, so that we don't have performance regression. The only exception is shuffled RDD, which outputs data in a random order because of the remote block fetching.
In the future, we can extend `RDD#isIdempotent` to an enum to indicate the 3 closure types, and change the `FetchFailed` handling logic accordingly.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
Personally I don't want to talk about implementation until we decide what we want our semantics to be around the unordered operations because that affects any implementation.
If we are saying we need to fix zip and any other unordered operation that means we don't really support unordered operations and everything needs to be sorted.
I would propose we fix the things that are using the round robin type partitioning (repartition) but then unordered things like zip/MapPartitions (via user code) we document or perhaps give the user the option to sort.
@mridulm you caught the issues with zip and others and have said they need to be fixed, what are your thoughts?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2604/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94821/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
yeah you would have to be able to handle network partitioning somehow. I don't know how difficult it is but its definitely work we may not want to do here. I was trying to clarify and make sure that is the problem @cloud-fan was talking about.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95697 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95697/testReport)** for PR 22112 at commit [`8952d08`](https://github.com/apache/spark/commit/8952d082b7b9082d38f5b332ccded2d2d7c96b08).
* This patch **fails due to an unknown error code, -9**.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95214 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95214/testReport)** for PR 22112 at commit [`f3ffc55`](https://github.com/apache/spark/commit/f3ffc55585370fd7ce5b37885880308e8df2149f).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
@tgravescs yes you are right about the problem here. Instead of asking executors to remove old committed shuffle data, I prefer #6648 , which just write new shuffle data with a different file name(putting stage attempt id in the shuffle file name). The reducers will ask the driver to get the latest shuffle status(the stage attempt id) and fetch the latest shuffle data.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95023 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95023/testReport)** for PR 22112 at commit [`4f8e24d`](https://github.com/apache/spark/commit/4f8e24d33e6df2c60740a6c4d0ebec4db4123f5b).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/2253/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/22112
**[Test build #95369 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/95369/testReport)** for PR 22112 at commit [`f8ad1e7`](https://github.com/apache/spark/commit/f8ad1e7247a3f33f50a8e2e2d92927ddf2713efc).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/95327/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by tgravescs <gi...@git.apache.org>.
Github user tgravescs commented on the issue:
https://github.com/apache/spark/pull/22112
looking. So what all have you done for testing on this? Any manual testing with the checkpoints, etc?
I'll try to run some today.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by gatorsmile <gi...@git.apache.org>.
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r213397871
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala ---
@@ -32,12 +32,16 @@ import org.apache.spark.{Partition, TaskContext}
* doesn't modify the keys.
* @param isFromBarrier Indicates whether this RDD is transformed from an RDDBarrier, a stage
* containing at least one RDDBarrier shall be turned into a barrier stage.
+ * @param orderSensitiveFunc whether or not the function is order-sensitive. If it's order
+ * sensitive, it may return totally different result if the input order
--- End diff --
`it may return totally different result if the input order changed ` -> `it may return totally different result when the input order is changed`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #22112: [SPARK-23243][Core] Fix RDD.repartition() data co...
Posted by cloud-fan <gi...@git.apache.org>.
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22112#discussion_r212207316
--- Diff: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala ---
@@ -1502,6 +1502,53 @@ private[spark] class DAGScheduler(
failedStages += failedStage
failedStages += mapStage
if (noResubmitEnqueued) {
+ // If the map stage is INDETERMINATE, which means the map tasks may return
+ // different result when re-try, we need to re-try all the tasks of the failed
+ // stage and its succeeding stages, because the input data will be changed after the
+ // map tasks are re-tried.
+ // Note that, if map stage is UNORDERED, we are fine. The shuffle partitioner is
+ // guaranteed to be idempotent, so the input data of the reducers will not change even
+ // if the map tasks are re-tried.
+ if (mapStage.rdd.computingRandomLevel == RDD.RandomLevel.INDETERMINATE) {
+ def rollBackStage(stage: Stage): Unit = stage match {
+ case mapStage: ShuffleMapStage =>
+ val numMissingPartitions = mapStage.findMissingPartitions().length
+ if (numMissingPartitions < mapStage.numTasks) {
+ markStageAsFinished(
+ mapStage,
+ Some("preceding shuffle map stage with random output gets retried."),
+ willRetry = true)
+ mapOutputTracker.unregisterAllMapOutput(mapStage.shuffleDep.shuffleId)
+ failedStages += mapStage
+ }
+
+ case resultStage =>
+ val numMissingPartitions = resultStage.findMissingPartitions().length
+ if (numMissingPartitions < resultStage.numTasks) {
+ // TODO: support to rollback result tasks.
+ val errorMessage = "A shuffle map stage with random output was failed and " +
+ s"retried. However, Spark cannot rollback the result stage $resultStage " +
+ "to re-process the input data, and has to fail this job. Please " +
+ "eliminate the randomness by checkpointing the RDD before " +
+ "repartition/zip and try again."
+ abortStage(failedStage, errorMessage, None)
+ }
+ }
+
+ def rollbackSucceedingStages(stageChain: List[Stage]): Unit = {
+ if (stageChain.head.id == failedStage.id) {
+ stageChain.foreach { stage =>
+ if (!failedStages.contains(stage)) rollBackStage(stage)
+ }
+ } else {
+ stageChain.head.parents.foreach(s => rollbackSucceedingStages(s :: stageChain))
+ }
+ }
--- End diff --
It's already added to `failedStages`, and we don't want to skip it when rollback stages.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [SPARK-23243][Core] Fix RDD.repartition() data correctne...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Test FAILed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/94855/
Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #22112: [WIP][SPARK-23243][Core] Fix RDD.repartition() data corr...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/22112
Merged build finished. Test FAILed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org