You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by VinceShieh <gi...@git.apache.org> on 2017/08/14 07:57:42 UTC
[GitHub] spark pull request #18936: [SPARK-21688][ML][MLLIB] make native BLAS the fir...
GitHub user VinceShieh opened a pull request:
https://github.com/apache/spark/pull/18936
[SPARK-21688][ML][MLLIB] make native BLAS the first choice for BLAS level 1 operations for dense data
## What changes were proposed in this pull request?
In this PR, we make native BLAS, if found, the default operations for ddot, daxpy and dscal.
Before this PR, these operations are bound with F2J BLAS, but we found out that with proper setting as we proposed in SPARK-21305, native blas can outperform F2J blas in model training. Moreover, a uni-level test shows these three operations are running faster on native than JVM on different data scale from 10 to 100,000.
## How was this patch tested?
we tested the threes operation on different data scale and got:
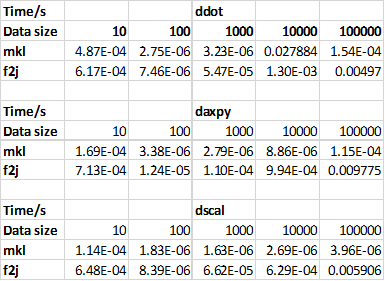
we also tested this PR on SVM and got the result:
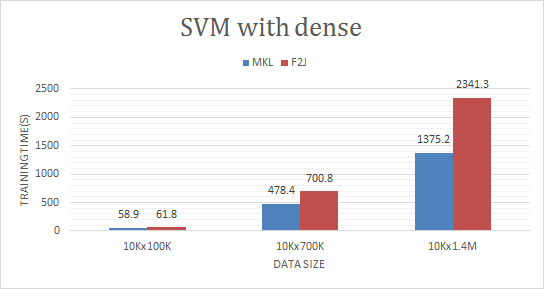
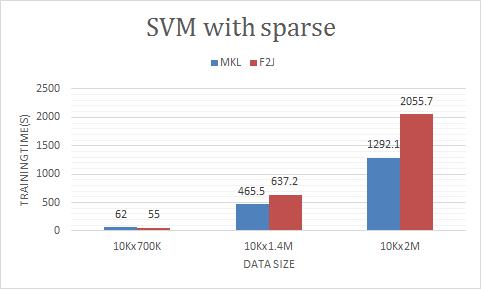
With this PR, these operations are more flexible to users that they can choose to run with F2J or native BLAS as they desire.
Signed-off-by: vincent <vi...@localhost.localdomain>
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/VinceShieh/spark SPARK-21688
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/18936.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #18936
----
commit c9f6347fe53cf3c72340e1daaecd4188381037c4
Author: Vincent Xie <vi...@intel.com>
Date: 2017-08-14T07:43:04Z
[SPARK-21688][ML][MLLIB] make native BLAS the first choice for BLAS level 1 operations for dense data
In this PR, we make native BLAS, if found, the default operations for ddot, daxpy and dscal.
Before this PR, these operations are bound with F2J BLAS, but we found out that with proper setting as we proposed in SPARK-21305, native blas can outperform F2J blas in model training. Moreover, a uni-level test shows these three operations are running faster on native than JVM on different data scale from 10 to 100,000.
Signed-off-by: vincent <vi...@localhost.localdomain>
----
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by srowen <gi...@git.apache.org>.
Github user srowen commented on the issue:
https://github.com/apache/spark/pull/18936
These aren't the only places these operations are called from F2JBLAS. You'd need all of them right?
CC @dbtsai
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by srowen <gi...@git.apache.org>.
Github user srowen commented on the issue:
https://github.com/apache/spark/pull/18936
Yeah I'd believe it's faster with better native threading settings. I think we're back to the issue that with default settings for BLAS libs, this setting would make things somewhat slower.
Do we have any idea what the performance hit would be? ideally for non-MKL implementations. If it's negligible at this point then there's no real issue there.
I do think it's appealing to enable better performance with the right settings. I think we'd want to change this everywhere at once if so as there's no reason to use level 1 in some places and not others.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by srowen <gi...@git.apache.org>.
Github user srowen commented on the issue:
https://github.com/apache/spark/pull/18936
I don't see what that has to do with it. The threading setting only affects what native code does. A single-thread configuration should be able to saturate CPU, too. Allowing multiple threads on top of parallelism hurts because it's introducing some pointless context switching.
What matters are benchmarks: Java vs native code with default settings. If that's not much different, there's really no problem with this change. And ideally the comparison is vs OpenBLAS.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by srowen <gi...@git.apache.org>.
Github user srowen commented on the issue:
https://github.com/apache/spark/pull/18936
BLAS doesn't work on sparse data. All of those invocations are on dense data of some kind. Many of the remaining ones operate on dense matrices even; they're not even level 1. I think all of them would change if you're measuring that level 1 is worth using BLAS for.
CC @MLnick as well as I see comments from him also suggesting that Java is faster for level 1. I'm still kind of unsure what to make of your benchmarks which disagree with previous ones, apparently. What's different?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by MLnick <gi...@git.apache.org>.
Github user MLnick commented on the issue:
https://github.com/apache/spark/pull/18936
I'm not actually sure why the f2jblas implementation was originally forced in level 1, but IIRC it was due to some benchmarking at that time. The intuition is that the overhead of calling into native BLAS exceeds the benefit given that pure JVM for level 1 is "fast enough".
Originally in the ALS recommend work the benchmarks showed f2jblas was faster, but then later it seemed the poor native performance was perhaps due to threading settings etc. So it does bear some investigation.
As Sean mentions, I think there needs to be some more extensive benchmarking than just a few methods and one of the algorithms. Also note that "native" !== "mkl", so that benchmarking needs to include at least OpenBLAS and any others that are common.
Note that this would only impact `mllib` since the `ml` aggregators do the on-the-fly standardization and don't in general use the level 1 BLAS ops. So I don't think the overall impact here is that important since `mllib` is in maintenance mode.
Overall, if we go ahead with this kind of change then we need to benchmark standalone and all the code paths it touches, and furthermore decide if it is worth the change to impact `mllib` only.
cc also @sethah
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by srowen <gi...@git.apache.org>.
Github user srowen commented on the issue:
https://github.com/apache/spark/pull/18936
BTW I do think this is a promising idea. I'd welcome more info about the performance implications, but if it seems like a net win for most users we should do it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by srowen <gi...@git.apache.org>.
Github user srowen commented on the issue:
https://github.com/apache/spark/pull/18936
Interesting, I wouldn't have expected much difference at all. Once it's in native code these are all just SSE instructions on the silicon... I don't know how it could be much different. But naturally I am not an expert on it.
Anyway, the problem here is that you can't selectively use F2J in some cases and not others, so it would potentially slow down OpenBLAS users.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/18936
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/80620/
Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/18936
**[Test build #80620 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/80620/testReport)** for PR 18936 at commit [`c9f6347`](https://github.com/apache/spark/commit/c9f6347fe53cf3c72340e1daaecd4188381037c4).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by VinceShieh <gi...@git.apache.org>.
Github user VinceShieh commented on the issue:
https://github.com/apache/spark/pull/18936
Yes, they are not the only place, but we only tested on the dense dataset and got the performance data shown above. We are conservative on sparse data, so keep the sparse path the way it was. May change them when we have the concrete data prove the necessity to do so.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/18936
Merged build finished. Test PASSed.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by VinceShieh <gi...@git.apache.org>.
Github user VinceShieh commented on the issue:
https://github.com/apache/spark/pull/18936
thanks, Sean and Nick.
To @srowen , I think the difference is the finding from our previous investigation that, thread setting in the native BLAS impacts the overall performance of a method/algorithm.
To @MLnick, Agree. We know it demands a certain amount of benchmark work for this PR, since the changes are in a low level of the stack, they will impact several methods and there are also other native BLAS implementations, not just MKL, So, we take SVM as an example to show what we might get from it. Also, given the fact that mllib is only in maintenance mode, pls let us know if such change is unworthy of the work required.
Thanks!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by VinceShieh <gi...@git.apache.org>.
Github user VinceShieh commented on the issue:
https://github.com/apache/spark/pull/18936
@srowen currently, what we see is, with default thread setting(take up all computation resource available) for native blas, the No. 1 hot spot (with 95%+ self time) is scala.concurrent.impl.Promise$DefaultPromise.tryAwait.
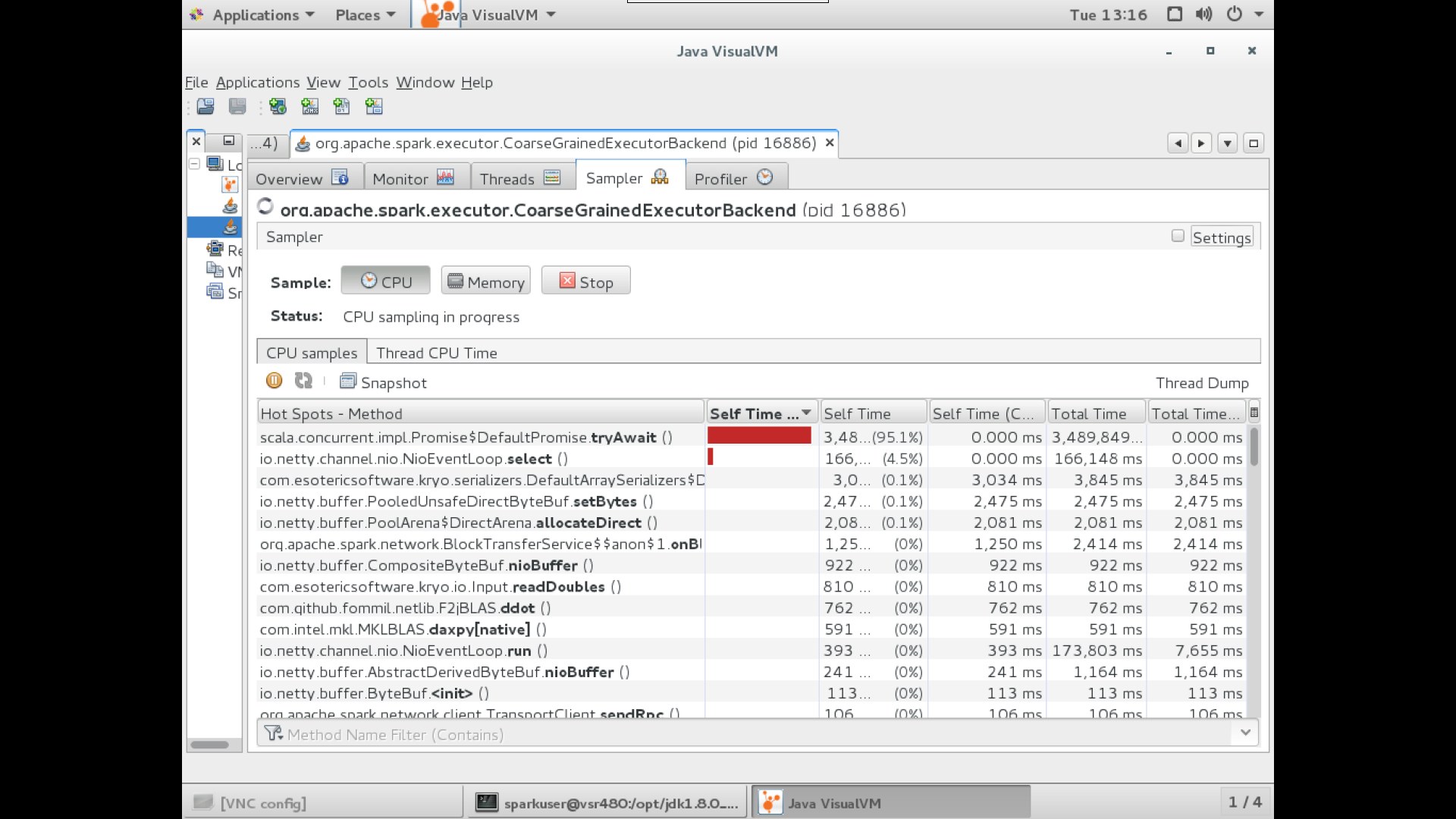
The performance hit might due to, the native takes up all computation cores and doesn't release in time, so the processes on JVM are unable to get enough resource to continue the following tasks. Just a bold guess. We will try to dig deeper to see if we can find more.
We only made changes to the places that take effect in SVM because that's we benchmark on. I will make the changes to the rest of the place once we have more benchmark data on other methods/algorithms affected.
Thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by VinceShieh <gi...@git.apache.org>.
Github user VinceShieh commented on the issue:
https://github.com/apache/spark/pull/18936
Okay. We will benchmark on OpenBLAS. Thanks.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by VinceShieh <gi...@git.apache.org>.
Github user VinceShieh commented on the issue:
https://github.com/apache/spark/pull/18936
Hi Sean, sorry for late reply. Yeah, actually we do have some performance data on F2J vs. OpenBLAS. It seems there is no performance gain from openblas, not even on the unit test level. We are thinking maybe we should setup and test on another cluster in case the result is due to the environment-related issues. we will sort out the data and post here later.
it's possible that openblas may not give us any benefit in this case, but still here are my two cents:
1. like openblas, MKL blas is also free, easy to get and much well documented.
2. it's much easier for users to use MKL blas than openblas, just download it and put it where the system can find it, no installation required. On the other hand, install openblas on each machine is still troublesome, cost us a while to get it work.
3. MKL blas is highly optimized thus has much better performance
4. this PR just opens up an opportunity for users to choose different BLAS impl, they can still go for F2J, so I think it'd be more user-friendly than binding all the level1 blas to F2J.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #18936: [SPARK-21688][ML][MLLIB] make native BLAS the first choi...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/18936
**[Test build #80620 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/80620/testReport)** for PR 18936 at commit [`c9f6347`](https://github.com/apache/spark/commit/c9f6347fe53cf3c72340e1daaecd4188381037c4).
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastructure@apache.org or file a JIRA ticket
with INFRA.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org