You are viewing a plain text version of this content. The canonical link for it is here.
Posted to jira@kafka.apache.org by GitBox <gi...@apache.org> on 2022/06/02 08:08:00 UTC
[GitHub] [kafka] dengziming opened a new pull request, #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
dengziming opened a new pull request, #12238:
URL: https://github.com/apache/kafka/pull/12238
*More detailed description of your change*
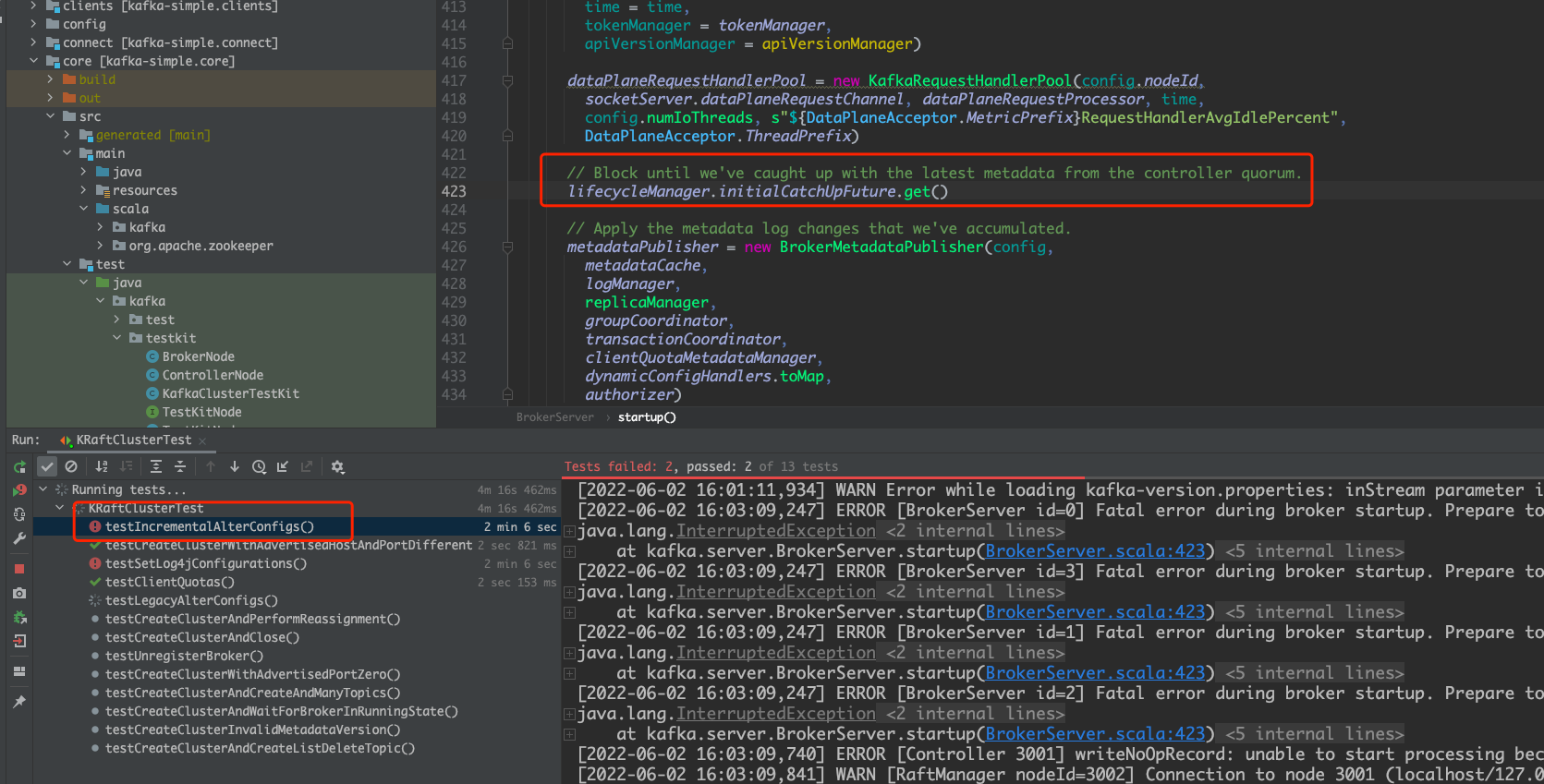
Will will generate NoOpRecord periodically to increase metadata LEO, however, when a broker startup, we will wait until its metadata LEO catches up with the controller LEO, we generate NoOpRecord every 500ms and send heartbeat request every 2000ms.
It's almost impossible for a broker to catch up with the controller LEO if the broker sends a query request every 2000ms but the controller LEO increases every 500ms, so the tests in `KRaftClusterTest` will fail.
*Summary of testing strategy (including rationale)*
After this change, the tests in `KRaftClusterTest` all succeed.
### Committer Checklist (excluded from commit message)
- [ ] Verify design and implementation
- [ ] Verify test coverage and CI build status
- [ ] Verify documentation (including upgrade notes)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] jsancio commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
jsancio commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1145046468
@dengziming Thanks for looking at this. Did you consider fixing the logic for when the controller allows the broker to unfence?
The current implementation requires that `request.currentMetadataOffset() >= lastCommittedOffset`. As you point out this very difficult to achieve on a busy system. Either because of `NoOpRecord` or a lot of controller operations.
For example, should we allow the broker to be behind by `A` records (or time) to unfence the broker? Another solution is to require the broker to only catch up to the last committed offset when they last sent the heartbeat. For example:
1. Broker sends a hearbeat with current offset of `Y`. The last commit offset is `X`. The controller remember this last commit offset, call it `X'`
2. Broker sends another hearbeat with current offset of `Z`. Unfence the broker if `Z >= X` or `Z >= X'`. What do you think?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dengziming commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
dengziming commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1144578570
cc @jsancio @cmccabe
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] jsancio commented on pull request #12238: KAFKA-13955: Fix failing KRaftClusterTest tests
Posted by GitBox <gi...@apache.org>.
jsancio commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1146263145
I merged this PR to fix the tests and I created https://issues.apache.org/jira/browse/KAFKA-13959.
> @showuon Yes, after we reach a consensus here, we should update the KIP and note it in the KIP discussion thread.
@dengziming @showuon My preference is to fix KAFKA-13959 and revert this commit before we ship 3.3.0.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
showuon commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1144876598
[KAFKA-13955](https://issues.apache.org/jira/browse/KAFKA-13955) is created for this failing tests, in case duplicated works by other people. (Because it failed many tests in PR build results)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
showuon commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1145703278
> should we allow the broker to be behind by A records (or time) to unfence the broker?
I've similar solution came out yesterday, but then, I don't think this is a good solution because it might break the expectation/assumption that when broker is up, the broker should already catch up all the metadata changes. There are chances the `A` records/time behind contain some important metadata update, right?
> Another solution is to require the broker to only catch up to the last committed offset when they last sent the heartbeat.
I like this idea. We can make sure the broker already catch up the last committed offset when heartbeat sent, which means, the metadata changes before broker startup are all caught up.
+1 for it!
Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] jsancio merged pull request #12238: KAFKA-13955: Fix failing KRaftClusterTest tests
Posted by GitBox <gi...@apache.org>.
jsancio merged PR #12238:
URL: https://github.com/apache/kafka/pull/12238
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] jsancio commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
jsancio commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1146244214
These are the failing tests:
```
Build / JDK 8 and Scala 2.12 / org.apache.kafka.connect.integration.RebalanceSourceConnectorsIntegrationTest.testRemovingWorker
Build / JDK 8 and Scala 2.12 / kafka.network.ConnectionQuotasTest.testListenerConnectionRateLimitWhenActualRateAboveLimit()
```
They look unrelated to KRaft.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] dengziming commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
dengziming commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1144636319
@showuon Yes, after we reach a consensus here, we should update the KIP and note it in the KIP discussion thread.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] showuon commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
showuon commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1144595607
Interesting bug. If we decided to increase the default `metadata.max.idle.interval.ms` value, we should note in the KIP discussion thread.
However, I'm wondering if increasing the `metadata.max.idle.interval.ms` too high will delay the time we find unavailable controller?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [kafka] cmccabe commented on pull request #12238: KIP-835: MetadataMaxIdleIntervalMs should be much bigger than brokerHeartbeatIntervalMs
Posted by GitBox <gi...@apache.org>.
cmccabe commented on PR #12238:
URL: https://github.com/apache/kafka/pull/12238#issuecomment-1146163957
> Another solution is to require the broker to only catch up to the last committed offset when they last sent the heartbeat.
I like this solution too. However, there are some complexities here (we'd want to make sure the heartbeat wasn't too long ago)
Bumping the no-op timeout to might be a good quick fix until we have time to implement that (although I wonder why we can't use 4 seconds rather than 5?)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: jira-unsubscribe@kafka.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org