You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@arrow.apache.org by ba...@apache.org on 2023/04/11 15:51:51 UTC
[arrow-julia] branch main updated: Add @testsets for misc tests (#421)
This is an automated email from the ASF dual-hosted git repository.
baumgold pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/arrow-julia.git
The following commit(s) were added to refs/heads/main by this push:
new 0a42df8 Add @testsets for misc tests (#421)
0a42df8 is described below
commit 0a42df8b3a1e1f2fce806432215b2aad4018f6fc
Author: Joao Aparicio <jp...@gmail.com>
AuthorDate: Tue Apr 11 10:51:45 2023 -0500
Add @testsets for misc tests (#421)
Tests under "misc" aren't bundled into testsets. As a consequence, tests
terminate when the first misc test fails, making it difficult to get a
good picture of how many failing misc tests remain.
In this commit I've bundled misc tests into testsets.
For example, in (unrelated) work that I'm doing I can see what's still
missing:
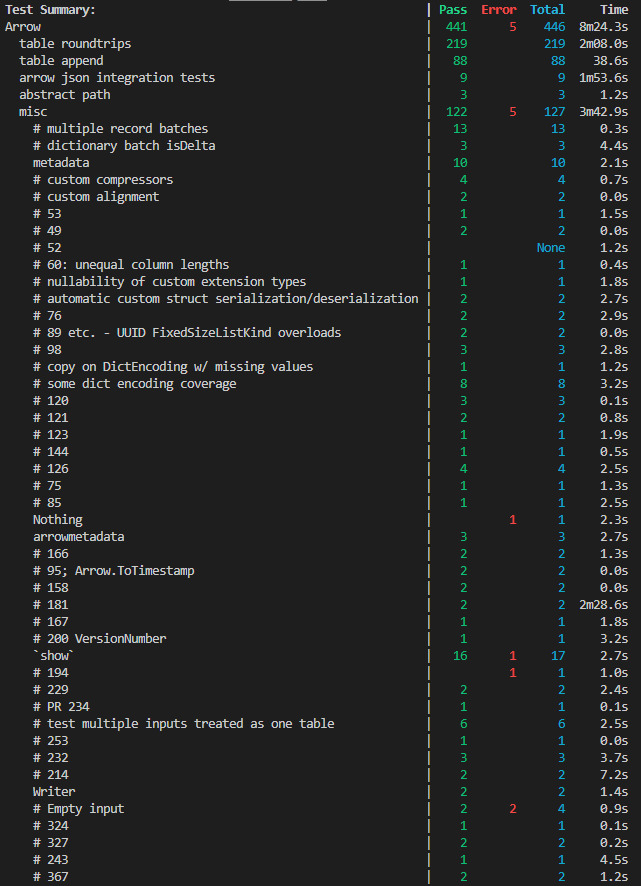
Now I can see I have 5 errors out of 127 total misc tests.
Before it would just show 1 error out of 69 misc tests, as it was
stopping early.
Does anyone else like this?
Co-authored-by: Joao Aparicio <jo...@mavensecurities.com>
---
test/runtests.jl | 123 ++++++++++++++++++++++++++++++++++++++-----------------
1 file changed, 86 insertions(+), 37 deletions(-)
diff --git a/test/runtests.jl b/test/runtests.jl
index 9b02988..512f3e1 100644
--- a/test/runtests.jl
+++ b/test/runtests.jl
@@ -110,7 +110,7 @@ end # @testset "abstract path"
@testset "misc" begin
-# multiple record batches
+@testset "# multiple record batches" begin
t = Tables.partitioner(((col1=Union{Int64, Missing}[1,2,3,4,5,6,7,8,9,missing],), (col1=Union{Int64, Missing}[missing,11],)))
io = Arrow.tobuffer(t)
tt = Arrow.Table(io)
@@ -138,8 +138,9 @@ tt, st = state
@test isequal(collect(str)[1].col1, [1,2,3,4,5,6,7,8,9,missing])
@test isequal(collect(str)[2].col1, [missing,11])
+end
-# dictionary batch isDelta
+@testset "# dictionary batch isDelta" begin
t = (
col1=Int64[1,2,3,4],
col2=Union{String, Missing}["hey", "there", "sailor", missing],
@@ -155,7 +156,9 @@ tt = Arrow.Table(Arrow.tobuffer(tt; dictencode=true, dictencodenested=true))
@test tt.col1 == [1,2,3,4,1,2,5,6]
@test isequal(tt.col2, ["hey", "there", "sailor", missing, "hey", "there", "sailor2", missing])
@test isequal(tt.col3, vcat(NamedTuple{(:a, :b), Tuple{Int64, Union{Missing, NamedTuple{(:c,), Tuple{String}}}}}[(a=Int64(1), b=missing), (a=Int64(1), b=missing), (a=Int64(3), b=(c="sailor",)), (a=Int64(4), b=(c="jo-bob",))], NamedTuple{(:a, :b), Tuple{Int64, Union{Missing, NamedTuple{(:c,), Tuple{String}}}}}[(a=Int64(1), b=missing), (a=Int64(1), b=missing), (a=Int64(5), b=(c="sailor2",)), (a=Int64(4), b=(c="jo-bob",))]))
+end
+@testset "metadata" begin
t = (col1=Int64[1,2,3,4,5,6,7,8,9,10],)
meta = Dict("key1" => "value1", "key2" => "value2")
meta2 = Dict("colkey1" => "colvalue1", "colkey2" => "colvalue2")
@@ -176,8 +179,9 @@ tt = Arrow.Table(Arrow.tobuffer(t; colmetadata=Dict(:col2 => meta2, :col3 => met
@test Arrow.getmetadata(tt.col2)["colkey1"] == "colvalue1"
@test Arrow.getmetadata(tt.col2)["colkey2"] == "colvalue2"
@test Arrow.getmetadata(tt.col3)["colkey3"] == "colvalue3"
+end
-# custom compressors
+@testset "# custom compressors" begin
lz4 = Arrow.CodecLz4.LZ4FrameCompressor(; compressionlevel=8)
Arrow.CodecLz4.TranscodingStreams.initialize(lz4)
t = (col1=Int64[1,2,3,4,5,6,7,8,9,10],)
@@ -191,37 +195,44 @@ t = (col1=Int64[1,2,3,4,5,6,7,8,9,10],)
tt = Arrow.Table(Arrow.tobuffer(t; compress=zstd))
@test length(tt) == length(t)
@test all(isequal.(values(t), values(tt)))
+end
-# custom alignment
+@testset "# custom alignment" begin
t = (col1=Int64[1,2,3,4,5,6,7,8,9,10],)
tt = Arrow.Table(Arrow.tobuffer(t; alignment=64))
@test length(tt) == length(t)
@test all(isequal.(values(t), values(tt)))
+end
-# 53
+@testset "# 53" begin
s = "a" ^ 100
t = (a=[SubString(s, 1:10), SubString(s, 11:20)],)
tt = Arrow.Table(Arrow.tobuffer(t))
@test tt.a == ["aaaaaaaaaa", "aaaaaaaaaa"]
+end
-# 49
+@testset "# 49" begin
@test_throws SystemError Arrow.Table("file_that_doesnt_exist")
@test_throws SystemError Arrow.Table(p"file_that_doesnt_exist")
+end
-# 52
+@testset "# 52" begin
t = (a=Arrow.DictEncode(string.(1:129)),)
tt = Arrow.Table(Arrow.tobuffer(t))
+end
-# 60: unequal column lengths
+@testset "# 60: unequal column lengths" begin
io = IOBuffer()
@test_throws ArgumentError Arrow.write(io, (a = Int[], b = ["asd"], c=collect(1:100)))
+end
-# nullability of custom extension types
+@testset "# nullability of custom extension types" begin
t = (a=['a', missing],)
tt = Arrow.Table(Arrow.tobuffer(t))
@test isequal(tt.a, ['a', missing])
+end
-# automatic custom struct serialization/deserialization
+@testset "# automatic custom struct serialization/deserialization" begin
t = (col1=[CustomStruct(1, 2.3, "hey"), CustomStruct(4, 5.6, "there")],)
Arrow.ArrowTypes.arrowname(::Type{CustomStruct}) = Symbol("JuliaLang.CustomStruct")
@@ -229,31 +240,35 @@ Arrow.ArrowTypes.JuliaType(::Val{Symbol("JuliaLang.CustomStruct")}, S) = CustomS
tt = Arrow.Table(Arrow.tobuffer(t))
@test length(tt) == length(t)
@test all(isequal.(values(t), values(tt)))
+end
-# 76
+@testset "# 76" begin
t = (col1=NamedTuple{(:a,),Tuple{Union{Int,String}}}[(a=1,), (a="x",)],)
tt = Arrow.Table(Arrow.tobuffer(t))
@test length(tt) == length(t)
@test all(isequal.(values(t), values(tt)))
+end
-# 89 etc. - UUID FixedSizeListKind overloads
+@testset "# 89 etc. - UUID FixedSizeListKind overloads" begin
@test Arrow.ArrowTypes.gettype(Arrow.ArrowTypes.ArrowKind(UUID)) == UInt8
@test Arrow.ArrowTypes.getsize(Arrow.ArrowTypes.ArrowKind(UUID)) == 16
+end
-# 98
+@testset "# 98" begin
t = (a = [Nanosecond(0), Nanosecond(1)], b = [uuid4(), uuid4()], c = [missing, Nanosecond(1)])
tt = Arrow.Table(Arrow.tobuffer(t))
@test copy(tt.a) isa Vector{Nanosecond}
@test copy(tt.b) isa Vector{UUID}
@test copy(tt.c) isa Vector{Union{Missing,Nanosecond}}
+end
-# copy on DictEncoding w/ missing values
+@testset "# copy on DictEncoding w/ missing values" begin
x = PooledArray(["hey", missing])
x2 = Arrow.toarrowvector(x)
@test isequal(copy(x2), x)
+end
-# some dict encoding coverage
-
+@testset "# some dict encoding coverage" begin
# signed indices for DictEncodedKind #112 #113 #114
av = Arrow.toarrowvector(PooledArray(repeat(["a", "b"], inner = 5)))
@test isa(first(av.indices), Signed)
@@ -270,31 +285,36 @@ av = Arrow.toarrowvector(CategoricalArray(["a", "bb", "ccc"]))
@test isa(first(av.indices), Signed)
@test length(av) == 3
@test eltype(av) == String
+end
-# 120
+@testset "# 120" begin
x = PooledArray(["hey", missing])
x2 = Arrow.toarrowvector(x)
@test eltype(DataAPI.refpool(x2)) == Union{Missing, String}
@test eltype(DataAPI.levels(x2)) == String
@test DataAPI.refarray(x2) == [1, 2]
+end
-# 121
+@testset "# 121" begin
a = PooledArray(repeat(string.('S', 1:130), inner=5), compress=true)
@test eltype(a.refs) == UInt8
av = Arrow.toarrowvector(a)
@test eltype(av.indices) == Int16
+end
-# 123
+@testset "# 123" begin
t = (x = collect(zip(rand(10), rand(10))),)
tt = Arrow.Table(Arrow.tobuffer(t))
@test tt.x == t.x
+end
-# 144
+@testset "# 144" begin
t = Tables.partitioner(((a=Arrow.DictEncode([1,2,3]),), (a=Arrow.DictEncode(fill(1, 129)),)))
tt = Arrow.Table(Arrow.tobuffer(t))
@test length(tt.a) == 132
+end
-# 126
+@testset "# 126" begin
t = Tables.partitioner(
(
(a=Arrow.toarrowvector(PooledArray([1,2,3 ])),),
@@ -316,19 +336,24 @@ io = IOBuffer()
@test_logs (:error, "error writing arrow data on partition = 2") begin
@test_throws ErrorException Arrow.write(io, t)
end
+end
-# 75
+@testset "# 75" begin
tbl = Arrow.Table(Arrow.tobuffer((sets = [Set([1,2,3]), Set([1,2,3])],)))
@test eltype(tbl.sets) <: Set
+end
-# 85
+@testset "# 85" begin
tbl = Arrow.Table(Arrow.tobuffer((tups = [(1, 3.14, "hey"), (1, 3.14, "hey")],)))
@test eltype(tbl.tups) <: Tuple
+end
-# Nothing
+@testset "Nothing" begin
tbl = Arrow.Table(Arrow.tobuffer((nothings=[nothing, nothing, nothing],)))
@test tbl.nothings == [nothing, nothing, nothing]
+end
+@testset "arrowmetadata" begin
# arrowmetadata
t = (col1=[CustomStruct2{:hey}(1), CustomStruct2{:hey}(2)],)
ArrowTypes.arrowname(::Type{<:CustomStruct2}) = Symbol("CustomStruct2")
@@ -340,8 +365,9 @@ ArrowTypes.arrowmetadata(::Type{CustomStruct2{sym}}) where {sym} = sym
ArrowTypes.JuliaType(::Val{:CustomStruct2}, S, meta) = CustomStruct2{Symbol(meta)}
tbl = Arrow.Table(Arrow.tobuffer(t))
@test eltype(tbl.col1) == CustomStruct2{:hey}
+end
-# 166
+@testset "# 166" begin
t = (
col1=[zero(Arrow.Timestamp{Arrow.Meta.TimeUnits.NANOSECOND, nothing})],
)
@@ -349,14 +375,16 @@ tbl = Arrow.Table(Arrow.tobuffer(t))
@test_logs (:warn, r"automatically converting Arrow.Timestamp with precision = NANOSECOND") begin
@test tbl.col1[1] == Dates.DateTime(1970)
end
+end
-# 95; Arrow.ToTimestamp
+@testset "# 95; Arrow.ToTimestamp" begin
x = [ZonedDateTime(Dates.DateTime(2020), tz"Europe/Paris")]
c = Arrow.ToTimestamp(x)
@test eltype(c) == Arrow.Timestamp{Arrow.Flatbuf.TimeUnits.MILLISECOND, Symbol("Europe/Paris")}
@test c[1] == Arrow.Timestamp{Arrow.Flatbuf.TimeUnits.MILLISECOND, Symbol("Europe/Paris")}(1577833200000)
+end
-# 158
+@testset "# 158" begin
# arrow ipc stream generated from pyarrow with no record batches
bytes = UInt8[0xff, 0xff, 0xff, 0xff, 0x78, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x0c, 0x00,
0x06, 0x00, 0x05, 0x00, 0x08, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x01, 0x04, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x08, 0x00,
@@ -368,8 +396,9 @@ bytes = UInt8[0xff, 0xff, 0xff, 0xff, 0x78, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00,
tbl = Arrow.Table(bytes)
@test length(tbl.a) == 0
@test eltype(tbl.a) == Union{Int64, Missing}
+end
-# 181
+@testset "# 181" begin
d = Dict{Int,Int}()
for i in 1:9
d = Dict(i => d)
@@ -378,16 +407,17 @@ tbl = (x = [d],)
msg = "reached nested serialization level (20) deeper than provided max depth argument (19); to increase allowed nesting level, pass `maxdepth=X`"
@test_throws ErrorException(msg) Arrow.tobuffer(tbl; maxdepth=19)
@test Arrow.Table(Arrow.tobuffer(tbl; maxdepth=20)).x == tbl.x
+end
-# 167
+@testset "# 167" begin
t = (
col1=[["boop", "she"], ["boop", "she"], ["boo"]],
)
tbl = Arrow.Table(Arrow.tobuffer(t))
@test eltype(tbl.col1) == Vector{String}
+end
-# 200
-@testset "VersionNumber" begin
+@testset "# 200 VersionNumber" begin
t = (
col1=[v"1"],
)
@@ -396,6 +426,7 @@ tbl = Arrow.Table(Arrow.tobuffer(t))
end
@testset "`show`" begin
+ str = nothing
table = (; a = 1:5, b = fill(1.0, 5))
arrow_table = Arrow.Table(Arrow.tobuffer(table))
# 2 and 3-arg show with no metadata
@@ -425,11 +456,11 @@ end
end
-#194
+@testset "# 194" begin
@test isempty(Arrow.Table(Arrow.tobuffer(Dict{Symbol, Vector}())))
+end
-
-#229
+@testset "# 229" begin
struct Foo229{x}
y::String
z::Int
@@ -443,8 +474,9 @@ cols = (k1=[Foo229{:a}("a", 1), Foo229{:b}("b", 2)], k2=[Foo229{:c}("c", 3), Foo
tbl = Arrow.Table(Arrow.tobuffer(cols))
@test tbl.k1 == cols.k1
@test tbl.k2 == cols.k2
+end
-# PR 234
+@testset "# PR 234" begin
# bugfix parsing primitive arrays
buf = [
0x14,0x00,0x00,0x00,0x00,0x00,0x0e,0x00,0x14,0x00,0x00,0x00,0x10,0x00,0x0c,0x00,0x08,
@@ -471,8 +503,9 @@ end
d = Arrow.FlatBuffers.getrootas(TestData, buf, 0);
@test d.DataInt32 == UInt32[1,2,3]
+end
-# test multiple inputs treated as one table
+@testset "# test multiple inputs treated as one table" begin
t = (
col1=[1, 2, 3, 4, 5],
col2=[1.2, 2.3, 3.4, 4.5, 5.6],
@@ -497,10 +530,14 @@ t2 = (
col1=[1.2, 2.3, 3.4, 4.5, 5.6],
)
@test_throws ArgumentError collect(Arrow.Stream([Arrow.tobuffer(t), Arrow.tobuffer(t2)]))
+end
+@testset "# 253" begin
# https://github.com/apache/arrow-julia/issues/253
@test Arrow.toidict(Pair{String, String}[]) == Base.ImmutableDict{String, String}()
+end
+@testset "# 232" begin
# https://github.com/apache/arrow-julia/issues/232
t = (; x=[Dict(true => 1.32, 1.2 => 0.53495216)])
@test_throws ArgumentError("`keytype(d)` must be concrete to serialize map-like `d`, but `keytype(d) == Real`") Arrow.tobuffer(t)
@@ -508,7 +545,9 @@ t = (; x=[Dict(32.0 => true, 1.2 => 0.53495216)])
@test_throws ArgumentError("`valtype(d)` must be concrete to serialize map-like `d`, but `valtype(d) == Real`") Arrow.tobuffer(t)
t = (; x=[Dict(true => 1.32, 1.2 => true)])
@test_throws ArgumentError("`keytype(d)` must be concrete to serialize map-like `d`, but `keytype(d) == Real`") Arrow.tobuffer(t)
+end
+@testset "# 214" begin
# https://github.com/apache/arrow-julia/issues/214
t1 = (; x = [(Nanosecond(42),)])
t2 = Arrow.Table(Arrow.tobuffer(t1))
@@ -519,6 +558,7 @@ t1 = (; x = [(; a=Nanosecond(i), b=Nanosecond(i+1)) for i = 1:5])
t2 = Arrow.Table(Arrow.tobuffer(t1))
t3 = Arrow.Table(Arrow.tobuffer(t2))
@test t3.x == t1.x
+end
@testset "Writer" begin
io = IOBuffer()
@@ -538,15 +578,19 @@ t3 = Arrow.Table(Arrow.tobuffer(t2))
@test table.b == collect(b)
end
-# Empty input
+@testset "# Empty input" begin
@test Arrow.Table(UInt8[]) isa Arrow.Table
@test isempty(Tables.rows(Arrow.Table(UInt8[])))
@test Arrow.Stream(UInt8[]) isa Arrow.Stream
@test isempty(Tables.partitions(Arrow.Stream(UInt8[])))
+end
+@testset "# 324" begin
# https://github.com/apache/arrow-julia/issues/324
@test_throws ArgumentError filter!(x -> x > 1, Arrow.toarrowvector([1, 2, 3]))
+end
+@testset "# 327" begin
# https://github.com/apache/arrow-julia/issues/327
zdt = ZonedDateTime(DateTime(2020, 11, 1, 6), tz"America/New_York"; from_utc=true)
arrow_zdt = ArrowTypes.toarrow(zdt)
@@ -557,13 +601,17 @@ zdt_again = ArrowTypes.fromarrow(ZonedDateTime, arrow_zdt)
original_table = (; col = [ ZonedDateTime(DateTime(1, 2, 3, 4, 5, 6), tz"UTC+3") for _ in 1:5])
table = Arrow.Table(joinpath(@__DIR__, "old_zdt.arrow"))
@test original_table.col == table.col
+end
+@testset "# 243" begin
if pkgversion(ArrowTypes) >= v"2.0.1" # need the ArrowTypes bugfix to pass this test
# https://github.com/apache/arrow-julia/issues/243
table = (; col = [(; v=v"1"), (; v=v"2"), missing])
@test isequal(Arrow.Table(Arrow.tobuffer(table)).col, table.col)
end
+end
+@testset "# 367" begin
# https://github.com/apache/arrow-julia/issues/367
if pkgversion(ArrowTypes) >= v"2.0.2"
t = (; x=Union{ZonedDateTime,Missing}[missing])
@@ -571,6 +619,7 @@ if pkgversion(ArrowTypes) >= v"2.0.2"
@test Tables.schema(a) == Tables.schema(t)
@test isequal(a.x, t.x)
end
+end
# https://github.com/apache/arrow-julia/issues/414
df = DataFrame(("$i" => rand(1000) for i in 1:65536)...)