You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by th...@apache.org on 2019/02/19 21:26:49 UTC
[incubator-mxnet] branch master updated: Fix READMEs for examples
(#14179)
This is an automated email from the ASF dual-hosted git repository.
thomasdelteil pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-mxnet.git
The following commit(s) were added to refs/heads/master by this push:
new b396a63 Fix READMEs for examples (#14179)
b396a63 is described below
commit b396a63bf99652bf3ee8c6c9135b73113127fcce
Author: Nathalie Rauschmayr <n....@gmail.com>
AuthorDate: Tue Feb 19 13:26:24 2019 -0800
Fix READMEs for examples (#14179)
* fixing examples
* fixing examples and adding READMEs
fixing examples and adding READMEs
fixing examples and adding READMEs
fixing examples and adding READMEs
add missing files
fixed some bugs in readmes
fixed some bugs in readmes
fixed some spelling mistakes
update
update
* removing images and fixing spelling mistakes
* removing images and fixing spelling mistakes
* updating links
* Adding license header
* empty commit
* Add missing license headers
* Adding changes requested by ChaiBapchya
---
example/captcha/mxnet_captcha.R | 4 +-
example/gan/CGAN_mnist_R/README.md | 168 +++++++++++++++++++++++++++
example/gluon/actor_critic/README.md | 61 ++++++++++
example/gluon/audio/README.md | 115 ++++++++++++++++++
example/gluon/house_prices/README.md | 29 +++++
example/gluon/lstm_crf/README.md | 36 ++++++
example/gluon/mnist/README.md | 55 +++++++++
example/gluon/super_resolution/README.md | 45 +++++++
example/gluon/{ => super_resolution}/data.py | 0
example/model-parallel/README.md | 20 ++++
example/sparse/README.md | 24 ++++
11 files changed, 555 insertions(+), 2 deletions(-)
diff --git a/example/captcha/mxnet_captcha.R b/example/captcha/mxnet_captcha.R
index 8988d25..43e819f 100644
--- a/example/captcha/mxnet_captcha.R
+++ b/example/captcha/mxnet_captcha.R
@@ -39,9 +39,9 @@ label <- mx.symbol.Reshape(data = label, target_shape = c(0))
captcha_net <- mx.symbol.SoftmaxOutput(data = fc2, label = label, name = "softmax")
mx.metric.acc2 <- mx.metric.custom("accuracy", function(label, pred) {
- ypred <- max.col(t(pred)) - 1
+ ypred <- max.col(t(data.matrix(pred))) - 1
ypred <- matrix(ypred, nrow = nrow(label), ncol = ncol(label), byrow = TRUE)
- return(sum(colSums(label == ypred) == 4) / ncol(label))
+ return(sum(colSums(data.matrix(label) == ypred) == 4) / ncol(label))
})
data.shape <- c(80, 30, 3)
diff --git a/example/gan/CGAN_mnist_R/README.md b/example/gan/CGAN_mnist_R/README.md
new file mode 100644
index 0000000..bf0bb08
--- /dev/null
+++ b/example/gan/CGAN_mnist_R/README.md
@@ -0,0 +1,168 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# Conditional Generative Adversarial Network with MXNet R package
+
+This tutorial shows how to build and train a Conditional Generative Adversarial Network (CGAN) on MNIST images.
+
+## How GAN works
+A Generative Adversarial Model simultaneously trains two models: a generator that learns to output fake samples from an unknown distribution and a discriminator that learns to distinguish fake from real samples.
+
+The CGAN is a conditional variation of the GAN where the generator is instructed to generate a real sample having specific characteristics rather than a generic sample from full distribution. Such condition could be the label associated with an image like in this tutorial or a more detailed tag as shown in the example below:
+
+![Image credit: (Scott Reed)[https://github.com/reedscot/icml2016]](https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/gan/CGAN_mnist_R/dcgan_network.jpg)
+
+## Initial setup
+
+The following packages are needed to run the tutorial:
+
+```
+require("imager")
+require("dplyr")
+require("readr")
+require("mxnet")
+```
+
+The full demo is comprised of the two following scripts:
+
+```CGAN_mnist_setup.R```: prepare data and define the model structure
+```CGAN_train.R```: execute the training
+
+## Data preperation
+
+The MNIST dataset is available [here](https://www.kaggle.com/c/digit-recognizer/data)). Once train.csv is downloaded into the data/ folder, we can import into R.
+
+```train <- read_csv('data/train.csv')
+train <- data.matrix(train)
+
+train_data <- train[,-1]
+train_data <- t(train_data/255*2-1)
+train_label <- as.integer(train[,1])
+
+dim(train_data) <- c(28, 28, 1, ncol(train_data))
+```
+Custom iterators are defined in ```iterators.R``` and imported by ```CGAN_mnist_setup.R```
+
+## Generator
+The generator is a network that creates novel samples (MNIST images) from 2 inputs:
+
+- Noise vector
+- Labels defining the object condition (which digit to produce)
+
+The noise vector provides the building blocks to the Generator model, which will learns how to structure that noise into a sample. The mx.symbol.Deconvolution operator is used to upsample the initial input from a 1x1 shape up to a 28x28 image.
+
+The information on the label for which to generate a fake sample is provided by a one-hot encoding of the label indices that is appended to the random noise. For MNIST, the 0-9 indices are therefore converted into a binary vector of length 10. More complex applications would require embeddings rather than simple one-hot to encode the condition.
+
+## Discriminator
+The discriminator attempts to distinguish between fake samples produced by the generator and real ones sampled from MNIST training data.
+
+In a conditional GAN, the labels associated with the samples are also provided to the Discriminator. In this demo, this information is again provided as a hot-hot encoding of the label that is broadcast to match the image dimensions (10 -> 28x28x10).
+
+## Training logic
+The training process of the discriminator is most obvious: the loss is simple a binary TRUE/FALSE response and that loss is propagated back into the CNN network. It can therefore be understood as a simple binary classification problem.
+
+```### Train loop on fake
+mx.exec.update.arg.arrays(exec_D, arg.arrays =
+ list(data=D_data_fake, digit=D_digit_fake, label=mx.nd.array(rep(0, batch_size))),
+ match.name=TRUE)
+mx.exec.forward(exec_D, is.train=T)
+mx.exec.backward(exec_D)
+update_args_D<- updater_D(weight = exec_D$ref.arg.arrays, grad = exec_D$ref.grad.arrays)
+mx.exec.update.arg.arrays(exec_D, update_args_D, skip.null=TRUE)
+
+### Train loop on real
+mx.exec.update.arg.arrays(exec_D, arg.arrays =
+ list(data=D_data_real, digit=D_digit_real, label=mx.nd.array(rep(1, batch_size))),
+ match.name=TRUE)
+mx.exec.forward(exec_D, is.train=T)
+mx.exec.backward(exec_D)
+update_args_D<- updater_D(weight = exec_D$ref.arg.arrays, grad = exec_D$ref.grad.arrays)
+mx.exec.update.arg.arrays(exec_D, update_args_D, skip.null=TRUE)
+```
+
+The generator loss comes from the backpropagation of the the discriminator loss into its generated output. By faking the generator labels to be real samples into the discriminator, the discriminator back-propagated loss provides the generator with the information on how to best adapt its parameters to trick the discriminator into believing the fake samples are real.
+
+This requires to backpropagate the gradients up to the input data of the discriminator (whereas this input gradient is typically ignored in vanilla feedforward network).
+
+```### Update Generator weights - use a seperate executor for writing data gradients
+exec_D_back <- mxnet:::mx.symbol.bind(symbol = D_sym,
+ arg.arrays = exec_D$arg.arrays,
+ aux.arrays = exec_D$aux.arrays, grad.reqs = rep("write", length(exec_D$arg.arrays)),
+ ctx = devices)
+
+mx.exec.update.arg.arrays(exec_D_back, arg.arrays =
+ list(data=D_data_fake, digit=D_digit_fake, label=mx.nd.array(rep(1, batch_size))),
+ match.name=TRUE)
+mx.exec.forward(exec_D_back, is.train=T)
+mx.exec.backward(exec_D_back)
+D_grads <- exec_D_back$ref.grad.arrays$data
+mx.exec.backward(exec_G, out_grads=D_grads)
+
+update_args_G <- updater_G(weight = exec_G$ref.arg.arrays, grad = exec_G$ref.grad.arrays)
+mx.exec.update.arg.arrays(exec_G, update_args_G, skip.null=TRUE)
+```
+
+The above training steps are executed in the ```CGAN_train.R``` script.
+
+## Monitor the training
+
+During training, the [imager](http://dahtah.github.io/imager/) package facilitates the visual quality assessment of the fake samples.
+
+```if (iteration==1 | iteration %% 100==0){
+ par(mfrow=c(3,3), mar=c(0.1,0.1,0.1,0.1))
+ for (i in 1:9) {
+ img <- as.array(exec_G$ref.outputs$G_sym_output)[,,,i]
+ plot(as.cimg(img), axes=F)
+ }
+}
+```
+Below are samples obtained at different stage of the training.
+
+Starting from noise:
+
+
+
+Slowly getting it - iteration 200:
+
+
+
+Generate specified digit images on demand - iteration 2400:
+
+
+
+## Inference
+
+Once the model is trained, synthetic images of the desired digit can be produced by feeding the generator with fixed labels rather than the randomly generated ones used during the training.
+
+Here we will generate fake ```9```:
+
+```digit <- mx.nd.array(rep(9, times=batch_size))
+data <- mx.nd.one.hot(indices = digit, depth = 10)
+data <- mx.nd.reshape(data = data, shape = c(1,1,-1, batch_size))
+
+exec_G <- mx.simple.bind(symbol = G_sym, data=data_shape_G, ctx = devices, grad.req = "null")
+mx.exec.update.arg.arrays(exec_G, G_arg_params, match.name=TRUE)
+mx.exec.update.arg.arrays(exec_G, list(data=data), match.name=TRUE)
+mx.exec.update.aux.arrays(exec_G, G_aux_params, match.name=TRUE)
+
+mx.exec.forward(exec_G, is.train=F)
+```
+
+
+Further details of the CGAN methodology can be found in the paper [Generative Adversarial Text to Image Synthesis](https://arxiv.org/abs/1605.05396).
+
+
diff --git a/example/gluon/actor_critic/README.md b/example/gluon/actor_critic/README.md
new file mode 100644
index 0000000..7f3a6a7
--- /dev/null
+++ b/example/gluon/actor_critic/README.md
@@ -0,0 +1,61 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# Actor Critic Model
+
+This example shows an actor critic model that consists of a critic that measures how good an action taken is and an actor that controls the agent's behavior.
+In our example actor and critic use the same model:
+
+```
+class Policy(gluon.Block):
+ def __init__(self, **kwargs):
+ super(Policy, self).__init__(**kwargs)
+ with self.name_scope():
+ self.dense = nn.Dense(16, in_units=4, activation='relu')
+ self.action_pred = nn.Dense(2, in_units=16)
+ self.value_pred = nn.Dense(1, in_units=16)
+
+ def forward(self, x):
+ x = self.dense(x)
+ probs = self.action_pred(x)
+ values = self.value_pred(x)
+ return F.softmax(probs), values
+```
+The example uses [Gym](https://gym.openai.com/docs/), which is a toolkit for developing and comparing reinforcement learning algorithms. The model is running an instance of [CartPole-v0](https://gym.openai.com/envs/CartPole-v0/) that simulates a pole that is attached by an un-actuated joint to a cart, which moves along a frictionless track. The goal is to prevent it from falling over.
+
+
+The example provides the following commandline options:
+```
+MXNet actor-critic example
+
+optional arguments:
+ -h, --help show this help message and exit
+ --gamma G discount factor (default: 0.99)
+ --seed N random seed (default: 1)
+ --render render the environment
+ --log-interval N interval between training status logs (default: 10)
+
+```
+
+To run the model execute, type
+```
+python actor_critic.py --render
+```
+
+You will get an output like the following:
+
+
diff --git a/example/gluon/audio/README.md b/example/gluon/audio/README.md
new file mode 100644
index 0000000..cb2b53e
--- /dev/null
+++ b/example/gluon/audio/README.md
@@ -0,0 +1,115 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# Urban Sounds Classification in MXNet Gluon
+
+This example provides an end-to-end pipeline for a common datahack competition - [Urban Sounds Classification Example](https://datahack.analyticsvidhya.com/contest/practice-problem-urban-sound-classification/).
+
+After logging in, the data set can be downloaded.
+The details of the dataset and the link to download it are given below:
+
+
+## Urban Sounds Dataset:
+### Description
+ The dataset contains 8732 wav files which are audio samples(<= 4s)) of street sounds like engine_idling, car_horn, children_playing, dog_barking and so on.
+ The task is to classify these audio samples into one of the following 10 labels:
+ ```
+ siren,
+ street_music,
+ drilling,
+ dog_bark,
+ children_playing,
+ gun_shot,
+ engine_idling,
+ air_conditioner,
+ jackhammer,
+ car_horn
+ ```
+
+To be able to run this example:
+
+1. `pip install -r requirements.txt`
+
+ If you are in the directory where the requirements.txt file lies,
+ this step installs the required libraries to run the example.
+ The main dependency that is required is: Librosa.
+ The version used to test the example is: `0.6.2`
+ For more details, refer here:
+https://librosa.github.io/librosa/install.html
+
+2. Download the dataset(train.zip, test.zip) required for this example from the location:
+https://drive.google.com/drive/folders/0By0bAi7hOBAFUHVXd1JCN3MwTEU
+
+3. Extract both the zip archives into the **current directory** - after unzipping you would get 2 new folders namely,
+ **Train** and **Test** and two csv files - **train.csv**, **test.csv**
+
+ Assuming you are in a directory *"UrbanSounds"*, after downloading and extracting train.zip, the folder structure should be:
+
+ ```
+ UrbanSounds
+ - Train
+ - 0.wav, 1.wav ...
+ - train.csv
+ - train.py
+ - predict.py ...
+ ```
+
+4. Apache MXNet is installed on the machine. For instructions, go to the link: https://mxnet.incubator.apache.org/install/
+
+
+
+For information on the current design of how the AudioFolderDataset is implemented, refer below:
+https://cwiki.apache.org/confluence/display/MXNET/Gluon+-+Audio
+
+### Usage
+
+For training:
+
+- Arguments
+ - train : The folder/directory that contains the audio(wav) files locally. Default = "./Train"
+ - csv: The file name of the csv file that contains audio file name to label mapping. Default = "train.csv"
+ - epochs : Number of epochs to train the model. Default = 30
+ - batch_size : The batch size for training. Default = 32
+
+
+###### To use the default arguments, use:
+```
+python train.py
+```
+or
+
+###### To pass command-line arguments for training data directory, epochs, batch_size, csv file name, use :
+```
+python train.py --train ./Train --csv train.csv --batch_size 32 --epochs 30
+```
+
+For prediction:
+
+- Arguments
+ - pred : The folder/directory that contains the audio(wav) files which are to be classified. Default = "./Test"
+
+
+###### To use the default arguments, use:
+```
+python predict.py
+```
+or
+
+###### To pass command-line arguments for test data directory, use :
+```
+python predict.py --pred ./Test
+```
diff --git a/example/gluon/house_prices/README.md b/example/gluon/house_prices/README.md
new file mode 100644
index 0000000..1393a0e
--- /dev/null
+++ b/example/gluon/house_prices/README.md
@@ -0,0 +1,29 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# House Prices: Advanced Regression Techniques
+
+This example shows how to predict house prices and it is based on the [House Price Kaggle challenge](https://www.kaggle.com/c/house-prices-advanced-regression-techniques#description)
+
+First you need to download train and test data set from here:
+```
+https://www.kaggle.com/c/house-prices-advanced-regression-techniques/download/train.csv
+https://www.kaggle.com/c/house-prices-advanced-regression-techniques/download/test.csv
+```
+Afterwards you can execute the script with ```python kaggle_k_fold_cross_validation.py```
+
+For a detailed explanation of the code, you can check out this [chapter](http://d2l.ai/chapter_deep-learning-basics/kaggle-house-price.html) of the Dive into Deep Learning book.
diff --git a/example/gluon/lstm_crf/README.md b/example/gluon/lstm_crf/README.md
new file mode 100644
index 0000000..519c3b8
--- /dev/null
+++ b/example/gluon/lstm_crf/README.md
@@ -0,0 +1,36 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# BiLSTM CRF model
+This example demonstrates how a [BiLSTM-CRF model](https://arxiv.org/pdf/1508.01991v1.pdf) can be implemented in Gluon to perform noun-phrase chunking as a sequence labeling task. In this example we define the following training sample:
+```
+georgia tech is a university in georgia
+B I O O O O B
+```
+The second line is the IOB representation of the above sentence that is learnt by the model. **I** stands for in chunk, **O** for out of a chunk and **B** for beginning of junks.
+
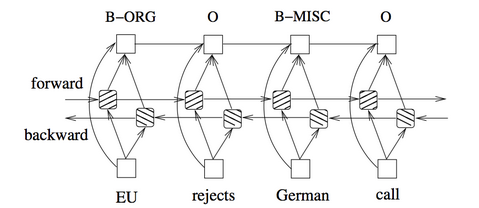
+The model consists of an LSTM layer with 2 hidden units and a CRF layer. The CRF layer has a state transition matrix which allows to take past and future tags into account when predicting the current tag. The bidirectional LSTM is reading the word sequence from beginning to end and vice versa. It prodcues a vector representation for the words. The following image is taken from https://arxiv.org/pdf/1508.01991v1.pdf and shows the model architecture:
+
+
+
+You can run the example by executing
+```
+python lstm_crf.py
+```
+The example code does not take any commandline arguments. If you want to change the number of hidden units or the size of vectors embeddings, then you need to change the variables ```EMBEDDING_DIM``` and ```HIDDEN_DIM```.
+
+
diff --git a/example/gluon/mnist/README.md b/example/gluon/mnist/README.md
new file mode 100644
index 0000000..c053364
--- /dev/null
+++ b/example/gluon/mnist/README.md
@@ -0,0 +1,55 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# MNIST classification example
+
+This script shows a simple example how to do image classification with Gluon.
+The model is trained on MNIST digits image dataset and the goal is to classify the digits ```0-9```. The model has the following layout:
+```
+net = nn.Sequential()
+with net.name_scope():
+ net.add(nn.Dense(128, activation='relu'))
+ net.add(nn.Dense(64, activation='relu'))
+ net.add(nn.Dense(10))
+```
+
+The script provides the following commandline arguments:
+
+
+```
+MXNet Gluon MNIST Example
+
+optional arguments:
+ -h, --help show this help message and exit
+ --batch-size BATCH_SIZE
+ batch size for training and testing (default: 100)
+ --epochs EPOCHS number of epochs to train (default: 10)
+ --lr LR learning rate (default: 0.1)
+ --momentum MOMENTUM SGD momentum (default: 0.9)
+ --cuda Train on GPU with CUDA
+ --log-interval N how many batches to wait before logging training
+ status
+```
+
+After one epoch we get the following output vector for the given test image:
+
+<img src="https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/example/gluon/mnist/test_image.png" width="250" height="250">
+
+[-5.461655 -4.745 -1.8203478 -0.5705207 8.923972 -2.2358544 -3.3020825 -2.409004 4.0074944 10.362008]
+
+As we can see the highest activation is 10.362 which corresponds to label `9`.
+
diff --git a/example/gluon/super_resolution/README.md b/example/gluon/super_resolution/README.md
new file mode 100644
index 0000000..ddcbe8b
--- /dev/null
+++ b/example/gluon/super_resolution/README.md
@@ -0,0 +1,45 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# Superresolution
+
+This example trains a convolutional neural network to enhance the resolution of images (also known as superresolution).
+The script takes the following commandline arguments:
+
+```
+Super-resolution using an efficient sub-pixel convolution neural network.
+
+optional arguments:
+ -h, --help show this help message and exit
+ --upscale_factor UPSCALE_FACTOR
+ super resolution upscale factor. default is 3.
+ --batch_size BATCH_SIZE
+ training batch size, per device. default is 4.
+ --test_batch_size TEST_BATCH_SIZE
+ test batch size
+ --epochs EPOCHS number of training epochs
+ --lr LR learning Rate. default is 0.001.
+ --use-gpu whether to use GPU.
+ --seed SEED random seed to use. Default=123
+ --resolve_img RESOLVE_IMG
+ input image to use
+```
+
+Once the network is trained you can use the following command to increase the resolution of your image:
+```
+python super_resolution.py --resolve_img myimage.jpg
+```
diff --git a/example/gluon/data.py b/example/gluon/super_resolution/data.py
similarity index 100%
rename from example/gluon/data.py
rename to example/gluon/super_resolution/data.py
diff --git a/example/model-parallel/README.md b/example/model-parallel/README.md
new file mode 100644
index 0000000..5375620
--- /dev/null
+++ b/example/model-parallel/README.md
@@ -0,0 +1,20 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# Run parts of a model on different devices
+
+This folder contains the example [matrix_factorization](https://github.com/apache/incubator-mxnet/tree/master/example/model-parallel/matrix_factorization) that demonstrates the basic usage of `group2ctxs`.
diff --git a/example/sparse/README.md b/example/sparse/README.md
new file mode 100644
index 0000000..8f13029
--- /dev/null
+++ b/example/sparse/README.md
@@ -0,0 +1,24 @@
+<!--- Licensed to the Apache Software Foundation (ASF) under one -->
+<!--- or more contributor license agreements. See the NOTICE file -->
+<!--- distributed with this work for additional information -->
+<!--- regarding copyright ownership. The ASF licenses this file -->
+<!--- to you under the Apache License, Version 2.0 (the -->
+<!--- "License"); you may not use this file except in compliance -->
+<!--- with the License. You may obtain a copy of the License at -->
+
+<!--- http://www.apache.org/licenses/LICENSE-2.0 -->
+
+<!--- Unless required by applicable law or agreed to in writing, -->
+<!--- software distributed under the License is distributed on an -->
+<!--- "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY -->
+<!--- KIND, either express or implied. See the License for the -->
+<!--- specific language governing permissions and limitations -->
+<!--- under the License. -->
+
+# Examples using Sparse Symbol API
+This folder contains examples that demonstrate the usage of [Sparse Symbol API](https://mxnet.incubator.apache.org/api/python/symbol/sparse.html)
+- [Factorization Machine](https://github.com/apache/incubator-mxnet/tree/master/example/sparse/factorization_machine) uses sparse weights
+- [Linear Classification Using Sparse Matrix Multiplication](https://github.com/apache/incubator-mxnet/tree/master/example/sparse/linear_classification) shows how to use a sparse data loader, sparse dot operator and sparse gradient updaters
+- [Matrix Factorization w/ Sparse Embedding](https://github.com/apache/incubator-mxnet/tree/master/example/sparse/matrix_factorization) uses sparse weights
+- [Wide and Deep Learning](https://github.com/apache/incubator-mxnet/tree/master/example/sparse/wide_deep) shows how to run sparse wide and deep classification
+