You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@skywalking.apache.org by GitBox <gi...@apache.org> on 2022/10/30 02:07:25 UTC
[GitHub] [skywalking-banyandb] hanahmily opened a new pull request, #198: Add data-model.md to explian objectes in API
hanahmily opened a new pull request, #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198
Signed-off-by: Gao Hongtao <ha...@gmail.com>
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [skywalking-banyandb] lujiajing1126 commented on a diff in pull request #198: Add data-model.md to explian objectes in API
Posted by GitBox <gi...@apache.org>.
lujiajing1126 commented on code in PR #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198#discussion_r1008972978
##########
docs/concept/data-model.md:
##########
@@ -0,0 +1,265 @@
+# Data Model
+
+This chapter introduces BanyanDB's data models and covers the following:
+
+* the high-level data organization
+* data model
+* data retrieval
+
+You can also find [examples](../crud/) of how to interact with BanyanDB using [bydbctl](../clients.md#command-line), how to create and drop groups, or how to create, read, update and drop streams/measures.
+
+## Structure of BanyanDB
+
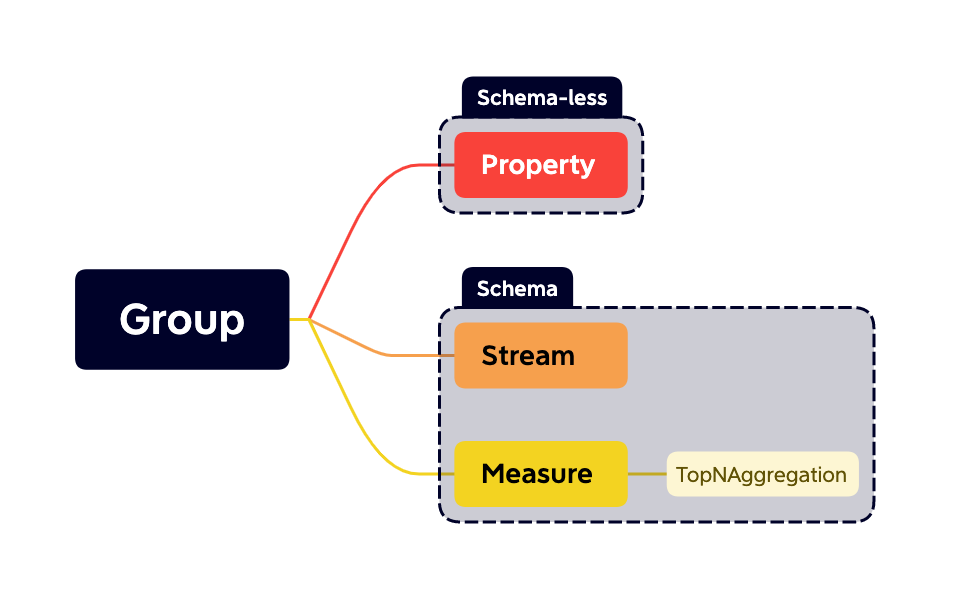
+The hierarchy that data is organized into **streams**, **measures** and **properties** in groups.
+
+
+
+### Measures
+
+BanyanDB lets you define a measure as follows:
+
+```yaml
+metadata:
+ name: service_cpm_minute
+ group: sw_metric
+tag_families:
+- name: default
+ tags:
+ - name: id
+ type: TAG_TYPE_ID
+ - name: entity_id
+ type: TAG_TYPE_STRING
+fields:
+- name: total
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+- name: value
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+entity:
+ tag_names:
+ - entity_id
+interval: 1m
+```
+
+`Measure` consists of a sequence of data points. Each data point contains tags and fields.
+
+`Tags` are key-value pairs. The database engine can index tag values by referring to the index rules and rule bindings, confining the query to filtering data points based on tags bound to an index rule.
+
+`Tags` are grouped into unique `tag_families` which are the logical and physical grouping of tags.
+
+`Measure` supports the following tag types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **STRING_ARRAY** : A group of strings
+* **INT_ARRAY** : A group of integers
+* **DATA_BINARY** : Raw binary
+* **ID** : Identity of a data point in a measure. If several data points come with an identical ID typed tag, the last write wins according to the `timestamp`.
+
+A group of selected tags composite an `entity` that points out a specific time series the data point belongs to. The database engine has capacities to encode and compress values in the same time series. Users should select appropriate tag combinations to optimize the data size. Another role of `entity` is the sharding key of data points, determining how to fragment data between shards.
+
+`Fields` are also key-value pairs like tags. But the value of each field is the actual value of a single data point. The database engine would encode and compress the field's values in the same time series. The query operation is forbidden to filter data points based on a field's value. You could apply aggregation
+functions to them.
+
+`Measure` supports the following fields types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **DATA_BINARY** : Raw binary
+
+`Measure` supports the following encoding methods:
+
+* **GORILLA** : GORILLA encoding is lossless. It is more suitable for a numerical sequence with similar values and is not recommended for sequence data with large fluctuations.
+
+`Measure` supports the types of the following fields:
+
+* **ZSTD** : Zstandard is a real-time compression algorithm, that provides high compression ratios. It offers a very wide range of compression/speed trade-offs, while being backed by a very fast decoder. For BanyanDB focus on speed.
+
+Another option named `interval` plays a critical role in encoding. It indicates the time range between two adjacent data points in a time series and implies that all data points belonging to the same time series are distributed based on a fixed interval. A better practice for the naming measure is to append the interval literal to the tail, for example, `service_cpm_minute`. It's a parameter of `GORILLA` encoding method.
+
+[Measure Registration Operations](../api-reference.md#measureregistryservice)
+
+#### TopNAggregation
+
+Find the Top-N entities from a dataset in a time range is a common scenario. We could see the diagrams like "Top 10 throughput endpoints", and "Most slow 20 endpoints", etc on SkyWalking's UI. Exploring and analyzing the top entities can always find some high-value information.
Review Comment:
```suggestion
Find the Top-N entities from a dataset in a time range is a common scenario. We could see the diagrams like "Top 10 throughput endpoints", and "Most slow 20 endpoints", etc on SkyWalking's UI. Exploring and analyzing the top entities can always reveal some high-value information.
```
##########
docs/concept/data-model.md:
##########
@@ -0,0 +1,265 @@
+# Data Model
+
+This chapter introduces BanyanDB's data models and covers the following:
+
+* the high-level data organization
+* data model
+* data retrieval
+
+You can also find [examples](../crud/) of how to interact with BanyanDB using [bydbctl](../clients.md#command-line), how to create and drop groups, or how to create, read, update and drop streams/measures.
+
+## Structure of BanyanDB
+
+The hierarchy that data is organized into **streams**, **measures** and **properties** in groups.
+
+
+
+### Measures
+
+BanyanDB lets you define a measure as follows:
+
+```yaml
+metadata:
+ name: service_cpm_minute
+ group: sw_metric
+tag_families:
+- name: default
+ tags:
+ - name: id
+ type: TAG_TYPE_ID
+ - name: entity_id
+ type: TAG_TYPE_STRING
+fields:
+- name: total
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+- name: value
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+entity:
+ tag_names:
+ - entity_id
+interval: 1m
+```
+
+`Measure` consists of a sequence of data points. Each data point contains tags and fields.
+
+`Tags` are key-value pairs. The database engine can index tag values by referring to the index rules and rule bindings, confining the query to filtering data points based on tags bound to an index rule.
+
+`Tags` are grouped into unique `tag_families` which are the logical and physical grouping of tags.
+
+`Measure` supports the following tag types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **STRING_ARRAY** : A group of strings
+* **INT_ARRAY** : A group of integers
+* **DATA_BINARY** : Raw binary
+* **ID** : Identity of a data point in a measure. If several data points come with an identical ID typed tag, the last write wins according to the `timestamp`.
+
+A group of selected tags composite an `entity` that points out a specific time series the data point belongs to. The database engine has capacities to encode and compress values in the same time series. Users should select appropriate tag combinations to optimize the data size. Another role of `entity` is the sharding key of data points, determining how to fragment data between shards.
+
+`Fields` are also key-value pairs like tags. But the value of each field is the actual value of a single data point. The database engine would encode and compress the field's values in the same time series. The query operation is forbidden to filter data points based on a field's value. You could apply aggregation
+functions to them.
+
+`Measure` supports the following fields types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **DATA_BINARY** : Raw binary
+
+`Measure` supports the following encoding methods:
+
+* **GORILLA** : GORILLA encoding is lossless. It is more suitable for a numerical sequence with similar values and is not recommended for sequence data with large fluctuations.
+
+`Measure` supports the types of the following fields:
+
+* **ZSTD** : Zstandard is a real-time compression algorithm, that provides high compression ratios. It offers a very wide range of compression/speed trade-offs, while being backed by a very fast decoder. For BanyanDB focus on speed.
+
+Another option named `interval` plays a critical role in encoding. It indicates the time range between two adjacent data points in a time series and implies that all data points belonging to the same time series are distributed based on a fixed interval. A better practice for the naming measure is to append the interval literal to the tail, for example, `service_cpm_minute`. It's a parameter of `GORILLA` encoding method.
+
+[Measure Registration Operations](../api-reference.md#measureregistryservice)
+
+#### TopNAggregation
+
+Find the Top-N entities from a dataset in a time range is a common scenario. We could see the diagrams like "Top 10 throughput endpoints", and "Most slow 20 endpoints", etc on SkyWalking's UI. Exploring and analyzing the top entities can always find some high-value information.
+
+BanyanDB introduces the `TopNAggregation`, aiming to pre-calculate the top/bottom entities during the measure writing phase. In the query phase, BanyanDB can quickly retrieve the top/bottom records. The performance would be much better than `top()` function which is based on the query phase aggregation procedure.
+
+> Caveat: `TopNAggregation` is an approximate realization, to use it well you need have a good understanding with the algorithm as well as the data distribution.
+
+```yaml
+---
+metadata:
+ name: endpoint_cpm_minute_top_bottom
+ group: sw_metric
+source_measure:
+ name: endpoint_cpm_minute
+ group: sw_metric
+field_name: value
+field_value_sort: SORT_UNSPECIFIED
+group_by_tag_names:
+- entity_id
+counters_number: 10000
+lru_size: 10
+```
+
+`endpoint_cpm_minute_top_bottom` is watching the data ingesting of `endpoint_cpm_minute` to generate top 1000 and bottom 1000 entity cardinalities respectively. If you want to only calculate Top 1000 or Bottom 1000, the `field_value_sort` could be `DESC` or `ASC`.
+
+* SORT_DESC: Top-N. In a series of `1,2,3...1000`. Top10's result is `1000,999...991`.
+* SORT_ASC: Bottom-N. In a series of `1,2,3...1000`. Bottom10's result is `1,2...10`.
+
+Tags in `group_by_tag_names` need to be as dimensions. The query phase could retrieve these tags. Tags no in `group_by_tag_names` could be dropped in the calculating phase.
+
+`counters_number` denotes the number of entity cardinality. As the example shows, calculating the Top 100 among 10 thousand is easier than among 10 million.
Review Comment:
```suggestion
`counters_number` denotes the number of entity cardinality. As the above example shows, calculating the Top 100 among 10 thousands is easier than among 10 millions.
```
##########
docs/concept/data-model.md:
##########
@@ -0,0 +1,265 @@
+# Data Model
+
+This chapter introduces BanyanDB's data models and covers the following:
+
+* the high-level data organization
+* data model
+* data retrieval
+
+You can also find [examples](../crud/) of how to interact with BanyanDB using [bydbctl](../clients.md#command-line), how to create and drop groups, or how to create, read, update and drop streams/measures.
+
+## Structure of BanyanDB
+
+The hierarchy that data is organized into **streams**, **measures** and **properties** in groups.
+
+
+
+### Measures
+
+BanyanDB lets you define a measure as follows:
+
+```yaml
+metadata:
+ name: service_cpm_minute
+ group: sw_metric
+tag_families:
+- name: default
+ tags:
+ - name: id
+ type: TAG_TYPE_ID
+ - name: entity_id
+ type: TAG_TYPE_STRING
+fields:
+- name: total
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+- name: value
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+entity:
+ tag_names:
+ - entity_id
+interval: 1m
+```
+
+`Measure` consists of a sequence of data points. Each data point contains tags and fields.
+
+`Tags` are key-value pairs. The database engine can index tag values by referring to the index rules and rule bindings, confining the query to filtering data points based on tags bound to an index rule.
+
+`Tags` are grouped into unique `tag_families` which are the logical and physical grouping of tags.
+
+`Measure` supports the following tag types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **STRING_ARRAY** : A group of strings
+* **INT_ARRAY** : A group of integers
+* **DATA_BINARY** : Raw binary
+* **ID** : Identity of a data point in a measure. If several data points come with an identical ID typed tag, the last write wins according to the `timestamp`.
+
+A group of selected tags composite an `entity` that points out a specific time series the data point belongs to. The database engine has capacities to encode and compress values in the same time series. Users should select appropriate tag combinations to optimize the data size. Another role of `entity` is the sharding key of data points, determining how to fragment data between shards.
+
+`Fields` are also key-value pairs like tags. But the value of each field is the actual value of a single data point. The database engine would encode and compress the field's values in the same time series. The query operation is forbidden to filter data points based on a field's value. You could apply aggregation
+functions to them.
+
+`Measure` supports the following fields types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **DATA_BINARY** : Raw binary
+
+`Measure` supports the following encoding methods:
+
+* **GORILLA** : GORILLA encoding is lossless. It is more suitable for a numerical sequence with similar values and is not recommended for sequence data with large fluctuations.
+
+`Measure` supports the types of the following fields:
+
+* **ZSTD** : Zstandard is a real-time compression algorithm, that provides high compression ratios. It offers a very wide range of compression/speed trade-offs, while being backed by a very fast decoder. For BanyanDB focus on speed.
+
+Another option named `interval` plays a critical role in encoding. It indicates the time range between two adjacent data points in a time series and implies that all data points belonging to the same time series are distributed based on a fixed interval. A better practice for the naming measure is to append the interval literal to the tail, for example, `service_cpm_minute`. It's a parameter of `GORILLA` encoding method.
+
+[Measure Registration Operations](../api-reference.md#measureregistryservice)
+
+#### TopNAggregation
+
+Find the Top-N entities from a dataset in a time range is a common scenario. We could see the diagrams like "Top 10 throughput endpoints", and "Most slow 20 endpoints", etc on SkyWalking's UI. Exploring and analyzing the top entities can always find some high-value information.
+
+BanyanDB introduces the `TopNAggregation`, aiming to pre-calculate the top/bottom entities during the measure writing phase. In the query phase, BanyanDB can quickly retrieve the top/bottom records. The performance would be much better than `top()` function which is based on the query phase aggregation procedure.
+
+> Caveat: `TopNAggregation` is an approximate realization, to use it well you need have a good understanding with the algorithm as well as the data distribution.
+
+```yaml
+---
+metadata:
+ name: endpoint_cpm_minute_top_bottom
+ group: sw_metric
+source_measure:
+ name: endpoint_cpm_minute
+ group: sw_metric
+field_name: value
+field_value_sort: SORT_UNSPECIFIED
+group_by_tag_names:
+- entity_id
+counters_number: 10000
+lru_size: 10
+```
+
+`endpoint_cpm_minute_top_bottom` is watching the data ingesting of `endpoint_cpm_minute` to generate top 1000 and bottom 1000 entity cardinalities respectively. If you want to only calculate Top 1000 or Bottom 1000, the `field_value_sort` could be `DESC` or `ASC`.
+
+* SORT_DESC: Top-N. In a series of `1,2,3...1000`. Top10's result is `1000,999...991`.
+* SORT_ASC: Bottom-N. In a series of `1,2,3...1000`. Bottom10's result is `1,2...10`.
+
+Tags in `group_by_tag_names` need to be as dimensions. The query phase could retrieve these tags. Tags no in `group_by_tag_names` could be dropped in the calculating phase.
Review Comment:
```suggestion
Tags in `group_by_tag_names` are used as dimensions. These tags can be searched (only equality is supported) in the query phase. Tags do not exist in `group_by_tag_names` will be dropped in the pre-calculating phase.
```
##########
docs/concept/data-model.md:
##########
@@ -0,0 +1,265 @@
+# Data Model
+
+This chapter introduces BanyanDB's data models and covers the following:
+
+* the high-level data organization
+* data model
+* data retrieval
+
+You can also find [examples](../crud/) of how to interact with BanyanDB using [bydbctl](../clients.md#command-line), how to create and drop groups, or how to create, read, update and drop streams/measures.
+
+## Structure of BanyanDB
+
+The hierarchy that data is organized into **streams**, **measures** and **properties** in groups.
+
+
+
+### Measures
+
+BanyanDB lets you define a measure as follows:
+
+```yaml
+metadata:
+ name: service_cpm_minute
+ group: sw_metric
+tag_families:
+- name: default
+ tags:
+ - name: id
+ type: TAG_TYPE_ID
+ - name: entity_id
+ type: TAG_TYPE_STRING
+fields:
+- name: total
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+- name: value
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+entity:
+ tag_names:
+ - entity_id
+interval: 1m
+```
+
+`Measure` consists of a sequence of data points. Each data point contains tags and fields.
+
+`Tags` are key-value pairs. The database engine can index tag values by referring to the index rules and rule bindings, confining the query to filtering data points based on tags bound to an index rule.
+
+`Tags` are grouped into unique `tag_families` which are the logical and physical grouping of tags.
+
+`Measure` supports the following tag types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **STRING_ARRAY** : A group of strings
+* **INT_ARRAY** : A group of integers
+* **DATA_BINARY** : Raw binary
+* **ID** : Identity of a data point in a measure. If several data points come with an identical ID typed tag, the last write wins according to the `timestamp`.
+
+A group of selected tags composite an `entity` that points out a specific time series the data point belongs to. The database engine has capacities to encode and compress values in the same time series. Users should select appropriate tag combinations to optimize the data size. Another role of `entity` is the sharding key of data points, determining how to fragment data between shards.
+
+`Fields` are also key-value pairs like tags. But the value of each field is the actual value of a single data point. The database engine would encode and compress the field's values in the same time series. The query operation is forbidden to filter data points based on a field's value. You could apply aggregation
+functions to them.
+
+`Measure` supports the following fields types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **DATA_BINARY** : Raw binary
+
+`Measure` supports the following encoding methods:
+
+* **GORILLA** : GORILLA encoding is lossless. It is more suitable for a numerical sequence with similar values and is not recommended for sequence data with large fluctuations.
+
+`Measure` supports the types of the following fields:
+
+* **ZSTD** : Zstandard is a real-time compression algorithm, that provides high compression ratios. It offers a very wide range of compression/speed trade-offs, while being backed by a very fast decoder. For BanyanDB focus on speed.
+
+Another option named `interval` plays a critical role in encoding. It indicates the time range between two adjacent data points in a time series and implies that all data points belonging to the same time series are distributed based on a fixed interval. A better practice for the naming measure is to append the interval literal to the tail, for example, `service_cpm_minute`. It's a parameter of `GORILLA` encoding method.
+
+[Measure Registration Operations](../api-reference.md#measureregistryservice)
+
+#### TopNAggregation
+
+Find the Top-N entities from a dataset in a time range is a common scenario. We could see the diagrams like "Top 10 throughput endpoints", and "Most slow 20 endpoints", etc on SkyWalking's UI. Exploring and analyzing the top entities can always find some high-value information.
+
+BanyanDB introduces the `TopNAggregation`, aiming to pre-calculate the top/bottom entities during the measure writing phase. In the query phase, BanyanDB can quickly retrieve the top/bottom records. The performance would be much better than `top()` function which is based on the query phase aggregation procedure.
+
+> Caveat: `TopNAggregation` is an approximate realization, to use it well you need have a good understanding with the algorithm as well as the data distribution.
+
+```yaml
+---
+metadata:
+ name: endpoint_cpm_minute_top_bottom
+ group: sw_metric
+source_measure:
+ name: endpoint_cpm_minute
+ group: sw_metric
+field_name: value
+field_value_sort: SORT_UNSPECIFIED
+group_by_tag_names:
+- entity_id
+counters_number: 10000
+lru_size: 10
+```
+
+`endpoint_cpm_minute_top_bottom` is watching the data ingesting of `endpoint_cpm_minute` to generate top 1000 and bottom 1000 entity cardinalities respectively. If you want to only calculate Top 1000 or Bottom 1000, the `field_value_sort` could be `DESC` or `ASC`.
Review Comment:
```suggestion
`endpoint_cpm_minute_top_bottom` is watching the data ingesting of the source measure `endpoint_cpm_minute` to generate both top 1000 and bottom 1000 entity cardinalities. If only Top 1000 or Bottom 1000 is needed, the `field_value_sort` could be `DESC` or `ASC` respectively.
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [skywalking-banyandb] wu-sheng commented on a diff in pull request #198: Add data-model.md to explian objectes in API
Posted by GitBox <gi...@apache.org>.
wu-sheng commented on code in PR #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198#discussion_r1017868651
##########
docs/concept/data-model.md:
##########
@@ -0,0 +1,265 @@
+# Data Model
+
+This chapter introduces BanyanDB's data models and covers the following:
+
+* the high-level data organization
+* data model
+* data retrieval
+
+You can also find [examples](../crud/) of how to interact with BanyanDB using [bydbctl](../clients.md#command-line), how to create and drop groups, or how to create, read, update and drop streams/measures.
+
+## Structure of BanyanDB
+
+The hierarchy that data is organized into **streams**, **measures** and **properties** in groups.
+
+
Review Comment:
This is how we refer static files hosted on the website.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [skywalking-banyandb] wu-sheng merged pull request #198: Add data-model.md to explian objectes in API
Posted by GitBox <gi...@apache.org>.
wu-sheng merged PR #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [skywalking-banyandb] codecov-commenter commented on pull request #198: Add data-model.md to explian objectes in API
Posted by GitBox <gi...@apache.org>.
codecov-commenter commented on PR #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198#issuecomment-1296065643
# [Codecov](https://codecov.io/gh/apache/skywalking-banyandb/pull/198?src=pr&el=h1&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) Report
> Merging [#198](https://codecov.io/gh/apache/skywalking-banyandb/pull/198?src=pr&el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (e233e8c) into [main](https://codecov.io/gh/apache/skywalking-banyandb/commit/e6b01fc695233189b8320f15920f9f4240d9b17a?el=desc&utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation) (e6b01fc) will **not change** coverage.
> The diff coverage is `n/a`.
> :exclamation: Current head e233e8c differs from pull request most recent head 2d9e0bf. Consider uploading reports for the commit 2d9e0bf to get more accurate results
```diff
@@ Coverage Diff @@
## main #198 +/- ##
=======================================
Coverage 44.57% 44.57%
=======================================
Files 84 84
Lines 8382 8382
=======================================
Hits 3736 3736
Misses 4325 4325
Partials 321 321
```
:mega: We’re building smart automated test selection to slash your CI/CD build times. [Learn more](https://about.codecov.io/iterative-testing/?utm_medium=referral&utm_source=github&utm_content=comment&utm_campaign=pr+comments&utm_term=The+Apache+Software+Foundation)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [skywalking-banyandb] lujiajing1126 commented on pull request #198: Add data-model.md to explian objectes in API
Posted by GitBox <gi...@apache.org>.
lujiajing1126 commented on PR #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198#issuecomment-1304551631
<img width="584" alt="image" src="https://user-images.githubusercontent.com/2568208/200123480-fcc7965a-7fc6-40fa-9b81-c551854519b1.png">
`Sream` should be `Stream`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [skywalking-banyandb] hanahmily commented on a diff in pull request #198: Add data-model.md to explian objectes in API
Posted by GitBox <gi...@apache.org>.
hanahmily commented on code in PR #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198#discussion_r1008780867
##########
docs/concept/data-model.md:
##########
@@ -0,0 +1,265 @@
+# Data Model
+
+This chapter introduces BanyanDB's data models and covers the following:
+
+* the high-level data organization
+* data model
+* data retrieval
+
+You can also find [examples](../crud/) of how to interact with BanyanDB using [bydbctl](../clients.md#command-line), how to create and drop groups, or how to create, read, update and drop streams/measures.
+
+## Structure of BanyanDB
+
+The hierarchy that data is organized into **streams**, **measures** and **properties** in groups.
+
+
+
+### Measures
+
+BanyanDB lets you define a measure as follows:
+
+```yaml
+metadata:
+ name: service_cpm_minute
+ group: sw_metric
+tag_families:
+- name: default
+ tags:
+ - name: id
+ type: TAG_TYPE_ID
+ - name: entity_id
+ type: TAG_TYPE_STRING
+fields:
+- name: total
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+- name: value
+ field_type: FIELD_TYPE_INT
+ encoding_method: ENCODING_METHOD_GORILLA
+ compression_method: COMPRESSION_METHOD_ZSTD
+entity:
+ tag_names:
+ - entity_id
+interval: 1m
+```
+
+`Measure` consists of a sequence of data points. Each data point contains tags and fields.
+
+`Tags` are key-value pairs. The database engine can index tag values by referring to the index rules and rule bindings, confining the query to filtering data points based on tags bound to an index rule.
+
+`Tags` are grouped into unique `tag_families` which are the logical and physical grouping of tags.
+
+`Measure` supports the following tag types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **STRING_ARRAY** : A group of strings
+* **INT_ARRAY** : A group of integers
+* **DATA_BINARY** : Raw binary
+* **ID** : Identity of a data point in a measure. If several data points come with an identical ID typed tag, the last write wins according to the `timestamp`.
+
+A group of selected tags composite an `entity` that points out a specific time series the data point belongs to. The database engine has capacities to encode and compress values in the same time series. Users should select appropriate tag combinations to optimize the data size. Another role of `entity` is the sharding key of data points, determining how to fragment data between shards.
+
+`Fields` are also key-value pairs like tags. But the value of each field is the actual value of a single data point. The database engine would encode and compress the field's values in the same time series. The query operation is forbidden to filter data points based on a field's value. You could apply aggregation
+functions to them.
+
+`Measure` supports the following fields types:
+
+* **STRING** : Text
+* **INT** : 64 bits long integer
+* **DATA_BINARY** : Raw binary
+
+`Measure` supports the following encoding methods:
+
+* **GORILLA** : GORILLA encoding is lossless. It is more suitable for a numerical sequence with similar values and is not recommended for sequence data with large fluctuations.
+
+`Measure` supports the types of the following fields:
+
+* **ZSTD** : Zstandard is a real-time compression algorithm, that provides high compression ratios. It offers a very wide range of compression/speed trade-offs, while being backed by a very fast decoder. For BanyanDB focus on speed.
+
+Another option named `interval` plays a critical role in encoding. It indicates the time range between two adjacent data points in a time series and implies that all data points belonging to the same time series are distributed based on a fixed interval. A better practice for the naming measure is to append the interval literal to the tail, for example, `service_cpm_minute`. It's a parameter of `GORILLA` encoding method.
+
+[Measure Registration Operations](../api-reference.md#measureregistryservice)
+
+#### TopNAggregation
Review Comment:
@lujiajing1126 Would you please check this section?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [skywalking-banyandb] wu-sheng commented on pull request #198: Add data-model.md to explian objectes in API
Posted by GitBox <gi...@apache.org>.
wu-sheng commented on PR #198:
URL: https://github.com/apache/skywalking-banyandb/pull/198#issuecomment-1296067012
The images are better hosted in here https://github.com/apache/skywalking-website/tree/master/static
Once they are merged, you could use a static link for it.
Notice, the folder should be versionalized in case some are changed from version to version.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscribe@skywalking.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org