You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@shardingsphere.apache.org by du...@apache.org on 2022/07/28 10:41:52 UTC
[shardingsphere] branch master updated: Modify according to new module (#19651)
This is an automated email from the ASF dual-hosted git repository.
duanzhengqiang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 24bbf9b75ea Modify according to new module (#19651)
24bbf9b75ea is described below
commit 24bbf9b75ea895b9db86a650fde4f07519456e30
Author: Mike0601 <40...@users.noreply.github.com>
AuthorDate: Thu Jul 28 18:41:46 2022 +0800
Modify according to new module (#19651)
* Refactor document
Remove concepts document
* refactor
* update feature sharding
* update according new module
* update according to new module
* update according to new module
* update according to new module
* modify according to new module
* update according new module
* update
* update
* update according new module
* update according to new module
* update
* update
* update according to new module
---
.../content/reference/sharding/_index.cn.md | 5 +-
.../content/reference/sharding/_index.en.md | 23 ++--
.../content/reference/sharding/execute.en.md | 74 +++++++-----
.../content/reference/sharding/merge.en.md | 74 ++++++------
.../content/reference/sharding/parse.en.md | 44 +++----
.../content/reference/sharding/rewrite.en.md | 130 ++++++++++++---------
.../content/reference/sharding/route.en.md | 74 +++++++-----
.../img/sharding/sharding_architecture_cn_v2.png | Bin 184565 -> 596429 bytes
.../img/sharding/sharding_architecture_en_v2.png | Bin 183848 -> 596429 bytes
9 files changed, 241 insertions(+), 183 deletions(-)
diff --git a/docs/document/content/reference/sharding/_index.cn.md b/docs/document/content/reference/sharding/_index.cn.md
index dc677475b23..82653513024 100644
--- a/docs/document/content/reference/sharding/_index.cn.md
+++ b/docs/document/content/reference/sharding/_index.cn.md
@@ -5,9 +5,8 @@ weight = 3
chapter = true
+++
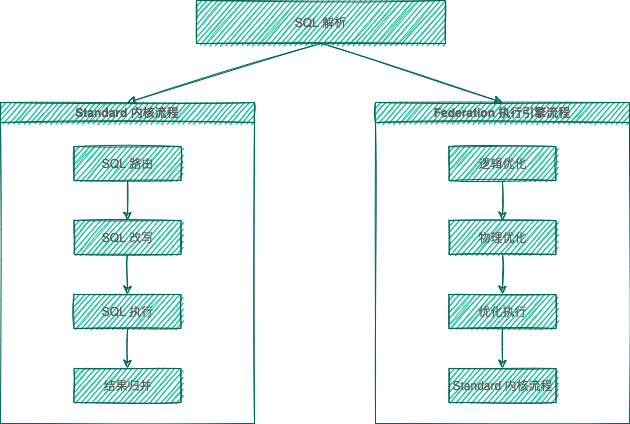
-ShardingSphere 的 3 个产品的数据分片主要流程是完全一致的,按照是否进行查询优化,可以分为 Standard 内核流程和 Federation 执行引擎流程。
-Standard 内核流程由 `SQL 解析 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并` 组成,主要用于处理标准分片场景下的 SQL 执行。
-Federation 执行引擎流程由 `SQL 解析 => 逻辑优化 => 物理优化 => 优化执行 => Standard 内核流程` 组成,Federation 执行引擎内部进行逻辑优化和物理优化,在优化执行阶段依赖 Standard 内核流程,对优化后的逻辑 SQL 进行路由、改写、执行和归并。
+ShardingSphere 数据分片的原理如下图所示,按照是否需要进行查询优化,可以分为 Simple Push Down 下推流程和 SQL Federation 执行引擎流程。 Simple Push Down 下推流程由 `SQL 解析 => SQL 绑定 => SQL 路由 => SQL 改写 => SQL 执行 => 结果归并` 组成,主要用于处理标准分片场景下的 SQL 执行。
+SQL Federation 执行引擎流程由 `SQL 解析 => SQL 绑定 => 逻辑优化 => 物理优化 => 数据拉取 => 算子执行` 组成,SQL Federation 执行引擎内部进行逻辑优化和物理优化,在优化执行阶段依赖 Standard 内核流程,对优化后的逻辑 SQL 进行路由、改写、执行和归并。
diff --git a/docs/document/content/reference/sharding/_index.en.md b/docs/document/content/reference/sharding/_index.en.md
index 0091dc686e2..50db4762b16 100644
--- a/docs/document/content/reference/sharding/_index.en.md
+++ b/docs/document/content/reference/sharding/_index.en.md
@@ -5,32 +5,35 @@ weight = 3
chapter = true
+++
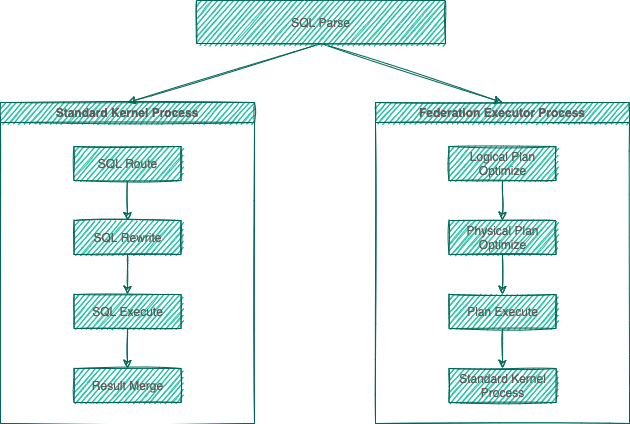
-The major sharding processes of all the three ShardingSphere products are identical. According to whether query optimization is performed, they can be divided into standard kernel process and federation executor engine process.
-The standard kernel process consists of `SQL Parse => SQL Route => SQL Rewrite => SQL Execute => Result Merge`, which is used to process SQL execution in standard sharding scenarios.
-The federation executor engine process consists of `SQL Parse => Logical Plan Optimize => Physical Plan Optimize => Plan Execute => Standard Kernel Process`. The federation executor engine perform logical plan optimization and physical plan optimization. In the optimization execution phase, it relies on the standard kernel process to route, rewrite, execute, and merge the optimized logical SQL.
+The figure below shows how sharding works. According to whether query and optimization are needed, it can be divided into the Simple Push Down process and SQL Federation execution engine process.
+Simple Push Down process consists of `SQL parser => SQL binder => SQL router => SQL rewriter => SQL executor => result merger`, mainly used to deal with SQL execution in standard sharding scenarios.
+SQL Federation execution engine consists of `SQL parser => SQL binder => logical optimization => physical optimization => data fetcher => operator calculation`.
+This process performs logical optimization and physical optimization internally, during which the standard kernel procedure is adopted to route, rewrite, execute and merge the optimized logical SQL.
-## SQL Parsing
+## SQL Parser
-It is divided into lexical parsing and syntactic parsing. The lexical parser will split SQL into inseparable words, and then the syntactic parser will analyze SQL and extract the parsing context, which can include tables, options, ordering items, grouping items, aggregation functions, pagination information, query conditions and placeholders that may be revised.
+It is divided into the lexical parser and syntactic parser. SQL is first split into indivisible words through a lexical parser.
+
+The syntactic parser is then used to analyze SQL and ultimately extract the parsing context, which can include tables, options, ordering items, grouping items, aggregation functions, pagination information, query conditions, and placeholders that may be modified.
## SQL Route
-It is the sharding strategy that matches users’ configurations according to the parsing context and the route path can be generated. It supports sharding route and broadcast route currently.
+The sharding strategy configured by the user is matched according to the parsing context and the routing path is generated. Currently, sharding router and broadcast router are supported.
## SQL Rewrite
-It rewrites SQL as statement that can be rightly executed in the real database, and can be divided into correctness rewrite and optimization rewrite.
+Rewrite SQL into statements that can be executed correctly in a real database. SQL rewriting is divided into rewriting for correctness and rewriting for optimization.
## SQL Execution
- Through multi-thread executor, it executes asynchronously.
+ It executes asynchronously through a multithreaded executor.
## Result Merger
-It merges multiple execution result sets to output through unified JDBC interface. Result merger includes methods as stream merger, memory merger and addition merger using decorator merger.
+It merges multiple execution result sets to achieve output through the unified JDBC interface. The result merger includes the stream merger, memory merger and appended merger using decorator mode.
## Query Optimization
-Supported by federation executor engine(under development), optimization is performed on complex query such as join query and subquery. It also supports distributed query across multiple database instances. It uses relational algebra internally to optimize query plan, and then get query result through the best query plan.
+Supported by the experimental Federation Execution Engine, it optimizes complex queries such as associated queries and sub-queries and supports distributed queries across multiple database instances. It internally optimizes query plans using relational algebra to query results through optimal plans.
diff --git a/docs/document/content/reference/sharding/execute.en.md b/docs/document/content/reference/sharding/execute.en.md
index a7e50905a5b..3ed70321cbc 100644
--- a/docs/document/content/reference/sharding/execute.en.md
+++ b/docs/document/content/reference/sharding/execute.en.md
@@ -3,83 +3,97 @@ title = "Execute Engine"
weight = 4
+++
-ShardingSphere adopts a set of automatic execution engine, responsible for sending the true SQL, which has been routed and rewritten, to execute in the underlying data source safely and effectively. It does not simply send the SQL through JDBC to directly execute in the underlying data source, or put execution requests directly to the thread pool to concurrently execute, but focuses more on the creation of a balanced data source connection, the consumption generated by the memory usage, [...]
+ShardingSphere uses an automated execution engine to safely and efficiently send the real SQL, which has been routed and rewritten, to the underlying data source for execution.
+
+It does not simply send SQL directly to the data source for execution via JDBC, nor are execution requests placed directly into a thread pool for concurrent execution.
+
+It focuses more on the creation of a balanced data source connection, the consumption generated by the memory usage, and the maximum utilization of the concurrency. The objective of the execution engine is to automatically balance resource control with execution efficiency.
## Connection Mode
-From the perspective of resource control, the connection number of the business side’s visit of the database should be limited. It can effectively prevent some certain business from occupying excessive resource, exhausting database connection resources and influencing the normal use of other businesses.
-Especially when one database contains many tables, a logic SQL that does not contain any sharding key will produce a large amount of physical SQLs that fall into different tables in one database. If each physical SQL takes an independent connection, a query will undoubtedly take up excessive resources.
+From the perspective of resource control, the connection number a business can make to the database should be limited. It can effectively prevent certain business operations from occupying excessive resources, exhausting database connection resources, and influencing the normal access of other businesses.
+
+Especially when one database instance contains many sub-tables, a logical SQL that does not contain any shard key will produce a large number of real SQLs that fall into different tables in one database. If each real SQL takes an independent connection, a query will undoubtedly take up excessive resources.
+
+From the perspective of execution efficiency, maintaining an independent database connection for each shard query can make more effective use of multi-thread to improve execution efficiency.
-From the perspective of execution efficiency, holding an independent database connection for each sharding query can make effective use of multi-thread to improve execution efficiency. Opening an independent thread for each database connection can parallelize IO produced consumption. Holding an independent database connection for each sharding query can also avoid loading the query result to the memory too early. It is enough for independent database connections to maintain result set qu [...]
+Creating a separate thread for each database connection allows I/O consumption to be processed in parallel. Maintaining a separate database connection for each shard also prevents premature loading of query result data into memory.
-Merging result set by moving down its cursor is called stream merger. It does not require to load all the query results to the memory. Thus, it is able to save memory resource effectively and reduce trash recycle frequency. When it is not able to make sure each sharding query holds an independent database connection, it requires to load all the current query results to the memory before reusing that database connection to acquire the query result from the next sharding table. Therefore, [...]
+It is enough for independent database connections to maintain result set quotation and cursor position, and move the cursor when acquiring corresponding data.
-The control and protection of database connection resources is one thing, adopting better merging model to save the memory resources of middleware is another thing. How to deal with the relationship between them is a problem that ShardingSphere execution engine should solve. To be accurate, if a sharding SQL needs to operate 200 tables under some database case, should we choose to create 200 parallel connection executions or a serial connection execution? Or to say, how to choose between [...]
+Merging the result set by moving down its cursor is called the stream merger. It does not need to load all the query results into the memory, which can effectively save memory resources effectively and reduce the frequency of garbage collection.
-Aiming at the above situation, ShardingSphere has provided a solution. It has put forward a Connection Mode concept divided into two types, `MEMORY_STRICTLY` mode and `CONNECTION_STRICTLY` mode.
+If each shard query cannot be guaranteed to have an independent database connection, the current query result set needs to be loaded into memory before reusing the database connection to obtain the query result set of the next shard table. Therefore, though the stream merger can be used, it will also degenerate into the memory merger in this scenario.
+
+On the one hand, we need to control and protect database connection resources; on the other hand, it is important to save middleware memory resources by adopting a better merging mode. How to deal with the relationship between the two is a problem that the ShardingSphere execution engine needs to solve. Specifically, if an SQL is sharded through the ShardingSphere, it needs to operate on 200 tables under a database instance. So, should we choose to create 200 connections in parallel, or [...]
+For the above scenario, ShardingSphere provides a solution. It introduces the concept of Connection Mode, which is divided into MEMORY_STRICTLY and CONNECTION_STRICTLY.
### MEMORY_STRICTLY Mode
-The prerequisite to use this mode is that ShardingSphere does not restrict the connection number of one operation. If the actual executed SQL needs to operate 200 tables in some database instance, it will create a new database connection for each table and deal with them concurrently through multi-thread to maximize the execution efficiency. When the SQL is up to standard, it will choose stream merger in priority to avoid memory overflow or frequent garbage recycle.
+The prerequisite to using this mode is that ShardingSphere does not restrict the connection number of one operation. If the actual executed SQL needs to operate 200 tables in some database instance, it will create a new database connection for each table and deal with them concurrently through multi-thread to maximize the execution efficiency. When SQL meets the conditions, stream merger is preferred to avoid memory overflow or frequent garbage recycling.
### CONNECTION_STRICTLY Mode
-The prerequisite to use this mode is that ShardingSphere strictly restricts the connection consumption number of one operation. If the SQL to be executed needs to operate 200 tables in database instance, it will create one database connection and operate them serially. If shards exist in different databases, it will still be multi-thread operations for different databases, but with only one database connection being created for each operation in each database. It can prevent the problem [...]
+The prerequisite to using this mode is that ShardingSphere strictly restricts the connection consumption number of one operation. If the SQL to be executed needs to operate 200 tables in a database instance, it will create one database connection and operate them serially. If shards exist in different databases, it will still adopt multi-thread operations for different databases, but with only one database connection being created for each operation in each database. It prevents the prob [...]
-The MEMORY_STRICTLY mode is applicable to OLAP operation and can increase the system capacity by removing database connection restrictions. It is also applicable to OLTP operation, which usually has sharding keys and can be routed to a single shard. So it is a wise choice to control database connection strictly to make sure resources of online system databases can be used by more applications.
+The MEMORY_STRICTLY mode applies to OLAP operation and can increase the system throughput by removing database connection restrictions. It is also applicable to OLTP operation, which usually has shard keys and can be routed to a single shard. So it is a wise choice to control database connections strictly to make sure that database resources in an online system can be used by more applications.
## Automatic Execution Engine
-ShardingSphere uses which mode at first is up to users’ setting and they can choose to use MEMORY_STRICTLY mode or CONNECTION_STRICTLY mode according to their actual business scenarios.
+ShardingSphere initially leaves the decision of which mode to use up to the users and they can choose to use MEMORY_STRICTLY mode or CONNECTION_STRICTLY mode according to their actual business scenarios.
-The solution gives users the right to choose, requiring them to know the advantages and disadvantages of both modes and make decision according to the actual business situations. No doubt, it is not the best solution due to increasing users’ study cost and use cost.
+This solution gives users the right to choose, who must understand the pros and cons of the two modes and make a choice based on the requirements of the business scenarios. No doubt, it is not the best solution as it increases users' learning and use costs.
-This kind of dichotomy solution lacks flexible coping ability to switch between two modes with static initialization. In practical situations, route results of each time may differ with different SQL and placeholder indexes. It means some operations may need to use memory merger, while others are better to use stream merger. Connection modes should not be set by users before initializing ShardingSphere, but should be decided dynamically by the situation of SQL and placeholder indexes.
+This dichotomy solution, which leaves the switching of the two modes to static initialization, lacks flexibility. In practical scenarios, the routing result varies with SQL and placeholder indexes. This means that some operations may need to use memory merger, while others may prefer stream merger. Connection modes should not be set by the user before ShardingSphere is started, but should be determined dynamically based on the SQL and placeholder indexes scenarios.
-To reduce users’ use cost and solve the dynamic connection mode problem, ShardingSphere has extracted the thought of automatic execution engine in order to eliminate the connection mode concept inside.
-Users do not need to know what are so called MEMORY_STRICTLY mode and CONNECTION_STRICTLY mode, but let the execution engine to choose the best solution according to current situations.
+In order to reduce the usage cost for users and achieve a dynamic connection mode, ShardingSphere has extracted the concept of the automatic execution engine to eliminate the connection mode concept internally. The user does not need to know what the MEMORY_STRICTLY mode and CONNECTION_STRICTLY mode are, but the execution engine automatically selects the best execution scheme according to the current scenario.
-Automatic execution engine has narrowed the selection scale of connection mode to each SQL operation. Aiming at each SQL request, automatic execution engine will do real-time calculations and evaluations according to its route result and execute the appropriate connection mode automatically to strike the most optimized balance between resource control and efficiency. For automatic execution engine, users only need to configure `maxConnectionSizePerQuery`, which represents the maximum con [...]
+The automatic execution engine chooses the connection mode based on each SQL operation. For each SQL request, the automatic execution engine will do real-time calculations and evaluations according to its route result and execute the appropriate connection mode automatically to strike the optimal balance between resource control and efficiency.
+For the automatic execution engine, users only need to configure `maxConnectionSizePerQuery`, which represents the maximum connection number allowed by each database for one query.
-The execution engine can be divided into two phases: `preparation` and `execution`.
+The execution engine is divided into two phases: preparation and execution.
### Preparation Phrase
As indicated by its name, this phrase is used to prepare the data to be executed. It can be divided into two steps: result set grouping and unit creation.
-Result set grouping is the key to realize the internal connection model concept. According to the configuration option of `maxConnectionSizePerQuery`, execution engine will choose an appropriate connection mode combined with current route result.
+Result set grouping is the key to realizing the internal connection model concept. According to the configuration items of `maxConnectionSizePerQuery`, the execution engine will choose an appropriate connection mode based on the current route result.
Detailed steps are as follow:
1. Group SQL route results according to data source names.
-2. Through the equation in the following picture, users can acquire the SQL route result group to be executed by each database case within the `maxConnectionSizePerQuery` permission range and calculate the most optimized connection mode of this request.
+1. As we can see in the following formula, users can acquire the SQL route result set to be executed by each database instance within the `maxConnectionSizePerQuery` permission range and calculate the optimal connection mode of this request.

-Within the range that maxConnectionSizePerQuery permits, when the request number that one connection needs to execute is more than 1, meaning current database connection cannot hold the corresponding data result set, it must uses memory merger. On the contrary, when it equals to 1, meaning current database connection can hold the according data result set, it can use stream merger.
+Within the scope of the maxConnectionSizePerQuery allowed, when the request number that one connection needs to execute is more than 1, the current database connection cannot hold the corresponding data result set, so it must use memory merger. On the contrary, when the number equals 1, the current database connection can hold the corresponding data result set, and it can use stream merger.
-Each choice of connection mode aims at each physical database; that is to say, if it is routed to more than one databases, the connection mode of each database may mix with each other and not be the same in one query.
+Each connection mode selection is specific to each physical database. That is, if you route to more than one database in the same query, the connection mode of each database may not be the same, and they may be mixed.
+Users can use the route grouping result acquired from the last step to create the execution unit. When the data source uses technologies, such as the database connection pool, to control database connection numbers, there is a chance that a deadlock will occur if concurrency is not handled properly while retrieving database connections. As multiple requests wait for each other to release database connection resources, starvation occurs, causing the crossing deadlock.
-Users can use the route group result acquired from the last step to create the execution unit. When the data source uses technologies, such as database connection pool, to control database connection number, there is some chance for deadlock, if it has not dealt with concurrency properly. As multiple requests waiting for each other to release database connection resources, it will generate hunger wait and cause the crossing deadlock problem.
+For example, suppose that a query requires obtaining two database connections at a data source and routing queries to two sub-tables of the same database. It is possible that query A has obtained one database connection from this data source and is waiting to obtain another database connection.
-For example, suppose one query needs to acquire two database connections from a data source and apply them in two table sharding queries routed to one database. It is possible that Query A has already acquired a database connection from that data source and waits to acquire another connection; but in the same time, Query B has also finished it and waits. If the maximum connection number that the connection pool permits is 2, those two query requests will wait forever. The following pictu [...]
+Query B has also acquired a database connection at the data source and is also waiting for another database connection to be acquired. If the maximum number of connections allowed in the database connection pool is 2, then the two query requests will wait forever. The following diagram depicts a deadlock situation.
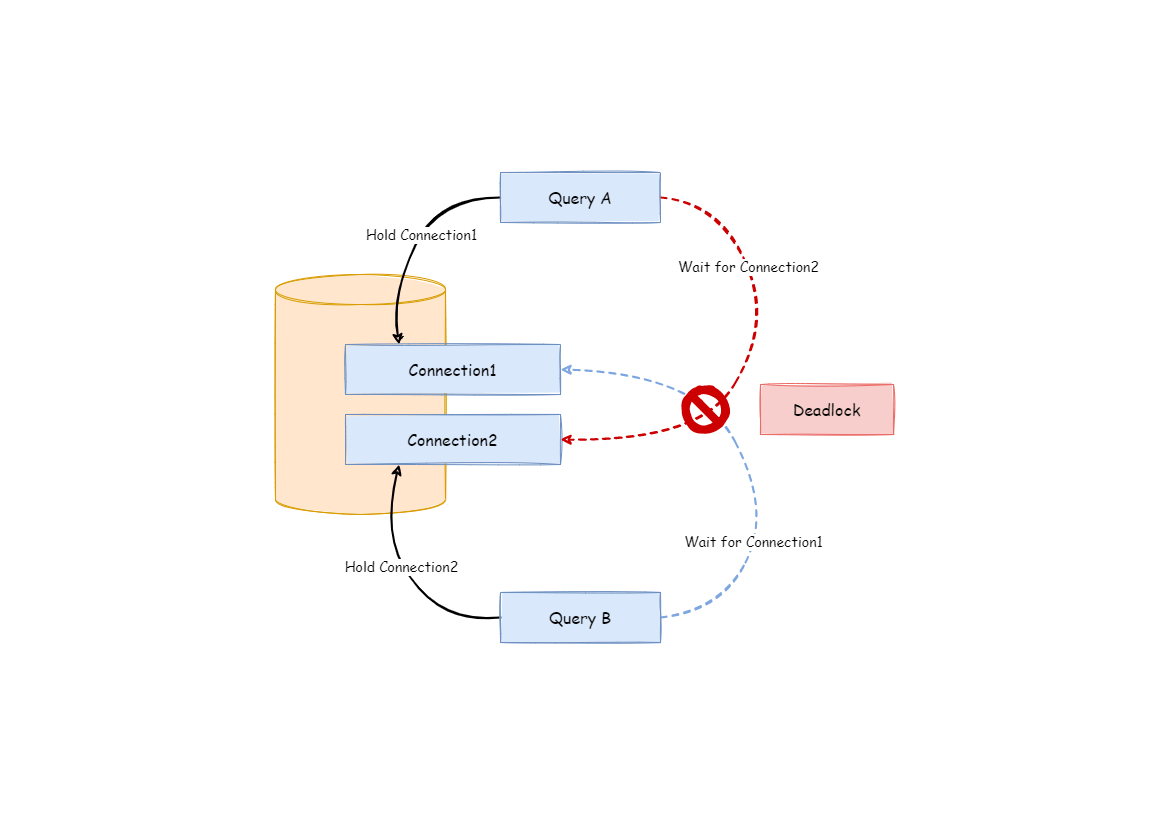
-To avoid the deadlock, ShardingSphere will go through synchronous processing when acquiring database connection. When creating execution units, it acquires all the database connections that this SQL requires for once with atomic method and reduces the possibility of acquiring only part of the resources. Due to the high operation frequency, locking the connection each time when acquiring it can decrease ShardingSphere's concurrency. Therefore, it has improved two aspects here:
+ShardingSphere synchronizes database connections to avoid deadlocks. When it creates the execution unit, it atomically obtains all the database connections required by the SQL request at one time, eliminating the possibility of obtaining partial resources in each query request.
+
+Because the operation on the database is very frequent, locking a database connection each time when acquiring it will reduce the concurrency of ShardingSphere. Therefore, ShardingSphere has improved two aspects here:
-1. Avoid the setting that locking only takes one database connection each time. Because under this kind of circumstance, two requests waiting for each other will not happen, so there is no need for locking.
-Most OLTP operations use sharding keys to route to the only data node, which will make the system in a totally unlocked state, thereby improve the concurrency efficiency further. In addition to routing to a single shard, readwrite-splitting also belongs to this category.
+1. Locking can be avoided and only one database connection needs to be obtained each time. Because under this circumstance, two requests waiting for each other will not happen, so there is no need for locking. Most OLTP operations use shard keys to route to the unique data node, which makes the system completely unlocked and further improves the concurrency efficiency. In addition to routing to a single shard, read/write-splitting also belongs to this category.
-2. Only aim at MEMORY_STRICTLY mode to lock resources. When using CONNECTION_STRICTLY mode, all the query result sets will release database connection resources after loading them to the memory, so deadlock wait will not appear.
+2. Locking resources only happens in MEMORY_STRICTLY mode. When using CONNECTION_STRICTLY mode, all the query result sets will release database connection resources after loading them to the memory, so deadlock wait will not appear.
### Execution Phrase
-Applied in actually SQL execution, this phrase can be divided into two steps: group execution and merger result generation.
+This stage is used to actually execute SQL and is divided into two steps: group execution and merger result generation.
+
+Group execution can distribute execution unit groups generated in the preparation phase to the underlying concurrency engine and send events for each key step during the execution process, such as starting, successful and failed execution events. The execution engine only focuses on sending events rather than subscribers to the event. Other ShardingSphere modules, such as distributed transactions, call linked tracing and so on, will subscribe to the events of interest and process them ac [...]
-Group execution can distribute execution unit groups generated in preparation phrase to the underlying concurrency engine and send events according to each key steps during the execution process, such as starting, successful and failed execution events. Execution engine only focuses on message sending rather than subscribers of the event. Other ShardingSphere modules, such as distributed transactions, invoked chain tracing and so on, will subscribe focusing events and do corresponding op [...]
+ShardingSphere generates memory merger result sets or stream merger result sets through the connection mode acquired in the preparation phase. And then it passes the result set to the result merger engine for the next step.
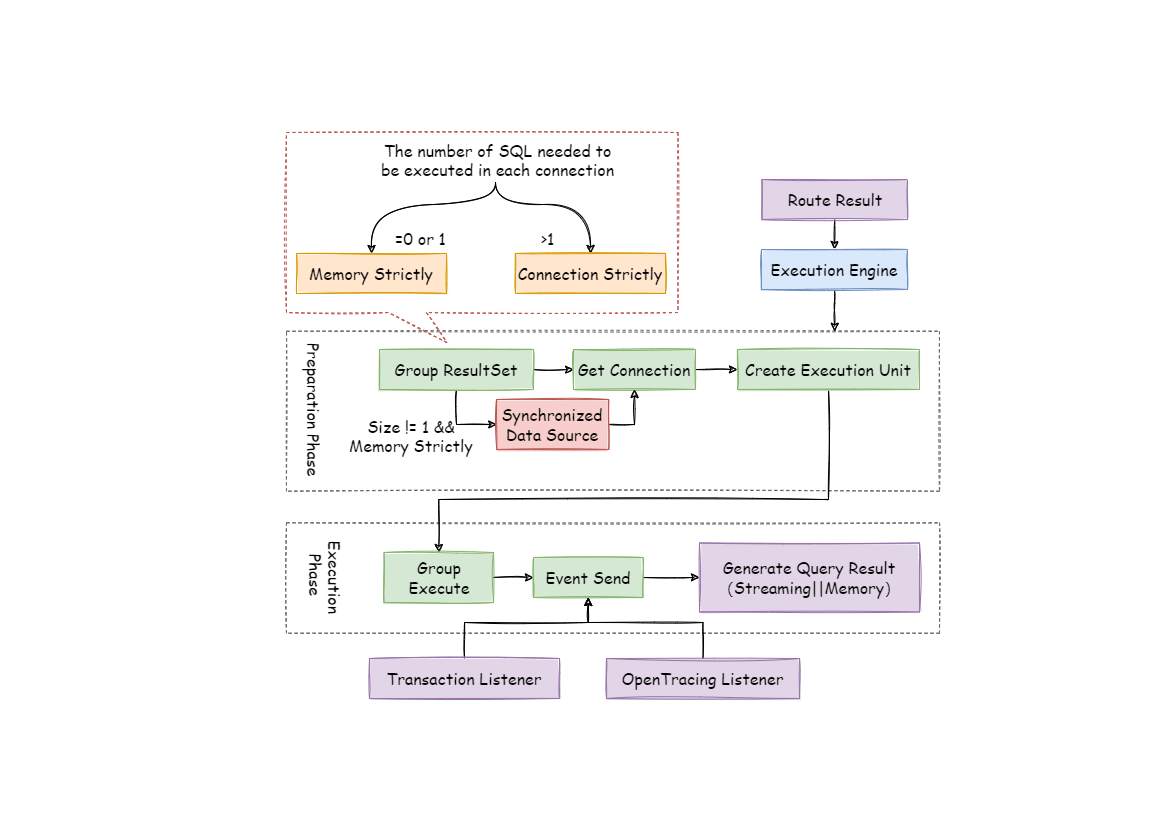
-The overall structure of execution engine is shown as the following picture:
+The overall structure of the execution engine is divided as shown below.
\ No newline at end of file
diff --git a/docs/document/content/reference/sharding/merge.en.md b/docs/document/content/reference/sharding/merge.en.md
index ffaf6aef13e..b2789bc674f 100644
--- a/docs/document/content/reference/sharding/merge.en.md
+++ b/docs/document/content/reference/sharding/merge.en.md
@@ -4,109 +4,107 @@ weight = 5
+++
-Result merger refers to merging multi-data result set acquired from all the data nodes as one result set and returning it to the request end rightly.
+Result merger refers to merging multi-data result sets acquired from all the data nodes as one result set and returning it to the requesting client correctly.
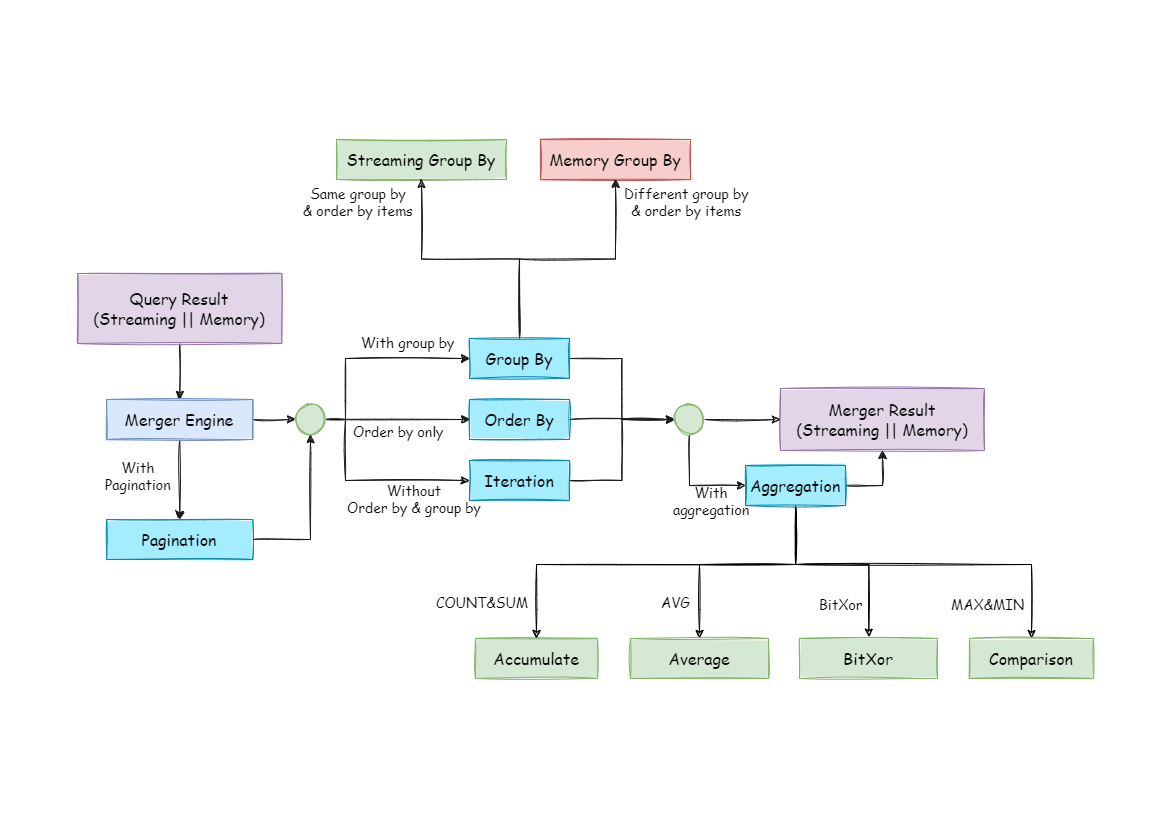
-In function, the result merger supported by ShardingSphere can be divided into five kinds, iteration, order-by, group-by, pagination and aggregation, which are in composition relation rather than clash relation. In structure, it can be divided into stream merger, memory merger and decorator merger, among which, stream merger and memory merger clash with each other; decorator merger can be further processed based on stream merger and memory merger.
+The result merger supported by ShardingSphere can be divided into five functional types: traversal, order-by, group-by, pagination and aggregation, which are combined rather than mutually exclusive. From the perspective of structure, it can be divided into stream merger, memory merger and decorator merger, among which stream merger and memory merger are mutually exclusive, and decorator merger can be further processed based on stream merger and memory merger.
-Since the result set is returned from database line by line instead of being loaded to the memory all at once, the most prior choice of merger method is to follow the database returned result set, for it is able to reduce the memory consumption to a large extend.
+Since the result set is returned from the database one by one instead of being loaded to the memory all at a time, the method of merging the result sets returned from the database can greatly reduce memory consumption and is the preferred method of merging.
-Stream merger means, each time, the data acquired from the result set is able to return the single piece of right data line by line.
+Stream merger means that each time the data is obtained from the result set is able to return the correct single piece of data line by line. It is the best fit with the native method of returning the result set of the database. Traversal, order-by, and stream group-by are all examples of the stream merger.
-It is the most suitable one for the method that the database returns original result set. Iteration, order-by, and stream group-by belong to stream merger.
+Memory merger needs to traverse all the data in the result set and store it in the memory first. After unified grouping, ordering, aggregation and other calculations, the data is packaged into the data result set accessed one by one and returned.
-Memory merger needs to iterate all the data in the result set and store it in the memory first. after unified grouping, ordering, aggregation and other computations, it will pack it into data result set, which is visited line by line, and return that result set.
+Decorator merger merges and reinforces all the result sets function uniformly. Currently, decorator merger has two types: pagination merger and aggregation merger.
-Decorator merger merges and reinforces all the result sets function uniformly. Currently, decorator merger has pagination merger and aggregation merger these two kinds.
+## Traversal Merger
-## Iteration Merger
-
-As the simplest merger method, iteration merger only requires the combination of multiple data result sets into a single-direction chain table. After iterating current data result sets in the chain table, it only needs to move the element of chain table to the next position and iterate the next data result set.
+As the simplest merger method, traversal merger only requires the combination of multiple data result sets into a one-way linked table. After traversing current data result sets in the linked table, it only needs to move the elements of the linked table back one bit and continue traversing the next data result set.
## Order-by Merger
-Because there is `ORDER BY` statement in SQL, each data result has its own order. So it is enough only to order data value that the result set cursor currently points to, which is equal to sequencing multiple already ordered arrays, and therefore, order-by merger is the most suitable ordering algorithm in this situation.
+Because there is an `ORDER BY` statement in SQL, each data result has its own order. So it only needs to sort data value that the result set cursor currently points to, which is equal to sorting multiple ordered arrays. Therefore, order-by merger is the most suitable sorting algorithm in this scenario.
-When merging order inquiries, ShardingSphere will compare current data values in each result set (which is realized by Java Comparable interface) and put them into the priority queue. Each time when acquiring the next piece of data, it only needs to move down the result set in the top end of the line, renter the priority order according to the new cursor and relocate its own position.
+When merging ordered queries, ShardingSphere will compare current data values in each result set (which is realized by the Java Comparable interface) and put them into the priority queue. Each time when acquiring the next piece of data, it only needs to move down the result set cursor at the top of the queue, reenter the priority order according to the new cursor and relocate its own position.
-Here is an instance to explain ShardingSphere's order-by merger. The following picture is an illustration of ordering by the score. Data result sets returned by 3 tables are shown in the example and each one of them has already been ordered according to the score, but there is no order between 3 data result sets. Order the data value that the result set cursor currently points to in these 3 result sets. Then put them into the priority queue. the data value of t_score_0 is the biggest, f [...]
+Here is an instance to explain ShardingSphere’s order-by merger. The following picture is an illustration of ordering by the score. Data result sets returned by 3 tables are shown in the example and each of them has already been ordered according to the score, but there is no order between the 3 data result sets. Order the data value that the result set cursor currently points to in these 3 result sets. Then put them into the priority queue. The first data value of `t_score_0` is the big [...]
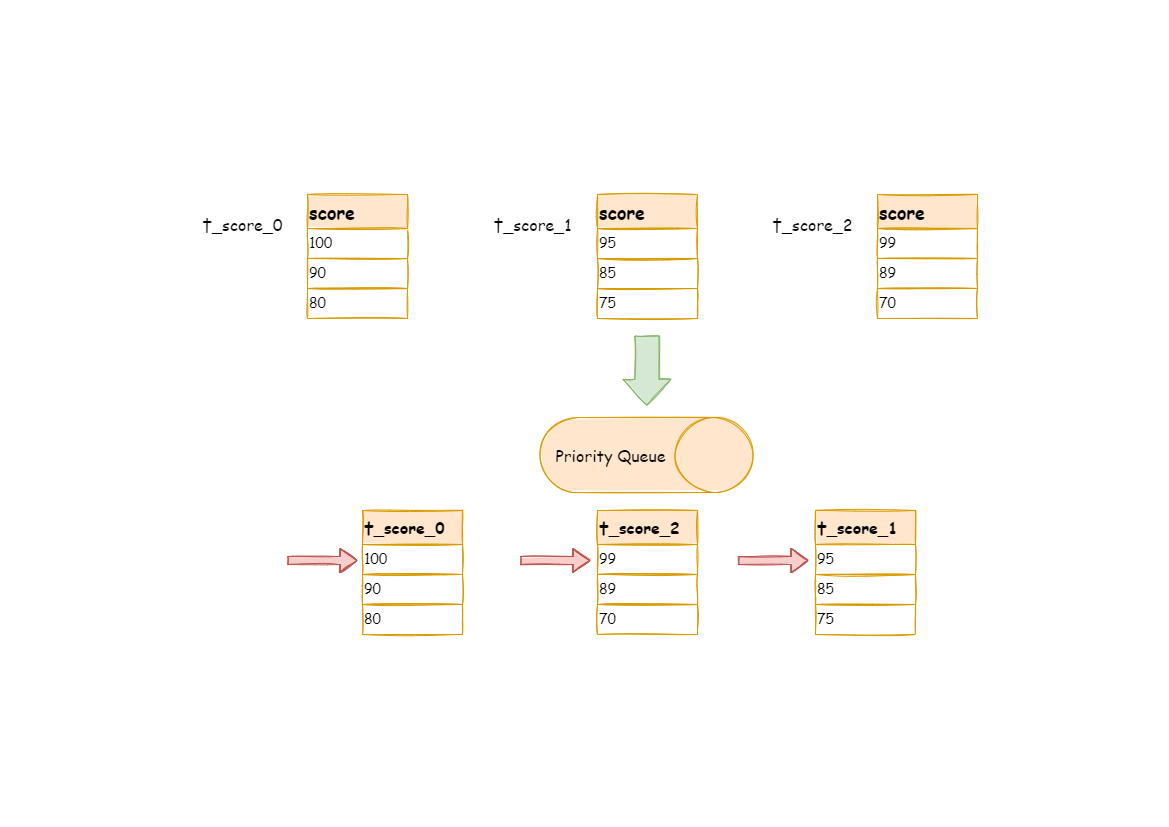
-This diagram illustrates how the order-by merger works when using next invocation. We can see from the diagram that when using next invocation, t_score_0 at the first of the queue will be popped out. After returning the data value currently pointed by the cursor (i.e., 100) to the client end, the cursor will be moved down and t_score_0 will be put back to the queue.
+The following diagram illustrates how the order-by merger works when using next call. We can see from the diagram that when using the `next` call, `t_score_0` at the first of the queue will be popped out. After returning the data value currently pointed by the cursor (i.e., 100) to the requesting client, the cursor will be moved down and `t_score_0` will be put back into the queue.
-While the priority queue will also be ordered according to the t_score_0 data value (90 here) pointed by the cursor of current data result set. According to the current value, t_score_0 is at the last of the queue, and in the second place of the queue formerly, the data result set of t_score_2, automatically moves to the first place of the queue.
+While the priority queue will also be ordered according to the `t_score_0` data value (90 here) pointed by the cursor of the current data result set. According to the current value, `t_score_0` is at the end of the queue, and the data result set of `t_score_2`, originally in the second place of the queue, automatically moves to the first place of the queue.
-In the second next operation, t_score_2 in the first position is popped out of the queue. Its value pointed by the cursor of the data result set is returned to the client end, with its cursor moved down to rejoin the queue, and the following will be in the same way. If there is no data in the result set, it will not rejoin the queue.
+In the second `next` call, `t_score_2` in the first place is popped out. Its value pointed by the cursor of the data result set is returned to the client end, with its cursor moved down to rejoin the queue, and the following will be the same way. If there is no data in the result set, it will not rejoin the queue.
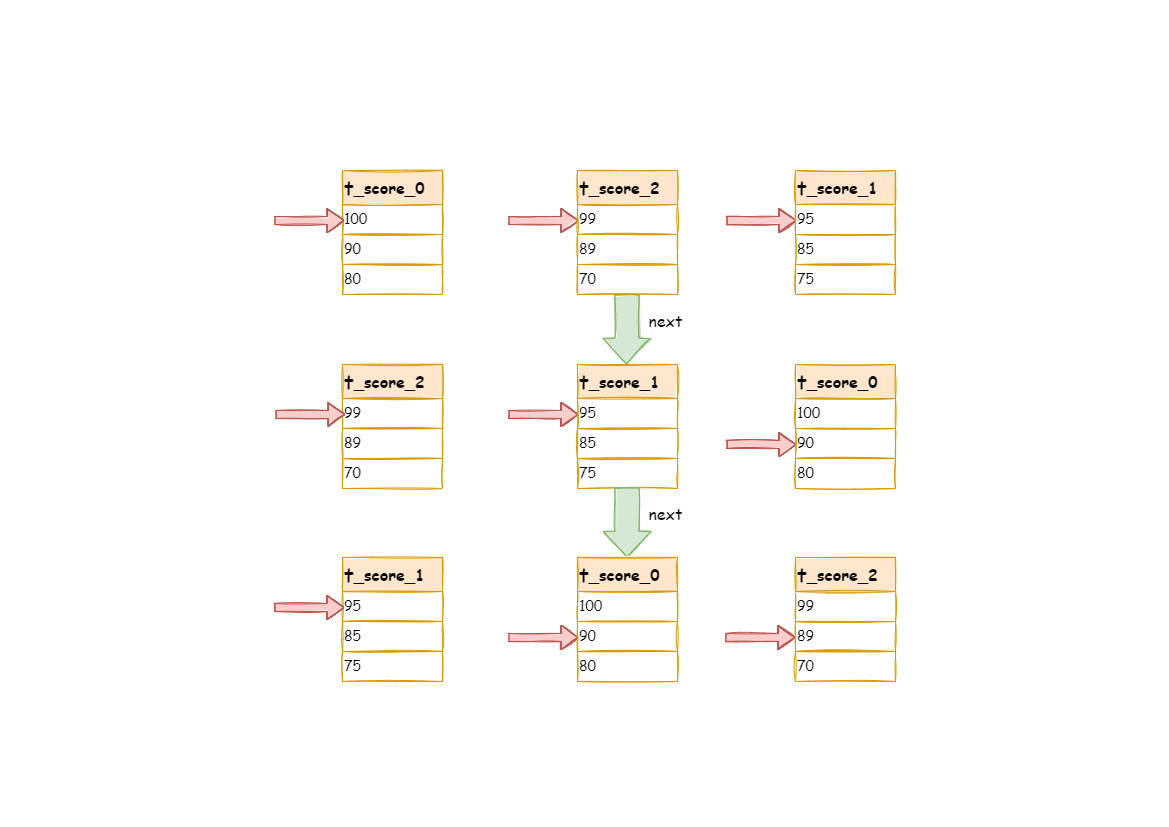
-It can be seen that, under the circumstance that data in each result set is ordered while result sets are disordered, ShardingSphere does not need to upload all the data to the memory to order. In the order-by merger method, each next operation only acquires the right piece of data each time, which saves the memory consumption to a large extent.
+It can be seen that when data in each result set is ordered, but multiple result sets are disordered, ShardingSphere can still order them with no need to upload all the data to the memory. In the stream merger method, each `next` operation only acquires the right piece of data each time, which saves memory consumption to a large extent.
-On the other hand, the order-by merger has maintained the orderliness on horizontal axis and vertical axis of the data result set. Naturally ordered, vertical axis refers to each data result set itself, which is acquired by SQL with `ORDER BY`. Horizontal axis refers to the current value pointed by each data result set, and its order needs to be maintained by the priority queue.Each time when the current cursor moves down, it requires to put the result set in the priority order again, wh [...]
+On the other hand, the order-by merger has maintained the orderliness on the horizontal axis and vertical axis of the data result set. Naturally ordered, the vertical axis refers to each data result set itself, which is acquired by SQL with `ORDER BY`. The horizontal axis refers to the current value pointed by each data result set, and its order needs to be maintained by the priority queue. Each time when the current cursor moves down, it requires putting the result set in the priority o [...]
## Group-by Merger
-With the most complicated situation, group-by merger can be divided into stream group-by merger and memory group-by merger. Stream group-by merger requires SQL field and order item type (ASC or DESC) to be the same with group-by item. Otherwise, its data accuracy can only be maintained by memory merger.
+Group-by merger is the most complex one and can be divided into stream group-by merger and memory group-by merger. Stream group-by merger requires that the SQL's ordering items must be consistent with the field and ordering types (ASC or DESC) of the group-by item; otherwise, data correctness can only be guaranteed by memory merger.
-For instance, if it is sharded by subject, table structure contains examinees' name (to simplify, name repetition is not taken into consideration) and score. The SQL used to acquire each examinee’s total score is as follow:
+For instance, if it is sharded based on subject, the table structure contains the examinees’ name (to simplify, name repetition is not taken into consideration) and score. The following SQL is used to acquire each examinee’s total score:
```sql
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY name;
```
-When order-by item and group-by item are totally consistent, the data obtained is continuous. The data to group are all stored in the data value that data result set cursor currently points to, stream group-by merger can be used, as illustrated by the diagram:
+When order-by item and group-by item are totally consistent, the data obtained is continuous. The data required by group-by is all stored in the data value that the data result set cursor currently points to. Thus, stream group-by merger can be used, as illustrated by the diagram:
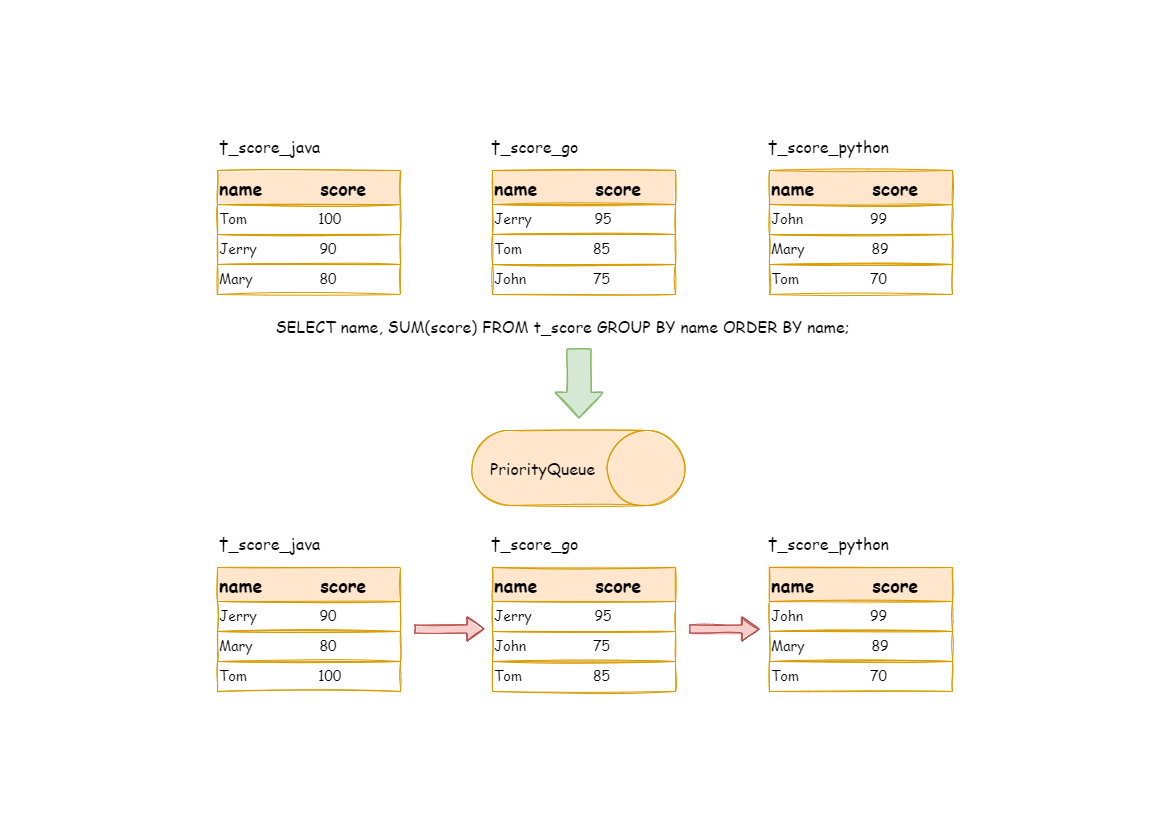
-The merging logic is similar to that of order-by merger. The following picture shows how stream group-by merger works in next invocation.
+The merging logic is similar to that of order-by merger. The following picture shows how the stream group-by merger works in the `next` call.
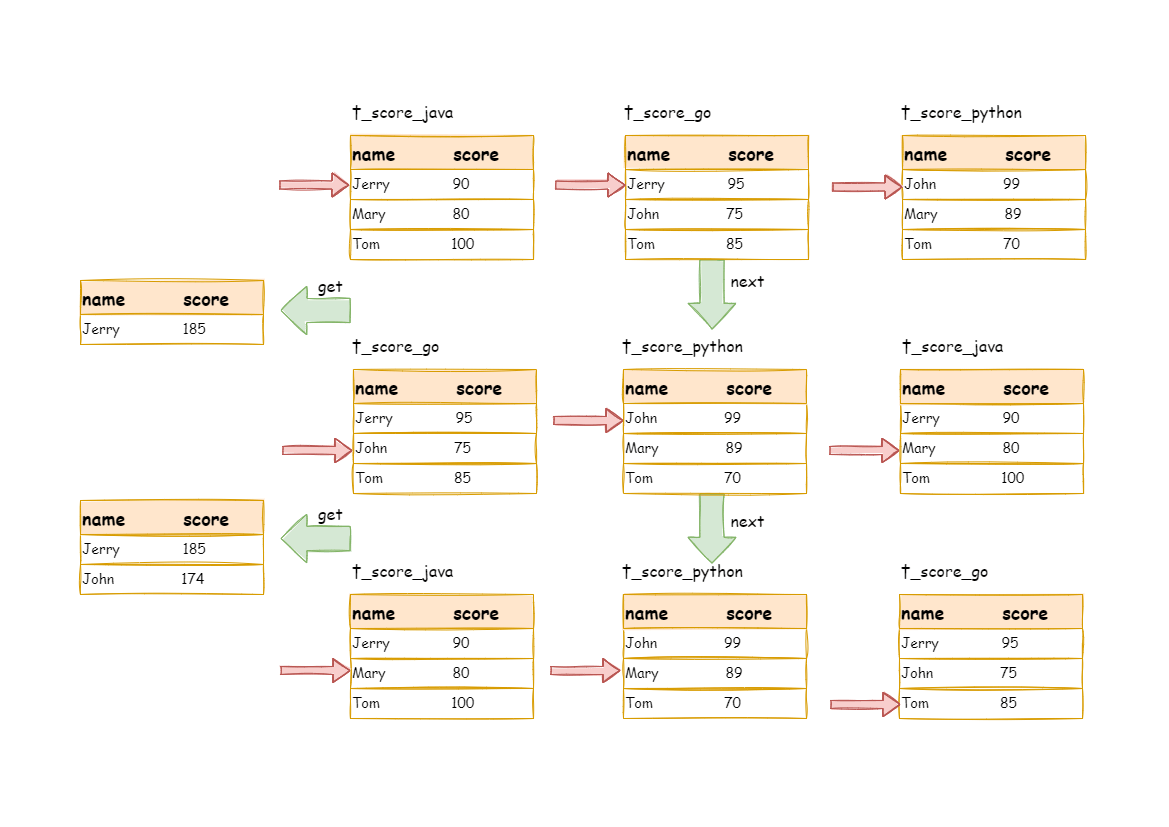
-We can see from the picture, in the first next invocation, t_score_java in the first position, along with other result set data also having the grouping value of “Jerry”, will be popped out of the queue. After acquiring all the students’ scores with the name of “Jerry”, the accumulation operation will be proceeded. Hence, after the first next invocation is finished, the result set acquired is the sum of Jerry’s scores. In the same time, all the cursors in data result sets will be moved d [...]
+We can see from the picture that, in the first `next` call, `t_score_java` in the first place will be popped out of the queue, along with other result set data having the same grouping value of “Jerry”. After acquiring all the students’ scores with the name of “Jerry”, the accumulation operation will proceed. Hence, after the first `next` call is finished, the result set acquired is the sum of Jerry’s scores. At the same time, all the cursors in data result sets will be moved down to a d [...]
-Stream group-by merger is different from order-by merger only in two points:
+Stream group-by merger is different from order-by merger only in two aspects:
-1. It will take out all the data with the same group item from multiple data result sets for once.
-2. It does the aggregation calculation according to aggregation function type.
+1. It will take out all the data with the same group item from multiple data result sets at once.
+1. It carried out the aggregation calculation according to the aggregation function type.
-For the inconsistency between the group item and the order item, it requires to upload all the data to the memory to group and aggregate, since the relevant data value needed to acquire group information is not continuous, and stream merger is not able to use. For example, acquire each examinee’s total score through the following SQL and order them from the highest to the lowest:
+For the inconsistency between the grouping item and ordering item, it requires uploading all the data to the memory to group and aggregate, since the relevant data value needed to acquire group information is not continuous, and stream merger is not available. For example, acquire each examinee’s total score through the following SQL and order them from the highest to the lowest:
```sql
SELECT name, SUM(score) FROM t_score GROUP BY name ORDER BY score DESC;
```
-Then, stream merger is not able to use, for the data taken out from each result set is the same as the original data of the diagram ordered by score in the upper half part structure.
+Then, stream merger is not able to use, for the data taken out from each result set is the same as the original data of the order-by merger diagram in the upper half part structure.
-When SQL only contains group-by statement, according to different database implementation, its sequencing order may not be the same as the group order. The lack of ordering statement indicates the order is not important in this SQL. Therefore, through SQL optimization re-write, ShardingSphere can automatically add the ordering item same as grouping item, converting it from the memory merger that consumes memory to stream merger.
+When SQL only contains the group-by statement, according to different database implementations, its sorting order may not be the same as the group order. The lack of an ordering statement indicates the order is not important in this SQL. Therefore, through the optimization of SQL rewriting, ShardingSphere can automatically add the ordering item the same as the grouping item, converting it from the memory merger that consumes memory to the stream merger.
## Aggregation Merger
-Whether stream group-by merger or memory group-by merger processes the aggregation function in the same way. Therefore, aggregation merger is an additional merging ability based on what have been introduced above, i.e., the decorator mode. The aggregation function can be categorized into three types, comparison, sum and average.
+Whether it is stream group-by merger or memory group-by merger, they process the aggregation function in the same way. In addition to grouped SQL, ungrouped SQL can also use aggregate functions. Therefore, aggregation merger is an additional merging ability based on what has been introduced above, i.e., the decorator mode. The aggregation function can be categorized into three types: comparison, sum and average.
-Comparison aggregation function refers to `MAX` and `MIN`. They need to compare all the result set data and return its maximum or minimum value directly.
+The comparison aggregation function refers to `MAX` and `MIN`. They need to compare all the result set data of each group and simply return the maximum or minimum value.
-Sum aggregation function refers to `SUM` and `COUNT`. They need to sum up all the result set data.
+The sum aggregation function refers to `SUM` and `COUNT`. They need to sum up all the result set data of each group.
-Average aggregation function refers only to `AVG`. It must be calculated through `SUM` and `COUNT` of SQL re-write, which has been mentioned in SQL re-write, so we will state no more here.
+The average aggregation function refers only to `AVG`. It must be calculated through `SUM` and `COUNT` rewritten by SQL, which has been mentioned in the SQL rewriting section.
## Pagination Merger
-All the merger types above can be paginated. Pagination is the decorator added on other kinds of mergers. ShardingSphere augments its ability to paginate the data result set through the decorator mode. Pagination merger is responsible for filtering the data unnecessary to acquire.
+All the merger types above can be paginated. Pagination is the decorator added to other kinds of mergers. ShardingSphere strengthens its ability to paginate the data result set through decorator mode. The pagination merger is responsible for filtering unnecessary data.
-ShardingSphere's pagination function can be misleading to users in that they may think it will take a large amount of memory. In distributed scenarios, it can only guarantee the data accuracy by rewriting ` LIMIT 10000000, 10` to `LIMIT 0, 10000010`. Users can easily have the misconception that ShardingSphere uploads a large amount of meaningless data to the memory and has the risk of memory overflow. Actually, it can be known from the principle of stream merger, only memory group-by mer [...]
+ShardingSphere’s pagination function can be misleading to users in that they may think it will take a large amount of memory. In distributed scenarios, it can only guarantee the data correctness by rewriting `LIMIT 10000000, 10` to `LIMIT 0, 10000010`. Users can easily misunderstand that ShardingSphere uploads a large amount of meaningless data to the memory and has the risk of memory overflow. Actually, it can be known from the principle of stream merger that only memory group-by merger [...]
-What’s to be noticed, pagination with `LIMIT` is not the best practice actually, because a large amount of data still needs to be transmitted to ShardingSphere's memory space for ordering. `LIMIT` cannot search for data by index, so paginating with ID is a better solution on the premise that the ID continuity can be guaranteed. For example:
+But it should be noted that pagination with `LIMIT` is not the best practice, because a large amount of data still needs to be transmitted to ShardingSphere’s memory space for ordering. `LIMIT` cannot query data by index, so paginating with ID is a better solution if ID continuity can be guaranteed. For example:
```sql
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id;
```
-Or search the next page through the ID of the last query result, for example:
+Or query the next page through the ID of the last query result, for example:
```sql
SELECT * FROM t_order WHERE id > 10000000 LIMIT 10;
```
-The overall structure of merger engine is shown in the following diagram:
+The overall structure of the merger engine is shown in the following diagram:
diff --git a/docs/document/content/reference/sharding/parse.en.md b/docs/document/content/reference/sharding/parse.en.md
index c39c33eaf2c..46b3100c894 100644
--- a/docs/document/content/reference/sharding/parse.en.md
+++ b/docs/document/content/reference/sharding/parse.en.md
@@ -3,37 +3,44 @@ title = "Parse Engine"
weight = 1
+++
-Compared to other programming languages, SQL is relatively simple, but it is still a complete set of programming language, so there is no essential difference between parsing SQL grammar and parsing other languages (Java, C and Go, etc.).
+SQL is relatively simple compared with other programming languages, but it's still a complete programming language. Therefore, there's no essential difference between parsing SQL syntax and parsing other languages (such as Java, C and Go, etc.).
## Abstract Syntax Tree
-The parsing process can be divided into lexical parsing and syntactic parsing. Lexical parser is used to divide SQL into indivisible atomic signs, i.e., Token. According to the dictionary provided by different database dialect, it is categorized into keyword, expression, literal value and operator. SQL is then converted into abstract syntax tree by syntactic parser.
+The parsing process is divided into lexical parsing and syntactic parsing. The lexical parser is used to split SQL into indivisible atomic symbols called Tokens.
-For example, the following SQL:
+Tokens are classified into keywords, expressions, literals, and operators based on the dictionaries provided by different database dialects. The syntactic parser is then used to convert the output of the lexical parser into an abstract syntax tree.
+
+For example:
```sql
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18
```
-Its parsing AST (Abstract Syntax Tree) is this:
+After the above SQL is parsed, its AST (Abstract Syntax Tree) is as follows:
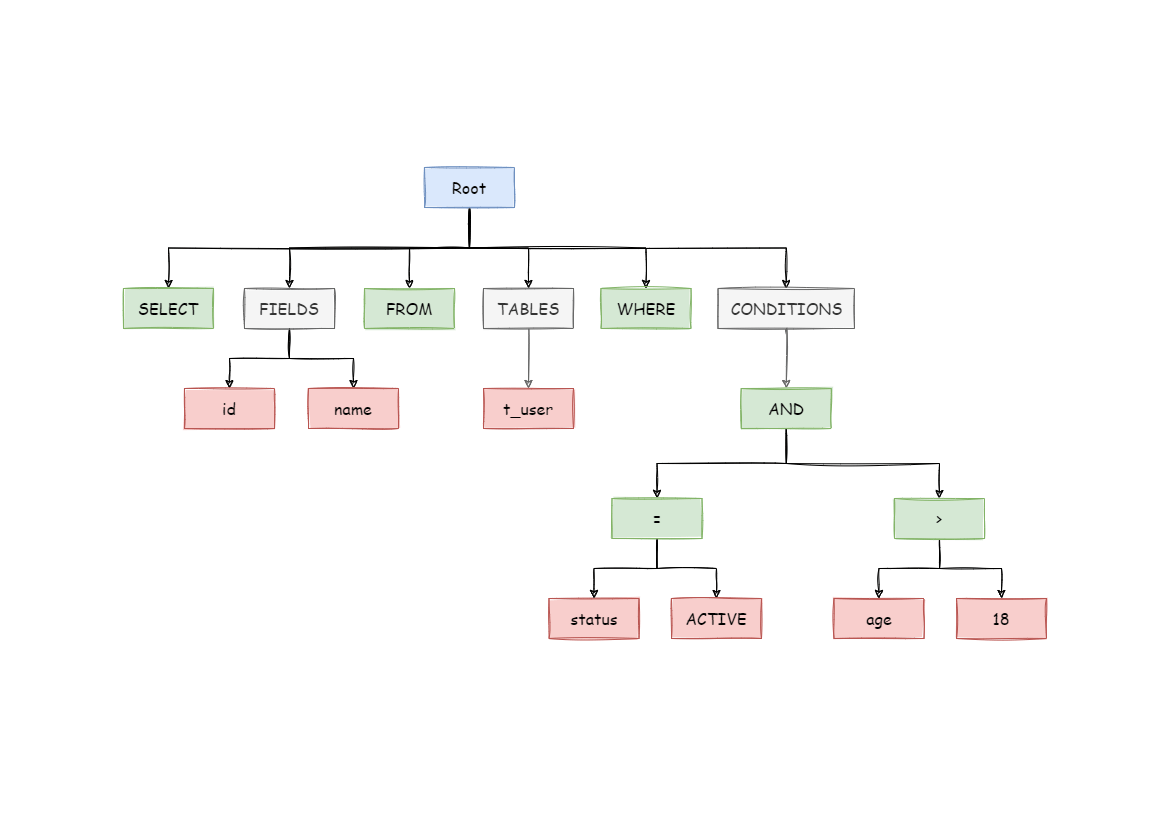
-To better understand, the Token of keywords in abstract syntax tree is shown in green; that of variables is shown in red; what’s to be further divided is shown in grey.
+The tokens for keywords in the AST are green, while the tokens for variables are red, and gray ones indicate that further splitting is required.
+
+Finally, the domain model is traversed through the abstract syntax tree by visitor; the context required for sharding is extracted through the domain model (SQLStatement); and then, mark locations that may need rewriting.
-At last, through traversing the abstract syntax tree, the context needed by sharding is extracted and the place that may need to be rewritten is also marked out. Parsing context for the use of sharding includes select items, table information, sharding conditions, auto-increment primary key information, Order By information, Group By information, and pagination information (Limit, Rownum and Top). One-time SQL parsing process is irreversible, each Token is parsed according to the origina [...]
+The parsing context for sharding includes select items, table, sharding condition, auto-increment primary key, and Order By, Group By, and pagination information (Limit, Rownum, Top). The SQL parsing process is irreversible.
-## SQL Parser
+Each Token is parsed in the original SQL order, providing high performance. Taking the similarities and differences of SQL dialects of various databases into consideration, the SQL dialect dictionary of various databases is provided in the parsing module.
-### History
+## SQL Parser Engine
-As the core of database sharding and table sharding, SQL parser takes the performance and compatibility as its most important index. ShardingSphere SQL parser has undergone the upgrade and iteration of 3 generations of products.
+### Iteration
-To pursue good performance and quick achievement, the first generation of SQL parser uses `Druid` before 1.4.x version. As tested in practice, its performance exceeds other parsers a lot.
+SQL parsing is the core of sharding solutions, and its performance and compatibility are the most important indicators. ShardingSphere's SQL parser has undergone three iterations and upgrades.
-The second generation of SQL parsing engine begins from 1.5.x version, ShardingSphere has adopted fully self-developed parsing engine ever since. Due to different purposes, ShardingSphere does not need to transform SQL into a totally abstract syntax tree or traverse twice through visitor. Using `half parsing` method, it only extracts the context required by data sharding, so the performance and compatibility of SQL parsing is further improved.
+To achieve high performance and fast implementation, the first generation of SQL parsers used Druid prior to V1.4.x. In practical tests, its performance far exceeds that of other parsers.
-The third generation of SQL parsing engine begins from 3.0.x version. ShardingSphere tries to adopts ANTLR as a generator for the SQL parsing engine, and uses Visit to obtain SQL Statement from AST. Starting from version 5.0.x, the architecture of the parsing engine has been refactored. At the same time, it is convenient to directly obtain the parsing results of the same SQL to improve parsing efficiency by putting the AST obtained from the first parsing into the cache. Therefore, we rec [...]
+The second generation of SQL parsers started from V1.5.x. ShardingSphere uses a completely self-developed SQL parsing engine. Owing to different purposes, ShardingSphere does not need to convert SQL into a complete abstract syntax tree, nor does it require a second traversal through the accessor pattern. It uses a half-parsing method to extract only the context required by data sharding, thus further improving the performance and compatibility of SQL parsing.
+
+The third generation of SQL parsers, starting with V3.0.x, attempts to use ANTLR as a generator of SQL parsing engines and uses Visit to obtain SQL statements from the AST.
+Since V5.0.x, the architecture of the parsing engine has been restructured and adjusted. Moreover, the AST obtained from the first parsing is stored in the cache so that the parsing results of the same SQL can be directly obtained next time to improve parsing efficiency. Therefore, it is recommended that you use PreparedStatement, a SQL-precompiled method, to improve performance.
### Features
@@ -50,12 +57,9 @@ The third generation of SQL parsing engine begins from 3.0.x version. ShardingSp
| SQL92 | supported |
| openGauss | supported |
-* SQL format (developing)
-* SQL parameterize (developing)
-
### API Usage
-- Maven
+- Introducing Maven dependency
```xml
<dependency>
@@ -71,7 +75,7 @@ The third generation of SQL parsing engine begins from 3.0.x version. ShardingSp
</dependency>
```
-- Get AST
+- Obtain AST
```java
CacheOption cacheOption = new CacheOption(128, 1024L);
@@ -79,7 +83,7 @@ SQLParserEngine parserEngine = new SQLParserEngine(sql, cacheOption);
ParseASTNode parseASTNode = parserEngine.parse(sql, useCache);
```
-- GET SQLStatement
+- Obtain SQLStatement
```java
CacheOption cacheOption = new CacheOption(128, 1024L);
@@ -89,7 +93,7 @@ SQLVisitorEngine sqlVisitorEngine = new SQLVisitorEngine(sql, "STATEMENT", useCa
SQLStatement sqlStatement = sqlVisitorEngine.visit(parseASTNode);
```
-- SQL Format
+- SQL Formatting
```java
ParseASTNode parseASTNode = parserEngine.parse(sql, useCache);
@@ -97,7 +101,7 @@ SQLVisitorEngine sqlVisitorEngine = new SQLVisitorEngine(sql, "STATEMENT", useCa
SQLStatement sqlStatement = sqlVisitorEngine.visit(parseASTNode);
```
-example:
+Example:
| Original SQL | Formatted SQL |
|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |-------------------------------------------------------------------------------------------------------------------------------------------- |
diff --git a/docs/document/content/reference/sharding/rewrite.en.md b/docs/document/content/reference/sharding/rewrite.en.md
index 9c91a21d8a1..b15b48e1825 100644
--- a/docs/document/content/reference/sharding/rewrite.en.md
+++ b/docs/document/content/reference/sharding/rewrite.en.md
@@ -3,205 +3,227 @@ title = "Rewrite Engine"
weight = 3
+++
-The SQL written by engineers facing logic databases and tables cannot be executed directly in actual databases. SQL rewrite is used to rewrite logic SQL into rightly executable ones in actual databases, including two parts, correctness rewrite and optimization rewrite.
+SQL written by engineers for logical databases and tables cannot be directly executed in real databases.
-## Correctness Rewrite
+SQL rewriting is used to rewrite logical SQL into SQL that can be executed correctly in real databases. It includes rewriting for correctness and rewriting for optimization.
-In situation with sharding tables, it requires to rewrite logic table names in sharding settings into actual table names acquired after routing. Database sharding does not require to rewrite table names. In addition to that, there are also column derivation, pagination information revision and other content.
+## Rewriting for Correctness
-## Identifier Rewrite
+In a scenario with table shards, you need to rewrite the logical table name in the table shards configuration to the real table name obtained after routing.
-Identifiers that need to be rewritten include table name, index name and schema name. Table name rewrite refers to the process to locate the position of logic tables in the original SQL and rewrite it as the physical table. Table name rewrite is one typical situation that requires to parse SQL. From a most plain case, if the logic SQL is as follow:
+Only database shards do not require rewriting table names. Additionally, it also includes column derivation and pagination information correction.
+
+## Identifier Rewriting
+
+The identifiers that need to be overwritten include table names, index names, and Schema names.
+
+Rewriting table names is the process of finding the location of the logical table in the original SQL and rewriting it into a real table.
+
+Table name rewriting is a typical scenario that requires SQL parsing. For example, if logical SQL is:
```sql
SELECT order_id FROM t_order WHERE order_id=1;
```
-If the SQL is configured with sharding key order_id=1, it will be routed to Sharding Table 1. Then, the SQL after rewrite should be:
+Assume that the SQL is configured with the shard key `order_id` and `order_id=1`, it will be routed to shard table 1. Then the rewritten SQL should be:
```sql
SELECT order_id FROM t_order_1 WHERE order_id=1;
```
-In this most simple kind of SQL, whether parsing SQL to abstract syntax tree seems unimportant, SQL can be rewritten only by searching for and substituting characters. But in the following situation, it is unable to rewrite SQL rightly merely by searching for and substituting characters:
+In the simplest SQL scenario, it doesn't seem to matter whether or not the SQL is parsed into an abstract syntax tree.
+
+SQL can be rewritten correctly only by finding and replacing strings. However, it is impossible to achieve the same effect in the following scenarios.
```sql
SELECT order_id FROM t_order WHERE order_id=1 AND remarks=' t_order xxx';
```
-The SQL rightly rewritten is supposed to be:
+The correct rewritten SQL would be:
```sql
SELECT order_id FROM t_order_1 WHERE order_id=1 AND remarks=' t_order xxx';
```
-Rather than:
+Instead of:
```sql
SELECT order_id FROM t_order_1 WHERE order_id=1 AND remarks=' t_order_1 xxx';
```
-Because there may be similar characters besides the table name, the simple character substitute method cannot be used to rewrite SQL. Here is another more complex SQL rewrite situation:
+Because there may be characters similar to the table name, you cannot rewrite SQL simply by replacing strings.
+
+Let's look at a more complex scenario:
```sql
SELECT t_order.order_id FROM t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
```
-The SQL above takes table name as the identifier of the field, so it should also be revised when SQL is rewritten:
+The above SQL uses the table name as an identifier of the field, so it needs to be modified when SQL is rewritten:
```sql
SELECT t_order_1.order_id FROM t_order_1 WHERE t_order_1.order_id=1 AND remarks=' t_order xxx';
```
-But if there is another table name defined in SQL, it is not necessary to revise that, even though that name is the same as the table name. For example:
+If a table alias is defined in SQL, the alias does not need to be modified, even if it is the same as the table name. For example:
```sql
SELECT t_order.order_id FROM t_order AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
```
-SQL rewrite only requires to revise its table name:
+Rewriting the table name is enough for SQL rewriting.
```sql
SELECT t_order.order_id FROM t_order_1 AS t_order WHERE t_order.order_id=1 AND remarks=' t_order xxx';
```
-Index name is another identifier that can be rewritten. In some databases (such as MySQL/SQLServer), the index is created according to the table dimension, and its names in different tables can repeat. In some other databases (such as PostgreSQL/Oracle), however, the index is created according to the database dimension, index names in different tables are required to be one and the only.
+The index name is another identifier that can be rewritten. In some databases (such as MySQL and SQLServer), indexes are created in the dimension of tables.
+
+Indexes in different tables can have the same name. In other databases (such as PostgreSQL and Oracle), indexes are created in the dimension of databases, and even indexes on different tables should have unique names.
-In ShardingSphere, schema management method is similar to that of the table. It uses logic schema to manage a set of data sources, so it requires to replace the logic schema written by users in SQL with physical database schema.
+In ShardingSphere, schemas are managed in the same way as tables. Logical Schemas are used to manage a set of data sources.
-ShardingSphere only supports to use schema in database management statements but not in DQL and DML statements, for example:
+Therefore, ShardingSphere needs to replace the logical Schema written by the user in SQL with the real database Schema.
+
+Currently, ShardingSphere does not support the use of Schema in DQL and DML statements. It only supports the use of Schema in database management statements. For example:
```sql
SHOW COLUMNS FROM t_order FROM order_ds;
```
-Schema rewrite refers to rewriting logic schema as a right and real schema found arbitrarily with unicast route.
+Schema rewriting refers to the rewriting of a logical Schema using unicast routing to a correct and real Schema that is randomly found.
## Column Derivation
-Column derivation in query statements usually results from two situations. First, ShardingSphere needs to acquire the corresponding data when merging results, but it is not returned through the query SQL. This kind of situation aims mainly at GROUP BY and ORDER BY. Result merger requires sorting and ranking according to items of `GROUP BY` and `ORDER BY`field. But if sorting and ranking items are not included in the original SQL, it should be rewritten. Look at the situation where the or [...]
+There are two cases that need to complement columns in a query statement. In the first case, ShardingSphere needs to get the data during the result merge, but the data is not returned by the queried SQL.
+
+In this case, it mainly applies to GROUP BY and ORDER BY. When merging the results, you need to group and order the field items according to `GROUP BY` and `ORDER BY`, but if the original SQL does not contain grouping or ordering items in the selections, you need to rewrite the original SQL. Let's look at a scenario where the original SQL has the required information for result merge.
```sql
SELECT order_id, user_id FROM t_order ORDER BY user_id;
```
-Since user_id is used in ranking, the result merger needs the data able to acquire user_id. The SQL above is able to acquire user_id data, so there is no need to add columns.
+Since `user_id` is used for sorting, the data of `user_id` needs to be retrieved in the result merge. And the above SQL can obtain the data of `user_id`, so there is no need to add columns.
-If the selected item does not contain the column required by result merger, it will need to add column, as the following SQL:
+If the selection does not contain the columns required to merge the results, you need to fill the columns, as in the following SQL:
```sql
SELECT order_id FROM t_order ORDER BY user_id;
```
-Since the original SQL does not contain user_id needed by result merger, the SQL needs to be rewritten by adding columns, and after that, it will be:
+Since the original SQL does not contain the `user_id` required in the result merge, you need to fill in and rewrite the SQL. Then SQL would be:
```sql
SELECT order_id, user_id AS ORDER_BY_DERIVED_0 FROM t_order ORDER BY user_id;
```
-What’s to be mentioned, column derivation will only add the missing column rather than all of them; the SQL that includes `*` in SELECT will also selectively add columns according to the meta-data information of tables. Here is a relatively complex SQL column derivation case:
+It should be noted that only missing columns are complemented instead of all columns. And SQL that contains * in the SELECT statement will also selectively complement columns based on the metadata information of the table. Here is a relatively complex column derivation scenario of SQL:
```sql
SELECT o.* FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
```
-Suppose only t_order_item table contains order_item_id column, according to the meta-data information of tables, the user_id in sorting item exists in table t_order as merging result, but order_item_id does not exist in t_order, so it needs to add columns. The SQL after that will be:
+We assume that only the table `t_order_item` contains the column `order_item_id`. According to the metadata information of the table, when the result is merged, the `user_id` in the ordering items exists on the table `t_order`, so there is no need to add columns. `order_item_id` is not in `t_order`, so column derivation is required. Then SQL would become:
```sql
SELECT o.*, order_item_id AS ORDER_BY_DERIVED_0 FROM t_order o, t_order_item i WHERE o.order_id=i.order_id ORDER BY user_id, order_item_id;
```
-Another situation of column derivation is using AVG aggregation function. In distributed situations, it is not right to calculate the average value with avg1 + avg2 + avg3 / 3, and it should be rewritten as (sum1 + sum2 + sum3) / (count1 + count2 + count3). This requires to rewrite the SQL that contains AVG as SUM and COUNT and recalculate the average value in result merger. Such as the following SQL:
+The second case of column derivation is the use of AVG aggregate functions. In distributed scenarios, using (avg1 + avg2 + avg3)/3 to calculate the average is incorrect and should be rewritten as (sum1 + sum2 + sum3) /(count1 + count2 + count3). In this case, rewriting the SQL containing AVG to SUM and COUNT is required, and recalculating the average when the results are merged. For example:
```sql
SELECT AVG(price) FROM t_order WHERE user_id=1;
```
-Should be rewritten as:
+The above SQL should be rewritten as:
```sql
SELECT COUNT(price) AS AVG_DERIVED_COUNT_0, SUM(price) AS AVG_DERIVED_SUM_0 FROM t_order WHERE user_id=1;
```
-Then it can calculate the right average value through result merger.
+Then you can calculate the average correctly by merging the results.
-The last kind of column derivation is in SQL with INSERT. With database auto-increment key, there is no need to fill in primary key field. But database auto-increment key cannot satisfy the requirement of only one primary key being in the distributed situation. So ShardingSphere provides a distributed auto-increment key generation strategy, enabling users to replace the current auto-increment key invisibly with a distributed one without changing existing codes through column derivation. [...]
+The last type of column derivation is the one that does not need to write the primary key field if the database auto-increment primary key is used during executing an INSERT SQL statement. However, the auto-increment primary key of the database cannot meet the unique primary key in distributed scenarios. Therefore, ShardingSphere provides the generation strategy of the distributed auto-increment primary key. Users can replace the existing auto-increment primary key transparently with the [...]
```sql
INSERT INTO t_order (`field1`, `field2`) VALUES (10, 1);
```
-It can be seen that the SQL above does not include an auto-increment key, which will be filled by the database itself. After ShardingSphere set an auto-increment key, the SQL will be rewritten as:
+As you can see, the above SQL does not contain the auto-increment primary key, which requires the database itself to fill. After ShardingSphere is configured with the auto-increment primary key, SQL will be rewritten as:
```sql
INSERT INTO t_order (`field1`, `field2`, order_id) VALUES (10, 1, xxxxx);
```
-Rewritten SQL will add auto-increment key name and its value generated automatically in the last part of INSERT FIELD and INSERT VALUE. `xxxxx` in the SQL above stands for the latter one.
+The rewritten SQL will add column names of the primary key and auto-increment primary key values generated automatically at the end of the INSERT FIELD and INSERT VALUE. The xxxxx in the above SQL represents the auto-increment primary key value generated automatically.
-If INSERT SQL does not contain the column name of the table, ShardingSphere can also automatically generate auto-increment key by comparing the number of parameter and column in the table meta-information. For example, the original SQL is:
+If the INSERT SQL does not contain the column name of the table, ShardingSphere can also compare the number of parameters and the number of columns in the table meta information and automatically generate auto-increment primary keys. For example, the original SQL is:
```sql
INSERT INTO t_order VALUES (10, 1);
```
-The rewritten SQL only needs to add an auto-increment key in the column where the primary key is:
+The rewritten SQL will simply add the auto-increment primary key in the column order in which the primary key locates:
```sql
INSERT INTO t_order VALUES (xxxxx, 10, 1);
```
-When auto-increment key derives column, if the user writes SQL with placeholder, he only needs to rewrite parameter list but not SQL itself.
+If you use placeholders to write SQL, you only need to rewrite the parameter list, not the SQL itself.
-## Pagination Revision
+## Pagination Correction
-The scenarios of acquiring pagination data from multiple databases is different from that of one single database. If every 10 pieces of data are taken as one page, the user wants to take the second page of data. It is not right to take, acquire LIMIT 10, 10 under sharding situations, and take out the first 10 pieces of data according to sorting conditions after merging. For example, if the SQL is:
+The scenario of acquiring pagination data from multiple databases is different from that of one single database. If every 10 pieces of data are taken as one page, the user wants to take the second page of data. It is not correct to acquire `LIMIT 10, 10` under sharding situations, or take out the first 10 pieces of data according to sorting conditions after merging. For example, if SQL is:
```sql
SELECT score FROM t_score ORDER BY score DESC LIMIT 1, 2;
```
-The following picture shows the pagination execution results without SQL rewrite.
+The following picture shows the pagination execution results without SQL rewriting.
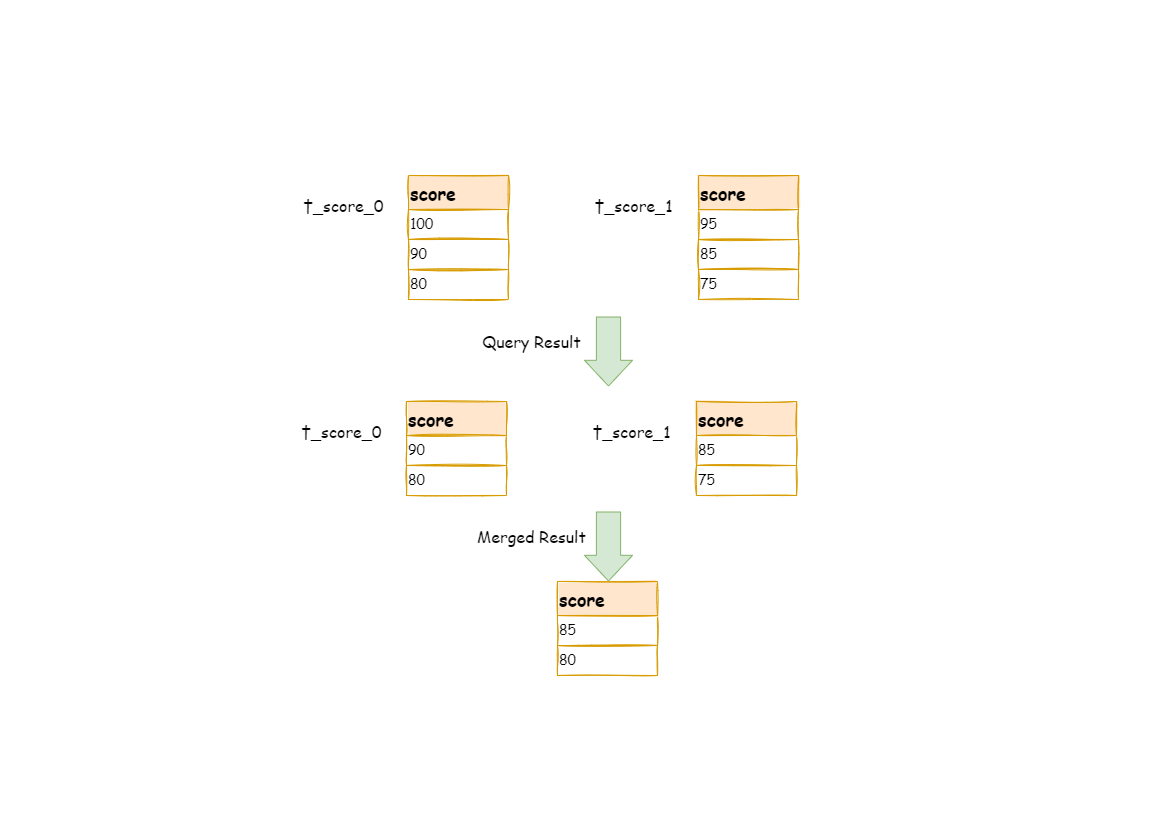
-As shown in the picture, if you want to acquire the second and the third piece of data ordered by score common in both tables, and they are supposed to be `95` and `90`.
-Since the executed SQL can only acquire the second and the third piece of data from each table, i.e., `90` and `80` from t_score_0, `85` and `75` from t_score_1.
+As shown in the picture, if you want to acquire the second and the third piece of data sorted by score in both tables, and they are supposed to be `95` and `90`.
+
+Since executed SQL can only acquire the second and the third piece of data from each table, i.e., `90` and `80` from `t_score_0`, `85` and `75` from `t_score_1`.
When merging results, it can only merge from `90`, `80`, `85` and `75` already acquired, so the right result cannot be acquired anyway.
-The right way is to rewrite pagination conditions as `LIMIT 0, 3`, take out all the data from the first two pages and combine sorting conditions to calculate the right data.
-The following picture shows the execution of pagination results after SQL rewrite.
+The right way is to rewrite pagination conditions as `LIMIT 0, 3`, take out all the data from the first two pages and calculate the right data based on sorting conditions.
+The following picture shows the execution results of pagination after SQL rewrite.
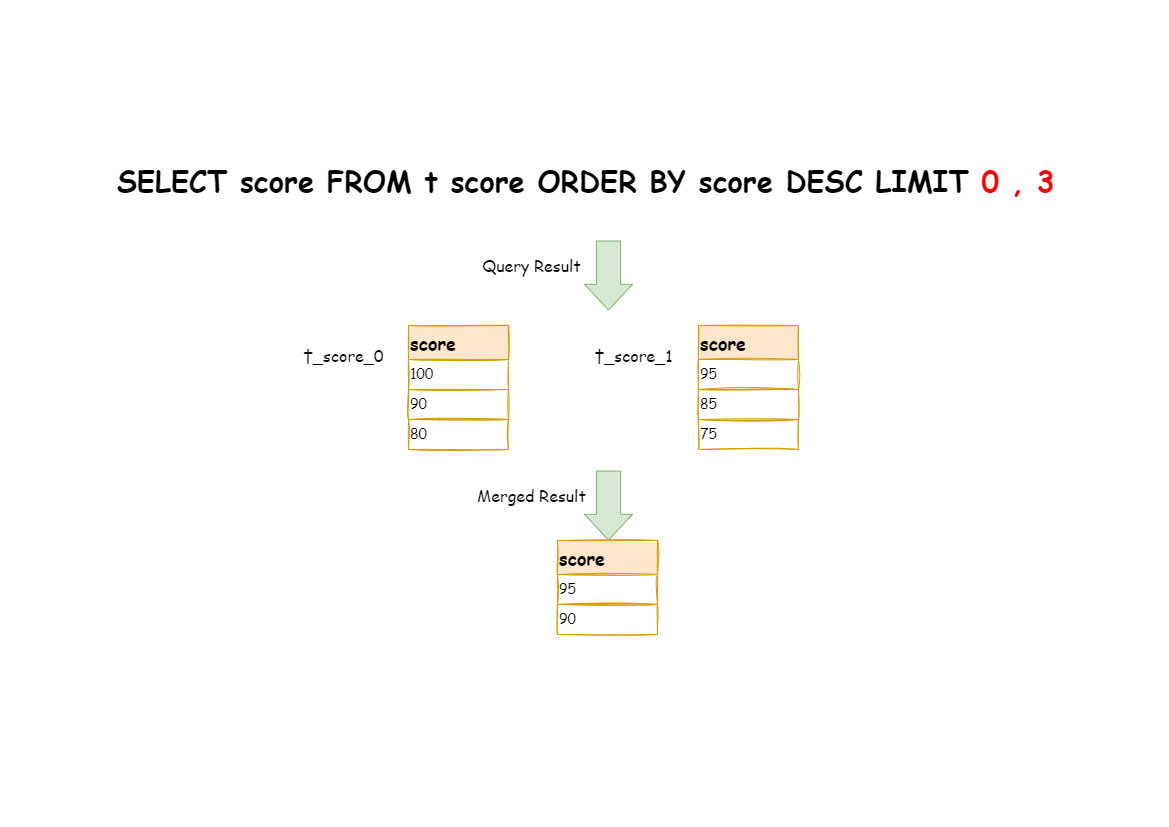
-The latter the offset position is, the lower the efficiency of using LIMIT pagination will be.
-There are many ways to avoid using LIMIT as pagination method, such as constructing a secondary index to record line record number and line offset amount,
-or using the tail ID of last pagination data as the pagination method of conditions of the next query.
+The latter the offset position is, the lower the efficiency of using `LIMIT` pagination will be.
+There are many ways to avoid using `LIMIT` as pagination method, such as constructing a secondary index to the number of line records and line offsets or using the end ID of the last pagination data as a condition for the next query.
-When revising pagination information, if the user uses placeholder method to write SQL, he only needs to rewrite parameter list rather than SQL itself.
+When revising pagination information, if the users use the placeholder to write SQL, they only need to rewrite the parameter list rather than SQL itself.
## Batch Split
-When using batch inserted SQL, if the inserted data crosses sharding, the user needs to rewrite SQL to avoid writing excessive data into the database. The differences between insert operation and query operation are: though the query sentence has used sharding keys that do not exist in current sharding, they will not have any influence on data, but insert operation has to delete extra sharding keys. Take the following SQL for example:
+When using bulk inserted SQL, if the inserted data crosses shards, the SQL needs to be rewritten to prevent excess data from being written to the database.
+
+The insertion operation differs from the query operation in that the query statement does not affect the data even if it uses the shard key that does not exist in the current shard. In contrast, insertion operations must remove excess shard keys. For example, see the following SQL:
```sql
INSERT INTO t_order (order_id, xxx) VALUES (1, 'xxx'), (2, 'xxx'), (3, 'xxx');
```
-If the database is still divided into two parts according to odd and even number of order_id, this SQL will be executed after its table name is revised. Then, both shards will be written with the same record. Though only the data that satisfies sharding conditions can be taken out from query statement, it is not reasonable for the schema to have excessive data. So the SQL should be rewritten as:
+If the database is still divided into two parts according to the odd and even number of order_id, this SQL will be executed after its table name is revised. Then, both shards will be written with the same record.
+
+Though only the data that satisfies sharding conditions can be retrieved from the query statement, it is not reasonable for the schema to have excessive data. So SQL should be rewritten as:
```sql
INSERT INTO t_order_0 (order_id, xxx) VALUES (2, 'xxx');
INSERT INTO t_order_1 (order_id, xxx) VALUES (1, 'xxx'), (3, 'xxx');
```
-IN query is similar to batch insertion, but IN operation will not lead to wrong data query result. Through rewriting IN query, the query performance can be further improved. Like the following SQL:
+IN query is similar to batch insertion, but IN operation will not lead to wrong data query result. Through rewriting IN query, the query performance can be further improved. See the following SQL:
```sql
SELECT * FROM t_order WHERE order_id IN (1, 2, 3);
```
-Is rewritten as:
+The SQL is rewritten as:
```sql
SELECT * FROM t_order_0 WHERE order_id IN (2);
@@ -215,20 +237,22 @@ SELECT * FROM t_order_0 WHERE order_id IN (1, 2, 3);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2, 3);
```
-Though the execution result of SQL is right, but it has not achieved the most optimized query efficiency.
+Though the execution result of SQL is right, it did not achieve the highest query efficiency.
-## Optimization Rewrite
+## Rewriting for Optimization
-Its purpose is to effectively improve the performance without influencing the correctness of the query. It can be divided into single node optimization and stream merger optimization.
+Its purpose is to effectively improve performance without influencing the correctness of the query. It can be divided into single node optimization and stream merger optimization.
### Single Node Optimization
-It refers to the optimization that stops the SQL rewrite from the route to the single node. After acquiring one route result, if it is routed to a single data node, result merging is unnecessary to be involved, so there is no need for rewrites as derived column, pagination information and others. In particular, there is no need to read from the first piece of information, which reduces the pressure for the database to a large extent and saves meaningless consumption of the network bandwidth.
+It refers to the optimization that stops the SQL rewrite from the route to the single node. After acquiring one route result, if it is routed to a single data node, there is no need to involve result merger, as well as rewrites such as column derivation and pagination information correction.
+
+In particular, there is no need to read from the first piece of information, which reduces the pressure on the database to a large extent and saves meaningless consumption of the network bandwidth.
### Stream Merger Optimization
-It only adds sorting items and sorting orders identical with grouping items and `ORDER BY` to `GROUP BY` SQL, and they are used to transfer memory merger to stream merger. In the result merger part, stream merger and memory merger will be explained in detail.
+It only adds `ORDER BY` and ordering items and sorting orders identical with grouping items to SQL that contains `GROUP BY`. And it is used to transfer memory merger to stream merger. Stream merger and memory merger will be explained in detail in the result merger section.
-The overall structure of rewrite engine is shown in the following picture.
+The overall structure of the rewrite engine is shown in the following picture.
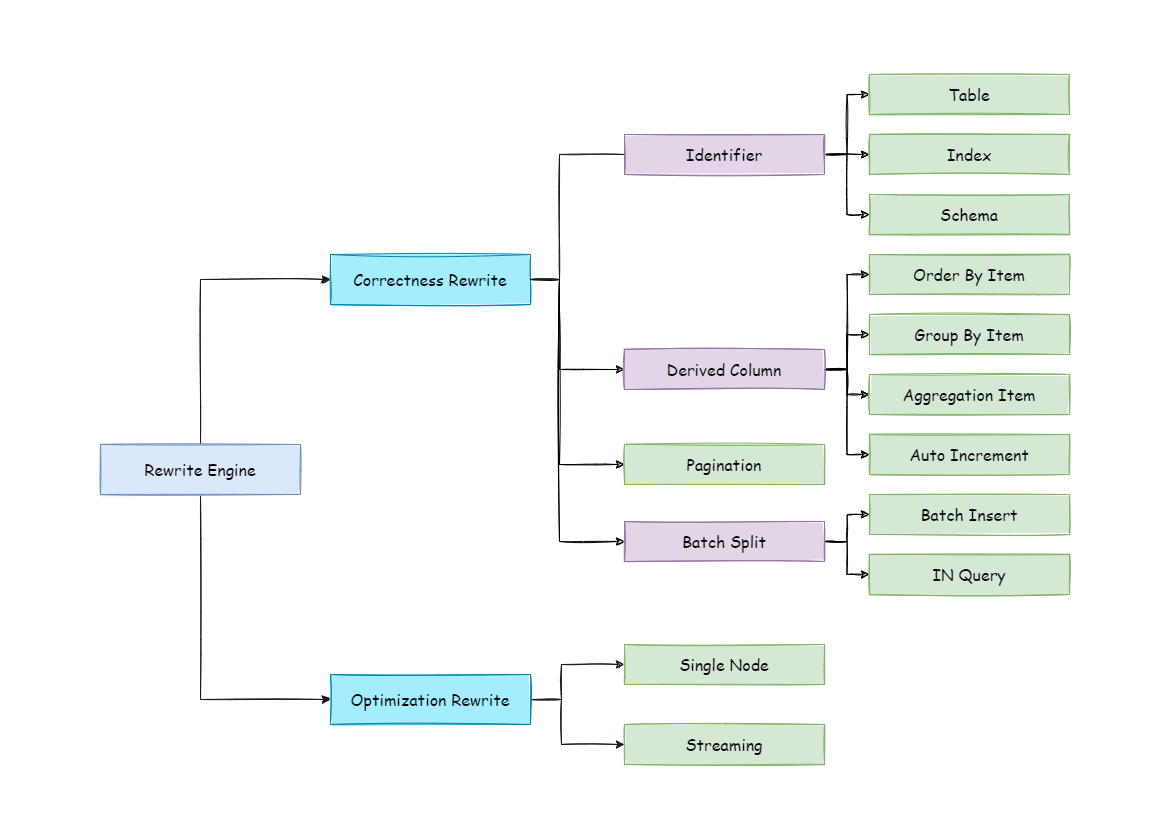
diff --git a/docs/document/content/reference/sharding/route.en.md b/docs/document/content/reference/sharding/route.en.md
index 2ac0ce4dcb4..56ce204b3a2 100644
--- a/docs/document/content/reference/sharding/route.en.md
+++ b/docs/document/content/reference/sharding/route.en.md
@@ -3,17 +3,23 @@ title = "Route Engine"
weight = 2
+++
-It refers to the sharding strategy that matches databases and tables according to the parsing context and generates route path. SQL with sharding keys can be divided into single-sharding route (equal mark as the operator of sharding key), multiple-sharding route (IN as the operator of sharding key) and range sharding route (BETWEEN as the operator of sharding key). SQL without sharding key adopts broadcast route.
+Sharding strategies for databases and tables are matched based on the parsing context, and routing paths are generated. SQL with shard keys can be divided into the single-shard router (the shard key operator is equal), multi-shard router (the shard key operator is IN), and range router (the shard key operator is BETWEEN). SQL that does not carry shard keys adopts broadcast routing.
-Sharding strategies can usually be set in the database or by users. Strategies built in the database are relatively simple and can generally be divided into last number modulo, hash, range, tag, time and so on. More flexible, sharding strategies set by users can be customized according to their needs. Together with automatic data migration, database middle layer can automatically shard and balance the data without users paying attention to sharding strategies, and thereby the distributed [...]
+Sharding strategies can usually be configured either by the built-in database or by the user. The built-in database scheme is relatively simple, and the built-in sharding strategy can be roughly divided into mantissa modulo, hash, range, label, time, etc.
+
+The sharding strategies configured by the user are more flexible. You can customize the compound sharding strategy based on the user's requirements. If it is used with automatic data migration, users do not need to work on the sharding strategies.
+
+Sharding and data balancing can be automatically achieved by the middle layer of the database, and distributed databases can achieve elastic scalability. In the planning of ShardingSphere, the elastic scaling function will be available at V4.x.
## Sharding Route
-It is used in the situation to route according to the sharding key, and can be sub-divided into 3 types, direct route, standard route and Cartesian product route.
+The scenario that is routed based on shard keys is divided into three types: direct route, standard route, and Cartesian route.
### Direct Route
-The conditions for direct route are relatively strict. It requires to shard through Hint (use HintAPI to appoint the route to databases and tables directly). On the premise of having database sharding but not table sharding, SQL parsing and the following result merging can be avoided. Therefore, with the highest compatibility, it can execute any SQL in complex situations, including sub-queries, self-defined functions.
-Direct route can also be used in the situation where sharding keys are not in SQL. For example, set sharding key as `3`.
+
+The requirement for direct route is relatively harsh. It needs to be sharded by Hint (using HintAPI to specify routes to databases and tables), and it can avoid SQL parsing and subsequent result merge on the premise of having database shards but not table shards.
+
+Therefore, it is the most compatible one and can execute any SQL in complex scenarios including sub-queries and custom functions. The direct route can also be used when shard keys are not in SQL. For example, set the key for database sharding to `3`,
```java
hintManager.setDatabaseShardingValue(3);
@@ -38,37 +44,42 @@ try (
```
### Standard Route
-Standard route is ShardingSphere's most recommended sharding method. Its application range is the SQL that does not include joint query or only includes joint query between binding tables. When the sharding operator is equal mark, the route result will fall into a single database (table); when sharding operators are BETWEEN or IN, the route result will not necessarily fall into the only database (table). So one logic SQL can finally be split into multiple real SQL to execute. For example [...]
+
+The standard route is the most recommended sharding method, and it is applicable to SQL that does not contain an associated query or only contains the associated query between binding tables.
+
+When the sharding operator is equal, the routing result will fall into a single database (table). When the sharding operator is BETWEEN or IN, the routing result will not necessarily fall into a unique database (table).
+
+Therefore, logical SQL may eventually be split into multiple real SQL to be executed. For example, if the data sharding is carried out according to the odd and even numbers of order_id, the SQL for a single table query is as follows:
```sql
SELECT * FROM t_order WHERE order_id IN (1, 2);
```
-The route result will be:
+Then the routing result should be:
```sql
SELECT * FROM t_order_0 WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 WHERE order_id IN (1, 2);
```
-The complexity and performance of the joint query are comparable with those of single-table query.
-For instance, if a joint query SQL that contains binding tables is as this:
+An associated query for a binding table is as complex as a single table query and they have the same performance. For example, if the SQL of an associated query that contains binding tables is as follows:
```sql
SELECT * FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
```
-Then, the route result will be:
+Then the routing result should be:
```sql
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
```
-It can be seen that, the number of divided SQL is the same as the number of single tables.
+As you can see, the number of SQL splits is consistent with that of a single table.
### Cartesian Route
-Cartesian route has the most complex situation, it cannot locate sharding rules according to the binding table relationship, so the joint query between non-binding tables needs to be split into Cartesian product combination to execute. If SQL in the last case is not configured with binding table relationship, the route result will be:
+
+The Cartesian route is the most complex one because it cannot locate sharding rules according to the relationship between binding tables, so associated queries between unbound tables need to be disassembled and executed as cartesian product combinations. If the SQL in the previous example was not configured with binding table relationships, the routing result would be:
```sql
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
@@ -77,21 +88,21 @@ SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE order_id IN (1, 2);
```
-Cartesian product route has a relatively low performance, so it should be careful to use.
+The Cartesian route query has low performance, so think carefully when you use it.
## Broadcast Route
-For SQL without sharding key, broadcast route is used. According to SQL types, it can be divided into five types, schema & table route, database schema route, database instance route, unicast route and ignore route.
+For SQL that does not carry shard keys, broadcast routes are used. According to the SQL type, it can be further divided into five types: full database and table route, full database route, full instance route, unicast route, and block route.
-### Schema & Table Route
+### Full database and table route
-Schema & table route is used to deal with all the operations of physical tables related to its logic table, including DQL and DML without sharding key and DDL, etc. For example.
+The full database table route is used to handle operations on all real tables related to its logical tables in the database, including DQL and DML without shard keys, as well as DDL, etc. For example:
```sql
SELECT * FROM t_order WHERE good_prority IN (1, 10);
```
-It will traverse all the tables in all the databases, match the logical table and the physical table name one by one and execute them if succeeded. After routing, they are:
+All tables in all databases will be traversed, matching logical tables and real table names one by one. The table that can be matched will be executed. The routing result would be:
```sql
SELECT * FROM t_order_0 WHERE good_prority IN (1, 10);
@@ -100,45 +111,50 @@ SELECT * FROM t_order_2 WHERE good_prority IN (1, 10);
SELECT * FROM t_order_3 WHERE good_prority IN (1, 10);
```
-### Database Schema Route
+### Full database route
+
+The full database route is used to handle operations on the database, including database management commands of type SET for database settings and transaction control statements such as TCL.
-Database schema route is used to deal with database operations, including the SET database management order used to set the database and transaction control statement as TCL. In this case, all physical databases matched with the name are traversed according to logical database name, and the command is executed in the physical database. For example:
+In this case, all real database matching names are traversed based on the logical database name, and the command is executed in the real database. For example:
```sql
SET autocommit=0;
```
-If this command is executed in `t_order`, `t_order` will have 2 physical databases. And it will actually be executed in both `t_order_0` and `t_order_1`.
+If the command is executed in `t_order`, `t_order` which has two real databases, it is actually executed on both `t_order_0` and `t_order_1`.
-### Database Instance Route
+### Full instance route
-Database instance route is used in DCL operation, whose authorization statement aims at database instances. No matter how many schemas are included in one instance, each one of them can only be executed once. For example:
+Full instance route is used for DCL operations, and authorized statements are used for database instances.
+
+No matter how many schemas are contained in an instance, each database instance is executed only once. For example:
```sql
CREATE USER customer@127.0.0.1 identified BY '123';
```
-This command will be executed in all the physical database instances to ensure customer users have access to each instance.
+This command will be executed on all real database instances to ensure that users can access each instance.
### Unicast Route
-Unicast route is used in the scenario of acquiring the information from some certain physical table. It only requires to acquire data from any physical table in any database. For example:
+The unicast route is used to obtain the information of a real table. It only needs to obtain data from any real table in any database. For example:
```sql
DESCRIBE t_order;
```
-The descriptions of the two physical tables, t_order_0 and t_order_1 of t_order have the same structure, so this command is executed once on any physical table.
+`t_order_0` and `t_order_1`, the two real tables of `t_order`, have the same description structure, so this command is executed only once on any real table.
-### Ignore Route
+### Block Route
-Ignore route is used to block the operation of SQL to the database. For example:
+Block route is used to block SQL operations on the database, for example:
```sql
USE order_db;
```
-This command will not be executed in physical database. Because ShardingSphere uses logic Schema, there is no need to send the Schema shift order to the database.
-The overall structure of route engine is as the following:
+This command will not be executed in a real database because ShardingSphere uses the logical Schema and there is no need to send the Schema shift command to the database.
+
+The overall structure of the routing engine is as follows.
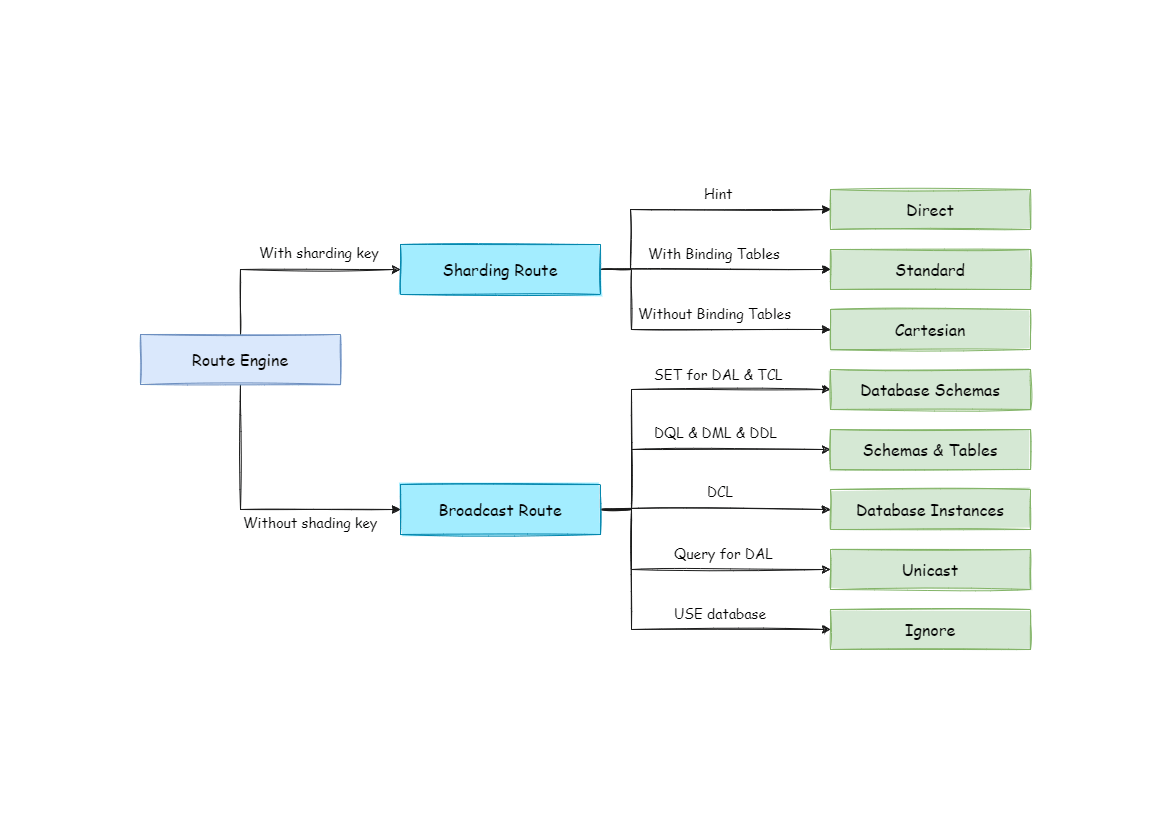
diff --git a/docs/document/static/img/sharding/sharding_architecture_cn_v2.png b/docs/document/static/img/sharding/sharding_architecture_cn_v2.png
index 68836028733..2a74c7927de 100644
Binary files a/docs/document/static/img/sharding/sharding_architecture_cn_v2.png and b/docs/document/static/img/sharding/sharding_architecture_cn_v2.png differ
diff --git a/docs/document/static/img/sharding/sharding_architecture_en_v2.png b/docs/document/static/img/sharding/sharding_architecture_en_v2.png
index 8b9e9176c11..2a74c7927de 100644
Binary files a/docs/document/static/img/sharding/sharding_architecture_en_v2.png and b/docs/document/static/img/sharding/sharding_architecture_en_v2.png differ