You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@carbondata.apache.org by xuchuanyin <gi...@git.apache.org> on 2018/04/21 03:31:00 UTC
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
GitHub user xuchuanyin opened a pull request:
https://github.com/apache/carbondata/pull/2200
[CARBONDATA-2373][DataMap] Add bloom datamap to support precise equal query
For each indexed column, adding a bloom filter for each blocklet to
indicate whether it belongs to this blocklet.
Currently bloom filter is using guava version.
Be sure to do all of the following checklist to help us incorporate
your contribution quickly and easily:
- [x] Any interfaces changed?
`Yes, added interface in DataMapMeta`
- [x] Any backward compatibility impacted?
`NO`
- [x] Document update required?
`NO`
- [x] Testing done
Please provide details on
- Whether new unit test cases have been added or why no new tests are required?
`Added tests`
- How it is tested? Please attach test report.
`Tested in local machine`
- Is it a performance related change? Please attach the performance test report.
`Bloom datamap can reduce blocklets in precise equal query scenario ann enhance the query performance`
- Any additional information to help reviewers in testing this change.
`NO`
- [x] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.
`Not related`
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/xuchuanyin/carbondata 0421_bloom_datamap
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/carbondata/pull/2200.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #2200
----
commit 160b0f42248fe719f898c10cb84ab2d32eafdaac
Author: xuchuanyin <xu...@...>
Date: 2018-04-21T02:59:04Z
Add bloom datamap using bloom filter
For each indexed column, adding a bloom filter for each blocklet to
indicate whether it belongs to this blocklet.
Currently bloom filter is using guava version.
----
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by xuchuanyin <gi...@git.apache.org>.
Github user xuchuanyin commented on the issue:
https://github.com/apache/carbondata/pull/2200
@jackylk All review comments have been fixed except this one: https://github.com/apache/carbondata/pull/2200#discussion_r183201359
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by xuchuanyin <gi...@git.apache.org>.
Github user xuchuanyin commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183201359
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMap.java ---
@@ -0,0 +1,243 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataInputStream;
+import java.io.EOFException;
+import java.io.IOException;
+import java.io.ObjectInputStream;
+import java.io.UnsupportedEncodingException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+
+import org.apache.carbondata.common.logging.LogService;
+import org.apache.carbondata.common.logging.LogServiceFactory;
+import org.apache.carbondata.core.datamap.dev.DataMapModel;
+import org.apache.carbondata.core.datamap.dev.cgdatamap.CoarseGrainDataMap;
+import org.apache.carbondata.core.datastore.block.SegmentProperties;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.indexstore.Blocklet;
+import org.apache.carbondata.core.indexstore.PartitionSpec;
+import org.apache.carbondata.core.memory.MemoryException;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.scan.expression.ColumnExpression;
+import org.apache.carbondata.core.scan.expression.Expression;
+import org.apache.carbondata.core.scan.expression.LiteralExpression;
+import org.apache.carbondata.core.scan.expression.conditional.EqualToExpression;
+import org.apache.carbondata.core.scan.filter.resolver.FilterResolverIntf;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.collect.ArrayListMultimap;
+import com.google.common.collect.Multimap;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.PathFilter;
+
+public class BloomCoarseGrainDataMap extends CoarseGrainDataMap {
+ private static final LogService LOGGER =
+ LogServiceFactory.getLogService(BloomCoarseGrainDataMap.class.getName());
+ private String[] indexFilePath;
+ private Set<String> indexedColumn;
+ private List<BloomDMModel> bloomIndexList;
+ private Multimap<String, List<BloomDMModel>> indexCol2BloomDMList;
+
+ @Override
+ public void init(DataMapModel dataMapModel) throws MemoryException, IOException {
+ Path indexPath = FileFactory.getPath(dataMapModel.getFilePath());
+ FileSystem fs = FileFactory.getFileSystem(indexPath);
+ if (!fs.exists(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap does not exist", indexPath));
+ }
+ if (!fs.isDirectory(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap must be a directory", indexPath));
+ }
+
+ FileStatus[] indexFileStatus = fs.listStatus(indexPath, new PathFilter() {
+ @Override public boolean accept(Path path) {
+ return path.getName().endsWith(".bloomindex");
+ }
+ });
+ indexFilePath = new String[indexFileStatus.length];
+ indexedColumn = new HashSet<String>();
+ bloomIndexList = new ArrayList<BloomDMModel>();
+ indexCol2BloomDMList = ArrayListMultimap.create();
+ for (int i = 0; i < indexFileStatus.length; i++) {
+ indexFilePath[i] = indexFileStatus[i].getPath().toString();
+ String indexCol = StringUtils.substringBetween(indexFilePath[i], ".carbondata.",
+ ".bloomindex");
+ indexedColumn.add(indexCol);
+ bloomIndexList.addAll(readBloomIndex(indexFilePath[i]));
+ indexCol2BloomDMList.put(indexCol, readBloomIndex(indexFilePath[i]));
+ }
+ LOGGER.info("find bloom index datamap for column: "
+ + StringUtils.join(indexedColumn, ", "));
+ }
+
+ private List<BloomDMModel> readBloomIndex(String indexFile) throws IOException {
+ LOGGER.info("read bloom index from file: " + indexFile);
+ List<BloomDMModel> bloomDMModelList = new ArrayList<BloomDMModel>();
+ DataInputStream dataInStream = null;
+ ObjectInputStream objectInStream = null;
+ try {
+ dataInStream = FileFactory.getDataInputStream(indexFile, FileFactory.getFileType(indexFile));
+ objectInStream = new ObjectInputStream(dataInStream);
+ try {
+ BloomDMModel model = null;
+ while ((model = (BloomDMModel) objectInStream.readObject()) != null) {
+ LOGGER.info("read bloom index: " + model);
+ bloomDMModelList.add(model);
+ }
+ } catch (EOFException e) {
+ LOGGER.info("read " + bloomDMModelList.size() + " bloom indices from " + indexFile);
+ }
+ return bloomDMModelList;
+ } catch (ClassNotFoundException e) {
+ LOGGER.error("Error occrus while reading bloom index");
+ throw new RuntimeException("Error occrus while reading bloom index", e);
+ } finally {
+ CarbonUtil.closeStreams(objectInStream, dataInStream);
+ }
+ }
+
+ @Override
+ public List<Blocklet> prune(FilterResolverIntf filterExp, SegmentProperties segmentProperties,
+ List<PartitionSpec> partitions) throws IOException {
+ List<Blocklet> hitBlocklets = new ArrayList<Blocklet>();
+ if (filterExp == null) {
+ return null;
--- End diff --
I learned it LuceneDataMap.
Besides, null and empty is not the same here. Empty means that we have pruned all the blocklets here, meaning there is no blocklet to scan later.
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Success with Spark 2.2.1, Please check CI http://88.99.58.216:8080/job/ApacheCarbonPRBuilder/4101/
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183199019
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMap.java ---
@@ -0,0 +1,243 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataInputStream;
+import java.io.EOFException;
+import java.io.IOException;
+import java.io.ObjectInputStream;
+import java.io.UnsupportedEncodingException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+
+import org.apache.carbondata.common.logging.LogService;
+import org.apache.carbondata.common.logging.LogServiceFactory;
+import org.apache.carbondata.core.datamap.dev.DataMapModel;
+import org.apache.carbondata.core.datamap.dev.cgdatamap.CoarseGrainDataMap;
+import org.apache.carbondata.core.datastore.block.SegmentProperties;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.indexstore.Blocklet;
+import org.apache.carbondata.core.indexstore.PartitionSpec;
+import org.apache.carbondata.core.memory.MemoryException;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.scan.expression.ColumnExpression;
+import org.apache.carbondata.core.scan.expression.Expression;
+import org.apache.carbondata.core.scan.expression.LiteralExpression;
+import org.apache.carbondata.core.scan.expression.conditional.EqualToExpression;
+import org.apache.carbondata.core.scan.filter.resolver.FilterResolverIntf;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.collect.ArrayListMultimap;
+import com.google.common.collect.Multimap;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.PathFilter;
+
+public class BloomCoarseGrainDataMap extends CoarseGrainDataMap {
--- End diff --
add @InterfaceAudience.Internal
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183199028
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMap.java ---
@@ -0,0 +1,243 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataInputStream;
+import java.io.EOFException;
+import java.io.IOException;
+import java.io.ObjectInputStream;
+import java.io.UnsupportedEncodingException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+
+import org.apache.carbondata.common.logging.LogService;
+import org.apache.carbondata.common.logging.LogServiceFactory;
+import org.apache.carbondata.core.datamap.dev.DataMapModel;
+import org.apache.carbondata.core.datamap.dev.cgdatamap.CoarseGrainDataMap;
+import org.apache.carbondata.core.datastore.block.SegmentProperties;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.indexstore.Blocklet;
+import org.apache.carbondata.core.indexstore.PartitionSpec;
+import org.apache.carbondata.core.memory.MemoryException;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.scan.expression.ColumnExpression;
+import org.apache.carbondata.core.scan.expression.Expression;
+import org.apache.carbondata.core.scan.expression.LiteralExpression;
+import org.apache.carbondata.core.scan.expression.conditional.EqualToExpression;
+import org.apache.carbondata.core.scan.filter.resolver.FilterResolverIntf;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.collect.ArrayListMultimap;
+import com.google.common.collect.Multimap;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.PathFilter;
+
+public class BloomCoarseGrainDataMap extends CoarseGrainDataMap {
+ private static final LogService LOGGER =
+ LogServiceFactory.getLogService(BloomCoarseGrainDataMap.class.getName());
+ private String[] indexFilePath;
+ private Set<String> indexedColumn;
+ private List<BloomDMModel> bloomIndexList;
+ private Multimap<String, List<BloomDMModel>> indexCol2BloomDMList;
+
+ @Override
+ public void init(DataMapModel dataMapModel) throws MemoryException, IOException {
+ Path indexPath = FileFactory.getPath(dataMapModel.getFilePath());
+ FileSystem fs = FileFactory.getFileSystem(indexPath);
+ if (!fs.exists(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap does not exist", indexPath));
+ }
+ if (!fs.isDirectory(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap must be a directory", indexPath));
+ }
+
+ FileStatus[] indexFileStatus = fs.listStatus(indexPath, new PathFilter() {
+ @Override public boolean accept(Path path) {
+ return path.getName().endsWith(".bloomindex");
--- End diff --
make a constant string for `.bloomindex`
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183210742
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
+ private String dataMapName;
+ private List<String> indexedColumns;
+ // map column name to ordinal in pages
+ private Map<String, Integer> col2Ordianl;
+ private Map<String, DataType> col2DataType;
+ private String currentBlockId;
+ private int currentBlockletId;
+ private List<String> currentDMFiles;
+ private List<DataOutputStream> currentDataOutStreams;
+ private List<ObjectOutputStream> currentObjectOutStreams;
+ private List<BloomFilter<byte[]>> indexBloomFilters;
+
+ public BloomDataMapWriter(AbsoluteTableIdentifier identifier, DataMapMeta dataMapMeta,
--- End diff --
Add @InterfaceAudience
And can you add description for:
1. BloomFilter is constructed in what level? page, blocklet, block?
2. bloomindex is written one file for one block, or one file for one write task?
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Success with Spark 2.2.1, Please check CI http://88.99.58.216:8080/job/ApacheCarbonPRBuilder/4088/
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183199149
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMapFactory.java ---
@@ -0,0 +1,192 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.File;
+import java.io.IOException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Objects;
+import java.util.Set;
+
+import org.apache.carbondata.common.exceptions.sql.MalformedDataMapCommandException;
+import org.apache.carbondata.common.logging.LogService;
+import org.apache.carbondata.common.logging.LogServiceFactory;
+import org.apache.carbondata.core.datamap.DataMapDistributable;
+import org.apache.carbondata.core.datamap.DataMapLevel;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapFactory;
+import org.apache.carbondata.core.datamap.dev.DataMapModel;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datamap.dev.cgdatamap.CoarseGrainDataMap;
+import org.apache.carbondata.core.datastore.filesystem.CarbonFile;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.memory.MemoryException;
+import org.apache.carbondata.core.metadata.CarbonMetadata;
+import org.apache.carbondata.core.metadata.schema.table.CarbonTable;
+import org.apache.carbondata.core.metadata.schema.table.DataMapSchema;
+import org.apache.carbondata.core.metadata.schema.table.column.CarbonColumn;
+import org.apache.carbondata.core.readcommitter.ReadCommittedScope;
+import org.apache.carbondata.core.scan.filter.intf.ExpressionType;
+import org.apache.carbondata.core.statusmanager.SegmentStatusManager;
+import org.apache.carbondata.core.util.CarbonUtil;
+import org.apache.carbondata.core.util.path.CarbonTablePath;
+import org.apache.carbondata.events.Event;
+
+import org.apache.commons.lang3.StringUtils;
+
+public class BloomCoarseGrainDataMapFactory implements DataMapFactory<CoarseGrainDataMap> {
--- End diff --
add @InterfaceAudience.Internal
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by xuchuanyin <gi...@git.apache.org>.
Github user xuchuanyin commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183211712
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
+ private String dataMapName;
+ private List<String> indexedColumns;
+ // map column name to ordinal in pages
+ private Map<String, Integer> col2Ordianl;
+ private Map<String, DataType> col2DataType;
+ private String currentBlockId;
+ private int currentBlockletId;
+ private List<String> currentDMFiles;
+ private List<DataOutputStream> currentDataOutStreams;
+ private List<ObjectOutputStream> currentObjectOutStreams;
+ private List<BloomFilter<byte[]>> indexBloomFilters;
+
+ public BloomDataMapWriter(AbsoluteTableIdentifier identifier, DataMapMeta dataMapMeta,
+ Segment segment, String writeDirectoryPath) {
+ super(identifier, segment, writeDirectoryPath);
+ dataMapName = dataMapMeta.getDataMapName();
+ indexedColumns = dataMapMeta.getIndexedColumns();
+ col2Ordianl = new HashMap<String, Integer>(indexedColumns.size());
+ col2DataType = new HashMap<String, DataType>(indexedColumns.size());
+
+ currentDMFiles = new ArrayList<String>(indexedColumns.size());
+ currentDataOutStreams = new ArrayList<DataOutputStream>(indexedColumns.size());
+ currentObjectOutStreams = new ArrayList<ObjectOutputStream>(indexedColumns.size());
+
+ indexBloomFilters = new ArrayList<BloomFilter<byte[]>>(indexedColumns.size());
+ }
+
+ @Override
+ public void onBlockStart(String blockId, long taskId) throws IOException {
+ this.currentBlockId = blockId;
+ this.currentBlockletId = 0;
+ currentDMFiles.clear();
+ currentDataOutStreams.clear();
+ currentObjectOutStreams.clear();
+ initDataMapFile();
+ }
+
+ @Override
+ public void onBlockEnd(String blockId) throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ CarbonUtil.closeStreams(this.currentDataOutStreams.get(indexColId),
+ this.currentObjectOutStreams.get(indexColId));
+ commitFile(this.currentDMFiles.get(indexColId));
+ }
+ }
+
+ @Override public void onBlockletStart(int blockletId) {
+ this.currentBlockletId = blockletId;
+ indexBloomFilters.clear();
+ for (int i = 0; i < indexedColumns.size(); i++) {
+ indexBloomFilters.add(BloomFilter.create(Funnels.byteArrayFunnel(),
+ BLOOM_FILTER_SIZE, 0.00001d));
+ }
+ }
+
+ @Override
+ public void onBlockletEnd(int blockletId) {
+ try {
+ writeBloomDataMapFile();
+ } catch (Exception e) {
+ for (ObjectOutputStream objectOutputStream : currentObjectOutStreams) {
+ CarbonUtil.closeStreams(objectOutputStream);
+ }
+ for (DataOutputStream dataOutputStream : currentDataOutStreams) {
+ CarbonUtil.closeStreams(dataOutputStream);
+ }
+ throw new RuntimeException(e);
+ }
+ }
+
+ @Override public void onPageAdded(int blockletId, int pageId, ColumnPage[] pages)
+ throws IOException {
+ col2Ordianl.clear();
+ col2DataType.clear();
+ for (int colId = 0; colId < pages.length; colId++) {
+ String columnName = pages[colId].getColumnSpec().getFieldName().toLowerCase();
+ if (indexedColumns.contains(columnName)) {
+ col2Ordianl.put(columnName, colId);
+ DataType columnType = pages[colId].getColumnSpec().getSchemaDataType();
+ col2DataType.put(columnName, columnType);
+ }
+ }
+
+ // for each row
+ for (int rowId = 0; rowId < pages[0].getPageSize(); rowId++) {
+ // for each indexed column
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ String indexedCol = indexedColumns.get(indexColId);
+ byte[] indexValue;
+ if (DataTypes.STRING == col2DataType.get(indexedCol)
+ || DataTypes.BYTE_ARRAY == col2DataType.get(indexedCol)) {
+ byte[] originValue = (byte[]) pages[col2Ordianl.get(indexedCol)].getData(rowId);
+ indexValue = new byte[originValue.length - 2];
+ System.arraycopy(originValue, 2, indexValue, 0, originValue.length - 2);
+ } else {
+ Object originValue = pages[col2Ordianl.get(indexedCol)].getData(rowId);
+ indexValue = CarbonUtil.getValueAsBytes(col2DataType.get(indexedCol), originValue);
+ }
+
+ indexBloomFilters.get(indexColId).put(indexValue);
+ }
+ }
+ }
+
+ private void initDataMapFile() throws IOException {
+ String dataMapDir = genDataMapStorePath(this.writeDirectoryPath, this.dataMapName);
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ String dmFile = dataMapDir + File.separator + this.currentBlockId
+ + '.' + indexedColumns.get(indexColId) + BloomCoarseGrainDataMap.BLOOM_INDEX_SUFFIX;
+ DataOutputStream dataOutStream = null;
+ ObjectOutputStream objectOutStream = null;
+ try {
+ FileFactory.createNewFile(dmFile, FileFactory.getFileType(dmFile));
+ dataOutStream = FileFactory.getDataOutputStream(dmFile,
+ FileFactory.getFileType(dmFile));
+ objectOutStream = new ObjectOutputStream(dataOutStream);
+ } catch (IOException e) {
+ CarbonUtil.closeStreams(objectOutStream, dataOutStream);
+ throw new IOException(e);
+ }
+
+ this.currentDMFiles.add(dmFile);
+ this.currentDataOutStreams.add(dataOutStream);
+ this.currentObjectOutStreams.add(objectOutStream);
+ }
+ }
+
+ private void writeBloomDataMapFile() throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ BloomDMModel model = new BloomDMModel(this.currentBlockId, this.currentBlockletId,
+ indexBloomFilters.get(indexColId));
+ // only in higher version of guava-bloom-filter, it provides readFrom/writeTo interface.
--- End diff --
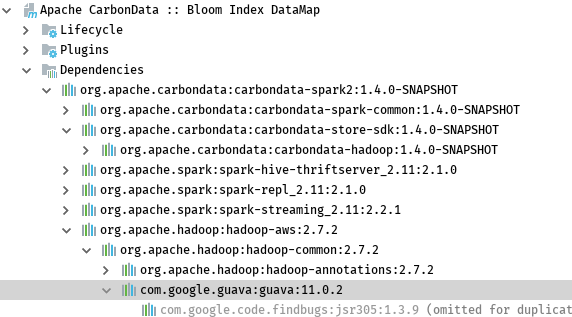
As shown above, hadoop-common use 11.0.2 version of guava. I've checked the interface of readFrom/writeTo of the bloomfilter provided by guava, it needs 24.* version. See https://github.com/google/guava/commit/62d17005a48e9b1044f1ed2d5de8905426d75299#diff-223d254389aa08fae7876742f8f07e8c for detailed information.
Since hadoop-common rely on this package, So I not going to replace it.
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183210634
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
+ private String dataMapName;
+ private List<String> indexedColumns;
+ // map column name to ordinal in pages
+ private Map<String, Integer> col2Ordianl;
+ private Map<String, DataType> col2DataType;
+ private String currentBlockId;
+ private int currentBlockletId;
+ private List<String> currentDMFiles;
+ private List<DataOutputStream> currentDataOutStreams;
+ private List<ObjectOutputStream> currentObjectOutStreams;
+ private List<BloomFilter<byte[]>> indexBloomFilters;
+
+ public BloomDataMapWriter(AbsoluteTableIdentifier identifier, DataMapMeta dataMapMeta,
+ Segment segment, String writeDirectoryPath) {
+ super(identifier, segment, writeDirectoryPath);
+ dataMapName = dataMapMeta.getDataMapName();
+ indexedColumns = dataMapMeta.getIndexedColumns();
+ col2Ordianl = new HashMap<String, Integer>(indexedColumns.size());
+ col2DataType = new HashMap<String, DataType>(indexedColumns.size());
+
+ currentDMFiles = new ArrayList<String>(indexedColumns.size());
+ currentDataOutStreams = new ArrayList<DataOutputStream>(indexedColumns.size());
+ currentObjectOutStreams = new ArrayList<ObjectOutputStream>(indexedColumns.size());
+
+ indexBloomFilters = new ArrayList<BloomFilter<byte[]>>(indexedColumns.size());
+ }
+
+ @Override
+ public void onBlockStart(String blockId, long taskId) throws IOException {
+ this.currentBlockId = blockId;
+ this.currentBlockletId = 0;
+ currentDMFiles.clear();
+ currentDataOutStreams.clear();
+ currentObjectOutStreams.clear();
+ initDataMapFile();
+ }
+
+ @Override
+ public void onBlockEnd(String blockId) throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ CarbonUtil.closeStreams(this.currentDataOutStreams.get(indexColId),
+ this.currentObjectOutStreams.get(indexColId));
+ commitFile(this.currentDMFiles.get(indexColId));
+ }
+ }
+
+ @Override public void onBlockletStart(int blockletId) {
--- End diff --
move @Override to previous line
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183210908
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
+ private String dataMapName;
+ private List<String> indexedColumns;
+ // map column name to ordinal in pages
+ private Map<String, Integer> col2Ordianl;
+ private Map<String, DataType> col2DataType;
+ private String currentBlockId;
+ private int currentBlockletId;
+ private List<String> currentDMFiles;
+ private List<DataOutputStream> currentDataOutStreams;
+ private List<ObjectOutputStream> currentObjectOutStreams;
+ private List<BloomFilter<byte[]>> indexBloomFilters;
+
+ public BloomDataMapWriter(AbsoluteTableIdentifier identifier, DataMapMeta dataMapMeta,
+ Segment segment, String writeDirectoryPath) {
+ super(identifier, segment, writeDirectoryPath);
+ dataMapName = dataMapMeta.getDataMapName();
+ indexedColumns = dataMapMeta.getIndexedColumns();
+ col2Ordianl = new HashMap<String, Integer>(indexedColumns.size());
+ col2DataType = new HashMap<String, DataType>(indexedColumns.size());
+
+ currentDMFiles = new ArrayList<String>(indexedColumns.size());
+ currentDataOutStreams = new ArrayList<DataOutputStream>(indexedColumns.size());
+ currentObjectOutStreams = new ArrayList<ObjectOutputStream>(indexedColumns.size());
+
+ indexBloomFilters = new ArrayList<BloomFilter<byte[]>>(indexedColumns.size());
+ }
+
+ @Override
+ public void onBlockStart(String blockId, long taskId) throws IOException {
+ this.currentBlockId = blockId;
+ this.currentBlockletId = 0;
+ currentDMFiles.clear();
+ currentDataOutStreams.clear();
+ currentObjectOutStreams.clear();
+ initDataMapFile();
+ }
+
+ @Override
+ public void onBlockEnd(String blockId) throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ CarbonUtil.closeStreams(this.currentDataOutStreams.get(indexColId),
+ this.currentObjectOutStreams.get(indexColId));
+ commitFile(this.currentDMFiles.get(indexColId));
+ }
+ }
+
+ @Override public void onBlockletStart(int blockletId) {
+ this.currentBlockletId = blockletId;
+ indexBloomFilters.clear();
+ for (int i = 0; i < indexedColumns.size(); i++) {
+ indexBloomFilters.add(BloomFilter.create(Funnels.byteArrayFunnel(),
+ BLOOM_FILTER_SIZE, 0.00001d));
+ }
+ }
+
+ @Override
+ public void onBlockletEnd(int blockletId) {
+ try {
+ writeBloomDataMapFile();
+ } catch (Exception e) {
+ for (ObjectOutputStream objectOutputStream : currentObjectOutStreams) {
+ CarbonUtil.closeStreams(objectOutputStream);
+ }
+ for (DataOutputStream dataOutputStream : currentDataOutStreams) {
+ CarbonUtil.closeStreams(dataOutputStream);
+ }
+ throw new RuntimeException(e);
+ }
+ }
+
+ @Override public void onPageAdded(int blockletId, int pageId, ColumnPage[] pages)
+ throws IOException {
+ col2Ordianl.clear();
+ col2DataType.clear();
+ for (int colId = 0; colId < pages.length; colId++) {
+ String columnName = pages[colId].getColumnSpec().getFieldName().toLowerCase();
+ if (indexedColumns.contains(columnName)) {
--- End diff --
This is not needed. The input `pages` contains the indexed column only
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by xuchuanyin <gi...@git.apache.org>.
Github user xuchuanyin commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183211728
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
--- End diff --
Yeah, it is used to control the rate. I'll make a default value for this.
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Success with Spark 2.2.1, Please check CI http://88.99.58.216:8080/job/ApacheCarbonPRBuilder/4100/
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183199053
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMap.java ---
@@ -0,0 +1,243 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataInputStream;
+import java.io.EOFException;
+import java.io.IOException;
+import java.io.ObjectInputStream;
+import java.io.UnsupportedEncodingException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+
+import org.apache.carbondata.common.logging.LogService;
+import org.apache.carbondata.common.logging.LogServiceFactory;
+import org.apache.carbondata.core.datamap.dev.DataMapModel;
+import org.apache.carbondata.core.datamap.dev.cgdatamap.CoarseGrainDataMap;
+import org.apache.carbondata.core.datastore.block.SegmentProperties;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.indexstore.Blocklet;
+import org.apache.carbondata.core.indexstore.PartitionSpec;
+import org.apache.carbondata.core.memory.MemoryException;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.scan.expression.ColumnExpression;
+import org.apache.carbondata.core.scan.expression.Expression;
+import org.apache.carbondata.core.scan.expression.LiteralExpression;
+import org.apache.carbondata.core.scan.expression.conditional.EqualToExpression;
+import org.apache.carbondata.core.scan.filter.resolver.FilterResolverIntf;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.collect.ArrayListMultimap;
+import com.google.common.collect.Multimap;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.PathFilter;
+
+public class BloomCoarseGrainDataMap extends CoarseGrainDataMap {
+ private static final LogService LOGGER =
+ LogServiceFactory.getLogService(BloomCoarseGrainDataMap.class.getName());
+ private String[] indexFilePath;
+ private Set<String> indexedColumn;
+ private List<BloomDMModel> bloomIndexList;
+ private Multimap<String, List<BloomDMModel>> indexCol2BloomDMList;
+
+ @Override
+ public void init(DataMapModel dataMapModel) throws MemoryException, IOException {
+ Path indexPath = FileFactory.getPath(dataMapModel.getFilePath());
+ FileSystem fs = FileFactory.getFileSystem(indexPath);
+ if (!fs.exists(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap does not exist", indexPath));
+ }
+ if (!fs.isDirectory(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap must be a directory", indexPath));
+ }
+
+ FileStatus[] indexFileStatus = fs.listStatus(indexPath, new PathFilter() {
+ @Override public boolean accept(Path path) {
+ return path.getName().endsWith(".bloomindex");
+ }
+ });
+ indexFilePath = new String[indexFileStatus.length];
+ indexedColumn = new HashSet<String>();
+ bloomIndexList = new ArrayList<BloomDMModel>();
+ indexCol2BloomDMList = ArrayListMultimap.create();
+ for (int i = 0; i < indexFileStatus.length; i++) {
+ indexFilePath[i] = indexFileStatus[i].getPath().toString();
+ String indexCol = StringUtils.substringBetween(indexFilePath[i], ".carbondata.",
+ ".bloomindex");
+ indexedColumn.add(indexCol);
+ bloomIndexList.addAll(readBloomIndex(indexFilePath[i]));
+ indexCol2BloomDMList.put(indexCol, readBloomIndex(indexFilePath[i]));
+ }
+ LOGGER.info("find bloom index datamap for column: "
+ + StringUtils.join(indexedColumn, ", "));
+ }
+
+ private List<BloomDMModel> readBloomIndex(String indexFile) throws IOException {
+ LOGGER.info("read bloom index from file: " + indexFile);
+ List<BloomDMModel> bloomDMModelList = new ArrayList<BloomDMModel>();
+ DataInputStream dataInStream = null;
+ ObjectInputStream objectInStream = null;
+ try {
+ dataInStream = FileFactory.getDataInputStream(indexFile, FileFactory.getFileType(indexFile));
+ objectInStream = new ObjectInputStream(dataInStream);
+ try {
+ BloomDMModel model = null;
+ while ((model = (BloomDMModel) objectInStream.readObject()) != null) {
+ LOGGER.info("read bloom index: " + model);
+ bloomDMModelList.add(model);
+ }
+ } catch (EOFException e) {
+ LOGGER.info("read " + bloomDMModelList.size() + " bloom indices from " + indexFile);
+ }
+ return bloomDMModelList;
+ } catch (ClassNotFoundException e) {
+ LOGGER.error("Error occrus while reading bloom index");
+ throw new RuntimeException("Error occrus while reading bloom index", e);
+ } finally {
+ CarbonUtil.closeStreams(objectInStream, dataInStream);
+ }
+ }
+
+ @Override
+ public List<Blocklet> prune(FilterResolverIntf filterExp, SegmentProperties segmentProperties,
+ List<PartitionSpec> partitions) throws IOException {
+ List<Blocklet> hitBlocklets = new ArrayList<Blocklet>();
+ if (filterExp == null) {
+ return null;
--- End diff --
better to return an empty list
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by xuchuanyin <gi...@git.apache.org>.
Github user xuchuanyin commented on the issue:
https://github.com/apache/carbondata/pull/2200
@jackylk review comments are fixed. Add a dm_property called ‘bloom_size’ to configure the size of bloom filter.
Since we can have multiple indexed columns and the cardinality of them are differs, so we can support specifying corresponding bloom_size in the future.
Besides, more tests are needed, such as exception, datamap profiling for this datamap -- will do it in the future, this version will provide the basic correct test case.
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183210621
--- Diff: datamap/bloom/src/test/scala/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMapSuite.scala ---
@@ -0,0 +1,123 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.datamap.bloom
+
+import java.io.{File, PrintWriter}
+import java.util.UUID
+
+import scala.util.Random
+
+import org.apache.spark.sql.Row
+import org.apache.spark.sql.test.util.QueryTest
+import org.scalatest.BeforeAndAfterAll
+
+class BloomCoarseGrainDataMapSuite extends QueryTest with BeforeAndAfterAll {
+ val inputFile = s"$resourcesPath/bloom_datamap_input.csv"
+ val normalTable = "carbon_normal"
+ val bloomDMSampleTable = "carbon_bloom"
+ val dataMapName = "bloom_dm"
+ val lineNum = 500000
+
+ override protected def beforeAll(): Unit = {
+ createFile(inputFile, line = lineNum, start = 0)
+ sql(s"DROP TABLE IF EXISTS $normalTable")
+ sql(s"DROP TABLE IF EXISTS $bloomDMSampleTable")
+ }
+
+ test("test bloom datamap") {
+ sql(
+ s"""
+ | CREATE TABLE $normalTable(id INT, name STRING, city STRING, age INT,
+ | s1 STRING, s2 STRING, s3 STRING, s4 STRING, s5 STRING, s6 STRING, s7 STRING, s8 STRING)
+ | STORED BY 'carbondata' TBLPROPERTIES('table_blocksize'='128')
+ | """.stripMargin)
+ sql(
+ s"""
+ | CREATE TABLE $bloomDMSampleTable(id INT, name STRING, city STRING, age INT,
+ | s1 STRING, s2 STRING, s3 STRING, s4 STRING, s5 STRING, s6 STRING, s7 STRING, s8 STRING)
+ | STORED BY 'carbondata' TBLPROPERTIES('table_blocksize'='128')
+ | """.stripMargin)
+ sql(
+ s"""
+ | CREATE DATAMAP $dataMapName ON TABLE $bloomDMSampleTable
+ | USING '${classOf[BloomCoarseGrainDataMapFactory].getName}'
+ | DMProperties('BLOOM_COLUMNS'='city,id')
+ """.stripMargin)
+
+ sql(
+ s"""
+ | LOAD DATA LOCAL INPATH '$inputFile' INTO TABLE $normalTable
+ | OPTIONS('header'='false')
+ """.stripMargin)
+ sql(
+ s"""
+ | LOAD DATA LOCAL INPATH '$inputFile' INTO TABLE $bloomDMSampleTable
+ | OPTIONS('header'='false')
+ """.stripMargin)
+
+ sql(s"show datamap on table $bloomDMSampleTable").show(false)
+ sql(s"select * from $bloomDMSampleTable where city = 'city_5'").show(false)
--- End diff --
can you also assert the bloom index file is created in the file system?
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183210997
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
+ private String dataMapName;
+ private List<String> indexedColumns;
+ // map column name to ordinal in pages
+ private Map<String, Integer> col2Ordianl;
+ private Map<String, DataType> col2DataType;
+ private String currentBlockId;
+ private int currentBlockletId;
+ private List<String> currentDMFiles;
+ private List<DataOutputStream> currentDataOutStreams;
+ private List<ObjectOutputStream> currentObjectOutStreams;
+ private List<BloomFilter<byte[]>> indexBloomFilters;
+
+ public BloomDataMapWriter(AbsoluteTableIdentifier identifier, DataMapMeta dataMapMeta,
+ Segment segment, String writeDirectoryPath) {
+ super(identifier, segment, writeDirectoryPath);
+ dataMapName = dataMapMeta.getDataMapName();
+ indexedColumns = dataMapMeta.getIndexedColumns();
+ col2Ordianl = new HashMap<String, Integer>(indexedColumns.size());
+ col2DataType = new HashMap<String, DataType>(indexedColumns.size());
+
+ currentDMFiles = new ArrayList<String>(indexedColumns.size());
+ currentDataOutStreams = new ArrayList<DataOutputStream>(indexedColumns.size());
+ currentObjectOutStreams = new ArrayList<ObjectOutputStream>(indexedColumns.size());
+
+ indexBloomFilters = new ArrayList<BloomFilter<byte[]>>(indexedColumns.size());
+ }
+
+ @Override
+ public void onBlockStart(String blockId, long taskId) throws IOException {
+ this.currentBlockId = blockId;
+ this.currentBlockletId = 0;
+ currentDMFiles.clear();
+ currentDataOutStreams.clear();
+ currentObjectOutStreams.clear();
+ initDataMapFile();
+ }
+
+ @Override
+ public void onBlockEnd(String blockId) throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ CarbonUtil.closeStreams(this.currentDataOutStreams.get(indexColId),
+ this.currentObjectOutStreams.get(indexColId));
+ commitFile(this.currentDMFiles.get(indexColId));
+ }
+ }
+
+ @Override public void onBlockletStart(int blockletId) {
+ this.currentBlockletId = blockletId;
+ indexBloomFilters.clear();
+ for (int i = 0; i < indexedColumns.size(); i++) {
+ indexBloomFilters.add(BloomFilter.create(Funnels.byteArrayFunnel(),
+ BLOOM_FILTER_SIZE, 0.00001d));
+ }
+ }
+
+ @Override
+ public void onBlockletEnd(int blockletId) {
+ try {
+ writeBloomDataMapFile();
+ } catch (Exception e) {
+ for (ObjectOutputStream objectOutputStream : currentObjectOutStreams) {
+ CarbonUtil.closeStreams(objectOutputStream);
+ }
+ for (DataOutputStream dataOutputStream : currentDataOutStreams) {
+ CarbonUtil.closeStreams(dataOutputStream);
+ }
+ throw new RuntimeException(e);
+ }
+ }
+
+ @Override public void onPageAdded(int blockletId, int pageId, ColumnPage[] pages)
+ throws IOException {
+ col2Ordianl.clear();
+ col2DataType.clear();
+ for (int colId = 0; colId < pages.length; colId++) {
+ String columnName = pages[colId].getColumnSpec().getFieldName().toLowerCase();
+ if (indexedColumns.contains(columnName)) {
+ col2Ordianl.put(columnName, colId);
+ DataType columnType = pages[colId].getColumnSpec().getSchemaDataType();
+ col2DataType.put(columnName, columnType);
+ }
+ }
+
+ // for each row
+ for (int rowId = 0; rowId < pages[0].getPageSize(); rowId++) {
+ // for each indexed column
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ String indexedCol = indexedColumns.get(indexColId);
+ byte[] indexValue;
+ if (DataTypes.STRING == col2DataType.get(indexedCol)
+ || DataTypes.BYTE_ARRAY == col2DataType.get(indexedCol)) {
+ byte[] originValue = (byte[]) pages[col2Ordianl.get(indexedCol)].getData(rowId);
+ indexValue = new byte[originValue.length - 2];
+ System.arraycopy(originValue, 2, indexValue, 0, originValue.length - 2);
+ } else {
+ Object originValue = pages[col2Ordianl.get(indexedCol)].getData(rowId);
+ indexValue = CarbonUtil.getValueAsBytes(col2DataType.get(indexedCol), originValue);
+ }
+
+ indexBloomFilters.get(indexColId).put(indexValue);
+ }
+ }
+ }
+
+ private void initDataMapFile() throws IOException {
+ String dataMapDir = genDataMapStorePath(this.writeDirectoryPath, this.dataMapName);
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ String dmFile = dataMapDir + File.separator + this.currentBlockId
+ + '.' + indexedColumns.get(indexColId) + BloomCoarseGrainDataMap.BLOOM_INDEX_SUFFIX;
+ DataOutputStream dataOutStream = null;
+ ObjectOutputStream objectOutStream = null;
+ try {
+ FileFactory.createNewFile(dmFile, FileFactory.getFileType(dmFile));
+ dataOutStream = FileFactory.getDataOutputStream(dmFile,
+ FileFactory.getFileType(dmFile));
+ objectOutStream = new ObjectOutputStream(dataOutStream);
+ } catch (IOException e) {
+ CarbonUtil.closeStreams(objectOutStream, dataOutStream);
+ throw new IOException(e);
+ }
+
+ this.currentDMFiles.add(dmFile);
+ this.currentDataOutStreams.add(dataOutStream);
+ this.currentObjectOutStreams.add(objectOutStream);
+ }
+ }
+
+ private void writeBloomDataMapFile() throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ BloomDMModel model = new BloomDMModel(this.currentBlockId, this.currentBlockletId,
+ indexBloomFilters.get(indexColId));
+ // only in higher version of guava-bloom-filter, it provides readFrom/writeTo interface.
--- End diff --
why we can not use higher version of guava? which component prevents us from introduce higher version? which version?
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder1/5269/
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Success with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder1/5281/
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183210637
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
+ private String dataMapName;
+ private List<String> indexedColumns;
+ // map column name to ordinal in pages
+ private Map<String, Integer> col2Ordianl;
+ private Map<String, DataType> col2DataType;
+ private String currentBlockId;
+ private int currentBlockletId;
+ private List<String> currentDMFiles;
+ private List<DataOutputStream> currentDataOutStreams;
+ private List<ObjectOutputStream> currentObjectOutStreams;
+ private List<BloomFilter<byte[]>> indexBloomFilters;
+
+ public BloomDataMapWriter(AbsoluteTableIdentifier identifier, DataMapMeta dataMapMeta,
+ Segment segment, String writeDirectoryPath) {
+ super(identifier, segment, writeDirectoryPath);
+ dataMapName = dataMapMeta.getDataMapName();
+ indexedColumns = dataMapMeta.getIndexedColumns();
+ col2Ordianl = new HashMap<String, Integer>(indexedColumns.size());
+ col2DataType = new HashMap<String, DataType>(indexedColumns.size());
+
+ currentDMFiles = new ArrayList<String>(indexedColumns.size());
+ currentDataOutStreams = new ArrayList<DataOutputStream>(indexedColumns.size());
+ currentObjectOutStreams = new ArrayList<ObjectOutputStream>(indexedColumns.size());
+
+ indexBloomFilters = new ArrayList<BloomFilter<byte[]>>(indexedColumns.size());
+ }
+
+ @Override
+ public void onBlockStart(String blockId, long taskId) throws IOException {
+ this.currentBlockId = blockId;
+ this.currentBlockletId = 0;
+ currentDMFiles.clear();
+ currentDataOutStreams.clear();
+ currentObjectOutStreams.clear();
+ initDataMapFile();
+ }
+
+ @Override
+ public void onBlockEnd(String blockId) throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ CarbonUtil.closeStreams(this.currentDataOutStreams.get(indexColId),
+ this.currentObjectOutStreams.get(indexColId));
+ commitFile(this.currentDMFiles.get(indexColId));
+ }
+ }
+
+ @Override public void onBlockletStart(int blockletId) {
+ this.currentBlockletId = blockletId;
+ indexBloomFilters.clear();
+ for (int i = 0; i < indexedColumns.size(); i++) {
+ indexBloomFilters.add(BloomFilter.create(Funnels.byteArrayFunnel(),
+ BLOOM_FILTER_SIZE, 0.00001d));
+ }
+ }
+
+ @Override
+ public void onBlockletEnd(int blockletId) {
+ try {
+ writeBloomDataMapFile();
+ } catch (Exception e) {
+ for (ObjectOutputStream objectOutputStream : currentObjectOutStreams) {
+ CarbonUtil.closeStreams(objectOutputStream);
+ }
+ for (DataOutputStream dataOutputStream : currentDataOutStreams) {
+ CarbonUtil.closeStreams(dataOutputStream);
+ }
+ throw new RuntimeException(e);
+ }
+ }
+
+ @Override public void onPageAdded(int blockletId, int pageId, ColumnPage[] pages)
--- End diff --
move @override to previous line
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183198993
--- Diff: datamap/bloom/pom.xml ---
@@ -0,0 +1,88 @@
+<project xmlns="http://maven.apache.org/POM/4.0.0"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <modelVersion>4.0.0</modelVersion>
+
+ <parent>
+ <groupId>org.apache.carbondata</groupId>
+ <artifactId>carbondata-parent</artifactId>
+ <version>1.4.0-SNAPSHOT</version>
+ <relativePath>../../pom.xml</relativePath>
+ </parent>
+
+ <artifactId>carbondata-bloom</artifactId>
+ <name>Apache CarbonData :: Bloom Index DataMap</name>
+
+ <properties>
+ <dev.path>${basedir}/../../dev</dev.path>
+ <lucene.version>6.3.0</lucene.version>
+ <solr.version>6.3.0</solr.version>
+ </properties>
+
+ <dependencies>
+ <dependency>
+ <groupId>org.apache.carbondata</groupId>
+ <artifactId>carbondata-spark2</artifactId>
+ <version>${project.version}</version>
+ </dependency>
+ <dependency>
+ <groupId>org.apache.commons</groupId>
+ <artifactId>commons-lang3</artifactId>
+ <version>3.3.2</version>
--- End diff --
can you move this version definition to parent pom
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183211031
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
--- End diff --
Can you make one DMPROPERTY for it? Is it control the bloom filter size?
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/carbondata/pull/2200
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183203455
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMap.java ---
@@ -0,0 +1,243 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataInputStream;
+import java.io.EOFException;
+import java.io.IOException;
+import java.io.ObjectInputStream;
+import java.io.UnsupportedEncodingException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+
+import org.apache.carbondata.common.logging.LogService;
+import org.apache.carbondata.common.logging.LogServiceFactory;
+import org.apache.carbondata.core.datamap.dev.DataMapModel;
+import org.apache.carbondata.core.datamap.dev.cgdatamap.CoarseGrainDataMap;
+import org.apache.carbondata.core.datastore.block.SegmentProperties;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.indexstore.Blocklet;
+import org.apache.carbondata.core.indexstore.PartitionSpec;
+import org.apache.carbondata.core.memory.MemoryException;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.scan.expression.ColumnExpression;
+import org.apache.carbondata.core.scan.expression.Expression;
+import org.apache.carbondata.core.scan.expression.LiteralExpression;
+import org.apache.carbondata.core.scan.expression.conditional.EqualToExpression;
+import org.apache.carbondata.core.scan.filter.resolver.FilterResolverIntf;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.collect.ArrayListMultimap;
+import com.google.common.collect.Multimap;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.PathFilter;
+
+public class BloomCoarseGrainDataMap extends CoarseGrainDataMap {
+ private static final LogService LOGGER =
+ LogServiceFactory.getLogService(BloomCoarseGrainDataMap.class.getName());
+ private String[] indexFilePath;
+ private Set<String> indexedColumn;
+ private List<BloomDMModel> bloomIndexList;
+ private Multimap<String, List<BloomDMModel>> indexCol2BloomDMList;
+
+ @Override
+ public void init(DataMapModel dataMapModel) throws MemoryException, IOException {
+ Path indexPath = FileFactory.getPath(dataMapModel.getFilePath());
+ FileSystem fs = FileFactory.getFileSystem(indexPath);
+ if (!fs.exists(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap does not exist", indexPath));
+ }
+ if (!fs.isDirectory(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap must be a directory", indexPath));
+ }
+
+ FileStatus[] indexFileStatus = fs.listStatus(indexPath, new PathFilter() {
+ @Override public boolean accept(Path path) {
+ return path.getName().endsWith(".bloomindex");
+ }
+ });
+ indexFilePath = new String[indexFileStatus.length];
+ indexedColumn = new HashSet<String>();
+ bloomIndexList = new ArrayList<BloomDMModel>();
+ indexCol2BloomDMList = ArrayListMultimap.create();
+ for (int i = 0; i < indexFileStatus.length; i++) {
+ indexFilePath[i] = indexFileStatus[i].getPath().toString();
+ String indexCol = StringUtils.substringBetween(indexFilePath[i], ".carbondata.",
+ ".bloomindex");
+ indexedColumn.add(indexCol);
+ bloomIndexList.addAll(readBloomIndex(indexFilePath[i]));
+ indexCol2BloomDMList.put(indexCol, readBloomIndex(indexFilePath[i]));
+ }
+ LOGGER.info("find bloom index datamap for column: "
+ + StringUtils.join(indexedColumn, ", "));
+ }
+
+ private List<BloomDMModel> readBloomIndex(String indexFile) throws IOException {
+ LOGGER.info("read bloom index from file: " + indexFile);
+ List<BloomDMModel> bloomDMModelList = new ArrayList<BloomDMModel>();
+ DataInputStream dataInStream = null;
+ ObjectInputStream objectInStream = null;
+ try {
+ dataInStream = FileFactory.getDataInputStream(indexFile, FileFactory.getFileType(indexFile));
+ objectInStream = new ObjectInputStream(dataInStream);
+ try {
+ BloomDMModel model = null;
+ while ((model = (BloomDMModel) objectInStream.readObject()) != null) {
+ LOGGER.info("read bloom index: " + model);
+ bloomDMModelList.add(model);
+ }
+ } catch (EOFException e) {
+ LOGGER.info("read " + bloomDMModelList.size() + " bloom indices from " + indexFile);
+ }
+ return bloomDMModelList;
+ } catch (ClassNotFoundException e) {
+ LOGGER.error("Error occrus while reading bloom index");
+ throw new RuntimeException("Error occrus while reading bloom index", e);
+ } finally {
+ CarbonUtil.closeStreams(objectInStream, dataInStream);
+ }
+ }
+
+ @Override
+ public List<Blocklet> prune(FilterResolverIntf filterExp, SegmentProperties segmentProperties,
+ List<PartitionSpec> partitions) throws IOException {
+ List<Blocklet> hitBlocklets = new ArrayList<Blocklet>();
+ if (filterExp == null) {
+ return null;
--- End diff --
Oh, then we should document it clearly somewhere, otherwise it is confusing
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder1/5280/
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by xuchuanyin <gi...@git.apache.org>.
Github user xuchuanyin commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183210168
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomCoarseGrainDataMap.java ---
@@ -0,0 +1,243 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataInputStream;
+import java.io.EOFException;
+import java.io.IOException;
+import java.io.ObjectInputStream;
+import java.io.UnsupportedEncodingException;
+import java.util.ArrayList;
+import java.util.HashSet;
+import java.util.List;
+import java.util.Set;
+
+import org.apache.carbondata.common.logging.LogService;
+import org.apache.carbondata.common.logging.LogServiceFactory;
+import org.apache.carbondata.core.datamap.dev.DataMapModel;
+import org.apache.carbondata.core.datamap.dev.cgdatamap.CoarseGrainDataMap;
+import org.apache.carbondata.core.datastore.block.SegmentProperties;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.indexstore.Blocklet;
+import org.apache.carbondata.core.indexstore.PartitionSpec;
+import org.apache.carbondata.core.memory.MemoryException;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.scan.expression.ColumnExpression;
+import org.apache.carbondata.core.scan.expression.Expression;
+import org.apache.carbondata.core.scan.expression.LiteralExpression;
+import org.apache.carbondata.core.scan.expression.conditional.EqualToExpression;
+import org.apache.carbondata.core.scan.filter.resolver.FilterResolverIntf;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.collect.ArrayListMultimap;
+import com.google.common.collect.Multimap;
+import org.apache.commons.lang3.StringUtils;
+import org.apache.hadoop.fs.FileStatus;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+import org.apache.hadoop.fs.PathFilter;
+
+public class BloomCoarseGrainDataMap extends CoarseGrainDataMap {
+ private static final LogService LOGGER =
+ LogServiceFactory.getLogService(BloomCoarseGrainDataMap.class.getName());
+ private String[] indexFilePath;
+ private Set<String> indexedColumn;
+ private List<BloomDMModel> bloomIndexList;
+ private Multimap<String, List<BloomDMModel>> indexCol2BloomDMList;
+
+ @Override
+ public void init(DataMapModel dataMapModel) throws MemoryException, IOException {
+ Path indexPath = FileFactory.getPath(dataMapModel.getFilePath());
+ FileSystem fs = FileFactory.getFileSystem(indexPath);
+ if (!fs.exists(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap does not exist", indexPath));
+ }
+ if (!fs.isDirectory(indexPath)) {
+ throw new IOException(
+ String.format("Path %s for Bloom index dataMap must be a directory", indexPath));
+ }
+
+ FileStatus[] indexFileStatus = fs.listStatus(indexPath, new PathFilter() {
+ @Override public boolean accept(Path path) {
+ return path.getName().endsWith(".bloomindex");
+ }
+ });
+ indexFilePath = new String[indexFileStatus.length];
+ indexedColumn = new HashSet<String>();
+ bloomIndexList = new ArrayList<BloomDMModel>();
+ indexCol2BloomDMList = ArrayListMultimap.create();
+ for (int i = 0; i < indexFileStatus.length; i++) {
+ indexFilePath[i] = indexFileStatus[i].getPath().toString();
+ String indexCol = StringUtils.substringBetween(indexFilePath[i], ".carbondata.",
+ ".bloomindex");
+ indexedColumn.add(indexCol);
+ bloomIndexList.addAll(readBloomIndex(indexFilePath[i]));
+ indexCol2BloomDMList.put(indexCol, readBloomIndex(indexFilePath[i]));
+ }
+ LOGGER.info("find bloom index datamap for column: "
+ + StringUtils.join(indexedColumn, ", "));
+ }
+
+ private List<BloomDMModel> readBloomIndex(String indexFile) throws IOException {
+ LOGGER.info("read bloom index from file: " + indexFile);
+ List<BloomDMModel> bloomDMModelList = new ArrayList<BloomDMModel>();
+ DataInputStream dataInStream = null;
+ ObjectInputStream objectInStream = null;
+ try {
+ dataInStream = FileFactory.getDataInputStream(indexFile, FileFactory.getFileType(indexFile));
+ objectInStream = new ObjectInputStream(dataInStream);
+ try {
+ BloomDMModel model = null;
+ while ((model = (BloomDMModel) objectInStream.readObject()) != null) {
+ LOGGER.info("read bloom index: " + model);
+ bloomDMModelList.add(model);
+ }
+ } catch (EOFException e) {
+ LOGGER.info("read " + bloomDMModelList.size() + " bloom indices from " + indexFile);
+ }
+ return bloomDMModelList;
+ } catch (ClassNotFoundException e) {
+ LOGGER.error("Error occrus while reading bloom index");
+ throw new RuntimeException("Error occrus while reading bloom index", e);
+ } finally {
+ CarbonUtil.closeStreams(objectInStream, dataInStream);
+ }
+ }
+
+ @Override
+ public List<Blocklet> prune(FilterResolverIntf filterExp, SegmentProperties segmentProperties,
+ List<PartitionSpec> partitions) throws IOException {
+ List<Blocklet> hitBlocklets = new ArrayList<Blocklet>();
+ if (filterExp == null) {
+ return null;
--- End diff --
:ok_hand: fine~
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on the issue:
https://github.com/apache/carbondata/pull/2200
@xuchuanyin Agree. Need more enhancement in future. Thanks for working for this.
LGTM
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183212032
--- Diff: datamap/bloom/src/main/java/org/apache/carbondata/datamap/bloom/BloomDataMapWriter.java ---
@@ -0,0 +1,216 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.carbondata.datamap.bloom;
+
+import java.io.DataOutputStream;
+import java.io.File;
+import java.io.IOException;
+import java.io.ObjectOutputStream;
+import java.util.ArrayList;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import org.apache.carbondata.common.annotations.InterfaceAudience;
+import org.apache.carbondata.core.datamap.DataMapMeta;
+import org.apache.carbondata.core.datamap.Segment;
+import org.apache.carbondata.core.datamap.dev.DataMapWriter;
+import org.apache.carbondata.core.datastore.impl.FileFactory;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.AbsoluteTableIdentifier;
+import org.apache.carbondata.core.metadata.datatype.DataType;
+import org.apache.carbondata.core.metadata.datatype.DataTypes;
+import org.apache.carbondata.core.util.CarbonUtil;
+
+import com.google.common.hash.BloomFilter;
+import com.google.common.hash.Funnels;
+import org.apache.hadoop.fs.FileSystem;
+import org.apache.hadoop.fs.Path;
+
+@InterfaceAudience.Internal
+public class BloomDataMapWriter extends DataMapWriter {
+ /**
+ * suppose one blocklet contains 20 page and all the indexed value is distinct.
+ * later we can make it configurable.
+ */
+ private static final int BLOOM_FILTER_SIZE = 32000 * 20;
+ private String dataMapName;
+ private List<String> indexedColumns;
+ // map column name to ordinal in pages
+ private Map<String, Integer> col2Ordianl;
+ private Map<String, DataType> col2DataType;
+ private String currentBlockId;
+ private int currentBlockletId;
+ private List<String> currentDMFiles;
+ private List<DataOutputStream> currentDataOutStreams;
+ private List<ObjectOutputStream> currentObjectOutStreams;
+ private List<BloomFilter<byte[]>> indexBloomFilters;
+
+ public BloomDataMapWriter(AbsoluteTableIdentifier identifier, DataMapMeta dataMapMeta,
+ Segment segment, String writeDirectoryPath) {
+ super(identifier, segment, writeDirectoryPath);
+ dataMapName = dataMapMeta.getDataMapName();
+ indexedColumns = dataMapMeta.getIndexedColumns();
+ col2Ordianl = new HashMap<String, Integer>(indexedColumns.size());
+ col2DataType = new HashMap<String, DataType>(indexedColumns.size());
+
+ currentDMFiles = new ArrayList<String>(indexedColumns.size());
+ currentDataOutStreams = new ArrayList<DataOutputStream>(indexedColumns.size());
+ currentObjectOutStreams = new ArrayList<ObjectOutputStream>(indexedColumns.size());
+
+ indexBloomFilters = new ArrayList<BloomFilter<byte[]>>(indexedColumns.size());
+ }
+
+ @Override
+ public void onBlockStart(String blockId, long taskId) throws IOException {
+ this.currentBlockId = blockId;
+ this.currentBlockletId = 0;
+ currentDMFiles.clear();
+ currentDataOutStreams.clear();
+ currentObjectOutStreams.clear();
+ initDataMapFile();
+ }
+
+ @Override
+ public void onBlockEnd(String blockId) throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ CarbonUtil.closeStreams(this.currentDataOutStreams.get(indexColId),
+ this.currentObjectOutStreams.get(indexColId));
+ commitFile(this.currentDMFiles.get(indexColId));
+ }
+ }
+
+ @Override public void onBlockletStart(int blockletId) {
+ this.currentBlockletId = blockletId;
+ indexBloomFilters.clear();
+ for (int i = 0; i < indexedColumns.size(); i++) {
+ indexBloomFilters.add(BloomFilter.create(Funnels.byteArrayFunnel(),
+ BLOOM_FILTER_SIZE, 0.00001d));
+ }
+ }
+
+ @Override
+ public void onBlockletEnd(int blockletId) {
+ try {
+ writeBloomDataMapFile();
+ } catch (Exception e) {
+ for (ObjectOutputStream objectOutputStream : currentObjectOutStreams) {
+ CarbonUtil.closeStreams(objectOutputStream);
+ }
+ for (DataOutputStream dataOutputStream : currentDataOutStreams) {
+ CarbonUtil.closeStreams(dataOutputStream);
+ }
+ throw new RuntimeException(e);
+ }
+ }
+
+ @Override public void onPageAdded(int blockletId, int pageId, ColumnPage[] pages)
+ throws IOException {
+ col2Ordianl.clear();
+ col2DataType.clear();
+ for (int colId = 0; colId < pages.length; colId++) {
+ String columnName = pages[colId].getColumnSpec().getFieldName().toLowerCase();
+ if (indexedColumns.contains(columnName)) {
+ col2Ordianl.put(columnName, colId);
+ DataType columnType = pages[colId].getColumnSpec().getSchemaDataType();
+ col2DataType.put(columnName, columnType);
+ }
+ }
+
+ // for each row
+ for (int rowId = 0; rowId < pages[0].getPageSize(); rowId++) {
+ // for each indexed column
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ String indexedCol = indexedColumns.get(indexColId);
+ byte[] indexValue;
+ if (DataTypes.STRING == col2DataType.get(indexedCol)
+ || DataTypes.BYTE_ARRAY == col2DataType.get(indexedCol)) {
+ byte[] originValue = (byte[]) pages[col2Ordianl.get(indexedCol)].getData(rowId);
+ indexValue = new byte[originValue.length - 2];
+ System.arraycopy(originValue, 2, indexValue, 0, originValue.length - 2);
+ } else {
+ Object originValue = pages[col2Ordianl.get(indexedCol)].getData(rowId);
+ indexValue = CarbonUtil.getValueAsBytes(col2DataType.get(indexedCol), originValue);
+ }
+
+ indexBloomFilters.get(indexColId).put(indexValue);
+ }
+ }
+ }
+
+ private void initDataMapFile() throws IOException {
+ String dataMapDir = genDataMapStorePath(this.writeDirectoryPath, this.dataMapName);
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ String dmFile = dataMapDir + File.separator + this.currentBlockId
+ + '.' + indexedColumns.get(indexColId) + BloomCoarseGrainDataMap.BLOOM_INDEX_SUFFIX;
+ DataOutputStream dataOutStream = null;
+ ObjectOutputStream objectOutStream = null;
+ try {
+ FileFactory.createNewFile(dmFile, FileFactory.getFileType(dmFile));
+ dataOutStream = FileFactory.getDataOutputStream(dmFile,
+ FileFactory.getFileType(dmFile));
+ objectOutStream = new ObjectOutputStream(dataOutStream);
+ } catch (IOException e) {
+ CarbonUtil.closeStreams(objectOutStream, dataOutStream);
+ throw new IOException(e);
+ }
+
+ this.currentDMFiles.add(dmFile);
+ this.currentDataOutStreams.add(dataOutStream);
+ this.currentObjectOutStreams.add(objectOutStream);
+ }
+ }
+
+ private void writeBloomDataMapFile() throws IOException {
+ for (int indexColId = 0; indexColId < indexedColumns.size(); indexColId++) {
+ BloomDMModel model = new BloomDMModel(this.currentBlockId, this.currentBlockletId,
+ indexBloomFilters.get(indexColId));
+ // only in higher version of guava-bloom-filter, it provides readFrom/writeTo interface.
--- End diff --
ok
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by xuchuanyin <gi...@git.apache.org>.
Github user xuchuanyin commented on the issue:
https://github.com/apache/carbondata/pull/2200
All review comments have been fixed
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Failed with Spark 2.1.0, Please check CI http://136.243.101.176:8080/job/ApacheCarbonPRBuilder1/5262/
---
[GitHub] carbondata pull request #2200: [CARBONDATA-2373][DataMap] Add bloom datamap ...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2200#discussion_r183198962
--- Diff: datamap/bloom/pom.xml ---
@@ -0,0 +1,88 @@
+<project xmlns="http://maven.apache.org/POM/4.0.0"
+ xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
+ xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
+ <modelVersion>4.0.0</modelVersion>
+
+ <parent>
+ <groupId>org.apache.carbondata</groupId>
+ <artifactId>carbondata-parent</artifactId>
+ <version>1.4.0-SNAPSHOT</version>
+ <relativePath>../../pom.xml</relativePath>
+ </parent>
+
+ <artifactId>carbondata-bloom</artifactId>
+ <name>Apache CarbonData :: Bloom Index DataMap</name>
+
+ <properties>
+ <dev.path>${basedir}/../../dev</dev.path>
+ <lucene.version>6.3.0</lucene.version>
--- End diff --
can you move this definition in parent pom
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by jackylk <gi...@git.apache.org>.
Github user jackylk commented on the issue:
https://github.com/apache/carbondata/pull/2200
Thanks for working on this, it is a very good feature 😀
---
[GitHub] carbondata issue #2200: [CARBONDATA-2373][DataMap] Add bloom datamap to supp...
Posted by CarbonDataQA <gi...@git.apache.org>.
Github user CarbonDataQA commented on the issue:
https://github.com/apache/carbondata/pull/2200
Build Failed with Spark 2.2.1, Please check CI http://88.99.58.216:8080/job/ApacheCarbonPRBuilder/4081/
---