You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@druid.apache.org by GitBox <gi...@apache.org> on 2018/07/18 02:23:48 UTC
[GitHub] clintropolis opened a new pull request #6016: Druid 'Shapeshifting'
Columns
clintropolis opened a new pull request #6016: Druid 'Shapeshifting' Columns
URL: https://github.com/apache/incubator-druid/pull/6016
This PR introduces a new approach to representing numerical columns in which row values are split into varyingly _encoded_ blocks, dubbed _shape-shifting_ columns for [obvious](https://rpg.stackexchange.com/questions/112244/is-the-shapeshifting-druid-an-original-dd-invention), [druid](https://wow.gamepedia.com/Druid_Shapeshift_forms) reasons. In other words, we are trading a bit extra compute and memory at indexing time to analyze each block of values and find the most appropriate encoding, in exchange for potential increased decoding speed and decreased encoded size on the query side. The end result is _hopefully_ faster performance in most cases.
Included in this PR is the base generic structure for creating and reading `ShapeShiftingColumn` as well as an implementation for the integer column part of dictionary encoded columns, `ShapeShiftingColumnarInts`. I have an additional branch in development with an implementation for long columns which was done as a reference to make sure the generic base structure is workable and will follow on the tail of this PR, as well as some experiments I would like to do with floats/doubles, so they hopefully won't be far behind either. For ints at least, the result is something that in many cases will decode as fast or faster and be as small or smaller `CompressedVSizeColumnarInts` with lz4.
## tl;dr
### The good
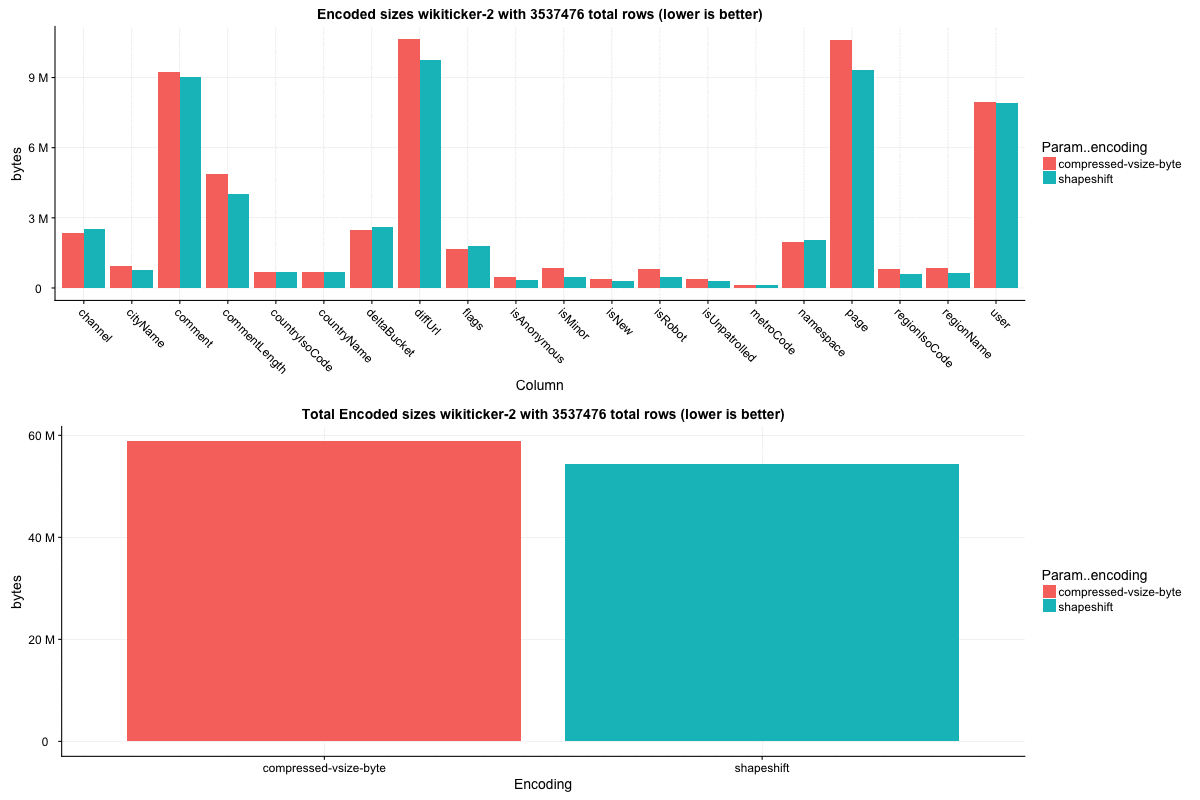
This PR can _likely_ make your queries faster, and maybe, your data smaller. Based on observations thus far, I would advocate making this the default in whatever major version + 1 this PR makes it into (if it continues to perform well in the wild of course), but the intention for now is to be an optional/experimental feature specified at indexing time. You will mainly see two types of plots generated from benchmarks in this writeup comparing `ShapeShiftingColumnarInts` to `CompressedVSizeColumnarInts` trying to convince you of this, one of which is a summary of encoded sizes by column and for the whole segment:
and the other which has a line chart of 'time to select n rows' where 'time to select' is the y axis and 'n' as a fraction of total rows in the column is the x axis:

as well as 2 bar charts, one showing encoded size comparison, the other encoding speed comparison. Most of these are animations which show each column. The dip at the end is actually a cliff caused by the benchmark iterating the column without a simulated filter, to get raw total scan speed for the entire column. Beyond benchmarks, there is a bunch of design description and background of how things ended up how they are, to hopefully make review easier.
### The bad
This isn't currently better 100% of the time, specifically in the case of low cardinality dimensions that have a semi-random distribution without a lot of repeated values. The reason shape-shifting columns perform worse in this case is due to fixed using block sizes that are decided prior to indexing, where `CompressedVSizeColumnarIntsSerializer` byte packs on the fly until a fixed size buffer is full, effectively allowing it to vary block size to have up to 4 times as many values per block as the current largest block size setting provided for the shape-shifting serializer, allowing lz4 to take advantage of having more values to work with per run. There is nothing preventing the use of varying sized blocks for shape-shifting columns, so this could likely be overcome in one way or another. I am just currently erring on the side of caution to attempt to limit heap pressure that this PR already introduces where there previously was none, which makes me nervous but has seemed ok so far while running on a test cluster. Additionally, because these columns have a different memory profile than `CompressedVSizeColumnarInts`, jvm configuration adjustments will likely need to be made, especially if your cluster is tuned to effectively use most of it's resources. See the 'Memory Footprint' section of the design section for more details. Overall indexing time might also change, sometimes faster, sometimes slower, encode speed is dependent on value composition so can range quite a lot between columns.
## Design
On the query side, `ShapeShiftingColumn` implementations are designed to implement the actual logic to get values for row indices within the column implementation, which through meticulous benchmarking has proven to be the maximally performant arrangement I could find and do the things we are doing here. This is an alternative approach to pushing down reads into a decoder type, as is done in the `BlockLayout...` `EntireLayout...` implementations for long columns. To put row reads _in_ the column, a `ShapeShiftingColumn` implementation operates on a slightly unintuitive pattern, that for each block it will pass itself into a decoder which knows how to mutate _things_ the column such that the column's 'get' function will produce the correct data for the row index. Vague, I know, but we'll get there. Sticking with the theme, these phase changes between the chunks of the data while reading are called _transformations_. This design is a bit less straightforward than I was hoping to end up with, but this inversion of responsibility allows the implementation beat the performance penalty that faces the `BlockLayout...` `EntireLayout...` with `EncodingReader` pattern which is [vaguely alluded to here](https://github.com/druid-io/druid/blob/master/processing/src/main/java/io/druid/segment/data/BlockLayoutColumnarLongsSupplier.java#L60). More on this later (and pictures).
### Background
##### FastPFOR
The works produced in this PR actually began life as a follow up [investigation to using the FastPFOR algorithm](https://github.com/druid-io/druid/issues/4080) to encode integer value columns, writing additional benchmarks to expand upon the random valued columns tested in that thread to use the column value generators to compare FastPFOR against `CompressedVSizeColumnarInts` across a wide variety of column value distributions. Things looked really good in early tests, FastPFOR was doing very well, often outperforming the lz4 bytepacking across the board on encoding speed, encoded size, and decoding speed.

From there, benchmarks were expanded to test against actual integer columns from actual segments, where FastPFOR was initially looking even better as a standalone option.
However, once I began looking at one of our 'metrics-like' data sets, where the encoded size using FastPFOR was on the order of double the size of using the existing lz4 bytepacking.

Examining more metrics datasources produced similar results. Many columns decoded faster, but the increased size cost was too much to be something that we could consider making the default, greatly reducing the utility of this feature if it were to require cluster operators to experiment with segments by hand to compare FastPFOR and lz4 bytepacking to see which performed better with their columns. Note that this is unrelated to the previous mentioned block size issue, increased block size had little effect on overall encoded size, it's more a case of being a data distribution which fastpfor overall does pretty poorly with compared to lz4.
Thinking that the sparse nature of many metrics datasets might be the cause, I made a 'RunFastPFOR' version of the column that eliminated blocks that were entirely zeros or a constant value by putting a byte header in each chunk to indicate if a block was zero, constant, or FastPFOR encoded, which helped a bit but still couldn't compete with the existing implementation. Noting that encoding speed for FastPFOR being so much faster than lz4, we considered a system that would try both and use whichever was better (similar to the intermediary column approach with longs), and also looked into introducing a run length encoding into the mix to see how much repeated values played a role in how well lz4 was doing comparatively. Searching for some reading about run length encoding, I came across some Apache ORC encoding docs (the original link is dead, but most of the content is contained [here](https://orc.apache.org/specification/ORCv2/)) which upon reading, caused something to click, realizing my earlier 'RunFastPFOR' sketch was maybe on to something, but to try _all_ encodings and vary per block. This is similar to the 'auto' idea via intermediary columns used in longs, but can much better capitalize on encodings that do well in specialized circumstances, since an encoding doesn't have to do well for the entire column at once. 'Shape-shifting' columns were born and I finally had something that was competitive even on metrics like datasets. Sizes still come out occasionally larger in some cases, due to differences in block sizes used between the 2 strategies, but in observations so far it has been able to achieve acceptable sizes.
##### Column Structure
Concurrent with experimentations with FastPFOR, I was also investigating how to best wire it into the current segment structure, should it prove itself useful. [Previous efforts](https://github.com/druid-io/druid/pull/3148) had done work to introduce the structure to have a variety of encodings for longs, floats, and double columns, so I began there. I created `EntireLayoutColumnarInts` and `BlockLayoutColumnarInts` in the pattern that was done with longs, and ported the byte packing algorithm we currently employ for ints into the `EncodingReader` and `EncodingWriter` pattern used by `ColumnarLongs`. Benchmarking it however (`bytepacked` in the chart below), showed a performance slowdown compared to the existing implementation (`vsize-byte` aka `VSizeColumnarInts`).
This is the performance drop in action from the overhead of these additional layers of indirection mentioned above. It is also apparent in the long implementation:

where at low row selection `lz4-auto` wins because it's decompressing a smaller volume of data, but when reading more values `lz4-longs`, which optimizes out the encoding reader entirely, becomes faster.
After it became apparent that FastPFOR alone was not a sufficient replacement for lz4 bytepacking, I sketched a couple of competing implementations of `ShapeShiftingColumnarInts` to try to both have a mechanism to abstract decoding and reading values from column implementation, but not suffer the same performance drop of the earlier approach. One was a simpler 'block' based approach that always eagerly decoded everything into an array, on the hope that because row gets are just an array access if on the same chunk, it could keep up with `CompressedVSizeColumnarInts` which eagerly decompresses but supports random access to individual row values unpacking bytes on the fly. The other approach was attempting to support random access for encodings that supported it, similar in spirit to the `BlockLayout` approach, but with one less layer of indirection. It had more overhead than the array based approach since it had a set of decoder objects and pushed reads down into them, but less than . Initial results were as expected, random access did better for a smaller number of rows selection, but was slower for a large scan than the array based approach, and both did reasonable compared to `CompressedVSizeColumnarInts`. In the following plots, `shapeshift` is the random access approach, `shapeshift-block` is the array based approach.

However I eventually ran into a degradation similar in nature to what I saw with the `BlockLayout`/`EntireLayout` approach with my random access implementation, but it only happened when more than 2 encodings were used for a column.
I refactored a handful of times to try and outsmart the jvm, but as far as I can tell from running with print inlining and assembly output enabled, I was running into a similar issue with byte-code getting too large to inline. However random access did quite a lot better for low selectivity in benchmarks, so I continued experimentation to try and get the best of both worlds, which led me to where things are now - decoders that mutate the column to either read 'directly' from memory, or to populate an int array.
I suspect even this implementation is dancing perilously close to going off the rails in the same way, so care should be definitely be taken when making any changes. However, this is true of everything in this area of the code, I find it impressively easy to just flat out wreck performance with the smallest of changes, so this is always a concern. My standard practice while working on this PR has been to fire off a full regression of benchmarks on a test machine with nearly every change I've make, and have run thousands of hours of them at this point.
### `ShapeShiftingColumn` Encoding
The generic base types for producing a `ShapeShiftingColumn` are
* `abstract class ShapeShiftingColumnSerializer<TChunk, TChunkMetrics extends FormMetrics>` - base column serializer which has parameters to specify the type of chunks to be encoded (e.g. `int[]` or `long[]`), and the type of _metrics_ that are collected about that chunk used during encoding selection.
* `interface FormEncoder<TChunk, TChunkMetrics extends FormMetrics>` is the interface describing... encoders, and it has generic parameters to match that of the `ShapeShiftingColumnSerializer`.
* `abstract class FormMetrics` - the base type for the data collected about the current chunk during indexing, the `ShapeShiftingColumnSerializer` metric type generic parameter must extend this class.
`ShapeShiftingColumnSerializer` provides all typical column serialization facilities for writing to `SegmentWriteOutMedium`, and provides a method for 'flushing' chunks to the medium, `flushCurrentChunk`, which is where encoding selection is performed. Implementors must implement 2 methods, `initializeChunk` and `resetChunkCollector` which allocate the chunk storage and reset the metrics collected about a chunk respectively. It's not perfectly automatic - implementors must manually add values to the current chunk, track when to call the flush mechanism, and ensure that the `FormMetrics` are updated, all within the 'add' method of the column type serializer interface the column implements. For ints, it looks like this
```java
@Override
public void addValue(int val) throws IOException
{
if (currentChunkPos == valuesPerChunk) {
flushCurrentChunk();
}
chunkMetrics.processNextRow(val);
currentChunk[currentChunkPos++] = val;
numValues++;
}
```
I blame this shortcoming more on Java generics not working with value types than anything else, as repeated near identical structure across column types is pretty common in this area of the code.
#### Encoding Selection
Encoding selection is probably the most 'magical' part of this setup. The column serializer will iterate over all available `FormEncoder` implementations, which must be able to estimate their encoded size, as well as provide a 'scaling' factor that correlates to _decoding speed relative to all other decoders_ and adjusted for the _optimization target_. The 'lowest' value is the best encoder, and is used to encode that block of values to the write out medium. This is the icky part, in that relatively thorough performance analysis must be done to see how encoding speeds relate to each other, and tune the responses of the scaling function accordingly.

The optimization target is to allow some _subtle_ control over behavior:
* `ShapeShiftingOptimizationTarget.SMALLER` - "make my data as small as possible"
* `ShapeShiftingOptimizationTarget.FASTBUTSMALLISH` - "make my data small, but be chill if a way faster encoding is close in size" (default)
* `ShapeShiftingOptimizationTarget.FASTER` - "I'm willing to trade some reasonable amount of size if it means more of my queries will be faster"
I think there is a lot of room for improvement here, and I don't know how scalable this will be. However, if the general idea is workable I would rather build improvements as an additional PR since this is already quite expansive. A very easy one would be noticing 'zero' and 'constant' blocks (if encodings exist) and short circuiting general encoding selection, since those will always be the fastest and smallest choices, if available.
Compression is provided generically, since it operates at the byte level in a value agnostic way, and is available for any encoder that implements `CompressibleFormEncoder`. Implementing this interface allows encoding to a temporary `ByteBuffer` to be compressed at indexing time. However, compression very dramatically increases encoding time because it requires actually encoding and compressing the values to determine the encoded size, so we need to be very considerate about what algorithms we attempt to compress. We at least preserve the temporary buffer, so if the last compressed encoding strategy to be used is selected it does not have to be re-encoded. It would probably be legitimate to just make all encoders compressible and get rid of the extra interface, but I haven't done that at this time.
#### `ShapeShiftingColumn` byte layout
Due to shared based serializer, all `ShapeShiftingColumn` implementations have the following byte layout, consisting of 3 major parts: the header, the offsets, and the data.
| version | headerSize | numValues | numChunks | logValuesPerChunk | offsetsOutSize | compositionSize | composition | offsets | values |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| byte | int | int | int | byte | int | int | `compositionSize` | `offsetsOutSize` | remaining |
##### Header
* version - byte indicating column version
* headerSize - size of header, to future proof header changes
* numValues - total number of rows in the column
* numChunks - number of value chunks in the column
* logValuesPerChunk - log base 2 of chunk size
* offsetsOutSize - size in bytes of the 'offsets' chunk
* compositionSize - size in bytes of the column composition
* composition - count metrics for all chunk codecs
##### Offsets
* The offsets section stores in order _starting_ offsets into the base `ByteBuffer` for each chunk, with 'final' offset indicating end of final chunk.
##### Data
* The data section stores the actual encoded chunks, pointed to by the offsets.
The column structure is similar in many ways to `GenericIndexed`, but tailored to this specific purpose (and I was afraid to touch that, since it's everywhere).
### `ShapeShiftingColumn` Decoding
`ShapeShiftingColumn` and `FormDecoder` are the generic structure on the decoding side.
* `abstract class ShapeShiftingColumn<TShapeShiftImpl extends ShapeShiftingColumn>` - Base type for reading shapeshifting columns, uses the 'curiously recurring template' pattern to be able to share this common structure and flow, and has a generic parameter is to grant type the corresponding `FormDecoder` implementations. To read row values for a block of data, the `ShapeShiftingColumn` first reads a byte header which corresponds to a `FormDecoder` implementation, and then calls the decoder `transform` method to decode values and prepare for reading.
* `interface FormDecoder<TColumn extends ShapeShiftingColumn>` - Mutates `ShapeShiftingColumn` with a `transform` method to allow reading row values for that block of data. What exactly _transformation_ entails is column implementation specific, as these types are tightly coupled, but can include setting the decoding values into a buffer and setting it as the columns read buffer, populating a primitive value array provided by the column, and the like. The two primary models of column reads I had in mind are 'direct' reads from a `ByteBuffer` and array reads where row values for a chunk are eagerly decoded to a primitive array, which was what I needed to support both `CompressionStrategy` and `FastPFOR`.
Decompression is provided generically here too for any `ShapeShiftingColumn` through `CompressedFormDecoder`, which will decompress the data from the buffer and `transform` again using the inner decoder pointed at the decompressed data buffer. While transformation is implementation specific, raw chunk loading is not since it's just offsets on the base buffer, so `ShapeShiftingColumn` provides a `loadChunk(int chunkNumber)` that will jump to the correct offset of the requested chunk and call `transform` to prepare for value reading.
Similar to the shortcomings on the serializer side of things, implementors of `ShapeShiftingColumn` will also need to manually handle chunk loading based on block size in the row index `get` method. For integers, it looks like this:
```java
@Override
public int get(final int index)
{
final int desiredChunk = index >> logValuesPerChunk;
if (desiredChunk != currentChunk) {
loadChunk(desiredChunk);
}
return currentForm.decode(index & chunkIndexMask);
}
```
where `currentForm` is a function that either reads a value from an array, or reads a value direct from a `ByteBuffer`, which is selected by it's implementation of `transform`.
#### Memory access
Currently, reads prefer to use `Unsafe` if the underlying column is stored in native order on a direct buffer for better performance due to lack of bounds checking on the 'get' method, and for non-native or non-direct reads, tracks offsets into the base `ByteBuffer` instead of slicing or creating any sort of other view. I know there is [an initiative to move to `Memory`](https://github.com/apache/incubator-druid/issues/3892), both of these approaches can be folded into that model. During experimentation I used `Memory` to see how it did, and without a `CompressionStrategy` it performance was closer to `Unsafe` than `ByteBuffer`, but with compression the overhead of wrapping made it slightly slower than just using `ByteBuffer`. That said, once compression supports `Memory` it should be a relatively straightforward change, and will reduce the duplicate unsafe/buffer versions of everything that currently exist. Additionally, JVM9+ claims to have performance improvements for direct byte buffers and maybe other stuff worth investigating.
## Shape-shifting integer columns
`ShapeShiftingColumnarInts` can be enabled via a new option on `IndexingSpec`
#### `IndexSpec.ColumnEncodingStrategy`
| property | type | default | description |
| --- | --- | --- | --- |
| strategy | string (`IndexSpec.EncodingStrategy`)| `compression` | `(compression|shapeshift)` `compression` will result in current behavior and use the `CompressionStrategy` defined on `indexSpec.dimensionCompression`, while `shapeshift` will use `ShapeShiftingColumnarIntsSerializer`.|
| optimizationTarget | string (`IndexSpec.ShapeShiftingOptimizationTarget`)| `fastbutsmallish` | `(smaller|fastbutsmallish|faster)` see previous description of optimization target value meanings above.|
| blockSize | string (`IndexSpec.ShapeShiftingBlockSize`)| `large` | `(large|middle|small)` Set shape shifting column block sizes, corresponding to 2^16, 2^15, and 2^14 bytes, which for ints are blocks of 16k values, 8k values, and 4k values respectively for ints. Smaller block sizes put have lower memory pressure and potentially faster low selectivity scan times, but will likely produce larger overall columns sizes due to more encoding overhead.
##### example
```json
"indexSpec": {
"dimensionCompression":"lz4",
"intEncodingStrategy": {
"strategy": "shapeshift",
"optimizationTarget":"fastbutsmallish",
"blockSize":"large"
}
}
```
`optimizationTarget` and `blockSize` have a very subtle effect, as quite often the best codec for a given block is unambiguous. In essence, it provides control to sway the decisions when there are multiple options that are very close in terms of encoded size.
Optimization targets:
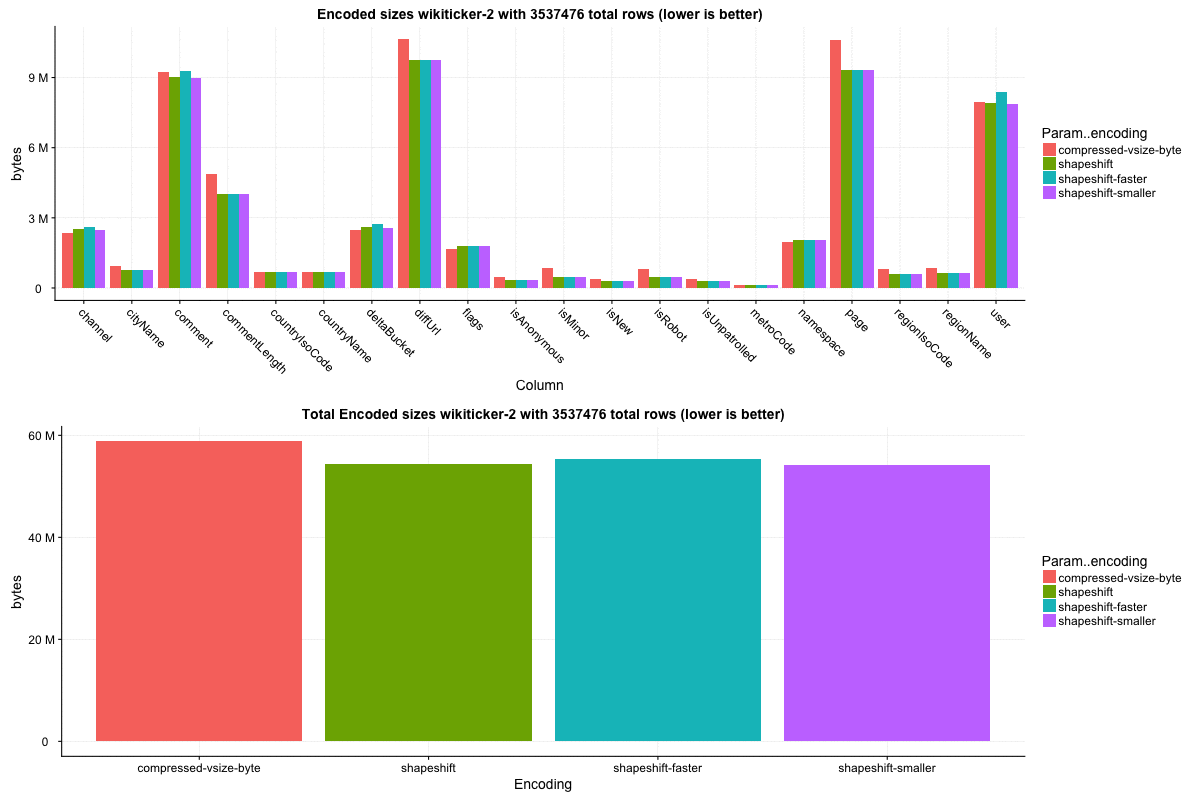

Block sizes:
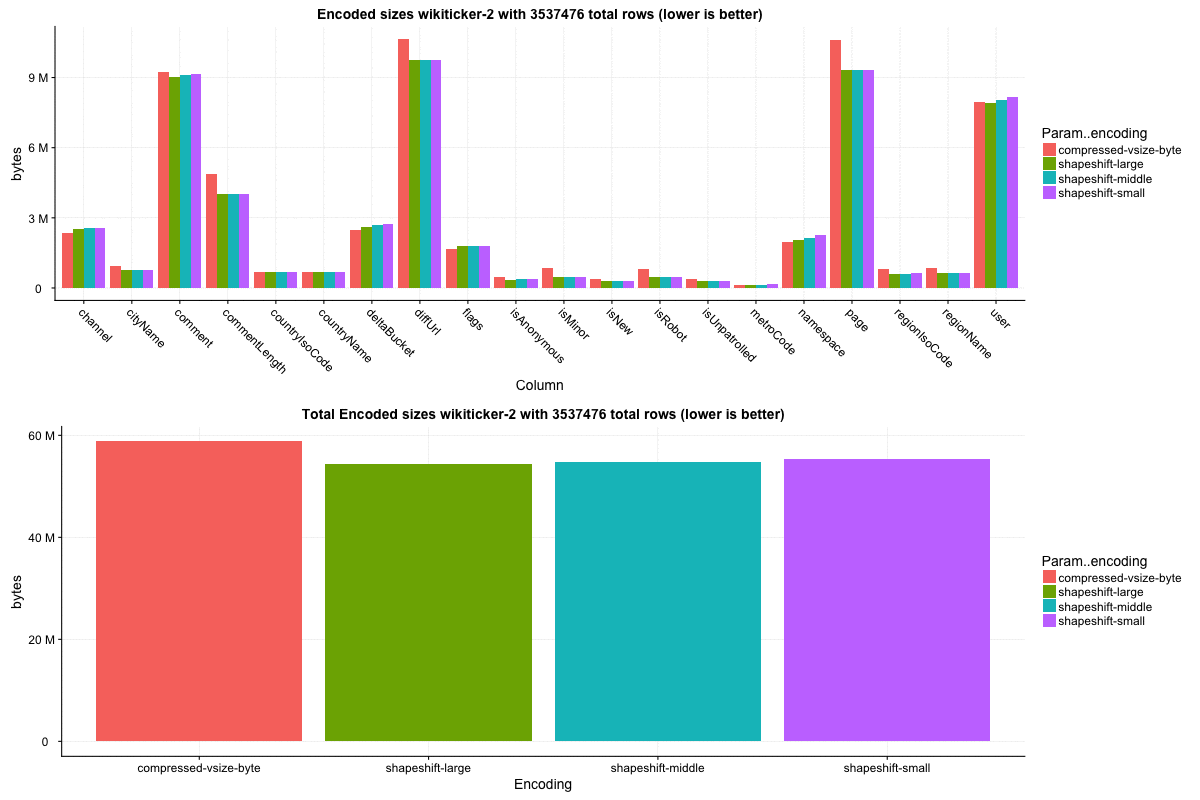
Given how similar the outcomes are, it may make sense to not expose one or both of these configuration settings at all, but on the other hand it seems useful to be able to influence in the manner that best suits the use case, no matter how minor the difference.
### Codecs
#### FastPFOR
The initial algorithm investigation that started this whole endeavor, FastPFOR is available via this [Java FastPFOR implementation](https://github.com/lemire/JavaFastPFOR) and does really well in a lot of cases.
##### layout
| header | encoded values |
| :---: | :---: |
| byte | `numOutputInts*Integer.BYTES` |
#### Bytepacking
Our old friend, byte packed integers, ported from the algorithm used by `CompressedVSizeColumnarInts`. Since values are analyzed on the fly, the number of bytes that values are packed into can vary on a chunk by chunk basis to be suited to the values. In some cases this can result in smaller column sizes than `CompressedVSizeColumnarInts`.
##### layout
| header | numBytes | encoded values |
| :---: | :---: | :---: |
| byte | byte | `numValues*numBytes`
#### Run Length Bytepacking
A simple run length encoding that uses the same byte packing strategy for integers, but uses the high bit to indicate if a value is a 'run' length or a single non-repeating value. The high bit set indicates that the value is a run length, and the next value is the value that is repeated that many times. There is very likely a better run-length implementation out there, I busted this out more or less from scratch based on the other byte packing algorithm to see how well a simple run length encoding would perform when thrown into the mix. The answer is pretty decent, situationally dependent, but I imagine there is a lot of opportunity for improvement here.
##### layout
| header | numBytes | encoded values |
| :---: | :---: | :---: |
| byte | byte | `((2*numDistinctRuns*numBytes) + (numSingleValues*numBytes))`|
#### Unencoded
Like the name says, full 4 byte ints - more for testing and reference, I have yet to see it used in the experiments conducted so far.
##### layout
| header | values |
| :---: | :---: |
| byte | `numValues*Integer.BYTES` |
#### Zero
This encoding is an optimization to employ if a chunk of values is all zero, allowing the chunk to be represented solely with the header byte. As you can imagine, this and constant encoding can _dramatically_ reduce column size for really sparse columns.

##### layout
| header |
| :---: |
| byte |
#### Constant
This encoding is an optimization to employ if a chunk of values is a non-zero constant, allowing the chunk to be represented with a header byte. Like zero, this can also have a very dramatic reduction of column size.
##### layout
| header | constant |
| :---: | :---: |
| byte | int |
#### Compression
Compression algorithms from `CompressionStrategy` are available to wrap 'compressible' encodings. Out of the box, integers uses lz4 with byte-packing, run length byte-packing. Unencoded is also compressible, but is not enabled by default to reduce overall indexing time. The metadata size is to account for things like the number of bytes stored in the header of a bytepacking chunk, etc.
##### layout
| header | inner codec header | inner codec metadata | compressed data |
| :---: | :---: | :---: | :---: |
| byte | byte | `innerForm.getMetadataSize()` | remaining chunk size |
### Encoding
`ShapeShiftingColumnarIntsSerializer` is a `ShapeShiftingColumnSerializer` with `int[]` chunk type and `IntFormMetrics` to collect chunk metrics, which tracks minimum and maximum values, number of unique 'runs', the longest 'run', and the total number of values which are part of a 'run'.
### Decoding
`ShapeShiftingColumnarInts` is a `ShapeShiftingColumn<ShapeShiftingColumnarInts>` using `FormDecoder<ShapeShiftingColumnarInts>` to decode values. `ShapeShiftingColumnarInts` decodes values in one of two basic ways depending on the encoding used, either eagerly decoding all values into an `int[]` provided by the column, or by reading values directly from a `ByteBuffer`. For buffer reads, `ShapeShiftingColumnarInts` cheats (as we must whenever possible), and natively knows of the byte packing algorithm used by `VSizeColumnarInts` and `CompressedVSizeColumnarInts` as well as constants. The base transform for int columns is to decode values into `int[]` - all decoders must currently support this, and may also implement a 'direct' transformation if the encoding supports it. I don't think it is strictly necessary that all decoders need to be able to produce to an array, admittedly this is more of an artifact of the journey that got me here and probably worth discussing.
#### Memory Footprint
`ShapeShiftingColumnarInts` does have a larger memory footprint than `CompressedVSizeColumnarInts`, having up to 64KB direct buffer, a 64KB on heap primitive 'decoded' value array, 65KB on heap primitive 'encoded' values array, depending on block size. The `FastPFOR` encoder/decoder object is an additional 1MB on heap and 200KB off heap direct buffer. With a small patch to allow setting 'page size', the FastPFOR object heap usage could be ~1/4 of it's current size, since the largest shape-shift block currently allowed is 16k values. All of the objects are pooled in `CompressedPools` and lazy allocated by the column, the on heap objects with a maximum cache size so they don't grow unbounded during spikes of load (this might need to be a config option). Pooling both prevents merely materializing the column from taking up unnecessary space (i.e. during merging at indexing time) and is also much faster since large on heap allocations can be rather slow. These sizes can be reduced by using a smaller `blockSize` on the indexing spec, which will use correctly sized direct buffers and heap arrays.
The 64KB direct buffer and 64KB on heap array are the primary memory vessels for the column, and are allocated from the pool for the lifetime of the column if they are required. They are both lazy allocated when a transformation that requires the space is encountered, so it's possible that only one or even (less commonly) none of them will be required. The 65KB 'encoded' values buffer is allocated and released for a very short time, only during a transformation for decoders that need to copy values to a `int[]` before decoding (e.g. `FastPFOR`). The `FastPFOR` pool is used in the same manner, very short lifetime during transformation, and then released back to the pool.
A downside of the current pooling approach I have in place is that each different block size has it's own set of pools to support it, so if multiple block sizes are used in practice, it will be a larger amount of heap and direct overhead.
#### Encoding Selection
Encoding selection for `ShapeShiftingColumnarIntsSerializer` was tuned by extensively benchmarking each encoding in a standalone manner and coming up with a selection speed ranking to properly weight the scaling factor of each `IntFormEncoder` implementation.

'zero' and 'constant' are the fastest, followed by 'bytepacking', with 'FastPFOR' very close behind and finally 'lz4 bytepacking'. Run length encoding performance seems very contextual, it can be quite slow if there are not a lot of runs, but can be very quick if there are many repeated values, so it's scaling value adjusts based on the data collected `IntFormMetrics`, and compression is not attempted at all if not enough of the overall values are 'runs'.
## Benchmarks
All benchmarks were generated on a `c5.large` and corroborated on my macbook pro with the new benchmarks introduced in this PR. You can even try at home with your own segments in a semi manual way, replacing the segments referenced (but not supplied) by `BaseColumnarIntsFromSegmentsBenchmark` by setting the parameters `columnName`, `rows`, `segmentPath` which points to the segment file, and `segmentName`. Benchmarks are run in 2 phases, the first to encode the columns with each encoding specified in `BaseColumnarIntsBenchmark`, then to select values out of each column. To run, from the root druid source directory use these commands
```
$ java -server -cp benchmarks/target/benchmarks.jar io.druid.benchmark.ColumnarIntsEncodeDataFromSegmentBenchmark
...
$ java -server -cp benchmarks/target/benchmarks.jar io.druid.benchmark.ColumnarIntsSelectRowsFromSegmentBenchmark
...
```
and the results will be written to `column-ints-encode-speed-segments.csv` and `column-ints-select-speed-segments.csv` respectively.
I've also attached the R code I used to generate all of these plots, which you can feed the csv output into like so:
```R
source("./path/to/plot-column-bench.R")
wikiSize = 533652 # number of rows in segment
wiki1SelectSpeed1 = read.csv("./path/to/column-ints-select-speed-segments.csv")
wiki1EncodeSpeed1 = read.csv("./path/to/column-ints-encode-speed-segments.csv")
# to generate gif images:
animatePlot(plotIntSegBench(wiki1SelectSpeed1, wiki1EncodeSpeed1, wikiSize), "wiki-1-1.gif")
animatePlot(plotIntSegSizeSummary(wiki1EncodeSpeed1, wikiSize), "wiki-1-summary-1.gif")
# or just generate plots in R studio:
plotIntSegBench(wiki1SelectSpeed1, wiki1EncodeSpeed1, wikiSize)
plotIntSegSizeSummary(wiki1EncodeSpeed1, wikiSize)
```
### Segments
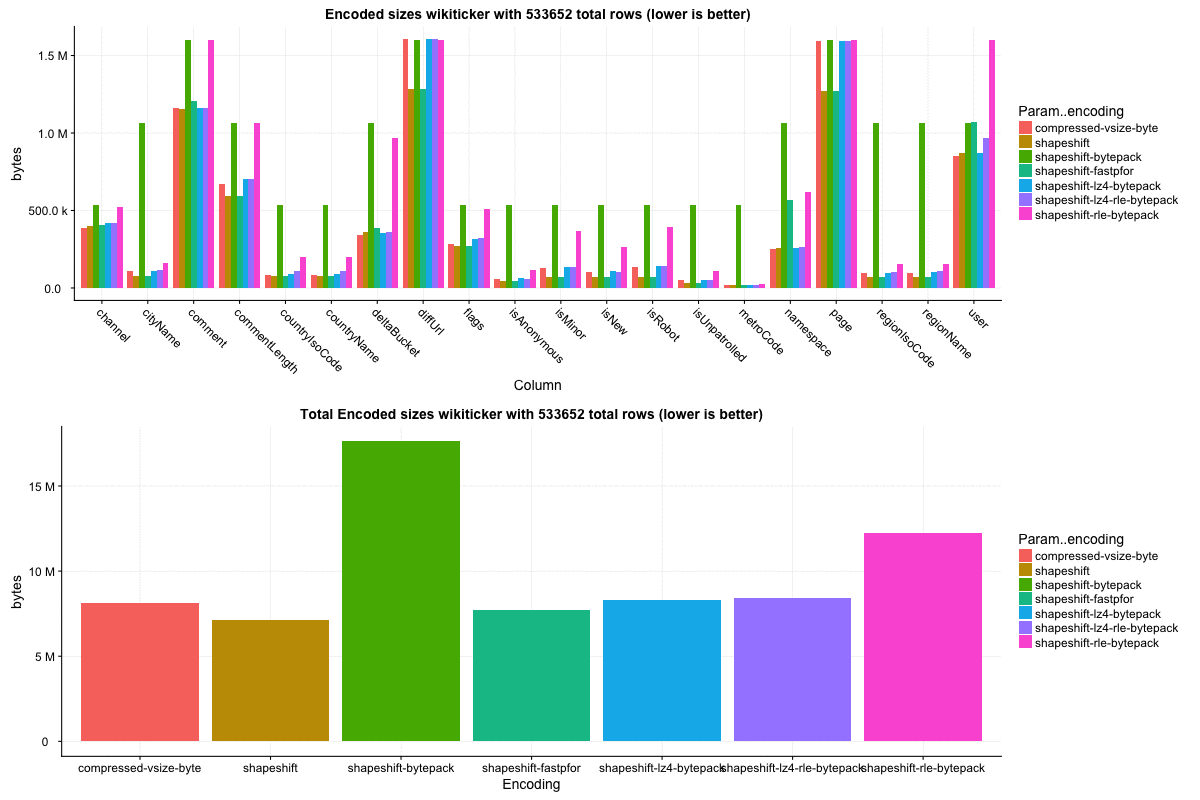
##### Datasource: 'Wikiticker'
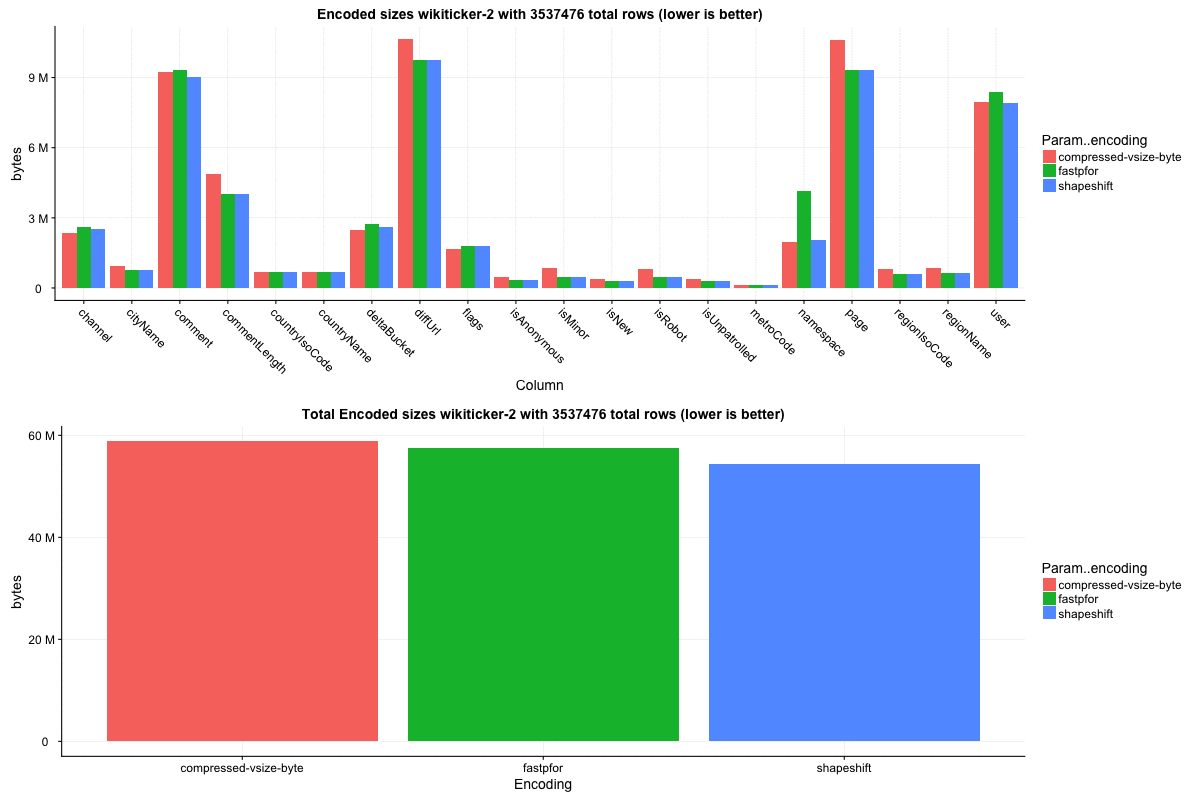
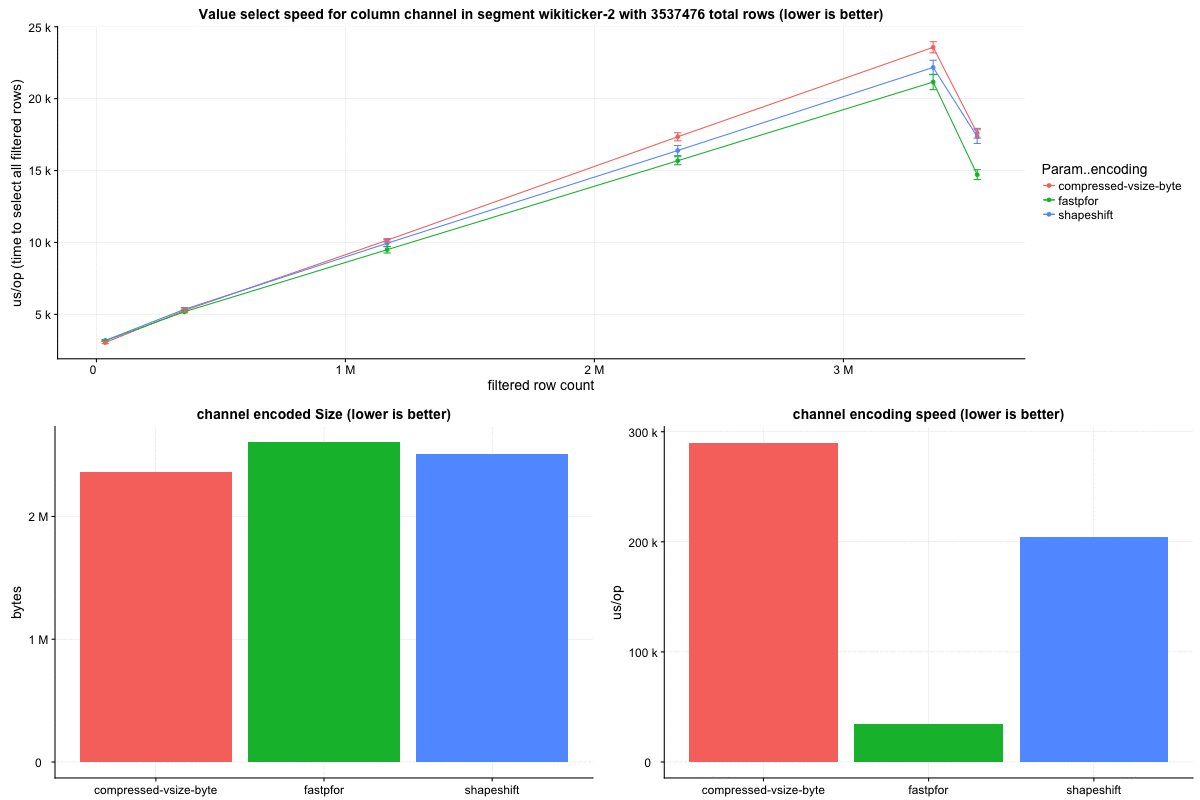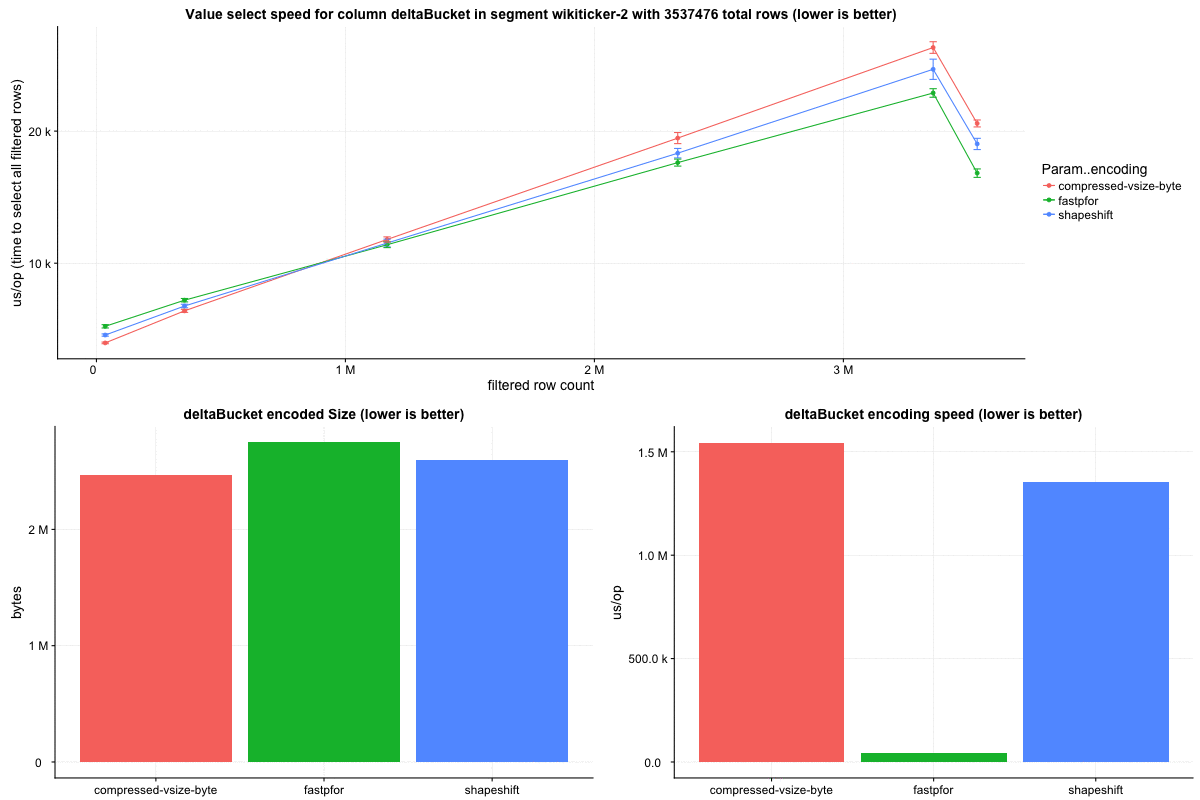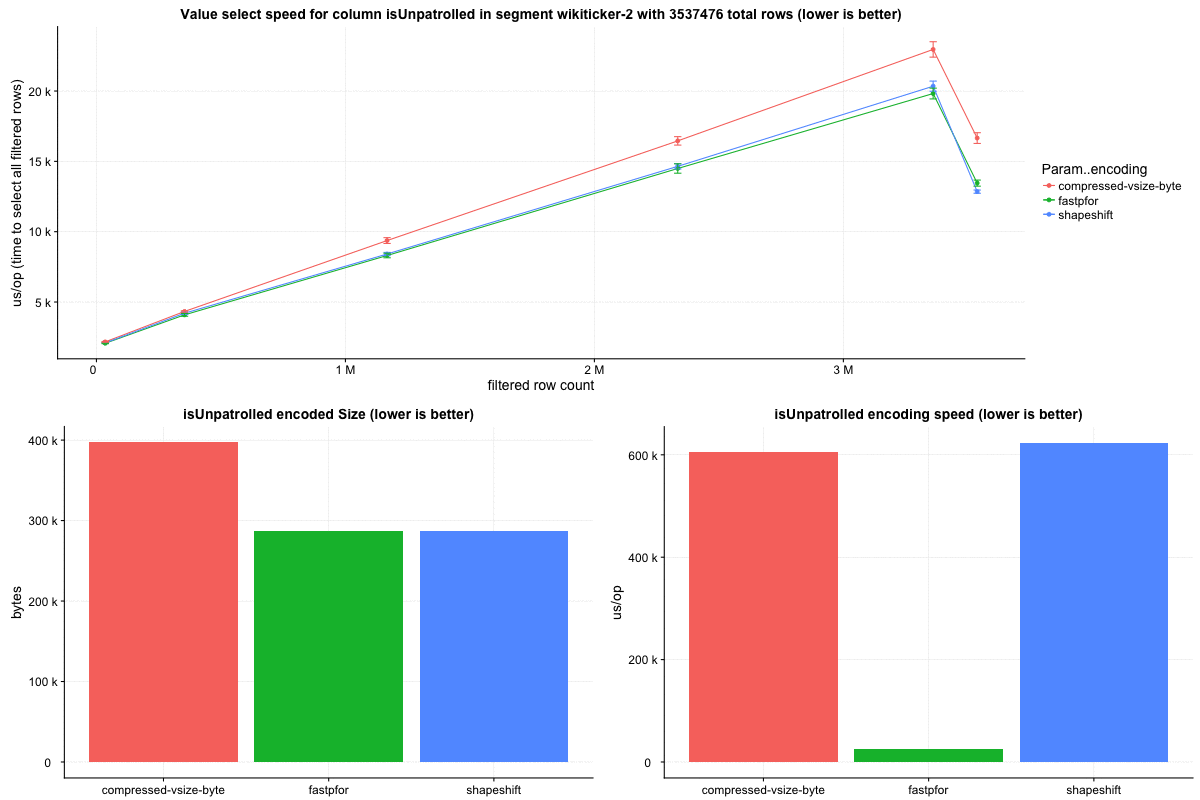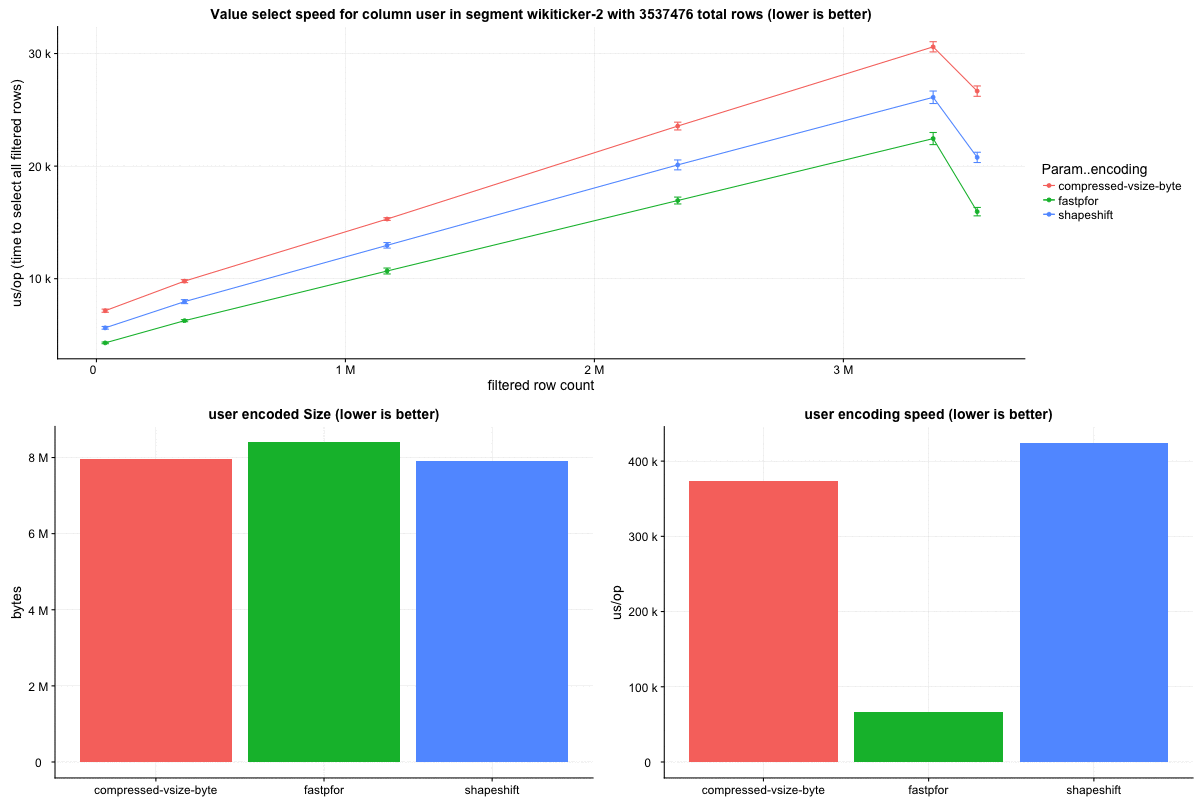
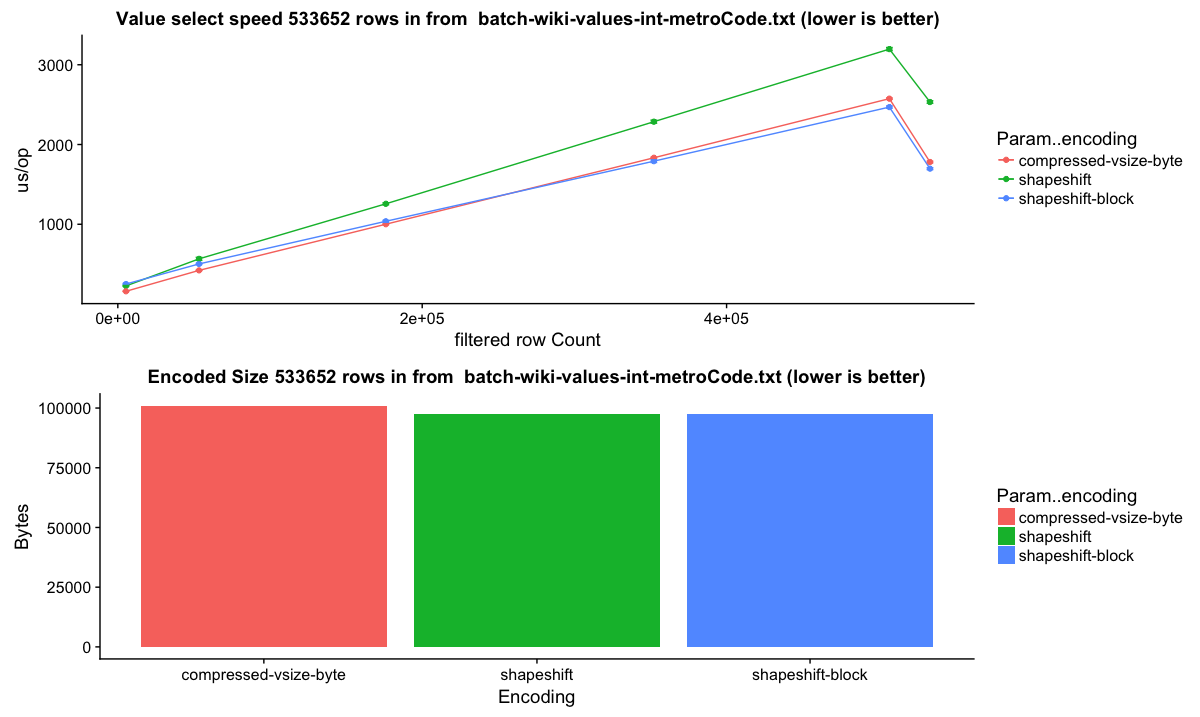
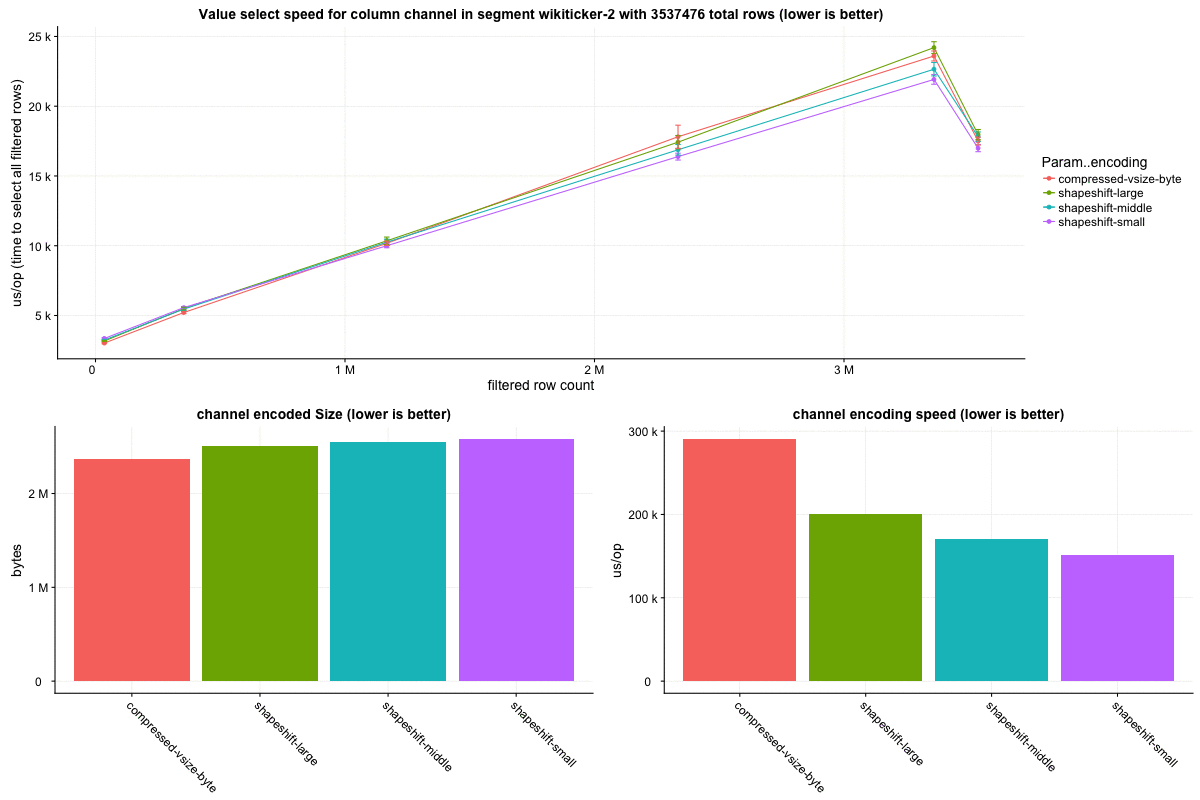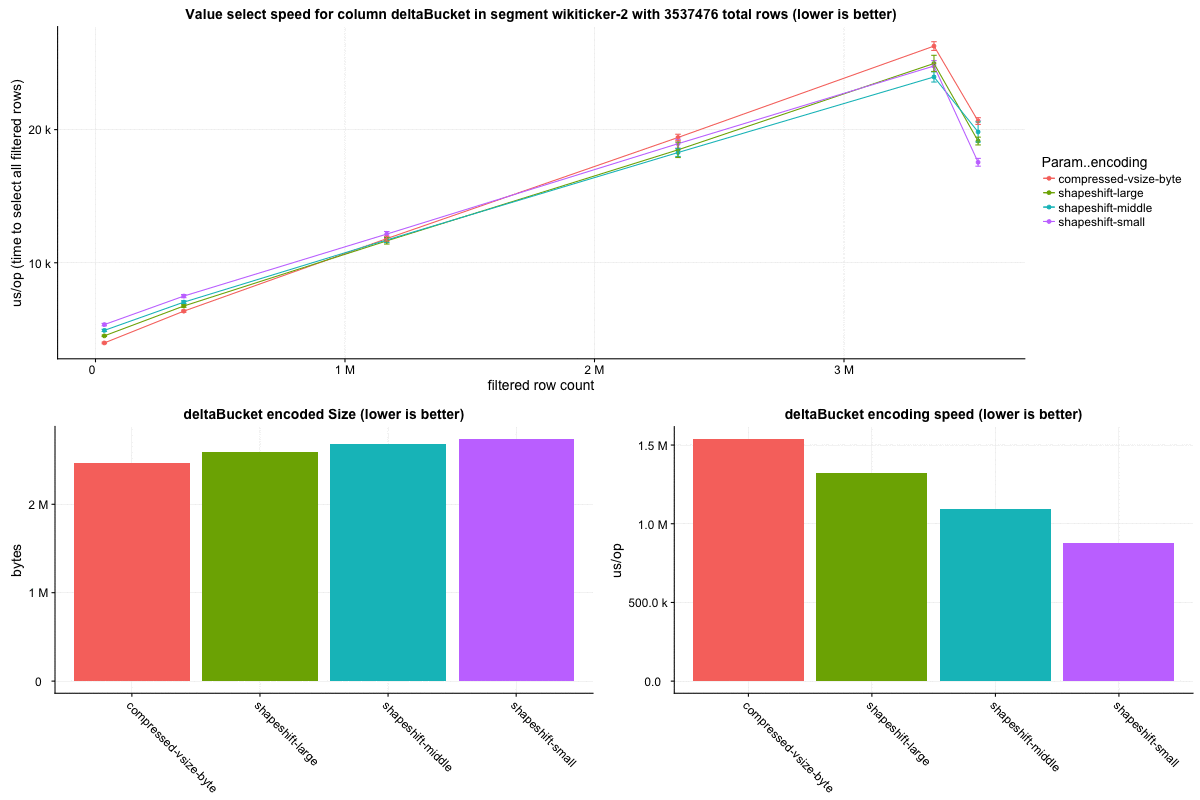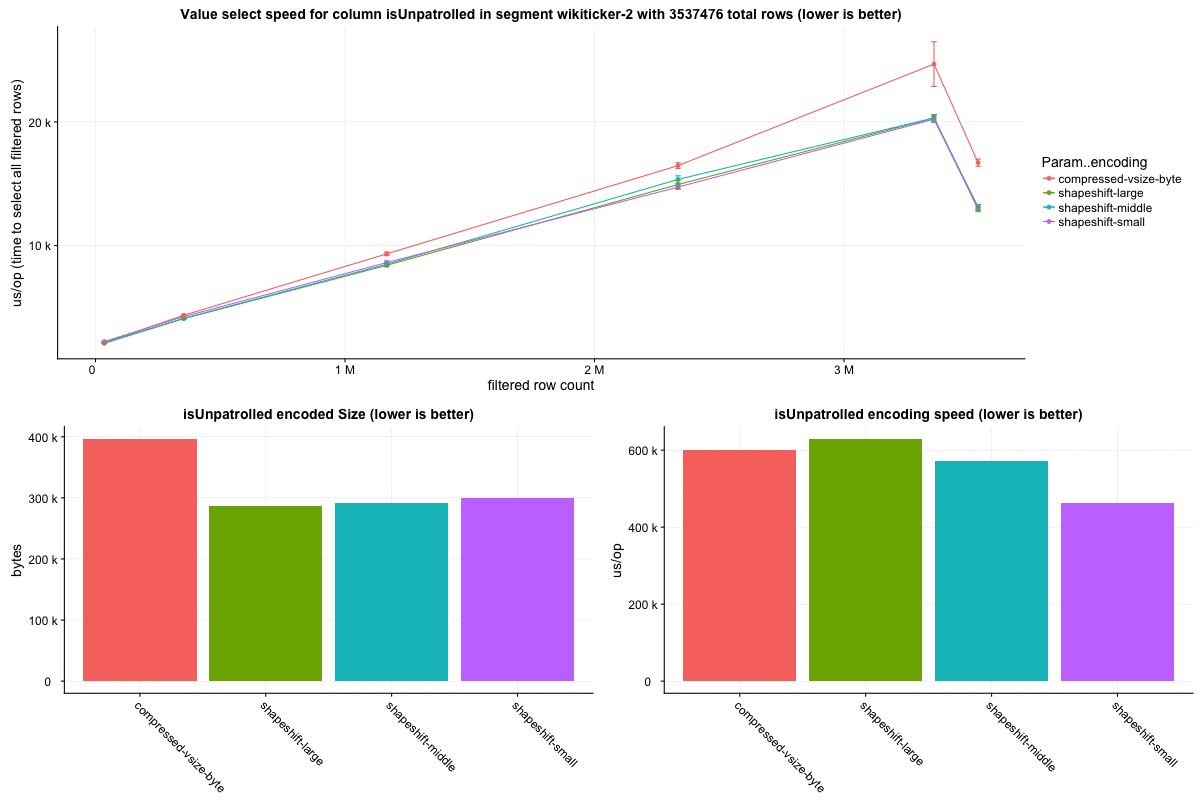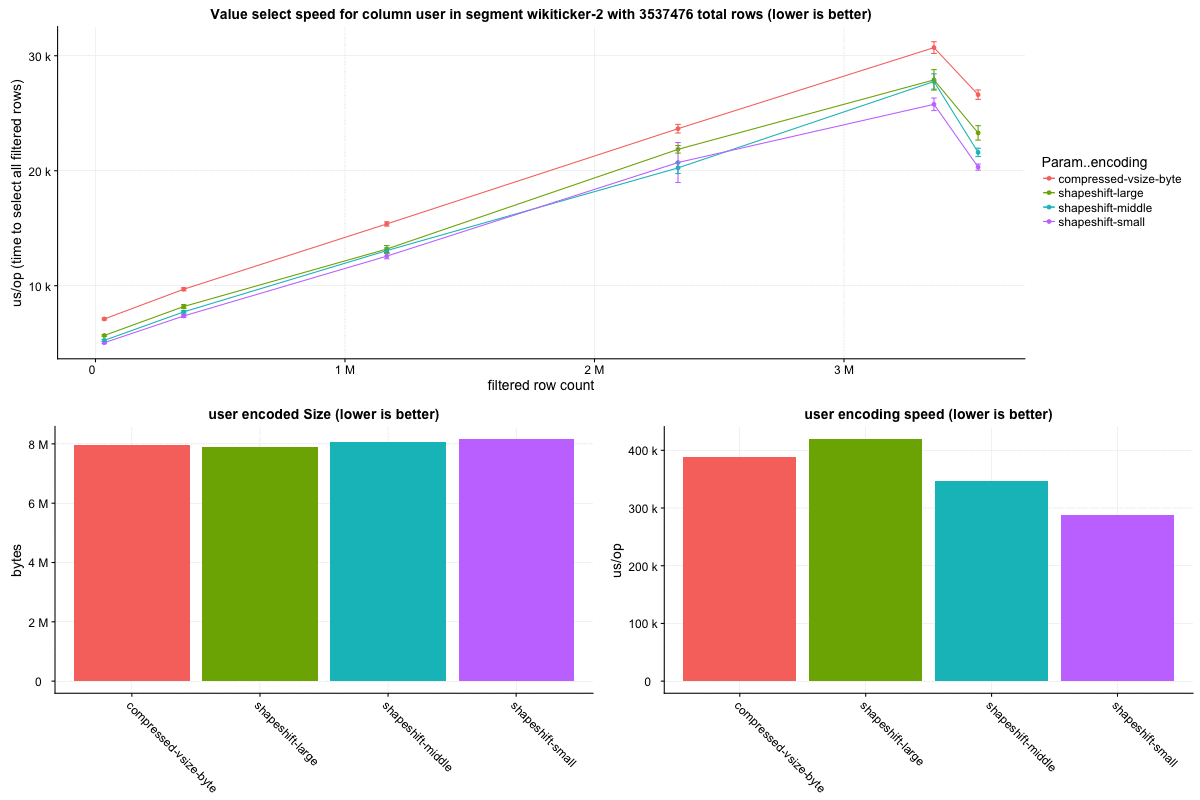
The `wikiticker` dataset is a relatively small volume realtime datasource on our test cluster that scrapes wikipedia edits from irc to feed into kafka for ingestion. Realtime segments are quite small, so I focused on compacted segments for benchmarks to be more in line with 'recommended' segment sizes, one partially compacted, with 500,000 rows and another fully compacted to ~3.5 million rows. In my observations `shapeshift` reduces int column sizes by 10-15%, with a notably faster scan time.
Column sizes:

Row select speed:

Query metrics collected on our test cluster corroborate with these lower level benchmark results, showing respectably better query speeds. To get a baseline I repeated the same set of queries every minute against the same datasources.
<img width="1445" alt="wiki-shapeshift-metrics" src="https://user-images.githubusercontent.com/1577461/42849938-3af69248-89da-11e8-9f55-05cc42c3c81d.png">
The segments were not exactly identical, but similar enough for comparison. The int column portion of wiki segments ranges from 5-15% of total smoosh size in my observations, and overall size reduction seems to be in the 1-5% range.
##### Datasource: 'Twitter'
Similar to 'wikiticker', the 'twitter' dataset is a realtime stream of twitter activity using the kafka indexing service. This dataset has smaller gains with shape shifting columns than wikipedia, but it still outperforms `CompressedVSizeColumnarInts` much of the time, even if only slightly.
Column sizes:

Row select speed:

##### Datasource: 'TPC-H Lineitem (1GB)'
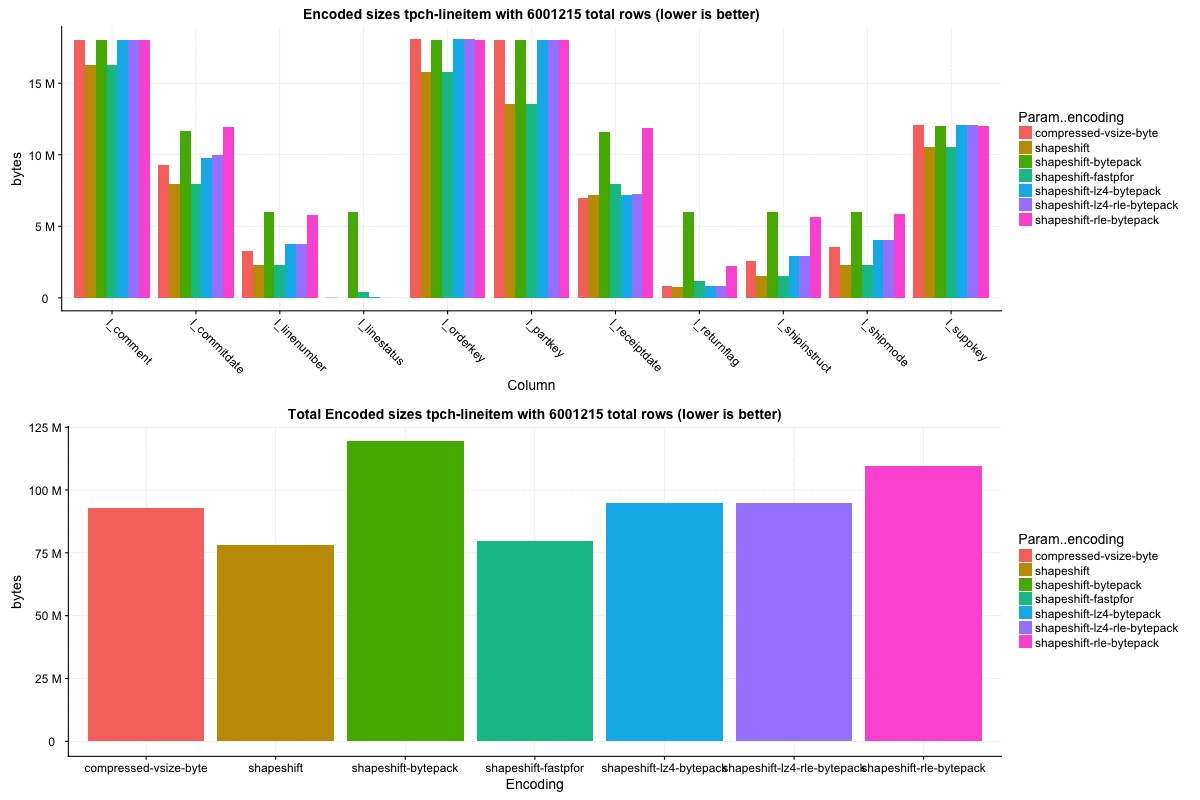
Segment created by ingesting 1GB of 'lineitem' schema adapted from the [tpc-h dataset](http://www.tpc.org/tpch/). This was a rather large segment with just over 6 million rows, and shape-shift does quite well here.
Column sizes:

Row select speed:

Integer columns overall are 15% smaller, and for many of the columns, select speeds are generally significantly faster. However, a few of the columns are marginally slower at low selectivity levels.
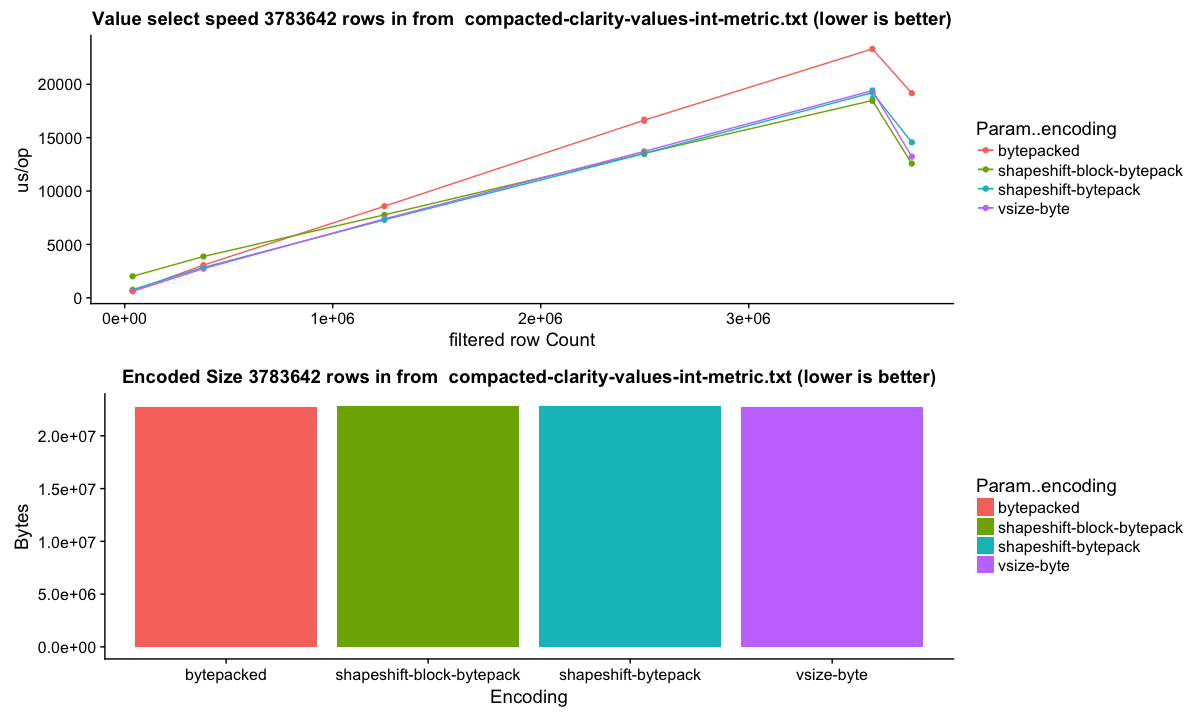
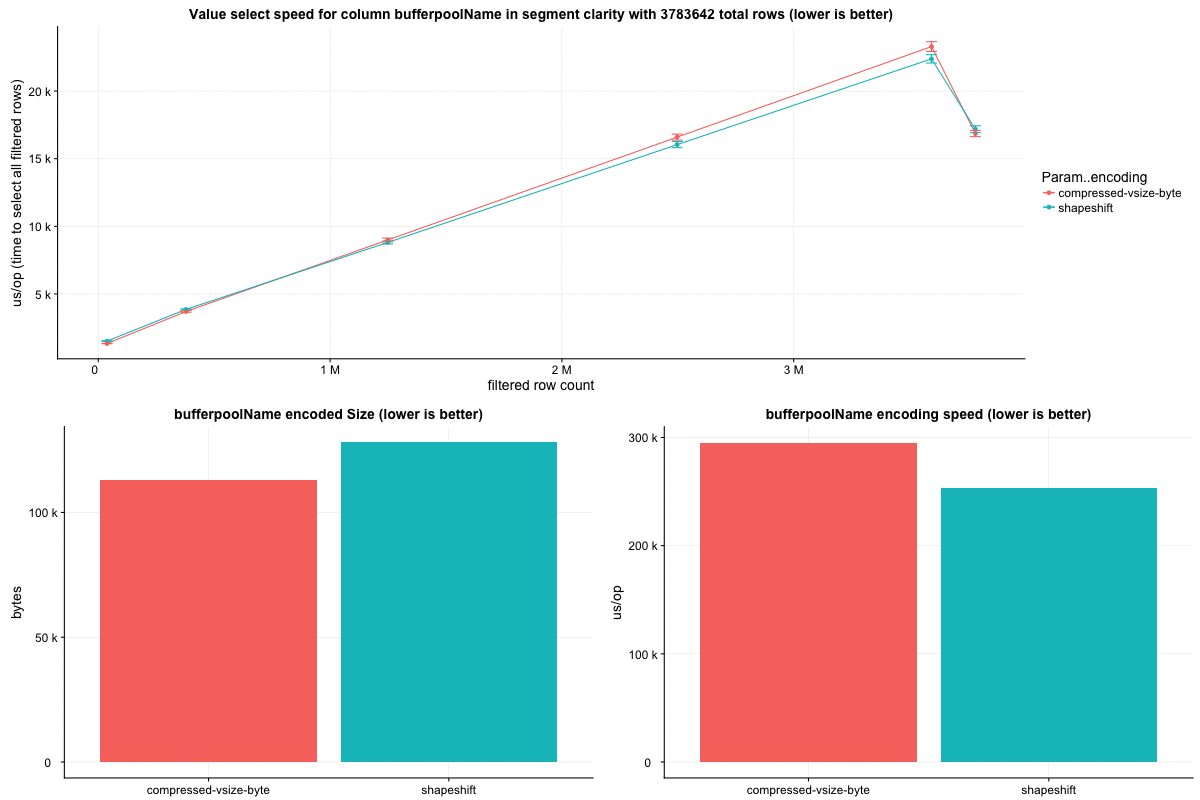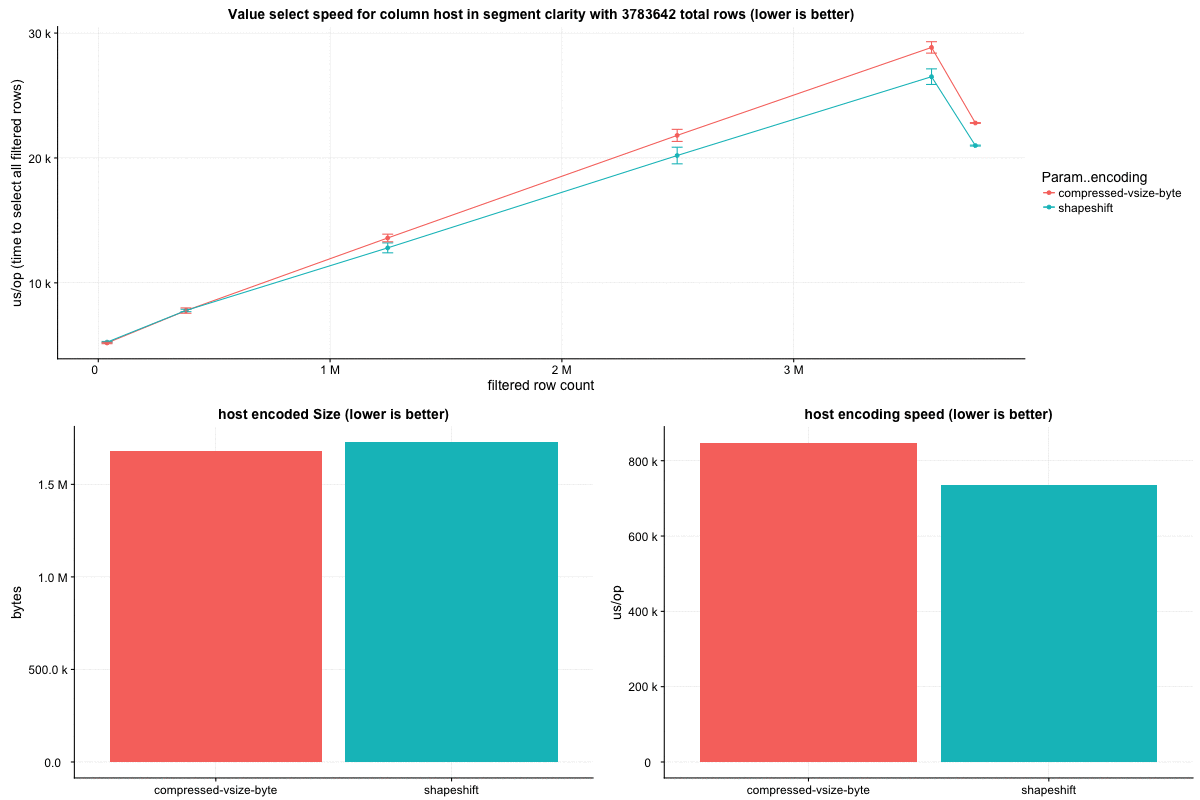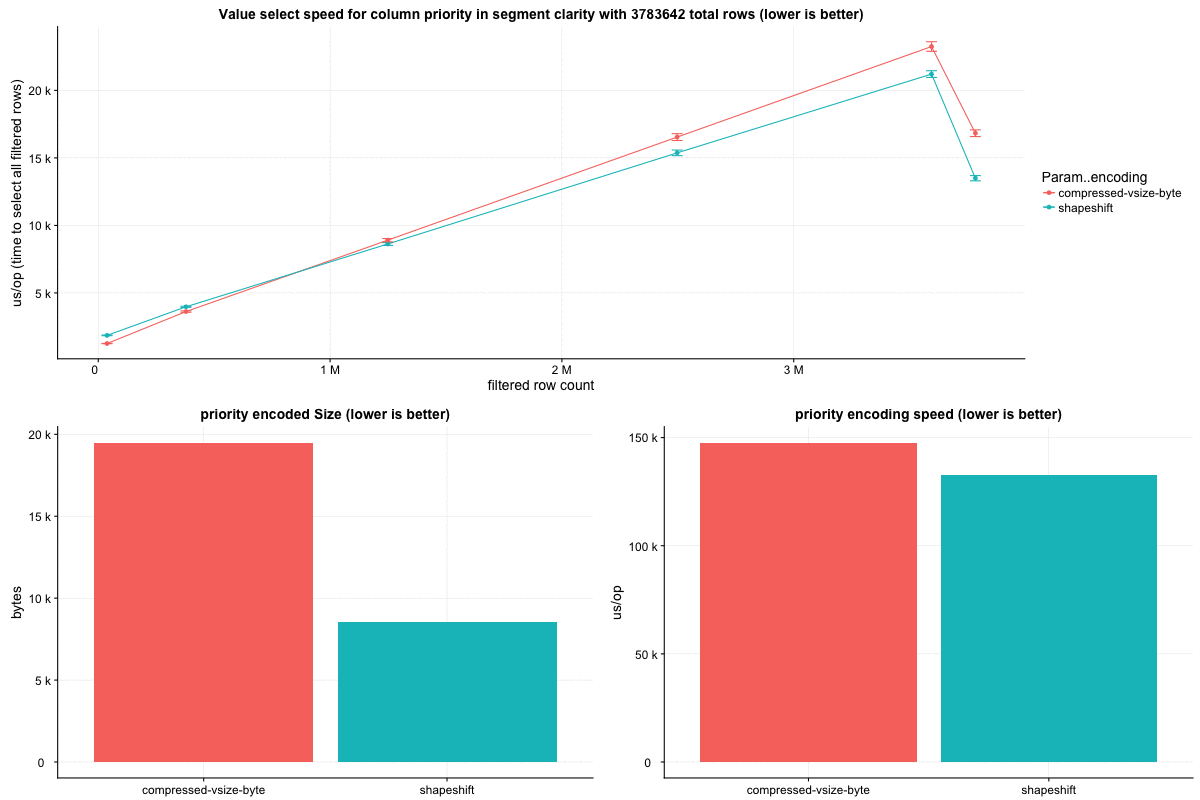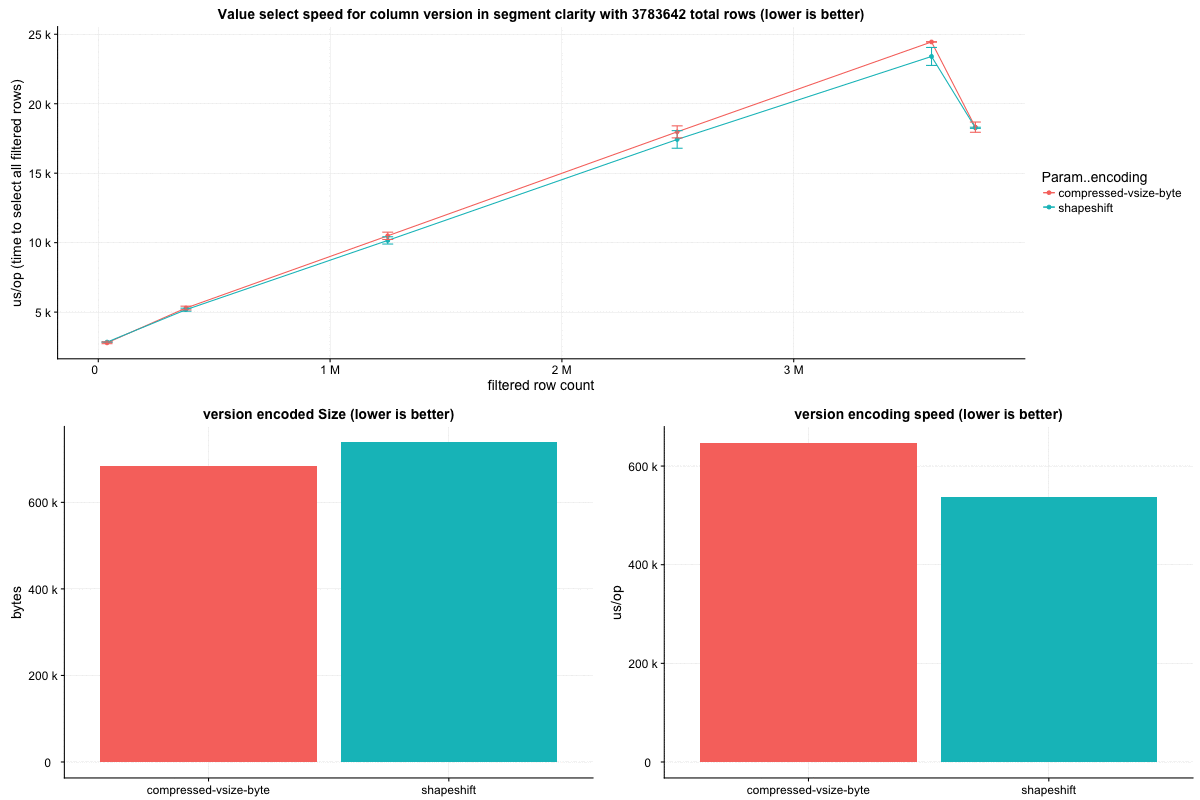
##### Datasource: 'Clarity' (metrics-like)
The 'clarity' dataset is one of our druid metrics datasources. Overall column size is actually larger here by 0.5%, but many of the columns have faster select speed.
Column sizes:
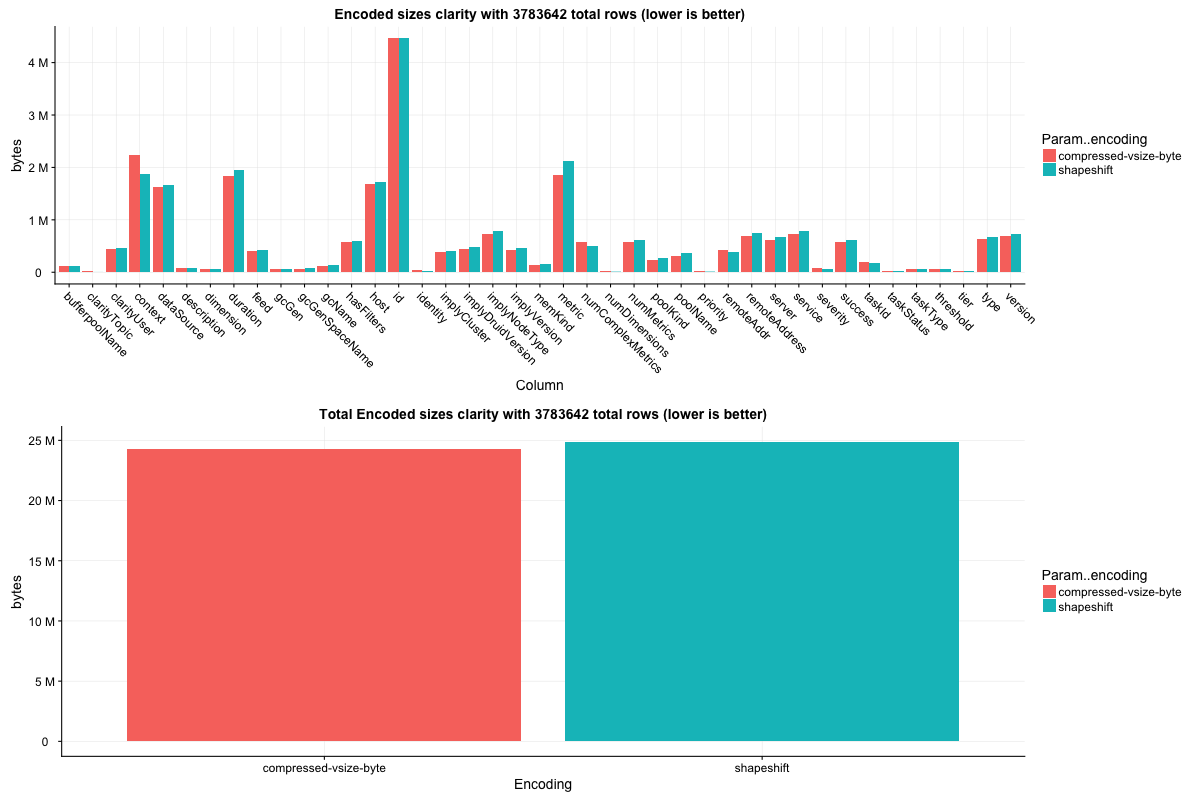
Row select speed:
Testing out a larger block size than is included in this PR, (64k values per block), this strategy can beat `CompressedVSizeColumnarInts` in overall encoded size:

but I'm on the fence about the memory footprint on blocks this large, and have not tested select speed.
## What's left
There are still a handful of things left to do, but don't anticipate any major changes and would welcome feedback on this. Thanks for sticking with it if you made it this far, I know this is absurdly long for a PR description 😜
### Todo:
- [ ] Tighten up configuration and control knobs
- [ ] Clean up 'todo' comments in code
- [ ] More thorough unit tests
- [ ] Test more segments from more datasources
- [ ] Stress test a test cluster to find where stuff falls over. We've had this PR running in our test cluster for over a month mirror indexing a few datasources, but have yet to really hammer it.
- [ ] Convince other people to test their own segments to confirm my results
- [ ] Seriously, convince more people to test segments
## Future Work
* Extend strategy to all numerical columns
* Smarter StupidPool that adapts object max cache size to load (or external library)
* More experiments with encoding types, JNI based decoder experiments using native versions of eager decoded algorithms like fastpfor and rle, to see if performance can be increased and column structure simplified by avoid the need for primitive arrays
* Encoders/decoders as extension points
* Collect metrics about encoded column composition
* Investigation if a sort of metrics feedback loop could help reduce encoding time by eliminating encoders which will likely perform poorly or any other enhancements to make indexing smarter and more efficient
[plot-column-bench.R.zip](https://github.com/apache/incubator-druid/files/2203886/plot-column-bench.R.zip)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: dev-unsubscribe@druid.apache.org
For additional commands, e-mail: dev-help@druid.apache.org