You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2021/08/18 18:12:53 UTC
[GitHub] [hudi] pratyakshsharma opened a new pull request #3496: Move content from cwiki to website (FAQ movement)
pratyakshsharma opened a new pull request #3496:
URL: https://github.com/apache/hudi/pull/3496
## *Tips*
- *Thank you very much for contributing to Apache Hudi.*
- *Please review https://hudi.apache.org/contribute/how-to-contribute before opening a pull request.*
## What is the purpose of the pull request
*(For example: This pull request adds quick-start document.)*
## Brief change log
*(for example:)*
- *Modify AnnotationLocation checkstyle rule in checkstyle.xml*
## Verify this pull request
*(Please pick either of the following options)*
This pull request is a trivial rework / code cleanup without any test coverage.
*(or)*
This pull request is already covered by existing tests, such as *(please describe tests)*.
(or)
This change added tests and can be verified as follows:
*(example:)*
- *Added integration tests for end-to-end.*
- *Added HoodieClientWriteTest to verify the change.*
- *Manually verified the change by running a job locally.*
## Committer checklist
- [ ] Has a corresponding JIRA in PR title & commit
- [ ] Commit message is descriptive of the change
- [ ] CI is green
- [ ] Necessary doc changes done or have another open PR
- [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #3496: Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#issuecomment-910407088
@pratyakshsharma thanks for doing this. the page itself looks good. however, there may be some broken links here. esp links to configs. Could we also fix that in this PR.
+1 on deleting the previous page.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar merged pull request #3496: [HUDI-2416] Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
vinothchandar merged pull request #3496:
URL: https://github.com/apache/hudi/pull/3496
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on a change in pull request #3496: [HUDI-2416] Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on a change in pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#discussion_r714347494
##########
File path: website/learn/faq.md
##########
@@ -0,0 +1,440 @@
+---
+title: FAQs
+keywords: [hudi, writing, reading]
+last_modified_at: 2021-08-18T15:59:57-04:00
+---
+# FAQs
+
+## General
+
+### When is Hudi useful for me or my organization?
+
+If you are looking to quickly ingest data onto HDFS or cloud storage, Hudi can provide you tools to [help](https://hudi.apache.org/docs/writing_data/). Also, if you have ETL/hive/spark jobs which are slow/taking up a lot of resources, Hudi can potentially help by providing an incremental approach to reading and writing data.
+
+As an organization, Hudi can help you build an [efficient data lake](https://docs.google.com/presentation/d/1FHhsvh70ZP6xXlHdVsAI0g__B_6Mpto5KQFlZ0b8-mM/edit#slide=id.p), solving some of the most complex, low-level storage management problems, while putting data into hands of your data analysts, engineers and scientists much quicker.
+
+### What are some non-goals for Hudi?
+
+Hudi is not designed for any OLTP use-cases, where typically you are using existing NoSQL/RDBMS data stores. Hudi cannot replace your in-memory analytical database (at-least not yet!). Hudi support near-real time ingestion in the order of few minutes, trading off latency for efficient batching. If you truly desirable sub-minute processing delays, then stick with your favorite stream processing solution.
+
+### What is incremental processing? Why does Hudi docs/talks keep talking about it?
+
+Incremental processing was first introduced by Vinoth Chandar, in the O'reilly [blog](https://www.oreilly.com/content/ubers-case-for-incremental-processing-on-hadoop/), that set off most of this effort. In purely technical terms, incremental processing merely refers to writing mini-batch programs in streaming processing style. Typical batch jobs consume **all input** and recompute **all output**, every few hours. Typical stream processing jobs consume some **new input** and recompute **new/changes to output**, continuously/every few seconds. While recomputing all output in batch fashion can be simpler, it's wasteful and resource expensive. Hudi brings ability to author the same batch pipelines in streaming fashion, run every few minutes.
+
+While we can merely refer to this as stream processing, we call it *incremental processing*, to distinguish from purely stream processing pipelines built using Apache Flink, Apache Apex or Apache Kafka Streams.
+
+### What is the difference between copy-on-write (COW) vs merge-on-read (MOR) storage types?
+
+**Copy On Write** - This storage type enables clients to ingest data on columnar file formats, currently parquet. Any new data that is written to the Hudi dataset using COW storage type, will write new parquet files. Updating an existing set of rows will result in a rewrite of the entire parquet files that collectively contain the affected rows being updated. Hence, all writes to such datasets are limited by parquet writing performance, the larger the parquet file, the higher is the time taken to ingest the data.
+
+**Merge On Read** - This storage type enables clients to ingest data quickly onto row based data format such as avro. Any new data that is written to the Hudi dataset using MOR table type, will write new log/delta files that internally store the data as avro encoded bytes. A compaction process (configured as inline or asynchronous) will convert log file format to columnar file format (parquet). Two different InputFormats expose 2 different views of this data, Read Optimized view exposes columnar parquet reading performance while Realtime View exposes columnar and/or log reading performance respectively. Updating an existing set of rows will result in either a) a companion log/delta file for an existing base parquet file generated from a previous compaction or b) an update written to a log/delta file in case no compaction ever happened for it. Hence, all writes to such datasets are limited by avro/log file writing performance, much faster than parquet. Although, there is a higher co
st to pay to read log/delta files vs columnar (parquet) files.
+
+More details can be found [here](https://hudi.apache.org/docs/concepts/) and also [Design And Architecture](https://cwiki.apache.org/confluence/display/HUDI/Design+And+Architecture).
+
+### How do I choose a storage type for my workload?
+
+A key goal of Hudi is to provide **upsert functionality** that is orders of magnitude faster than rewriting entire tables or partitions.
+
+Choose Copy-on-write storage if :
+
+ - You are looking for a simple alternative, that replaces your existing parquet tables without any need for real-time data.
+ - Your current job is rewriting entire table/partition to deal with updates, while only a few files actually change in each partition.
+ - You are happy keeping things operationally simpler (no compaction etc), with the ingestion/write performance bound by the [parquet file size](https://hudi.apache.org/docs/configurations#hoodieparquetmaxfilesize) and the number of such files affected/dirtied by updates
+ - Your workload is fairly well-understood and does not have sudden bursts of large amount of update or inserts to older partitions. COW absorbs all the merging cost on the writer side and thus these sudden changes can clog up your ingestion and interfere with meeting normal mode ingest latency targets.
+
+Choose merge-on-read storage if :
+
+ - You want the data to be ingested as quickly & queryable as much as possible.
+ - Your workload can have sudden spikes/changes in pattern (e.g bulk updates to older transactions in upstream database causing lots of updates to old partitions on DFS). Asynchronous compaction helps amortize the write amplification caused by such scenarios, while normal ingestion keeps up with incoming stream of changes.
+
+Immaterial of what you choose, Hudi provides
+
+ - Snapshot isolation and atomic write of batch of records
+ - Incremental pulls
+ - Ability to de-duplicate data
+
+Find more [here](https://hudi.apache.org/docs/concepts/).
+
+### Is Hudi an analytical database?
+
+A typical database has a bunch of long running storage servers always running, which takes writes and reads. Hudi's architecture is very different and for good reasons. It's highly decoupled where writes and queries/reads can be scaled independently to be able to handle the scale challenges. So, it may not always seems like a database.
+
+Nonetheless, Hudi is designed very much like a database and provides similar functionality (upserts, change capture) and semantics (transactional writes, snapshot isolated reads).
+
+### How do I model the data stored in Hudi?
+
+When writing data into Hudi, you model the records like how you would on a key-value store - specify a key field (unique for a single partition/across dataset), a partition field (denotes partition to place key into) and preCombine/combine logic that specifies how to handle duplicates in a batch of records written. This model enables Hudi to enforce primary key constraints like you would get on a database table. See [here](https://hudi.apache.org/docs/writing_data/) for an example.
+
+When querying/reading data, Hudi just presents itself as a json-like hierarchical table, everyone is used to querying using Hive/Spark/Presto over Parquet/Json/Avro.
+
+### Does Hudi support cloud storage/object stores?
+
+Yes. Generally speaking, Hudi is able to provide its functionality on any Hadoop FileSystem implementation and thus can read and write datasets on [Cloud stores](https://hudi.apache.org/docs/cloud) (Amazon S3 or Microsoft Azure or Google Cloud Storage). Over time, Hudi has also incorporated specific design aspects that make building Hudi datasets on the cloud easy, such as [consistency checks for s3](https://hudi.apache.org/docs/configurations#hoodieconsistencycheckenabled), Zero moves/renames involved for data files.
+
+### What versions of Hive/Spark/Hadoop are support by Hudi?
+
+As of September 2019, Hudi can support Spark 2.1+, Hive 2.x, Hadoop 2.7+ (not Hadoop 3).
+
+### How does Hudi actually store data inside a dataset?
+
+At a high level, Hudi is based on MVCC design that writes data to versioned parquet/base files and log files that contain changes to the base file. All the files are stored under a partitioning scheme for the dataset, which closely resembles how Apache Hive tables are laid out on DFS. Please refer [here](https://hudi.apache.org/docs/concepts/) for more details.
+
+## Using Hudi
+
+### What are some ways to write a Hudi dataset?
+
+Typically, you obtain a set of partial updates/inserts from your source and issue [write operations](https://hudi.apache.org/docs/writing_data/) against a Hudi dataset. If you ingesting data from any of the standard sources like Kafka, or tailing DFS, the [delta streamer](https://hudi.apache.org/docs/writing_data/#deltastreamer) tool is invaluable and provides an easy, self-managed solution to getting data written into Hudi. You can also write your own code to capture data from a custom source using the Spark datasource API and use a [Hudi datasource](https://hudi.apache.org/docs/writing_data/#datasource-writer) to write into Hudi.
+
+### How is a Hudi job deployed?
+
+The nice thing about Hudi writing is that it just runs like any other spark job would on a YARN/Mesos or even a K8S cluster. So you could simply use the Spark UI to get visibility into write operations.
+
+### How can I now query the Hudi dataset I just wrote?
+
+Unless Hive sync is enabled, the dataset written by Hudi using one of the methods above can simply be queries via the Spark datasource like any other source.
+
+```scala
+val hoodieROView = spark.read.format("org.apache.hudi").load(basePath + "/path/to/partitions/*")
+val hoodieIncViewDF = spark.read().format("org.apache.hudi")
+ .option(DataSourceReadOptions.VIEW_TYPE_OPT_KEY(), DataSourceReadOptions.VIEW_TYPE_INCREMENTAL_OPT_VAL())
+ .option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY(), <beginInstantTime>)
+ .load(basePath);
+```
+
+```java
+Limitations:
+
+Note that currently the reading realtime view natively out of the Spark datasource is not supported. Please use the Hive path below
+```
+
+if Hive Sync is enabled in the [deltastreamer](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/docker/demo/sparksql-incremental.commands#L50) tool or [datasource](https://hudi.apache.org/docs/configurations#hoodiedatasourcehive_syncenable), the dataset is available in Hive as a couple of tables, that can now be read using HiveQL, Presto or SparkSQL. See [here](https://hudi.apache.org/docs/querying_data/) for more.
+
+### How does Hudi handle duplicate record keys in an input?
+
+When issuing an `upsert` operation on a dataset and the batch of records provided contains multiple entries for a given key, then all of them are reduced into a single final value by repeatedly calling payload class's [preCombine()](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/hudi-common/src/main/java/org/apache/hudi/common/model/HoodieRecordPayload.java#L40) method . By default, we pick the record with the greatest value (determined by calling .compareTo()) giving latest-write-wins style semantics. [This FAQ entry](https://hudi.apache.org/learn/faq#can-i-implement-my-own-logic-for-how-input-records-are-merged-with-record-on-storage) shows the interface for HoodieRecordPayload if you are interested.
+
+For an insert or bulk_insert operation, no such pre-combining is performed. Thus, if your input contains duplicates, the dataset would also contain duplicates. If you don't want duplicate records either issue an upsert or consider specifying option to de-duplicate input in either [datasource](https://hudi.apache.org/docs/configurations#hoodiedatasourcewriteinsertdropduplicates) or [deltastreamer](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/HoodieDeltaStreamer.java#L229).
+
+### Can I implement my own logic for how input records are merged with record on storage?
+
+Here is the payload interface that is used in Hudi to represent any hudi record.
+
+```java
+public interface HoodieRecordPayload<T extends HoodieRecordPayload> extends Serializable {
+ /**
+ * When more than one HoodieRecord have the same HoodieKey, this function combines them before attempting to insert/upsert by taking in a property map.
+ * Implementation can leverage the property to decide their business logic to do preCombine.
+ * @param another instance of another {@link HoodieRecordPayload} to be combined with.
+ * @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.
+ * @return the combined value
+ */
+ default T preCombine(T another, Properties properties);
+
+/**
+ * This methods lets you write custom merging/combining logic to produce new values as a function of current value on storage and whats contained
+ * in this object. Implementations can leverage properties if required.
+ * <p>
+ * eg:
+ * 1) You are updating counters, you may want to add counts to currentValue and write back updated counts
+ * 2) You may be reading DB redo logs, and merge them with current image for a database row on storage
+ * </p>
+ *
+ * @param currentValue Current value in storage, to merge/combine this payload with
+ * @param schema Schema used for record
+ * @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.
+ * @return new combined/merged value to be written back to storage. EMPTY to skip writing this record.
+ */
+ default Option<IndexedRecord> combineAndGetUpdateValue(IndexedRecord currentValue, Schema schema, Properties properties) throws IOException;
+
+/**
+ * Generates an avro record out of the given HoodieRecordPayload, to be written out to storage. Called when writing a new value for the given
+ * HoodieKey, wherein there is no existing record in storage to be combined against. (i.e insert) Return EMPTY to skip writing this record.
+ * Implementations can leverage properties if required.
+ * @param schema Schema used for record
+ * @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.
+ * @return the {@link IndexedRecord} to be inserted.
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
+ default Option<IndexedRecord> getInsertValue(Schema schema, Properties properties) throws IOException;
+
+/**
+ * This method can be used to extract some metadata from HoodieRecordPayload. The metadata is passed to {@code WriteStatus.markSuccess()} and
+ * {@code WriteStatus.markFailure()} in order to compute some aggregate metrics using the metadata in the context of a write success or failure.
+ * @return the metadata in the form of Map<String, String> if any.
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
+ default Option<Map<String, String>> getMetadata() {
+ return Option.empty();
+ }
+
+}
+```
+
+As you could see, ([combineAndGetUpdateValue(), getInsertValue()](https://github.com/apache/hudi/blob/master/hudi-common/src/main/java/org/apache/hudi/common/model/HoodieRecordPayload.java)) that control how the record on storage is combined with the incoming update/insert to generate the final value to be written back to storage. preCombine() is used to merge records within the same incoming batch.
+
+### How do I delete records in the dataset using Hudi?
+
+GDPR has made deletes a must-have tool in everyone's data management toolbox. Hudi supports both soft and hard deletes. For details on how to actually perform them, see [here](https://hudi.apache.org/docs/writing_data/#deletes).
+
+### Does deleted records appear in Hudi's incremental query results?
+
+Soft Deletes (unlike hard deletes) do appear in the incremental pull query results. So, if you need a mechanism to propagate deletes to downstream tables, you can use Soft deletes.
+
+### How do I migrate my data to Hudi?
+
+Hudi provides built in support for rewriting your entire dataset into Hudi one-time using the HDFSParquetImporter tool available from the hudi-cli . You could also do this via a simple read and write of the dataset using the Spark datasource APIs. Once migrated, writes can be performed using normal means discussed [here](https://hudi.apache.org/learn/faq#what-are-some-ways-to-write-a-hudi-dataset). This topic is discussed in detail [here](https://hudi.apache.org/docs/migration_guide/), including ways to doing partial migrations.
+
+### How can I pass hudi configurations to my spark job?
+
+Hudi configuration options covering the datasource and low level Hudi write client (which both deltastreamer & datasource internally call) are [here](https://hudi.apache.org/docs/configurations/). Invoking *--help* on any tool such as DeltaStreamer would print all the usage options. A lot of the options that control upsert, file sizing behavior are defined at the write client level and below is how we pass them to different options available for writing data.
+
+ - For Spark DataSource, you can use the "options" API of DataFrameWriter to pass in these configs.
+
+```scala
+inputDF.write().format("org.apache.hudi")
+ .options(clientOpts) // any of the Hudi client opts can be passed in as well
+ .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY(), "_row_key")
+ ...
+```
+
+ - When using `HoodieWriteClient` directly, you can simply construct HoodieWriteConfig object with the configs in the link you mentioned.
+
+ - When using HoodieDeltaStreamer tool to ingest, you can set the configs in properties file and pass the file as the cmdline argument "*--props*"
+
+### How to create Hive style partition folder structure?
+
+By default Hudi creates the partition folders with just the partition values, but if would like to create partition folders similar to the way Hive will generate the structure, with paths that contain key value pairs, like country=us/… or datestr=2021-04-20. This is Hive style (or format) partitioning. The paths include both the names of the partition keys and the values that each path represents.
+
+To enable hive style partitioning, you need to add this hoodie config when you write your data:
+```java
+hoodie.datasource.write.hive_style_partitioning: true
+```
+
+### How do I pass hudi configurations to my beeline Hive queries?
+
+If Hudi's input format is not picked the returned results may be incorrect. To ensure correct inputformat is picked, please use `org.apache.hadoop.hive.ql.io.HiveInputFormat` or `org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat` for `hive.input.format` config. This can be set like shown below:
+```java
+set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat
+```
+
+or
+
+```java
+set hive.input.format=org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat
+```
+
+### Can I register my Hudi dataset with Apache Hive metastore?
+
+Yes. This can be performed either via the standalone [Hive Sync tool](https://hudi.apache.org/docs/writing_data/#syncing-to-hive) or using options in [deltastreamer](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/docker/demo/sparksql-incremental.commands#L50) tool or [datasource](https://hudi.apache.org/docs/configurations#hoodiedatasourcehive_syncenable).
+
+### How does the Hudi indexing work & what are its benefits?
+
+The indexing component is a key part of the Hudi writing and it maps a given recordKey to a fileGroup inside Hudi consistently. This enables faster identification of the file groups that are affected/dirtied by a given write operation.
+
+Hudi supports a few options for indexing as below
+
+ - *HoodieBloomIndex (default)* : Uses a bloom filter and ranges information placed in the footer of parquet/base files (and soon log files as well)
+ - *HoodieGlobalBloomIndex* : The default indexing only enforces uniqueness of a key inside a single partition i.e the user is expected to know the partition under which a given record key is stored. This helps the indexing scale very well for even [very large datasets](https://eng.uber.com/uber-big-data-platform/). However, in some cases, it might be necessary instead to do the de-duping/enforce uniqueness across all partitions and the global bloom index does exactly that. If this is used, incoming records are compared to files across the entire dataset and ensure a recordKey is only present in one partition.
+ - *HBaseIndex* : Apache HBase is a key value store, typically found in close proximity to HDFS. You can also store the index inside HBase, which could be handy if you are already operating HBase.
+
+You can implement your own index if you'd like, by subclassing the `HoodieIndex` class and configuring the index class name in configs.
+
+### What does the Hudi cleaner do?
+
+The Hudi cleaner process often runs right after a commit and deltacommit and goes about deleting old files that are no longer needed. If you are using the incremental pull feature, then ensure you configure the cleaner to [retain sufficient amount of last commits](https://hudi.apache.org/docs/configurations#hoodiecleanercommitsretained) to rewind. Another consideration is to provide sufficient time for your long running jobs to finish running. Otherwise, the cleaner could delete a file that is being or could be read by the job and will fail the job. Typically, the default configuration of 10 allows for an ingestion running every 30 mins to retain up-to 5 hours worth of data. If you run ingestion more frequently or if you want to give more running time for a query, consider increasing the value for the config : `hoodie.cleaner.commits.retained`
+
+### What's Hudi's schema evolution story?
+
+Hudi uses Avro as the internal canonical representation for records, primarily due to its nice [schema compatibility & evolution](https://docs.confluent.io/platform/current/schema-registry/avro.html) properties. This is a key aspect of having reliability in your ingestion or ETL pipelines. As long as the schema passed to Hudi (either explicitly in DeltaStreamer schema provider configs or implicitly by Spark Datasource's Dataset schemas) is backwards compatible (e.g no field deletes, only appending new fields to schema), Hudi will seamlessly handle read/write of old and new data and also keep the Hive schema up-to date.
+
+### How do I run compaction for a MOR dataset?
+
+Simplest way to run compaction on MOR dataset is to run the [compaction inline](https://hudi.apache.org/docs/configurations#hoodiecompactinline), at the cost of spending more time ingesting; This could be particularly useful, in common cases where you have small amount of late arriving data trickling into older partitions. In such a scenario, you may want to just aggressively compact the last N partitions while waiting for enough logs to accumulate for older partitions. The net effect is that you have converted most of the recent data, that is more likely to be queried to optimized columnar format.
+
+That said, for obvious reasons of not blocking ingesting for compaction, you may want to run it asynchronously as well. This can be done either via a separate [compaction job](https://github.com/apache/hudi/blob/master/hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactor.java) that is scheduled by your workflow scheduler/notebook independently. If you are using delta streamer, then you can run in [continuous mode](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/HoodieDeltaStreamer.java#L241) where the ingestion and compaction are both managed concurrently in a single spark run time.
+
+### What performance/ingest latency can I expect for Hudi writing?
+
+The speed at which you can write into Hudi depends on the [write operation](https://hudi.apache.org/docs/writing_data/) and some trade-offs you make along the way like file sizing. Just like how databases incur overhead over direct/raw file I/O on disks, Hudi operations may have overhead from supporting database like features compared to reading/writing raw DFS files. That said, Hudi implements advanced techniques from database literature to keep these minimal. User is encouraged to have this perspective when trying to reason about Hudi performance. As the saying goes : there is no free lunch (not yet atleast)
+
+| Storage Type | Type of workload | Performance | Tips |
+|-------|--------|--------|--------|
+| copy on write | bulk_insert | Should match vanilla spark writing + an additional sort to properly size files | properly size [bulk insert parallelism](https://hudi.apache.org/docs/configurations#hoodiebulkinsertshuffleparallelism) to get right number of files. use insert if you want this auto tuned |
+| copy on write | insert | Similar to bulk insert, except the file sizes are auto tuned requiring input to be cached into memory and custom partitioned. | Performance would be bound by how parallel you can write the ingested data. Tune [this limit](https://hudi.apache.org/docs/configurations#hoodieinsertshuffleparallelism) up, if you see that writes are happening from only a few executors. |
+| copy on write | upsert/ de-duplicate & insert | Both of these would involve index lookup. Compared to naively using Spark (or similar framework)'s JOIN to identify the affected records, Hudi indexing is often 7-10x faster as long as you have ordered keys (discussed below) or <50% updates. Compared to naively overwriting entire partitions, Hudi write can be several magnitudes faster depending on how many files in a given partition is actually updated. For e.g, if a partition has 1000 files out of which only 100 is dirtied every ingestion run, then Hudi would only read/merge a total of 100 files and thus 10x faster than naively rewriting entire partition. | Ultimately performance would be bound by how quickly we can read and write a parquet file and that depends on the size of the parquet file, configured [here](https://hudi.apache.org/docs/configurations#hoodieparquetmaxfilesize). Also be sure to properly tune your [bloom filters](https://hudi.apache.org/docs/configurations#Index-
Configs). [HUDI-56](https://issues.apache.org/jira/browse/HUDI-56) will auto-tune this. |
+| merge on read | bulk insert | Currently new data only goes to parquet files and thus performance here should be similar to copy_on_write bulk insert. This has the nice side-effect of getting data into parquet directly for query performance. [HUDI-86](https://issues.apache.org/jira/browse/HUDI-86) will add support for logging inserts directly and this up drastically. | |
+| merge on read | insert | Similar to above | |
+| merge on read | upsert/ de-duplicate & insert | Indexing performance would remain the same as copy-on-write, while ingest latency for updates (costliest I/O operation in copy_on_write) are sent to log files and thus with asynchronous compaction provides very very good ingest performance with low write amplification. | |
+
+Like with many typical system that manage time-series data, Hudi performs much better if your keys have a timestamp prefix or monotonically increasing/decreasing. You can almost always achieve this. Even if you have UUID keys, you can follow tricks like [this](https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/) to get keys that are ordered. See also [Tuning Guide](https://cwiki.apache.org/confluence/display/HUDI/Tuning+Guide) for more tips on JVM and other configurations.
+
+### What performance can I expect for Hudi reading/queries?
+
+ - For ReadOptimized views, you can expect the same best in-class columnar query performance as a standard parquet table in Hive/Spark/Presto
+ - For incremental views, you can expect speed up relative to how much data usually changes in a given time window and how much time your entire scan takes. For e.g, if only 100 files changed in the last hour in a partition of 1000 files, then you can expect a speed of 10x using incremental pull in Hudi compared to full scanning the partition to find out new data.
+ - For real time views, you can expect performance similar to the same avro backed table in Hive/Spark/Presto
+
+### How do I to avoid creating tons of small files?
+
+A key design decision in Hudi was to avoid creating small files and always write properly sized files.
+
+There are 2 ways to avoid creating tons of small files in Hudi and both of them have different trade-offs:
+
+a) **Auto Size small files during ingestion**: This solution trades ingest/writing time to keep queries always efficient. Common approaches to writing very small files and then later stitching them together only solve for system scalability issues posed by small files and also let queries slow down by exposing small files to them anyway.
+
+Hudi has the ability to maintain a configured target file size, when performing **upsert/insert** operations. (Note: **bulk_insert** operation does not provide this functionality and is designed as a simpler replacement for normal `spark.write.parquet` )
+
+For **copy-on-write**, this is as simple as configuring the [maximum size for a base/parquet file](https://hudi.apache.org/docs/configurations#hoodieparquetmaxfilesize) and the [soft limit](https://hudi.apache.org/docs/configurations#hoodieparquetsmallfilelimit) below which a file should be considered a small file. For the initial bootstrap to Hudi table, tuning record size estimate is also important to ensure sufficient records are bin-packed in a parquet file. For subsequent writes, Hudi automatically uses average record size based on previous commit. Hudi will try to add enough records to a small file at write time to get it to the configured maximum limit. For e.g , with `compactionSmallFileSize=100MB` and limitFileSize=120MB, Hudi will pick all files < 100MB and try to get them upto 120MB.
+
+For **merge-on-read**, there are few more configs to set. MergeOnRead works differently for different INDEX choices.
+
+ - Indexes with **canIndexLogFiles = true** : Inserts of new data go directly to log files. In this case, you can configure the [maximum log size](https://hudi.apache.org/docs/configurations#hoodielogfilemaxsize) and a [factor](https://hudi.apache.org/docs/configurations#hoodielogfiletoparquetcompressionratio) that denotes reduction in size when data moves from avro to parquet files.
Review comment:
this is a per index property. i.e not configurable.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] pratyakshsharma commented on pull request #3496: Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
pratyakshsharma commented on pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#issuecomment-917389381
@vinothchandar Please take a look. Fixed all the broken links now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #3496: Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#issuecomment-910864802
I do think there are some.
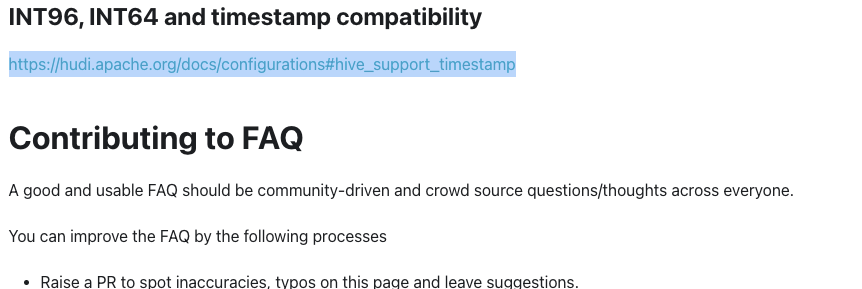
e.g https://hudi.apache.org/docs/configurations#hive_support_timestamp instead of
https://hudi.apache.org/docs/configurations/#hoodiedatasourcehive_syncsupport_timestamp
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on pull request #3496: [HUDI-2416] Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#issuecomment-925367776
Thanks for this @pratyakshsharma !
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] pratyakshsharma commented on a change in pull request #3496: [HUDI-2416] Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
pratyakshsharma commented on a change in pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#discussion_r706600974
##########
File path: website/learn/faq.md
##########
@@ -0,0 +1,440 @@
+---
+title: FAQs
+keywords: [hudi, writing, reading]
+last_modified_at: 2021-08-18T15:59:57-04:00
+---
+# FAQs
+
+## General
+
+### When is Hudi useful for me or my organization?
+
+If you are looking to quickly ingest data onto HDFS or cloud storage, Hudi can provide you tools to [help](https://hudi.apache.org/docs/writing_data/). Also, if you have ETL/hive/spark jobs which are slow/taking up a lot of resources, Hudi can potentially help by providing an incremental approach to reading and writing data.
+
+As an organization, Hudi can help you build an [efficient data lake](https://docs.google.com/presentation/d/1FHhsvh70ZP6xXlHdVsAI0g__B_6Mpto5KQFlZ0b8-mM/edit#slide=id.p), solving some of the most complex, low-level storage management problems, while putting data into hands of your data analysts, engineers and scientists much quicker.
+
+### What are some non-goals for Hudi?
+
+Hudi is not designed for any OLTP use-cases, where typically you are using existing NoSQL/RDBMS data stores. Hudi cannot replace your in-memory analytical database (at-least not yet!). Hudi support near-real time ingestion in the order of few minutes, trading off latency for efficient batching. If you truly desirable sub-minute processing delays, then stick with your favorite stream processing solution.
+
+### What is incremental processing? Why does Hudi docs/talks keep talking about it?
+
+Incremental processing was first introduced by Vinoth Chandar, in the O'reilly [blog](https://www.oreilly.com/content/ubers-case-for-incremental-processing-on-hadoop/), that set off most of this effort. In purely technical terms, incremental processing merely refers to writing mini-batch programs in streaming processing style. Typical batch jobs consume **all input** and recompute **all output**, every few hours. Typical stream processing jobs consume some **new input** and recompute **new/changes to output**, continuously/every few seconds. While recomputing all output in batch fashion can be simpler, it's wasteful and resource expensive. Hudi brings ability to author the same batch pipelines in streaming fashion, run every few minutes.
+
+While we can merely refer to this as stream processing, we call it *incremental processing*, to distinguish from purely stream processing pipelines built using Apache Flink, Apache Apex or Apache Kafka Streams.
+
+### What is the difference between copy-on-write (COW) vs merge-on-read (MOR) storage types?
+
+**Copy On Write** - This storage type enables clients to ingest data on columnar file formats, currently parquet. Any new data that is written to the Hudi dataset using COW storage type, will write new parquet files. Updating an existing set of rows will result in a rewrite of the entire parquet files that collectively contain the affected rows being updated. Hence, all writes to such datasets are limited by parquet writing performance, the larger the parquet file, the higher is the time taken to ingest the data.
+
+**Merge On Read** - This storage type enables clients to ingest data quickly onto row based data format such as avro. Any new data that is written to the Hudi dataset using MOR table type, will write new log/delta files that internally store the data as avro encoded bytes. A compaction process (configured as inline or asynchronous) will convert log file format to columnar file format (parquet). Two different InputFormats expose 2 different views of this data, Read Optimized view exposes columnar parquet reading performance while Realtime View exposes columnar and/or log reading performance respectively. Updating an existing set of rows will result in either a) a companion log/delta file for an existing base parquet file generated from a previous compaction or b) an update written to a log/delta file in case no compaction ever happened for it. Hence, all writes to such datasets are limited by avro/log file writing performance, much faster than parquet. Although, there is a higher co
st to pay to read log/delta files vs columnar (parquet) files.
+
+More details can be found [here](https://hudi.apache.org/docs/concepts/) and also [Design And Architecture](https://cwiki.apache.org/confluence/display/HUDI/Design+And+Architecture).
+
+### How do I choose a storage type for my workload?
+
+A key goal of Hudi is to provide **upsert functionality** that is orders of magnitude faster than rewriting entire tables or partitions.
+
+Choose Copy-on-write storage if :
+
+ - You are looking for a simple alternative, that replaces your existing parquet tables without any need for real-time data.
+ - Your current job is rewriting entire table/partition to deal with updates, while only a few files actually change in each partition.
+ - You are happy keeping things operationally simpler (no compaction etc), with the ingestion/write performance bound by the [parquet file size](https://hudi.apache.org/docs/configurations#hoodieparquetmaxfilesize) and the number of such files affected/dirtied by updates
+ - Your workload is fairly well-understood and does not have sudden bursts of large amount of update or inserts to older partitions. COW absorbs all the merging cost on the writer side and thus these sudden changes can clog up your ingestion and interfere with meeting normal mode ingest latency targets.
+
+Choose merge-on-read storage if :
+
+ - You want the data to be ingested as quickly & queryable as much as possible.
+ - Your workload can have sudden spikes/changes in pattern (e.g bulk updates to older transactions in upstream database causing lots of updates to old partitions on DFS). Asynchronous compaction helps amortize the write amplification caused by such scenarios, while normal ingestion keeps up with incoming stream of changes.
+
+Immaterial of what you choose, Hudi provides
+
+ - Snapshot isolation and atomic write of batch of records
+ - Incremental pulls
+ - Ability to de-duplicate data
+
+Find more [here](https://hudi.apache.org/docs/concepts/).
+
+### Is Hudi an analytical database?
+
+A typical database has a bunch of long running storage servers always running, which takes writes and reads. Hudi's architecture is very different and for good reasons. It's highly decoupled where writes and queries/reads can be scaled independently to be able to handle the scale challenges. So, it may not always seems like a database.
+
+Nonetheless, Hudi is designed very much like a database and provides similar functionality (upserts, change capture) and semantics (transactional writes, snapshot isolated reads).
+
+### How do I model the data stored in Hudi?
+
+When writing data into Hudi, you model the records like how you would on a key-value store - specify a key field (unique for a single partition/across dataset), a partition field (denotes partition to place key into) and preCombine/combine logic that specifies how to handle duplicates in a batch of records written. This model enables Hudi to enforce primary key constraints like you would get on a database table. See [here](https://hudi.apache.org/docs/writing_data/) for an example.
+
+When querying/reading data, Hudi just presents itself as a json-like hierarchical table, everyone is used to querying using Hive/Spark/Presto over Parquet/Json/Avro.
+
+### Does Hudi support cloud storage/object stores?
+
+Yes. Generally speaking, Hudi is able to provide its functionality on any Hadoop FileSystem implementation and thus can read and write datasets on [Cloud stores](https://hudi.apache.org/docs/cloud) (Amazon S3 or Microsoft Azure or Google Cloud Storage). Over time, Hudi has also incorporated specific design aspects that make building Hudi datasets on the cloud easy, such as [consistency checks for s3](https://hudi.apache.org/docs/configurations#hoodieconsistencycheckenabled), Zero moves/renames involved for data files.
+
+### What versions of Hive/Spark/Hadoop are support by Hudi?
+
+As of September 2019, Hudi can support Spark 2.1+, Hive 2.x, Hadoop 2.7+ (not Hadoop 3).
+
+### How does Hudi actually store data inside a dataset?
+
+At a high level, Hudi is based on MVCC design that writes data to versioned parquet/base files and log files that contain changes to the base file. All the files are stored under a partitioning scheme for the dataset, which closely resembles how Apache Hive tables are laid out on DFS. Please refer [here](https://hudi.apache.org/docs/concepts/) for more details.
+
+## Using Hudi
+
+### What are some ways to write a Hudi dataset?
+
+Typically, you obtain a set of partial updates/inserts from your source and issue [write operations](https://hudi.apache.org/docs/writing_data/) against a Hudi dataset. If you ingesting data from any of the standard sources like Kafka, or tailing DFS, the [delta streamer](https://hudi.apache.org/docs/writing_data/#deltastreamer) tool is invaluable and provides an easy, self-managed solution to getting data written into Hudi. You can also write your own code to capture data from a custom source using the Spark datasource API and use a [Hudi datasource](https://hudi.apache.org/docs/writing_data/#datasource-writer) to write into Hudi.
+
+### How is a Hudi job deployed?
+
+The nice thing about Hudi writing is that it just runs like any other spark job would on a YARN/Mesos or even a K8S cluster. So you could simply use the Spark UI to get visibility into write operations.
+
+### How can I now query the Hudi dataset I just wrote?
+
+Unless Hive sync is enabled, the dataset written by Hudi using one of the methods above can simply be queries via the Spark datasource like any other source.
+
+```scala
+val hoodieROView = spark.read.format("org.apache.hudi").load(basePath + "/path/to/partitions/*")
+val hoodieIncViewDF = spark.read().format("org.apache.hudi")
+ .option(DataSourceReadOptions.VIEW_TYPE_OPT_KEY(), DataSourceReadOptions.VIEW_TYPE_INCREMENTAL_OPT_VAL())
+ .option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY(), <beginInstantTime>)
+ .load(basePath);
+```
+
+```java
+Limitations:
+
+Note that currently the reading realtime view natively out of the Spark datasource is not supported. Please use the Hive path below
+```
+
+if Hive Sync is enabled in the [deltastreamer](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/docker/demo/sparksql-incremental.commands#L50) tool or [datasource](https://hudi.apache.org/docs/configurations#hoodiedatasourcehive_syncenable), the dataset is available in Hive as a couple of tables, that can now be read using HiveQL, Presto or SparkSQL. See [here](https://hudi.apache.org/docs/querying_data/) for more.
+
+### How does Hudi handle duplicate record keys in an input?
+
+When issuing an `upsert` operation on a dataset and the batch of records provided contains multiple entries for a given key, then all of them are reduced into a single final value by repeatedly calling payload class's [preCombine()](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/hudi-common/src/main/java/org/apache/hudi/common/model/HoodieRecordPayload.java#L40) method . By default, we pick the record with the greatest value (determined by calling .compareTo()) giving latest-write-wins style semantics. [This FAQ entry](https://hudi.apache.org/learn/faq#can-i-implement-my-own-logic-for-how-input-records-are-merged-with-record-on-storage) shows the interface for HoodieRecordPayload if you are interested.
+
+For an insert or bulk_insert operation, no such pre-combining is performed. Thus, if your input contains duplicates, the dataset would also contain duplicates. If you don't want duplicate records either issue an upsert or consider specifying option to de-duplicate input in either [datasource](https://hudi.apache.org/docs/configurations#hoodiedatasourcewriteinsertdropduplicates) or [deltastreamer](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/HoodieDeltaStreamer.java#L229).
+
+### Can I implement my own logic for how input records are merged with record on storage?
+
+Here is the payload interface that is used in Hudi to represent any hudi record.
+
+```java
+public interface HoodieRecordPayload<T extends HoodieRecordPayload> extends Serializable {
+ /**
+ * When more than one HoodieRecord have the same HoodieKey, this function combines them before attempting to insert/upsert by taking in a property map.
+ * Implementation can leverage the property to decide their business logic to do preCombine.
+ * @param another instance of another {@link HoodieRecordPayload} to be combined with.
+ * @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.
+ * @return the combined value
+ */
+ default T preCombine(T another, Properties properties);
+
+/**
+ * This methods lets you write custom merging/combining logic to produce new values as a function of current value on storage and whats contained
+ * in this object. Implementations can leverage properties if required.
+ * <p>
+ * eg:
+ * 1) You are updating counters, you may want to add counts to currentValue and write back updated counts
+ * 2) You may be reading DB redo logs, and merge them with current image for a database row on storage
+ * </p>
+ *
+ * @param currentValue Current value in storage, to merge/combine this payload with
+ * @param schema Schema used for record
+ * @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.
+ * @return new combined/merged value to be written back to storage. EMPTY to skip writing this record.
+ */
+ default Option<IndexedRecord> combineAndGetUpdateValue(IndexedRecord currentValue, Schema schema, Properties properties) throws IOException;
+
+/**
+ * Generates an avro record out of the given HoodieRecordPayload, to be written out to storage. Called when writing a new value for the given
+ * HoodieKey, wherein there is no existing record in storage to be combined against. (i.e insert) Return EMPTY to skip writing this record.
+ * Implementations can leverage properties if required.
+ * @param schema Schema used for record
+ * @param properties Payload related properties. For example pass the ordering field(s) name to extract from value in storage.
+ * @return the {@link IndexedRecord} to be inserted.
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
+ default Option<IndexedRecord> getInsertValue(Schema schema, Properties properties) throws IOException;
+
+/**
+ * This method can be used to extract some metadata from HoodieRecordPayload. The metadata is passed to {@code WriteStatus.markSuccess()} and
+ * {@code WriteStatus.markFailure()} in order to compute some aggregate metrics using the metadata in the context of a write success or failure.
+ * @return the metadata in the form of Map<String, String> if any.
+ */
+ @PublicAPIMethod(maturity = ApiMaturityLevel.STABLE)
+ default Option<Map<String, String>> getMetadata() {
+ return Option.empty();
+ }
+
+}
+```
+
+As you could see, ([combineAndGetUpdateValue(), getInsertValue()](https://github.com/apache/hudi/blob/master/hudi-common/src/main/java/org/apache/hudi/common/model/HoodieRecordPayload.java)) that control how the record on storage is combined with the incoming update/insert to generate the final value to be written back to storage. preCombine() is used to merge records within the same incoming batch.
+
+### How do I delete records in the dataset using Hudi?
+
+GDPR has made deletes a must-have tool in everyone's data management toolbox. Hudi supports both soft and hard deletes. For details on how to actually perform them, see [here](https://hudi.apache.org/docs/writing_data/#deletes).
+
+### Does deleted records appear in Hudi's incremental query results?
+
+Soft Deletes (unlike hard deletes) do appear in the incremental pull query results. So, if you need a mechanism to propagate deletes to downstream tables, you can use Soft deletes.
+
+### How do I migrate my data to Hudi?
+
+Hudi provides built in support for rewriting your entire dataset into Hudi one-time using the HDFSParquetImporter tool available from the hudi-cli . You could also do this via a simple read and write of the dataset using the Spark datasource APIs. Once migrated, writes can be performed using normal means discussed [here](https://hudi.apache.org/learn/faq#what-are-some-ways-to-write-a-hudi-dataset). This topic is discussed in detail [here](https://hudi.apache.org/docs/migration_guide/), including ways to doing partial migrations.
+
+### How can I pass hudi configurations to my spark job?
+
+Hudi configuration options covering the datasource and low level Hudi write client (which both deltastreamer & datasource internally call) are [here](https://hudi.apache.org/docs/configurations/). Invoking *--help* on any tool such as DeltaStreamer would print all the usage options. A lot of the options that control upsert, file sizing behavior are defined at the write client level and below is how we pass them to different options available for writing data.
+
+ - For Spark DataSource, you can use the "options" API of DataFrameWriter to pass in these configs.
+
+```scala
+inputDF.write().format("org.apache.hudi")
+ .options(clientOpts) // any of the Hudi client opts can be passed in as well
+ .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY(), "_row_key")
+ ...
+```
+
+ - When using `HoodieWriteClient` directly, you can simply construct HoodieWriteConfig object with the configs in the link you mentioned.
+
+ - When using HoodieDeltaStreamer tool to ingest, you can set the configs in properties file and pass the file as the cmdline argument "*--props*"
+
+### How to create Hive style partition folder structure?
+
+By default Hudi creates the partition folders with just the partition values, but if would like to create partition folders similar to the way Hive will generate the structure, with paths that contain key value pairs, like country=us/… or datestr=2021-04-20. This is Hive style (or format) partitioning. The paths include both the names of the partition keys and the values that each path represents.
+
+To enable hive style partitioning, you need to add this hoodie config when you write your data:
+```java
+hoodie.datasource.write.hive_style_partitioning: true
+```
+
+### How do I pass hudi configurations to my beeline Hive queries?
+
+If Hudi's input format is not picked the returned results may be incorrect. To ensure correct inputformat is picked, please use `org.apache.hadoop.hive.ql.io.HiveInputFormat` or `org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat` for `hive.input.format` config. This can be set like shown below:
+```java
+set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat
+```
+
+or
+
+```java
+set hive.input.format=org.apache.hudi.hadoop.hive.HoodieCombineHiveInputFormat
+```
+
+### Can I register my Hudi dataset with Apache Hive metastore?
+
+Yes. This can be performed either via the standalone [Hive Sync tool](https://hudi.apache.org/docs/writing_data/#syncing-to-hive) or using options in [deltastreamer](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/docker/demo/sparksql-incremental.commands#L50) tool or [datasource](https://hudi.apache.org/docs/configurations#hoodiedatasourcehive_syncenable).
+
+### How does the Hudi indexing work & what are its benefits?
+
+The indexing component is a key part of the Hudi writing and it maps a given recordKey to a fileGroup inside Hudi consistently. This enables faster identification of the file groups that are affected/dirtied by a given write operation.
+
+Hudi supports a few options for indexing as below
+
+ - *HoodieBloomIndex (default)* : Uses a bloom filter and ranges information placed in the footer of parquet/base files (and soon log files as well)
+ - *HoodieGlobalBloomIndex* : The default indexing only enforces uniqueness of a key inside a single partition i.e the user is expected to know the partition under which a given record key is stored. This helps the indexing scale very well for even [very large datasets](https://eng.uber.com/uber-big-data-platform/). However, in some cases, it might be necessary instead to do the de-duping/enforce uniqueness across all partitions and the global bloom index does exactly that. If this is used, incoming records are compared to files across the entire dataset and ensure a recordKey is only present in one partition.
+ - *HBaseIndex* : Apache HBase is a key value store, typically found in close proximity to HDFS. You can also store the index inside HBase, which could be handy if you are already operating HBase.
+
+You can implement your own index if you'd like, by subclassing the `HoodieIndex` class and configuring the index class name in configs.
+
+### What does the Hudi cleaner do?
+
+The Hudi cleaner process often runs right after a commit and deltacommit and goes about deleting old files that are no longer needed. If you are using the incremental pull feature, then ensure you configure the cleaner to [retain sufficient amount of last commits](https://hudi.apache.org/docs/configurations#hoodiecleanercommitsretained) to rewind. Another consideration is to provide sufficient time for your long running jobs to finish running. Otherwise, the cleaner could delete a file that is being or could be read by the job and will fail the job. Typically, the default configuration of 10 allows for an ingestion running every 30 mins to retain up-to 5 hours worth of data. If you run ingestion more frequently or if you want to give more running time for a query, consider increasing the value for the config : `hoodie.cleaner.commits.retained`
+
+### What's Hudi's schema evolution story?
+
+Hudi uses Avro as the internal canonical representation for records, primarily due to its nice [schema compatibility & evolution](https://docs.confluent.io/platform/current/schema-registry/avro.html) properties. This is a key aspect of having reliability in your ingestion or ETL pipelines. As long as the schema passed to Hudi (either explicitly in DeltaStreamer schema provider configs or implicitly by Spark Datasource's Dataset schemas) is backwards compatible (e.g no field deletes, only appending new fields to schema), Hudi will seamlessly handle read/write of old and new data and also keep the Hive schema up-to date.
+
+### How do I run compaction for a MOR dataset?
+
+Simplest way to run compaction on MOR dataset is to run the [compaction inline](https://hudi.apache.org/docs/configurations#hoodiecompactinline), at the cost of spending more time ingesting; This could be particularly useful, in common cases where you have small amount of late arriving data trickling into older partitions. In such a scenario, you may want to just aggressively compact the last N partitions while waiting for enough logs to accumulate for older partitions. The net effect is that you have converted most of the recent data, that is more likely to be queried to optimized columnar format.
+
+That said, for obvious reasons of not blocking ingesting for compaction, you may want to run it asynchronously as well. This can be done either via a separate [compaction job](https://github.com/apache/hudi/blob/master/hudi-utilities/src/main/java/org/apache/hudi/utilities/HoodieCompactor.java) that is scheduled by your workflow scheduler/notebook independently. If you are using delta streamer, then you can run in [continuous mode](https://github.com/apache/hudi/blob/d3edac4612bde2fa9deca9536801dbc48961fb95/hudi-utilities/src/main/java/org/apache/hudi/utilities/deltastreamer/HoodieDeltaStreamer.java#L241) where the ingestion and compaction are both managed concurrently in a single spark run time.
+
+### What performance/ingest latency can I expect for Hudi writing?
+
+The speed at which you can write into Hudi depends on the [write operation](https://hudi.apache.org/docs/writing_data/) and some trade-offs you make along the way like file sizing. Just like how databases incur overhead over direct/raw file I/O on disks, Hudi operations may have overhead from supporting database like features compared to reading/writing raw DFS files. That said, Hudi implements advanced techniques from database literature to keep these minimal. User is encouraged to have this perspective when trying to reason about Hudi performance. As the saying goes : there is no free lunch (not yet atleast)
+
+| Storage Type | Type of workload | Performance | Tips |
+|-------|--------|--------|--------|
+| copy on write | bulk_insert | Should match vanilla spark writing + an additional sort to properly size files | properly size [bulk insert parallelism](https://hudi.apache.org/docs/configurations#hoodiebulkinsertshuffleparallelism) to get right number of files. use insert if you want this auto tuned |
+| copy on write | insert | Similar to bulk insert, except the file sizes are auto tuned requiring input to be cached into memory and custom partitioned. | Performance would be bound by how parallel you can write the ingested data. Tune [this limit](https://hudi.apache.org/docs/configurations#hoodieinsertshuffleparallelism) up, if you see that writes are happening from only a few executors. |
+| copy on write | upsert/ de-duplicate & insert | Both of these would involve index lookup. Compared to naively using Spark (or similar framework)'s JOIN to identify the affected records, Hudi indexing is often 7-10x faster as long as you have ordered keys (discussed below) or <50% updates. Compared to naively overwriting entire partitions, Hudi write can be several magnitudes faster depending on how many files in a given partition is actually updated. For e.g, if a partition has 1000 files out of which only 100 is dirtied every ingestion run, then Hudi would only read/merge a total of 100 files and thus 10x faster than naively rewriting entire partition. | Ultimately performance would be bound by how quickly we can read and write a parquet file and that depends on the size of the parquet file, configured [here](https://hudi.apache.org/docs/configurations#hoodieparquetmaxfilesize). Also be sure to properly tune your [bloom filters](https://hudi.apache.org/docs/configurations#Index-
Configs). [HUDI-56](https://issues.apache.org/jira/browse/HUDI-56) will auto-tune this. |
+| merge on read | bulk insert | Currently new data only goes to parquet files and thus performance here should be similar to copy_on_write bulk insert. This has the nice side-effect of getting data into parquet directly for query performance. [HUDI-86](https://issues.apache.org/jira/browse/HUDI-86) will add support for logging inserts directly and this up drastically. | |
+| merge on read | insert | Similar to above | |
+| merge on read | upsert/ de-duplicate & insert | Indexing performance would remain the same as copy-on-write, while ingest latency for updates (costliest I/O operation in copy_on_write) are sent to log files and thus with asynchronous compaction provides very very good ingest performance with low write amplification. | |
+
+Like with many typical system that manage time-series data, Hudi performs much better if your keys have a timestamp prefix or monotonically increasing/decreasing. You can almost always achieve this. Even if you have UUID keys, you can follow tricks like [this](https://www.percona.com/blog/2014/12/19/store-uuid-optimized-way/) to get keys that are ordered. See also [Tuning Guide](https://cwiki.apache.org/confluence/display/HUDI/Tuning+Guide) for more tips on JVM and other configurations.
+
+### What performance can I expect for Hudi reading/queries?
+
+ - For ReadOptimized views, you can expect the same best in-class columnar query performance as a standard parquet table in Hive/Spark/Presto
+ - For incremental views, you can expect speed up relative to how much data usually changes in a given time window and how much time your entire scan takes. For e.g, if only 100 files changed in the last hour in a partition of 1000 files, then you can expect a speed of 10x using incremental pull in Hudi compared to full scanning the partition to find out new data.
+ - For real time views, you can expect performance similar to the same avro backed table in Hive/Spark/Presto
+
+### How do I to avoid creating tons of small files?
+
+A key design decision in Hudi was to avoid creating small files and always write properly sized files.
+
+There are 2 ways to avoid creating tons of small files in Hudi and both of them have different trade-offs:
+
+a) **Auto Size small files during ingestion**: This solution trades ingest/writing time to keep queries always efficient. Common approaches to writing very small files and then later stitching them together only solve for system scalability issues posed by small files and also let queries slow down by exposing small files to them anyway.
+
+Hudi has the ability to maintain a configured target file size, when performing **upsert/insert** operations. (Note: **bulk_insert** operation does not provide this functionality and is designed as a simpler replacement for normal `spark.write.parquet` )
+
+For **copy-on-write**, this is as simple as configuring the [maximum size for a base/parquet file](https://hudi.apache.org/docs/configurations#hoodieparquetmaxfilesize) and the [soft limit](https://hudi.apache.org/docs/configurations#hoodieparquetsmallfilelimit) below which a file should be considered a small file. For the initial bootstrap to Hudi table, tuning record size estimate is also important to ensure sufficient records are bin-packed in a parquet file. For subsequent writes, Hudi automatically uses average record size based on previous commit. Hudi will try to add enough records to a small file at write time to get it to the configured maximum limit. For e.g , with `compactionSmallFileSize=100MB` and limitFileSize=120MB, Hudi will pick all files < 100MB and try to get them upto 120MB.
+
+For **merge-on-read**, there are few more configs to set. MergeOnRead works differently for different INDEX choices.
+
+ - Indexes with **canIndexLogFiles = true** : Inserts of new data go directly to log files. In this case, you can configure the [maximum log size](https://hudi.apache.org/docs/configurations#hoodielogfilemaxsize) and a [factor](https://hudi.apache.org/docs/configurations#hoodielogfiletoparquetcompressionratio) that denotes reduction in size when data moves from avro to parquet files.
Review comment:
I do not see this property (`canIndexLogFiles`) for indexing log files now on our configurations page. Have we enabled indexing for log files by default? Do you suggest any changes here? @vinothchandar
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] pratyakshsharma commented on pull request #3496: Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
pratyakshsharma commented on pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#issuecomment-901326642
[FAQs _ Apache Hudi!.pdf](https://github.com/apache/hudi/files/7009280/FAQs._.Apache.Hudi.pdf)
@vinothchandar please have a look.
Once you approve this, we can actually delete the content from cwiki and leave a comment to redirect users to this page on website. :)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] pratyakshsharma commented on pull request #3496: Move content from cwiki to website (FAQ movement)
Posted by GitBox <gi...@apache.org>.
pratyakshsharma commented on pull request #3496:
URL: https://github.com/apache/hudi/pull/3496#issuecomment-910554793
@vinothchandar There are no broken links here. I have fixed them already. You can try building this on local to reconfirm. :)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org