You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/02/21 13:25:05 UTC
[GitHub] [hudi] bkosuru opened a new issue #4864: [SUPPORT]
bkosuru opened a new issue #4864:
URL: https://github.com/apache/hudi/issues/4864
Hello,
Insert with INSERT_DROP_DUPS_OPT_KEY fails after several hours. Any suggestions to make it work? See the details below.
We want to prevent inserting duplicate records.
Hudi table size: 13.4 TB
Data size to insert: 3.8TB (uncompressed) {failed for 200GB input also}
The table has 2 partitions - spog/g=g1/p=p1
The data to be inserted belongs to one partition g=g2
The partition size is for g=g2 is 2TB
g2 has 44 p partitions with sizes ranging from 1.3 M to 270G
Environment Description:
Hudi version : 0.8.0
Spark version : 2.4.4
Storage (HDFS/S3/GCS..) : HDFS
Running on Docker? (yes/no) : No
Table type: COW
Spark settings:
new SparkConf()
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.ui.enabled", "false")
.set("spark.sql.parquet.mergeSchema", "false")
.set("spark.sql.files.ignoreCorruptFiles", "true")
.set("spark.sql.hive.convertMetastoreParquet", "false")
--driver-memory 25G \
--executor-memory 50G \
--executor-cores 2 \
--num-executors 400 \
--conf spark.dynamicAllocation.enabled=False \
--conf spark.network.timeout=240s \
--conf spark.shuffle.sasl.timeout=60000 \
--conf spark.driver.maxResultSize=20g \
--conf spark.port.maxRetries=60 \
--conf spark.shuffle.service.enabled=True \
--conf spark.sql.shuffle.partitions=3000 \
--conf "spark.driver.extraJavaOptions=-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof" \
--conf "spark.executor.extraJavaOptions=-XX:NewSize=1g -XX:SurvivorRatio=2 -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof" \
--conf spark.driver.memoryOverhead=1024 \
--conf spark.executor.memoryOverhead=3072 \
--conf spark.yarn.max.executor.failures=100 \
--conf spark.kryoserializer.buffer.max=512m \
--conf spark.task.maxFailures=4 \
--conf spark.rdd.compress=True \
private val AVG_RECORD_SIZE: Int =
256 // approx bytes of our average record, contra Hudi default assumption of 1024
private val ONE_GIGABYTE: Int =
1024 * 1024 * 1024 // used for Parquet file size & block size
private val BLOOM_MAX_ENTRIES: Int = ONE_GIGABYTE / (2 * AVG_RECORD_SIZE)
df.write
.format("hudi")
// DataSourceWriteOptions
.option(HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
.option( KEYGENERATOR_CLASS_OPT_KEY,"com.xyz.SpoKeyGenerator")
.option(OPERATION_OPT_KEY, INSERT_OPERATION_OPT_VAL)
.option(INSERT_DROP_DUPS_OPT_KEY, value = true)
.option(INSERT_PARALLELISM, 2000)
.option(PARTITIONPATH_FIELD_OPT_KEY, "g,p")
.option(PRECOMBINE_FIELD_OPT_KEY, "isDeleted")
.option(RECORDKEY_FIELD_OPT_KEY, "s,o")
.option(URL_ENCODE_PARTITIONING_OPT_KEY, value = true)
// HoodieIndexConfig
.option(HOODIE_BLOOM_INDEX_FILTER_DYNAMIC_MAX_ENTRIES, BLOOM_MAX_ENTRIES)
.option(BLOOM_INDEX_FILTER_TYPE, BloomFilterTypeCode.DYNAMIC_V0.name)
// HoodieCompactionConfig
.option(COPY_ON_WRITE_TABLE_RECORD_SIZE_ESTIMATE, 64)
// HoodieStorageConfig
.option(LOGFILE_SIZE_MAX_BYTES, ONE_GIGABYTE / 0.35)
.option(PARQUET_BLOCK_SIZE_BYTES, ONE_GIGABYTE)
.option(PARQUET_FILE_MAX_BYTES,ONE_GIGABYTE)
// Commit history
.option(CLEANER_COMMITS_RETAINED_PROP, Integer.MAX_VALUE - 2)
.option(MIN_COMMITS_TO_KEEP_PROP, Integer.MAX_VALUE - 1)
.option(MAX_COMMITS_TO_KEEP_PROP, Integer.MAX_VALUE)
// HoodieWriteConfig
.option(EMBEDDED_TIMELINE_SERVER_ENABLED, "false")
.option(TABLE_NAME, "spog")
.mode(SaveMode.Append)
class SpoKeyGenerator(props: TypedProperties)
extends ComplexKeyGenerator(props) {
def hash128(s: String): String = {
val h: Array[Long] = MurmurHash3.hash128(s.getBytes)
h(0).toString + h(1).toString
}
override def getRecordKey(record: GenericRecord): String = {
val s = HoodieAvroUtils.getNestedFieldValAsString(record, "s", false)
val o = HoodieAvroUtils.getNestedFieldValAsString(record, "o", false)
genKey(s, o)
}
private def genKey(s: String, o: String): String = hash128(s + o)
override def getRecordKey(row: Row): String = {
val s = row.getAs(0).toString
val o = row.getAs(1).toString
genKey(s, o)
}
}
Thanks,
Bindu
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1073106703
from the screen shot, it seems index lookup is failing. I don't see any failure wrt drop duplicates.
Can you try tuning the bloom index configs?
If your data is immutable, you can try setting the operation type to "insert". It may not involve any index look up.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1061352779
@harsh1231 : Can you please follow up on this when you get a chance.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bkosuru commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
bkosuru commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1047227041
Hi Sivabalan,
Without INSERT_DROP_DUPS_OPT_KEY setting, the job runs fine. Here is the stack trace-
User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: Task 198 in stage 7.0 failed 4 times, most recent failure: Lost task 198.3 in stage 7.0 (TID 8888, xyz1.cnet.com, executor 467): ExecutorLostFailure (executor 467 exited caused by one of the running tasks) Reason: Container marked as failed: container_e330_16441790_15827_02_00078 on host: xyz1.cnet.com. Exit status: 143. Diagnostics: [2022-02-13 08:14:04.532]Container killed on request. Exit code is 143
[2022-02-13 08:14:04.532]Container exited with a non-zero exit code 143.
[2022-02-13 08:14:04.537]Killed by external signal
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1892)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1880)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1879)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1879)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:930)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:930)
at scala.Option.foreach(Option.scala:257)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:930)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2113)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2062)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2051)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:741)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2081)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2102)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2121)
at org.apache.spark.rdd.RDD$$anonfun$take$1.apply(RDD.scala:1386)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.take(RDD.scala:1359)
at org.apache.spark.rdd.RDD$$anonfun$isEmpty$1.apply$mcZ$sp(RDD.scala:1494)
at org.apache.spark.rdd.RDD$$anonfun$isEmpty$1.apply(RDD.scala:1494)
at org.apache.spark.rdd.RDD$$anonfun$isEmpty$1.apply(RDD.scala:1494)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:385)
at org.apache.spark.rdd.RDD.isEmpty(RDD.scala:1493)
at org.apache.spark.api.java.JavaRDDLike$class.isEmpty(JavaRDDLike.scala:544)
at org.apache.spark.api.java.AbstractJavaRDDLike.isEmpty(JavaRDDLike.scala:45)
at org.apache.hudi.HoodieSparkSqlWriter$.write(HoodieSparkSqlWriter.scala:181)
at org.apache.hudi.DefaultSource.createRelation(DefaultSource.scala:145)
at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:45)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.doExecute(commands.scala:86)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:677)
at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:677)
at org.apache.spark.sql.execution.SQLExecution$$anonfun$withNewExecutionId$1.apply(SQLExecution.scala:78)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:73)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:677)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:285)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:271)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:229)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1047199352
may I know whats the exception you are seeing? can you provide us w/ stacktrace. And is it that w/o setting INSERT_DROP_DUPS_OPT_KEY, your job runs fine and its a perf issue only when you set this config?
can you throw some more light please.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bkosuru commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
bkosuru commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1073231293
Hi Sivabalan,
Could you please give some suggestions for tuning bloom index configs? Our data is immutable but we have duplicate data. We want to insert unique rows only. We have allocated enough resources(400 executors, 50G) and it still fails. Do you think we should allocate more? Thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bkosuru commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
bkosuru commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1047229347
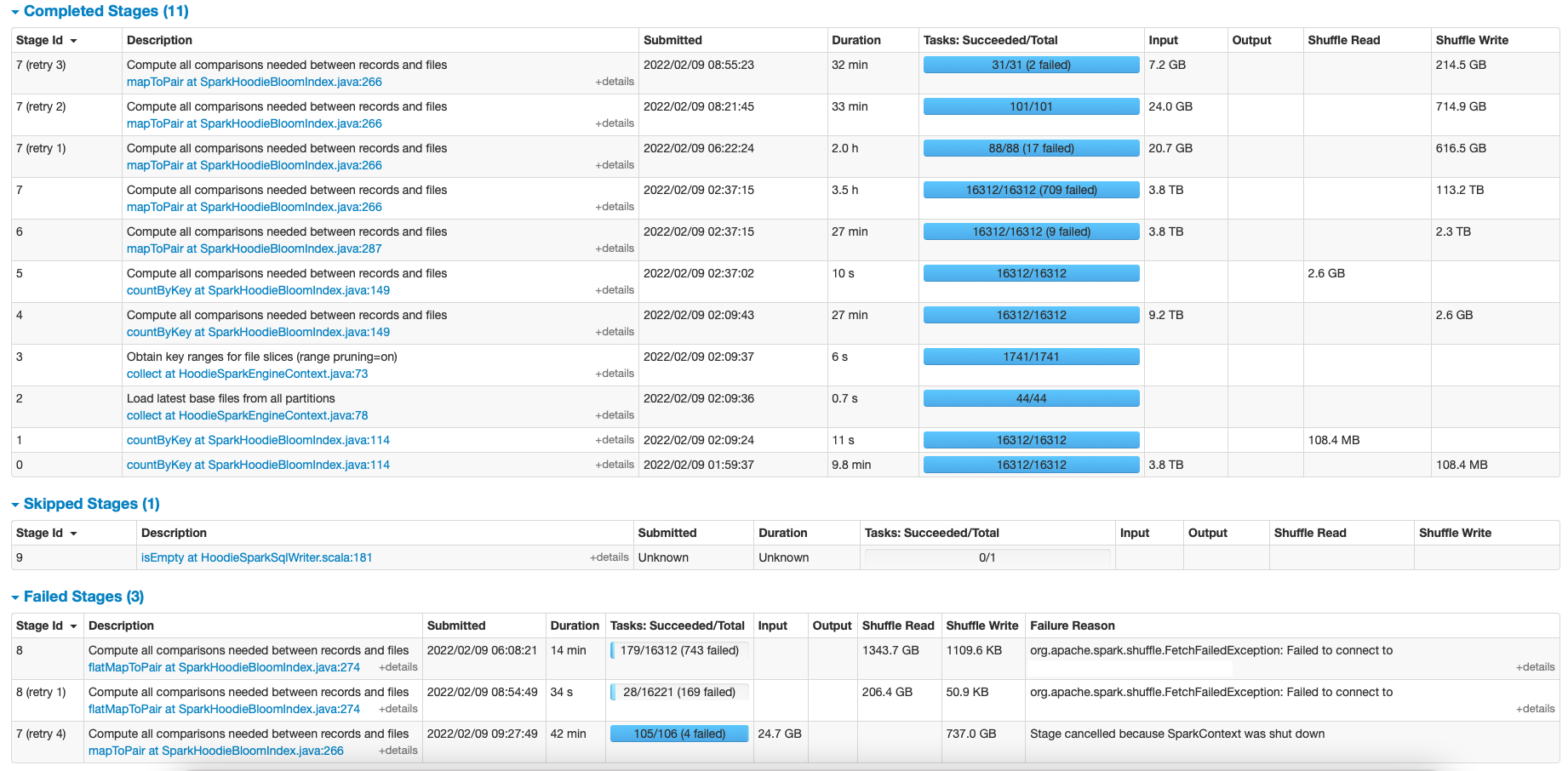
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bkosuru edited a comment on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
bkosuru edited a comment on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1073231293
Hi @nsivabalan,
Could you please give some suggestions for tuning bloom index configs? Our data is immutable but we have duplicate data. We want to insert unique rows only. We have allocated enough resources(400 executors, 50G) and it still fails. Do you think we should allocate more resources? Is there a way to insert_drop_dup to a single partition to make it more efficient. We know that the data we are going to insert belongs to a single partition.
Thanks!
Bindu
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1047199464
CC @harsh1231 perf ticket.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] bkosuru commented on issue #4864: Insert with INSERT_DROP_DUPS_OPT_KEY fails
Posted by GitBox <gi...@apache.org>.
bkosuru commented on issue #4864:
URL: https://github.com/apache/hudi/issues/4864#issuecomment-1047229501
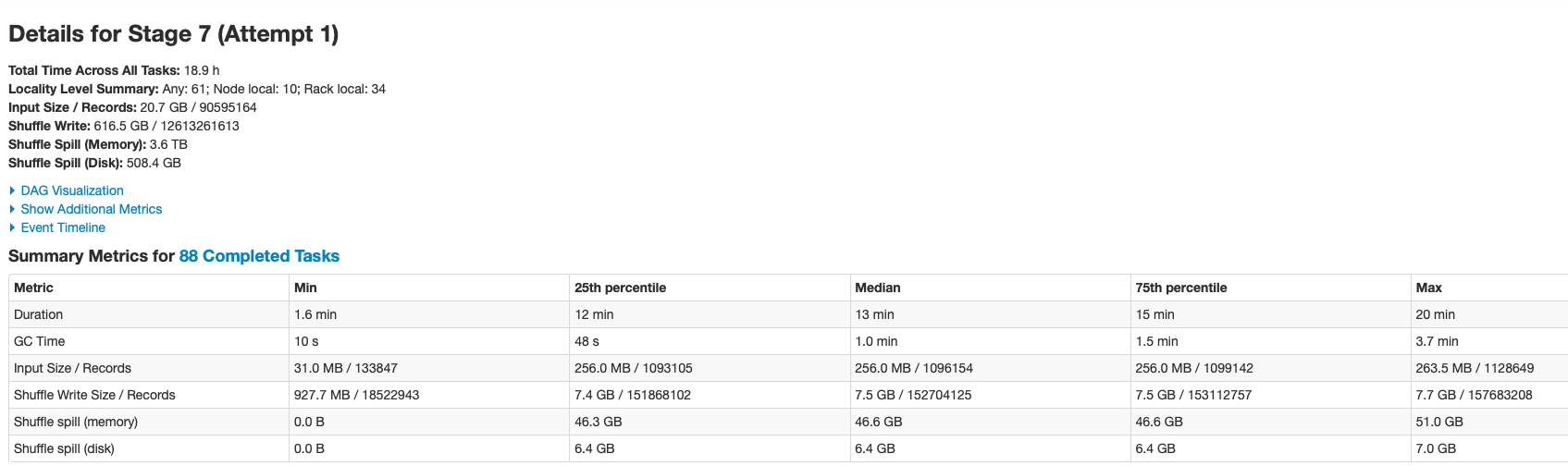
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org