You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by "alamb (via GitHub)" <gi...@apache.org> on 2023/03/31 19:35:28 UTC
[GitHub] [arrow-datafusion] alamb commented on pull request #5790: Revert pr #5020
alamb commented on PR #5790:
URL: https://github.com/apache/arrow-datafusion/pull/5790#issuecomment-1492496143
For anyone else following along the original PR that added this change was https://github.com/apache/arrow-datafusion/pull/5020
@yahoNanJing -- looking at the screen shot you provided,
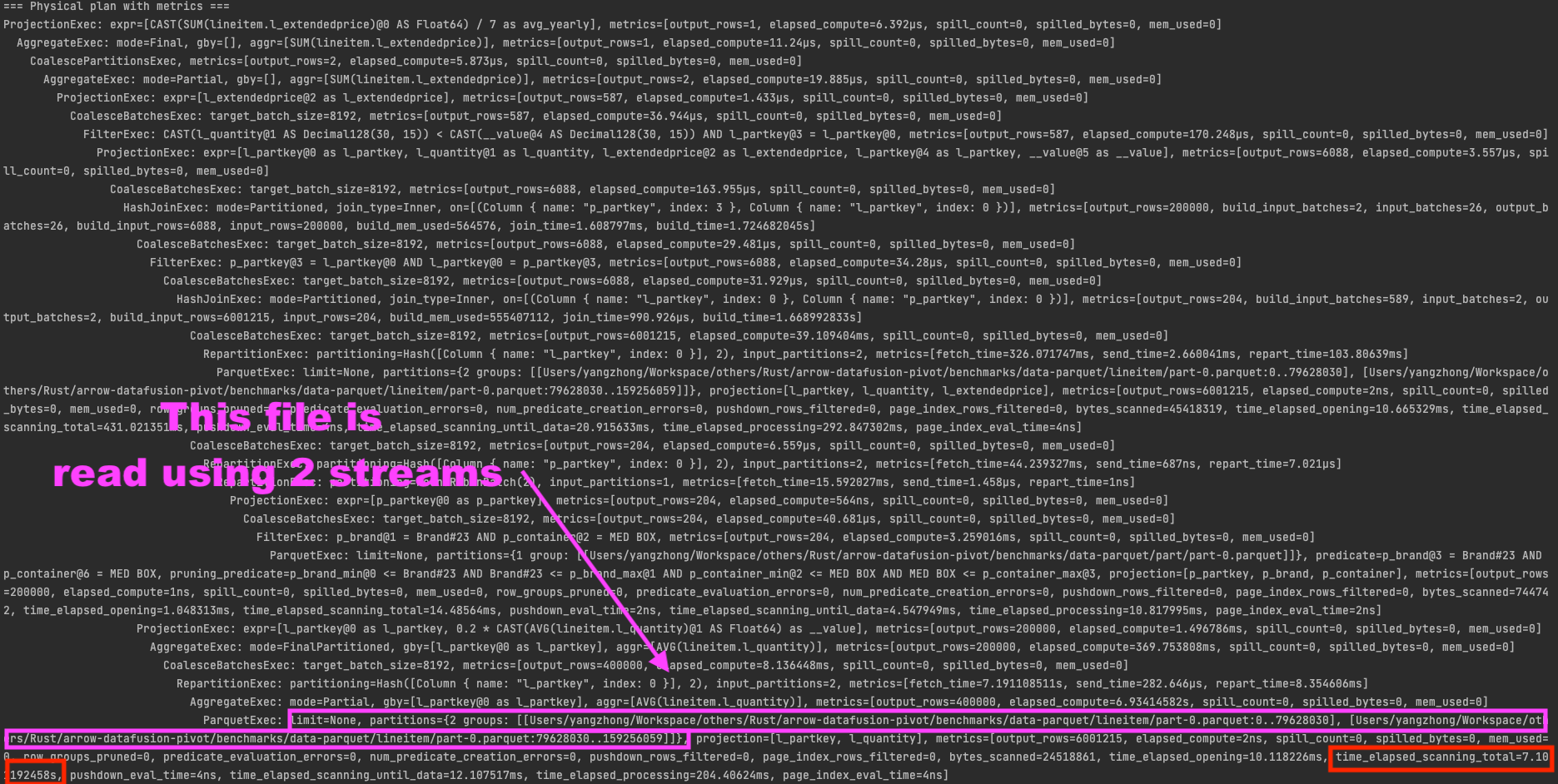
It looks to me like the parquet file in question is being read using 2 streams (aka the file was opened by two different tasks which are reading it in parallel)
Thus while the wall clock time takes only 4 seconds it may be possible that the total cpu time is actually 7 seconds
You could potentially disable the `repartition_file_scans` option
https://docs.rs/datafusion/latest/datafusion/config/struct.OptimizerOptions.html#structfield.repartition_file_scans
And see if the metrics were more like what you expected
Perhaps @thinkharderdev or @tustvold have additional thoughts they could share
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org