You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@shardingsphere.apache.org by du...@apache.org on 2023/02/24 05:34:32 UTC
[shardingsphere] branch master updated: fixes to recent articles (#24336)
This is an automated email from the ASF dual-hosted git repository.
duanzhengqiang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 102b43fb5d3 fixes to recent articles (#24336)
102b43fb5d3 is described below
commit 102b43fb5d336eaf7c0820224b3ef52ef7512d02
Author: FPokerFace <11...@users.noreply.github.com>
AuthorDate: Fri Feb 24 13:34:26 2023 +0800
fixes to recent articles (#24336)
---
...342\200\235_is_Published_Internationally.en.md" | 6 ++--
...etup_on_Massive_Data_Management_Practices.en.md | 8 ++---
...ere_Enterprise_User_Case_-_Energy_Monster.en.md | 14 ++++----
...,_Bringing_New_Cloud_Native_Possibilities.en.md | 42 ++++++++++++----------
...42\200\231s_Show_processlist_&_Kill_Work.en.md" | 22 ++++++------
5 files changed, 48 insertions(+), 44 deletions(-)
diff --git "a/docs/blog/content/material/2022_08_02_Book_Release_\342\200\234A_Definitive_Guide_to_Apache_ShardingSphere\342\200\235_is_Published_Internationally.en.md" "b/docs/blog/content/material/2022_08_02_Book_Release_\342\200\234A_Definitive_Guide_to_Apache_ShardingSphere\342\200\235_is_Published_Internationally.en.md"
index feed534ac6d..14cccddbdbb 100644
--- "a/docs/blog/content/material/2022_08_02_Book_Release_\342\200\234A_Definitive_Guide_to_Apache_ShardingSphere\342\200\235_is_Published_Internationally.en.md"
+++ "b/docs/blog/content/material/2022_08_02_Book_Release_\342\200\234A_Definitive_Guide_to_Apache_ShardingSphere\342\200\235_is_Published_Internationally.en.md"
@@ -23,9 +23,9 @@ This is a technical book written for the ShardingSphere community users as well
- Use ShardingSphere pluggable architecture to build custom solutions.
# Why did we write a professional book about ShardingSphere?
-> ***To introduce the strengths of ShardingSphere’s kernel, features, and architecture to more programmers.\***
->
-> *— By Zhang Liang, Apache ShardingSphere PMC Chair*
+**To introduce the strengths of ShardingSphere’s kernel, features, and architecture to more programmers.**
+
+<p align="right">— By Zhang Liang, Apache ShardingSphere PMC Chair</p>
As the Apache ShardingSphere community has grown in the past two years, its project features and application scenarios have become increasingly diversified and many developers have applied ShardingSphere to real production scenarios.
diff --git a/docs/blog/content/material/2022_09_02_First_Look_at_ShardingSphere_5.2.0_&_In-Person_Meetup_on_Massive_Data_Management_Practices.en.md b/docs/blog/content/material/2022_09_02_First_Look_at_ShardingSphere_5.2.0_&_In-Person_Meetup_on_Massive_Data_Management_Practices.en.md
index 8f9c48ea8ca..11a4f92f3f8 100644
--- a/docs/blog/content/material/2022_09_02_First_Look_at_ShardingSphere_5.2.0_&_In-Person_Meetup_on_Massive_Data_Management_Practices.en.md
+++ b/docs/blog/content/material/2022_09_02_First_Look_at_ShardingSphere_5.2.0_&_In-Person_Meetup_on_Massive_Data_Management_Practices.en.md
@@ -6,7 +6,7 @@ chapter = true
**One more day before ShardingSphere's first in-person meetup in Beijing on September 3, 2022.**
-**Join us to learn about the best practices and technical highlights of Apache ShardingSphere's latest release - version** `5.2.0`**.**
+**Join us to learn about the best practices and technical highlights of Apache ShardingSphere's latest release - version`5.2.0`.**
On Saturday, the first in-person Meetup of the ShardingSphere Community will be held in Beijing on Sep 3, 2022. Four technology experts from the developers’ community are invited to give you a detailed analysis of the following:
@@ -40,15 +40,15 @@ The `5.2.0` release brings the following new features:
Best Practices
--------------
-**1\. Enhance user’s ability to manage ShardingSphere**
+**1. Enhance user's ability to manage ShardingSphere**
Newly added features, including data sharding, SQL audit, and MySQL `SHOW PROCESSLIST` & `KILL`, can enhance users’ capability to manage ShardingSphere.
-**2\. Add heterogeneous database migration for users**
+**2. Add heterogeneous database migration for users**
Specific DistSQL for data migration and heterogeneous migration is added. Data can be migrated from Oracle to PostgreSQL.
-**3\. Provide enhanced and complete cloud solutions**
+**3. Provide enhanced and complete cloud solutions**
Version 5.2.0 transfers Helm Charts from ShardingSphere repository to the shardingsphere-on-cloud sub-project, to provide more complete cloud solutions for ShardingSphere.
diff --git a/docs/blog/content/material/2022_09_06_Apache_ShardingSphere_Enterprise_User_Case_-_Energy_Monster.en.md b/docs/blog/content/material/2022_09_06_Apache_ShardingSphere_Enterprise_User_Case_-_Energy_Monster.en.md
index 8f3cc4433d1..2a8e35e2ead 100644
--- a/docs/blog/content/material/2022_09_06_Apache_ShardingSphere_Enterprise_User_Case_-_Energy_Monster.en.md
+++ b/docs/blog/content/material/2022_09_06_Apache_ShardingSphere_Enterprise_User_Case_-_Energy_Monster.en.md
@@ -35,11 +35,11 @@ It involves the design of new databases and tables and data cleaning and migrati
* Stability: smooth release in a short time without halting.
-• Accuracy: ensure accurate cleaning of tens of millions of data volumes.
+* Accuracy: ensure accurate cleaning of tens of millions of data volumes.
-• Scalability: solve the performance problems caused by increasing data volume and ensure scalability.
+* Scalability: solve the performance problems caused by increasing data volume and ensure scalability.
-> **_Solutions to data cleansing and migration_**
+**_Solutions to data cleansing and migration_**
* Initial data synchronization.
* The application’s server cuts off the entry (users).
@@ -49,7 +49,7 @@ It involves the design of new databases and tables and data cleaning and migrati
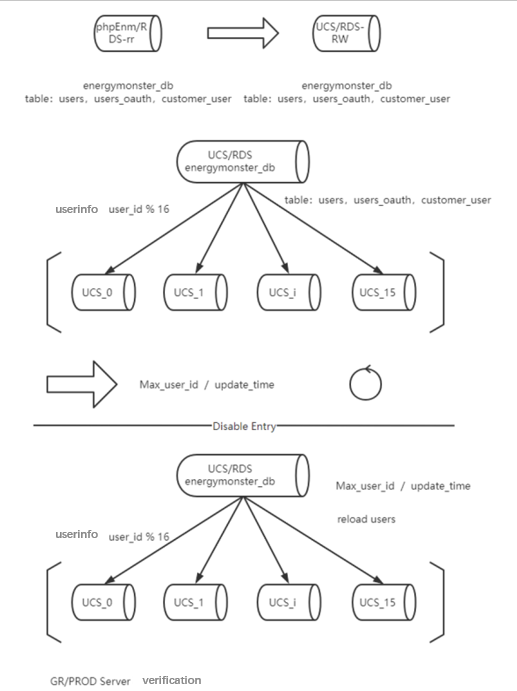
-> **_Data sharding strategy_**
+**_Data sharding strategy_**
The database adopts a database shards design, divided into 16 databases. The default shard key is `user_id` and the default sharding strategy `user_id` is mod 16, such as `${user_id % 16}` for the user table. For SQL that does not carry shard keys, broadcast routing is used.
@@ -57,7 +57,7 @@ The database adopts a database shards design, divided into 16 databases. The def
`user_id` is used as the shard key because `user_id` can cover most business scenarios, and other fields possibly can be empty. In the local test, the query of shard key strategy (openId,mobile) took 50ms to 200ms.
-> **_Using the sharding algorithm_**
+**_Using the sharding algorithm_**
There are currently three sharding algorithms available.
@@ -114,7 +114,7 @@ To avoid data query failure caused by changing the shard key value, shard key de
The druid data connection pool starter will load and create a default data source. This will cause conflicts when ShardingSphere-JDBC creates data sources.
-**5. `**inline strategy**` reports an error in range query.**
+**5. `inline strategy` reports an error in range query.**
The `inline strategy` doesn't support range query by default and the `standard strategy` is advised. Add the following configuration if the `inline strategy` is needed for the range query.
@@ -122,7 +122,7 @@ The `inline strategy` doesn't support range query by default and the `standard s
**Note:** Here all the `inline strategy` range queries will query each sub-table in broadcasting.
-**6. The “Cannot find owner from table” error is reported.**
+**6. The "Cannot find owner from table" error is reported.**
SQL (simplified):
diff --git a/docs/blog/content/material/2022_09_08_Apache_ShardingSphere_5.2.0_is_Released,_Bringing_New_Cloud_Native_Possibilities.en.md b/docs/blog/content/material/2022_09_08_Apache_ShardingSphere_5.2.0_is_Released,_Bringing_New_Cloud_Native_Possibilities.en.md
index baf11b56552..ffb8087fa7c 100644
--- a/docs/blog/content/material/2022_09_08_Apache_ShardingSphere_5.2.0_is_Released,_Bringing_New_Cloud_Native_Possibilities.en.md
+++ b/docs/blog/content/material/2022_09_08_Apache_ShardingSphere_5.2.0_is_Released,_Bringing_New_Cloud_Native_Possibilities.en.md
@@ -40,31 +40,35 @@ As a result, a large number of database connections will be occupied and busines
In response to the above problems, ShardingSphere 5.2.0 provides the SQL audit for data sharding feature and allows users to configure audit strategies. The strategy specifies multiple audit algorithms, and users can decide whether audit rules should be disabled. If any audit algorithm fails to pass, SQL execution will be prohibited. The configuration of SQL audit for data sharding is as follows.
- rules:
- - !SHARDING
- tables:
- t_order:
- actualDataNodes: ds_${0..1}.t_order_${0..1}
- tableStrategy:
- standard:
- shardingColumn: order_id
- shardingAlgorithmName: t_order_inline
- auditStrategy:
- auditorNames:
- - sharding_key_required_auditor
- allowHintDisable: true
- defaultAuditStrategy:
+```sql
+rules:
+- !SHARDING
+ tables:
+ t_order:
+ actualDataNodes: ds_${0..1}.t_order_${0..1}
+ tableStrategy:
+ standard:
+ shardingColumn: order_id
+ shardingAlgorithmName: t_order_inline
+ auditStrategy:
auditorNames:
- sharding_key_required_auditor
allowHintDisable: true
-
- auditors:
- sharding_key_required_auditor:
- type: DML_SHARDING_CONDITIONS
+ defaultAuditStrategy:
+ auditorNames:
+ - sharding_key_required_auditor
+ allowHintDisable: true
+
+ auditors:
+ sharding_key_required_auditor:
+ type: DML_SHARDING_CONDITIONS
+```
In view of complex business scenarios, the new feature allows users to dynamically disable the audit algorithm by using SQL hints so that the business SQL that is allowable in partial scenarios can be executed. Currently, ShardingSphere 5.2.0 has a built-in DML disables full-route audit algorithm. Users can also implement ShardingAuditAlgorithm interface by themselves to realize more advanced SQL audit functions.
- /* ShardingSphere hint: disableAuditNames=sharding_key_required_auditor */ SELECT * FROM t_order;
+```sql
+/* ShardingSphere hint: disableAuditNames=sharding_key_required_auditor */ SELECT * FROM t_order;
+```
### Elastic data migration
diff --git "a/docs/blog/content/material/2022_09_22_How_does_ShardingSphere\342\200\231s_Show_processlist_&_Kill_Work.en.md" "b/docs/blog/content/material/2022_09_22_How_does_ShardingSphere\342\200\231s_Show_processlist_&_Kill_Work.en.md"
index 4b4da55717c..88ffe874688 100644
--- "a/docs/blog/content/material/2022_09_22_How_does_ShardingSphere\342\200\231s_Show_processlist_&_Kill_Work.en.md"
+++ "b/docs/blog/content/material/2022_09_22_How_does_ShardingSphere\342\200\231s_Show_processlist_&_Kill_Work.en.md"
@@ -18,7 +18,7 @@ In response to the above issues, [Apache ShardingSphere](https://shardingsphere.
`Show processlist`: this command can display the list of SQL currently being executed by ShardingSphere and the execution progress of each SQL. If ShardingSphere is deployed in cluster mode, the `Show processlist` function aggregates the SQL running for all Proxy instances in the cluster and then displays the result, so you can always see all the SQL running at that moment.
-```
+```mysql
mysql> show processlist \G;
*************************** 1. row ***************************
Id: 82a67f254959e0a0807a00f3cd695d87
@@ -34,7 +34,7 @@ Command: Execute
`Kill <processID>`: This command is implemented based on `Show processlist` and can terminate the running SQL listed in the `Show processlist`.
-```
+```mysql
mysql> kill 82a67f254959e0a0807a00f3cd695d87;
Query OK, 0 rows affected (0.17 sec)
```
@@ -49,7 +49,7 @@ Each SQL executed in ShardingSphere will generate an `ExecutionGroupContext` obj
When ShardingSphere receives a SQL command, the `GovernanceExecuteProcessReporter# report` is called to store `ExecutionGroupContext` information into the cache of `ConcurrentHashMap `(currently only DML and DDL statements of MySQL are supported; other types of databases will be supported in later versions. Query statements are also classified into DML).
-```
+```java
public final class GovernanceExecuteProcessReporter implements ExecuteProcessReporter {
@Override
@@ -93,7 +93,7 @@ The latter contains the mapping between `executionID` and `Statement objects` th
Every time ShardingSphere receives a SQL statement, the SQL information will be cached into the two Maps. After SQL is executed, the cache of Map will be deleted.
-```
+```java
@RequiredArgsConstructor
public final class ProxyJDBCExecutor {
@@ -136,7 +136,7 @@ The SQL shown in the `Show processlist` was obtained from `processContexts`. But
When ShardingSphere receives the `Show process` command, it is sent to the executor `ShowProcessListExecutor#execute` for processing. The implementation of the `getQueryResult()` is the focus.
-```
+```java
public final class ShowProcessListExecutor implements DatabaseAdminQueryExecutor {
private Collection<String> batchProcessContexts;
@@ -213,7 +213,7 @@ You’ll use the `guava` package's `EventBus` function, which is an information
This method is the core to implementing `Show processlist`. Next, we'll introduce specific procedures of this method.
-```
+```java
public final class ProcessRegistrySubscriber {
@Subscribe
public void loadShowProcessListData(final ShowProcessListRequestEvent event) {
@@ -251,7 +251,7 @@ However, monitoring is an asynchronous process and the main thread does not bloc
Let's take a look at how the ShardingSphere handles the monitoring logic.
-```
+```java
public final class ComputeNodeStateChangedWatcher implements GovernanceWatcher<GovernanceEvent> {
@Override
@@ -305,7 +305,7 @@ As shown in the above code, it is a new node, so `ShowProcessListTriggerEvent` w
In this case, single-machine processing is transformed into cluster processing. Let's look at how ShardingSphere handles it.
-```
+```java
public final class ClusterContextManagerCoordinator { @Subscribe
public synchronized void triggerShowProcessList(final ShowProcessListTriggerEvent event) {
if (!event.getInstanceId().equals(contextManager.getInstanceContext().getInstance().getMetaData().getId())) {
@@ -325,7 +325,7 @@ public final class ClusterContextManagerCoordinator { @Subscribe
When you delete the node, monitoring will also be triggered and `ShowProcessListUnitCompleteEvent` will be posted. This event will finally awake the pending lock.
-```
+```java
public final class ClusterContextManagerCoordinator {
@Subscribe
@@ -344,7 +344,7 @@ ShardingSphere uses the `isReady(Paths)` method to determine whether all instanc
There is a maximum waiting time of 5 seconds for data processing. If the processing is not completed in 5 seconds, then `false` is returned.
-```
+```java
public final class ClusterContextManagerCoordinator {
@Subscribe
@@ -361,7 +361,7 @@ public final class ClusterContextManagerCoordinator {
After each instance processed the data, the instance that received the `Show processlist` command needs to aggregate the data and then display the result.
-```
+```java
public final class ProcessRegistrySubscriber {
private void sendShowProcessList(final String processListId) {