You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@spark.apache.org by li...@apache.org on 2019/07/03 07:01:40 UTC
[spark] branch master updated: [SPARK-28167][SQL] Show global
temporary view in database tool
This is an automated email from the ASF dual-hosted git repository.
lixiao pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/spark.git
The following commit(s) were added to refs/heads/master by this push:
new ea03030 [SPARK-28167][SQL] Show global temporary view in database tool
ea03030 is described below
commit ea0303063f5d0e25dbc6c126b13bbefe59a8d1f7
Author: Yuming Wang <yu...@ebay.com>
AuthorDate: Wed Jul 3 00:01:05 2019 -0700
[SPARK-28167][SQL] Show global temporary view in database tool
## What changes were proposed in this pull request?
This pr add support show global temporary view and local temporary view in database tool.
TODO: Database tools should support show temporary views because it's schema is null.
## How was this patch tested?
unit tests and manual tests:
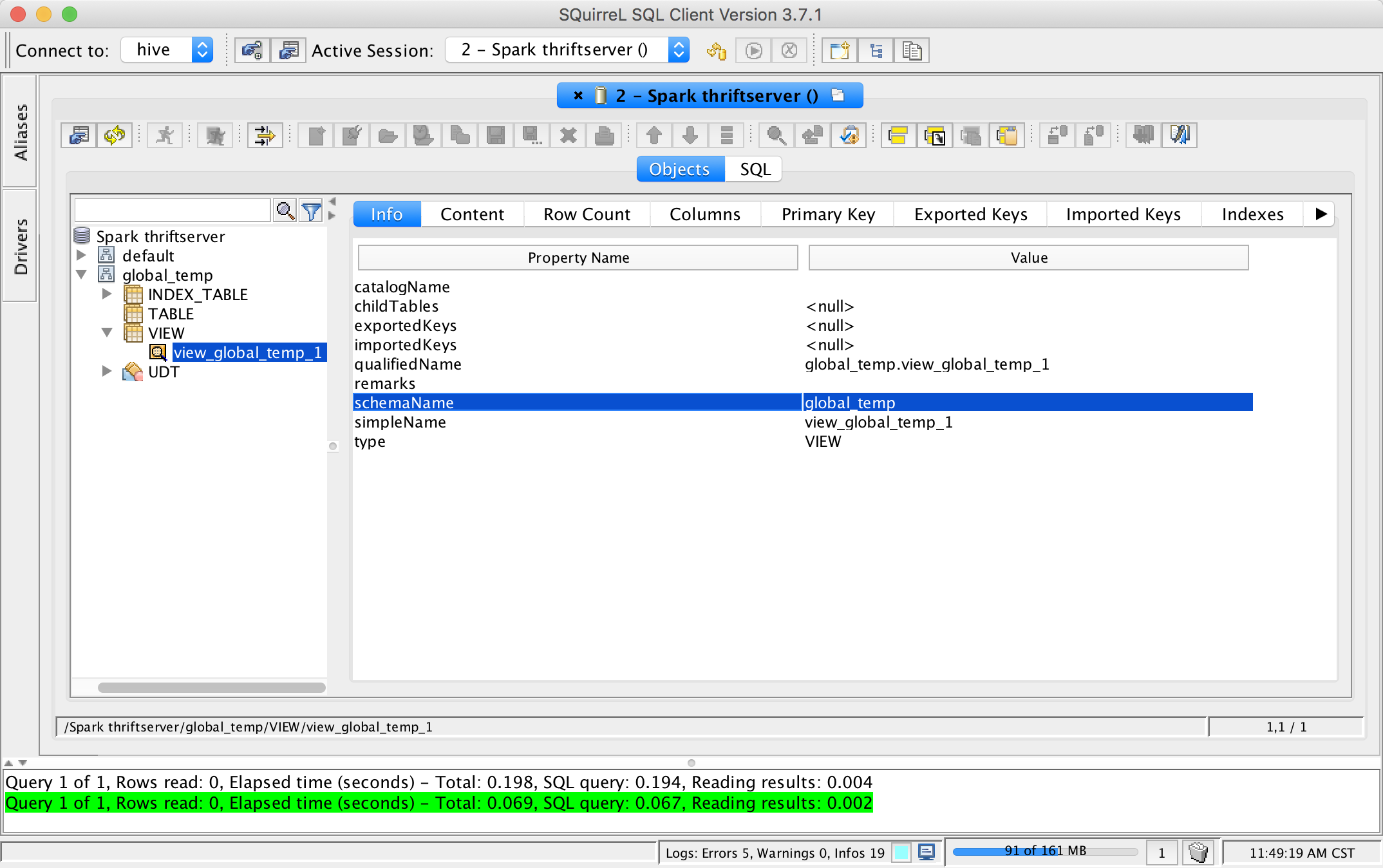
Closes #24972 from wangyum/SPARK-28167.
Authored-by: Yuming Wang <yu...@ebay.com>
Signed-off-by: gatorsmile <ga...@gmail.com>
---
.../thriftserver/SparkGetColumnsOperation.scala | 95 ++++++++++++++--------
.../thriftserver/SparkGetSchemasOperation.scala | 8 ++
.../thriftserver/SparkGetTablesOperation.scala | 55 +++++++++----
.../thriftserver/SparkMetadataOperationSuite.scala | 46 +++++++++--
4 files changed, 148 insertions(+), 56 deletions(-)
diff --git a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetColumnsOperation.scala b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetColumnsOperation.scala
index 4b78e2f..6d3c9fc 100644
--- a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetColumnsOperation.scala
+++ b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetColumnsOperation.scala
@@ -17,7 +17,6 @@
package org.apache.spark.sql.hive.thriftserver
-import java.util.UUID
import java.util.regex.Pattern
import scala.collection.JavaConverters.seqAsJavaListConverter
@@ -33,6 +32,7 @@ import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.catalyst.TableIdentifier
import org.apache.spark.sql.catalyst.catalog.SessionCatalog
import org.apache.spark.sql.hive.thriftserver.ThriftserverShimUtils.toJavaSQLType
+import org.apache.spark.sql.types.StructType
/**
* Spark's own SparkGetColumnsOperation
@@ -56,8 +56,6 @@ private[hive] class SparkGetColumnsOperation(
val catalog: SessionCatalog = sqlContext.sessionState.catalog
- private var statementId: String = _
-
override def runInternal(): Unit = {
val cmdStr = s"catalog : $catalogName, schemaPattern : $schemaName, tablePattern : $tableName" +
s", columnName : $columnName"
@@ -77,7 +75,7 @@ private[hive] class SparkGetColumnsOperation(
}
val db2Tabs = catalog.listDatabases(schemaPattern).map { dbName =>
- (dbName, catalog.listTables(dbName, tablePattern))
+ (dbName, catalog.listTables(dbName, tablePattern, includeLocalTempViews = false))
}.toMap
if (isAuthV2Enabled) {
@@ -88,42 +86,31 @@ private[hive] class SparkGetColumnsOperation(
}
try {
+ // Tables and views
db2Tabs.foreach {
case (dbName, tables) =>
catalog.getTablesByName(tables).foreach { catalogTable =>
- catalogTable.schema.foreach { column =>
- if (columnPattern != null && !columnPattern.matcher(column.name).matches()) {
- } else {
- val rowData = Array[AnyRef](
- null, // TABLE_CAT
- dbName, // TABLE_SCHEM
- catalogTable.identifier.table, // TABLE_NAME
- column.name, // COLUMN_NAME
- toJavaSQLType(column.dataType.sql).asInstanceOf[AnyRef], // DATA_TYPE
- column.dataType.sql, // TYPE_NAME
- null, // COLUMN_SIZE
- null, // BUFFER_LENGTH, unused
- null, // DECIMAL_DIGITS
- null, // NUM_PREC_RADIX
- (if (column.nullable) 1 else 0).asInstanceOf[AnyRef], // NULLABLE
- column.getComment().getOrElse(""), // REMARKS
- null, // COLUMN_DEF
- null, // SQL_DATA_TYPE
- null, // SQL_DATETIME_SUB
- null, // CHAR_OCTET_LENGTH
- null, // ORDINAL_POSITION
- "YES", // IS_NULLABLE
- null, // SCOPE_CATALOG
- null, // SCOPE_SCHEMA
- null, // SCOPE_TABLE
- null, // SOURCE_DATA_TYPE
- "NO" // IS_AUTO_INCREMENT
- )
- rowSet.addRow(rowData)
- }
- }
+ addToRowSet(columnPattern, dbName, catalogTable.identifier.table, catalogTable.schema)
}
}
+
+ // Global temporary views
+ val globalTempViewDb = catalog.globalTempViewManager.database
+ val databasePattern = Pattern.compile(CLIServiceUtils.patternToRegex(schemaName))
+ if (databasePattern.matcher(globalTempViewDb).matches()) {
+ catalog.globalTempViewManager.listViewNames(tablePattern).foreach { globalTempView =>
+ catalog.globalTempViewManager.get(globalTempView).foreach { plan =>
+ addToRowSet(columnPattern, globalTempViewDb, globalTempView, plan.schema)
+ }
+ }
+ }
+
+ // Temporary views
+ catalog.listLocalTempViews(tablePattern).foreach { localTempView =>
+ catalog.getTempView(localTempView.table).foreach { plan =>
+ addToRowSet(columnPattern, null, localTempView.table, plan.schema)
+ }
+ }
setState(OperationState.FINISHED)
} catch {
case e: HiveSQLException =>
@@ -132,6 +119,44 @@ private[hive] class SparkGetColumnsOperation(
}
}
+ private def addToRowSet(
+ columnPattern: Pattern,
+ dbName: String,
+ tableName: String,
+ schema: StructType): Unit = {
+ schema.foreach { column =>
+ if (columnPattern != null && !columnPattern.matcher(column.name).matches()) {
+ } else {
+ val rowData = Array[AnyRef](
+ null, // TABLE_CAT
+ dbName, // TABLE_SCHEM
+ tableName, // TABLE_NAME
+ column.name, // COLUMN_NAME
+ toJavaSQLType(column.dataType.sql).asInstanceOf[AnyRef], // DATA_TYPE
+ column.dataType.sql, // TYPE_NAME
+ null, // COLUMN_SIZE
+ null, // BUFFER_LENGTH, unused
+ null, // DECIMAL_DIGITS
+ null, // NUM_PREC_RADIX
+ (if (column.nullable) 1 else 0).asInstanceOf[AnyRef], // NULLABLE
+ column.getComment().getOrElse(""), // REMARKS
+ null, // COLUMN_DEF
+ null, // SQL_DATA_TYPE
+ null, // SQL_DATETIME_SUB
+ null, // CHAR_OCTET_LENGTH
+ null, // ORDINAL_POSITION
+ "YES", // IS_NULLABLE
+ null, // SCOPE_CATALOG
+ null, // SCOPE_SCHEMA
+ null, // SCOPE_TABLE
+ null, // SOURCE_DATA_TYPE
+ "NO" // IS_AUTO_INCREMENT
+ )
+ rowSet.addRow(rowData)
+ }
+ }
+ }
+
private def getPrivObjs(db2Tabs: Map[String, Seq[TableIdentifier]]): Seq[HivePrivilegeObject] = {
db2Tabs.foldLeft(Seq.empty[HivePrivilegeObject])({
case (i, (dbName, tables)) => i ++ tables.map { tableId =>
diff --git a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetSchemasOperation.scala b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetSchemasOperation.scala
index d585049..e2acd95 100644
--- a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetSchemasOperation.scala
+++ b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetSchemasOperation.scala
@@ -17,6 +17,8 @@
package org.apache.spark.sql.hive.thriftserver
+import java.util.regex.Pattern
+
import org.apache.hadoop.hive.ql.security.authorization.plugin.HiveOperationType
import org.apache.hive.service.cli._
import org.apache.hive.service.cli.operation.GetSchemasOperation
@@ -56,6 +58,12 @@ private[hive] class SparkGetSchemasOperation(
sqlContext.sessionState.catalog.listDatabases(schemaPattern).foreach { dbName =>
rowSet.addRow(Array[AnyRef](dbName, DEFAULT_HIVE_CATALOG))
}
+
+ val globalTempViewDb = sqlContext.sessionState.catalog.globalTempViewManager.database
+ val databasePattern = Pattern.compile(CLIServiceUtils.patternToRegex(schemaName))
+ if (databasePattern.matcher(globalTempViewDb).matches()) {
+ rowSet.addRow(Array[AnyRef](globalTempViewDb, DEFAULT_HIVE_CATALOG))
+ }
setState(OperationState.FINISHED)
} catch {
case e: HiveSQLException =>
diff --git a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetTablesOperation.scala b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetTablesOperation.scala
index 56f89df..5090124 100644
--- a/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetTablesOperation.scala
+++ b/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkGetTablesOperation.scala
@@ -18,6 +18,7 @@
package org.apache.spark.sql.hive.thriftserver
import java.util.{List => JList}
+import java.util.regex.Pattern
import scala.collection.JavaConverters.seqAsJavaListConverter
@@ -63,6 +64,7 @@ private[hive] class SparkGetTablesOperation(
val catalog = sqlContext.sessionState.catalog
val schemaPattern = convertSchemaPattern(schemaName)
+ val tablePattern = convertIdentifierPattern(tableName, true)
val matchingDbs = catalog.listDatabases(schemaPattern)
if (isAuthV2Enabled) {
@@ -72,29 +74,52 @@ private[hive] class SparkGetTablesOperation(
authorizeMetaGets(HiveOperationType.GET_TABLES, privObjs, cmdStr)
}
- val tablePattern = convertIdentifierPattern(tableName, true)
+ // Tables and views
matchingDbs.foreach { dbName =>
- catalog.getTablesByName(catalog.listTables(dbName, tablePattern)).foreach { catalogTable =>
- val tableType = tableTypeString(catalogTable.tableType)
+ val tables = catalog.listTables(dbName, tablePattern, includeLocalTempViews = false)
+ catalog.getTablesByName(tables).foreach { table =>
+ val tableType = tableTypeString(table.tableType)
if (tableTypes == null || tableTypes.isEmpty || tableTypes.contains(tableType)) {
- val rowData = Array[AnyRef](
- "",
- catalogTable.database,
- catalogTable.identifier.table,
- tableType,
- catalogTable.comment.getOrElse(""))
- // Since HIVE-7575(Hive 2.0.0), adds 5 additional columns to the ResultSet of GetTables.
- if (HiveUtils.isHive23) {
- rowSet.addRow(rowData ++ Array(null, null, null, null, null))
- } else {
- rowSet.addRow(rowData)
- }
+ addToRowSet(table.database, table.identifier.table, tableType, table.comment)
}
}
}
+
+ // Temporary views and global temporary views
+ if (tableTypes == null || tableTypes.isEmpty || tableTypes.contains(VIEW.name)) {
+ val globalTempViewDb = catalog.globalTempViewManager.database
+ val databasePattern = Pattern.compile(CLIServiceUtils.patternToRegex(schemaName))
+ val tempViews = if (databasePattern.matcher(globalTempViewDb).matches()) {
+ catalog.listTables(globalTempViewDb, tablePattern, includeLocalTempViews = true)
+ } else {
+ catalog.listLocalTempViews(tablePattern)
+ }
+ tempViews.foreach { view =>
+ addToRowSet(view.database.orNull, view.table, VIEW.name, None)
+ }
+ }
setState(OperationState.FINISHED)
}
+ private def addToRowSet(
+ dbName: String,
+ tableName: String,
+ tableType: String,
+ comment: Option[String]): Unit = {
+ val rowData = Array[AnyRef](
+ "",
+ dbName,
+ tableName,
+ tableType,
+ comment.getOrElse(""))
+ // Since HIVE-7575(Hive 2.0.0), adds 5 additional columns to the ResultSet of GetTables.
+ if (HiveUtils.isHive23) {
+ rowSet.addRow(rowData ++ Array(null, null, null, null, null))
+ } else {
+ rowSet.addRow(rowData)
+ }
+ }
+
private def tableTypeString(tableType: CatalogTableType): String = tableType match {
case EXTERNAL | MANAGED => "TABLE"
case VIEW => "VIEW"
diff --git a/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala b/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
index dc54476..e524861 100644
--- a/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
+++ b/sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/SparkMetadataOperationSuite.scala
@@ -38,8 +38,7 @@ class SparkMetadataOperationSuite extends HiveThriftJdbcTest {
val metaData = statement.getConnection.getMetaData
- checkResult(metaData.getSchemas(null, "%"),
- Seq("db1", "db2", "default"))
+ checkResult(metaData.getSchemas(null, "%"), Seq("db1", "db2", "default", "global_temp"))
checkResult(metaData.getSchemas(null, "db1"), Seq("db1"))
checkResult(metaData.getSchemas(null, "db_not_exist"), Seq.empty)
checkResult(metaData.getSchemas(null, "db*"), Seq("db1", "db2"))
@@ -68,7 +67,7 @@ class SparkMetadataOperationSuite extends HiveThriftJdbcTest {
val metaData = statement.getConnection.getMetaData
checkResult(metaData.getTables(null, "%", "%", null),
- Seq("table1", "table2", "view1"))
+ Seq("table1", "table2", "view1", "view_global_temp_1", "view_temp_1"))
checkResult(metaData.getTables(null, "%", "table1", null), Seq("table1"))
@@ -78,10 +77,19 @@ class SparkMetadataOperationSuite extends HiveThriftJdbcTest {
Seq("table1", "table2"))
checkResult(metaData.getTables(null, "%", "%", Array("VIEW")),
- Seq("view1"))
+ Seq("view1", "view_global_temp_1", "view_temp_1"))
+
+ checkResult(metaData.getTables(null, "%", "view_global_temp_1", null),
+ Seq("view_global_temp_1"))
+
+ checkResult(metaData.getTables(null, "%", "view_temp_1", null),
+ Seq("view_temp_1"))
checkResult(metaData.getTables(null, "%", "%", Array("TABLE", "VIEW")),
- Seq("table1", "table2", "view1"))
+ Seq("table1", "table2", "view1", "view_global_temp_1", "view_temp_1"))
+
+ checkResult(metaData.getTables(null, "%", "table_not_exist", Array("TABLE", "VIEW")),
+ Seq.empty)
}
}
@@ -119,7 +127,9 @@ class SparkMetadataOperationSuite extends HiveThriftJdbcTest {
("table1", "val", "12", "STRING", "String column"),
("table2", "key", "4", "INT", ""),
("table2", "val", "3", "DECIMAL(10,0)", "Decimal column"),
- ("view1", "key", "4", "INT", "Int column")))
+ ("view1", "key", "4", "INT", "Int column"),
+ ("view_global_temp_1", "col2", "4", "INT", ""),
+ ("view_temp_1", "col2", "4", "INT", "")))
checkResult(metaData.getColumns(null, "%", "table1", null),
Seq(
@@ -129,6 +139,30 @@ class SparkMetadataOperationSuite extends HiveThriftJdbcTest {
checkResult(metaData.getColumns(null, "%", "table1", "key"),
Seq(("table1", "key", "4", "INT", "Int column")))
+ checkResult(metaData.getColumns(null, "%", "view%", null),
+ Seq(
+ ("view1", "key", "4", "INT", "Int column"),
+ ("view_global_temp_1", "col2", "4", "INT", ""),
+ ("view_temp_1", "col2", "4", "INT", "")))
+
+ checkResult(metaData.getColumns(null, "%", "view_global_temp_1", null),
+ Seq(("view_global_temp_1", "col2", "4", "INT", "")))
+
+ checkResult(metaData.getColumns(null, "%", "view_temp_1", null),
+ Seq(("view_temp_1", "col2", "4", "INT", "")))
+
+ checkResult(metaData.getColumns(null, "%", "view_temp_1", "col2"),
+ Seq(("view_temp_1", "col2", "4", "INT", "")))
+
+ checkResult(metaData.getColumns(null, "default", "%", null),
+ Seq(
+ ("table1", "key", "4", "INT", "Int column"),
+ ("table1", "val", "12", "STRING", "String column"),
+ ("table2", "key", "4", "INT", ""),
+ ("table2", "val", "3", "DECIMAL(10,0)", "Decimal column"),
+ ("view1", "key", "4", "INT", "Int column"),
+ ("view_temp_1", "col2", "4", "INT", "")))
+
checkResult(metaData.getColumns(null, "%", "table_not_exist", null), Seq.empty)
}
}
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@spark.apache.org
For additional commands, e-mail: commits-help@spark.apache.org