You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/03/08 11:46:13 UTC
[GitHub] [iceberg] NageshB82 opened a new issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
NageshB82 opened a new issue #2302:
URL: https://github.com/apache/iceberg/issues/2302
Environment
- Spark 3.0.1
- Apache hive v2.3.*. - Hive server using Derby DB internally for metastore
- Hadoop v3.2.*
- Minio docker
Recreation Steps :
- Started hiveserver metastore
- Using Scala code created tables in Iceberg.
- CREATE TABLE if not exists Account(accountId string , name string, description string) USING iceberg TBLPROPERTIES('engine.hive.enabled'='true', 'write.parquet.compression-codec'='snappy/gzip')"
- Loaded almost 400k json parquet records in icerberg, it loaded pretty quickly in iceberg table.
- Started Spark thrift-hiverserver using <SPARK_HOME>/bin/start-thriftserver.sh
- Written JDBC program to read iceberg table through thrift server
- We see while making any query it takes almost around 8-10 seconds depending upon limit we query from eg: 200 to 20000 records per call.
We observered thrift server logs to check where it is taking maximum time, looks like it is taking most of time almost 5-7 seconds of time to fetch parquet files from iceberg table and decompressing it either these are stored in s3 (minio)/local FS
`21/03/03 00:27:37 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
21/03/03 00:27:37 INFO HadoopRDD: Input split: null:0+0
21/03/03 00:27:38 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:39 INFO CodeGenerator: Code generated in 182.353266 ms
21/03/03 00:27:39 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:41 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:41 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:42 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:42 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:42 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:43 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:43 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:43 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:44 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:44 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:45 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:45 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:46 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:46 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:46 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:46 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:47 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:47 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:48 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:48 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:49 INFO S3AInputStream: Switching to Random IO seek policy
21/03/03 00:27:49 INFO CodecPool: Got brand-new decompressor [.gz]
21/03/03 00:27:49 INFO MemoryStore: Block taskresult_0 stored as bytes in memory (estimated size 10.9 MiB, free 422.8 MiB)
21/03/03 00:27:49 INFO BlockManagerInfo: Added taskresult_0 in memory on fuddled1.fyre.ibm.com:36922 (size: 10.9 MiB, free: 423.4 MiB)
21/03/03 00:27:49 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 11425022 bytes result sent via BlockManager)`
We tried changing compression to 'snappy' instead of default compression 'gzip' both takes same amount of time, to make a query from iceberg table.
`21/03/05 00:15:11 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
21/03/05 00:15:11 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, fuddled1.fyre.ibm.com, executor driver, partition 0, ANY, 101471 bytes)
21/03/05 00:15:11 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
21/03/05 00:15:11 INFO HadoopRDD: Input split: null:0+0
21/03/05 00:15:11 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:12 INFO CodeGenerator: Code generated in 189.91119 ms
21/03/05 00:15:12 INFO CodecPool: Got brand-new decompressor [.snappy]
21/03/05 00:15:15 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:16 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:17 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:17 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:18 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:19 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:19 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:20 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:21 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:22 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:22 INFO S3AInputStream: Switching to Random IO seek policy
21/03/05 00:15:23 INFO MemoryStore: Block taskresult_0 stored as bytes in memory (estimated size 10.9 MiB, free 422.8 MiB)
21/03/05 00:15:23 INFO BlockManagerInfo: Added taskresult_0 in memory on fuddled1.fyre.ibm.com:42090 (size: 10.9 MiB, free: 423.4 MiB)
21/03/05 00:15:23 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 11425022 bytes result sent via BlockManager)`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-804112512
From that it looks like it's doing a single file read for these jobs, I was hoping you could also share the actual stage details for a job. You get this by clicking on the link in the stage description, it should give a query plan and runtime breakdown.
That said I would be very surprised by these runtimes on any system for reading approximately 40 mbs of data.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-803906213
@RussellSpitzer Here I am attaching the spark UI job and stages output when we are querying data from Account table from iceberg using simple jdbc program
// get connection
Connection con = DriverManager.getConnection("jdbc:hive2://<sparkthrift_server_ip>:10000/default", "", "");
// create statement
Statement stmt = con.createStatement();
// execute statements
ResultSet res = stmt.executeQuery("SELECT * FROM Account order by id limit 20000;");
Its almost taking minimum on 8 sec to fetch any 200 or 20000 records
<img width="1527" alt="spark_job_read" src="https://user-images.githubusercontent.com/80257736/111967121-aac0b300-8b1d-11eb-9bea-8e3f28ef5c1a.png">
<img width="1533" alt="spark-stages-read" src="https://user-images.githubusercontent.com/80257736/111967159-b8763880-8b1d-11eb-9acc-0378f18c3e4d.png">
Here is Table creation statement we used for Account table in iceberg
spark.sql(
"CREATE TABLE if not exists Account(name string,dn string, accountCreationDate string, disabled long, forceChangePwd long, pwdLife long, numberLoginError long, lastChangePwd string, lastLogin string, lastWrongLogin string, state long, expire string, lastCertTime string, creationDate string, creationUser string, challengeCounter long,challengeFailedAttempt long, targetName string, applicationId string, lastAccessTime string, complianceStatus string, isDeleted string, lastUpdatedTime long, cumulativeScore string, currentScore string, critical string, high int, medium int, low int, firstOccurrence long, lastOccurrence long, id string, sourceTypes string, lastModifiedTime long, _id string, type string, isimId string, externalId string) USING iceberg TBLPROPERTIES('engine.hive.enabled'='true')"
)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-814857921
It's not the processors, but the file system I'm worried about. Getting a speed of about 1-10 seconds per megabyte on read is quite slow. The test with The parquet reader was for us to see how fast a non Iceberg reader could access the filesystem and parallelism aside, the access was still quite slow basically at the same speed as iceberg.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-814844057
@RussellSpitzer We have tried this same steps on High end machine where its 16 core machine, here as well are not seeing much time difference bit 1 0r 2 seconds less than previous setup, Like you are pointing perhaps spark provide the parallelism but with iceberg its not, so we tried created one 1 file in iceberg table and tried to fetch it though thrift service so its just taking 2-3 seconds but when we increases files in iceberg table reading it taking more and more time
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-805619263
@RussellSpitzer As you suggested, We tried creating External table in spark (not iceberg table) as below and tried query on that
`CREATE EXTERNAL TABLE Account(name string,dn string, accountCreationDate string, disabled long, forceChangePwd long, pwdLife long, numberLoginError long, lastChangePwd string, lastLogin string, lastWrongLogin string, state long, expire string, lastCertTime string, creationDate string, creationUser string, challengeCounter long,challengeFailedAttempt long, targetName string, isDeleted string, lastUpdatedTime long, id string, sourceTypes string, _id string, type string, isimId string, externalId string)
STORED AS PARQUET LOCATION '/root/Documents/Account';`
Querying data in same way like we queried for iceberg table using thrift server,
Here I see each paginated records are fetching around 3-5 seconds for 20k records per page (while as Iceberg tables queries are taking 8-11 sec per page)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-802571890
@RussellSpitzer Did you get a chance to look at it ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-805467854
@RussellSpitzer Added more details , as below
DAG Visualization
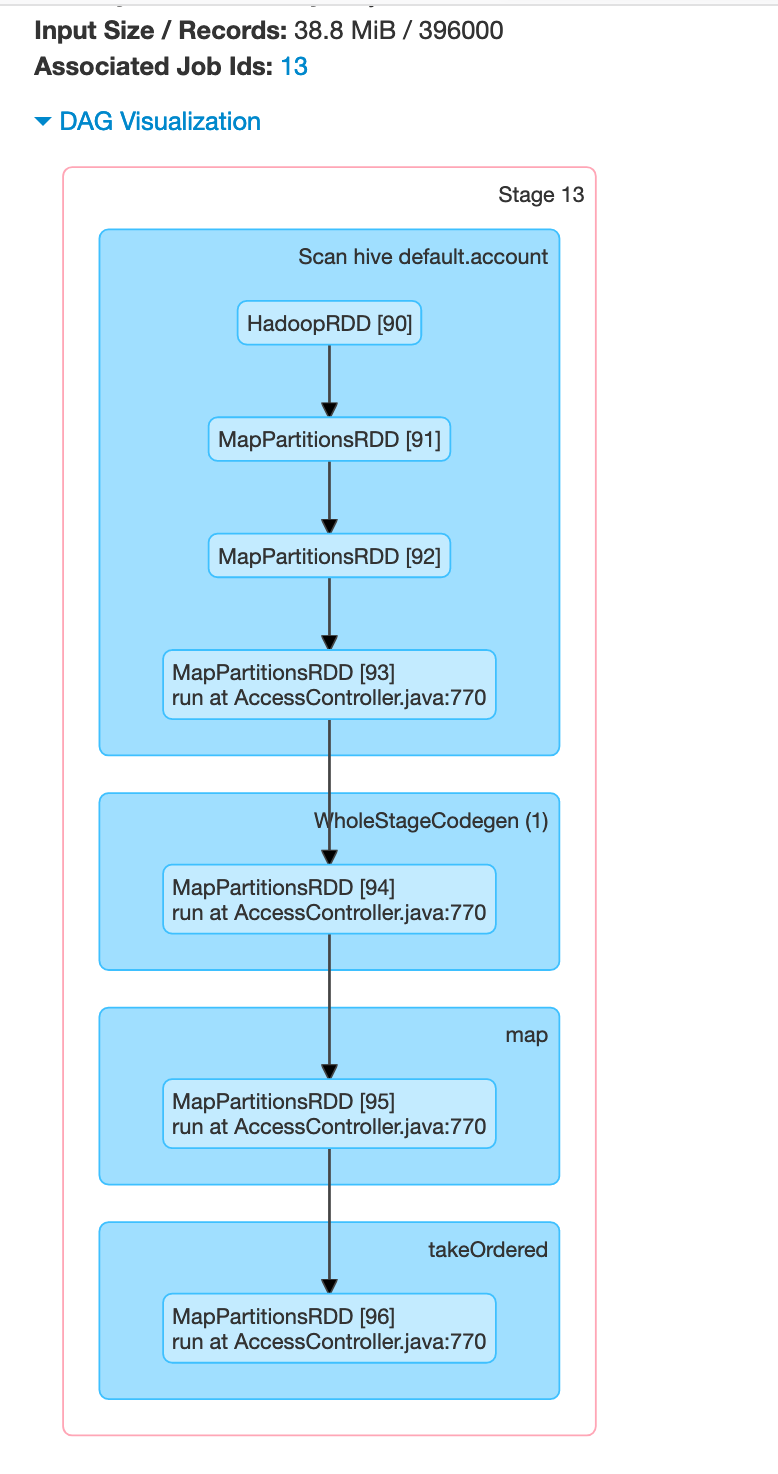
Event timeline

Summary mertics
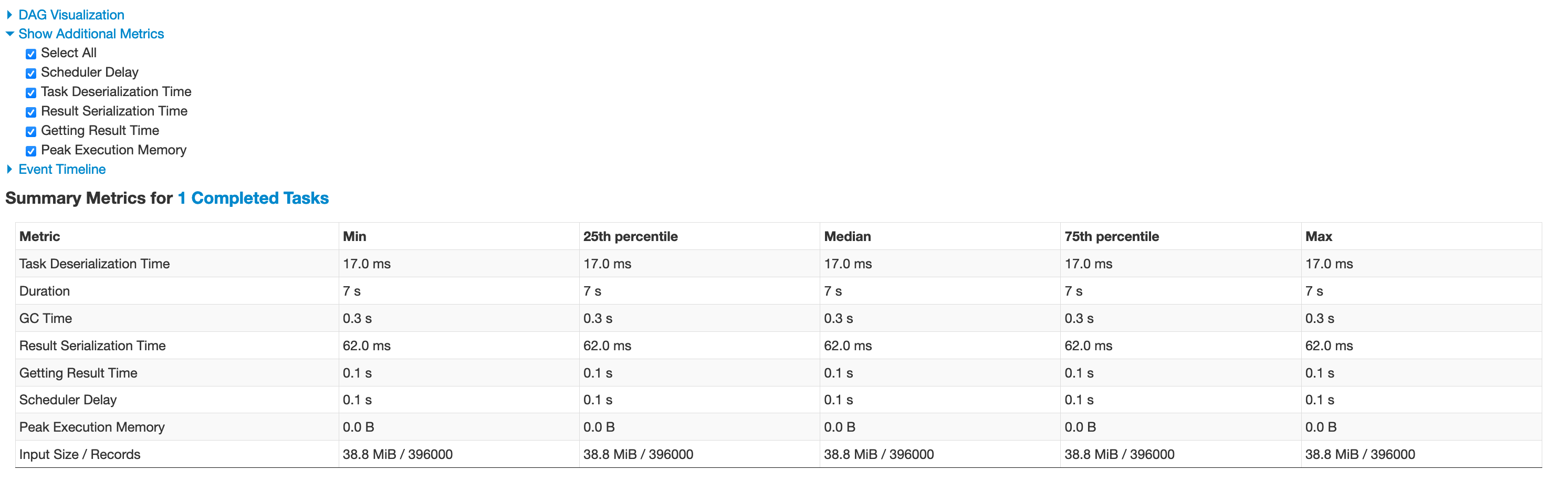
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-792762315
Could you add a few more details? Like How much data is in each file? Does your query end up looking in every file? How were the tables loaded?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-804114746
It may be helpful to benchmark the IO limits of your device, is there a possibility within your configuration storage is being throttled? While it could be cpu bound on the decopression both scenarios are very strange since the read here is trivial
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 edited a comment on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 edited a comment on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-793438458
We have loaded the tables using below spark scala code
val accountDF = spark.read.schema(accschema).parquet("/Users/data/Account/*.parquet")
accountDF.writeTo("Account")
.overwritePartitions()
There are almost 12 parquet files and each parquet file contains around 33k json records and size of each file is around 2.05MB
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-804627993
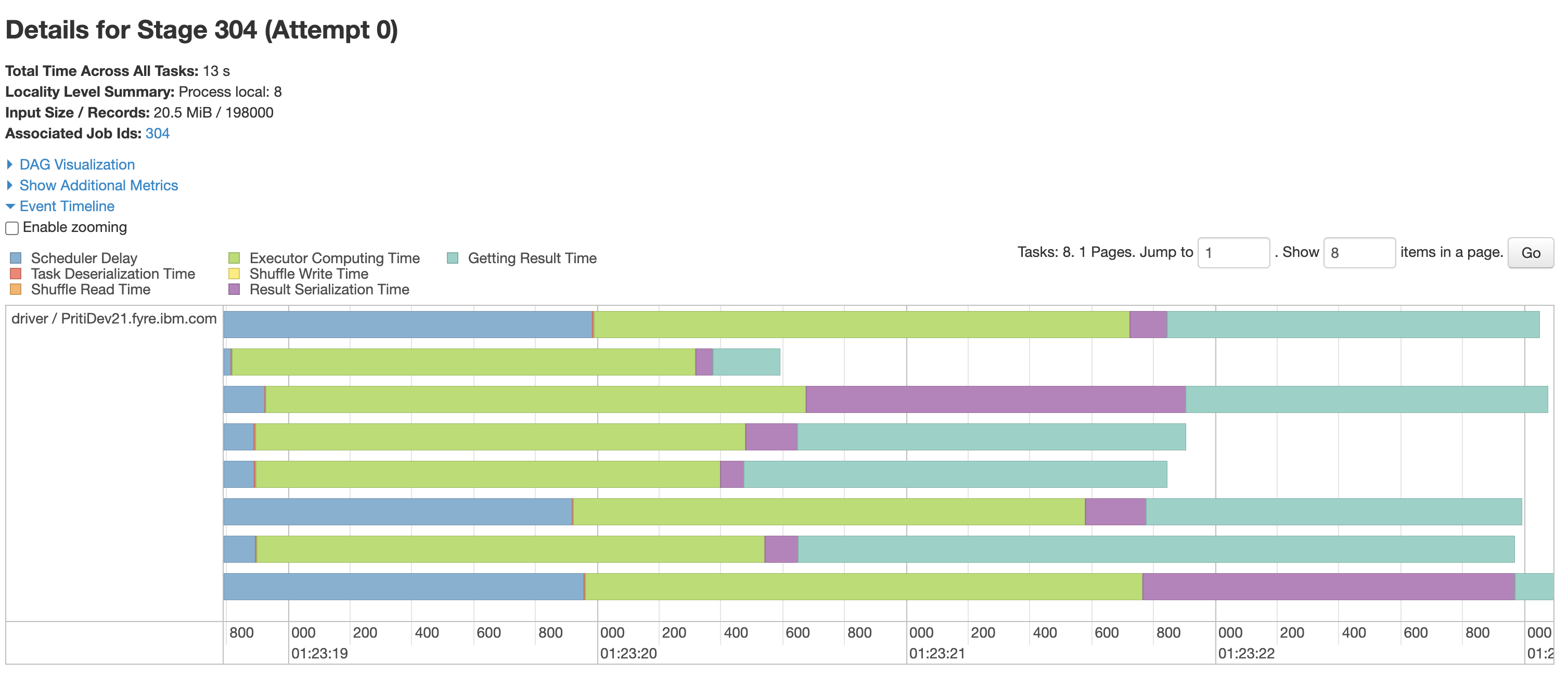
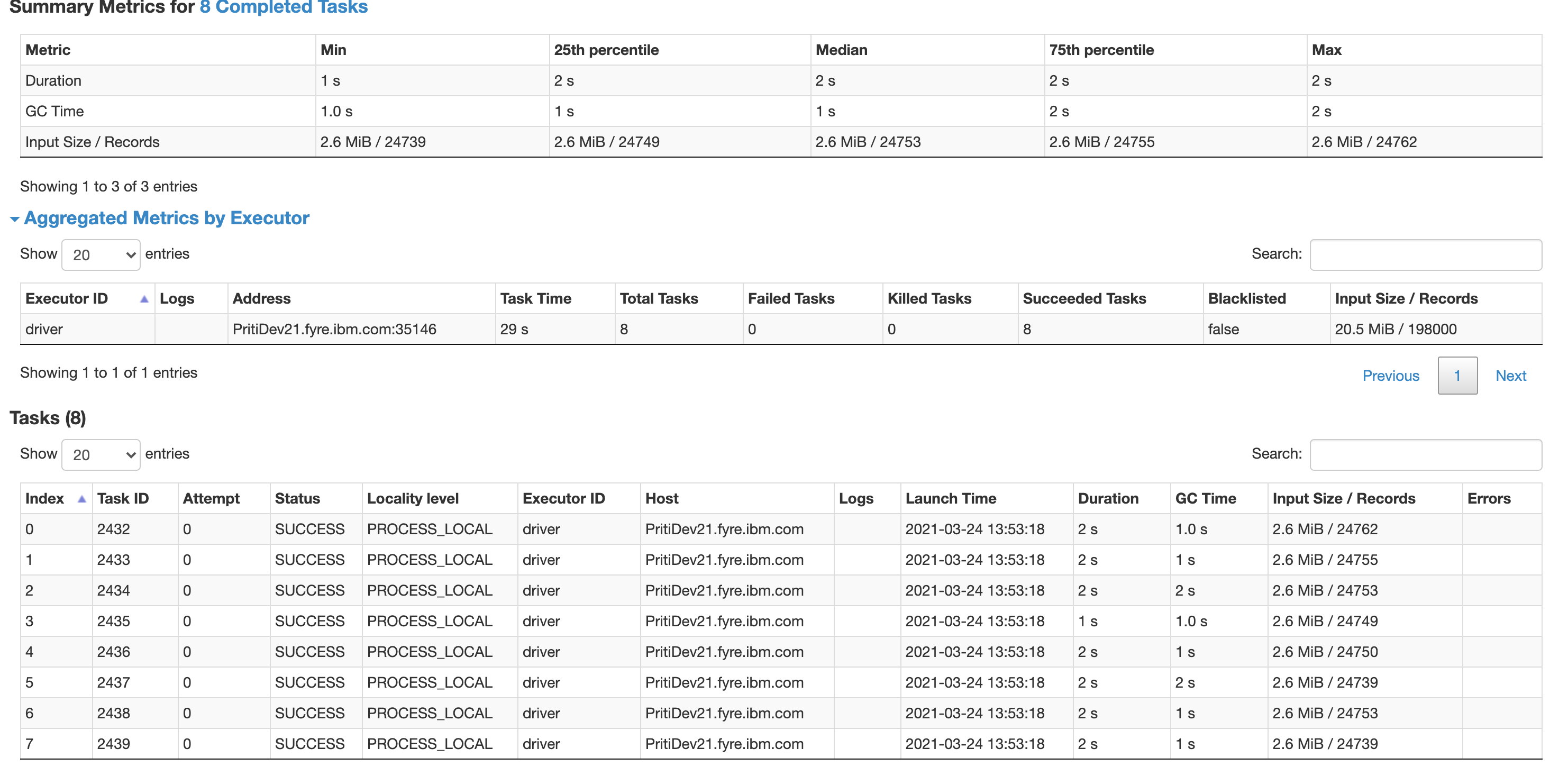
@RussellSpitzer Here is details of one of the stage
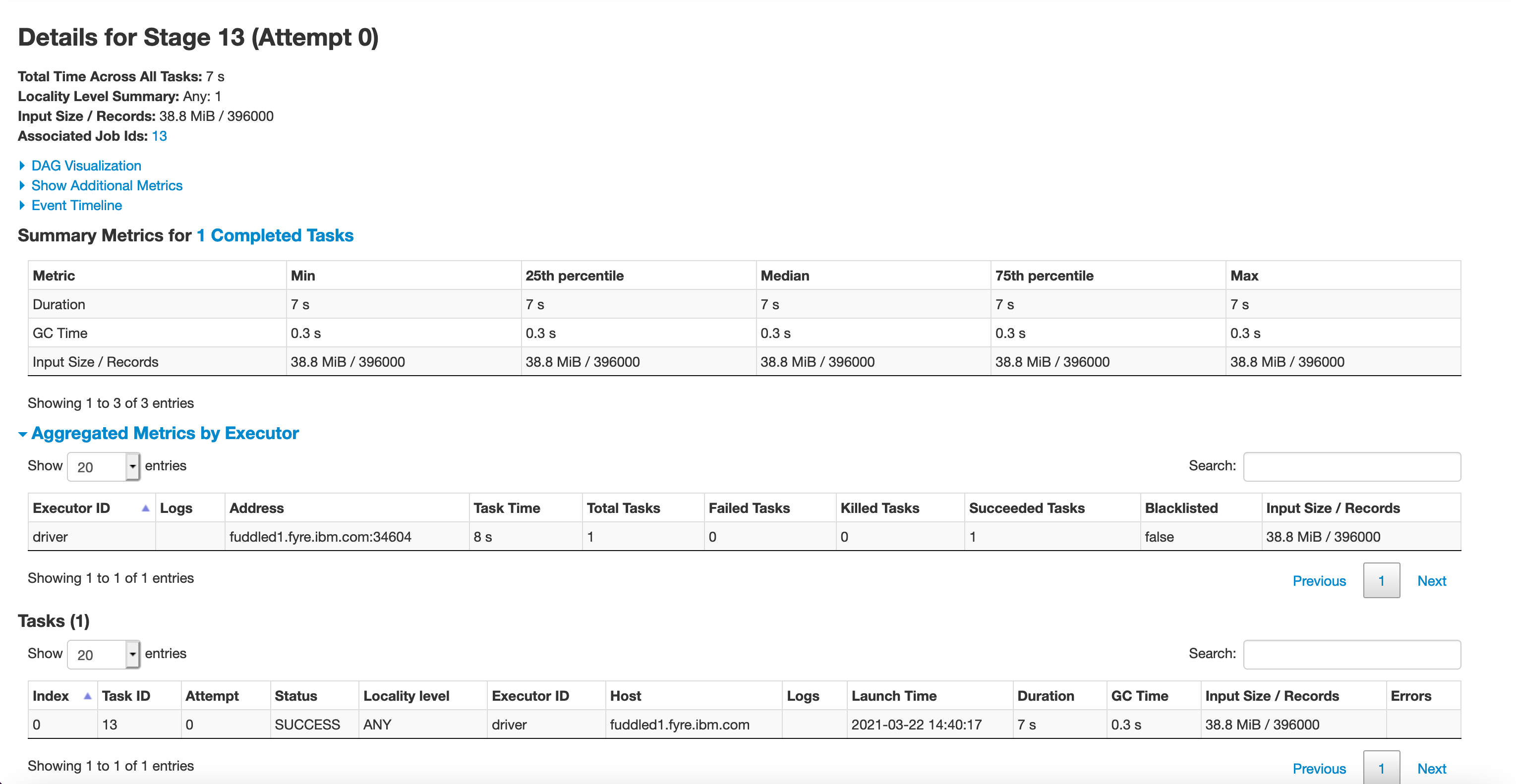
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-805920632
Ok so that speed differences looks to be entirely due to the parallelization difference there, 8 files vs 1. The overall speed seems to be in line. My guess would be it's just a slow setup of hardware and IO. Probably IO based on how long even those tiny tasks took, over a second to read 2.6 mb's of data and deserialize it? Seems not great, results serialization time is also incredibly long on some of those tasks. Everything kinda feels like this system is being overloaded to me ...
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-804914069
Could you please include the event timeline and Dag Visualization?
In addition if you haven't started benchmarking your storage yet, try doing a non iceberg read and write just using the parquet datasource of the same data. Just to check whether it is a storage issue (remember to use the same compression)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] RussellSpitzer commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
RussellSpitzer commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-802829643
I have some thoughts but we still really need more info, if you have a chance could you capture the Spark UI for the job? In particular the stage in which the table is read? My main guess is the actually time spent is related to something like such as scheduling delay or some other Spark level thing. It really doesn't make any sense that it would be reading the files if changing the compression has no effect. I've seen the difference between snappy and gzip be 2x. Also the size of your data is so small it should be practically instantaneous.
So I would request to see the stage/job UI and possibly the table creation statement.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] NageshB82 commented on issue #2302: Reading from iceberg table through spark thrift server using jdbc taking larger time
Posted by GitBox <gi...@apache.org>.
NageshB82 commented on issue #2302:
URL: https://github.com/apache/iceberg/issues/2302#issuecomment-793438458
We have loaded the tables using below spark scala code
val accountDF = spark.read.schema(accschema).parquet("/Users/data/Account/*.parquet")
accountDF.writeTo("Account")
.overwritePartitions()
There are almost 12 parquet files and each parquet file contains around 33k json records
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org