You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2022/11/21 13:05:24 UTC
[GitHub] [iceberg] Fokko commented on a diff in pull request #6233: Python: Implement DataScan.plan_files
Fokko commented on code in PR #6233:
URL: https://github.com/apache/iceberg/pull/6233#discussion_r1027642501
##########
python/pyiceberg/table/__init__.py:
##########
@@ -138,7 +157,10 @@ def __eq__(self, other: Any) -> bool:
)
-class TableScan:
+S = TypeVar("S", bound="TableScan", covariant=True)
Review Comment:
Instead of introducing a generic, we can also return `Self` which feels more Pythonic to me: https://peps.python.org/pep-0673/
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
Review Comment:
Why the `dataclass` here? Should we make it at least frozen?
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
+ pos_to_name: dict[int, str]
+ wrapped: dict[str, Any]
+
+ def __init__(self, partition_type: StructType):
+ self.pos_to_name = {}
+ for pos, field in enumerate(partition_type.fields):
+ self.pos_to_name[pos] = field.name
+
+ def wrap(self, to_wrap: dict[str, Any]) -> _DictAsStruct:
+ self.wrapped = to_wrap
+ return self
+
+ def get(self, pos: int) -> Any:
+ return self.wrapped[self.pos_to_name[pos]]
+
+ def set(self, pos: int, value: Any) -> None:
+ raise NotImplementedError("Cannot set values in DictAsStruct")
+
+
+class DataScan(TableScan["DataScan"]):
+ def __init__(
+ self,
+ table: Table,
+ row_filter: Optional[BooleanExpression] = None,
+ partition_filter: Optional[BooleanExpression] = None,
+ selected_fields: Tuple[str] = ("*",),
+ case_sensitive: bool = True,
+ snapshot_id: Optional[int] = None,
+ options: Properties = EMPTY_DICT,
+ ):
+ super().__init__(table, row_filter, partition_filter, selected_fields, case_sensitive, snapshot_id, options)
+
+ def plan_files(self) -> Iterator[ScanTask]:
+ snapshot = self.snapshot()
+ if not snapshot:
+ return ()
+
+ io = self.table.io
+
+ # step 1: filter manifests using partition summaries
+ # the filter depends on the partition spec used to write the manifest file, so create a cache of filters for each spec id
+
+ @cache
+ def manifest_filter(spec_id: int) -> Callable[[ManifestFile], bool]:
Review Comment:
Can we move those to the class itself? marking it with an underscore indicates that it is not for public use. I don't like inline classes because they are slow and they clutter up your scope (use variables from the outer functions).
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
+ pos_to_name: dict[int, str]
+ wrapped: dict[str, Any]
+
+ def __init__(self, partition_type: StructType):
+ self.pos_to_name = {}
+ for pos, field in enumerate(partition_type.fields):
+ self.pos_to_name[pos] = field.name
+
+ def wrap(self, to_wrap: dict[str, Any]) -> _DictAsStruct:
+ self.wrapped = to_wrap
+ return self
+
+ def get(self, pos: int) -> Any:
+ return self.wrapped[self.pos_to_name[pos]]
+
+ def set(self, pos: int, value: Any) -> None:
+ raise NotImplementedError("Cannot set values in DictAsStruct")
+
+
+class DataScan(TableScan["DataScan"]):
+ def __init__(
+ self,
+ table: Table,
+ row_filter: Optional[BooleanExpression] = None,
+ partition_filter: Optional[BooleanExpression] = None,
+ selected_fields: Tuple[str] = ("*",),
+ case_sensitive: bool = True,
+ snapshot_id: Optional[int] = None,
+ options: Properties = EMPTY_DICT,
+ ):
+ super().__init__(table, row_filter, partition_filter, selected_fields, case_sensitive, snapshot_id, options)
+
+ def plan_files(self) -> Iterator[ScanTask]:
+ snapshot = self.snapshot()
+ if not snapshot:
+ return ()
Review Comment:
In this function, we return both a tuple and a generator. I prefer to be more specific and pick one of them. WDYT?
##########
python/pyiceberg/table/__init__.py:
##########
@@ -16,24 +16,43 @@
# under the License.
from __future__ import annotations
+from abc import ABC, abstractmethod
+from dataclasses import dataclass
+from functools import cache
Review Comment:
This is only available in Python 3.9+, probably we want to import `lru_cache(maxsize=None)`
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
Review Comment:
I'd like to keep the names of the arguments and classes consistent, how about renaming `file` to `data_file`?
##########
python/pyiceberg/manifest.py:
##########
@@ -141,6 +141,14 @@ def read_manifest_entry(input_file: InputFile) -> Iterator[ManifestEntry]:
yield ManifestEntry(**dict_repr)
+def live_entries(input_file: InputFile) -> Iterator[ManifestEntry]:
+ return filter(lambda entry: entry.status != ManifestEntryStatus.DELETED, read_manifest_entry(input_file))
Review Comment:
`filter` returns a generator, we could also just normal list comprehension because this makes it easier down the line. A generator you first have to wrap with `list` to see its contents, instead, now we can just materialize it into an immutable tuple:
```suggestion
return (entry for entry in read_manifest_entry(input_file) if entry.status != ManifestEntryStatus.DELETED)
```
(also, those generators make profiling a harder)
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
+ pos_to_name: dict[int, str]
+ wrapped: dict[str, Any]
+
+ def __init__(self, partition_type: StructType):
+ self.pos_to_name = {}
Review Comment:
We can also do this in a single line:
```suggestion
self.pos_to_name = {pos: field.name for pos, field in enumerate(partition_type.fields)}
```
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,114 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ data_file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.data_file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
Review Comment:
Interestingly enough I'm also seeing a huge difference between PyArrow and S3FS:
PyArrow:
```
➜ python git:(python-implement-plan-files) ✗ python3
Python 3.10.8 (main, Oct 13 2022, 09:48:40) [Clang 14.0.0 (clang-1400.0.29.102)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import timeit
>>>
>>> setup = '''
... from pyiceberg.catalog import load_catalog
... from pyiceberg.expressions import EqualTo
...
... def test_runtime():
... assert [
... file.file.file_path
... for file in load_catalog("local", type="rest")
... .load_table(("nyc", "taxis"))
... .scan()
... .filter_partitions(EqualTo("VendorID", 5))
... .plan_files()
... ] == [
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-506-c9e4e601-f928-4527-bfd2-5331347d5020-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-497-5482509f-866d-466f-9fc3-5ea9699a8418-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-488-4c01921b-7f5a-4237-926f-c3493ab043b3-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-479-286951ca-66ac-46fa-9d48-68ee9901c241-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-461-3c2c0cc4-7dbd-41f7-be16-7a3f9ac21717-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-443-06baebe6-78e0-4b88-a926-77fd7cc61dbd-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-434-3950631d-6608-4c11-8359-5ef0ee9512af-00003.parquet",
... ]
... '''
>>> timeit.Timer('test_runtime()', setup=setup).repeat(5, 5)
[7.958402707998175, 8.398074124997947, 8.664345958997728, 8.544483707999461, 8.72150599998713]
>>> result = [7.958402707998175, 8.398074124997947, 8.664345958997728, 8.544483707999461, 8.72150599998713]
>>> sum(result) / len(result)
8.457362499996089 seconds
```
S3FS:
```
➜ python git:(python-implement-plan-files) ✗ python3
Python 3.10.8 (main, Oct 13 2022, 09:48:40) [Clang 14.0.0 (clang-1400.0.29.102)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import timeit
>>>
>>> setup = '''
... from pyiceberg.catalog import load_catalog
... from pyiceberg.expressions import EqualTo
...
... def test_runtime():
... assert [
... file.file.file_path
... for file in load_catalog("local", type="rest")
... .load_table(("nyc", "taxis"))
... .scan()
... .filter_partitions(EqualTo("VendorID", 5))
... .plan_files()
... ] == [
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-506-c9e4e601-f928-4527-bfd2-5331347d5020-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-497-5482509f-866d-466f-9fc3-5ea9699a8418-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-488-4c01921b-7f5a-4237-926f-c3493ab043b3-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-479-286951ca-66ac-46fa-9d48-68ee9901c241-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-461-3c2c0cc4-7dbd-41f7-be16-7a3f9ac21717-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-443-06baebe6-78e0-4b88-a926-77fd7cc61dbd-00003.parquet",
... "s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-434-3950631d-6608-4c11-8359-5ef0ee9512af-00003.parquet",
... ]
... '''
>>>
>>>
>>>
>>> timeit.Timer('test_runtime()', setup=setup).repeat(5, 5)
[0.9587976249895291, 0.6429896249901503, 0.6377595839876449, 0.6488105829921551, 0.7382178330008173]
>>> sum(result) / len(result)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'result' is not defined
>>> result = [0.9587976249895291, 0.6429896249901503, 0.6377595839876449, 0.6488105829921551, 0.7382178330008173]
>>> sum(result) / len(result)
0.7253150499920593 seconds
```
All far from 81 seconds (even the 9 vs 12 manifests don't explain that difference)
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
+ pos_to_name: dict[int, str]
+ wrapped: dict[str, Any]
Review Comment:
```suggestion
wrapped: Dict[str, Any]
```
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,114 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ data_file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.data_file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
Review Comment:
Some partitioned table locally in a minio:
```
pyiceberg --catalog local files nyc.taxis
Snapshots: local.nyc.taxis
└── Snapshot 1845088053833480628, schema 0: s3a://warehouse/wh/nyc/taxis/metadata/snap-1845088053833480628-1-bbe114f3-1429-44ee-a594-7c7b50f70fd7.avro
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/bbe114f3-1429-44ee-a594-7c7b50f70fd7-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-506-c9e4e601-f928-4527-bfd2-5331347d5020-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-506-c9e4e601-f928-4527-bfd2-5331347d5020-00002.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-506-c9e4e601-f928-4527-bfd2-5331347d5020-00003.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-506-c9e4e601-f928-4527-bfd2-5331347d5020-00004.parquet
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/255cf01f-394b-4321-a551-7d6731c03377-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-497-5482509f-866d-466f-9fc3-5ea9699a8418-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-497-5482509f-866d-466f-9fc3-5ea9699a8418-00002.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-497-5482509f-866d-466f-9fc3-5ea9699a8418-00003.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-497-5482509f-866d-466f-9fc3-5ea9699a8418-00004.parquet
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/e0648a46-5c3f-42f9-a220-29d2cdb565b5-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-488-4c01921b-7f5a-4237-926f-c3493ab043b3-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-488-4c01921b-7f5a-4237-926f-c3493ab043b3-00002.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-488-4c01921b-7f5a-4237-926f-c3493ab043b3-00003.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-488-4c01921b-7f5a-4237-926f-c3493ab043b3-00004.parquet
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/a079054f-f6db-451b-89f1-246a034cec6f-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-479-286951ca-66ac-46fa-9d48-68ee9901c241-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-479-286951ca-66ac-46fa-9d48-68ee9901c241-00002.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-479-286951ca-66ac-46fa-9d48-68ee9901c241-00003.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-479-286951ca-66ac-46fa-9d48-68ee9901c241-00004.parquet
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/19abeb75-e5c8-4bbc-b880-0736097bdc8a-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-470-333f3406-9008-486d-af2e-b08a06194056-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-470-333f3406-9008-486d-af2e-b08a06194056-00002.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-470-333f3406-9008-486d-af2e-b08a06194056-00003.parquet
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/e7172d96-1911-435f-889a-9b0f2f778c73-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-461-3c2c0cc4-7dbd-41f7-be16-7a3f9ac21717-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-461-3c2c0cc4-7dbd-41f7-be16-7a3f9ac21717-00002.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-461-3c2c0cc4-7dbd-41f7-be16-7a3f9ac21717-00003.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-461-3c2c0cc4-7dbd-41f7-be16-7a3f9ac21717-00004.parquet
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/60f0b9bc-46c3-49e4-9f87-713974fd941a-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-452-533c1841-0279-4999-a2ec-9d202373c517-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-452-533c1841-0279-4999-a2ec-9d202373c517-00002.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-452-533c1841-0279-4999-a2ec-9d202373c517-00003.parquet
├── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/15a93fd1-de7f-44ce-b5cc-447af407f98b-m0.avro
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-443-06baebe6-78e0-4b88-a926-77fd7cc61dbd-00001.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-443-06baebe6-78e0-4b88-a926-77fd7cc61dbd-00002.parquet
│ ├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-443-06baebe6-78e0-4b88-a926-77fd7cc61dbd-00003.parquet
│ └── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-443-06baebe6-78e0-4b88-a926-77fd7cc61dbd-00004.parquet
└── Manifest: s3a://warehouse/wh/nyc/taxis/metadata/d612b293-3e35-4cf6-8fff-46b50c135a15-m0.avro
├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=1/00003-434-3950631d-6608-4c11-8359-5ef0ee9512af-00001.parquet
├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=2/00003-434-3950631d-6608-4c11-8359-5ef0ee9512af-00002.parquet
├── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-434-3950631d-6608-4c11-8359-5ef0ee9512af-00003.parquet
└── Datafile: s3a://warehouse/wh/nyc/taxis/data/VendorID=6/00003-434-3950631d-6608-4c11-8359-5ef0ee9512af-00004.parquet
```
##########
python/pyproject.toml:
##########
@@ -84,6 +84,7 @@ build-backend = "poetry.core.masonry.api"
[tool.poetry.extras]
pyarrow = ["pyarrow"]
+duckdb = ["duckdb"]
Review Comment:
- Looks like the actual import is missing, we should add one above that's optional (and pin it to a version).
- Let's add this option to the docs as well
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
+ pos_to_name: dict[int, str]
Review Comment:
```suggestion
pos_to_name: Dict[int, str]
```
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
+ pos_to_name: dict[int, str]
+ wrapped: dict[str, Any]
+
+ def __init__(self, partition_type: StructType):
+ self.pos_to_name = {}
+ for pos, field in enumerate(partition_type.fields):
+ self.pos_to_name[pos] = field.name
+
+ def wrap(self, to_wrap: dict[str, Any]) -> _DictAsStruct:
Review Comment:
```suggestion
def wrap(self, to_wrap: Dict[str, Any]) -> _DictAsStruct:
```
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,143 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
+ pos_to_name: dict[int, str]
+ wrapped: dict[str, Any]
+
+ def __init__(self, partition_type: StructType):
+ self.pos_to_name = {}
+ for pos, field in enumerate(partition_type.fields):
+ self.pos_to_name[pos] = field.name
+
+ def wrap(self, to_wrap: dict[str, Any]) -> _DictAsStruct:
+ self.wrapped = to_wrap
+ return self
+
+ def get(self, pos: int) -> Any:
+ return self.wrapped[self.pos_to_name[pos]]
+
+ def set(self, pos: int, value: Any) -> None:
+ raise NotImplementedError("Cannot set values in DictAsStruct")
+
+
+class DataScan(TableScan["DataScan"]):
+ def __init__(
+ self,
+ table: Table,
+ row_filter: Optional[BooleanExpression] = None,
+ partition_filter: Optional[BooleanExpression] = None,
+ selected_fields: Tuple[str] = ("*",),
+ case_sensitive: bool = True,
+ snapshot_id: Optional[int] = None,
+ options: Properties = EMPTY_DICT,
+ ):
+ super().__init__(table, row_filter, partition_filter, selected_fields, case_sensitive, snapshot_id, options)
+
+ def plan_files(self) -> Iterator[ScanTask]:
+ snapshot = self.snapshot()
+ if not snapshot:
+ return ()
+
+ io = self.table.io
+
+ # step 1: filter manifests using partition summaries
+ # the filter depends on the partition spec used to write the manifest file, so create a cache of filters for each spec id
+
+ @cache
+ def manifest_filter(spec_id: int) -> Callable[[ManifestFile], bool]:
+ spec = self.table.specs()[spec_id]
+ return visitors.manifest_evaluator(spec, self.table.schema(), self.partition_filter, self.case_sensitive)
+
+ def partition_summary_filter(manifest_file: ManifestFile) -> bool:
Review Comment:
We could replace this function by list comprehension. This combines it with the filter below:
```python
manifests = [
manifest_file
for manifest_file in snapshot.manifests(io)
if manifest_filter(manifest_file.partition_spec_id)(manifest_file)
]
```
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,114 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ data_file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.data_file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
Review Comment:
81 seconds is insane. I'll fire up the profiler.
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,114 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ data_file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.data_file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
Review Comment:
Profiling the following code:
```python
assert [
file.file.file_path
for file in load_catalog("local", type="rest")
.load_table(("nyc", "taxis"))
.scan()
.filter_partitions(EqualTo("VendorID", 5))
.plan_files()
] == [
"s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-506-c9e4e601-f928-4527-bfd2-5331347d5020-00003.parquet",
"s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-497-5482509f-866d-466f-9fc3-5ea9699a8418-00003.parquet",
"s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-488-4c01921b-7f5a-4237-926f-c3493ab043b3-00003.parquet",
"s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-479-286951ca-66ac-46fa-9d48-68ee9901c241-00003.parquet",
"s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-461-3c2c0cc4-7dbd-41f7-be16-7a3f9ac21717-00003.parquet",
"s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-443-06baebe6-78e0-4b88-a926-77fd7cc61dbd-00003.parquet",
"s3a://warehouse/wh/nyc/taxis/data/VendorID=5/00003-434-3950631d-6608-4c11-8359-5ef0ee9512af-00003.parquet",
]
```
And we get a nice call graph.
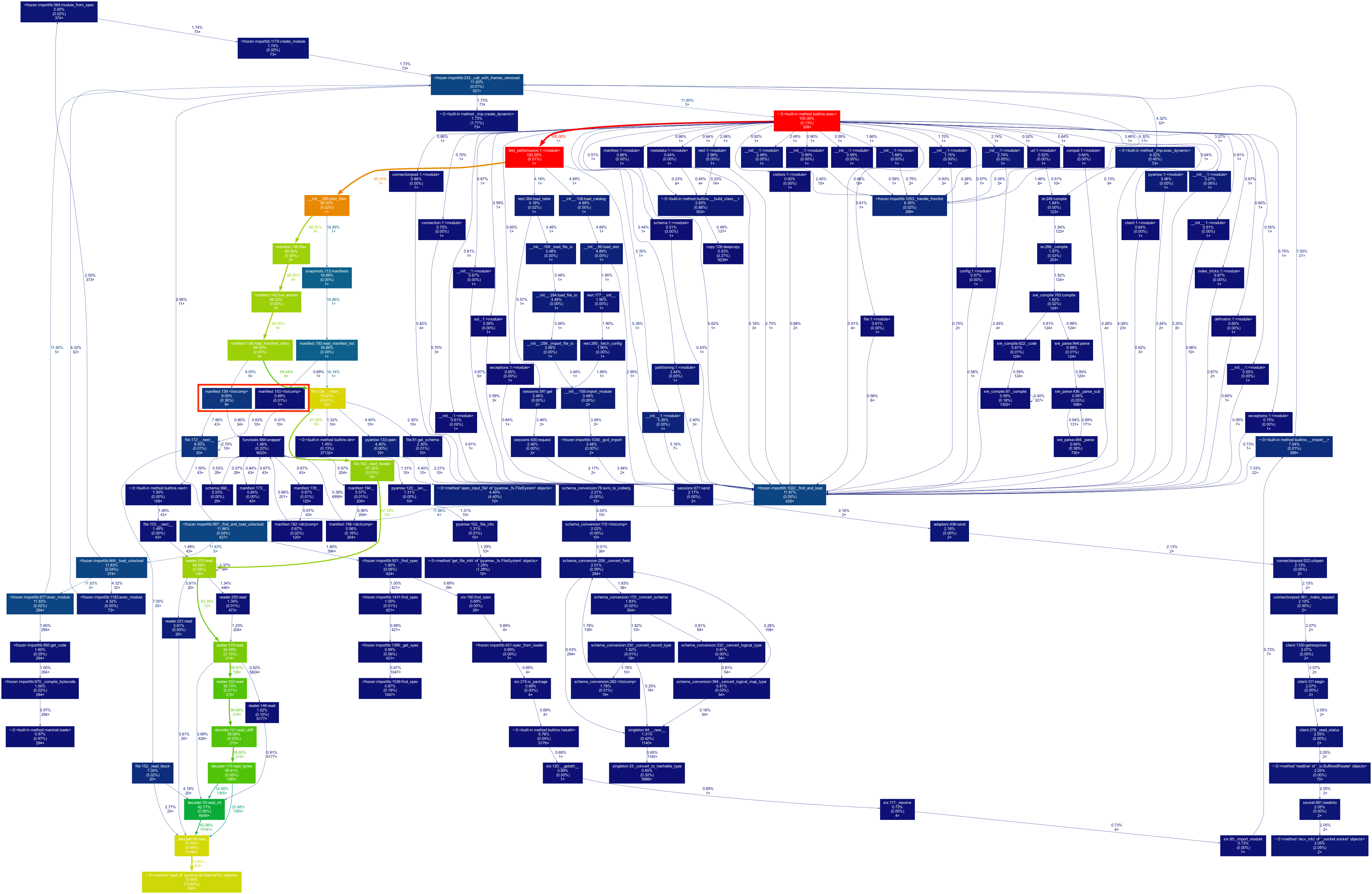
I've marked the conversion, and it indeed takes a bit of time. Probably we could benefit much more from an Avro reader that delegates the reading to C (like FastAvro).
##########
python/pyiceberg/table/__init__.py:
##########
@@ -199,16 +223,114 @@ def use_ref(self, name: str):
raise ValueError(f"Cannot scan unknown ref={name}")
- def select(self, *field_names: str) -> TableScan:
+ def select(self, *field_names: str) -> S:
if "*" in self.selected_fields:
return self.update(selected_fields=field_names)
return self.update(selected_fields=tuple(set(self.selected_fields).intersection(set(field_names))))
- def filter_rows(self, new_row_filter: BooleanExpression) -> TableScan:
+ def filter_rows(self, new_row_filter: BooleanExpression) -> S:
return self.update(row_filter=And(self.row_filter, new_row_filter))
- def filter_partitions(self, new_partition_filter: BooleanExpression) -> TableScan:
+ def filter_partitions(self, new_partition_filter: BooleanExpression) -> S:
return self.update(partition_filter=And(self.partition_filter, new_partition_filter))
- def with_case_sensitive(self, case_sensitive: bool = True) -> TableScan:
+ def with_case_sensitive(self, case_sensitive: bool = True) -> S:
return self.update(case_sensitive=case_sensitive)
+
+
+class ScanTask(ABC):
+ pass
+
+
+@dataclass(init=False)
+class FileScanTask(ScanTask):
+ data_file: DataFile
+ start: int
+ length: int
+
+ def __init__(self, data_file: DataFile, start: Optional[int] = None, length: Optional[int] = None):
+ self.data_file = data_file
+ self.start = start or 0
+ self.length = length or data_file.file_size_in_bytes
+
+
+class _DictAsStruct(StructProtocol):
Review Comment:
With S3FS the conversion becomes much more dominant, so good idea to rip that out:
The manifests creating takes around 5.5% of the total time (including reading etc).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org