You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2022/08/09 04:16:21 UTC
[GitHub] [spark] Transurgeon opened a new pull request, #37444: [SPARK-40012][PYTHON][DOCS][WIP] Make pyspark.sql.dataframe examples self-contained
Transurgeon opened a new pull request, #37444:
URL: https://github.com/apache/spark/pull/37444
### What changes were proposed in this pull request?
This PR proposes to improve the examples in pyspark.sql.dataframe by making each example self-contained with more realistic examples
### Why are the changes needed?
To make the documentation more readable and able to copy and paste directly in PySpark shell.
### Does this PR introduce _any_ user-facing change?
Yes, Documentation changes only
### How was this patch tested?
Built documentation on local
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS][WIP] Make pyspark.sql.dataframe examples self-contained
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1224257738
@HyukjinKwon.
No not WIP anymore, I wanted to get some feedback to see if I was making good changes before I continue working on it.
Should I remove the WIP tag?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1229827907
Hey, let's co-author this change. I will create another PR on the top of this PR to speed this up.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955517851
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4100,7 +4256,7 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Parameters
----------
cols : str
- new column names
+ new column names. The length of the list needs to be the same as the number of columns in the initial :class:`DataFrame`
Review Comment:
@Transurgeon mind running `./dev/lint-python` script and fix the line length, etc?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dcoliversun commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
dcoliversun commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953482703
##########
python/pyspark/sql/dataframe.py:
##########
@@ -862,8 +894,18 @@ def take(self, num: int) -> List[Row]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
... (16, "Bob")], ["age", "name"])
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
itholic commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955516822
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4064,11 +4200,31 @@ def drop(self, *cols: "ColumnOrName") -> "DataFrame": # type: ignore[misc]
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop('age').collect()
Review Comment:
How about using `show()` here instead of `collect()`, to make it easier to show that a column has been deleted?
```python
>>> df.drop('age').show()
+-----+
| name|
+-----+
| Tom|
|Alice|
| Bob|
+-----+
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955584535
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4100,7 +4256,7 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Parameters
----------
cols : str
- new column names
+ new column names. The length of the list needs to be the same as the number of columns in the initial :class:`DataFrame`
Review Comment:
done
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4109,8 +4265,18 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
also done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955541665
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4100,7 +4256,7 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Parameters
----------
cols : str
- new column names
+ new column names. The length of the list needs to be the same as the number of columns in the initial :class:`DataFrame`
Review Comment:
yes will do, sorry about that
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953197497
##########
python/pyspark/sql/dataframe.py:
##########
@@ -2743,7 +2814,20 @@ def fillna(
Examples
--------
- >>> df4.na.fill(50).show()
+ Fill all null values with 50 when the data type of the column is an integer
+
+ >>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
+ ... (None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
Review Comment:
intentation
##########
python/pyspark/sql/dataframe.py:
##########
@@ -2753,7 +2837,19 @@ def fillna(
| 50| 50| null|
+---+------+-----+
- >>> df5.na.fill(False).show()
+ Fill all null values with False when the data type of the column is a boolean
Review Comment:
```suggestion
Fill all null values with ``False`` when the data type of the column is a boolean
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953198186
##########
python/pyspark/sql/dataframe.py:
##########
@@ -3393,12 +3549,22 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Parameters
----------
cols : str
- new column names
+ new column names. The length of the list needs to be the same as the number of columns in the initial DataFrame
Review Comment:
```suggestion
new column names. The length of the list needs to be the same as the number of columns in the initial :class:`DataFrame`
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1224746488
@HyukjinKwon I made some additional changes. I think we can start by merging this PR, then I will make another one for the rest of the changes.
I have a list of all the functions I made changes to in this PR, should I add it to the JIRA ticket to avoid duplicate changes?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953195936
##########
python/pyspark/sql/dataframe.py:
##########
@@ -363,9 +363,18 @@ def schema(self) -> StructType:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame(
... [(14, "Tom"), (23, "Alice"),(16, "Bob")], ["age", "name"])
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953197159
##########
python/pyspark/sql/dataframe.py:
##########
@@ -798,8 +820,18 @@ def count(self) -> int:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.count()
Review Comment:
ditto. let's add some description
##########
python/pyspark/sql/dataframe.py:
##########
@@ -862,8 +894,18 @@ def take(self, num: int) -> List[Row]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.take(2)
Review Comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955519026
##########
python/pyspark/sql/dataframe.py:
##########
@@ -477,9 +477,22 @@ def schema(self) -> StructType:
Examples
--------
+ >>> df = spark.createDataFrame(
+ ... [(14, "Tom"), (23, "Alice"),(16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
+
+ Retrieve the schema of the current DataFrame.
+
>>> df.schema
- StructType([StructField('age', IntegerType(), True),
- StructField('name', StringType(), True)])
+ StructType([StructField('age', IntegerType(), True),
+ StructField('name', StringType(), True)])
Review Comment:
Please avoid using tabs
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS][WIP] Make pyspark.sql.dataframe examples self-contained
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1223376894
@Transurgeon is this still WIP? If there are too many to fix, feel free to split into multiple PRs.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955575094
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1722,8 +1806,17 @@ def dtypes(self) -> List[Tuple[str, str]]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"),
+ ... (23, "Alice")], ["age", "name"])
Review Comment:
what do you mean by inline?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon closed pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
URL: https://github.com/apache/spark/pull/37444
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1227093926
Im gonna take this over if the PR author gets inactive few more days - this is the last task left for the umbrella task.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955518944
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4109,8 +4265,18 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
indentation
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955518409
##########
python/pyspark/sql/dataframe.py:
##########
@@ -731,29 +744,51 @@ def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool =
Examples
--------
- >>> df
- DataFrame[age: int, name: string]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
>>> df.show()
+---+-----+
|age| name|
+---+-----+
- | 2|Alice|
- | 5| Bob|
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
+
+ Show only top 2 rows.
+
+ >>> df.show(2)
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+---+-----+
+ only showing top 2 rows
+
+ Show DataFrame where the maximum number of characters is 3.
Review Comment:
"the maximum number of characters is 3" sounds a bit confusing. I believe this is the maximum number of rows to show.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953195766
##########
python/pyspark/sql/dataframe.py:
##########
@@ -363,9 +363,18 @@ def schema(self) -> StructType:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.schema
- StructType([StructField('age', IntegerType(), True),
- StructField('name', StringType(), True)])
+ StructType([StructField('age', LongType(), True), StructField('name', StringType(), True)])
Review Comment:
The change here seems unnecessarily
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953195599
##########
python/pyspark/sql/dataframe.py:
##########
@@ -363,9 +363,18 @@ def schema(self) -> StructType:
Examples
Review Comment:
Can we add `Returns` section?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955575341
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1722,8 +1806,17 @@ def dtypes(self) -> List[Tuple[str, str]]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"),
+ ... (23, "Alice")], ["age", "name"])
Review Comment:
nvm, I remember in the other example you had [14, "tom"] in the same line as the others
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dcoliversun commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
dcoliversun commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953483561
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1375,8 +1437,17 @@ def dtypes(self) -> List[Tuple[str, str]]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"),
+ ... (23, "Alice")], ["age", "name"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame([(14, "Tom"),
... (23, "Alice")], ["age", "name"])
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -2899,7 +3022,20 @@ def replace( # type: ignore[misc]
|null| null|null|
+----+------+----+
- >>> df4.na.replace(['Alice', 'Bob'], ['A', 'B'], 'name').show()
+ Replace all instances of Alice to 'A' and Bob to 'B' under the name column
+
+ >>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
Review Comment:
Why do we need to create duplicate dataframe here? If we don't need it, better to delete
```shell
>>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),(None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
>>> df.show()
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
| 5| null| Bob|
|null| null| Tom|
|null| null| null|
+----+------+-----+
>>> df.na.replace('Alice', None).show()
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
| 5| null| Bob|
|null| null| Tom|
|null| null|null|
+----+------+----+
>>> df.show()
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
| 5| null| Bob|
|null| null| Tom|
|null| null| null|
+----+------+-----+
>>> df.na.replace(['Alice', 'Bob'], ['A', 'B'], 'name').show()
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80| A|
| 5| null| B|
|null| null| Tom|
|null| null|null|
+----+------+----+
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1179,6 +1231,16 @@ def distinct(self) -> "DataFrame":
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (23, "Alice")], ["age", "name"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
... (23, "Alice")], ["age", "name"])
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -2869,7 +2978,18 @@ def replace( # type: ignore[misc]
Examples
--------
- >>> df4.na.replace(10, 20).show()
+ >>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
+ ... (None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
... (None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -2762,7 +2858,20 @@ def fillna(
|null|Mallory| true|
+----+-------+-----+
- >>> df4.na.fill({'age': 50, 'name': 'unknown'}).show()
+ Fill all null values in the 'age' column to 50 and "unknown" in the 'name' column
+
+ >>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
+ ... (None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
... (None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -878,8 +920,18 @@ def tail(self, num: int) -> List[Row]:
Examples
--------
- >>> df.tail(1)
- [Row(age=5, name='Bob')]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
... (16, "Bob")], ["age", "name"])
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -2753,7 +2837,19 @@ def fillna(
| 50| 50| null|
+---+------+-----+
- >>> df5.na.fill(False).show()
+ Fill all null values with False when the data type of the column is a boolean
+
+ >>> df = spark.createDataFrame([(10, "Alice", None), (5, "Bob", None),
+ ... (None, "Mallory", True)], ["age", "name", "spy"])
Review Comment:
```suggestion
>>> df = spark.createDataFrame([(10, "Alice", None), (5, "Bob", None),
... (None, "Mallory", True)], ["age", "name", "spy"])
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1224999813
I think you can reuse the same JIRA, and make a followup.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955518611
##########
python/pyspark/sql/dataframe.py:
##########
@@ -731,29 +744,51 @@ def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool =
Examples
--------
- >>> df
- DataFrame[age: int, name: string]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
should use 4 spaces instead of a tab
##########
python/pyspark/sql/dataframe.py:
##########
@@ -992,8 +1027,21 @@ def count(self) -> int:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
indentation
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955518826
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1722,8 +1806,17 @@ def dtypes(self) -> List[Tuple[str, str]]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"),
+ ... (23, "Alice")], ["age", "name"])
Review Comment:
I think you can inline here
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS][WIP] Make pyspark.sql.dataframe examples self-contained
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1208893246
I set the tag [WIP] because dataframe.py needs a lot of updates. I will add some additional changes to this PR in the upcoming days.
Please review and provide some feedback.
Thanks
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
itholic commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955514877
##########
python/pyspark/sql/dataframe.py:
##########
@@ -3358,7 +3451,20 @@ def fillna(
Examples
--------
- >>> df4.na.fill(50).show()
+ Fill all null values with 50 when the data type of the column is an integer
+
+ >>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
+ ... (None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
+ >>> df.show()
+ +----+------+-----+
+ | age|height| name|
+ +----+------+-----+
+ | 10| 80|Alice|
+ | 5| null| Bob|
+ |null| null| Tom|
+ |null| null| null|
+ +----+------+-----+
+ >>> df.na.fill(50).show()
Review Comment:
ditto ?
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4064,11 +4200,31 @@ def drop(self, *cols: "ColumnOrName") -> "DataFrame": # type: ignore[misc]
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop('age').collect()
Review Comment:
How about using `show()` here to make it easier to show that a column has been deleted?
##########
python/pyspark/sql/dataframe.py:
##########
@@ -3489,7 +3620,18 @@ def replace( # type: ignore[misc]
Examples
--------
- >>> df4.na.replace(10, 20).show()
+ >>> df = spark.createDataFrame([(10, 80, "Alice"), (5, None, "Bob"),
+ ... (None, None, "Tom"), (None, None, None)], ["age", "height", "name"])
+ >>> df.show()
+ +----+------+-----+
+ | age|height| name|
+ +----+------+-----+
+ | 10| 80|Alice|
+ | 5| null| Bob|
+ |null| null| Tom|
+ |null| null| null|
+ +----+------+-----+
+ >>> df.na.replace(10, 20).show()
Review Comment:
ditto ?
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4100,7 +4256,7 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Parameters
----------
cols : str
- new column names
+ new column names. The length of the list needs to be the same as the number of columns in the initial :class:`DataFrame`
Review Comment:
Seems like it exceeds the 100 lines, which violates `flake8` rule.
```shell
starting flake8 test...
flake8 checks failed:
./python/pyspark/sql/dataframe.py:4250:101: E501 line too long (128 > 100 characters)
"""
Returns a best-effort snapshot of the files that compose this :class:`DataFrame`.
This method simply asks each constituent BaseRelation for its respective files and
takes the union of all results. Depending on the source relations, this may not find
all input files. Duplicates are removed.
new column names. The length of the list needs to be the same as the number of columns in the initial :class:`DataFrame`
.. versionadded:: 3.1.0
Returns
-------
list
List of file paths.
Examples
--------
>>> df = spark.read.load("examples/src/main/resources/people.json", format="json")
>>> len(df.inputFiles())
1
"""
^
1 E501 line too long (128 > 100 characters)
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -3368,7 +3474,19 @@ def fillna(
| 50| 50| null|
+---+------+-----+
- >>> df5.na.fill(False).show()
+ Fill all null values with ``False`` when the data type of the column is a boolean
+
+ >>> df = spark.createDataFrame([(10, "Alice", None), (5, "Bob", None),
+ ... (None, "Mallory", True)], ["age", "name", "spy"])
+ >>> df.show()
+ +----+-------+----+
+ | age| name| spy|
+ +----+-------+----+
+ | 10| Alice|null|
+ | 5| Bob|null|
+ |null|Mallory|true|
+ +----+-------+----+
+ >>> df.na.fill(False).show()
Review Comment:
ditto ?
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4100,7 +4256,7 @@ def toDF(self, *cols: "ColumnOrName") -> "DataFrame":
Parameters
----------
cols : str
- new column names
+ new column names. The length of the list needs to be the same as the number of columns in the initial :class:`DataFrame`
Review Comment:
You can run `dev/lint-python` to check if the static analysis is passed.
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1722,8 +1806,17 @@ def dtypes(self) -> List[Tuple[str, str]]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"),
+ ... (23, "Alice")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ +---+-----+
>>> df.dtypes
Review Comment:
Can we have a new line between the examples with short description, for better readability ?
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4064,11 +4200,31 @@ def drop(self, *cols: "ColumnOrName") -> "DataFrame": # type: ignore[misc]
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop('age').collect()
- [Row(name='Alice'), Row(name='Bob')]
+ [Row(name='Tom'), Row(name='Alice'), Row(name='Bob')]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
Review Comment:
I think we don't need to create a new DataFrame here, since `drop()` doesn't remove the column in-place.
e.g.
```python
>>> df.drop('age').show()
+-----+
| name|
+-----+
| Tom|
|Alice|
| Bob|
+-----+
>>> df.drop(df.age).show()
+-----+
| name|
+-----+
| Tom|
|Alice|
| Bob|
+-----+
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955543656
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1722,8 +1806,17 @@ def dtypes(self) -> List[Tuple[str, str]]:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"),
+ ... (23, "Alice")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ +---+-----+
>>> df.dtypes
Review Comment:
yes of course, working on it right now
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1227821941
Hi Hyukjin and Oliver, thanks all for your feedback.
I have created a commit with all your suggestions and allowed all jobs to be run in git Actions for my fork.
I will make one last commit for further minor changes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953198052
##########
python/pyspark/sql/dataframe.py:
##########
@@ -3356,11 +3476,29 @@ def drop(self, *cols: "ColumnOrName") -> "DataFrame": # type: ignore[misc]
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"), (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop('age').collect()
- [Row(name='Alice'), Row(name='Bob')]
+ [Row(name='Tom'), Row(name='Alice'), Row(name='Bob')]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"), (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop(df.age).collect()
- [Row(name='Alice'), Row(name='Bob')]
+ [Row(name='Tom'), Row(name='Alice'), Row(name='Bob')]
>>> df.join(df2, df.name == df2.name, 'inner').drop(df.name).collect()
Review Comment:
I think it's showing a common example that join and drop the join key.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1225003672
We should make the tests passed before merging it in (https://github.com/Transurgeon/spark/runs/7981691501).
cc @dcoliversun @khalidmammadov FYI if you guys find some time to review, and work on the rest of API.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #37444: [SPARK-40012][PYTHON][DOCS][WIP] Make pyspark.sql.dataframe examples self-contained
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1210031490
Can one of the admins verify this patch?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS][WIP] Make pyspark.sql.dataframe examples self-contained
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953047129
##########
python/pyspark/sql/dataframe.py:
##########
@@ -3356,11 +3476,29 @@ def drop(self, *cols: "ColumnOrName") -> "DataFrame": # type: ignore[misc]
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"), (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop('age').collect()
- [Row(name='Alice'), Row(name='Bob')]
+ [Row(name='Tom'), Row(name='Alice'), Row(name='Bob')]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"), (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop(df.age).collect()
- [Row(name='Alice'), Row(name='Bob')]
+ [Row(name='Tom'), Row(name='Alice'), Row(name='Bob')]
>>> df.join(df2, df.name == df2.name, 'inner').drop(df.name).collect()
Review Comment:
I am not sure what these 3 inner joins do exactly. I dont see anywhere an instantiation of df2..
What should I do with these 3 examples?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953196728
##########
python/pyspark/sql/dataframe.py:
##########
@@ -363,9 +363,18 @@ def schema(self) -> StructType:
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.schema
Review Comment:
Let's describe the example like:
```
>>> df = spark.createDataFrame(
... [(14, "Tom"), (23, "Alice"), (16, "Bob")], ["age", "name"])
Retrieve the schema of the current DataFrame.
>>> df.schema
```
##########
python/pyspark/sql/dataframe.py:
##########
@@ -571,29 +580,42 @@ def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool =
Examples
--------
- >>> df
- DataFrame[age: int, name: string]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
ditto for indentation
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955578677
##########
python/pyspark/sql/dataframe.py:
##########
@@ -4064,11 +4200,31 @@ def drop(self, *cols: "ColumnOrName") -> "DataFrame": # type: ignore[misc]
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
>>> df.drop('age').collect()
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955576741
##########
python/pyspark/sql/dataframe.py:
##########
@@ -731,29 +744,51 @@ def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool =
Examples
--------
- >>> df
- DataFrame[age: int, name: string]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953197013
##########
python/pyspark/sql/dataframe.py:
##########
@@ -571,29 +580,42 @@ def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool =
Examples
--------
- >>> df
- DataFrame[age: int, name: string]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
>>> df.show()
+---+-----+
|age| name|
+---+-----+
- | 2|Alice|
- | 5| Bob|
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+---+-----+
+ >>> df.show(2)
Review Comment:
Let's add some description for each example.
e.g.)
```
Show only top 2 rows.
>>> df.show(2)
+---+-----+
|age| name|
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955554324
##########
python/pyspark/sql/dataframe.py:
##########
@@ -363,9 +363,18 @@ def schema(self) -> StructType:
Examples
Review Comment:
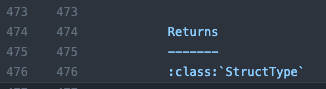
I think the returns section is already there..
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955518000
##########
python/pyspark/sql/dataframe.py:
##########
@@ -363,9 +363,18 @@ def schema(self) -> StructType:
Examples
Review Comment:
Let's add `Returns` section since we're here.
##########
python/pyspark/sql/dataframe.py:
##########
@@ -477,9 +477,22 @@ def schema(self) -> StructType:
Examples
--------
+ >>> df = spark.createDataFrame(
+ ... [(14, "Tom"), (23, "Alice"),(16, "Bob")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
+
+ Retrieve the schema of the current DataFrame.
+
>>> df.schema
- StructType([StructField('age', IntegerType(), True),
- StructField('name', StringType(), True)])
+ StructType([StructField('age', IntegerType(), True),
Review Comment:
Let's remove the space in the end
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955518301
##########
python/pyspark/sql/dataframe.py:
##########
@@ -731,29 +744,51 @@ def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool =
Examples
--------
- >>> df
- DataFrame[age: int, name: string]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
>>> df.show()
+---+-----+
|age| name|
+---+-----+
- | 2|Alice|
- | 5| Bob|
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+ +---+-----+
+
+ Show only top 2 rows.
+
+ >>> df.show(2)
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+---+-----+
+ only showing top 2 rows
+
+ Show DataFrame where the maximum number of characters is 3.
Review Comment:
`` :class:`DataFrame` ``
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dcoliversun commented on pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
dcoliversun commented on PR #37444:
URL: https://github.com/apache/spark/pull/37444#issuecomment-1225369750
@Transurgeon Hi. Look like that CI is disabled in your forked repo.
<img width="1270" alt="image" src="https://user-images.githubusercontent.com/44011673/186369580-4eebd0ae-f1ab-4c93-b1bf-ac8e110e62e2.png">
Maybe the [doc](https://docs.github.com/en/actions/managing-workflow-runs/disabling-and-enabling-a-workflow#enabling-a-workflow) can help you :)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r953197392
##########
python/pyspark/sql/dataframe.py:
##########
@@ -1179,6 +1231,16 @@ def distinct(self) -> "DataFrame":
Examples
--------
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (23, "Alice")], ["age", "name"])
+ >>> df.show()
+ +---+-----+
+ |age| name|
+ +---+-----+
+ | 14| Tom|
+ | 23|Alice|
+ | 23|Alice|
+ +---+-----+
>>> df.distinct().count()
Review Comment:
ditto
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] Transurgeon commented on a diff in pull request #37444: [SPARK-40012][PYTHON][DOCS] Make pyspark.sql.dataframe examples self-contained (Part 1)
Posted by GitBox <gi...@apache.org>.
Transurgeon commented on code in PR #37444:
URL: https://github.com/apache/spark/pull/37444#discussion_r955492471
##########
python/pyspark/sql/dataframe.py:
##########
@@ -571,29 +580,42 @@ def show(self, n: int = 20, truncate: Union[bool, int] = True, vertical: bool =
Examples
--------
- >>> df
- DataFrame[age: int, name: string]
+ >>> df = spark.createDataFrame([(14, "Tom"), (23, "Alice"),
+ ... (16, "Bob")], ["age", "name"])
>>> df.show()
+---+-----+
|age| name|
+---+-----+
- | 2|Alice|
- | 5| Bob|
+ | 14| Tom|
+ | 23|Alice|
+ | 16| Bob|
+---+-----+
+ >>> df.show(2)
Review Comment:
I added some simple descriptions, please take a look
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org