You are viewing a plain text version of this content. The canonical link for it is here.
Posted to dev@rocketmq.apache.org by GitBox <gi...@apache.org> on 2020/05/30 02:08:17 UTC
[GitHub] [rocketmq] zhangyixin1222 opened a new issue #2056: 关于目前raft协议选举中存在的问题及改进策略
zhangyixin1222 opened a new issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056
raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
假定有编号为【1,2,3,4,5,6,7】共7个结点构成了一个选举整体,当结点1作为候选人发起term=6的投票,该term对应投票为【1,2,3,4】所接受,结点1作为leader执行leader职责前,刚好结点7发起term=7的投票(因为网络抖动原因结点7发起的term=6刚好未被结点【1,2,3,4】所接收),抛开上帝视角具体分析,此时存在以下两种情况:
情况1:结点【4,5,6,7】多数结点接受结点7该term=7的选举,结点7作为leader执行职责,该情况下目前所用raft协议能保证结点1会自动失去leader资格。
情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
解决策略:1、引入结点在接受到leader名义发起的提议后,如果term<自身已知选举认可term且term>自身已提交term时,对提议仅进行记录但拒绝接受该提议。当接受到提交请求时,如果提交所用term>自身已提交term,则找到对应提议并无条件进行提交(因为raft协议的提议提交命令发送前提为大多数已经接受了)。2、如果接受了提议,则在自身未主动探测到leader丢失下,拒绝对后续的选举term进行投票(以保证在接受结点1提议后结点7无法获取到多数结点的认可当选为leader出现双主问题).
问题扩展:实际情况会存在网络抖动引起的N个(N>=2)结点同时误认自己是leader或当前leader因为所用term并非全局视角下的最大term在履行leader职责时未受少数结点认可存在的问题
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636428598
> > 可以在pre-vote基础上对raft做进一步改进以对选举过程中产生的消耗做相关优化,在pre-vote阶段根据自身接受日志记录的term及日志index作为获取选举资格的凭证,但在每次选举中携带自身【termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点,拉取选票会出现以下几种情况:
> > 【
> > 情况1:其他结点(如结点B)收到选举消息后经过对比发现结点B自身记录的日志term>结点A发送过来的termLoged,则反馈termSmallError异常的反对票.
> > 情况2:其他结点(如结点B)收到选举消息后发现自身记录日志term小于结点A发送过来的termLogged,或者自身记录日志term=结点A发送过来的termLogged且自身日志index<indexLogged则更新自身记录的termWanted并反馈以赞同票。
> > 情况3:其他结点(如节点B)发现自身记录日志term与A发过来的termLogged一致且自身日志index=indexLogged,则以跟自身已认可的termWanted与接受到的termWanted进行对比,如果自身已认可的termWanted>=B结点发过来的termWanted,则反馈选举失败(但不为反对票)并在反馈报文中告知自身记录的最大termWanted。
> > 】
> > 结点A根据获取到的多数反馈或经过一定超时时间后根据不同情况分别做如下策略:
> > 【
> > 情况1:如果结点A获得了多数结点的认可并未获得反对票,则以leader身份并以termWanted作为任期开始执行leader责任(如果任期失败则再次进入leader查找及选主状态)。
> > 情况2:如果结点A如果未收到反对票也未获得大多数认可时则据反馈的termWanted集合中与自身(termWanted+1)的最大值来变更termWanted并在随机等待后进行下一轮选票拉取。
> > 情况3:如果收到的投票中存在反对票,结点B会随机等待后再次判断leader是否存在及在无法知晓leader存在后经过pre-vote阶段获取自身候选人资格并判断是否存在新leader,如果不存在新leader则尝试通过pre-vote获取候选人资格并在候选人资格获得后重新发起选举(之所以如此设计是因为当结点B等少数结点是所有结点中唯一持有更大termLogged的结点并在此后因为这系列少数结点故障永久性无法通信);
> > 】
> > 通过以上方案,避免了每次拉选票之前频繁的pre-vote中候选人资格认证阶段的消耗,并能够在获取到leader存在后及时变更自身状态,也保证了当选的leader确实拥有最新的日志记录,同时避免了出现长时间脑裂的恢复后日志term落后引发的误选及有效日志回滚,也避免了少部分记录有最新日志记录结点(因为某些原因日志未受多数认可而leader故障引发无主)集体永久性宕机后引发的无法选举问题。为了保证特殊情况下的及时获取leader信息日志,仍补充issue中所提到的策略
>
> 两个小问题:
> 自身记录日志term 就是 termLoged 嘛。可以问一下为什么要拆分出term 和 termWanted 嘞,因为您说
>
> > termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点
>
> 如果是这样的话那我理解您定义的
>
> termLoged 相当于dledger里的lastLogTerm,termWanted 相当于 dledger里的term。
>
> 实际上如果每个node都只有一个的term值的话维护起来会方便一点,状态没那么复杂。
对,这部分是你理解的,跟raft协议一致,之所以引入两个不同term是为了当以失败自增的选举term拉取选票前提下保障当选为leader具有全局可见的最新日志纪录。我所提及的变更是对pre-vote这个阶段在选举失败后的重复认可(对第一次pre-vote获取选举人资格及第一次拉取选票这些步骤及之前都未做改动),为了弥补期间出现的间歇性脑裂带来的日志纪录延滞造成的候选人资格剥夺未知问题(因为脑裂期间确实存在着leader已当选问题),在正式选取拉取选票时携带自身最新日志纪录term做对比可以修复该问题。但不管哪种方案,都无法消除该issue所提及的问题(因少部分结点认可过更大的选举term导致当选leader所广播消息暂时不受自身认可(虽然可以在新一轮的比较日志纪录term后会重新正确认可其leader权))。(所涉及的讨论都以在网络或硬件在不同阶段及不同结点可能出现各种问题下如何加速选举及在不丢失历史日志纪录前提下保证最快的一致性恢复,所论述基础抛开上帝视角)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636633078
我建议您最好写一个更为详细,所有术语定义较为准确的proposal出来,并说出您认为原有的raft实现哪种case没有处理好,举出一个详细准确例子(比如按照raft算法走一遍),再说说您的解决方案为什么可以解决那个例子。我感觉您在表述的时候默认了很多您心中清楚但我们并不清楚的概念,再加上您的解释没有很好的上下文,这样的话阅读起来有一点点困难,一点小建议哈~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] lizhiboo commented on issue #2056: 关于目前raft协议选举中存在的问题及改进策略
Posted by GitBox <gi...@apache.org>.
lizhiboo commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636267028
> raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
> 假定有编号为【1,2,3,4,5,6,7】共7个结点构成了一个选举整体,当结点1作为候选人发起term=6的投票,该term对应投票为【1,2,3,4】所接受,结点1作为leader执行leader职责前,刚好结点7发起term=7的投票(因为网络抖动原因结点7发起的term=6刚好未被结点【1,2,3,4】所接收),抛开上帝视角具体分析,此时存在以下两种情况:
> 情况1:结点【4,5,6,7】多数结点接受结点7该term=7的选举,结点7作为leader执行职责,该情况下目前所用raft协议能保证结点1会自动失去leader资格。
> 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
> 解决策略:1、引入结点在接受到leader名义发起的提议后,如果term<自身已知选举认可term且term>自身已提交term时,对提议仅进行记录但拒绝接受该提议。当接受到提交请求时,如果提交所用term>自身已提交term,则找到对应提议并无条件进行提交(因为raft协议的提议提交命令发送前提为大多数已经接受了)。2、如果接受了提议,则在自身未主动探测到leader丢失下,拒绝对后续的选举term进行投票(以保证在接受结点1提议后结点7无法获取到多数结点的认可当选为leader出现双主问题).
> 问题扩展:实际情况会存在网络抖动引起的N个(N>=2)结点同时误认自己是leader或当前leader因为所用term并非全局视角下的最大term在履行leader职责时未受少数结点认可存在的问题
In my opinion, the situation that you describe before is inevitable. PRE-VOTE request can minimize the probability of leadership transition. Candidate send PRE-VOTE request before send the true VOTE request. If PRE-VOTE failed(do not receive majority's vote), candidate reset vote timeout to wait for the next PRE-VOTE. If PRE-VOTE successed(receive majority's vote), candidate will send VOTE request.
Openmessaging-dledger has already support PRE-VOTE protocol, it maybe help you. Code address is [https://github.com/openmessaging/openmessaging-storage-dledger](url)
The PRE-VOTE mechanism details please refer to RAFT paper.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: 关于目前raft协议选举中存在的问题及改进策略
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636318438
可以在pre-vote基础上对raft做进一步改进以对选举过程中产生的消耗做相关优化,在pre-vote阶段根据自身接受日志记录的term及日志index作为获取选举资格的凭证,但在每次选举中携带自身【termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点,拉取选票会出现以下几种情况:
【
情况1:其他结点(如结点B)收到选举消息后经过对比发现结点B自身记录的日志term>结点A发送过来的termLoged,则反馈termSmallError异常的反对票.
情况2:其他结点(如结点B)收到选举消息后发现自身记录日志term小于结点A发送过来的termLogged,或者自身记录日志term=结点A发送过来的termLogged且自身日志index<indexLogged则更新自身记录的termWanted并反馈以赞同票。
情况3:其他结点(如节点B)发现自身记录日志term与A发过来的termLogged一致且自身日志index=indexLogged,则以跟自身已认可的termWanted与接受到的termWanted进行对比,如果自身已认可的termWanted>=B结点发过来的termWanted,则反馈选举失败(但不为反对票)并在反馈报文中告知自身记录的最大termWanted。
】
结点A根据获取到的多数反馈或经过一定超时时间后根据不同情况分别做如下策略:
【
情况1:如果结点A获得了多数结点的认可并未获得反对票,则以leader身份并以termWanted作为任期开始执行leader责任(如果任期失败则再次进入leader查找及选主状态)。
情况2:如果结点A如果未收到反对票也未获得大多数认可时则据反馈的termWanted集合中与自身(termWanted+1)的最大值来变更termWanted并在随机等待后进行下一轮选票拉取。
情况3:如果收到的投票中存在反对票,结点B会随机等待后再次判断leader是否存在及在无法知晓leader存在后经过pre-vote阶段获取自身候选人资格并判断是否存在新leader,如果不存在新leader则尝试通过pre-vote获取候选人资格并在候选人资格获得后重新发起选举(之所以如此设计是因为当结点B等少数结点是所有结点中唯一持有更大termLogged的结点并在此后因为这系列少数结点故障永久性无法通信);
】
通过以上方案,避免了每次拉选票之前频繁的pre-vote中候选人资格认证阶段的消耗,并能够在获取到leader存在后及时变更自身状态,也保证了当选的leader确实拥有最新的日志记录,同时避免了出现长时间脑裂的恢复后日志term落后引发的误选及有效日志回滚,也避免了少部分记录有最新日志记录结点(因为某些原因日志未受多数认可而leader故障引发无主)集体永久性宕机后引发的无法选举问题。为了保证特殊情况下的及时获取leader信息日志,仍补充issue中所提到的策略
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636604891
> > candidator进入follower状态是为了感知到自己日志滞后之后临时不参与leader当选把机会让给强者
>
> 即使只有一个candidate X,该candidate仍然有可能感受到日志滞后,但这并不影响该candidate具有唯一最大的term值,它仍然应该成为leader。 如果其成为leader后,即使它的日志比部分节点落后,这也是安全的。因为比leader X 日志更新的节点一定是少数派,否则X 就不可能成为leader。如果leader X 只是感知到它的日志比少部分节点落后,那么它就可以安全的overwrite掉那些比它更新的日志记录。
>
> 决定candidate 之间 强弱顺序的只有term (也就是你定义的termWanted ) 决定。
这种思路存在以下这个问题,结点1获得候选人并发起term=7投票,然后因为略慢了一拍,更快的机器上的候选人结点7用更旧的term=6发起投票并获得leader地位且发起新一轮leader责权履行。引入反对票是针对这系列情况,即一旦感知到自己存在日志纪录term不为最新导致不能百分百当选就迅速退避。一旦当选就尽快履责,一旦当选无望就迅速退避。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636415449
> raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
> 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,
> 会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
节点1 在发现 5,6,7 认可了term = 7 的时候,会立刻退化成为follower 状态。如果出现了这种情况说明节点1 本就不应该继续成为leader了。任何leader在察觉到有比自己高的term的时候就意味着有新的leader要被选取出来了。
> 但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交
这个多数投票只是让节点1成为了leader,entry X 的commit动作只会发生在 超过半数的node 都写入了entry X 之后才会commit。
感觉情况2就是正常的raft处理leader change的情况,可能我理解有偏差,还望指正。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636429527
> 因少部分结点认可过更大的选举term导致当选leader所广播消息暂时不受自身认可
我觉得这可能不是一个问题,感觉这是raft协议期望发生的事情。
可以再详细讲一下为什么你觉得
> 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
这种情况出问题了嘛,非常感谢~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636587698
> 已提交是多数认可的充分非必要条件,多数认可是已提交的必要非充分条件。比如结点1发送的完appendentry指令给123456时候挂了,而且123456都记录了该appenentry时候就属于多数认可但未提交例子。
看起来这里就是我们的分歧所在了,我理解的是在raft里,123456 如果都记录了该term = 6 appendEntry(都存有该log entry的replica),那么此时该log entry 就已经提交了。这是和paxos/zab 不一样的地方。
*准确来说,raft的leader选举过程相当于 paxos的phase1, raft的appendEntrys相当于paxos的phase 2。 [Paxos vs Raft(]https://arxiv.org/pdf/2004.05074.pdf)*
>对于因为选举中存在多数同意但少数不同意(但不是反对,反对是loggedterm延滞引发) 则是脑裂引起的没争取到该部分结点认同的leader资格。
可以详细定义一下什么是同意,什么是不同意,什么是反对吗?(就是具体的判断条件),因为这是raft原论文里没有出现过的概念,为避免歧义,我们还是争取尽量准确地定义术语吧 :smile:
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636459458
> > raft协议中leader履行职责中在广播日志提议后如果收到了多数响应会发出提交指令的,并向客户端反馈结果
>
> raft 里leader 的提议是指什么嘞? 是指把某个entry复制到其他节点上吗? 因为raft里并没有像paxos明确提出proposal的概念,所以我不太清楚“广播日志提议” 是不是指向其他节点发送
> AppendEntries。
>
> 我是这么理解raft的commit 的:commit完成的标志应该是:如果一条log具有和leader相同的term且被复制到大多数节点上,那么在复制到大多数节点上这个行为完成的瞬间,这条log及其之前的所有log实质上就已经commit了。raft原论文中并没有明确 commit这样一个RPC call,只是在每次leader 向其他节点发送appendEntry或者心跳包(空的appendEntry)的时候,会携带上leader 的commitIndex,其他节点根据这个commitIndex来“学习”最新的commitIndex 的值。但是这个commitIndex的作用仅仅是通知。commitIndex 可能比实际已经commit的log Index要小,但是绝对能保证commitIndex及其之前的log全都已经commit了。
>
> > 结点7如果快了一拍,在结点234中任意一个结点收到结点1提议消息之前收到选票也是会获取leader资格的(这仅会使的结点1发现提议不收认可自动切换到寻找leader状态),该情况下结点7就进入leader状态。
>
> “在结点234中任意一个结点收到结点1提议消息之前”,我认为可以改成“在节点234 任意一个节点复制了某个结点1 的term = 6 的log之前”,这样可能能消除部分歧义。
>
> > 新选leader会将新term的空日志跟所知的旧term记录日志一次性提议保障不落下之前的有效提议(即已提交的或多数认可的提议)。
>
> 已提交和多数认可的协议,可以问一下这两个区别在哪里嘛~
>
> > 退化为follower在于自身已经感知到自身所持日志纪录并非最新,在因为未获得最新选举term不必要进入follower。
>
> 对不起这句话后半句我没有完全理解,可以更详细的解释一下后面一句嘛~
>
> 非常感谢~
commitindex作用就是提交指令,只是附加了心跳功能。对部分结点的commitindex确实会小于日志索引,但对多数是相等的,因为具有appendentry请求加持。其实raft的appendentry作用就是zk的proposal,commitindex对多数结点来说作用相当于是zk的commit作用。
你的表述更准确。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636615709
> 我来整理一下
>
> 投票者
>
> * 投反对票:根据收到的loggedterm,loggedindex,termwanted进行对比,如果前两者自身更大,而无论自身termWanted更大或者更小或相等,则反馈结果中填入票数-10000
> * 投不同意票:如果前两者自身更小或相等而自身所知termwanted更大,则反馈结果中填入票数0
> * 投同意票: 如果前两者自身更小或相等而自身所知termwanted更小或相等,则反馈结果中填入票数1
>
> 是这样嘛?
>
> 所以节点 7 到底能不能感知到有term = 7 的候选人决定了节点7能不能成为leader
>
> > 即一旦感知到自己存在日志纪录term不为最新导致不能百分百当选就迅速退避
> > 为什么不能百分百当选就迅速退避呢?仍然有可能成为leader啊。
>
> 完全有可能 节点A 的日志记录比B 新, 但是节点A 的term比B要小。
> 而这个时候节点A就是普通的拒绝节点B就行了,节点B也不应该
>
> 我感觉你的反对票的目的是,如果有任何一个follower在投票过程中发现自己的日志记录比candidate新,那么这个candidate就应该退化为follower。是这个意思吗
对,是这样的。但follower在等待一定时间后察觉到leader不存在还是会继续pre-vote以及过渡到候选人阶段,这是为了避免发生新leader在当选后刚提议消息只被少数结点获取就跟着这些少数结点永久性宕机这种情况时永久性不能恢复生产的及其特殊情况
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636441247
> > > 因少部分结点认可过更大的选举term导致当选leader所广播消息暂时不受自身认可
> >
> >
> > 我觉得这可能不是一个问题,感觉这是raft协议期望发生的事情。
> > 可以再详细讲一下为什么
> > > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
> >
> >
> > 这种情况出问题了嘛,非常感谢~
>
> 因为这样会引发部分结点对真实leader(当选leader结点已受大多数结点认可并履行职责)的不认可导致的一定时期内的分区问题。该分区问题本来可通过无条件接受提交指令(能发出提交指令肯定说明已经受到了多数结点接受)来得以快速恢复
可以详细解释一下什么是提交指令嘛,我记得raft里没有提交指令。提交与否是由某个log是否在当前term内copy到多数节点上决定的。term =6 的提议如果在**term = 6 期间**被复制到了多数节点上,那么这个值就一定被commit了,不需要再做额外的请求使其commit。
我感觉您描述的应该不是一个safety的问题,而是一个performance的问题。并且您描述里的分区,具体指的是什么呢?node 7 肯定不可能成为 leader, 而
- node 1 要么永远都联系不到 5,6,7, 因此node 1 一直都不知道有一个term 为 7 的node,因此node 1 可以继续成为leader 并正常运行
- node 1 可以联系到 5 ,6 , 7 因此退化成为follower,把自己的term 也改成 7 。 如果node 7 一直不能成为 leader, 那么某个follower 会 timeout 为candidate 并使用 term 8 进行投票
这里面分区会发生在什么时候呢?
非常感谢~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: 关于目前raft协议选举中存在的问题及改进策略
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636270759
> > raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
> > 假定有编号为【1,2,3,4,5,6,7】共7个结点构成了一个选举整体,当结点1作为候选人发起term=6的投票,该term对应投票为【1,2,3,4】所接受,结点1作为leader执行leader职责前,刚好结点7发起term=7的投票(因为网络抖动原因结点7发起的term=6刚好未被结点【1,2,3,4】所接收),抛开上帝视角具体分析,此时存在以下两种情况:
> > 情况1:结点【4,5,6,7】多数结点接受结点7该term=7的选举,结点7作为leader执行职责,该情况下目前所用raft协议能保证结点1会自动失去leader资格。
> > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
> > 解决策略:1、引入结点在接受到leader名义发起的提议后,如果term<自身已知选举认可term且term>自身已提交term时,对提议仅进行记录但拒绝接受该提议。当接受到提交请求时,如果提交所用term>自身已提交term,则找到对应提议并无条件进行提交(因为raft协议的提议提交命令发送前提为大多数已经接受了)。2、如果接受了提议,则在自身未主动探测到leader丢失下,拒绝对后续的选举term进行投票(以保证在接受结点1提议后结点7无法获取到多数结点的认可当选为leader出现双主问题).
> > 问题扩展:实际情况会存在网络抖动引起的N个(N>=2)结点同时误认自己是leader或当前leader因为所用term并非全局视角下的最大term在履行leader职责时未受少数结点认可存在的问题
>
> In my opinion, the situation that you describe before is inevitable. PRE-VOTE request can minimize the probability of leadership transition. Candidate send PRE-VOTE request before send the true VOTE request. If PRE-VOTE failed(do not receive majority's vote), candidate reset vote timeout to wait for the next PRE-VOTE. If PRE-VOTE successed(receive majority's vote), candidate will send VOTE request.
> Openmessaging-dledger has already support PRE-VOTE protocol, it maybe help you. Code address is [https://github.com/openmessaging/openmessaging-storage-dledger](url)
> The PRE-VOTE mechanism details please refer to RAFT paper.
prevote只能保证参与选举时的结点拥有了最新的日志信息,当结点1跟结点7都具有最新信息,并在prevote阶段因此都获取了候选人资格,在获取了候选人资格后一段时间内因为网络等问题发生一定时间段的间歇性脑裂,导致了term变更期间因随机等待时常差异造成同一时刻会用不同term参与选举在特殊情况下产生了之前描述的问题
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636429527
> 因少部分结点认可过更大的选举term导致当选leader所广播消息暂时不受自身认可
我觉得这可能不是一个问题,感觉这是raft协议期望发生的事情。
可以再详细讲一下为什么
> 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
这种情况出问题了嘛,非常感谢~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: 关于目前raft协议选举中存在的问题及改进策略
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636291527
> > raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
> > 假定有编号为【1,2,3,4,5,6,7】共7个结点构成了一个选举整体,当结点1作为候选人发起term=6的投票,该term对应投票为【1,2,3,4】所接受,结点1作为leader执行leader职责前,刚好结点7发起term=7的投票(因为网络抖动原因结点7发起的term=6刚好未被结点【1,2,3,4】所接收),抛开上帝视角具体分析,此时存在以下两种情况:
> > 情况1:结点【4,5,6,7】多数结点接受结点7该term=7的选举,结点7作为leader执行职责,该情况下目前所用raft协议能保证结点1会自动失去leader资格。
> > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
> > 解决策略:1、引入结点在接受到leader名义发起的提议后,如果term<自身已知选举认可term且term>自身已提交term时,对提议仅进行记录但拒绝接受该提议。当接受到提交请求时,如果提交所用term>自身已提交term,则找到对应提议并无条件进行提交(因为raft协议的提议提交命令发送前提为大多数已经接受了)。2、如果接受了提议,则在自身未主动探测到leader丢失下,拒绝对后续的选举term进行投票(以保证在接受结点1提议后结点7无法获取到多数结点的认可当选为leader出现双主问题).
> > 问题扩展:实际情况会存在网络抖动引起的N个(N>=2)结点同时误认自己是leader或当前leader因为所用term并非全局视角下的最大term在履行leader职责时未受少数结点认可存在的问题
>
> In my opinion, the situation that you describe before is inevitable. PRE-VOTE request can minimize the probability of leadership transition. Candidate send PRE-VOTE request before send the true VOTE request. If PRE-VOTE failed(do not receive majority's vote), candidate reset vote timeout to wait for the next PRE-VOTE. If PRE-VOTE successed(receive majority's vote), candidate will send VOTE request.
> Openmessaging-dledger has already support PRE-VOTE protocol, it maybe help you. Code address is [https://github.com/openmessaging/openmessaging-storage-dledger](url)
> The PRE-VOTE mechanism details please refer to RAFT paper.
采用pre-vote进行候选人抉择只能保证参与选举时的结点拥有了最新的日志信息,上述情况为当结点1跟结点7都具有最新信息,并在prevote阶段因此都获取了候选人资格,在获取了候选人资格后一段时间内因为网络等问题发生一定时间段的间歇性脑裂,导致了term变更期间因随机等待时常差异造成同一时刻会用不同term参与选举在特殊情况下产生了之前描述的问题。该情况发生概率较小但确实存在,并且出现时候一般不容易排查,所以引入接受到提交请求无条件提交并更新自身认可的leader为发起提交命令的结点能保证在有结点获取多数投票并担任leader之后的个别结点记录的选举term异常带来的无主问题
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636600651
> > > > 已提交是多数认可的充分非必要条件,多数认可是已提交的必要非充分条件。比如结点1发送的完appendentry指令给123456时候挂了,而且123456都记录了该appenentry时候就属于多数认可但未提交例子。
> > >
> > >
> > > 看起来这里就是我们的分歧所在了,我理解的是在raft里,123456 如果都记录了该term = 6 appendEntry(都存有该log entry的replica),那么此时该log entry 就已经提交了。这是和paxos/zab 不一样的地方。
> > > _准确来说,raft的leader选举过程相当于 paxos的phase1, raft的appendEntrys相当于paxos的phase 2。 [Paxos vs Raft](https://arxiv.org/pdf/2004.05074.pdf)_
> > > > 对于因为选举中存在多数同意但少数不同意(但不是反对,反对是loggedterm延滞引发) 则是脑裂引起的没争取到该部分结点认同的leader资格。
> > >
> > >
> > > 可以详细定义一下什么是同意,什么是不同意,什么是反对吗?(就是具体的判断条件),因为这是raft原论文里没有出现过的概念,为避免歧义,我们还是争取尽量准确地定义术语吧
> >
> >
> > raft只有同意跟不同意两种情况,即票数1跟票数0。为了加速感知到日志纪录的滞后性并进入follower,引入反对票。可以理解为每个结点在收到选举请求后,根据收到的loggedterm,loggedindex,termwanted进行对比,如果前两者自身更大,则反馈结果中填入票数-10000,如果前两者自身更小或相等而自身所知termwanted更大,则反馈结果中填入票数0,否则反馈结果中填入票数1。选举发起人收到多数结点反馈或超时后计算总得票数据此获得leader权
>
> > termwanted进行对比,如果前两者自身更大,则反馈结果中填入票数-10000,
>
> 如果前两者loggedterm,loggedindex,自身更大的话,为什么要candidate进入follower状态呢?如果loggedTerm, loggedIndex 比 candidate的日志更大的话(也就是更up-to-date),那这就应该是普通的拒绝票。candidate并不是遇到了任意一个比自己日志记录更新的follower就要退化到follower的.candidate 不一定要日志全局最新,只用比大部分节点的日志新就好了,我是这样理解的。
follower状态是选举发起人进入。根据term跟index的对比做出投票是投票者的行为。遇到-10000的票从candidator进入follower状态是为了感知到自己日志滞后之后临时不参与leader当选把机会让给强者。因为收到多数票再超时并有反对票,已经就感知到了有更强的结点可能会当选leader。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] lizhiboo commented on issue #2056: issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
lizhiboo commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636340722
> 可以在pre-vote基础上对raft做进一步改进以对选举过程中产生的消耗做相关优化,在pre-vote阶段根据自身接受日志记录的term及日志index作为获取选举资格的凭证,但在每次选举中携带自身【termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点,拉取选票会出现以下几种情况:
> 【
> 情况1:其他结点(如结点B)收到选举消息后经过对比发现结点B自身记录的日志term>结点A发送过来的termLoged,则反馈termSmallError异常的反对票.
>
> 情况2:其他结点(如结点B)收到选举消息后发现自身记录日志term小于结点A发送过来的termLogged,或者自身记录日志term=结点A发送过来的termLogged且自身日志index<indexLogged则更新自身记录的termWanted并反馈以赞同票。
>
> 情况3:其他结点(如节点B)发现自身记录日志term与A发过来的termLogged一致且自身日志index=indexLogged,则以跟自身已认可的termWanted与接受到的termWanted进行对比,如果自身已认可的termWanted>=B结点发过来的termWanted,则反馈选举失败(但不为反对票)并在反馈报文中告知自身记录的最大termWanted。
> 】
>
> 结点A根据获取到的多数反馈或经过一定超时时间后根据不同情况分别做如下策略:
> 【
> 情况1:如果结点A获得了多数结点的认可并未获得反对票,则以leader身份并以termWanted作为任期开始执行leader责任(如果任期失败则再次进入leader查找及选主状态)。
>
> 情况2:如果结点A如果未收到反对票也未获得大多数认可时则据反馈的termWanted集合中与自身(termWanted+1)的最大值来变更termWanted并在随机等待后进行下一轮选票拉取。
>
> 情况3:如果收到的投票中存在反对票,结点B会随机等待后再次判断leader是否存在及在无法知晓leader存在后经过pre-vote阶段获取自身候选人资格并判断是否存在新leader,如果不存在新leader则尝试通过pre-vote获取候选人资格并在候选人资格获得后重新发起选举(之所以如此设计是因为当结点B等少数结点是所有结点中唯一持有更大termLogged的结点并在此后因为这系列少数结点故障永久性无法通信);
> 】
>
> 通过以上方案,避免了每次拉选票之前频繁的pre-vote中候选人资格认证阶段的消耗,并能够在获取到leader存在后及时变更自身状态,也保证了当选的leader确实拥有最新的日志记录,同时避免了出现长时间脑裂的恢复后日志term落后引发的误选及有效日志回滚,也避免了少部分记录有最新日志记录结点(因为某些原因日志未受多数认可而leader故障引发无主)集体永久性宕机后引发的无法选举问题。为了保证特殊情况下的及时获取leader信息日志,仍补充issue中所提到的策略
The standard leader election process in raft is comparing candidate's term, lastLogIndex, lastLogTerm. I think your solution described above modified raft election process. I'm not sure it works or not. Can you describe the whole election process in detail, and prove it ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636449082
> > > > 因少部分结点认可过更大的选举term导致当选leader所广播消息暂时不受自身认可
> > >
> > >
> > > 我觉得这可能不是一个问题,感觉这是raft协议期望发生的事情。
> > > 可以再详细讲一下为什么
> > > > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
> > >
> > >
> > > 这种情况出问题了嘛,非常感谢~
> >
> >
> > 因为这样会引发部分结点对真实leader(当选leader结点已受大多数结点认可并履行职责)的不认可导致的一定时期内的分区问题。该分区问题本来可通过无条件接受提交指令(能发出提交指令肯定说明已经受到了多数结点接受)来得以快速恢复
>
> 可以详细解释一下什么是提交指令嘛,我记得raft里没有提交指令。提交与否是由某个log是否在当前term内copy到多数节点上决定的。term =6 的提议如果在**term = 6 期间**被复制到了多数节点上,那么这个值就一定被commit了,不需要再做额外的请求使其commit。
>
> 我感觉您描述的应该不是一个safety的问题,而是一个performance的问题。并且您描述里的分区,具体指的是什么呢?node 7 肯定不可能成为 leader, 而
>
> * node 1 要么永远都联系不到 5,6,7, 因此node 1 一直都不知道有一个term 为 7 的node,因此node 1 可以继续成为leader 并正常运行
> * node 1 可以联系到 5 ,6 , 7 因此退化成为follower,把自己的term 也改成 7 。 如果node 7 一直不能成为 leader, 那么某个follower 会 timeout 为candidate 并使用 term 8 进行投票
>
> 这里面分区会发生在什么时候呢?
>
> 非常感谢~
raft协议中leader履行职责中在广播日志提议后如果收到了多数响应会发出提交指令的,并向客户端反馈结果(这跟zk是一样的)。而且协议本身明确了收到多数赞同票就可以作为leader,即即使567结点没赞同,但只要1234多数结点赞同就会进入leader状态(因为raft或zk的一致性在于保证提交的消息及多数认可的提议绝对不丢失,不会因为只有少数结点存在着提议日志就因噎废食)。因为通过pre-vote获取候选人资格这一前提保证了候选人持有多数结点具有的最新日志。结点7如果快了一拍,在结点234中任意一个结点收到结点1提议消息之前收到选票也是会获取leader资格的(这仅会使的结点1发现提议不收认可自动切换到寻找leader状态),该情况下结点7就进入leader状态。新选leader会将新term的空日志跟所知的旧term的记录日志一次性提议保障不落下之前的有效提议(即已提交的或多数认可的提议)。退化为follower在于自身已经感知到自身所持日志纪录并非最新,在因为未获得最新选举term不必要进入follower。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-637916668
对当前的raft选举协议做简述
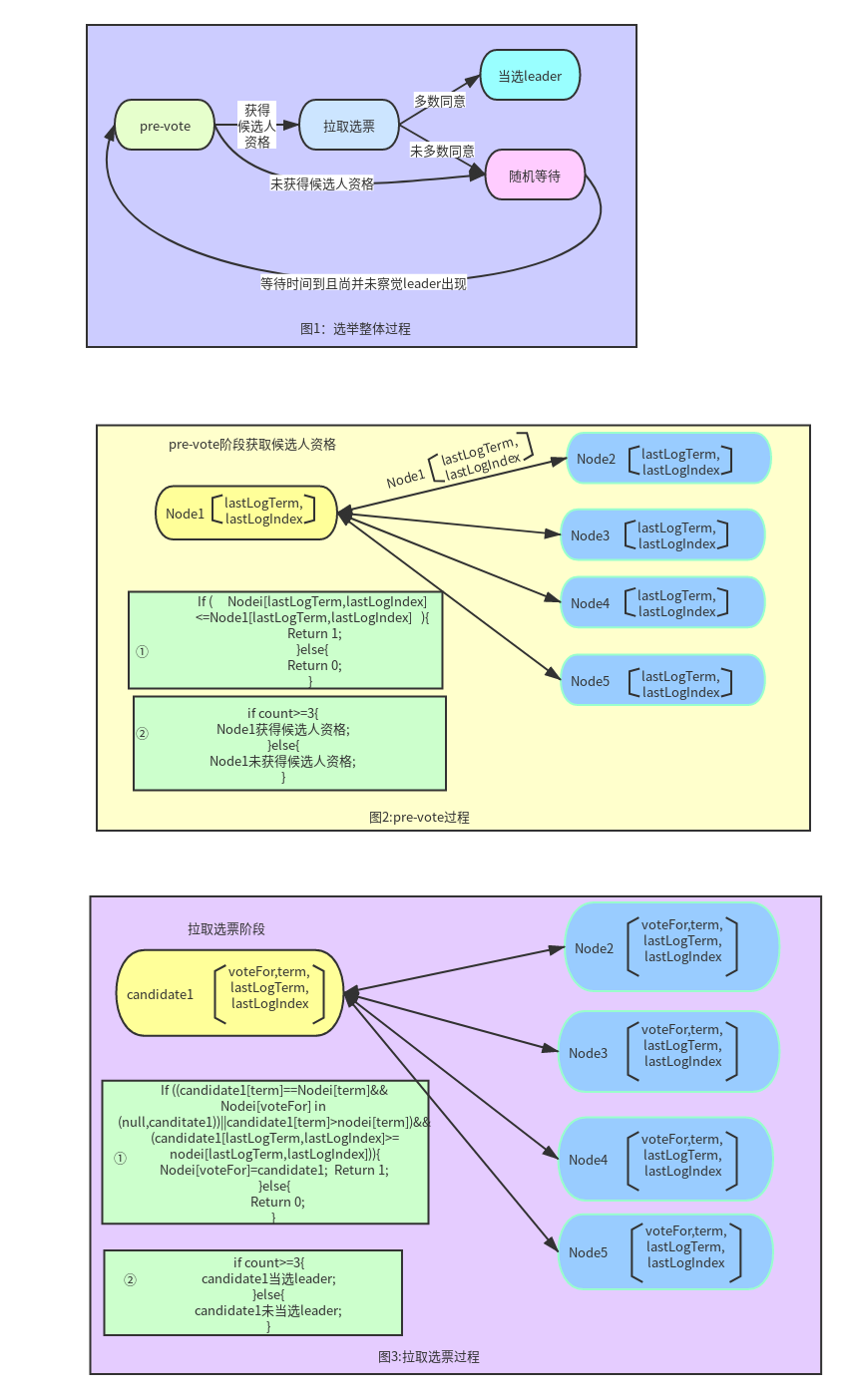
对改版后的选举方式作简述(差异之处用红色标记)
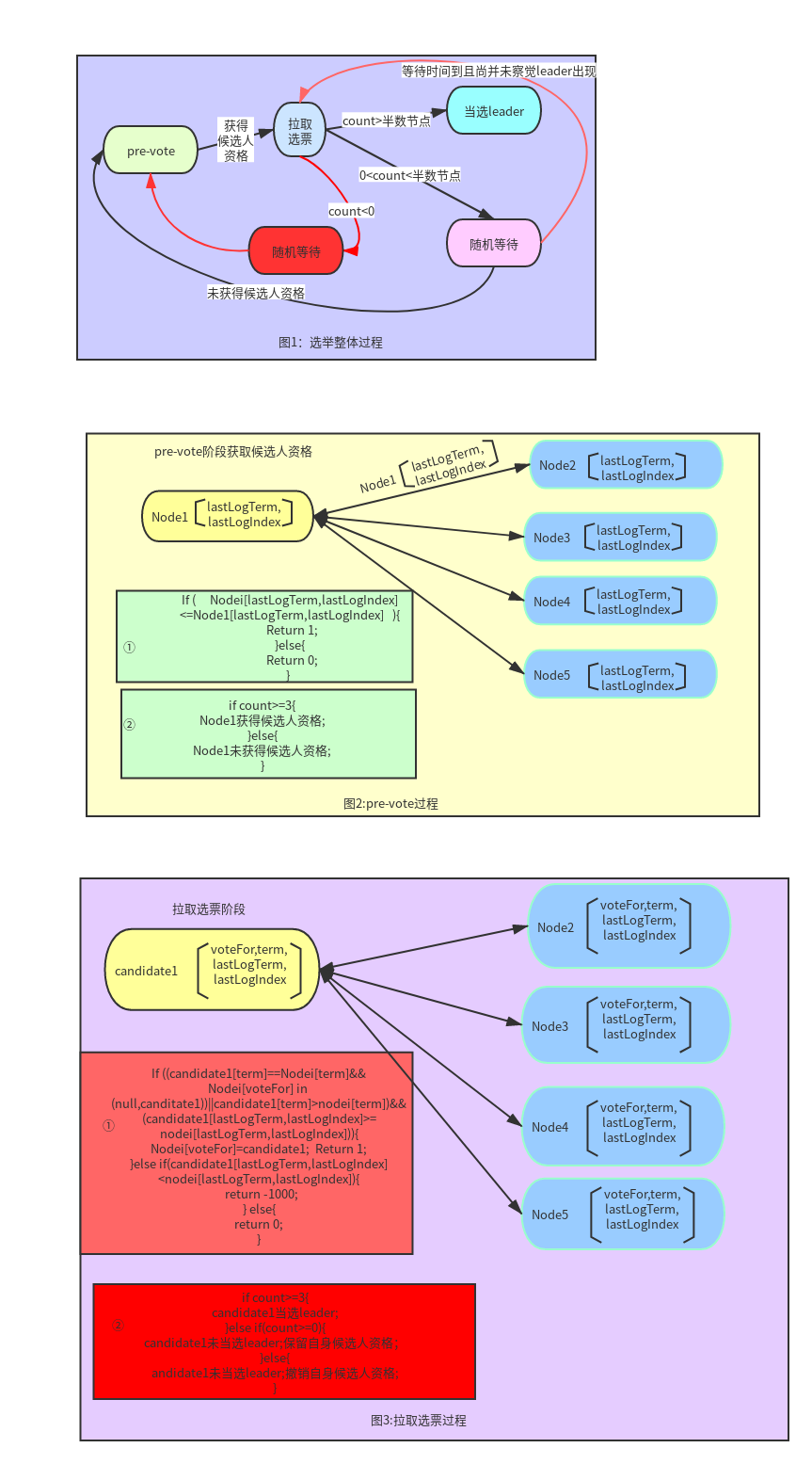
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636595635
> > 已提交是多数认可的充分非必要条件,多数认可是已提交的必要非充分条件。比如结点1发送的完appendentry指令给123456时候挂了,而且123456都记录了该appenentry时候就属于多数认可但未提交例子。
>
> 看起来这里就是我们的分歧所在了,我理解的是在raft里,123456 如果都记录了该term = 6 appendEntry(都存有该log entry的replica),那么此时该log entry 就已经提交了。这是和paxos/zab 不一样的地方。
>
> _准确来说,raft的leader选举过程相当于 paxos的phase1, raft的appendEntrys相当于paxos的phase 2。 [Paxos vs Raft](https://arxiv.org/pdf/2004.05074.pdf)_
>
> > 对于因为选举中存在多数同意但少数不同意(但不是反对,反对是loggedterm延滞引发) 则是脑裂引起的没争取到该部分结点认同的leader资格。
>
> 可以详细定义一下什么是同意,什么是不同意,什么是反对吗?(就是具体的判断条件),因为这是raft原论文里没有出现过的概念,为避免歧义,我们还是争取尽量准确地定义术语吧
raft只有同意跟不同意两种情况,即票数1跟票数0。为了加速感知到日志纪录的滞后性并进入follower,引入反对票。可以理解为每个结点在收到选举请求后,根据收到的loggedterm,loggedindex,termwanted进行对比,如果前两者自身更大,则反馈结果中填入票数-10000,如果前两者自身更小或相等而自身所知termwanted更大,则反馈结果中填入票数0,否则反馈结果中填入票数1。选举发起人收到多数结点反馈或超时后计算总得票数据此获得leader权
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe removed a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe removed a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636415462
> > raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
>
> > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,
>
> > 会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
>
> 节点1 在发现 5,6,7 认可了term = 7 的时候,会立刻退化成为follower 状态。如果出现了这种情况说明节点1 本就不应该继续成为leader了。任何leader在察觉到有比自己高的term的时候就意味着有新的leader要被选取出来了。
>
> > 但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交
>
> 这个多数投票只是让节点1成为了leader,entry X 的commit动作只会发生在 超过半数的node 都写入了entry X 之后才会commit。
>
> 感觉情况2就是正常的raft处理leader change的情况,可能我理解有偏差,还望指正。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
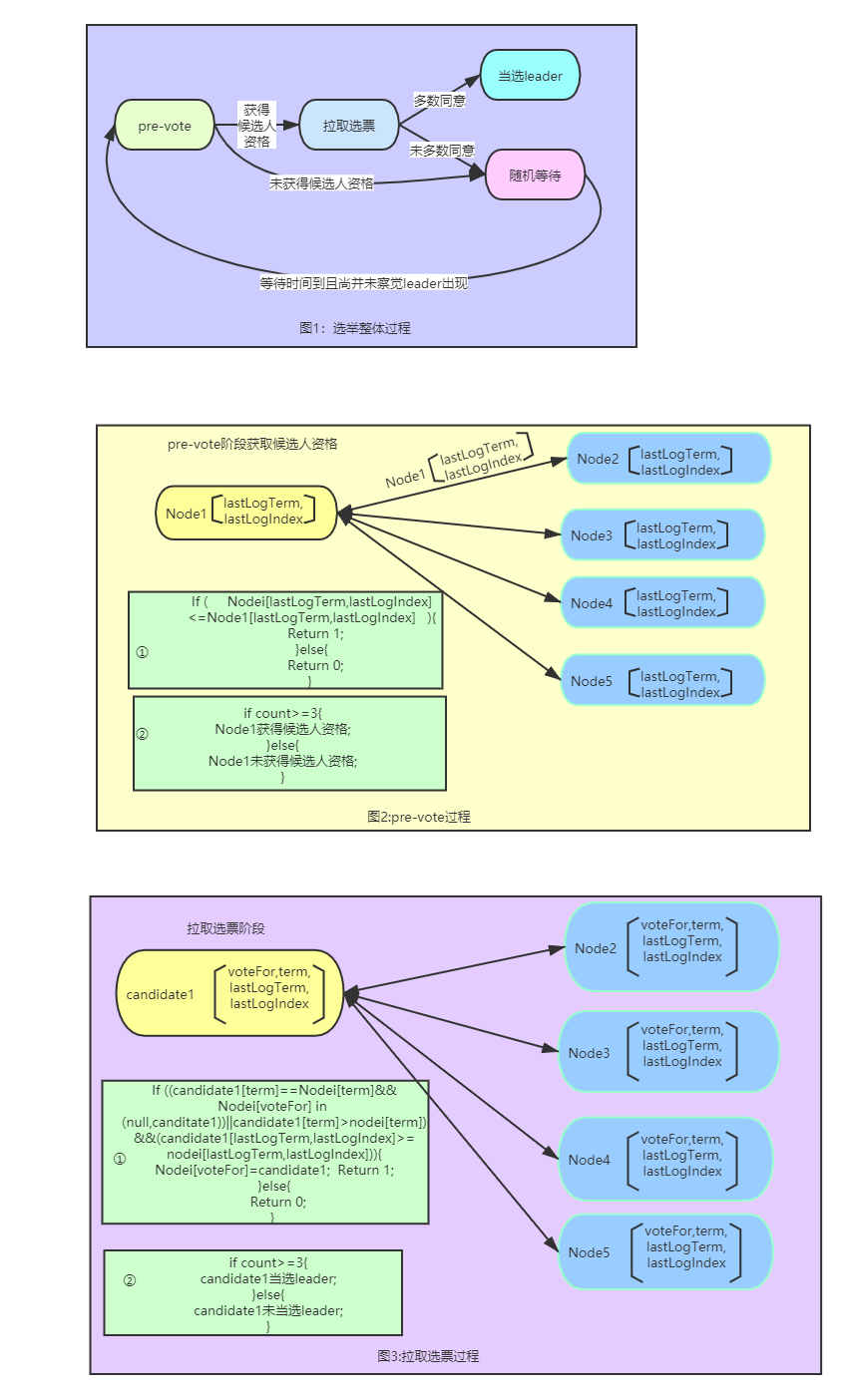
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-637916668
对当前的raft选举协议做简述
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 removed a comment on issue #2056: 关于目前raft协议选举中存在的问题及改进策略
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 removed a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636270759
> > raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
> > 假定有编号为【1,2,3,4,5,6,7】共7个结点构成了一个选举整体,当结点1作为候选人发起term=6的投票,该term对应投票为【1,2,3,4】所接受,结点1作为leader执行leader职责前,刚好结点7发起term=7的投票(因为网络抖动原因结点7发起的term=6刚好未被结点【1,2,3,4】所接收),抛开上帝视角具体分析,此时存在以下两种情况:
> > 情况1:结点【4,5,6,7】多数结点接受结点7该term=7的选举,结点7作为leader执行职责,该情况下目前所用raft协议能保证结点1会自动失去leader资格。
> > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
> > 解决策略:1、引入结点在接受到leader名义发起的提议后,如果term<自身已知选举认可term且term>自身已提交term时,对提议仅进行记录但拒绝接受该提议。当接受到提交请求时,如果提交所用term>自身已提交term,则找到对应提议并无条件进行提交(因为raft协议的提议提交命令发送前提为大多数已经接受了)。2、如果接受了提议,则在自身未主动探测到leader丢失下,拒绝对后续的选举term进行投票(以保证在接受结点1提议后结点7无法获取到多数结点的认可当选为leader出现双主问题).
> > 问题扩展:实际情况会存在网络抖动引起的N个(N>=2)结点同时误认自己是leader或当前leader因为所用term并非全局视角下的最大term在履行leader职责时未受少数结点认可存在的问题
>
> In my opinion, the situation that you describe before is inevitable. PRE-VOTE request can minimize the probability of leadership transition. Candidate send PRE-VOTE request before send the true VOTE request. If PRE-VOTE failed(do not receive majority's vote), candidate reset vote timeout to wait for the next PRE-VOTE. If PRE-VOTE successed(receive majority's vote), candidate will send VOTE request.
> Openmessaging-dledger has already support PRE-VOTE protocol, it maybe help you. Code address is [https://github.com/openmessaging/openmessaging-storage-dledger](url)
> The PRE-VOTE mechanism details please refer to RAFT paper.
prevote只能保证参与选举时的结点拥有了最新的日志信息,当结点1跟结点7都具有最新信息,并在prevote阶段因此都获取了候选人资格,在获取了候选人资格后一段时间内因为网络等问题发生一定时间段的间歇性脑裂,导致了term变更期间因随机等待时常差异造成同一时刻会用不同term参与选举在特殊情况下产生了之前描述的问题
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636598234
> > > 已提交是多数认可的充分非必要条件,多数认可是已提交的必要非充分条件。比如结点1发送的完appendentry指令给123456时候挂了,而且123456都记录了该appenentry时候就属于多数认可但未提交例子。
> >
> >
> > 看起来这里就是我们的分歧所在了,我理解的是在raft里,123456 如果都记录了该term = 6 appendEntry(都存有该log entry的replica),那么此时该log entry 就已经提交了。这是和paxos/zab 不一样的地方。
> > _准确来说,raft的leader选举过程相当于 paxos的phase1, raft的appendEntrys相当于paxos的phase 2。 [Paxos vs Raft](https://arxiv.org/pdf/2004.05074.pdf)_
> > > 对于因为选举中存在多数同意但少数不同意(但不是反对,反对是loggedterm延滞引发) 则是脑裂引起的没争取到该部分结点认同的leader资格。
> >
> >
> > 可以详细定义一下什么是同意,什么是不同意,什么是反对吗?(就是具体的判断条件),因为这是raft原论文里没有出现过的概念,为避免歧义,我们还是争取尽量准确地定义术语吧
>
> raft只有同意跟不同意两种情况,即票数1跟票数0。为了加速感知到日志纪录的滞后性并进入follower,引入反对票。可以理解为每个结点在收到选举请求后,根据收到的loggedterm,loggedindex,termwanted进行对比,如果前两者自身更大,则反馈结果中填入票数-10000,如果前两者自身更小或相等而自身所知termwanted更大,则反馈结果中填入票数0,否则反馈结果中填入票数1。选举发起人收到多数结点反馈或超时后计算总得票数据此获得leader权
> termwanted进行对比,如果前两者自身更大,则反馈结果中填入票数-10000,
如果前两者loggedterm,loggedindex,自身更大的话,为什么要candidate进入follower状态呢?如果loggedTerm, loggedIndex 比 candidate的日志更大的话(也就是更up-to-date),那这就应该是普通的拒绝票。candidate并不是遇到了任意一个比自己日志记录更新的follower就要退化到follower的.candidate 不一定要日志全局最新,只用比大部分节点的日志新就好了,我是这样理解的。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636428598
> > 可以在pre-vote基础上对raft做进一步改进以对选举过程中产生的消耗做相关优化,在pre-vote阶段根据自身接受日志记录的term及日志index作为获取选举资格的凭证,但在每次选举中携带自身【termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点,拉取选票会出现以下几种情况:
> > 【
> > 情况1:其他结点(如结点B)收到选举消息后经过对比发现结点B自身记录的日志term>结点A发送过来的termLoged,则反馈termSmallError异常的反对票.
> > 情况2:其他结点(如结点B)收到选举消息后发现自身记录日志term小于结点A发送过来的termLogged,或者自身记录日志term=结点A发送过来的termLogged且自身日志index<indexLogged则更新自身记录的termWanted并反馈以赞同票。
> > 情况3:其他结点(如节点B)发现自身记录日志term与A发过来的termLogged一致且自身日志index=indexLogged,则以跟自身已认可的termWanted与接受到的termWanted进行对比,如果自身已认可的termWanted>=B结点发过来的termWanted,则反馈选举失败(但不为反对票)并在反馈报文中告知自身记录的最大termWanted。
> > 】
> > 结点A根据获取到的多数反馈或经过一定超时时间后根据不同情况分别做如下策略:
> > 【
> > 情况1:如果结点A获得了多数结点的认可并未获得反对票,则以leader身份并以termWanted作为任期开始执行leader责任(如果任期失败则再次进入leader查找及选主状态)。
> > 情况2:如果结点A如果未收到反对票也未获得大多数认可时则据反馈的termWanted集合中与自身(termWanted+1)的最大值来变更termWanted并在随机等待后进行下一轮选票拉取。
> > 情况3:如果收到的投票中存在反对票,结点B会随机等待后再次判断leader是否存在及在无法知晓leader存在后经过pre-vote阶段获取自身候选人资格并判断是否存在新leader,如果不存在新leader则尝试通过pre-vote获取候选人资格并在候选人资格获得后重新发起选举(之所以如此设计是因为当结点B等少数结点是所有结点中唯一持有更大termLogged的结点并在此后因为这系列少数结点故障永久性无法通信);
> > 】
> > 通过以上方案,避免了每次拉选票之前频繁的pre-vote中候选人资格认证阶段的消耗,并能够在获取到leader存在后及时变更自身状态,也保证了当选的leader确实拥有最新的日志记录,同时避免了出现长时间脑裂的恢复后日志term落后引发的误选及有效日志回滚,也避免了少部分记录有最新日志记录结点(因为某些原因日志未受多数认可而leader故障引发无主)集体永久性宕机后引发的无法选举问题。为了保证特殊情况下的及时获取leader信息日志,仍补充issue中所提到的策略
>
> 两个小问题:
> 自身记录日志term 就是 termLoged 嘛。可以问一下为什么要拆分出term 和 termWanted 嘞,因为您说
>
> > termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点
>
> 如果是这样的话那我理解您定义的
>
> termLoged 相当于dledger里的lastLogTerm,termWanted 相当于 dledger里的term。
>
> 实际上如果每个node都只有一个的term值的话维护起来会方便一点,状态没那么复杂。
对,这部分是你理解的,跟raft协议一致,之所以引入两个不同term是为了当以失败自增的选举term拉取选票前提下保障当选为leader具有全局可见的最新日志纪录。我所提及的变更是对pre-vote这个阶段在选举失败后的重复认可(对第一次pre-vote获取选举人资格及第一次拉取选票这些步骤及之前都未做改动),为了弥补期间出现的间歇性脑裂带来的日志纪录延滞造成的候选人资格剥夺未知问题(因为脑裂期间确实存在着leader已当选问题),在正式选取拉取选票时携带自身最新日志纪录term做对比可以修复该问题。但不管哪种方案,都无法消除该issue所提及的问题(因少部分结点认可过更大的选举term导致当选leader所广播消息暂时不受自身认可(虽然可以在新一轮的比较日志纪录term后会重新正确认可其leader权))。(所涉及的讨论都以在网络或硬件在不同阶段及不同结点可能出现各种问题下如何加速选举及在不丢失历史日志纪录前提下保证最快的一致性恢复,所论述基础抛开上帝视角)。当然,正如raft协议所提及,非选举状态每个结点都只维持一个term,在进入无法获知leader则根据该term分化出日志term及失败自增的选举term。因为容易证明(非选举状态维护两个term会带来连续两次leader故障所引发的其他问题)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636587698
> 已提交是多数认可的充分非必要条件,多数认可是已提交的必要非充分条件。比如结点1发送的完appendentry指令给123456时候挂了,而且123456都记录了该appenentry时候就属于多数认可但未提交例子。
看起来这里就是我们的分歧所在了,我理解的是在raft里,123456 如果都记录了该term = 6 appendEntry(都存有该log entry的replica),那么此时该log entry 就已经提交了。这是和paxos/zab 不一样的地方。
*准确来说,raft的leader选举过程相当于 paxos的phase1, raft的appendEntrys相当于paxos的phase 2。 [Paxos vs Raft](https://arxiv.org/pdf/2004.05074.pdf)*
>对于因为选举中存在多数同意但少数不同意(但不是反对,反对是loggedterm延滞引发) 则是脑裂引起的没争取到该部分结点认同的leader资格。
可以详细定义一下什么是同意,什么是不同意,什么是反对吗?(就是具体的判断条件),因为这是raft原论文里没有出现过的概念,为避免歧义,我们还是争取尽量准确地定义术语吧 :smile:
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636601949
> candidator进入follower状态是为了感知到自己日志滞后之后临时不参与leader当选把机会让给强者
即使只有一个candidate X,该candidate仍然有可能感受到日志滞后,但这并不影响该candidate具有唯一最大的term值,它仍然应该成为leader。 如果其成为leader后,即使它的日志比部分节点落后,这也是安全的。因为比leader X 日志更新的节点一定是少数派,否则X 就不可能成为leader。如果leader X 只是感知到它的日志比少部分节点落后,那么它就可以安全的overwrite掉那些比它更新的日志记录。
决定candidate 之间 强弱顺序的只有term (也就是你定义的termWanted ) 决定。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636431464
> > 因少部分结点认可过更大的选举term导致当选leader所广播消息暂时不受自身认可
>
> 我觉得这可能不是一个问题,感觉这是raft协议期望发生的事情。
> 可以再详细讲一下为什么
>
> > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
>
> 这种情况出问题了嘛,非常感谢~
因为这样会引发部分结点对真实leader(当选leader结点已受大多数结点认可并履行职责)的不认可导致的一定时期内的分区问题。该分区问题本来可通过无条件接受提交指令(能发出提交指令肯定说明已经受到了多数结点接受)来得以快速恢复
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636415462
> > raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
>
> > 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,
>
> > 会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
>
> 节点1 在发现 5,6,7 认可了term = 7 的时候,会立刻退化成为follower 状态。如果出现了这种情况说明节点1 本就不应该继续成为leader了。任何leader在察觉到有比自己高的term的时候就意味着有新的leader要被选取出来了。
>
> > 但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交
>
> 这个多数投票只是让节点1成为了leader,entry X 的commit动作只会发生在 超过半数的node 都写入了entry X 之后才会commit。
>
> 感觉情况2就是正常的raft处理leader change的情况,可能我理解有偏差,还望指正。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636415449
> raft协议在网络抖动,机器临时故障等极小概率情况下会产生以下选举问题:
> 情况2:结点【5,6,7】等少数结点接受结点7该term=7的选举,结点7未作为leader执行职责,但此时因为【5,6,7】结点已经认可了term=7的任期,
> 会导致结点1以term=6所发送提议无法被接受,但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交。可惜目前所用的raft协议未考虑该情况下的处理方案。
节点1 在发现 5,6,7 认可了term = 7 的时候,会立刻退化成为follower 状态。如果出现了这种情况说明节点1 不应该继续成为leader了。任何leader在察觉到有比自己高的term的时候就意味着有新的leader要被选取出来了。
> 但结点1因为已经此实确实获取多数结点认可,在提议被多数接受后会进行提交
这个多数投票只是让节点1成为了leader,entry X 的commit动作只会发生在 超过半数的node 都写入了entry X 之后才会commit。
感觉情况2就是正常的raft处理leader change的情况,可能我理解有偏差,还望指正。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636458133
> raft协议中leader履行职责中在广播日志提议后如果收到了多数响应会发出提交指令的,并向客户端反馈结果
raft 里leader 的提议是指什么嘞? 是指把某个entry复制到其他节点上吗? 因为raft里并没有像paxos明确提出proposal的概念,所以我不太清楚“广播日志提议” 是不是指向其他节点发送
AppendEntries。
我是这么理解raft的commit 的:commit完成的标志应该是:如果一条log具有和leader相同的term且被复制到大多数节点上,那么在复制到大多数节点上这个行为完成的瞬间,这条log及其之前的所有log实质上就已经commit了。raft原论文中并没有明确 commit这样一个RPC call,只是在每次leader 向其他节点发送appendEntry或者心跳包(空的appendEntry)的时候,会携带上leader 的commitIndex,其他节点根据这个commitIndex来“学习”最新的commitIndex 的值。但是这个commitIndex的作用仅仅是通知。commitIndex 可能比实际已经commit的log Index要小,但是绝对能保证commitIndex及其之前的log全都已经commit了。
> 结点7如果快了一拍,在结点234中任意一个结点收到结点1提议消息之前收到选票也是会获取leader资格的(这仅会使的结点1发现提议不收认可自动切换到寻找leader状态),该情况下结点7就进入leader状态。
“在结点234中任意一个结点收到结点1提议消息之前”,我认为可以改成“在节点234 任意一个节点复制了某个结点1 的term = 6 的log之前”,这样可能能消除部分歧义。
> 新选leader会将新term的空日志跟所知的旧term记录日志一次性提议保障不落下之前的有效提议(即已提交的或多数认可的提议)。
已提交和多数认可的协议,可以问一下这两个区别在哪里嘛~
> 退化为follower在于自身已经感知到自身所持日志纪录并非最新,在因为未获得最新选举term不必要进入follower。
对不起这句话后半句我没有完全理解,可以更详细的解释一下后面一句嘛~
非常感谢~
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636621667
> 我感觉你的反对票的目的是,如果有任何一个follower在投票过程中发现自己的日志记录比candidate新,那么这个candidate就应该退化为follower。是这个意思吗
问题是这样实现的话就已经不是raft协议了,我认为这样实现是不对的,会导致liveness甚至是safety的问题。
考虑这样一个情况
node 7 在 term = 6 期间把一条log复制到了 node 6 上,然后node 7 宕机。
这个时候,如果按照你的实现,只有可能node 6 能成为candidate,因为node 1 2 3 4 5 的日志记录都比node 6 的要旧。
可是这样的话假设node 1 具有最短的timeout间隔而node 6 具有最长的timeout间隔。这也就意味着即使node 1 本应最先成为leader,却因为多出来的条件而导致不能成为leader,就违背了任意不同node采用不同timeout时长的初衷了。
更重要的是这样做并没有什么意义,candidate就没有必要比每一个node的日记记录都要新,才用你说的反对票机制并不能带来额外的好处
> 这是为了避免发生新leader在当选后刚提议消息只被少数结点获取就跟着这些少数结点永久性宕机这种情况时,永久性不能恢复生产的及其特殊情况
我不认为这种情况会在raft协议中出现,如果只是少数派节点宕机那么raft一定能选出一个leader来继续工作,如果您能提供一个详细的example说明为什么会出现少数节点宕机会导致永久不能恢复生产的话,非常感谢~
至于新的提案里的loggedTerm, loggerIndex 在raft里就有这样的概念, 叫lastLogTerm 和 lastLogIndex, termWated 就是 raft 里的 term, 不同的是raft 里的term是 “当前节点所见到过的最大term“。
总而言之,新的提案对raft的核心步骤做出了修改,将一个原本宽松的条件升级成了一个更为严格的条件,必须得证明这样做不会影响livenss我们才能讨论实现的可能。(safety 被损害的可能性不大,毕竟让leader选举更严格了)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636633078
我建议您最好写一个更为详细,所有术语定义较为准确的proposal出来,并说出您认为原有的raft实现哪种case没有处理好,举出一个详细准确例子(比如按照raft算法走一遍),再说说您的解决方案为什么可以解决那个例子。我感觉您在表述的时候默认了很多您心中清楚但我们并不清楚的概念,再加上您的解释没有很好的上下文,这样的话阅读起来有一点点困难,一点小建议哈~
举个例子
> 所以结点1在获取反对票时并无法确定是少数新leader如7宕机还是自己收到选票后就已经有了正常工作的新的leader出现
以及
> 这是为了避免发生新leader在当选后刚提议消息只被少数结点获取就跟着这些少数结点永久性宕机这种情况时永久性不能恢复生产的及其特殊情况。
这两句话如果有例子的话会更好理解一点
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636615709
> 我来整理一下
>
> 投票者
>
> * 投反对票:根据收到的loggedterm,loggedindex,termwanted进行对比,如果前两者自身更大,而无论自身termWanted更大或者更小或相等,则反馈结果中填入票数-10000
> * 投不同意票:如果前两者自身更小或相等而自身所知termwanted更大,则反馈结果中填入票数0
> * 投同意票: 如果前两者自身更小或相等而自身所知termwanted更小或相等,则反馈结果中填入票数1
>
> 是这样嘛?
>
> 所以节点 7 到底能不能感知到有term = 7 的候选人决定了节点7能不能成为leader
>
> > 即一旦感知到自己存在日志纪录term不为最新导致不能百分百当选就迅速退避
> > 为什么不能百分百当选就迅速退避呢?仍然有可能成为leader啊。
>
> 完全有可能 节点A 的日志记录比B 新, 但是节点A 的term比B要小。
> 而这个时候节点A就是普通的拒绝节点B就行了,节点B也不应该
>
> 我感觉你的反对票的目的是,如果有任何一个follower在投票过程中发现自己的日志记录比candidate新,那么这个candidate就应该退化为follower。是这个意思吗
对,是这样的。但follower在等待一定时间后察觉到leader不存在还是会继续pre-vote以及过渡到候选人阶段,这是为了避免发生新leader在当选后刚提议消息只被少数结点获取就跟着这些少数结点永久性宕机这种情况时永久性不能恢复生产的及其特殊情况。设计目标是更快更健壮减少可不必要的人为干预。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636417675
> 可以在pre-vote基础上对raft做进一步改进以对选举过程中产生的消耗做相关优化,在pre-vote阶段根据自身接受日志记录的term及日志index作为获取选举资格的凭证,但在每次选举中携带自身【termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点,拉取选票会出现以下几种情况:
> 【
> 情况1:其他结点(如结点B)收到选举消息后经过对比发现结点B自身记录的日志term>结点A发送过来的termLoged,则反馈termSmallError异常的反对票.
>
> 情况2:其他结点(如结点B)收到选举消息后发现自身记录日志term小于结点A发送过来的termLogged,或者自身记录日志term=结点A发送过来的termLogged且自身日志index<indexLogged则更新自身记录的termWanted并反馈以赞同票。
>
> 情况3:其他结点(如节点B)发现自身记录日志term与A发过来的termLogged一致且自身日志index=indexLogged,则以跟自身已认可的termWanted与接受到的termWanted进行对比,如果自身已认可的termWanted>=B结点发过来的termWanted,则反馈选举失败(但不为反对票)并在反馈报文中告知自身记录的最大termWanted。
> 】
>
> 结点A根据获取到的多数反馈或经过一定超时时间后根据不同情况分别做如下策略:
> 【
> 情况1:如果结点A获得了多数结点的认可并未获得反对票,则以leader身份并以termWanted作为任期开始执行leader责任(如果任期失败则再次进入leader查找及选主状态)。
>
> 情况2:如果结点A如果未收到反对票也未获得大多数认可时则据反馈的termWanted集合中与自身(termWanted+1)的最大值来变更termWanted并在随机等待后进行下一轮选票拉取。
>
> 情况3:如果收到的投票中存在反对票,结点B会随机等待后再次判断leader是否存在及在无法知晓leader存在后经过pre-vote阶段获取自身候选人资格并判断是否存在新leader,如果不存在新leader则尝试通过pre-vote获取候选人资格并在候选人资格获得后重新发起选举(之所以如此设计是因为当结点B等少数结点是所有结点中唯一持有更大termLogged的结点并在此后因为这系列少数结点故障永久性无法通信);
> 】
>
> 通过以上方案,避免了每次拉选票之前频繁的pre-vote中候选人资格认证阶段的消耗,并能够在获取到leader存在后及时变更自身状态,也保证了当选的leader确实拥有最新的日志记录,同时避免了出现长时间脑裂的恢复后日志term落后引发的误选及有效日志回滚,也避免了少部分记录有最新日志记录结点(因为某些原因日志未受多数认可而leader故障引发无主)集体永久性宕机后引发的无法选举问题。为了保证特殊情况下的及时获取leader信息日志,仍补充issue中所提到的策略
两个小问题:
自身记录日志term 就是 termLoged 嘛。可以问一下为什么要拆分出term 和 termWanted 嘞,因为您说
> termLoged,indexLogged,termWanted,nodeId】拉取选票,其中termLoged为自身接受日志记录的最新term,indexLodded为自身接受最大term日志记录的最大index,termWanted初始值为termLoged,在每次选举失败后+1,nodeId为自身结点
如果是这样的话那我理解您定义的
termLoged 相当于dledger里的lastLogTerm,termWanted 相当于 dledger里的term。
实际上如果每个node都只有一个的term值的话维护起来会方便一点,状态没那么复杂。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 edited a comment on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 edited a comment on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636459458
> > raft协议中leader履行职责中在广播日志提议后如果收到了多数响应会发出提交指令的,并向客户端反馈结果
>
> raft 里leader 的提议是指什么嘞? 是指把某个entry复制到其他节点上吗? 因为raft里并没有像paxos明确提出proposal的概念,所以我不太清楚“广播日志提议” 是不是指向其他节点发送
> AppendEntries。
>
> 我是这么理解raft的commit 的:commit完成的标志应该是:如果一条log具有和leader相同的term且被复制到大多数节点上,那么在复制到大多数节点上这个行为完成的瞬间,这条log及其之前的所有log实质上就已经commit了。raft原论文中并没有明确 commit这样一个RPC call,只是在每次leader 向其他节点发送appendEntry或者心跳包(空的appendEntry)的时候,会携带上leader 的commitIndex,其他节点根据这个commitIndex来“学习”最新的commitIndex 的值。但是这个commitIndex的作用仅仅是通知。commitIndex 可能比实际已经commit的log Index要小,但是绝对能保证commitIndex及其之前的log全都已经commit了。
>
> > 结点7如果快了一拍,在结点234中任意一个结点收到结点1提议消息之前收到选票也是会获取leader资格的(这仅会使的结点1发现提议不收认可自动切换到寻找leader状态),该情况下结点7就进入leader状态。
>
> “在结点234中任意一个结点收到结点1提议消息之前”,我认为可以改成“在节点234 任意一个节点复制了某个结点1 的term = 6 的log之前”,这样可能能消除部分歧义。
>
> > 新选leader会将新term的空日志跟所知的旧term记录日志一次性提议保障不落下之前的有效提议(即已提交的或多数认可的提议)。
>
> 已提交和多数认可的协议,可以问一下这两个区别在哪里嘛~
>
> > 退化为follower在于自身已经感知到自身所持日志纪录并非最新,在因为未获得最新选举term不必要进入follower。
>
> 对不起这句话后半句我没有完全理解,可以更详细的解释一下后面一句嘛~
>
> 非常感谢~
commitindex作用就是提交指令,只是附加了心跳功能。对部分结点的commitindex确实会小于日志索引,但对多数是相等的,因为具有appendentry请求加持。其实raft的appendentry作用就是zk的proposal,commitindex对多数结点来说作用相当于是zk的commit作用。
你的表述更准确。
已提交是多数认可的充分非必要条件,多数认可是已提交的必要非充分条件。比如结点1发送的完appendentry指令给123456时候挂了,而且123456都记录了该appenentry时候就属于多数认可但未提交例子。
分布式协议能保证有效请求(即被多数结点接受的请求)绝对纪录一致且绝对不丢失,但对于少数结点接受的请求仅做尽量不丢失(对该问题的探讨网上很多针对于zk的描述都是错误的)。具有candidator资格的结点在选举中未收到反对票情况下能绝对保证自身具有持有的纪录日志是全局最新的,在收到反对票能感知到自身纪录日志存在局部非最新,所以保险起见收到反对票才自动退化为follower更符合实际情况。对于因为选举中存在多数同意但少数不同意(但不是反对,反对是loggedterm延滞引发)则是脑裂引起的没争取到该部分结点认同的leader资格。在自身后续提议appendentry获得多数接受的情况下不会影响全局一致性问题。选举中对raft做改造,对选举投票反馈中修改为同意,不同意(含网络硬件故障引起的不可知),反对三种情况。
另外以上方案隐含的优势是选举中更偏向于结点中通信更快运转更快的结点。
另外可以对raft做进一步改造,类似于投票效力加权功能,让leader倾向存在于部分结点
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] zhangyixin1222 commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
zhangyixin1222 commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636630269
> > 我感觉你的反对票的目的是,如果有任何一个follower在投票过程中发现自己的日志记录比candidate新,那么这个candidate就应该退化为follower。是这个意思吗
>
> 问题是这样实现的话就已经不是raft协议了,我认为这样实现是不对的,会导致liveness甚至是safety的问题。
>
> 考虑这样一个情况
>
> node 7 在 term = 6 期间把一条log复制到了 node 6 上,然后node 7 宕机。
>
> 这个时候,如果按照你的实现,只有可能node 6 能成为candidate,因为node 1 2 3 4 5 的日志记录都比node 6 的要旧。
>
> 可是这样的话假设node 1 具有最短的timeout间隔而node 6 具有最长的timeout间隔。这也就意味着即使node 1 本应最先成为leader,却因为多出来的条件而导致不能成为leader,就违背了任意不同node采用不同timeout时长的初衷了。
>
> 更重要的是这样做并没有什么意义,candidate就没有必要比每一个node的日记记录都要新,才用你说的反对票机制并不能带来额外的好处
>
> > 这是为了避免发生新leader在当选后刚提议消息只被少数结点获取就跟着这些少数结点永久性宕机这种情况时,永久性不能恢复生产的及其特殊情况
>
> 我不认为这种情况会在raft协议中出现,如果只是少数派节点宕机那么raft一定能选出一个leader来继续工作,如果您能提供一个详细的example说明为什么会出现少数节点宕机会导致永久不能恢复生产的话,非常感谢~
>
> 至于新的提案里的loggedTerm, loggerIndex 在raft里就有这样的概念, 叫lastLogTerm 和 lastLogIndex, termWated 就是 raft 里的 term, 不同的是raft 里的term是 “当前节点所见到过的最大term“。
>
> 总而言之,新的提案对raft的核心步骤做出了修改,将一个原本宽松的条件升级成了一个更为严格的条件,必须得证明这样做不会影响livenss我们才能讨论实现的可能。(safety 被损害的可能性不大,毕竟让leader选举更严格了)
引入退化follower再次等待一定时长后参选,是为了保障不会所有节点同时遇到这种情况下的永久性follower。
任何结点不能站在上帝视角观察整个过程。所以结点1在获取反对票时并无法确定是少数新leader如7宕机还是自己收到选票后就已经有了正常工作的新的leader出现。pre-vote候选人资格只是保证了获取资格时的日志纪录最新,不代表投票时的日志纪录最新,因为别的结点完全有可能会在这期间获得候选人资格并当选leader。
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [rocketmq] imaffe commented on issue #2056: Issues and Improvement Strategies in the Raft Protocol Election
Posted by GitBox <gi...@apache.org>.
imaffe commented on issue #2056:
URL: https://github.com/apache/rocketmq/issues/2056#issuecomment-636612872
我来整理一下
投票者
- 投反对票:根据收到的loggedterm,loggedindex,termwanted进行对比,如果前两者自身更大,而无论自身termWanted更大或者更小或相等,则反馈结果中填入票数-10000
- 投不同意票:如果前两者自身更小或相等而自身所知termwanted更大,则反馈结果中填入票数0
- 投同意票: 如果前两者自身更小或相等而自身所知termwanted更小或相等,则反馈结果中填入票数1
是这样嘛?
所以节点 7 到底能不能感知到有term = 7 的候选人决定了节点7能不能成为leader
> 即一旦感知到自己存在日志纪录term不为最新导致不能百分百当选就迅速退避
为什么不能百分百当选就迅速退避呢?仍然有可能成为leader啊。
完全有可能 节点A 的日志记录比B 新, 但是节点A 的term比B要小。
而这个时候节点A就是普通的拒绝节点B就行了,节点B也不应该
我感觉你的反对票的目的是,如果有任何一个follower在投票过程中发现自己的日志记录比candidate新,那么这个candidate就应该退化为follower。是这个意思吗
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org