You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/05/06 02:24:14 UTC
[GitHub] [hudi] aiwenmo opened a new issue, #5513: [SUPPORT] Sync realtime whole mysql database to hudi failed when using flink datastream api
aiwenmo opened a new issue, #5513:
URL: https://github.com/apache/hudi/issues/5513
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)?
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org.
- If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
org.apache.hudi.org.apache.avro.AvroRuntimeException: Not a valid schema field.
**To Reproduce**
Steps to reproduce the behavior:
1.Some relevant codes are shown below.
`
public void addSink(
StreamExecutionEnvironment env,
DataStream<RowData> rowDataDataStream,
Table table,
List<String> columnNameList,
List<LogicalType> columnTypeList) {
final String[] columnNames = columnNameList.toArray(new String[columnNameList.size()]);
final LogicalType[] columnTypes = columnTypeList.toArray(new LogicalType[columnTypeList.size()]);
final String tableName = getSinkTableName(table);
Integer parallelism = 1;
boolean isMor = true;
Map<String, String> sink = config.getSink();
Configuration configuration = Configuration.fromMap(sink);
if (sink.containsKey("parallelism")) {
parallelism = Integer.valueOf(sink.get("parallelism"));
}
if (configuration.contains(FlinkOptions.PATH)) {
configuration.set(FlinkOptions.PATH, configuration.getValue(FlinkOptions.PATH) + tableName);
}
if (sink.containsKey(FlinkOptions.TABLE_TYPE.key())) {
isMor = HoodieTableType.MERGE_ON_READ.name().equals(sink.get(FlinkOptions.TABLE_TYPE.key()));
}
configuration.set(FlinkOptions.TABLE_NAME, tableName);
configuration.set(FlinkOptions.HIVE_SYNC_DB, getSinkSchemaName(table));
configuration.set(FlinkOptions.HIVE_SYNC_TABLE, tableName);
long ckpTimeout = rowDataDataStream.getExecutionEnvironment()
.getCheckpointConfig().getCheckpointTimeout();
configuration.setLong(FlinkOptions.WRITE_COMMIT_ACK_TIMEOUT, ckpTimeout);
RowType rowType = RowType.of(false, columnTypes, columnNames);
configuration.setString(FlinkOptions.SOURCE_AVRO_SCHEMA,
AvroSchemaConverter.convertToSchema(rowType).toString());
// bulk_insert mode
final String writeOperation = configuration.get(FlinkOptions.OPERATION);
if (WriteOperationType.fromValue(writeOperation) == WriteOperationType.BULK_INSERT) {
Pipelines.bulkInsert(configuration, rowType, rowDataDataStream);
} else
// Append mode
if (OptionsResolver.isAppendMode(configuration)) {
Pipelines.append(configuration, rowType, rowDataDataStream);
} else {
DataStream<HoodieRecord> hoodieRecordDataStream = Pipelines.bootstrap(configuration, rowType, parallelism, rowDataDataStream);
DataStream<Object> pipeline = Pipelines.hoodieStreamWrite(configuration, parallelism, hoodieRecordDataStream);
// compaction
if (StreamerUtil.needsAsyncCompaction(configuration)) {
Pipelines.compact(configuration, pipeline);
} else {
Pipelines.clean(configuration, pipeline);
}
if (isMor) {
Pipelines.clean(configuration, pipeline);
Pipelines.compact(configuration, pipeline);
}
}
}
`
2. Use dlink to submit task. The SQL is as follows.
` sql
EXECUTE CDCSOURCE demo WITH (
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'source.server-time-zone' = 'UTC',
'checkpoint'='1000',
'scan.startup.mode'='initial',
'parallelism'='1',
'database-name'='data_deal',
'table-name'='data_deal\.stu,data_deal\.score',
'sink.connector'='datastream-hudi',
'sink.path'='hdfs://cluster1/tmp/flink/cdcdata/',
'sink.hoodie.datasource.write.recordkey.field'='id',
'sink.hoodie.parquet.max.file.size'='268435456',
'sink.write.precombine.field'='update_time',
'sink.write.tasks'='1',
'sink.write.bucket_assign.tasks'='2',
'sink.write.precombine'='true',
'sink.compaction.async.enabled'='true',
'sink.write.task.max.size'='1024',
'sink.write.rate.limit'='3000',
'sink.write.operation'='upsert',
'sink.table.type'='COPY_ON_WRITE',
'sink.compaction.tasks'='1',
'sink.compaction.delta_seconds'='20',
'sink.compaction.async.enabled'='true',
'sink.read.streaming.skip_compaction'='true',
'sink.compaction.delta_commits'='20',
'sink.compaction.trigger.strategy'='num_or_time',
'sink.compaction.max_memory'='500',
'sink.changelog.enabled'='true',
'sink.read.streaming.enabled'='true',
'sink.read.streaming.check.interval'='3',
'sink.hive_sync.enable'='true',
'sink.hive_sync.mode'='hms',
'sink.hive_sync.db'='cdc_ods',
'sink.table.prefix.schema'='true',
'sink.hive_sync.metastore.uris'='thrift://cdh.com:9083',
'sink.hive_sync.username'='flinkcdc'
)
`
4.org.apache.hudi.org.apache.avro.AvroRuntimeException: Not a valid schema field.
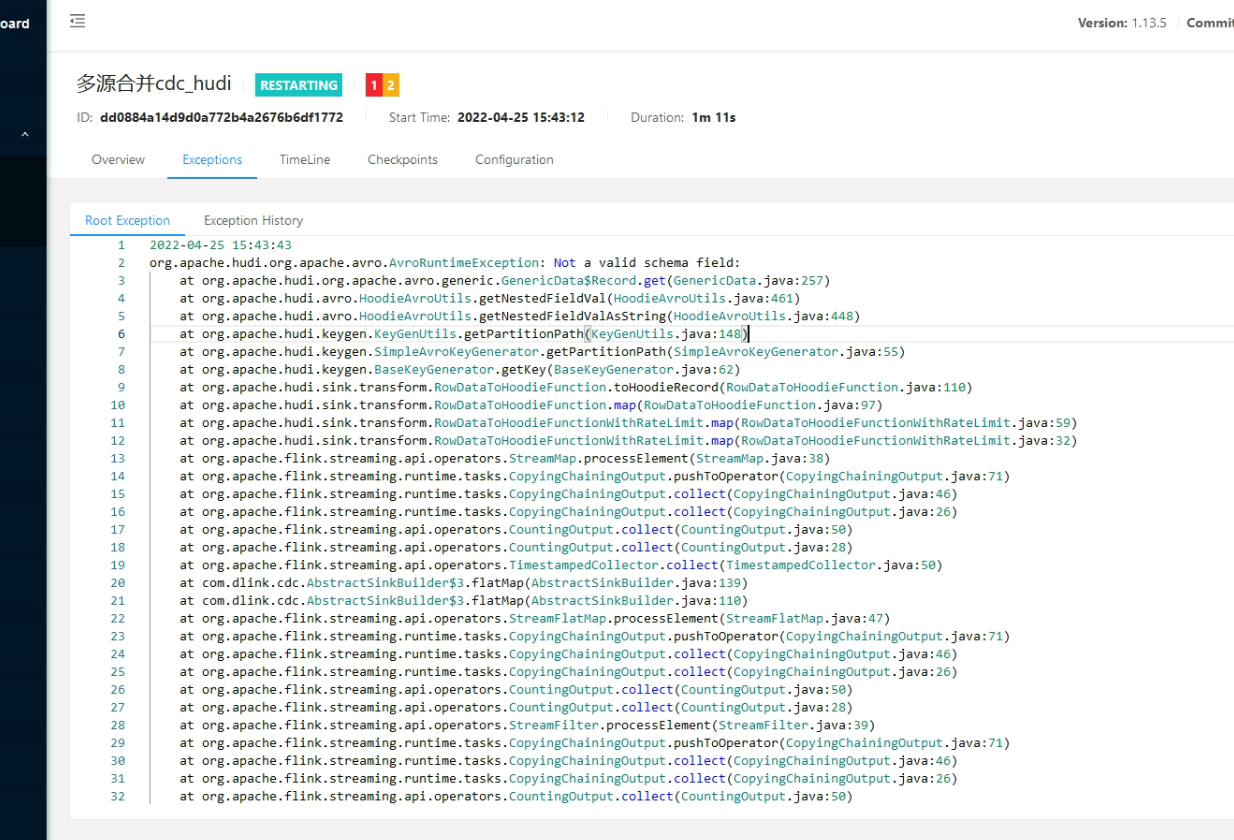
5.Table has no partitions.
**Expected behavior**
The task is running normally.
**Environment Description**
* Hudi version :
0.10.0
* Flink version :
1.13.5
* Dlink version :
0.6.3-snapshot (main)
* Hadoop version :
3.0.0-cdh6.3.2
* Hive version :
2.1.1-cdh6.3.2
* Storage (HDFS/S3/GCS..) :
HDFS
* Running on Docker? (yes/no) :
no
**Additional context**
The solution is to add "sink.hoodie.datasource.write.keygenerator.type"="NON_PARTITION".
**Stacktrace**
```Add the stacktrace of the error.```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] aiwenmo closed issue #5513: [SUPPORT] Sync realtime whole mysql database to hudi failed when using flink datastream api
Posted by GitBox <gi...@apache.org>.
aiwenmo closed issue #5513: [SUPPORT] Sync realtime whole mysql database to hudi failed when using flink datastream api
URL: https://github.com/apache/hudi/issues/5513
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #5513: [SUPPORT] Sync realtime whole mysql database to hudi failed when using flink datastream api
Posted by GitBox <gi...@apache.org>.
danny0405 commented on issue #5513:
URL: https://github.com/apache/hudi/issues/5513#issuecomment-1119274099
You need to set up the key generator clazz correctly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] aiwenmo commented on issue #5513: [SUPPORT] Sync realtime whole mysql database to hudi failed when using flink datastream api
Posted by GitBox <gi...@apache.org>.
aiwenmo commented on issue #5513:
URL: https://github.com/apache/hudi/issues/5513#issuecomment-1119280273
> You need to set up the key generator clazz correctly.
thx. Your method is also OK.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #5513: [SUPPORT] Sync realtime whole mysql database to hudi failed when using flink datastream api
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #5513:
URL: https://github.com/apache/hudi/issues/5513#issuecomment-1129966941
> > You need to set up the key generator clazz correctly.
>
> thx. Your method is also OK.
@aiwenmo did the suggestion solve the issue? if so let's close this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org