You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2021/02/05 07:46:56 UTC
[GitHub] [hudi] hseagle opened a new issue #2538: [SUPPORT]MOR doesn't work on version 0.7.0
hseagle opened a new issue #2538:
URL: https://github.com/apache/hudi/issues/2538
In the lastest version 0.7.0, MOR does not work. It means the duplicated keys hasn't been merged.
Here is the sample application code
```scala
case class Person(firstname:String, age:Int, gender:Int)
val personDF = List(Person("tom",45,1), Person("iris",44,0)).toDF.withColumn("ts",unix_timestamp).withColumn("insert_time",current_timestamp)
//val personDF2 = List(Person("peng",56,1), Person("iris",51,0),Person("jacky",25,1)).toDF.withColumn("ts",unix_timestamp).withColumn("insert_time",current_timestamp)
//personDF.write.mode(SaveMode.Overwrite).format("hudi").saveAsTable("employee")
val hudiCommonOptions = Map(
"hoodie.compact.inline" -> "true",
"hoodie.compact.inline.max.delta.commits" ->"1"
)
val tableName = "employee"
val hudiHiveOptions = Map(
DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY -> "true",
DataSourceWriteOptions.HIVE_URL_OPT_KEY -> "jdbc:hive2://localhost:10000",
DataSourceWriteOptions.HIVE_TABLE_OPT_KEY -> tableName,
DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY -> "gender",
DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY -> "true",
"hoodie.datasource.write.table.type"->"MERGE_ON_READ",
"hoodie.datasource.hive_sync.support_timestamp"->"true",
"hoodie.datasource.write.operation" -> "upsert",
DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY -> classOf[MultiPartKeysValueExtractor].getName
)
val basePath = s"/tmp/$tableName"
personDF.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "firstname").
option(PARTITIONPATH_FIELD_OPT_KEY, "gender").
option(TABLE_NAME, tableName).
options(hudiCommonOptions).
options(hudiHiveOptions).
mode(SaveMode.Overwrite).
save(basePath)
val personDF2 = List(Person("tom",26,1), Person("iris",31,0),Person("jacky",35,1)).toDF.withColumn("ts",unix_timestamp).withColumn("insert_time",current_timestamp)
personDF2.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "firstname").
option(PARTITIONPATH_FIELD_OPT_KEY, "gender").
option(TABLE_NAME, tableName).
options(hudiCommonOptions).
options(hudiHiveOptions).
mode(SaveMode.Append).
save(basePath)
sql(s"refresh table ${tableName}_rt")
sql(s"select firstname, age, gender, ts, insert_time from ${tableName}_rt").show(20,false)
```
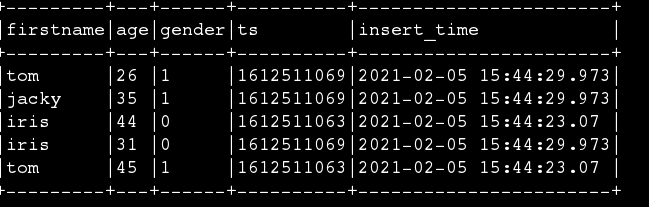
The final query result is showed in the images. We can find that the duplicated key haven't been merged.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #2538: [SUPPORT]MOR doesn't work on version 0.7.0
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #2538:
URL: https://github.com/apache/hudi/issues/2538#issuecomment-774115857
probably you are missing to set the input format config. Did you try older versions of Hudi and the issue is only w/ 0.7.0? or the is the first time you are trying out Hudi?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar closed issue #2538: [SUPPORT]MOR doesn't work on version 0.7.0
Posted by GitBox <gi...@apache.org>.
vinothchandar closed issue #2538:
URL: https://github.com/apache/hudi/issues/2538
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] vinothchandar commented on issue #2538: [SUPPORT]MOR doesn't work on version 0.7.0
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #2538:
URL: https://github.com/apache/hudi/issues/2538#issuecomment-774416809
@hseagle `spark.sql.hive.convertMetastoreParquet=false` was always required for MOR tables. So not sure what the issue was. Do you mind opening a new support issue for the timestamp thing. (there is also a possibility that something exists already). Closing this one for now
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] hseagle commented on issue #2538: [SUPPORT]MOR doesn't work on version 0.7.0
Posted by GitBox <gi...@apache.org>.
hseagle commented on issue #2538:
URL: https://github.com/apache/hudi/issues/2538#issuecomment-774390684
Thank you for your response. I tried to add the input format in spark-defaults.conf. But the duplicated key is still existed.
One more thing, I tested it by using version 0.6.0, the duplicated key was merged.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] hseagle commented on issue #2538: [SUPPORT]MOR doesn't work on version 0.7.0
Posted by GitBox <gi...@apache.org>.
hseagle commented on issue #2538:
URL: https://github.com/apache/hudi/issues/2538#issuecomment-774397457
After set **spark.sql.hive.convertMetastoreParquet=false**, the duplicated key can be removed.
But another issue is encounted, the column with timestamp data type cann't be fetched. The error message is showed as below
```log
Caused by: java.lang.ClassCastException: org.apache.hadoop.io.LongWritable cannot be cast to org.apache.hadoop.hive.serde2.io.TimestampWritable
at org.apache.hadoop.hive.serde2.objectinspector.primitive.WritableTimestampObjectInspector.getPrimitiveJavaObject(WritableTimestampObjectInspector.java:39)
at org.apache.spark.sql.hive.HadoopTableReader$.$anonfun$fillObject$14(TableReader.scala:468)
at org.apache.spark.sql.hive.HadoopTableReader$.$anonfun$fillObject$14$adapted(TableReader.scala:467)
at org.apache.spark.sql.hive.HadoopTableReader$.$anonfun$fillObject$18(TableReader.scala:493)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:459)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$$anon$1.hasNext(WholeStageCodegenExec.scala:729)
at org.apache.spark.sql.execution.SparkPlan.$anonfun$getByteArrayRdd$1(SparkPlan.scala:340)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:872)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:872)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:349)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:313)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:446)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:449)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org