You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@dolphinscheduler.apache.org by ch...@apache.org on 2021/05/28 09:42:18 UTC
[dolphinscheduler-website] branch master updated: Add a blog about
json_split (#371)
This is an automated email from the ASF dual-hosted git repository.
chengshiwen pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/dolphinscheduler-website.git
The following commit(s) were added to refs/heads/master by this push:
new e52a2a4 Add a blog about json_split (#371)
e52a2a4 is described below
commit e52a2a4fd8fe853150083461a3bc43460681116c
Author: QuakeWang <45...@users.noreply.github.com>
AuthorDate: Fri May 28 17:42:10 2021 +0800
Add a blog about json_split (#371)
* Create load-balance.md
docs: add en-us load-balance.md
* Delete load-balance.md
* Create test.md
* Add files via upload
add some pictures about json split
* Delete test.md
* Add files via upload
add a picture about snowflake
* Update json_split.md
update the blog
* Update blog.js
add the information about json_split.html
---
blog/zh-cn/json_split.md | 97 ++++++++++++++++-----
img/JsonSplit/json.png | Bin 0 -> 60578 bytes
img/JsonSplit/server.png | Bin 0 -> 20050 bytes
img/JsonSplit/snowflake.png | Bin 0 -> 9403 bytes
...\206\346\226\271\346\241\210-1620304011852.png" | Bin 0 -> 104322 bytes
...13\206\345\210\206\346\226\271\346\241\210.png" | Bin 0 -> 105135 bytes
site_config/blog.js | 8 ++
7 files changed, 81 insertions(+), 24 deletions(-)
diff --git a/blog/zh-cn/json_split.md b/blog/zh-cn/json_split.md
index 4ac7532..00e2030 100644
--- a/blog/zh-cn/json_split.md
+++ b/blog/zh-cn/json_split.md
@@ -1,57 +1,106 @@
-## 背景
+## 为什么要把 DolphinScheduler 工作流定义中保存任务及关系的大 json 给拆了?
-当前dolphinscheduler的工作流中的任务及关系保存时是以大json的方式保存到数据库中process_definiton表的process_definition_json字段,如果某个工作流很大比如有100或者1000个任务,这个json字段也就非常大,在使用时需要解析json,非常耗费性能,且任务没法重用,故社区计划启动json拆分项目
+### 背景
-## 一期总结
+当前 DolphinScheduler 的工作流中的任务及关系保存时是以大 json 的方式保存到数据库中 process_definiton 表的 process_definition_json 字段,如果某个工作流很大比如有 1000 个任务,这个 json 字段也就随之变得非常大,在使用时需要解析 json,非常耗费性能,且任务没法重用,故社区计划启动 json 拆分项目。可喜的是目前我们已经完成了这个工作的大部分,因此总结一下,供大家参考学习。
-json split项目从2021-01-12开始启动,到2021-04-25一期已完成。代码正在合入dev分支。感谢lenboo、JinyLeeChina、simon824、wen-hemin四位伙伴参与coding。
+### 总结
-- 代码变更12793行
+json split 项目从 2021-01-12 开始启动,到 2021-04-25 初步完成主要开发。代码已合入 dev 分支。感谢 lenboo、JinyLeeChina、simon824、wen-hemin 四位伙伴参与 coding。
+
+主要变化以及贡献如下:
+
+- 代码变更 12793 行
- 修改/增加 168 个文件
-- 共145次commit
-- 有85个pr
+- 共 145 次 Commits
+- 有 85 个 PR
### 拆分方案回顾
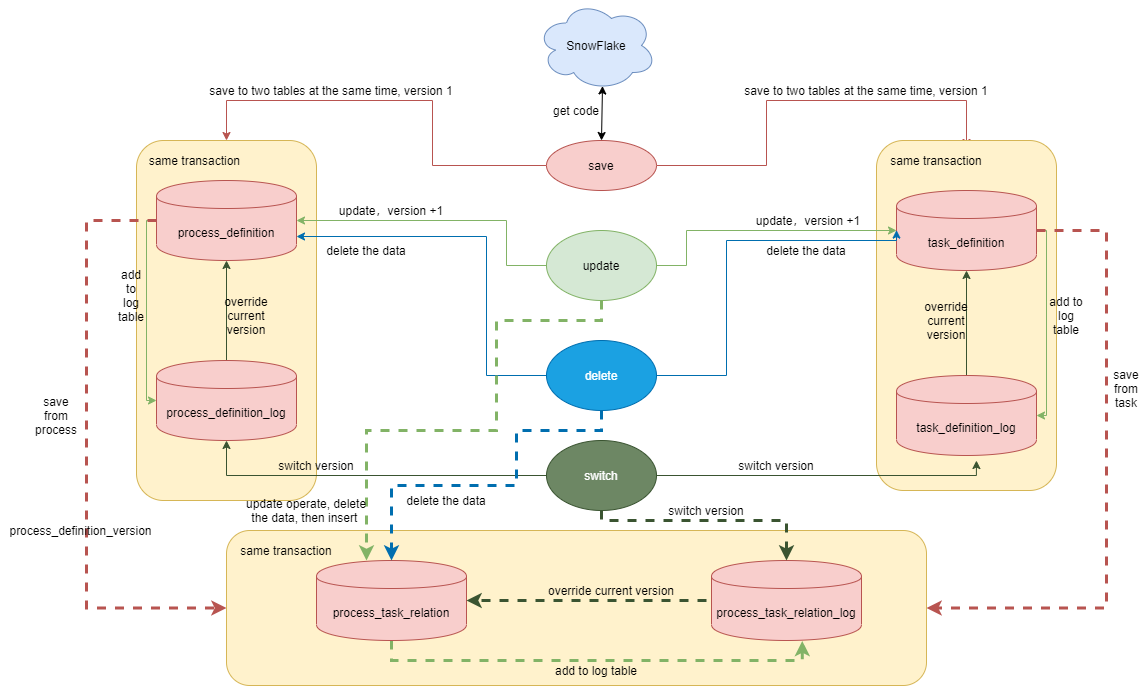
-- [ ] api模块进行save操作时
+- [ ] api 模块进行 save 操作时
-1. 通过雪花算法生成13位的数字作为process_definition_code,工作流定义保存至process_definition(主表)和process_definition_log(日志表),这两个表保存的是同样的数据,工作流定义版本为1
-2. 通过雪花算法生成13位的数字作为task_definition_code,任务定义表保存至task_definition(主表)和task_definition_log(日志表),也是保存同样的数据,任务定义版本为1
-3. 工作流任务关系保存在 process_task_relation(主表)和process_task_relation_log(日志表),该表保存的code和version是工作流的code和version,因为任务是通过工作流进行组织,以工作流来画dag。也是通过post_task_code和post_task_version标识dag的当前节点,这个节点的前置依赖通过pre_task_code和pre_task_version来标识,如果没有依赖,pre_task_code和pre_task_version为0
+1. 通过雪花算法生成 13 位的数字作为 process_definition_code,工作流定义保存至 process_definition(主表)和 process_definition_log(日志表),这两个表保存的是同样的数据,工作流定义版本为 1
+2. 通过雪花算法生成 13 位的数字作为 task_definition_code,任务定义表保存至 task_definition(主表)和 task_definition_log(日志表),也是保存同样的数据,任务定义版本为 1
+3. 工作流任务关系保存在 process_task_relation(主表)和 process_task_relation_log(日志表),该表保存的 code 和 version 是工作流的 code 和 version,因为任务是通过工作流进行组织,以工作流来画 dag。也是通过 post_task_code 和 post_task_version 标识 dag 的当前节点,这个节点的前置依赖通过 pre_task_code 和 pre_task_version 来标识,如果没有依赖,pre_task_code 和 pre_task_version 为 0
-- [ ] api模块进行update操作时,工作流定义和任务定义直接更新主表数据,更新后的数据insert到日志表。关系表主表先删除然后再插入新的关系,关系表日志表直接插入新的关系
+- [ ] api 模块进行 update 操作时,工作流定义和任务定义直接更新主表数据,更新后的数据 insert 到日志表。关系表主表先删除然后再插入新的关系,关系表日志表直接插入新的关系
-- [ ] api模块进行delete操作时,工作流定义、任务定义和关系表直接删除主表数据,日志表数据不变动
-- [ ] api模块进行switch操作时,直接将日志表中对应version数据覆盖到主表
+- [ ] api 模块进行 delete 操作时,工作流定义、任务定义和关系表直接删除主表数据,日志表数据不变动
+- [ ] api 模块进行 switch 操作时,直接将日志表中对应 version 数据覆盖到主表
### Json存取方案
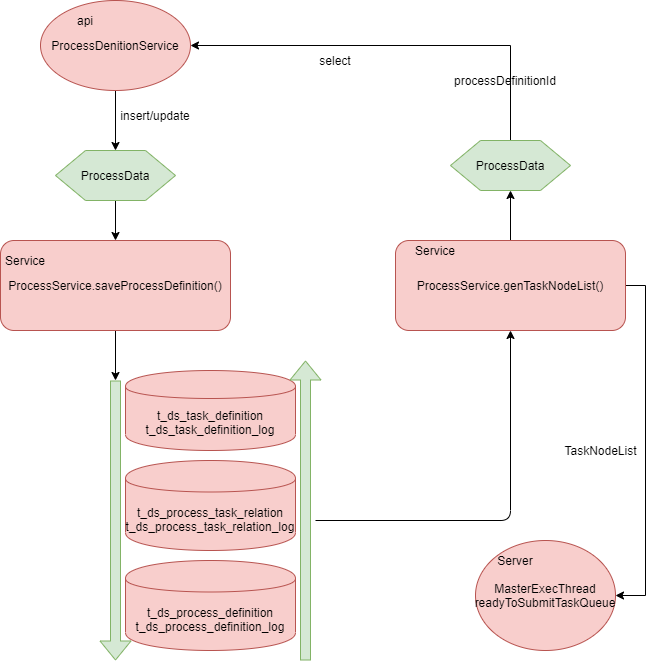
-- [ ] 当前一期拆分方案,api模块controller层整体未变动,传入的大json还是在service层映射为ProcessData对象。insert或update操作在公共Service模块通过ProcessService.saveProcessDefiniton()入口完成保存数据库操作,按照task_definition、process_task_relation、process_definition的顺序保存。保存时,如果该任务已经存在并且关联的工作流未上线,则更改任务;如果任务关联的工作流已上线,则不允许更改任务
+- [ ] 当前一期拆分方案,api 模块 controller 层整体未变动,传入的大 json 还是在 service 层映射为 ProcessData 对象。insert 或 update 操作在公共 Service 模块通过 ProcessService.saveProcessDefiniton() 入口完成保存数据库操作,按照 task_definition、process_task_relation、process_definition 的顺序保存。保存时,如果该任务已经存在并且关联的工作流未上线,则更改任务;如果任务关联的工作流已上线,则不允许更改任务
-- [ ] api查询操作时,当前还是通过工作流id来查询,在公共Service模块通过ProcessService.genTaskNodeList()入口完成数据组装,还是组装为ProcessData对象,进而生成json返回
-- [ ] Server模块(Master)也是通过公共Service模块ProcessService.genTaskNodeList()获得TaskNodeList生成调度dag,把当前任务所有信息放到 MasterExecThread.readyToSubmitTaskQueue队列,以便生成taskInstance,dispatch给worker
+- [ ] api 查询操作时,当前还是通过工作流 id 来查询,在公共 Service 模块通过ProcessService.genTaskNodeList() 入口完成数据组装,还是组装为 ProcessData 对象,进而生成 json 返回
+- [ ] Server 模块(Master)也是通过公共 Service 模块 ProcessService.genTaskNodeList() 获得 TaskNodeList 生成调度 dag,把当前任务所有信息放到 MasterExecThread.readyToSubmitTaskQueue 队列,以便生成 taskInstance、dispatch 给 worker
## 二期规划
-### api/ui模块改造
+### api/ui 模块改造
-- [ ] processDefinition接口通过processDefinitionId请求后端的替换为processDefinitonCode
-- [ ] 支持task的单独定义,当前task的插入及修改是通过工作流来操作的,二期需要支持单独定义
-- [ ] 前端及后端controller层 json 拆分,一期已完成api模块service层到dao的json拆分,二期需要完成前端及controller层json拆分
+- [ ] processDefinition 接口通过 processDefinitionId 请求后端的替换为 processDefinitonCode
+- [ ] 支持 task 的单独定义,当前 task 的插入及修改是通过工作流来操作的,二期需要支持单独定义
+- [ ] 前端及后端 controller 层 json 拆分,一期已完成 api 模块 service 层到 dao 的 json 拆分,二期需要完成前端及 controller 层 json 拆分
### server模块改造
-- [ ] t_ds_command、t_ds_error_command、t_ds_schedules中process_definition_id替换为process_definition_code
+- [ ] t_ds_command、t_ds_error_command、t_ds_schedules 中 process_definition_id 替换为 process_definition_code
-- [ ] 生成taskInstance流程改造
+- [ ] 生成 taskInstance 流程改造
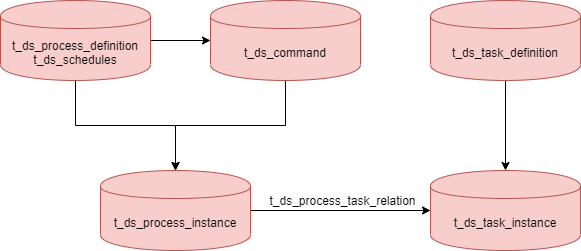
-当前生成process_instance,是通过process_definition和schedules及command表生成,而生成taskInstance还是来源于MasterExecThread.readyToSubmitTaskQueue队列,而队列中数据来源于dag对象,此时,该队列及dag中保存taskInstance的所有信息,这种方式非常占用内存。可改造为如下图的数据流转方式,readyToSubmitTaskQueue队列及dag中保存任务code和版本信息,在生成task_instance前,查询task_definition
+当前生成 process_instance,是通过 process_definition 和 schedules 及 command 表生成,而生成 taskInstance 还是来源于 MasterExecThread.readyToSubmitTaskQueue 队列,并且队列中数据来源于 dag 对象。此时,该队列及 dag 中保存 taskInstance 的所有信息,这种方式非常占用内存。可改造为如下图的数据流转方式,readyToSubmitTaskQueue 队列及 dag 中保存任务 code 和版本信息,在生成 task_instance 前,查询 task_definition
+---
+
+**附录:雪花算法(snowflake)**
+
+**雪花算法(snowflake):** 是一种生成分布式全剧唯一 ID 的算法,生成的 ID 称为 **snowflake**,这种算法是由 Twitter 创建,并用于推文的 ID。
+
+一个 Snowflake ID 有 64 bit。前 41 bit 是时间戳,表示了自选定的时期以来的毫秒数。 接下来的 10 bit 代表计算机 ID,防止冲突。 其余 12 bit 代表每台机器上生成 ID 的序列号,这允许在同一毫秒内创建多个 Snowflake ID。SnowflakeID 基于时间生成,故可以按时间排序。此外,一个 ID 的生成时间可以由其自身推断出来,反之亦然。该特性可以用于按时间筛选 ID,以及与之联系的对象。
+
+**雪花算法的结构:**
+
+
+
+主要分为 5 个部分:
+
+1. 是 1 个 bit:0,这个是无意义的;
+2. 是 41 个 bit:表示的是时间戳;
+3. 是 10 个 bit:表示的是机房 id,0000000000,因为此时传入的是0;
+4. 是 12 个 bit:表示的序号,就是某个机房某台机器上这一毫秒内同时生成的 id 的序号,0000 0000 0000。
+
+ 接下去我们来解释一下四个部分:
+
+**1 bit,是无意义的:**
+
+ 因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
+
+**41 bit:表示的是时间戳,单位是毫秒。**
+
+ 41 bit 可以表示的数字多达 2^41 - 1,也就是可以标识 2 ^ 41 - 1 个毫秒值,换算成年就是表示 69 年的时间。
+
+**10 bit:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。**
+
+ 但是 10 bit 里 5 个 bit 代表机房 id,5 个 bit 代表机器 id。意思就是最多代表 2 ^ 5 个机房(32 个机房),每个机房里可以代表 2 ^ 5 个机器(32 台机器),这里可以随意拆分,比如拿出4位标识业务号,其他6位作为机器号。可以随意组合。
+
+**12 bit:这个是用来记录同一个毫秒内产生的不同 id。**
+
+ 12 bit 可以代表的最大正整数是 2 ^ 12 - 1 = 4096,也就是说可以用这个 12 bit 代表的数字来区分同一个毫秒内的 4096 个不同的 id。也就是同一毫秒内同一台机器所生成的最大ID数量为4096
+
+ 简单来说,你的某个服务假设要生成一个全局唯一 id,那么就可以发送一个请求给部署了 SnowFlake 算法的系统,由这个 SnowFlake 算法系统来生成唯一 id。这个 SnowFlake 算法系统首先肯定是知道自己所在的机器号,(这里姑且讲 10bit 全部作为工作机器 ID)接着 SnowFlake 算法系统接收到这个请求之后,首先就会用二进制位运算的方式生成一个 64 bit 的 long 型 id,64 个 bit 中的第一个 bit 是无意义的。接着用当前时间戳(单位到毫秒)占用41 个 bit,然后接着 10 个 bit 设置机器 id。最后再判断一下,当前这台机房的这台机器上这一毫秒内,这是第几个请求,给这次生成 id 的请求累加一个序号,作为最后的 12 个 bit。
+
+SnowFlake 的特点是:
+
+1. 毫秒数在高位,自增序列在低位,整个 ID 都是趋势递增的。
+2. 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成 ID 的性能也是非常高的。
+3. 可以根据自身业务特性分配 bi t位,非常灵活。
+
diff --git a/img/JsonSplit/json.png b/img/JsonSplit/json.png
new file mode 100644
index 0000000..4f0b40f
Binary files /dev/null and b/img/JsonSplit/json.png differ
diff --git a/img/JsonSplit/server.png b/img/JsonSplit/server.png
new file mode 100644
index 0000000..af8949b
Binary files /dev/null and b/img/JsonSplit/server.png differ
diff --git a/img/JsonSplit/snowflake.png b/img/JsonSplit/snowflake.png
new file mode 100644
index 0000000..1901a54
Binary files /dev/null and b/img/JsonSplit/snowflake.png differ
diff --git "a/img/JsonSplit/\346\213\206\345\210\206\346\226\271\346\241\210-1620304011852.png" "b/img/JsonSplit/\346\213\206\345\210\206\346\226\271\346\241\210-1620304011852.png"
new file mode 100644
index 0000000..c77df50
Binary files /dev/null and "b/img/JsonSplit/\346\213\206\345\210\206\346\226\271\346\241\210-1620304011852.png" differ
diff --git "a/img/JsonSplit/\346\213\206\345\210\206\346\226\271\346\241\210.png" "b/img/JsonSplit/\346\213\206\345\210\206\346\226\271\346\241\210.png"
new file mode 100644
index 0000000..e40150f
Binary files /dev/null and "b/img/JsonSplit/\346\213\206\345\210\206\346\226\271\346\241\210.png" differ
diff --git a/site_config/blog.js b/site_config/blog.js
index 12bab0c..be7422c 100644
--- a/site_config/blog.js
+++ b/site_config/blog.js
@@ -71,6 +71,14 @@ export default {
desc: 'DAG:全称是Directed Acyclic Graph,简称DAG。工作流中的任务以有向无环图的形式组合,从拓扑上看,这些节点的入口度为零,直到没有后续节点为止。',
link: '/zh-ch/blog/DAG.html',
},
+ {
+ title: '为什么要把 DolphinScheduler 工作流定义中保存任务及关系的大 json 给拆了?',
+ author: '进勇',
+ editor: '王福政',
+ dateStr: '2021-05-25',
+ desc: '当前 DolphinScheduler 的工作流中的任务及关系保存时是以大 json 的方式保存到数据库中 process_definiton 表的 process_definition_json 字段,如果某个工作流很大比如有 1000 个任务,这个 json 字段也就随之变得非常大,在使用时需要解析 json,非常耗费性能,且任务没法重用,故社区计划启动 json 拆分项目。',
+ link: '/zh-ch/blog/json_split.html',
+ },
],
},
};