You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/07/31 14:20:54 UTC
[GitHub] [iceberg] ayush-san opened a new issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
ayush-san opened a new issue #2900:
URL: https://github.com/apache/iceberg/issues/2900
Hi all,
We are using Flink + iceberg to consume CDC data. We have combined all the tables of a single DB in one job. Our job is frequently running into GC issues. Earlier it was running default on parallel GC and I have changed it to G1GC. G1GC did bring some improvements but still, I am facing the same problem.
Following are the params on my job - -ytm 5120m -yjm 1024m -yD env.java.opts="-XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=35"
This job is running CDC ingestion for 17 tables with a parallelism of 1 and throughput is around ~10k messages for the 10minutes checkpointing interval
I am attaching a part of the thread dump and gc log too
During old GC, the job gets stuck and its checkpointing which is normally under 1 sec gets increased exponentially to the timeout threshold. Job either get failed due to checkpointing timeout or it failed to get the heartbeat of the task manager
<img width="1118" alt="Screenshot 2021-07-29 at 16 08 58" src="https://user-images.githubusercontent.com/57655135/127742589-c174fc7b-748e-4c85-b898-37c3f3a14b62.png">
<img width="1349" alt="Screenshot 2021-07-29 at 16 09 19" src="https://user-images.githubusercontent.com/57655135/127742613-d3c5724b-634e-4d89-928c-30e34a9c0674.png">
As you can see in this screenshot checkpoint duration which is normally under 1 sec, spikes to over 10mins too but throughput is never above 1k per min
<img width="1342" alt="Screenshot 2021-07-31 at 19 46 26" src="https://user-images.githubusercontent.com/57655135/127742660-614c2cf3-863b-43b1-9b86-7c157aea5fc9.png">
[thread_dump.txt](https://github.com/apache/iceberg/files/6911309/thread_dump.txt)
[gc-11.log](https://github.com/apache/iceberg/files/6911310/gc-11.log)
[gc-13.log](https://github.com/apache/iceberg/files/6911311/gc-13.log)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-893229843
@rdblue I enabled heapdump on the job with the following params
```
-XX:+HeapDumpOnOutOfMemoryError -XX:+HeapDumpBeforeFullGC -XX:+HeapDumpAfterFullGC -XX:HeapDumpPath=/tmp/heap.dump
```
It generated 6 files of a total 15GB heap dump in 30mins. At this only young GC was happening and the job was running steadily.
PFA heap dump of 2 files
[heapReport-2021-08-05-12-49.pdf](https://github.com/apache/iceberg/files/6936752/heapReport-2021-08-05-12-49.pdf)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-893229843
@rdblue I enabled heapdump on the job with the following params
```
-XX:+HeapDumpOnOutOfMemoryError -XX:+HeapDumpBeforeFullGC -XX:+HeapDumpAfterFullGC -XX:HeapDumpPath=/tmp/heap.dump
```
It generated 6 files of a total 15GB heap dump in 30mins. At this only young GC was happening and the job was running steadily.
PFA heap dump of 2 files
[heapReport-2021-08-05-12-49.pdf](https://github.com/apache/iceberg/files/6936752/heapReport-2021-08-05-12-49.pdf)
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu edited a comment on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
stevenzwu edited a comment on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-893575995
I am not surprised by `org.apache.flink.runtime.taskmanager.Task` as it is the worker thread. So that doesn't really help much here.
I often found denominator tree from Eclipse MAT very useful to understand the memory footprint: https://www.eclipse.org/mat/about/dominator_tree.png
Reading the original description, I have some questions for this setup: "We have combined all the tables of a single DB in one job."
1. are tables partitioned by event time or ingestion time? or some other partition spec that can make writers append to multiple files concurrently?
2. do you run multiple writer tasks/threads in the same core? E.g., assuming your DB has 10 tables, does each slot/core run 10 writers or only 1 writer? If each taskmanager has too many writer tasks, memory consumption by Parquet is going to be a problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu edited a comment on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
stevenzwu edited a comment on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-895340841
@ayush-san you might have the right hutch regarding " not running maintenance procedures"? You can verify the hypothesis by writing to a new empty table, which should eliminate the factor. if you are not seeing the GC issue after the switch, that will likely confirm the theory.
How long have you been running the ingestion job to Iceberg? When did you start to see the problem since the beginning of the job? How often do you checkpoint/commit?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-896121910
@ayush-san, the problem is that expiring snapshots dropped snapshots that were needed to reconstruct the history of your table between the last checkpoint and the current state. Because Flink can't determine what changed between those two, it throws an error. There isn't anything wrong with the table or the snapshot expiration, it is just that you expired snapshots that you ended up needing to use.
To avoid the problem, I recommend keeping snapshots around for a longer period of time so that you don't expire snapshots that haven't been processed by your job yet.
It looks like you'd also benefit from compaction in the streaming job, which we've been discussing elsewhere. There have been a few ideas around this, but the one I like the best is a second set of writers that write larger files across checkpoints once the content has already been committed. When those files get large enough, they swap the small files for a large one.
Getting back to the purpose of this issue, it looks like the problem was probably that there was too much metadata for each table. Regular maintenance is probably the right fix.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-894383649
@ayush-san let's assume if you taskmanager has 1 CPU and 4 GB of memory and you run 10 disjointed pipelines (with parallelism of 1) in the same process, so you have 10 IcebergFileWriter tasks running in the same taskmanager. Each writer can use 128 MB for Parquet row group size. I am sure there will be a few Xs of overhead of 128 MB row group size. so the memory usage can add up.
if you have the heap dump file, try it with Eclipse MAT. the denominator tree is quite useful to drill down the class holding on to the memory. Use the heap dump file generated by `-XX:+HeapDumpOnOutOfMemoryError`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-892464407
@openinx @rdblue can you please help here
I asked this question on [flink user mailing list too](https://lists.apache.org/thread.html/r3f08299bfa2b0408e83b1c425063a1094ad0ee10a5385f32acfa41fc%40%3Cuser.flink.apache.org%3E).
They have suggested that this might be related to Iceberg Flink connector implementation and connector memory configurations
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san edited a comment on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san edited a comment on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-896486746
@rdblue Since the main issue here is that table metadata keeps on increasing in the streaming use case. Will only running `remove_orphan_files` keep the metadata directory in check as per my understanding it will not find any orphans files without expire_snapshot action?
Also, can you help me understand why does flink need to reconstruct the history of the table? Or please point me towards any design doc/ conversation thread that will me help understand flink-iceberg better? Since I have seen that during every checkpoint all tables reads through all metadata Avro files.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-895713796
> How long have you been running the ingestion job to Iceberg? When did you start to see the problem since the beginning of the job?
We are running 5 jobs with 90 somethings tables for about 2 months now and have only started getting GC errors from the last week. We never faced this issue while doing the POC with just 10 tables.
> How often do you checkpoint/commit?
We have a checkpoint at every 10 min
@stevenzwu Since now the consistency issue(https://github.com/apache/iceberg/issues/2308) with rewrite action will be solved in 0.12, I can start running maintenance procedures for the streaming job too
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-908969597
Yes, it's kind of a deadlock for us as without `expireSnapshots` flink job is taking up memory and also checkpoint time is very high. But with `expireSnapshots`, flink is not being able to create the history.
@rdblue I don't think its about the number of snapshots to be expired as `startingSnapshotId` is always set to null so flink tries to get the complete history.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-895242592
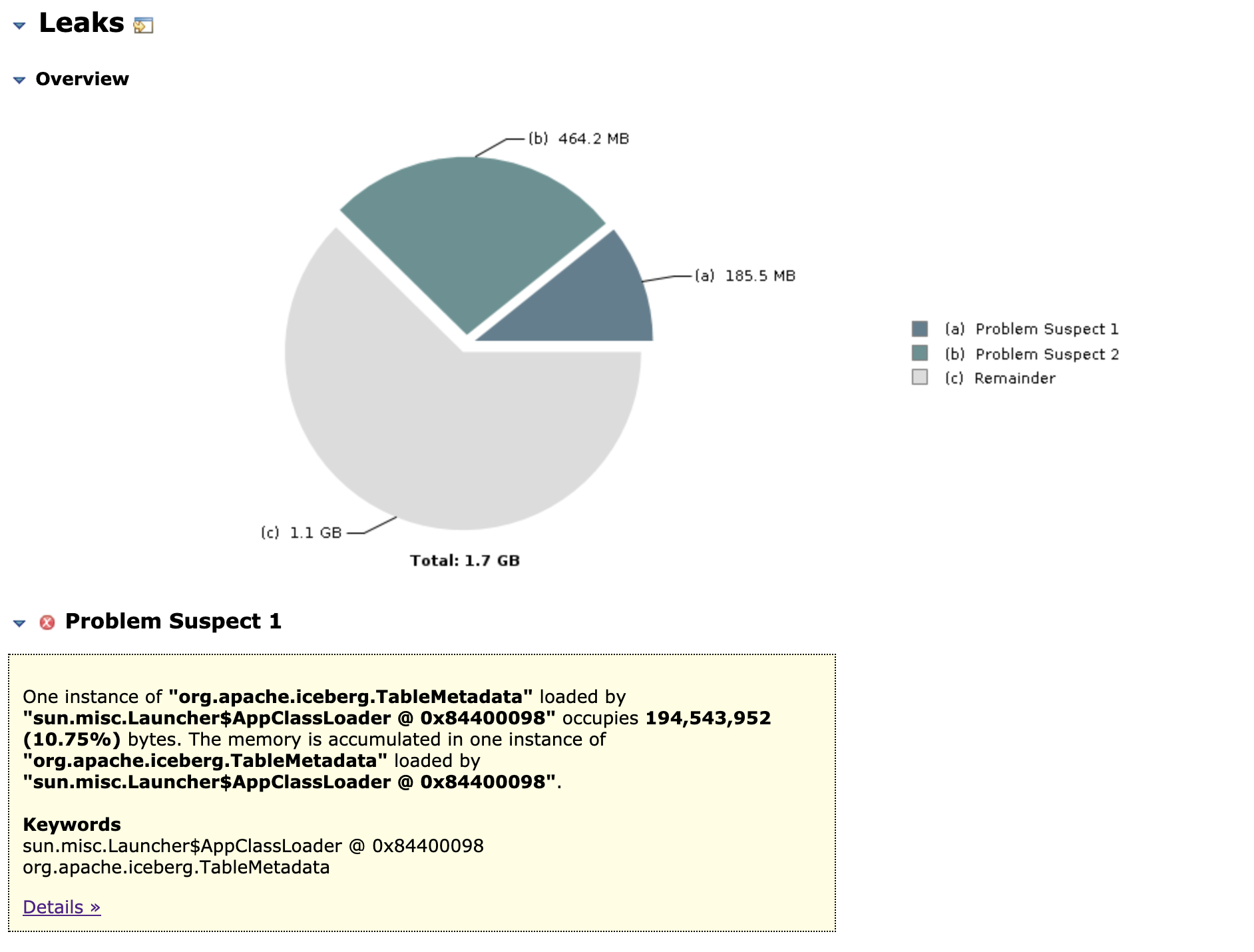
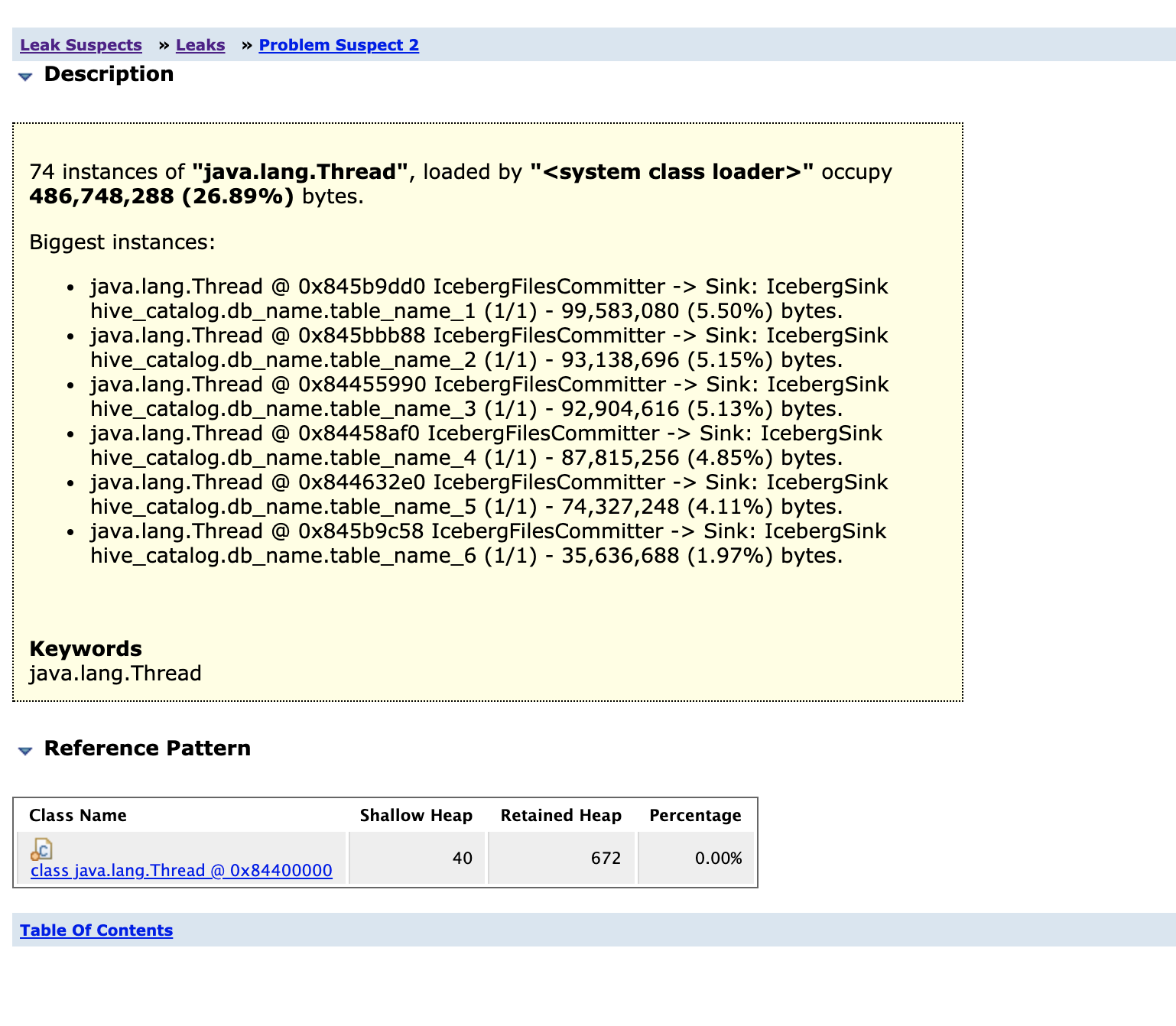
@stevenzwu, I tried my heap dumps with MAT and the denominator tree output points to `org.apache.iceberg.TableMetadata` class
I am attaching the output I generated by using [auto-mat](https://github.com/jfrog/auto-mat)
[Top Consumers.pdf](https://github.com/apache/iceberg/files/6954933/Top.Consumers.pdf)
Also IcebergFilesCommitter and `org.apache.iceberg.TableMetadata` both appear as leak suspects
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-892804416
@ayush-san, is it possible to get a heap dump just after the GC completes or while the job is running steadily? My guess is that the full GC is needed and taking a long time because of an object leak or something. So it the GC needs to traverse a huge set of objects that are all still reachable. A heap dump could really help us know what is happening.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-912453808
But @openinx this shouldn't cause GC right?
Yes after your PR, CDC flink job memory req will go down drastically but can you help me understand why does almost all the time taken by tables during checkpointing is due to opening multiple Avro metadata files?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-894014352
> are tables partitioned by event time or ingestion time? or some other partition spec that can make writers append to multiple files concurrently?
These are unpartitioned tables
> do you run multiple writer tasks/threads in the same core? E.g., assuming your DB has 10 tables, does each slot/core run 10 writers or only 1 writer? If each taskmanager has too many writer tasks, memory consumption by Parquet is going to be a problem.
Currently, all the tables are sharing the same taskmanager and each has its own writer
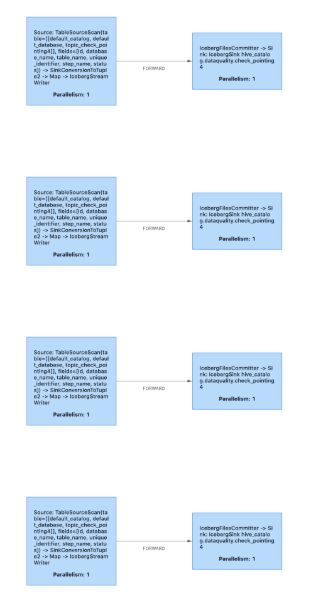
> If each taskmanager has too many writer tasks, memory consumption by Parquet is going to be a problem.
@stevenzwu Can you please give more detail on this issue? Why is this causing the problem?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-892804416
@ayush-san, is it possible to get a heap dump just after the GC completes or while the job is running steadily? My guess is that the full GC is needed and taking a long time because of an object leak or something. So it the GC needs to traverse a huge set of objects that are all still reachable. A heap dump could really help us know what is happening.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-908969597
Yes, it's kind of a deadlock for us as without `expireSnapshots` flink job is taking up memory and also checkpoint time is very high. But with `expireSnapshots`, flink is not being able to create the history.
@rdblue I don't think its about the number of snapshots to be expired as `startingSnapshotId` is always set to null so flink tries to get the complete history.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu edited a comment on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
stevenzwu edited a comment on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-894383649
@ayush-san let's assume if your taskmanager has 1 CPU and 4 GB of memory and you run 10 disjointed pipelines (each with parallelism of 1) in the same process, so you have 10 IcebergFileWriter tasks running in the same taskmanager. Each writer can use 128 MB for Parquet row group size. so the row group memory usage can add up to 1 GB. Actual number probably will be a few Xs of the 1 GB due to other memory overhead with Parquet writer.
if you have the heap dump file, try it with Eclipse MAT. the denominator tree is quite useful to drill down the class holding on to the memory. Use the heap dump file generated by `-XX:+HeapDumpOnOutOfMemoryError`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-895960999
I ran the following maintenance procedure on my streaming table and the metadata size was reduced considerably. Also checkpoint for this table came down to 700ms from earlier 8-9 mins.
```
Actions.forTable(table).rewriteDataFiles().targetSizeInBytes(256 * 1024 * 1024).execute();
spark.sql("CALL hive.system.rewrite_manifests('db_name.table_name')").show()
spark.sql("CALL hive.system.expire_snapshots(table => 'db_name.table_name', older_than => 1628428025000, retain_last => 5)").show()
spark.sql("CALL catalog_name.system.remove_orphan_files(table => 'db_name.table_name')").show()
```
But running expire_snapshots action leads to a bigger issue of flink job not being able to resume from the checkpoint due to this https://github.com/apache/iceberg/issues/2482
Error: `org.apache.iceberg.exceptions.ValidationException: Cannot determine history between starting snapshot null and current 7571686194699158451`
@stevenzwu @rdblue Is there any plan to update expire-snapshot action implementation?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu edited a comment on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
stevenzwu edited a comment on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-893575995
I am not surprised by `org.apache.flink.runtime.taskmanager.Task` as it is the worker thread. So that doesn't really help much here.
I often found denominator tree from Eclipse MAT very useful to understand the memory footprint: https://www.eclipse.org/mat/about/dominator_tree.png
Reading the original description, I have some questions for this setup: "We have combined all the tables of a single DB in one job."
1. are tables partitioned by event time or ingestion time?
2. do you run multiple writer tasks/threads in the same core? E.g., assuming your DB has 10 tables, does each slot/core run 10 writers or only 1 writer? If each taskmanager has too many writer tasks, memory consumption by Parquet is going to be a problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-912041356
@ayush-san, why is `startingSnapshotId` always set to `null`? That should be the last snapshot processed in your streaming job. If you're starting a completely new stream, then it should be the oldest known snapshot.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-896486746
@rdblue Since the main issue here is that table metadata keeps on increasing in the streaming use case. Will only running `remove_orphan_files` keep the metadata directory in check?
Also, can you help me understand why does flink need to reconstruct the history of the table? Or please point me towards any design doc/ conversation thread that will me help understand flink-iceberg better? Since I have seen that during every checkpoint all tables reads through all metadata Avro files.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] openinx commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
openinx commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-912422832
@ayush-san , there is a known memory consumer in the flink CDC write path, I publish a PR here: https://github.com/apache/iceberg/pull/2680, but still don't get the reviewer to get this merged...
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-907871931
The orphan files check shouldn't make a difference here. The only action/operation you need to run is `expireSnapshots` to remove old snapshots that are taking up memory. Orphan files are files that are not referenced by table metadata. Snapshot expiration usually cleans up data files that were logically deleted, so under normal circumstances it should not leak data files for the orphan file cleanup to find.
If I remember correctly, the problem after that was that you removed too many snapshots and could no longer run the downstream job because the snapshots were removed and Iceberg couldn't tell what had been done between the last snapshot that was processed and the oldest snapshot in history.
What's happening here is that we get incremental changes by reading each snapshot and filtering down to manifests and data files that were added in that snapshot. Those files are what Flink processes when reading incremental changes from a table. But if you don't have all of the snapshots since the last time your Flink job ran, then although the data is in the table, Iceberg isn't sure what files it needs to process. That's because files could have been changed or rewritten before the current snapshot.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-895340841
@ayush-san you might have the right hutch regarding " not running maintenance procedures"? You can verify the hypothesis by writing to a new empty table.
How long have you been running the ingestion job to Iceberg? When did you start to see the problem since the beginning of the job? How often do you checkpoint/commit?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-912336270
@rdblue We were stopping the job while performing the maintenance ops(expire snapshot, compaction) due this - https://github.com/apache/iceberg/issues/2308
Since this is fixed in 0.12, I will start using it. Is there any documentation regarding any breaking changes while updating the iceberg runtime jar? Just like what airflow offers - https://github.com/apache/airflow/blob/main/UPDATING.md#airflow-212
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] stevenzwu commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
stevenzwu commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-893575995
I am not surprised by `org.apache.flink.runtime.taskmanager.Task` as it is the worker thread. I often found denominator tree from Eclipse MAT very useful to understand the memory footprint: https://www.eclipse.org/mat/about/dominator_tree.png
Reading the original description, I have some questions for this setup: "We have combined all the tables of a single DB in one job."
1. are tables partitioned by event time or ingestion time?
2. do you run multiple writer tasks/threads in the same core? E.g., assuming your DB has 10 tables, does each slot/core run 10 writers or only 1 writer? If each taskmanager has too many writer tasks, memory consumption by Parquet is going to be a problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
rdblue commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-893532373
Thanks, @ayush-san!
@openinx, @stevenzwu, the main thing that stands out from the memory report is that there are 1.78gb of `org.apache.flink.runtime.taskmanager.Task` objects held by `org.apache.flink.runtime.taskmanager.Task.TASK_THREADS_GROUP`. I'm not very familiar with Flink internals, but that seems like the issue to me. Does that help narrow down what the problem might be?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] ayush-san commented on issue #2900: Flink CDC job getting failed due to G1 old gc and large checkpointing time
Posted by GitBox <gi...@apache.org>.
ayush-san commented on issue #2900:
URL: https://github.com/apache/iceberg/issues/2900#issuecomment-895244837
Also as I was going through the task logs, I can see that almost all the time taken by my tables during checkpointing is due to opening multiple Avro metadata files. Is it due to the fact that I am not running maintenance procedures(compaction/expirying snapshots) on my CDC table or due to s3 thorttling?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org