You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@orc.apache.org by GitBox <gi...@apache.org> on 2022/05/07 12:08:29 UTC
[GitHub] [orc] cxzl25 opened a new pull request, #1108: ORC-1167: Support orc.row.batch.size configuration
cxzl25 opened a new pull request, #1108:
URL: https://github.com/apache/orc/pull/1108
### What changes were proposed in this pull request?
Support `orc.row.batch.size` configuration in `Reader.Options`.
### Why are the changes needed?
Now create `OrcMapreduceRecordReader`, the default value of batch size is 1024.
If we read 1024 relatively large strings, we might get `NegativeArraySizeException`, but no configuration to reduce batch size.
```
java.lang.NegativeArraySizeException
at org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays(TreeReaderFactory.java:1544)
at org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.readOrcByteArrays(TreeReaderFactory.java:1566)
at org.apache.orc.impl.TreeReaderFactory$StringDirectTreeReader.nextVector(TreeReaderFactory.java:1662)
at org.apache.orc.impl.TreeReaderFactory$StringTreeReader.nextVector(TreeReaderFactory.java:1508)
at org.apache.orc.impl.TreeReaderFactory$StructTreeReader.nextBatch(TreeReaderFactory.java:2047)
at org.apache.orc.impl.RecordReaderImpl.nextBatch(RecordReaderImpl.java:1219)
at org.apache.orc.mapreduce.OrcMapreduceRecordReader.ensureBatch(OrcMapreduceRecordReader.java:84)
at org.apache.orc.mapreduce.OrcMapreduceRecordReader.nextKeyValue(OrcMapreduceRecordReader.java:102)
at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:39)
```
### How was this patch tested?
Production environment verification
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869375186
##########
java/core/src/test/org/apache/orc/impl/TestOrcLargeStripe.java:
##########
@@ -214,4 +215,77 @@ public void testStringDirectGreaterThan2GB() throws IOException {
fs.delete(testFilePath, false);
}
}
+
+ @Test
+ public void testRowBatchSizeWhenStringDirectGreaterThan2GB() throws IOException {
+ final Runtime rt = Runtime.getRuntime();
+ assumeTrue(rt.maxMemory() > 4_000_000_000L);
Review Comment:
I'm not sure this test case provides a test coverage in our GitHub Action CI because we have `-Xmx2048m` in our pom file.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869544673
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,10 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
Review Comment:
Do we need to split the two configurations? This way the reader and writer use different batch sizes.
I see the discussion result of [ORC-777](https://issues.apache.org/jira/browse/ORC-777) is not introducing configuration items to confuse users.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r867429255
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,10 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
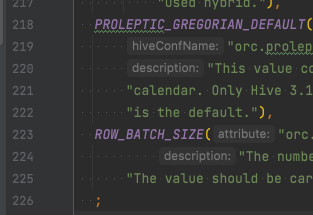
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
+ "The number of rows to include in a orc vectorized reader batch. " +
Review Comment:
IntelliJ IDEA sometimes hinted that I didn't notice it was a few characters indent, I fixed it now, thanks again for your patience.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun closed pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun closed pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
URL: https://github.com/apache/orc/pull/1108
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r867411746
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,11 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
+ "The number of rows to include in a orc vectorized reader batch. " +
+ "The number should be carefully chosen to minimize overhead " +
+ "and avoid OOMs in reading data.")
Review Comment:
The following will be enough. I also change `number` to `value` in the second sentence.
```java
ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
"The number of rows to include in a orc vectorized reader batch. " +
"The value should be carefully chosen to minimize overhead and avoid OOMs in reading data.")
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869520001
##########
java/core/src/java/org/apache/orc/impl/TreeReaderFactory.java:
##########
@@ -1994,7 +1995,18 @@ private static byte[] commonReadByteArrays(InStream stream, IntegerReader length
totalLength = (int) (batchSize * scratchlcv.vector[0]);
}
}
-
+ if (totalLength < 0) {
+ StringBuilder sb = new StringBuilder("totalLength:" + totalLength
+ + " is a negative number.");
+ if (batchSize > 1) {
Review Comment:
It makes sense to add this exception.
Because when the user encounters the `NegativeArraySizeException`, user does not know what to do. The user can only read the source code of the orc to know that the batch size can be adjusted.
I can remove it in this PR first and then raise another jira to add this exception.
I encountered this problem when reading orc datasource in Spark 3.2, because the orc structure is complex, so the default is to use `OrcMapreduceRecordReader` to read.
Then I use config
```
spark.sql.orc.enableNestedColumnVectorizedReader=true
spark.sql.orc.columnarReaderBatchSize=1
```
Temporarily solved the problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869368112
##########
java/core/src/java/org/apache/orc/impl/TreeReaderFactory.java:
##########
@@ -1994,7 +1995,18 @@ private static byte[] commonReadByteArrays(InStream stream, IntegerReader length
totalLength = (int) (batchSize * scratchlcv.vector[0]);
}
}
-
+ if (totalLength < 0) {
+ StringBuilder sb = new StringBuilder("totalLength:" + totalLength
+ + " is a negative number.");
+ if (batchSize > 1) {
Review Comment:
This PR seems to be mixing three things.
First, when `totalLength < 0` happens, do we need to throw a new exception from ORC side?
Second, in the above case, when `batchSize == 1` additionally, this PR is adding a new exception here. Logically, the following.
```java
if (totalLength < 0 && batchSize == 1) {
throw new IOException("totalLength:" + totalLength + " is a negative number."
}
```
- If this is a meaningful error, can we proceed that in a separate PR because we may want to backport that.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r875924127
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,10 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
Review Comment:
How about the `orc.read.row.batch.size` configuration item in this PR?
Then I raise another PR about `NegativeArraySizeException`.
If the writer needs to support configuration in the future, I will raise another PR and configure it with `orc.write.row.batch.size`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869529451
##########
java/core/src/test/org/apache/orc/impl/TestOrcLargeStripe.java:
##########
@@ -214,4 +215,77 @@ public void testStringDirectGreaterThan2GB() throws IOException {
fs.delete(testFilePath, false);
}
}
+
+ @Test
+ public void testRowBatchSizeWhenStringDirectGreaterThan2GB() throws IOException {
+ final Runtime rt = Runtime.getRuntime();
+ assumeTrue(rt.maxMemory() > 4_000_000_000L);
Review Comment:
Currently this UT needs a large memory to execute successfully, similar to `org.apache.orc.impl.TestOrcLargeStripe#testStringDirectGreaterThan2GB`.
At present, I modified the `-Xmx2048m` test of `maven-surefire-plugin` locally to verify.
Is it possible to increase the 2048m to say 4g or 5g?
I see github runner supports 7g ram.
https://docs.github.com/cn/actions/using-github-hosted-runners/about-github-hosted-runners#supported-runners-and-hardware-resources
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869641689
##########
java/core/src/java/org/apache/orc/impl/TreeReaderFactory.java:
##########
@@ -1994,7 +1995,18 @@ private static byte[] commonReadByteArrays(InStream stream, IntegerReader length
totalLength = (int) (batchSize * scratchlcv.vector[0]);
}
}
-
+ if (totalLength < 0) {
+ StringBuilder sb = new StringBuilder("totalLength:" + totalLength
+ + " is a negative number.");
+ if (batchSize > 1) {
Review Comment:
Yes, I agree with you that the directional error message will be helpful.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r867428891
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,11 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
+ "The number of rows to include in a orc vectorized reader batch. " +
+ "The number should be carefully chosen to minimize overhead " +
+ "and avoid OOMs in reading data.")
Review Comment:
Sorry I didn't notice the indentation issue here, I was breaking lines because it was over 100 characters. After changing the indentation, it is now 98 characters, thanks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869369840
##########
java/core/src/test/org/apache/orc/impl/TestOrcLargeStripe.java:
##########
@@ -214,4 +215,77 @@ public void testStringDirectGreaterThan2GB() throws IOException {
fs.delete(testFilePath, false);
}
}
+
+ @Test
+ public void testRowBatchSizeWhenStringDirectGreaterThan2GB() throws IOException {
Review Comment:
Thank you for adding this test coverage. Can we revise the title? `StringDirect` looks a little confusing.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r875924127
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,10 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
Review Comment:
How about the �orc.read.row.batch.size` configuration item in this PR?
Then I raise another PR about `NegativeArraySizeException`.
If the writer needs to support configuration in the future, I will raise another PR and configure it with `orc.write.row.batch.size`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r871535151
##########
java/core/src/test/org/apache/orc/impl/TestOrcLargeStripe.java:
##########
@@ -214,4 +215,77 @@ public void testStringDirectGreaterThan2GB() throws IOException {
fs.delete(testFilePath, false);
}
}
+
+ @Test
+ public void testRowBatchSizeWhenStringDirectGreaterThan2GB() throws IOException {
+ final Runtime rt = Runtime.getRuntime();
+ assumeTrue(rt.maxMemory() > 4_000_000_000L);
Review Comment:
Make sense.
Now the trigger condition is that a relatively large string object is required. I tried the size as much as possible in this test case, but 2g is still not enough.
I now use the mock method to test this exception.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869358165
##########
java/core/src/java/org/apache/orc/impl/TreeReaderFactory.java:
##########
@@ -1994,7 +1995,18 @@ private static byte[] commonReadByteArrays(InStream stream, IntegerReader length
totalLength = (int) (batchSize * scratchlcv.vector[0]);
}
}
-
+ if (totalLength < 0) {
+ StringBuilder sb = new StringBuilder("totalLength:" + totalLength
+ + " is a negative number.");
+ if (batchSize > 1) {
+ sb.append(" The current batch size is ")
+ .append(batchSize)
+ .append(", you can reduce the value by '")
+ .append(OrcConf.ROW_BATCH_SIZE.getAttribute())
+ .append("'.");
Review Comment:
Instead of this chaining, the following will be better in the readability.
```java
sb.append(" The current batch size is ")
sb.append(batchSize)
sb.append(", you can reduce the value by '")
sb.append(OrcConf.ROW_BATCH_SIZE.getAttribute())
sb.append("'.");
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869643704
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,10 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
Review Comment:
cc @pgaref
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r867428606
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,11 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
+ "The number of rows to include in a orc vectorized reader batch. " +
+ "The number should be carefully chosen to minimize overhead " +
+ "and avoid OOMs in reading data.")
Review Comment:
@cxzl25 . Here I changed your indentation too. I understand the indentation is heterogenous in this file, but please follow my example.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] cxzl25 commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
cxzl25 commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r867428472
##########
java/core/src/java/org/apache/orc/impl/TreeReaderFactory.java:
##########
@@ -1994,7 +1994,16 @@ private static byte[] commonReadByteArrays(InStream stream, IntegerReader length
totalLength = (int) (batchSize * scratchlcv.vector[0]);
}
}
-
+ if (totalLength < 0) {
+ StringBuilder sb = new StringBuilder("totalLength:" + totalLength
+ + " is a negative number.");
+ if (batchSize > 1) {
+ sb.append(" The current batch size is ")
+ .append(batchSize)
+ .append(", you can reduce the value by 'orc.row.batch.size'.");
+ }
+ throw new IOException(sb.toString());
Review Comment:
Thanks for such a quick review, I added some UT. @dongjoon-hyun
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r867429018
##########
java/core/src/java/org/apache/orc/OrcConf.java:
##########
@@ -219,7 +219,10 @@ public enum OrcConf {
"orc.proleptic.gregorian.default", false,
"This value controls whether pre-ORC 27 files are using the hybrid or proleptic\n" +
"calendar. Only Hive 3.1 and the C++ library wrote using the proleptic, so hybrid\n" +
- "is the default.")
+ "is the default."),
+ ROW_BATCH_SIZE("orc.row.batch.size", "orc.row.batch.size", 1024,
+ "The number of rows to include in a orc vectorized reader batch. " +
Review Comment:
My example included this line too.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r867411894
##########
java/core/src/java/org/apache/orc/impl/TreeReaderFactory.java:
##########
@@ -1994,7 +1994,16 @@ private static byte[] commonReadByteArrays(InStream stream, IntegerReader length
totalLength = (int) (batchSize * scratchlcv.vector[0]);
}
}
-
+ if (totalLength < 0) {
+ StringBuilder sb = new StringBuilder("totalLength:" + totalLength
+ + " is a negative number.");
+ if (batchSize > 1) {
+ sb.append(" The current batch size is ")
+ .append(batchSize)
+ .append(", you can reduce the value by 'orc.row.batch.size'.");
+ }
+ throw new IOException(sb.toString());
Review Comment:
We need a test coverage for this new code path, @cxzl25 .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [orc] dongjoon-hyun commented on a diff in pull request #1108: ORC-1167: Support `orc.row.batch.size` configuration
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on code in PR #1108:
URL: https://github.com/apache/orc/pull/1108#discussion_r869643074
##########
java/core/src/test/org/apache/orc/impl/TestOrcLargeStripe.java:
##########
@@ -214,4 +215,77 @@ public void testStringDirectGreaterThan2GB() throws IOException {
fs.delete(testFilePath, false);
}
}
+
+ @Test
+ public void testRowBatchSizeWhenStringDirectGreaterThan2GB() throws IOException {
+ final Runtime rt = Runtime.getRuntime();
+ assumeTrue(rt.maxMemory() > 4_000_000_000L);
Review Comment:
No, increasing the memory requirements is harmful because we will miss the memory leakage issues in the future development. That's the point why we requires `2g` in our tests. Can you revise the test case instead?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@orc.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org