You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2020/04/06 20:21:46 UTC
[GitHub] [incubator-hudi] tverdokhlebd opened a new issue #1491: [SUPPORT]
OutOfMemoryError during upsert 30M records
tverdokhlebd opened a new issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491
Hello. I have config:
--
docker run --rm -v /var/lib/jenkins-slave/workspace/Transfer_ml_data_to_s3_hudi:/var/lib/jenkins-slave/workspace/Transfer_ml_data_to_s3_hudi
-v /mnt/ml_data:/mnt/ml_data bde2020/spark-master:2.4.5-hadoop2.7
bash ./spark/bin/spark-submit
--master 'local[2]'
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.hadoop:hadoop-aws:2.7.3,org.apache.spark:spark-avro_2.11:2.4.4
--conf spark.local.dir=/mnt/ml_data
--conf spark.ui.enabled=false
--conf spark.driver.memory=4g
--conf spark.driver.memoryOverhead=1024
--conf spark.driver.maxResultSize=2g
--conf spark.kryoserializer.buffer.max=512m
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
--conf spark.rdd.compress=true
--conf spark.shuffle.service.enabled=true
--conf spark.sql.hive.convertMetastoreParquet=false
--conf spark.executorEnv.hudi.outputPath=s3a://ir-mtu-ml-bucket/ml_hudi
--conf spark.executorEnv.hudi.tableName=ext_ml_data
--conf spark.executorEnv.hudi.recordKey=tds_cid
--conf spark.executorEnv.hudi.precombineKey=hit_timestamp
--conf spark.executorEnv.hudi.parallelism=8
--conf spark.executorEnv.hudi.bulkInsertParallelism=8
--class mtu.spark.analytics.ExtMLDataToS3
--
I do:
1. Bulk insert from Vertica to s3 storage with 30M records;
2. Upsert from Vertica to the same s3 storage with the same 30M records;
I received various errors during three tries:
- java.util.concurrent.TimeoutException: Cannot receive any reply from c3dcd5b0c2ab:41498 in 10000 milliseconds
- java.lang.OutOfMemoryError: Java heap space
- The java.lang.OutOfMemoryError: GC overhead limit exceeded error
I have read "Tunning guide" and tried to tune some technics - memory fractions (Decreased from default values), off-heap parameters, collector, parallelism and etc. I also increased driver memory from 4GB to 10GB, but it also does not help me.
Stack trace with heap space https://drive.google.com/open?id=1-Kerkt2j-z_0zXal01rha55j1NzsxYto
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611069603
hi @vinothchandar @bvaradar I think we can analyze this issue in parallel, reproduce steps:
1. Download CSV data with 5M records
```
https://drive.google.com/open?id=1uwJ68_RrKMUTbEtsGl56_P5b_mNX3k2S
```
2. Run demo command
```
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
import org.apache.spark.sql.functions._
val tableName = "hudi_mor_table"
val basePath = "file:///tmp/hudi_mor_table"
var inputDF = spark.read.format("csv").option("header", "true").load("file:///work/hudi-debug/2.csv")
val hudiOptions = Map[String,String](
"hoodie.insert.shuffle.parallelism" -> "10",
"hoodie.upsert.shuffle.parallelism" -> "10",
"hoodie.delete.shuffle.parallelism" -> "10",
"hoodie.bulkinsert.shuffle.parallelism" -> "10",
"hoodie.datasource.write.recordkey.field" -> "tds_cid",
"hoodie.datasource.write.partitionpath.field" -> "hit_date",
"hoodie.table.name" -> tableName,
"hoodie.datasource.write.precombine.field" -> "hit_timestamp",
"hoodie.datasource.write.operation" -> "upsert"
)
inputDF.write.format("org.apache.hudi").
options(hudiOptions).
mode("Overwrite").
save(basePath)
spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610564674
Code:
sparkSession
.read
.jdbc(
url = jdbcConfig.url,
table = table,
columnName = "partition",
lowerBound = 0,
upperBound = jdbcConfig.partitionsCount.toInt,
numPartitions = jdbcConfig.partitionsCount.toInt,
connectionProperties = new Properties() {
put("driver", jdbcConfig.driver)
put("user", jdbcConfig.user)
put("password", jdbcConfig.password)
}
)
.withColumn("year", substring(col(jdbcConfig.dateColumnName), 0, 4))
.withColumn("month", substring(col(jdbcConfig.dateColumnName), 6, 2))
.withColumn("day", substring(col(jdbcConfig.dateColumnName), 9, 2))
.write
.option(HoodieWriteConfig.TABLE_NAME, hudiConfig.tableName)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, hudiConfig.recordKey)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, hudiConfig.precombineKey)
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, hudiConfig.partitionPathKey)
.option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY, classOf[ComplexKeyGenerator].getName)
.option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
.option("hoodie.datasource.write.operation", writeOperation)
.option("hoodie.bulkinsert.shuffle.parallelism", hudiConfig.bulkInsertParallelism)
.option("hoodie.insert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.upsert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.cleaner.policy", HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name())
.option("hoodie.cleaner.fileversions.retained", "1")
.option("hoodie.metrics.graphite.host", hudiConfig.graphiteHost)
.option("hoodie.metrics.graphite.port", hudiConfig.graphitePort)
.option("hoodie.metrics.graphite.metric.prefix", hudiConfig.graphiteMetricPrefix)
.format("org.apache.hudi")
.mode(SaveMode.Append)
.save(outputPath)
This code is executing on Jenkins, with next parameters:
docker run --rm -v ${PWD}:${PWD} -v /mnt/ml_data:/mnt/ml_data bde2020/spark-master:2.4.5-hadoop2.7 \
bash ./spark/bin/spark-submit \
--master "local[2]" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.hadoop:hadoop-aws:2.7.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf spark.local.dir=/mnt/ml_data \
--conf spark.ui.enabled=false \
--conf spark.driver.memory=4g \
--conf spark.driver.memoryOverhead=1024 \
--conf spark.driver.maxResultSize=2g \
--conf spark.kryoserializer.buffer.max=512m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.rdd.compress=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.hadoop.fs.defaultFS=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.access.key=${AWS_ACCESS_KEY_ID} \
--conf spark.hadoop.fs.s3a.secret.key=${AWS_SECRET_ACCESS_KEY} \
--conf spark.executorEnv.period.startDate=${date} \
--conf spark.executorEnv.period.numDays=${numDays} \
--conf spark.executorEnv.jdbc.url=${VERTICA_URL} \
--conf spark.executorEnv.jdbc.user=${VERTICA_USER} \
--conf spark.executorEnv.jdbc.password=${VERTICA_PWD} \
--conf spark.executorEnv.jdbc.driver=${VERTICA_DRIVER}\
--conf spark.executorEnv.jdbc.schemaName=mtu_owner \
--conf spark.executorEnv.jdbc.tableName=ext_ml_data \
--conf spark.executorEnv.jdbc.dateColumnName=hit_date \
--conf spark.executorEnv.jdbc.partitionColumnName=hit_timestamp \
--conf spark.executorEnv.jdbc.partitionsCount=8 \
--conf spark.executorEnv.hudi.outputPath=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.executorEnv.hudi.tableName=ext_ml_data \
--conf spark.executorEnv.hudi.recordKey=tds_cid \
--conf spark.executorEnv.hudi.precombineKey=hit_timestamp \
--conf spark.executorEnv.hudi.parallelism=8 \
--conf spark.executorEnv.hudi.bulkInsertParallelism=8 \
--class mtu.spark.analytics.ExtMLDataToS3 \
${PWD}/ml-vertica-to-s3-hudi.jar
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611161092
1. use the same CSV dataset, bulk_insert, then upsert.
2. no, other params keep default
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610899494
@tverdokhlebd, thanks for your feedback, will try to reproduce it follow your steps.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] bvaradar commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1491:
URL: https://github.com/apache/hudi/issues/1491#issuecomment-675432638
@lamber-ken : Would you be able to handle https://issues.apache.org/jira/browse/HUDI-818 that is assigned to you ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
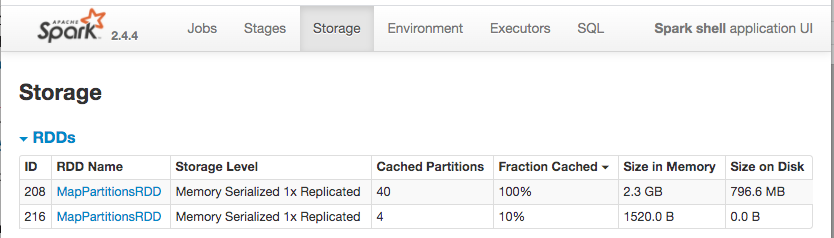
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611092165
Something cached in memory
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-615473505
Hi @tverdokhlebd, glad to hear that your problem has been solved.
> Upsert was hanging without this parameter
When do upsert operation, hudi need to buffer input records in memory, the size of the buffer is controlled by the option `hoodie.memory.merge.max.size`. if the value of that option is small, hudi will spill contents to disk, in that case, the upsert performance will decline.
> without "hoodie.memory.merge.max.size" parameter and got error (heap size).
BTW, I can't understand why without that parameter, will get error(heap size), have you encountered a similar situation before? @vinothchandar
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610980530
> upsert (use the same CSV dataset) ?
Yes, use the same CSV dataset.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-615141491
Hi @lamber-ken
Yes, I have resolved this problem.
Firstly, the problem was in SBT memory that allocated default memory size 1GB. Then, I fixed it and set 8GB and transferring 5M records successfully finished in my local environment.
Next, I have tried to transfer 30M records, but upsert failed again. I tunned *.parallelism parameters (Changed from 8 to 100) and everything went fine (20MB for each parquet file).
Also, I added parameter "hoodie.memory.merge.max.size" with value "2004857600000" that you had recommended. Upsert was hanging without this parameter (It is necessary to recheck again).
@lamber-ken, can you explain to me, what the parameter is?
UPD:
Rechecked without "hoodie.memory.merge.max.size" parameter and got error (heap size).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610564674
Code:
sparkSession
.read
.jdbc(
url = jdbcConfig.url,
table = table,
columnName = "partition",
lowerBound = 0,
upperBound = jdbcConfig.partitionsCount.toInt,
numPartitions = jdbcConfig.partitionsCount.toInt,
connectionProperties = new Properties() {
put("driver", jdbcConfig.driver)
put("user", jdbcConfig.user)
put("password", jdbcConfig.password)
}
)
.withColumn("year", substring(col(jdbcConfig.dateColumnName), 0, 4))
.withColumn("month", substring(col(jdbcConfig.dateColumnName), 6, 2))
.withColumn("day", substring(col(jdbcConfig.dateColumnName), 9, 2))
.write
.option(HoodieWriteConfig.TABLE_NAME, hudiConfig.tableName)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, hudiConfig.recordKey)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, hudiConfig.precombineKey)
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, hudiConfig.partitionPathKey)
.option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY, classOf[ComplexKeyGenerator].getName)
.option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
.option("hoodie.datasource.write.operation", writeOperation)
.option("hoodie.bulkinsert.shuffle.parallelism", hudiConfig.bulkInsertParallelism)
.option("hoodie.insert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.upsert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.cleaner.policy", HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name())
.option("hoodie.cleaner.fileversions.retained", "1")
.option("hoodie.metrics.graphite.host", hudiConfig.graphiteHost)
.option("hoodie.metrics.graphite.port", hudiConfig.graphitePort)
.option("hoodie.metrics.graphite.metric.prefix", hudiConfig.graphiteMetricPrefix)
.format("org.apache.hudi")
.mode(SaveMode.Append)
.save(outputPath)
This code is executing on Jenkins, with next parameters:
docker run --rm -v ${PWD}:${PWD} -v /mnt/ml_data:/mnt/ml_data bde2020/spark-master:2.4.5-hadoop2.7 \
bash ./spark/bin/spark-submit \
--master "local[2]" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.hadoop:hadoop-aws:2.7.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf spark.local.dir=/mnt/ml_data \
--conf spark.ui.enabled=false \
--conf spark.driver.memory=4g \
--conf spark.driver.memoryOverhead=1024 \
--conf spark.driver.maxResultSize=2g \
--conf spark.kryoserializer.buffer.max=512m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.rdd.compress=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.hadoop.fs.defaultFS=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.access.key=${AWS_ACCESS_KEY_ID} \
--conf spark.hadoop.fs.s3a.secret.key=${AWS_SECRET_ACCESS_KEY} \
--conf spark.executorEnv.period.startDate=${date} \
--conf spark.executorEnv.period.numDays=${numDays} \
--conf spark.executorEnv.jdbc.url=${VERTICA_URL} \
--conf spark.executorEnv.jdbc.user=${VERTICA_USER} \
--conf spark.executorEnv.jdbc.password=${VERTICA_PWD} \
--conf spark.executorEnv.jdbc.driver=${VERTICA_DRIVER}\
--conf spark.executorEnv.jdbc.schemaName=mtu_owner \
--conf spark.executorEnv.jdbc.tableName=ext_ml_data \
--conf spark.executorEnv.jdbc.dateColumnName=hit_date \
--conf spark.executorEnv.jdbc.partitionColumnName=hit_timestamp \
--conf spark.executorEnv.jdbc.partitionsCount=8 \
--conf spark.executorEnv.hudi.outputPath=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.executorEnv.hudi.tableName=ext_ml_data \
--conf spark.executorEnv.hudi.recordKey=tds_cid \
--conf spark.executorEnv.hudi.precombineKey=hit_timestamp \
--conf spark.executorEnv.hudi.parallelism=8 \
--conf spark.executorEnv.hudi.bulkInsertParallelism=8 \
--class mtu.spark.analytics.ExtMLDataToS3 \
${PWD}/ml-vertica-to-s3-hudi.jar
I try to move 53 million records (The table contains 48 columns) from the Vertica database to s3 storage.
Operation "bulk_insert" successfully completes and take about 40-50 minutes.
Operation "upsert" on the same records throws exceptions with OOM.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611164201
> @lamber-ken , can you try with those params?
No proplem, will reply to you in a few hours, need to deal with other things : )
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611626685
I run those operations with `local[2]` and 6GB driver memory, still worked fine.
I run those operations on local env not in docker env. Can you run those operations in linux env?
```
dcadmin-imac:flink-1.6.3.sdk dcadmin$ ${SPARK_HOME}/bin/spark-shell --master 'local[2]' --driver-memory 6G --packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
Ivy Default Cache set to: /Users/dcadmin/.ivy2/cache
The jars for the packages stored in: /Users/dcadmin/.ivy2/jars
:: loading settings :: url = jar:file:/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
org.apache.hudi#hudi-spark-bundle_2.11 added as a dependency
org.apache.spark#spark-avro_2.11 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-e1b9ce1d-8bb9-4da6-a29f-c5287bfad216;1.0
confs: [default]
found org.apache.hudi#hudi-spark-bundle_2.11;0.5.1-incubating in central
found org.apache.spark#spark-avro_2.11;2.4.4 in central
found org.spark-project.spark#unused;1.0.0 in spark-list
:: resolution report :: resolve 226ms :: artifacts dl 5ms
:: modules in use:
org.apache.hudi#hudi-spark-bundle_2.11;0.5.1-incubating from central in [default]
org.apache.spark#spark-avro_2.11;2.4.4 from central in [default]
org.spark-project.spark#unused;1.0.0 from spark-list in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 3 | 0 | 0 | 0 || 3 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-e1b9ce1d-8bb9-4da6-a29f-c5287bfad216
confs: [default]
0 artifacts copied, 3 already retrieved (0kB/5ms)
20/04/09 23:59:12 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
20/04/09 23:59:18 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://10.101.52.18:4041
Spark context available as 'sc' (master = local[2], app id = local-1586447958208).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_211)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._
scala>
scala> val tableName = "hudi_mor_table"
tableName: String = hudi_mor_table
scala> val basePath = "file:///tmp/hudi_mor_table"
basePath: String = file:///tmp/hudi_mor_table
scala>
scala> var inputDF = spark.read.format("csv").option("header", "true").load("file:///work/hudi-debug/2.csv")
inputDF: org.apache.spark.sql.DataFrame = [tds_cid: string, hit_timestamp: string ... 46 more fields]
scala>
scala> val hudiOptions = Map[String,String](
| "hoodie.insert.shuffle.parallelism" -> "10",
| "hoodie.upsert.shuffle.parallelism" -> "10",
| "hoodie.delete.shuffle.parallelism" -> "10",
| "hoodie.bulkinsert.shuffle.parallelism" -> "10",
| "hoodie.datasource.write.recordkey.field" -> "tds_cid",
| "hoodie.datasource.write.partitionpath.field" -> "hit_date",
| "hoodie.table.name" -> tableName,
| "hoodie.datasource.write.precombine.field" -> "hit_timestamp",
| "hoodie.datasource.write.operation" -> "upsert",
| "hoodie.memory.merge.max.size" -> "2004857600000",
| "hoodie.cleaner.policy" -> "KEEP_LATEST_FILE_VERSIONS",
| "hoodie.cleaner.fileversions.retained" -> "1"
| )
hudiOptions: scala.collection.immutable.Map[String,String] = Map(hoodie.insert.shuffle.parallelism -> 10, hoodie.datasource.write.precombine.field -> hit_timestamp, hoodie.cleaner.fileversions.retained -> 1, hoodie.delete.shuffle.parallelism -> 10, hoodie.datasource.write.operation -> upsert, hoodie.datasource.write.recordkey.field -> tds_cid, hoodie.table.name -> hudi_mor_table, hoodie.memory.merge.max.size -> 2004857600000, hoodie.cleaner.policy -> KEEP_LATEST_FILE_VERSIONS, hoodie.upsert.shuffle.parallelism -> 10, hoodie.datasource.write.partitionpath.field -> hit_date, hoodie.bulkinsert.shuffle.parallelism -> 10)
scala>
scala> inputDF.write.format("org.apache.hudi").
| options(hudiOptions).
| mode("Append").
| save(basePath)
20/04/10 00:01:07 WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf.
[Stage 3:==================================> (6 + 2) / 10]20/04/10 00:02:58 WARN MemoryStore: Not enough space to cache rdd_16_6 in memory! (computed 58.5 MB so far)
20/04/10 00:02:58 WARN BlockManager: Persisting block rdd_16_6 to disk instead.
20/04/10 00:02:58 WARN MemoryStore: Not enough space to cache rdd_16_7 in memory! (computed 58.1 MB so far)
20/04/10 00:02:58 WARN BlockManager: Persisting block rdd_16_7 to disk instead.
[Stage 3:==============================================> (8 + 2) / 10]20/04/10 00:03:12 WARN MemoryStore: Not enough space to cache rdd_16_8 in memory! (computed 17.3 MB so far)
20/04/10 00:03:12 WARN BlockManager: Persisting block rdd_16_8 to disk instead.
20/04/10 00:03:12 WARN MemoryStore: Not enough space to cache rdd_16_9 in memory! (computed 131.4 MB so far)
20/04/10 00:03:12 WARN BlockManager: Persisting block rdd_16_9 to disk instead.
[Stage 14:============================================> (32 + 2) / 40]20/04/10 00:30:38 WARN MemoryStore: Not enough space to cache rdd_44_32 in memory! (computed 58.3 MB so far)
20/04/10 00:30:38 WARN BlockManager: Persisting block rdd_44_32 to disk instead.
20/04/10 00:30:38 WARN MemoryStore: Not enough space to cache rdd_44_33 in memory! (computed 58.2 MB so far)
20/04/10 00:30:38 WARN BlockManager: Persisting block rdd_44_33 to disk instead.
[Stage 14:=================================================> (35 + 2) / 40]20/04/10 00:30:42 WARN MemoryStore: Not enough space to cache rdd_44_35 in memory! (computed 11.6 MB so far)
20/04/10 00:30:42 WARN BlockManager: Persisting block rdd_44_35 to disk instead.
20/04/10 00:30:43 WARN MemoryStore: Not enough space to cache rdd_44_36 in memory! (computed 11.6 MB so far)
20/04/10 00:30:43 WARN BlockManager: Persisting block rdd_44_36 to disk instead.
[Stage 14:=====================================================> (38 + 2) / 40]20/04/10 00:30:51 WARN MemoryStore: Not enough space to cache rdd_44_38 in memory! (computed 58.8 MB so far)
20/04/10 00:30:51 WARN BlockManager: Persisting block rdd_44_38 to disk instead.
20/04/10 00:30:51 WARN MemoryStore: Not enough space to cache rdd_44_39 in memory! (computed 11.4 MB so far)
20/04/10 00:30:51 WARN BlockManager: Persisting block rdd_44_39 to disk instead.
20/04/10 00:33:53 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
scala> spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
20/04/10 00:34:10 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
res1: Long = 5087127
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610221356
Tried to set this config:
- local[4]
- driver memory 12GB
- driver memoryOverhead 2048
And result:
20/04/07 07:05:38 INFO ExternalAppendOnlyMap: Thread 132 spilling in-memory map of 1598.4 MB to disk (1 time so far)
20/04/07 07:05:39 INFO ExternalAppendOnlyMap: Thread 130 spilling in-memory map of 1598.4 MB to disk (1 time so far)
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000658800000, 1736441856, 0) failed; error='Out of memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 1736441856 bytes for committing reserved memory.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-615473505
Hi @tverdokhlebd, glad to hear that your problem has been solved.
> Upsert was hanging without this parameter
When do upsert operation, hudi need to buffer input records in memory, controls the size of the buffer is controlled by the option `hoodie.memory.merge.max.size`. if the value of that option is small, hudi will spill contents to disk, in that case, the upsert performance will decline.
> without "hoodie.memory.merge.max.size" parameter and got error (heap size).
BTW, I can't understand why without that parameter, will get error(heap size), have you encountered a similar situation before? @vinothchandar
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610899494
@tverdokhlebd, thanks for your feedback, will try to reproduce it follow your steps.
1. bulk_insert the CSV dataset
2. upsert (use the same CSV dataset) ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610564674
Code:
sparkSession
.read
.jdbc(
url = jdbcConfig.url,
table = table,
columnName = "partition",
lowerBound = 0,
upperBound = jdbcConfig.partitionsCount.toInt,
numPartitions = jdbcConfig.partitionsCount.toInt,
connectionProperties = new Properties() {
put("driver", jdbcConfig.driver)
put("user", jdbcConfig.user)
put("password", jdbcConfig.password)
}
)
.withColumn("year", substring(col(jdbcConfig.dateColumnName), 0, 4))
.withColumn("month", substring(col(jdbcConfig.dateColumnName), 6, 2))
.withColumn("day", substring(col(jdbcConfig.dateColumnName), 9, 2))
.write
.option(HoodieWriteConfig.TABLE_NAME, hudiConfig.tableName)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, hudiConfig.recordKey)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, hudiConfig.precombineKey)
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, hudiConfig.partitionPathKey)
.option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY, classOf[ComplexKeyGenerator].getName)
.option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
.option("hoodie.datasource.write.operation", writeOperation)
.option("hoodie.bulkinsert.shuffle.parallelism", hudiConfig.bulkInsertParallelism)
.option("hoodie.insert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.upsert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.cleaner.policy", HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name())
.option("hoodie.cleaner.fileversions.retained", "1")
.option("hoodie.metrics.graphite.host", hudiConfig.graphiteHost)
.option("hoodie.metrics.graphite.port", hudiConfig.graphitePort)
.option("hoodie.metrics.graphite.metric.prefix", hudiConfig.graphiteMetricPrefix)
.format("org.apache.hudi")
.mode(SaveMode.Append)
.save(outputPath)
This code is executing on Jenkins, with next parameters:
docker run --rm -v ${PWD}:${PWD} -v /mnt/ml_data:/mnt/ml_data bde2020/spark-master:2.4.5-hadoop2.7 \
bash ./spark/bin/spark-submit \
--master "local[2]" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.hadoop:hadoop-aws:2.7.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf spark.local.dir=/mnt/ml_data \
--conf spark.ui.enabled=false \
--conf spark.driver.memory=4g \
--conf spark.driver.memoryOverhead=1024 \
--conf spark.driver.maxResultSize=2g \
--conf spark.kryoserializer.buffer.max=512m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.rdd.compress=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.hadoop.fs.defaultFS=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.access.key=${AWS_ACCESS_KEY_ID} \
--conf spark.hadoop.fs.s3a.secret.key=${AWS_SECRET_ACCESS_KEY} \
--conf spark.executorEnv.period.startDate=${date} \
--conf spark.executorEnv.period.numDays=${numDays} \
--conf spark.executorEnv.jdbc.url=${VERTICA_URL} \
--conf spark.executorEnv.jdbc.user=${VERTICA_USER} \
--conf spark.executorEnv.jdbc.password=${VERTICA_PWD} \
--conf spark.executorEnv.jdbc.driver=${VERTICA_DRIVER}\
--conf spark.executorEnv.jdbc.schemaName=mtu_owner \
--conf spark.executorEnv.jdbc.tableName=ext_ml_data \
--conf spark.executorEnv.jdbc.dateColumnName=hit_date \
--conf spark.executorEnv.jdbc.partitionColumnName=hit_timestamp \
--conf spark.executorEnv.jdbc.partitionsCount=8 \
--conf spark.executorEnv.hudi.outputPath=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.executorEnv.hudi.tableName=ext_ml_data \
--conf spark.executorEnv.hudi.recordKey=tds_cid \
--conf spark.executorEnv.hudi.precombineKey=hit_timestamp \
--conf spark.executorEnv.hudi.parallelism=8 \
--conf spark.executorEnv.hudi.bulkInsertParallelism=8 \
--class mtu.spark.analytics.ExtMLDataToS3 \
${PWD}/ml-vertica-to-s3-hudi.jar
I try to move 53 million records (The table contains 48 columns) from the Vertica database to s3 storage.
Operation "bulk_insert" successfully completes and takes ~40-50 minutes.
Operation "upsert" on the same records throws exceptions with OOM.
On Hudi 0.5.1 "upsert" operations were hanging. I found the issue https://github.com/apache/incubator-hudi/issues/1328 and updated Hudi to 0.5.2. The problem with hanging, it seems to me, was resolved.
After the "bulk_insert" operation, the total size of data on S3 storage is 3.7GB.
Exported data from the database to CSV file for ~30M records is ~8.6GB.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610307143
So, the process took 2h 40m and thrown "java.lang.OutOfMemoryError: GC overhead limit exceeded".
Log https://drive.google.com/open?id=1Ark99uXcdp5_4Ns7-DdaSkMfkahJgK6n.
Is it normal, that the process took such time?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610221356
Tried to set this config:
- local[4]
- driver memory 12GB
- driver memoryOverhead 2048
And result:
20/04/07 07:05:38 INFO ExternalAppendOnlyMap: Thread 132 spilling in-memory map of 1598.4 MB to disk (1 time so far)
20/04/07 07:05:39 INFO ExternalAppendOnlyMap: Thread 130 spilling in-memory map of 1598.4 MB to disk (1 time so far)
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000658800000, 1736441856, 0) failed; error='Out of memory' (errno=12)
There is insufficient memory for the Java Runtime Environment to continue.
Native memory allocation (mmap) failed to map 1736441856 bytes for committing reserved memory.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken removed a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken removed a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611092165
Something cached in memory

----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-615141491
Hi @lamber-ken
Yes, I have resolved this problem.
Firstly, the problem was in SBT memory that allocated default memory size 1GB. Then, I fixed it and set 8GB and transferring 5M records successfully finished in my local environment.
Next, I have tried to transfer 30M records, but upsert failed again. I tunned *.parallelism parameters (Changed from 8 to 100) and everything went fine (20MB for each parquet file).
Also, I added parameter "hoodie.memory.merge.max.size" with value "2004857600000" that you had recommended. Upsert was hanging without this parameter (It is necessary to recheck again).
@lamber-ken, can you explain to me, what the parameter is?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610564674
Code:
sparkSession
.read
.jdbc(
url = jdbcConfig.url,
table = table,
columnName = "partition",
lowerBound = 0,
upperBound = jdbcConfig.partitionsCount.toInt,
numPartitions = jdbcConfig.partitionsCount.toInt,
connectionProperties = new Properties() {
put("driver", jdbcConfig.driver)
put("user", jdbcConfig.user)
put("password", jdbcConfig.password)
}
)
.withColumn("year", substring(col(jdbcConfig.dateColumnName), 0, 4))
.withColumn("month", substring(col(jdbcConfig.dateColumnName), 6, 2))
.withColumn("day", substring(col(jdbcConfig.dateColumnName), 9, 2))
.write
.option(HoodieWriteConfig.TABLE_NAME, hudiConfig.tableName)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, hudiConfig.recordKey)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, hudiConfig.precombineKey)
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, hudiConfig.partitionPathKey)
.option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY, classOf[ComplexKeyGenerator].getName)
.option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
.option("hoodie.datasource.write.operation", writeOperation)
.option("hoodie.bulkinsert.shuffle.parallelism", hudiConfig.bulkInsertParallelism)
.option("hoodie.insert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.upsert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.cleaner.policy", HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name())
.option("hoodie.cleaner.fileversions.retained", "1")
.option("hoodie.metrics.graphite.host", hudiConfig.graphiteHost)
.option("hoodie.metrics.graphite.port", hudiConfig.graphitePort)
.option("hoodie.metrics.graphite.metric.prefix", hudiConfig.graphiteMetricPrefix)
.format("org.apache.hudi")
.mode(SaveMode.Append)
.save(outputPath)
This code is executing on Jenkins, with next parameters:
docker run --rm -v ${PWD}:${PWD} -v /mnt/ml_data:/mnt/ml_data bde2020/spark-master:2.4.5-hadoop2.7 \
bash ./spark/bin/spark-submit \
--master "local[2]" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.hadoop:hadoop-aws:2.7.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf spark.local.dir=/mnt/ml_data \
--conf spark.ui.enabled=false \
--conf spark.driver.memory=4g \
--conf spark.driver.memoryOverhead=1024 \
--conf spark.driver.maxResultSize=2g \
--conf spark.kryoserializer.buffer.max=512m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.rdd.compress=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.hadoop.fs.defaultFS=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.access.key=${AWS_ACCESS_KEY_ID} \
--conf spark.hadoop.fs.s3a.secret.key=${AWS_SECRET_ACCESS_KEY} \
--conf spark.executorEnv.period.startDate=${date} \
--conf spark.executorEnv.period.numDays=${numDays} \
--conf spark.executorEnv.jdbc.url=${VERTICA_URL} \
--conf spark.executorEnv.jdbc.user=${VERTICA_USER} \
--conf spark.executorEnv.jdbc.password=${VERTICA_PWD} \
--conf spark.executorEnv.jdbc.driver=${VERTICA_DRIVER}\
--conf spark.executorEnv.jdbc.schemaName=mtu_owner \
--conf spark.executorEnv.jdbc.tableName=ext_ml_data \
--conf spark.executorEnv.jdbc.dateColumnName=hit_date \
--conf spark.executorEnv.jdbc.partitionColumnName=hit_timestamp \
--conf spark.executorEnv.jdbc.partitionsCount=8 \
--conf spark.executorEnv.hudi.outputPath=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.executorEnv.hudi.tableName=ext_ml_data \
--conf spark.executorEnv.hudi.recordKey=tds_cid \
--conf spark.executorEnv.hudi.precombineKey=hit_timestamp \
--conf spark.executorEnv.hudi.parallelism=8 \
--conf spark.executorEnv.hudi.bulkInsertParallelism=8 \
--class mtu.spark.analytics.ExtMLDataToS3 \
${PWD}/ml-vertica-to-s3-hudi.jar
I try to move 53 million records (The table contains 48 columns) from the Vertica database to s3 storage.
Operation "bulk_insert" successfully completes and takes about 40-50 minutes.
Operation "upsert" on the same records throws exceptions with OOM.
On Hudi 0.5.1 "upsert" operations were hanging. I found the issue https://github.com/apache/incubator-hudi/issues/1328 and updated Hudi to 0.5.2. The problem with hanging, it seems to me, was resolved.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610073501
@bvaradar , it's a local mode with 2 threads. Yes, I have tried to increase hudi parallelism (Default values)/threads, but it didn't help me.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610073501
@bvaradar , it's a local mode with 2 threads. Yes, I have tried to increase hudi parallelism (Default values), but it didn't help me.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-615473505
Hi @tverdokhlebd, I'm glad to hear that your problem has been solved.
> Upsert was hanging without this parameter
When do upsert operation, hudi need to buffer input records in memory, controls the size of the buffer is controlled by the option `hoodie.memory.merge.max.size`. if the value of that option is small, hudi will spill contents to disk, in that case, the upsert performance will decline.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611636241
@lamber-ken , I have run on my local machine (Windows, WSL) without docker.
But, I have also Jenkins (Linux) and there I run processing in a docker environment.
I will try to run processing with your parameters one to one.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610580236
> Can you give this a shot on a cluster?
Do you mean access to the cluster? Those steps also were reproducing on my local machine.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610630535
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610626104
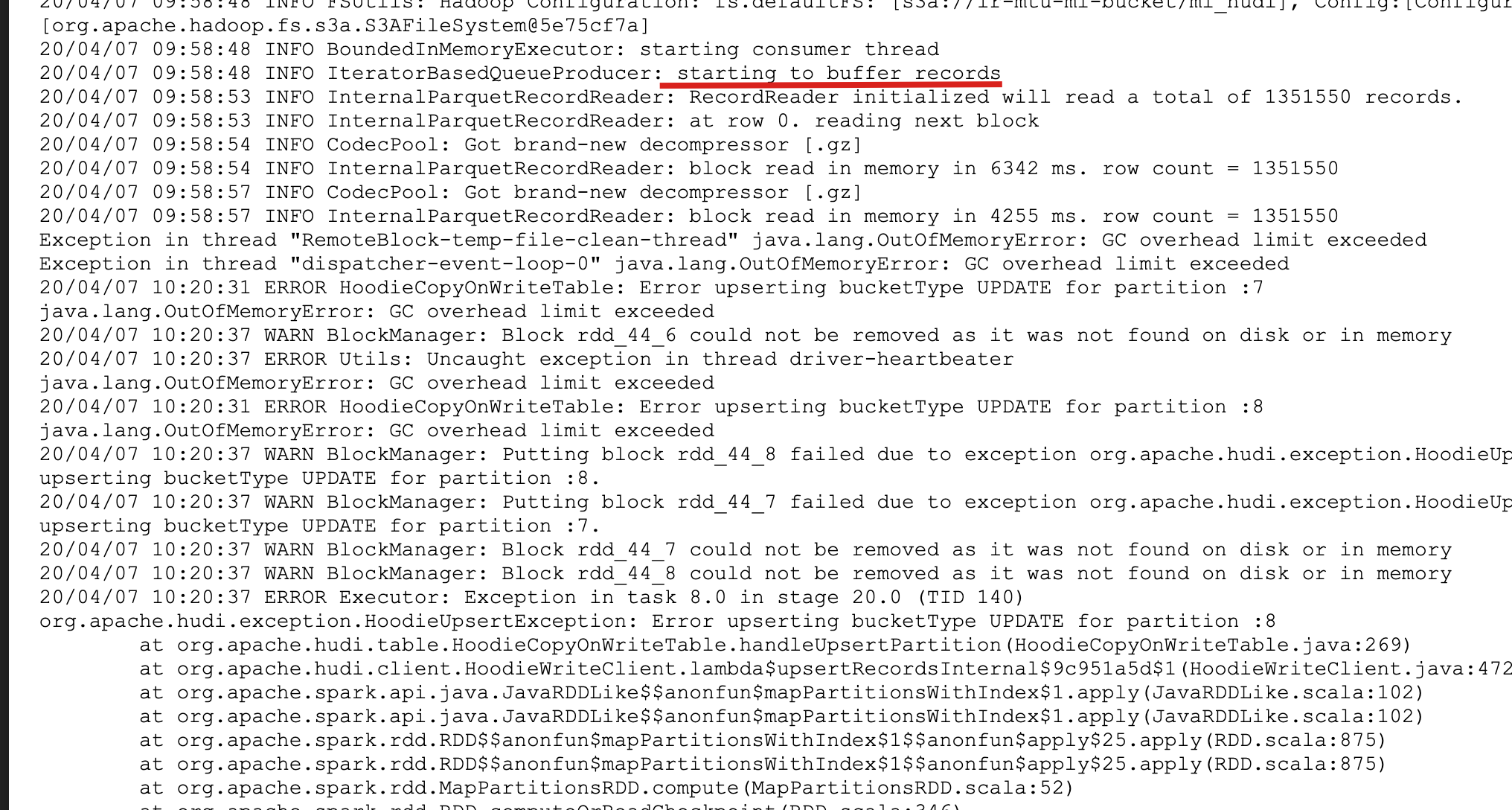
hi @tverdokhlebd, thanks your detailed spark log, from your description and dataset, key information
- run on local machine
- the size of each record is large
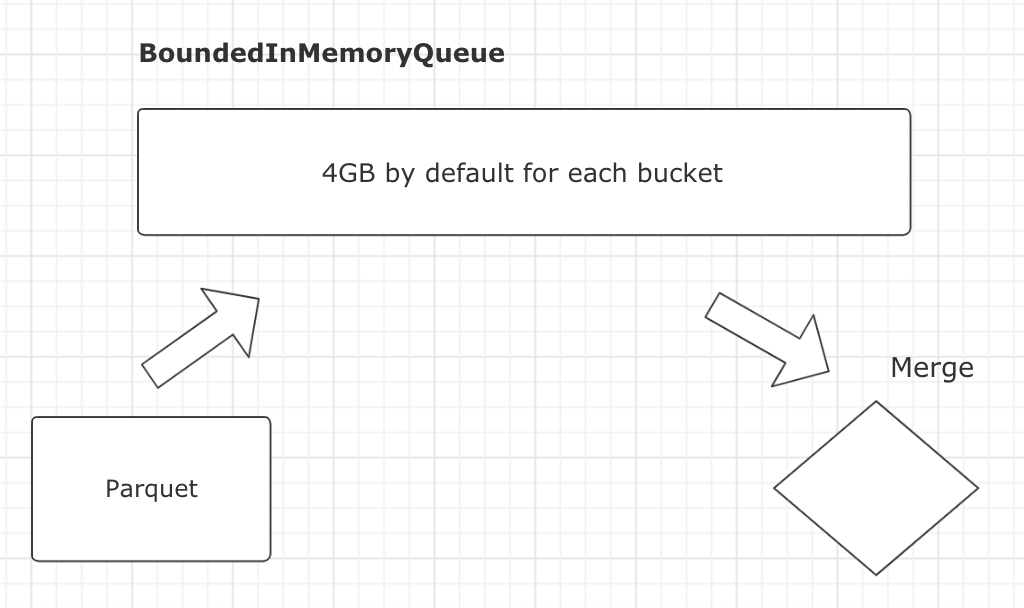
I noticed that OOM happened after parquet read old record to memory, which means we need to control the number of old records, so try add this option
```
.option("hoodie.write.buffer.limit.bytes", "131072") //128MB
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] n3nash commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
n3nash commented on issue #1491:
URL: https://github.com/apache/hudi/issues/1491#issuecomment-824533410
Closing this ticket due to inactivity, details and PR to follow up on the filed JIRA
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] tverdokhlebd removed a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd removed a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610221356
Tried to set this config:
- local[4]
- driver memory 12GB
- driver memoryOverhead 2048
And result:
20/04/07 07:05:38 INFO ExternalAppendOnlyMap: Thread 132 spilling in-memory map of 1598.4 MB to disk (1 time so far)
20/04/07 07:05:39 INFO ExternalAppendOnlyMap: Thread 130 spilling in-memory map of 1598.4 MB to disk (1 time so far)
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000658800000, 1736441856, 0) failed; error='Out of memory' (errno=12)
There is insufficient memory for the Java Runtime Environment to continue.
Native memory allocation (mmap) failed to map 1736441856 bytes for committing reserved memory.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] vinothchandar commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610504319
Is this real data or can you share a reproducible snippet of code? Especially with these local microbenchmarks, its useful to understand as the small costs that typically don't matter in real cluster, kind of tend to amplify..
From the logs, it seems like
1) bulk_insert is succeeding and upsert is what's failing... and it's failing during the write phase, when we actually allocate some memory to do the merge..
2) From the logs below, it seems like you have a lot of data potentially for a single node.. How much total data do you have in those 53M records? (That's a key metric for runtime, more than number of records. Hudi does not have a maxiumum records limit etc per se)
```
20/04/07 08:02:55 INFO ExternalAppendOnlyMap: Thread 136 spilling in-memory map of 1325.4 MB to disk (1 time so far)
20/04/07 08:03:04 INFO ExternalAppendOnlyMap: Thread 137 spilling in-memory map of 1329.9 MB to disk (1 time so far)
20/04/07 08:03:04 INFO ExternalAppendOnlyMap: Thread 135 spilling in-memory map of 1325.7 MB to disk (1 time so far)
20/04/07 08:03:07 INFO ExternalAppendOnlyMap: Thread 47 spilling in-memory map of 1385.6 MB to disk (1 time so far)
20/04/07 08:03:25 INFO ExternalAppendOnlyMap: Thread 136 spilling in-memory map of 1325.4 MB to disk (2 times so far)
20/04/07 08:03:41 INFO ExternalAppendOnlyMap: Thread 137 spilling in-memory map of 1325.5 MB to disk (2 times so far)
20/04/07 08:03:43 INFO ExternalAppendOnlyMap: Thread 135 spilling in-memory map of 1325.4 MB to disk (2 times so far)
20/04/07 08:03:58 INFO ExternalAppendOnlyMap: Thread 47 spilling in-memory map of 1381.4 MB to disk (2 times so far)
20/04/07 08:04:08 INFO ExternalAppendOnlyMap: Thread 136 spilling in-memory map of 1325.4 MB to disk (3 times so far)
20/04/07 08:04:24 INFO ExternalAppendOnlyMap: Thread 137 spilling in-memory map of 1325.4 MB to disk (3 times so far)
20/04/07 08:04:28 INFO ExternalAppendOnlyMap: Thread 135 spilling in-memory map of 1327.7 MB to disk (3 times so far)
20/04/07 08:04:57 INFO ExternalAppendOnlyMap: Thread 136 spilling in-memory map of 1325.4 MB to disk (4 times so far)
20/04/07 08:04:59 INFO ExternalAppendOnlyMap: Thread 47 spilling in-memory map of 1491.8 MB to disk (3 times so far)
20/04/07 08:05:14 INFO ExternalAppendOnlyMap: Thread 137 spilling in-memory map of 1363.9 MB to disk (4 times so far)
20/04/07 08:05:16 INFO ExternalAppendOnlyMap: Thread 135 spilling in-memory map of 1325.4 MB to disk (4 times so far)
20/04/07 08:05:47 INFO ExternalAppendOnlyMap: Thread 47 spilling in-memory map of 1349.8 MB to disk (4 times so far)
20/04/07 08:06:05 INFO ExternalAppendOnlyMap: Thread 137 spilling in-memory map of 1300.9 MB to disk (5 times so far)
```
I suspect what's happening is that spark memory is actually full (Hudi caches input to derive workload profile etc and typically advised to keep input data in memory) and it keeps spilling to disk, slowing everything down.. (more of a spark tuning thing)... But things don't break until Hudi tries to allocate some memory on its own, at which point the heap is full..
Can you give this a shot on a cluster?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] bvaradar commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610079124
Ohh. I didn't realize that. Haven't tried ingesting 30M record ingestion in local mode with 2 threads. You might be stretching the limits here. The OOM error happens in executor. How much is executor memory ? Try giving more ?
If you are running this with local docker, have you given docker desktop with enough memory to docker engine ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610580236
> Can you give this a shot on a cluster?
Do you mean access to the cluster? Those steps also were reproducing on my local machine.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611158024
@lamber-ken , did you do "bulk insert" on a partition and then "upsert" to the same partition, yes?
Did you test with those params?
.option("hoodie.cleaner.policy", HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name())
.option("hoodie.cleaner.fileversions.retained", "1")
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611921813
Hi, here is spark command
```
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--master 'local[2]' \
--driver-memory 6G \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-615473505
Hi @tverdokhlebd, I'm glad to hear that your problem has been solved.
> Upsert was hanging without this parameter
When do upsert operation, hudi need to buffer input records in memory, controls the size of the buffer is controlled by the option `hoodie.memory.merge.max.size`. if the value of that option is small, hudi will spill contents to disk, in that case, the upsert performance will decline.
> without "hoodie.memory.merge.max.size" parameter and got error (heap size).
BTW, I can't understand why without that parameter, will get error(heap size), have you encountered a similar situation before? @vinothchandar
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610880742
> .option("hoodie.write.buffer.limit.bytes", "131072") //128MB
I have tried but it doesn't help me (local[3] with driver memory 8g).
Next, I have split my data into a single file with 5M records and try again, but it also doesn't help me - upsert failed with GC limit exception.
Also, tried to decrease parquet file size, memory merge fraction.
So, I have attached log and data with 5M records:
- CSV data with 5M records https://drive.google.com/open?id=1uwJ68_RrKMUTbEtsGl56_P5b_mNX3k2S
- Log with GC limit exception https://drive.google.com/open?id=147Qz7Iau1RWyRlWYSq8WvtWFB0fAXLM8
@lamber-ken, can you try to do bulk insert and then upsert on those data and configuration?
My configuration:
-Dspark.master=local[3] \
-Dspark.local.dir="$currentDir/tmp" \
-Dspark.ui.enabled=false \
-Dspark.driver.memory=8g \
-Dspark.driver.memoryOverhead=1g \
-Dspark.kryoserializer.buffer.max=512m \
-Dspark.rdd.compress=true \
-Dspark.shuffle.service.enabled=true \
-Dspark.sql.hive.convertMetastoreParquet=false \
-Dspark.serializer=org.apache.spark.serializer.KryoSerializer \
-Dspark.executorEnv.hudi.tableName="ext_ml_data" \
-Dspark.executorEnv.hudi.recordKey="tds_cid" \
-Dspark.executorEnv.hudi.precombineKey="hit_timestamp" \
-Dspark.executorEnv.hudi.partitionPathKey="year,month,day" \
-Dspark.executorEnv.hudi.parallelism=8 \
-Dspark.executorEnv.hudi.bulkInsertParallelism=8 \
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611462195
Hmm, this is strange :(
I have tried with your parameters (parallelism and memory), but it does not help me again:
1. Do "bulk_insert" with append mode to partition path "2020-03-19" from the CSV file
2. Do "upsert" with append mode to partition path "2020-03-19" from the same CSV file
I did those operations with 2 threads and 6GB driver memory and without parameter "hoodie.delete.shuffle.parallelism". I think that parameter doesn't affect processing.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610982711
Ok, I had downloaded the CSV data, trying
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] nsivabalan commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #1491:
URL: https://github.com/apache/hudi/issues/1491#issuecomment-633142444
@lamber-ken : Did you get a chance to follow up on this. We have this tagged for bug bash. Would be great if can get some progress on this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611116577
hi @tverdokhlebd, it works fine in my local env(didn't run command on docker).
My local machine: 16GB, 4core.
Just some warning, no OOM error
```
20/04/09 02:07:32 WARN BlockManager: Persisting block rdd_48_33 to disk instead.
[Stage 16:==================================================> (36 + 4) / 40]20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_37 in memory! (computed 58.0 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_37 to disk instead.
[Stage 16:===================================================> (37 + 3) / 40]20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_38 in memory! (computed 39.2 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_38 to disk instead.
20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_39 in memory! (computed 11.5 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_39 to disk instead.
20/04/09 02:10:27 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
scala> spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
20/04/09 02:22:07 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
```
### Upsert commnad
```
export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
${SPARK_HOME}/bin/spark-shell \
--driver-memory 6G \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
import org.apache.spark.sql.functions._
val tableName = "hudi_mor_table"
val basePath = "file:///tmp/hudi_mor_table"
var inputDF = spark.read.format("csv").option("header", "true").load("file:///work/hudi-debug/2.csv")
val hudiOptions = Map[String,String](
"hoodie.insert.shuffle.parallelism" -> "10",
"hoodie.upsert.shuffle.parallelism" -> "10",
"hoodie.delete.shuffle.parallelism" -> "10",
"hoodie.bulkinsert.shuffle.parallelism" -> "10",
"hoodie.datasource.write.recordkey.field" -> "tds_cid",
"hoodie.datasource.write.partitionpath.field" -> "hit_date",
"hoodie.table.name" -> tableName,
"hoodie.datasource.write.precombine.field" -> "hit_timestamp",
"hoodie.datasource.write.operation" -> "upsert",
"hoodie.memory.merge.max.size" -> "2004857600000"
)
inputDF.write.format("org.apache.hudi").
options(hudiOptions).
mode("Append").
save(basePath)
spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610635678
> Can you give this a shot on a cluster?
more, what @vinothchandar wants to say is that run your snippet code on yarn cluster if possiable, so we can know how it behaves to when running in a cluster.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610880742
> .option("hoodie.write.buffer.limit.bytes", "131072") //128MB
I have tried but it doesn't help me (local[3] with driver memory 8g).
Next, I have split my data into a single file with 5M records and try again, but it also doesn't help me - upsert failed with GC limit exception.
Also, tried to decrease parquet file size, memory merge fraction.
So, I have attached log and data with 5M records:
- CSV data with 5M records https://drive.google.com/open?id=1uwJ68_RrKMUTbEtsGl56_P5b_mNX3k2S
- Log with GC limit exception https://drive.google.com/open?id=147Qz7Iau1RWyRlWYSq8WvtWFB0fAXLM8
@lamber-ken, can you try to do bulk insert and then upsert on those data and configuration?
Part of code and configuration you may take above from my reply.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] vinothchandar closed issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
vinothchandar closed issue #1491:
URL: https://github.com/apache/hudi/issues/1491
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611116577
hi @tverdokhlebd, it works fine in my local env, just some warning, no OOM
```
20/04/09 02:07:32 WARN BlockManager: Persisting block rdd_48_33 to disk instead.
[Stage 16:==================================================> (36 + 4) / 40]20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_37 in memory! (computed 58.0 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_37 to disk instead.
[Stage 16:===================================================> (37 + 3) / 40]20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_38 in memory! (computed 39.2 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_38 to disk instead.
20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_39 in memory! (computed 11.5 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_39 to disk instead.
20/04/09 02:10:27 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
scala> spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
20/04/09 02:22:07 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610233979
I will try with default memoryOverhead and 10GB driver memory
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610880742
> .option("hoodie.write.buffer.limit.bytes", "131072") //128MB
I have tried but it doesn't help me. Tested on local mode with 3 threads and driver memory 8GB.
Next, I have split my data into a single file with 5M records and try again, but it also doesn't help me - upsert failed with GC limit exception.
Also, tried to decrease parquet file size, memory merge fraction, buffer limit bytes.
So, I have attached log and data with 5M records:
- CSV data with 5M records https://drive.google.com/open?id=1uwJ68_RrKMUTbEtsGl56_P5b_mNX3k2S
- Log with GC limit exception https://drive.google.com/open?id=147Qz7Iau1RWyRlWYSq8WvtWFB0fAXLM8
@lamber-ken, can you try to do bulk insert and then upsert on those data and configuration?
Part of code and configuration you may take above from my reply.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611288468
Hi @tverdokhlebd, the whole upsert cost about 30min
```
dcadmin-imac:hudi-debug dcadmin$ export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
dcadmin-imac:hudi-debug dcadmin$ ${SPARK_HOME}/bin/spark-shell \
> --driver-memory 6G \
> --packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4 \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
Ivy Default Cache set to: /Users/dcadmin/.ivy2/cache
The jars for the packages stored in: /Users/dcadmin/.ivy2/jars
:: loading settings :: url = jar:file:/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
org.apache.hudi#hudi-spark-bundle_2.11 added as a dependency
org.apache.spark#spark-avro_2.11 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-204b7ab2-3e3f-4853-9220-5e038fc99fc2;1.0
confs: [default]
found org.apache.hudi#hudi-spark-bundle_2.11;0.5.1-incubating in central
found org.apache.spark#spark-avro_2.11;2.4.4 in central
found org.spark-project.spark#unused;1.0.0 in spark-list
:: resolution report :: resolve 258ms :: artifacts dl 5ms
:: modules in use:
org.apache.hudi#hudi-spark-bundle_2.11;0.5.1-incubating from central in [default]
org.apache.spark#spark-avro_2.11;2.4.4 from central in [default]
org.spark-project.spark#unused;1.0.0 from spark-list in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 3 | 0 | 0 | 0 || 3 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-204b7ab2-3e3f-4853-9220-5e038fc99fc2
confs: [default]
0 artifacts copied, 3 already retrieved (0kB/5ms)
20/04/09 09:23:38 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://10.101.52.18:4040
Spark context available as 'sc' (master = local[*], app id = local-1586395425370).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_211)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._
scala>
scala> val tableName = "hudi_mor_table"
tableName: String = hudi_mor_table
scala> val basePath = "file:///tmp/hudi_mor_table"
basePath: String = file:///tmp/hudi_mor_table
scala>
scala> var inputDF = spark.read.format("csv").option("header", "true").load("file:///work/hudi-debug/2.csv")
inputDF: org.apache.spark.sql.DataFrame = [tds_cid: string, hit_timestamp: string ... 46 more fields]
scala>
scala> val hudiOptions = Map[String,String](
| "hoodie.insert.shuffle.parallelism" -> "10",
| "hoodie.upsert.shuffle.parallelism" -> "10",
| "hoodie.delete.shuffle.parallelism" -> "10",
| "hoodie.bulkinsert.shuffle.parallelism" -> "10",
| "hoodie.datasource.write.recordkey.field" -> "tds_cid",
| "hoodie.datasource.write.partitionpath.field" -> "hit_date",
| "hoodie.table.name" -> tableName,
| "hoodie.datasource.write.precombine.field" -> "hit_timestamp",
| "hoodie.datasource.write.operation" -> "upsert",
| "hoodie.memory.merge.max.size" -> "2004857600000",
| "hoodie.cleaner.policy" -> "KEEP_LATEST_FILE_VERSIONS",
| "hoodie.cleaner.fileversions.retained" -> "1"
| )
hudiOptions: scala.collection.immutable.Map[String,String] = Map(hoodie.insert.shuffle.parallelism -> 10, hoodie.datasource.write.precombine.field -> hit_timestamp, hoodie.cleaner.fileversions.retained -> 1, hoodie.delete.shuffle.parallelism -> 10, hoodie.datasource.write.operation -> upsert, hoodie.datasource.write.recordkey.field -> tds_cid, hoodie.table.name -> hudi_mor_table, hoodie.memory.merge.max.size -> 2004857600000, hoodie.cleaner.policy -> KEEP_LATEST_FILE_VERSIONS, hoodie.upsert.shuffle.parallelism -> 10, hoodie.datasource.write.partitionpath.field -> hit_date, hoodie.bulkinsert.shuffle.parallelism -> 10)
scala>
scala> inputDF.write.format("org.apache.hudi").
| options(hudiOptions).
| mode("Append").
| save(basePath)
20/04/09 09:23:53 WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf.
[Stage 3:> (0 + 4) / 10]20/04/09 09:24:55 WARN MemoryStore: Not enough space to cache rdd_16_1 in memory! (computed 87.6 MB so far)
20/04/09 09:24:55 WARN BlockManager: Persisting block rdd_16_1 to disk instead.
20/04/09 09:24:56 WARN MemoryStore: Not enough space to cache rdd_16_2 in memory! (computed 196.9 MB so far)
20/04/09 09:24:56 WARN BlockManager: Persisting block rdd_16_2 to disk instead.
20/04/09 09:24:56 WARN MemoryStore: Not enough space to cache rdd_16_0 in memory! (computed 130.8 MB so far)
20/04/09 09:24:56 WARN BlockManager: Persisting block rdd_16_0 to disk instead.
20/04/09 09:24:56 WARN MemoryStore: Not enough space to cache rdd_16_3 in memory! (computed 196.3 MB so far)
20/04/09 09:24:56 WARN BlockManager: Persisting block rdd_16_3 to disk instead.
[Stage 3:=======================> (4 + 4) / 10]20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_6 in memory! (computed 58.5 MB so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_6 to disk instead.
20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_4 in memory! (computed 58.3 MB so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_4 to disk instead.
20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_5 in memory! (computed 87.6 MB so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_5 to disk instead.
20/04/09 09:25:12 WARN MemoryStore: Failed to reserve initial memory threshold of 1024.0 KB for computing block rdd_16_7 in memory.
20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_7 in memory! (computed 0.0 B so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_7 to disk instead.
[Stage 3:==============================================> (8 + 2) / 10]20/04/09 09:25:26 WARN MemoryStore: Not enough space to cache rdd_16_9 in memory! (computed 58.4 MB so far)
20/04/09 09:25:26 WARN BlockManager: Persisting block rdd_16_9 to disk instead.
20/04/09 09:25:26 WARN MemoryStore: Not enough space to cache rdd_16_8 in memory! (computed 87.6 MB so far)
20/04/09 09:25:26 WARN BlockManager: Persisting block rdd_16_8 to disk instead.
[Stage 14:=======================================> (28 + 4) / 40]20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_30 in memory! (computed 39.3 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_30 to disk instead.
20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_29 in memory! (computed 58.5 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_29 to disk instead.
20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_28 in memory! (computed 58.6 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_28 to disk instead.
20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_31 in memory! (computed 17.3 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_31 to disk instead.
[Stage 14:============================================> (32 + 4) / 40]20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_33 in memory! (computed 26.0 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_33 to disk instead.
20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_32 in memory! (computed 25.8 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_32 to disk instead.
20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_35 in memory! (computed 5.2 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_35 to disk instead.
20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_34 in memory! (computed 5.1 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_34 to disk instead.
[Stage 14:==================================================> (36 + 4) / 40]20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_38 in memory! (computed 1032.0 KB so far)
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_38 to disk instead.
20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_36 in memory! (computed 3.4 MB so far)
20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_37 in memory! (computed 3.4 MB so far)
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_37 to disk instead.
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_36 to disk instead.
20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_39 in memory! (computed 7.6 MB so far)
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_39 to disk instead.
20/04/09 09:47:19 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
scala>
scala> spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
20/04/09 09:47:19 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
res1: Long = 5045301
scala>
scala>
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-614366584
hi @tverdokhlebd, are you still facing this problem? Or can you ask your colleagues to try again?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-615473505
Hi @tverdokhlebd, glad to hear that your problem has been solved.
> Upsert was hanging without this parameter
When do upsert operation, hudi need to buffer input records in memory, the size of the buffer is controlled by the option `hoodie.memory.merge.max.size`. if the value of that option is small, hudi will spill contents to disk, in that case, the upsert performance will decline.
> without "hoodie.memory.merge.max.size" parameter and got error (heap size).
but, I can't understand why without that parameter, will get error(heap size), have you encountered a similar situation before? @vinothchandar
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611920831
> I run those operations with local[2] and 6GB driver memory, still worked fine.
How did you set memory? I don't see any memory config...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [hudi] n3nash closed issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
n3nash closed issue #1491:
URL: https://github.com/apache/hudi/issues/1491
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] bvaradar commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 30M records
Posted by GitBox <gi...@apache.org>.
bvaradar commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 30M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610070984
Didnt spend too much time into the debug logs. Can you try increasing hudi parallelism configurations and give more executors. I couldn't find how many executors are present in the application.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610564674
Code:
sparkSession
.read
.jdbc(
url = jdbcConfig.url,
table = table,
columnName = "partition",
lowerBound = 0,
upperBound = jdbcConfig.partitionsCount.toInt,
numPartitions = jdbcConfig.partitionsCount.toInt,
connectionProperties = new Properties() {
put("driver", jdbcConfig.driver)
put("user", jdbcConfig.user)
put("password", jdbcConfig.password)
}
)
.withColumn("year", substring(col(jdbcConfig.dateColumnName), 0, 4))
.withColumn("month", substring(col(jdbcConfig.dateColumnName), 6, 2))
.withColumn("day", substring(col(jdbcConfig.dateColumnName), 9, 2))
.write
.option(HoodieWriteConfig.TABLE_NAME, hudiConfig.tableName)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, hudiConfig.recordKey)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, hudiConfig.precombineKey)
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, hudiConfig.partitionPathKey)
.option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY, classOf[ComplexKeyGenerator].getName)
.option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
.option("hoodie.datasource.write.operation", writeOperation)
.option("hoodie.bulkinsert.shuffle.parallelism", hudiConfig.bulkInsertParallelism)
.option("hoodie.insert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.upsert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.cleaner.policy", HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name())
.option("hoodie.cleaner.fileversions.retained", "1")
.option("hoodie.metrics.graphite.host", hudiConfig.graphiteHost)
.option("hoodie.metrics.graphite.port", hudiConfig.graphitePort)
.option("hoodie.metrics.graphite.metric.prefix", hudiConfig.graphiteMetricPrefix)
.format("org.apache.hudi")
.mode(SaveMode.Append)
.save(outputPath)
This code is executing on Jenkins, with next parameters:
docker run --rm -v ${PWD}:${PWD} -v /mnt/ml_data:/mnt/ml_data bde2020/spark-master:2.4.5-hadoop2.7 \
bash ./spark/bin/spark-submit \
--master "local[2]" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.hadoop:hadoop-aws:2.7.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf spark.local.dir=/mnt/ml_data \
--conf spark.ui.enabled=false \
--conf spark.driver.memory=4g \
--conf spark.driver.memoryOverhead=1024 \
--conf spark.driver.maxResultSize=2g \
--conf spark.kryoserializer.buffer.max=512m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.rdd.compress=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.hadoop.fs.defaultFS=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.access.key=${AWS_ACCESS_KEY_ID} \
--conf spark.hadoop.fs.s3a.secret.key=${AWS_SECRET_ACCESS_KEY} \
--conf spark.executorEnv.period.startDate=${date} \
--conf spark.executorEnv.period.numDays=${numDays} \
--conf spark.executorEnv.jdbc.url=${VERTICA_URL} \
--conf spark.executorEnv.jdbc.user=${VERTICA_USER} \
--conf spark.executorEnv.jdbc.password=${VERTICA_PWD} \
--conf spark.executorEnv.jdbc.driver=${VERTICA_DRIVER}\
--conf spark.executorEnv.jdbc.schemaName=mtu_owner \
--conf spark.executorEnv.jdbc.tableName=ext_ml_data \
--conf spark.executorEnv.jdbc.dateColumnName=hit_date \
--conf spark.executorEnv.jdbc.partitionColumnName=hit_timestamp \
--conf spark.executorEnv.jdbc.partitionsCount=8 \
--conf spark.executorEnv.hudi.outputPath=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.executorEnv.hudi.tableName=ext_ml_data \
--conf spark.executorEnv.hudi.recordKey=tds_cid \
--conf spark.executorEnv.hudi.precombineKey=hit_timestamp \
--conf spark.executorEnv.hudi.parallelism=8 \
--conf spark.executorEnv.hudi.bulkInsertParallelism=8 \
--class mtu.spark.analytics.ExtMLDataToS3 \
${PWD}/ml-vertica-to-s3-hudi.jar
I try to move 53 million records (The table contains 48 columns) from the Vertica database to s3 storage.
Operation "bulk_insert" successfully completes and take about 40-50 minutes.
Operation "upsert" on the same records throws exceptions with OOM.
On Hudi 0.5.1 "upsert" operations were hanging. I found the issue https://github.com/apache/incubator-hudi/issues/1328 and updated Hudi to 0.5.2. The problem, it seems to me, was resolved.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611116577
hi @tverdokhlebd, it works fine in my local env, just some warning, no OOM
```
20/04/09 02:07:32 WARN BlockManager: Persisting block rdd_48_33 to disk instead.
[Stage 16:==================================================> (36 + 4) / 40]20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_37 in memory! (computed 58.0 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_37 to disk instead.
[Stage 16:===================================================> (37 + 3) / 40]20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_38 in memory! (computed 39.2 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_38 to disk instead.
20/04/09 02:07:38 WARN MemoryStore: Not enough space to cache rdd_48_39 in memory! (computed 11.5 MB so far)
20/04/09 02:07:38 WARN BlockManager: Persisting block rdd_48_39 to disk instead.
20/04/09 02:10:27 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
scala> spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
20/04/09 02:22:07 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
```
### Upsert commnad
```
import org.apache.spark.sql.functions._
val tableName = "hudi_mor_table"
val basePath = "file:///tmp/hudi_mor_table"
var inputDF = spark.read.format("csv").option("header", "true").load("file:///work/hudi-debug/2.csv")
val hudiOptions = Map[String,String](
"hoodie.insert.shuffle.parallelism" -> "10",
"hoodie.upsert.shuffle.parallelism" -> "10",
"hoodie.delete.shuffle.parallelism" -> "10",
"hoodie.bulkinsert.shuffle.parallelism" -> "10",
"hoodie.datasource.write.recordkey.field" -> "tds_cid",
"hoodie.datasource.write.partitionpath.field" -> "hit_date",
"hoodie.table.name" -> tableName,
"hoodie.datasource.write.precombine.field" -> "hit_timestamp",
"hoodie.datasource.write.operation" -> "upsert",
"hoodie.memory.merge.max.size" -> "2004857600000"
)
inputDF.write.format("org.apache.hudi").
options(hudiOptions).
mode("Append").
save(basePath)
spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610307143
So, the process took 2h 40m (local[4] and driver memory 10gb) and thrown "java.lang.OutOfMemoryError: GC overhead limit exceeded".
Log https://drive.google.com/open?id=1Ark99uXcdp5_4Ns7-DdaSkMfkahJgK6n.
Is it normal, that the process took such time?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611288468
Hi @tverdokhlebd, the whole upsert cost about 30min
```
dcadmin-imac:hudi-debug dcadmin$ export SPARK_HOME=/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7
dcadmin-imac:hudi-debug dcadmin$ ${SPARK_HOME}/bin/spark-shell \
> --driver-memory 6G \
> --packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.1-incubating,org.apache.spark:spark-avro_2.11:2.4.4 \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
Ivy Default Cache set to: /Users/dcadmin/.ivy2/cache
The jars for the packages stored in: /Users/dcadmin/.ivy2/jars
:: loading settings :: url = jar:file:/work/BigData/install/spark/spark-2.4.4-bin-hadoop2.7/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
org.apache.hudi#hudi-spark-bundle_2.11 added as a dependency
org.apache.spark#spark-avro_2.11 added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-204b7ab2-3e3f-4853-9220-5e038fc99fc2;1.0
confs: [default]
found org.apache.hudi#hudi-spark-bundle_2.11;0.5.1-incubating in central
found org.apache.spark#spark-avro_2.11;2.4.4 in central
found org.spark-project.spark#unused;1.0.0 in spark-list
:: resolution report :: resolve 258ms :: artifacts dl 5ms
:: modules in use:
org.apache.hudi#hudi-spark-bundle_2.11;0.5.1-incubating from central in [default]
org.apache.spark#spark-avro_2.11;2.4.4 from central in [default]
org.spark-project.spark#unused;1.0.0 from spark-list in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 3 | 0 | 0 | 0 || 3 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-204b7ab2-3e3f-4853-9220-5e038fc99fc2
confs: [default]
0 artifacts copied, 3 already retrieved (0kB/5ms)
20/04/09 09:23:38 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://10.101.52.18:4040
Spark context available as 'sc' (master = local[*], app id = local-1586395425370).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_211)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._
scala>
scala> val tableName = "hudi_mor_table"
tableName: String = hudi_mor_table
scala> val basePath = "file:///tmp/hudi_mor_table"
basePath: String = file:///tmp/hudi_mor_table
scala>
scala> var inputDF = spark.read.format("csv").option("header", "true").load("file:///work/hudi-debug/2.csv")
inputDF: org.apache.spark.sql.DataFrame = [tds_cid: string, hit_timestamp: string ... 46 more fields]
scala>
scala> val hudiOptions = Map[String,String](
| "hoodie.insert.shuffle.parallelism" -> "10",
| "hoodie.upsert.shuffle.parallelism" -> "10",
| "hoodie.delete.shuffle.parallelism" -> "10",
| "hoodie.bulkinsert.shuffle.parallelism" -> "10",
| "hoodie.datasource.write.recordkey.field" -> "tds_cid",
| "hoodie.datasource.write.partitionpath.field" -> "hit_date",
| "hoodie.table.name" -> tableName,
| "hoodie.datasource.write.precombine.field" -> "hit_timestamp",
| "hoodie.datasource.write.operation" -> "upsert",
| "hoodie.memory.merge.max.size" -> "2004857600000",
| "hoodie.cleaner.policy" -> "KEEP_LATEST_FILE_VERSIONS",
| "hoodie.cleaner.fileversions.retained" -> "1"
| )
hudiOptions: scala.collection.immutable.Map[String,String] = Map(hoodie.insert.shuffle.parallelism -> 10, hoodie.datasource.write.precombine.field -> hit_timestamp, hoodie.cleaner.fileversions.retained -> 1, hoodie.delete.shuffle.parallelism -> 10, hoodie.datasource.write.operation -> upsert, hoodie.datasource.write.recordkey.field -> tds_cid, hoodie.table.name -> hudi_mor_table, hoodie.memory.merge.max.size -> 2004857600000, hoodie.cleaner.policy -> KEEP_LATEST_FILE_VERSIONS, hoodie.upsert.shuffle.parallelism -> 10, hoodie.datasource.write.partitionpath.field -> hit_date, hoodie.bulkinsert.shuffle.parallelism -> 10)
scala>
scala> inputDF.write.format("org.apache.hudi").
| options(hudiOptions).
| mode("Append").
| save(basePath)
20/04/09 09:23:53 WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf.
[Stage 3:> (0 + 4) / 10]20/04/09 09:24:55 WARN MemoryStore: Not enough space to cache rdd_16_1 in memory! (computed 87.6 MB so far)
20/04/09 09:24:55 WARN BlockManager: Persisting block rdd_16_1 to disk instead.
20/04/09 09:24:56 WARN MemoryStore: Not enough space to cache rdd_16_2 in memory! (computed 196.9 MB so far)
20/04/09 09:24:56 WARN BlockManager: Persisting block rdd_16_2 to disk instead.
20/04/09 09:24:56 WARN MemoryStore: Not enough space to cache rdd_16_0 in memory! (computed 130.8 MB so far)
20/04/09 09:24:56 WARN BlockManager: Persisting block rdd_16_0 to disk instead.
20/04/09 09:24:56 WARN MemoryStore: Not enough space to cache rdd_16_3 in memory! (computed 196.3 MB so far)
20/04/09 09:24:56 WARN BlockManager: Persisting block rdd_16_3 to disk instead.
[Stage 3:=======================> (4 + 4) / 10]20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_6 in memory! (computed 58.5 MB so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_6 to disk instead.
20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_4 in memory! (computed 58.3 MB so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_4 to disk instead.
20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_5 in memory! (computed 87.6 MB so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_5 to disk instead.
20/04/09 09:25:12 WARN MemoryStore: Failed to reserve initial memory threshold of 1024.0 KB for computing block rdd_16_7 in memory.
20/04/09 09:25:12 WARN MemoryStore: Not enough space to cache rdd_16_7 in memory! (computed 0.0 B so far)
20/04/09 09:25:12 WARN BlockManager: Persisting block rdd_16_7 to disk instead.
[Stage 3:==============================================> (8 + 2) / 10]20/04/09 09:25:26 WARN MemoryStore: Not enough space to cache rdd_16_9 in memory! (computed 58.4 MB so far)
20/04/09 09:25:26 WARN BlockManager: Persisting block rdd_16_9 to disk instead.
20/04/09 09:25:26 WARN MemoryStore: Not enough space to cache rdd_16_8 in memory! (computed 87.6 MB so far)
20/04/09 09:25:26 WARN BlockManager: Persisting block rdd_16_8 to disk instead.
[Stage 14:=======================================> (28 + 4) / 40]20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_30 in memory! (computed 39.3 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_30 to disk instead.
20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_29 in memory! (computed 58.5 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_29 to disk instead.
20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_28 in memory! (computed 58.6 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_28 to disk instead.
20/04/09 09:44:14 WARN MemoryStore: Not enough space to cache rdd_44_31 in memory! (computed 17.3 MB so far)
20/04/09 09:44:14 WARN BlockManager: Persisting block rdd_44_31 to disk instead.
[Stage 14:============================================> (32 + 4) / 40]20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_33 in memory! (computed 26.0 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_33 to disk instead.
20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_32 in memory! (computed 25.8 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_32 to disk instead.
20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_35 in memory! (computed 5.2 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_35 to disk instead.
20/04/09 09:44:19 WARN MemoryStore: Not enough space to cache rdd_44_34 in memory! (computed 5.1 MB so far)
20/04/09 09:44:19 WARN BlockManager: Persisting block rdd_44_34 to disk instead.
[Stage 14:==================================================> (36 + 4) / 40]20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_38 in memory! (computed 1032.0 KB so far)
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_38 to disk instead.
20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_36 in memory! (computed 3.4 MB so far)
20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_37 in memory! (computed 3.4 MB so far)
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_37 to disk instead.
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_36 to disk instead.
20/04/09 09:44:26 WARN MemoryStore: Not enough space to cache rdd_44_39 in memory! (computed 7.6 MB so far)
20/04/09 09:44:26 WARN BlockManager: Persisting block rdd_44_39 to disk instead.
20/04/09 09:47:19 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
scala>
scala> spark.read.format("org.apache.hudi").load(basePath + "/2020-03-19/*").count();
20/04/09 09:47:19 WARN DefaultSource: Snapshot view not supported yet via data source, for MERGE_ON_READ tables. Please query the Hive table registered using Spark SQL.
res1: Long = 5045301
scala>
scala>
```

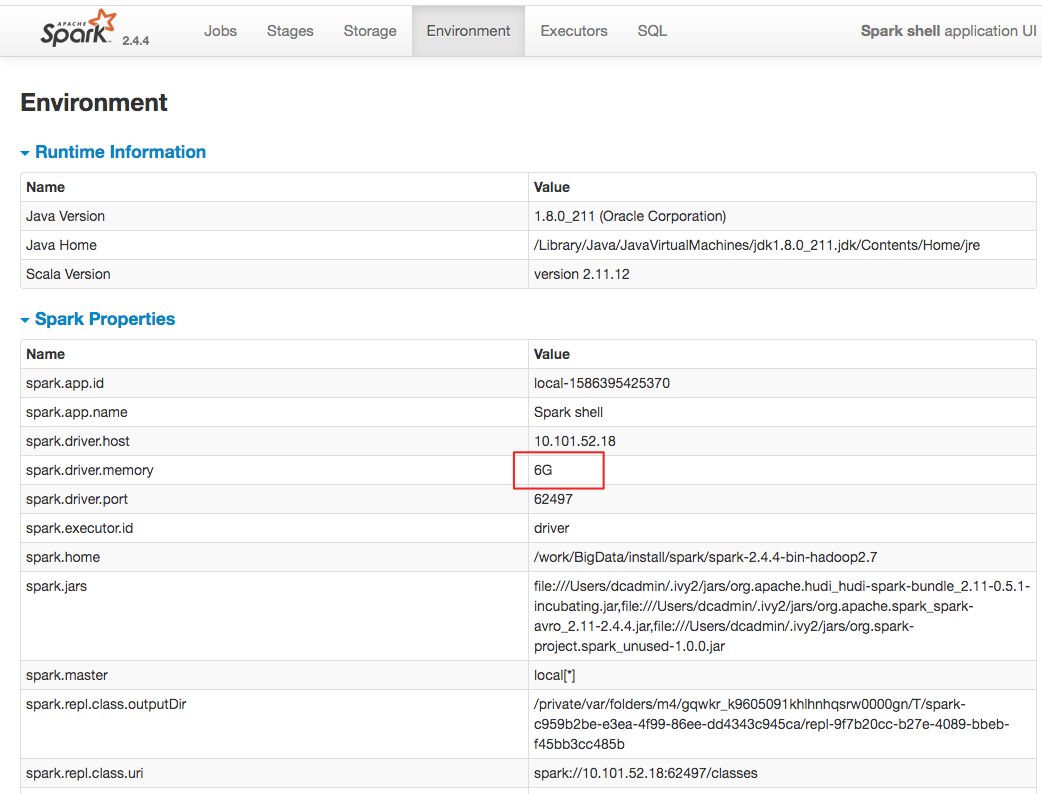
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610564674
Code:
`
sparkSession
.read
.jdbc(
url = jdbcConfig.url,
table = table,
columnName = "partition",
lowerBound = 0,
upperBound = jdbcConfig.partitionsCount.toInt,
numPartitions = jdbcConfig.partitionsCount.toInt,
connectionProperties = new Properties() {
put("driver", jdbcConfig.driver)
put("user", jdbcConfig.user)
put("password", jdbcConfig.password)
}
)
.withColumn("year", substring(col(jdbcConfig.dateColumnName), 0, 4))
.withColumn("month", substring(col(jdbcConfig.dateColumnName), 6, 2))
.withColumn("day", substring(col(jdbcConfig.dateColumnName), 9, 2))
.write
.option(HoodieWriteConfig.TABLE_NAME, hudiConfig.tableName)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, hudiConfig.recordKey)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, hudiConfig.precombineKey)
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, hudiConfig.partitionPathKey)
.option(DataSourceWriteOptions.KEYGENERATOR_CLASS_OPT_KEY, classOf[ComplexKeyGenerator].getName)
.option(DataSourceWriteOptions.HIVE_STYLE_PARTITIONING_OPT_KEY, "true")
.option("hoodie.datasource.write.operation", writeOperation)
.option("hoodie.bulkinsert.shuffle.parallelism", hudiConfig.bulkInsertParallelism)
.option("hoodie.insert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.upsert.shuffle.parallelism", hudiConfig.parallelism)
.option("hoodie.cleaner.policy", HoodieCleaningPolicy.KEEP_LATEST_FILE_VERSIONS.name())
.option("hoodie.cleaner.fileversions.retained", "1")
.option("hoodie.metrics.graphite.host", hudiConfig.graphiteHost)
.option("hoodie.metrics.graphite.port", hudiConfig.graphitePort)
.option("hoodie.metrics.graphite.metric.prefix", hudiConfig.graphiteMetricPrefix)
.format("org.apache.hudi")
.mode(SaveMode.Append)
.save(outputPath)
`
This code is executing on Jenkins, with next parameters:
`
docker run --rm -v ${PWD}:${PWD} -v /mnt/ml_data:/mnt/ml_data bde2020/spark-master:2.4.5-hadoop2.7 \
bash ./spark/bin/spark-submit \
--master "local[2]" \
--packages org.apache.hudi:hudi-spark-bundle_2.11:0.5.2-incubating,org.apache.hadoop:hadoop-aws:2.7.3,org.apache.spark:spark-avro_2.11:2.4.4 \
--conf spark.local.dir=/mnt/ml_data \
--conf spark.ui.enabled=false \
--conf spark.driver.memory=4g \
--conf spark.driver.memoryOverhead=1024 \
--conf spark.driver.maxResultSize=2g \
--conf spark.kryoserializer.buffer.max=512m \
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer \
--conf spark.rdd.compress=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.sql.hive.convertMetastoreParquet=false \
--conf spark.hadoop.fs.defaultFS=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem \
--conf spark.hadoop.fs.s3a.access.key=${AWS_ACCESS_KEY_ID} \
--conf spark.hadoop.fs.s3a.secret.key=${AWS_SECRET_ACCESS_KEY} \
--conf spark.executorEnv.period.startDate=${date} \
--conf spark.executorEnv.period.numDays=${numDays} \
--conf spark.executorEnv.jdbc.url=${VERTICA_URL} \
--conf spark.executorEnv.jdbc.user=${VERTICA_USER} \
--conf spark.executorEnv.jdbc.password=${VERTICA_PWD} \
--conf spark.executorEnv.jdbc.driver=${VERTICA_DRIVER}\
--conf spark.executorEnv.jdbc.schemaName=mtu_owner \
--conf spark.executorEnv.jdbc.tableName=ext_ml_data \
--conf spark.executorEnv.jdbc.dateColumnName=hit_date \
--conf spark.executorEnv.jdbc.partitionColumnName=hit_timestamp \
--conf spark.executorEnv.jdbc.partitionsCount=8 \
--conf spark.executorEnv.hudi.outputPath=s3a://ir-mtu-ml-bucket/ml_hudi \
--conf spark.executorEnv.hudi.tableName=ext_ml_data \
--conf spark.executorEnv.hudi.recordKey=tds_cid \
--conf spark.executorEnv.hudi.precombineKey=hit_timestamp \
--conf spark.executorEnv.hudi.parallelism=8 \
--conf spark.executorEnv.hudi.bulkInsertParallelism=8 \
--class mtu.spark.analytics.ExtMLDataToS3 \
${PWD}/ml-vertica-to-s3-hudi.jar
`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT]
OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-611161702
@lamber-ken , can you try with those params?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken edited a comment on issue #1491:
[SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-610635678
> Can you give this a shot on a cluster?
btw, what @vinothchandar wants to say is that run your snippet code on yarn cluster if possiable, so we can know how it behaves to when running in a cluster.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
[GitHub] [incubator-hudi] lamber-ken commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
lamber-ken commented on issue #1491:
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-616729550
> @lamber-ken since this has come up a few times, worth tracking a jira for 0.6 that can help get a better default for this?
Agree, https://issues.apache.org/jira/browse/HUDI-818
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] vinothchandar commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
vinothchandar commented on issue #1491:
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-616684234
@lamber-ken since this has come up a few times, worth tracking a jira for 0.6 that can help get a better default for this?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] tverdokhlebd edited a comment on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd edited a comment on issue #1491:
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-617163716
@lamber-ken, I have tested on 4GB driver memory (local[12]) file "2.csv" (5M records):
1. bulk_insert with *.parallelism 80 and without "hoodie.memory.merge.max.size" - no errors
2. upsert with *.parallelism 80 and without "hoodie.memory.merge.max.size" - no errors
3. upsert with *.parallelism 75 and without "hoodie.memory.merge.max.size" - java heap/gc overhead limit errors
4. upsert with *.parallelism 75 and with "hoodie.memory.merge.max.size" - no errors
5. upsert with *.parallelism 75 and with "hoodie.memory.merge.max.size" - issue communicating with driver in heartbeater error
So, the parameter "hoodie.memory.merge.max.size" does not guarantee that process will go without errors.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-hudi] tverdokhlebd commented on issue #1491: [SUPPORT] OutOfMemoryError during upsert 53M records
Posted by GitBox <gi...@apache.org>.
tverdokhlebd commented on issue #1491:
URL: https://github.com/apache/incubator-hudi/issues/1491#issuecomment-617163716
@lamber-ken, I have tested on 4GB driver memory (local[12]) file "2.csv" (5M records):
1. bulk_insert with *.parallelism 80 and without "hoodie.memory.merge.max.size" - no errors
2. upsert with *.parallelism 80 and without "hoodie.memory.merge.max.size" - no errors
3. upsert with *.parallelism 75 and without "hoodie.memory.merge.max.size" - java heap/gc overhead limit errors
4. upsert with *.parallelism 75 and with "hoodie.memory.merge.max.size" - no errors
5. upsert with *.parallelism 75 and with "hoodie.memory.merge.max.size" - issue communicating with driver in heartbeater error
So, the parameter "hoodie.memory.merge.max.size" does not guarantee that process goes without errors.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org