You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@shardingsphere.apache.org by yx...@apache.org on 2022/08/25 13:53:44 UTC
[shardingsphere] branch master updated: Rename url from contribute to involved (#20528)
This is an automated email from the ASF dual-hosted git repository.
yx9o pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 8c07e05affd Rename url from contribute to involved (#20528)
8c07e05affd is described below
commit 8c07e05affdbc183529d626bdea99267125b3aab
Author: Liang Zhang <zh...@apache.org>
AuthorDate: Thu Aug 25 21:53:32 2022 +0800
Rename url from contribute to involved (#20528)
---
CONTRIBUTING.md | 2 +-
MATURITY.md | 10 +-
README.md | 4 +-
README_ZH.md | 4 +-
...hnical_Deep_Dive_by_Apache_ShardingSphere.en.md | 6 +-
...nology_Budget_with_Apache_ShardingSphere.en.md" | 4 +-
...h_Availability_with_Apache_ShardingSphere.en.md | 2 +-
...eSQL_is_Improved_26.8%_with_Version_5.1.0.en.md | 4 +-
...Observability_Apache_ShardingSphere_Agent.en.md | 8 +-
...e_ShardingSphere_ Enterprise_Applications.en.md | 13 +-
..._2022_Understanding_Apache_ShardingSphere.en.md | 5 +-
...cal_Guide_to_Apache_ShardingSphere's_HINT.en.md | 4 +-
...e_Performance_Record_with_10_Million_tpmC.en.md | 2 +-
...oduction_Scenarios_Your_Quick_Start_Guide.en.md | 3 +-
..._System_with_100s_of_Millions_of_Records.en.md" | 4 +-
...Sphere_implement_distributed_transactions.en.md | 4 +-
...lity_Apache_ShardingSphere_Feature_Update.en.md | 2 +-
...ngSphere_Enterprise_Applications_Bilibili.en.md | 2 +-
...200\231s_simpler_than_Dubbo\342\200\231s.en.md" | 4 +-
...stem_RTO_60x_and_increasing_speed_by_20%.en.md" | 2 +-
...r_Apache_ShardingSphere_5.1.2_is_released.en.md | 3 +-
...2022_06_30_ShardingSphere_&_Database_Mesh.en.md | 3 +-
...river_That_Requires_No_Code_Modifications.en.md | 4 +-
...otocol_Troubleshooting_Guide_and_Examples.en.md | 3 +-
...t-of-the-box_ShardingSphere-Proxy_Cluster.en.md | 18 +-
...ity_Efficiency_and_Replicability_at_Scale.en.md | 8 +-
...s_Building_a_Dynamic_Distributed_Database.en.md | 6 +-
...hardingSphere-on-Cloud_Solution_Released.en.md" | 8 +-
...Apache_ShardingSphere_5.1.0_Now Avaliable.en.md | 4 +-
.../content/material/Feb_23_Stack_Overflow.en.md | 144 ++---
...he_ShardingSphere_Enterprise_Applications.en.md | 362 +++++------
..._Solution_Based_on_PostgreSQL_&_openGauss.en.md | 352 +++++-----
...0_The_Ideal_Database_Management_Ecosystem.en.md | 5 +-
...Sharding_Strategy_Based_on_Apache_ShardingS.md" | 712 ++++++++++-----------
...ingSphere_Shadow_Database_Feature_Upgrade.en.md | 375 ++++-------
...RDINGSPHERE\342\200\231S_OPERATING_MODES.en.md" | 238 +++----
...3_DistSQL_Cluster_Governance_Capabilities.en.md | 2 +-
.../Nov_23_1_Integrate_SCTL_into_RAL.en.md | 26 +-
...inute_Quick_Start_Guide_to_ShardingSphere.cn.md | 2 +-
...r_Butler-Like_Sharding_Configuration_Tool.cn.md | 2 +-
...r_Butler_Like_Sharding_Configuration_Tool.en.md | 2 +-
docs/blog/content/material/committer.cn.md | 6 +-
docs/blog/content/material/committer.en.md | 7 +-
docs/blog/content/material/ss_5.0.0beta.cn.md | 2 +-
docs/blog/content/material/ss_5.0.0beta.en.md | 390 ++++++-----
.../content/{contribute => involved}/2FA.cn.md | 0
.../content/{contribute => involved}/2FA.en.md | 0
.../content/{contribute => involved}/_index.cn.md | 10 +-
.../content/{contribute => involved}/_index.en.md | 12 +-
.../{contribute => involved}/committer.cn.md | 0
.../{contribute => involved}/committer.en.md | 0
.../{contribute => involved}/conduct/_index.cn.md | 0
.../{contribute => involved}/conduct/_index.en.md | 0
.../{contribute => involved}/conduct/code.cn.md | 0
.../{contribute => involved}/conduct/code.en.md | 0
.../conduct/document.cn.md | 0
.../conduct/document.en.md | 0
.../{contribute => involved}/conduct/issue.cn.md | 0
.../{contribute => involved}/conduct/issue.en.md | 0
.../{contribute => involved}/contributor.cn.md | 2 +-
.../{contribute => involved}/contributor.en.md | 2 +-
.../content/{contribute => involved}/dev-env.cn.md | 2 +-
.../content/{contribute => involved}/dev-env.en.md | 2 +-
.../document-contributor.cn.md | 2 +-
.../document-contributor.en.md | 2 +-
.../content/{contribute => involved}/icla.cn.md | 0
.../content/{contribute => involved}/icla.en.md | 0
.../{contribute => involved}/release/_index.cn.md | 0
.../{contribute => involved}/release/_index.en.md | 0
.../release/elasticjob-ui.cn.md | 4 +-
.../release/elasticjob-ui.en.md | 4 +-
.../release/elasticjob.cn.md | 4 +-
.../release/elasticjob.en.md | 4 +-
.../release/shardingsphere.cn.md | 2 +-
.../release/shardingsphere.en.md | 2 +-
.../{contribute => involved}/subscribe.cn.md | 0
.../{contribute => involved}/subscribe.en.md | 0
.../content/{contribute => involved}/vote.cn.md | 5 +-
.../content/{contribute => involved}/vote.en.md | 4 +-
docs/community/content/team/_index.cn.md | 2 +-
docs/community/content/team/_index.en.md | 2 +-
docs/community/layouts/index.html | 2 +-
.../src/main/release-docs/README.txt | 2 +-
.../src/main/release-docs/README.txt | 2 +-
84 files changed, 1362 insertions(+), 1484 deletions(-)
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 7b2eaf47094..fb10f706721 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -28,7 +28,7 @@ You can report a bug, submit a new feature enhancement recommendation, or commit
- Reply a deadline message to pickup this issue.
- Find a mentor in [Core developers list](https://shardingsphere.apache.org/community/en/team/), he will give you feedback for design and implements.
- Fork to your github repo and begin to work.
- - Please follow Sharding's [Development conventions](https://shardingsphere.apache.org/community/en/contribute/conduct/code/), and complete check before pull request submit.
+ - Please follow Sharding's [Development conventions](https://shardingsphere.apache.org/community/en/involved/conduct/code/), and complete check before pull request submit.
- Submit a pull request to master branch when finished.
- Mentor will do code review and discuss some details, include design, implement, performance and code style. Code will be merged until mentor accepted.
- Finally, congratulations that you have become the official contributor for Apache ShardingSphere.
diff --git a/MATURITY.md b/MATURITY.md
index f78e8aea59d..96d380c3c94 100644
--- a/MATURITY.md
+++ b/MATURITY.md
@@ -22,7 +22,7 @@ Mentors and community members are encouraged to contribute to this page and comm
| **CD20** | The project's code is easily discoverable and publicly accessible. | **YES.** The [website](https://shardingsphere.apache.org/) includes `SCM` link which can access GitHub directly. |
| **CD30** | The code can be built in a reproducible way using widely available standard tools. | **YES.** The build uses Apache Maven and Jenkins as the continuous integration tools, user can find `How to Build` in the [GitHub's README.md](https://github.com/apache/incubator-shardingsphere/blob/dev/RE [...]
| **CD40** | The full history of the project's code is available via a source code control system, in a way that allows any released version to be recreated. | **YES.** The project uses git to manage source code, demo code, documentation and website, all releases are tagged. |
-| **CD50** | The provenance of each line of code is established via the source code control system, in a reliable way based on strong authentication of the committer. When third-party contributions are committed, commit messages provide reliable information about the code provenance. | **YES.** The project uses GitHub which managed by Apache Infra, it ensuring provenance of each line of code to a committer. The third-party contributions are accepted in accordance with the [contributor gu [...]
+| **CD50** | The provenance of each line of code is established via the source code control system, in a reliable way based on strong authentication of the committer. When third-party contributions are committed, commit messages provide reliable information about the code provenance. | **YES.** The project uses GitHub which managed by Apache Infra, it ensuring provenance of each line of code to a committer. The third-party contributions are accepted in accordance with the [contributor gu [...]
**Licenses and Copyright**
@@ -42,7 +42,7 @@ Mentors and community members are encouraged to contribute to this page and comm
| **RE20** | Releases are approved by the project's PMC (see CS10), in order to make them an act of the Foundation. | **YES.** All releases have been voted by ShardingSphere community and incubator, which have least 3 (P)PMC votes. |
| **RE30** | Releases are signed and/or distributed along with digests that can be reliably used to validate the downloaded archives. | **YES.** All releases are signed, and the [KEYS file](https://dist.apache.org/repos/dist/release/incubator/shardingsphere/KEYS) is provided on dist.apache.org. |
| **RE40** | Convenience binaries can be distributed alongside source code but they are not Apache Releases -- they are just a convenience provided with no guarantee. | **YES.** Convenience binaries are distributed via [Maven Central Repository](https://mvnrepository.com/artifact/org.apache.shardingsphere), [DockerHub](https://hub.docker.com/r/apache/sharding-proxy/tags) [...]
-| **RE50** | The release process is documented and repeatable to the extent that someone new to the project is able to independently generate the complete set of artifacts required for a release. | **YES.** [Release guide](https://shardingsphere.apache.org/community/en/contribute/release/) is available. The releases of the project have been performed by 3 different release managers. |
+| **RE50** | The release process is documented and repeatable to the extent that someone new to the project is able to independently generate the complete set of artifacts required for a release. | **YES.** [Release guide](https://shardingsphere.apache.org/community/en/involved/release/) is available. The releases of the project have been performed by 3 different release managers. |
**Quality**
@@ -59,10 +59,10 @@ Mentors and community members are encouraged to contribute to this page and comm
| **ID** | **Description** | **Status** |
| -------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | ---------- |
| **CO10** | The project has a well-known homepage that points to all the information required to operate according to this maturity model. | **YES.** The [website](https://shardingsphere.apache.org/) describes of the project with download, user manual, technical details, how to contribute and team introduce. |
-| **CO20** | The community welcomes contributions from anyone who acts in good faith and in a respectful manner and adds value to the project. | **YES.** There is [contributor guide](https://shardingsphere.apache.org/community/en/contribute/contributor/) and the current committers are really welcome contributions. |
-| **CO30** | Contributions include not only source code, but also documentation, constructive bug reports, constructive discussions, marketing and generally anything that adds value to the project. | **YES.** The contribution guide refers to non source code contribution, like [documentation](https://shardingsphere.apache.org/community/en/contribute/document-contributor/). The community has elected some [...]
+| **CO20** | The community welcomes contributions from anyone who acts in good faith and in a respectful manner and adds value to the project. | **YES.** There is [contributor guide](https://shardingsphere.apache.org/community/en/involved/contributor/) and the current committers are really welcome contributions. |
+| **CO30** | Contributions include not only source code, but also documentation, constructive bug reports, constructive discussions, marketing and generally anything that adds value to the project. | **YES.** The contribution guide refers to non source code contribution, like [documentation](https://shardingsphere.apache.org/community/en/involved/document-contributor/). The community has elected some n [...]
| **CO40** | The community strives to be meritocratic and over time aims to give more rights and responsibilities to contributors who add value to the project. | **YES.** The community has elected 2 new PPMC members and 4 new committers during incubation, based on meritocracy. |
-| **CO50** | The way in which contributors can be granted more rights such as commit access or decision power is clearly documented and is the same for all contributors. | **YES.** The criteria is documented in the [committer guide](https://shardingsphere.apache.org/community/en/contribute/committer/). |
+| **CO50** | The way in which contributors can be granted more rights such as commit access or decision power is clearly documented and is the same for all contributors. | **YES.** The criteria is documented in the [committer guide](https://shardingsphere.apache.org/community/en/involved/committer/). |
| **CO60** | The community operates based on consensus of its members (see CS10) who have decision power. Dictators, benevolent or not, are not welcome in Apache projects. | **YES.** The project works to build consensus. All votes have been unanimous so far. |
| **CO70** | The project strives to answer user questions in a timely manner. | **YES.** The project typically provides detailed answers to user questions within a few days via [dev@ mailing list](mailto:dev@shardingsphere.apache.org) and [GitHub issues](https://github.com/apache/incu [...]
diff --git a/README.md b/README.md
index e9e4e336fd2..d8d42c91979 100644
--- a/README.md
+++ b/README.md
@@ -54,7 +54,7 @@ For full documentation & more details, visit: [Docs](https://shardingsphere.apac
<hr>
-For guides on how to get started and setup your environment, contributor & committer guides, visit: [Contribution Guidelines](https://shardingsphere.apache.org/community/en/contribute/)
+For guides on how to get started and setup your environment, contributor & committer guides, visit: [Contribution Guidelines](https://shardingsphere.apache.org/community/en/involved/)
### Team
@@ -68,7 +68,7 @@ We deeply appreciate [community contributors](https://shardingsphere.apache.org/
<hr>
-:link: [Mailing List](https://shardingsphere.apache.org/community/en/contribute/subscribe/). Best for: Apache community updates, releases, changes.
+:link: [Mailing List](https://shardingsphere.apache.org/community/en/involved/subscribe/). Best for: Apache community updates, releases, changes.
:link: [GitHub Issues](https://github.com/apache/shardingsphere/issues). Best for: larger systemic questions/bug reports or anything development related.
diff --git a/README_ZH.md b/README_ZH.md
index e4f7df6276e..e15c2f90a78 100644
--- a/README_ZH.md
+++ b/README_ZH.md
@@ -48,7 +48,7 @@ ShardingSphere 已于 2020 年 4 月 16 日成为 [Apache 软件基金会](https
<hr>
-搭建开发环境和贡献者指南,请参考:[https://shardingsphere.apache.org/community/cn/contribute/](https://shardingsphere.apache.org/community/cn/contribute/)
+搭建开发环境和贡献者指南,请参考:[https://shardingsphere.apache.org/community/cn/involved/](https://shardingsphere.apache.org/community/cn/involved/)
### 团队成员
@@ -62,7 +62,7 @@ ShardingSphere 已于 2020 年 4 月 16 日成为 [Apache 软件基金会](https
<hr>
-:link: [Mailing List](https://shardingsphere.apache.org/community/cn/contribute/subscribe/). 适合于 Apache 社区相关讨论和版本发布;
+:link: [Mailing List](https://shardingsphere.apache.org/community/cn/involved/subscribe/). 适合于 Apache 社区相关讨论和版本发布;
:link: [GitHub Issues](https://github.com/apache/shardingsphere/issues). 适合于设计问题、缺陷报告或者开发相关;
diff --git a/docs/blog/content/material/2022_03_09_SQL_Parse_Format_Function_A _Technical_Deep_Dive_by_Apache_ShardingSphere.en.md b/docs/blog/content/material/2022_03_09_SQL_Parse_Format_Function_A _Technical_Deep_Dive_by_Apache_ShardingSphere.en.md
index 812086c3670..0e56080a256 100644
--- a/docs/blog/content/material/2022_03_09_SQL_Parse_Format_Function_A _Technical_Deep_Dive_by_Apache_ShardingSphere.en.md
+++ b/docs/blog/content/material/2022_03_09_SQL_Parse_Format_Function_A _Technical_Deep_Dive_by_Apache_ShardingSphere.en.md
@@ -263,22 +263,24 @@ mysql> parse SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18;
For more [DistSQL](https://opensource.com/article/21/9/distsql) functions, please refer to the documentation: [https://shardingsphere.apache.org/document/current/cn/concepts/distsql/](https://shardingsphere.apache.org/document/current/cn/concepts/distsql/)
## Conclusion
+
Currently, Apache ShardingSphere’s Format function only supports [MySQL](https://www.mysql.com/). After understanding its concept and how to use it, if you’re interested, you are welcome to contribute to developing the SQL Parse Format function.
### Apache ShardingSphere Open Source Project Links:
+
[ShardingSphere Github
](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
## Author
+
**Chen Chuxin**

> SphereEx Middleware Engineer & Apache ShardingSphere Committer
> Currently, he devotes himself to developing the kernel module of Apache ShardingSphere.
-
diff --git "a/docs/blog/content/material/2022_03_11_Asia\342\200\231s_E-Commerce_Giant_Dangdang_Increases_Order_Processing_Speed_by_30%_Saves_Over_Ten_Million_in_Technology_Budget_with_Apache_ShardingSphere.en.md" "b/docs/blog/content/material/2022_03_11_Asia\342\200\231s_E-Commerce_Giant_Dangdang_Increases_Order_Processing_Speed_by_30%_Saves_Over_Ten_Million_in_Technology_Budget_with_Apache_ShardingSphere.en.md"
index 26e835d0b1c..e1989168749 100644
--- "a/docs/blog/content/material/2022_03_11_Asia\342\200\231s_E-Commerce_Giant_Dangdang_Increases_Order_Processing_Speed_by_30%_Saves_Over_Ten_Million_in_Technology_Budget_with_Apache_ShardingSphere.en.md"
+++ "b/docs/blog/content/material/2022_03_11_Asia\342\200\231s_E-Commerce_Giant_Dangdang_Increases_Order_Processing_Speed_by_30%_Saves_Over_Ten_Million_in_Technology_Budget_with_Apache_ShardingSphere.en.md"
@@ -118,15 +118,17 @@ Recently, to celebrate the third anniversary of ShardingSphere entering Apache S
Since Version 5.0.0, Apache ShardingSphere has embarked on its new journey: with the plugin oriented architect at its core, it evloved from a data sharding application to a comprehensive and enhanced data governance tool applicable to various complex application scenarios. Concurrently, Apache ShardingSphere also has more features, and big data solutions.
## Conclusion
+
Digitization motivated Dangdang to achieve high-quality development and fulfill its mission. ShardingSphere is glad to support Dangdang’s WMS with its cutting-edging data services.
Having gone through two years‘ development, Apache ShardingSphere 5.0.0 GA has been released. The pluggable ecosystem marks an evolution from a data sharding middleware tool to a pioneer in the industry following the “Database Plus” concept.
## Apache ShardingSphere Project Links:
+
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
diff --git a/docs/blog/content/material/2022_03_16_Create_a_Distributed_Database_with_High_Availability_with_Apache_ShardingSphere.en.md b/docs/blog/content/material/2022_03_16_Create_a_Distributed_Database_with_High_Availability_with_Apache_ShardingSphere.en.md
index 6c883ecb30d..382f92818d1 100644
--- a/docs/blog/content/material/2022_03_16_Create_a_Distributed_Database_with_High_Availability_with_Apache_ShardingSphere.en.md
+++ b/docs/blog/content/material/2022_03_16_Create_a_Distributed_Database_with_High_Availability_with_Apache_ShardingSphere.en.md
@@ -448,7 +448,7 @@ As always, if you’re interested, you’re more than welcome to join us and con
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
## Author
diff --git a/docs/blog/content/material/2022_03_23_Apache_ShardingSphere_Proxy_Performance_with_PostgreSQL_is_Improved_26.8%_with_Version_5.1.0.en.md b/docs/blog/content/material/2022_03_23_Apache_ShardingSphere_Proxy_Performance_with_PostgreSQL_is_Improved_26.8%_with_Version_5.1.0.en.md
index f9c90850e9d..9fc0c713bdc 100644
--- a/docs/blog/content/material/2022_03_23_Apache_ShardingSphere_Proxy_Performance_with_PostgreSQL_is_Improved_26.8%_with_Version_5.1.0.en.md
+++ b/docs/blog/content/material/2022_03_23_Apache_ShardingSphere_Proxy_Performance_with_PostgreSQL_is_Improved_26.8%_with_Version_5.1.0.en.md
@@ -297,9 +297,10 @@ Apache ShardingSphere Open Source Project Links:
[ShardingSphere Github](https://github.com/apache/shardingsphere)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/ssb/redirect)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
### Author
+
Wu Weijie
> SphereEx Infrastructure R&D Engineer & Apache ShardingSphere Committer
@@ -307,4 +308,3 @@ Wu Weijie
Wu now focuses on the research and development of Apache ShardingSphere and its sub-project ElasticJob.

-
diff --git a/docs/blog/content/material/2022_03_25_A_Deep_Dive_Into_Observability_Apache_ShardingSphere_Agent.en.md b/docs/blog/content/material/2022_03_25_A_Deep_Dive_Into_Observability_Apache_ShardingSphere_Agent.en.md
index a2dfceb5e60..5e61d9f496c 100644
--- a/docs/blog/content/material/2022_03_25_A_Deep_Dive_Into_Observability_Apache_ShardingSphere_Agent.en.md
+++ b/docs/blog/content/material/2022_03_25_A_Deep_Dive_Into_Observability_Apache_ShardingSphere_Agent.en.md
@@ -175,6 +175,7 @@ Through a careful search of Span, we can check the tracing status of SQL stateme

## Topology Mapping
+
We cannot find topology mappings when we check dependencies through Zipkin Web.
So, we need to configure them:
@@ -195,9 +196,9 @@ After performing the same access test as before, we can view dependencies throug

-
## Sampling Rate
+
The Observability plugin also enables users to set differnt sampling rate configured to suit different scenarios. Zipkin plugins support various sampling rate type configurations including const, counting, rate limiting, and boundary.
For scenarios with a high volume of requests, we suggest you to choose the boundary type and configure it with the appropriate sampling rate to reduce the collect volume of tracing data.
@@ -214,20 +215,23 @@ Zipkin:
```
## Summary
+
With the Observability plugin compatible with many common monitoring frameworks and systems by default, users can easily monitor and manage Apache ShardingSphere.
In the future, we will continue to enhance the monitoring capability.
## Apache ShardingSphere Open Source Project Links:
+
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://twitter.com/ShardingSphere)
-[Contributor Guideline](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guideline](https://shardingsphere.apache.org/community/cn/involved/)
## Co-Authors
+

Pingchuan JIANG
diff --git a/docs/blog/content/material/2022_03_29_CITIC_Industrial_Cloud_Apache_ShardingSphere_ Enterprise_Applications.en.md b/docs/blog/content/material/2022_03_29_CITIC_Industrial_Cloud_Apache_ShardingSphere_ Enterprise_Applications.en.md
index 8b32f7993e3..92db2965133 100644
--- a/docs/blog/content/material/2022_03_29_CITIC_Industrial_Cloud_Apache_ShardingSphere_ Enterprise_Applications.en.md
+++ b/docs/blog/content/material/2022_03_29_CITIC_Industrial_Cloud_Apache_ShardingSphere_ Enterprise_Applications.en.md
@@ -16,8 +16,6 @@ Now, CITIC Industrial Cloud is exploring how to innovate with existing database
As one of the most prominent open source middleware projects, with its ever-expanding ecosystem,[Apache ShardingSphere](https://shardingsphere.apache.org/) can meet some of CITIC Industrial Cloud’s technology needs in its development roadmap.
-
-
## Ensuring Data Consistency in Data Migration
Enterprises are challenged by ever expanding data related issues. Luckily, Scale-out can solve this problem.
@@ -33,6 +31,7 @@ Apache ShardingSphere can divide data migration into multiple sessions and execu
Additionally, SQL execution is suspended during the read-only period since the data is globally consistent when write is disabled. Accordingly, the impact on system usability will be reduced when performing database switches.
## JDBC and Proxy are Designed for Different Core Users
+
Apache ShardingSphere now supports access through JDBC and Proxy together with Mesh in the cloud (TODO). Users can choose the product that can best suit their needs to perform operations such as data sharding, read/write splitting, and data migration on original clusters.
[ShardingSphere-JDBC](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-jdbc) is designed for Java developers. It’s positioned as a lightweight Java framework, or as an enhanced JDBC driver with higher performance. If the performance loss is between 2% and 7%, and you want to optimize the performance, ShardingSphere-JDBC can help reduce the loss to less than 0.1%. Developers can directly access databases through the JDBC client and the service is provided in [...]
@@ -50,6 +49,7 @@ While JDBC can boost development efficiency, Proxy can deliver better O&M perfor
Thanks to the combination of ShardingSphere-JDBC and ShardingSphere-Proxy, while adopting the same sharding strategy in one registry center, ShardingSphere can create an application system suitable for all scenarios. This database gateway-like model allows users to manage all underlying database clusters through Proxy and observe distributed cluster status through SQL, and it can, therefore, enable maintainers and architects to adjust the system architecture to the one that can perfectly [...]
## ShardingSphere Federated Queries
+
SQL Federation queries are a query mode providing cross-database querying capabilities. Users can execute queries without storing the data in the same database.
The SQL Federation engine contains processes such as SQL Parser, SQL Binder, SQL Optimizer, Data Fetcher and Operator Calculator, suitable for dealing with co-related queries and subqueries cross multiple database instances. At the underlying layer, it uses [Calcite](https://calcite.apache.org/) to implement RBO (Rule Based Optimizer) and CBO (Cost Based Optimizer) based on relational algebra, and query the results through the optimal execution plan.
@@ -59,13 +59,14 @@ As concepts such as data warehouse and data lake are gaining popularity, the app
If the user needs to perform a Federation query in a relational database, it can be easily implemented by ShardingSphere. Although data lake deployment is rather complex, ShardingSphere allows federated computations for data inside and outside the data lake by docking with databases, achieving `LEFT OUTER JOIN`,` RIGHT OUTER JOIN`, complex aggregate queries, etc.
## Apache ShardingSphere Project Links:
+
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://apacheshardingsphere.slack.com/ssb/redirect)
[
-Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
Author
Yacine Si Tayeb
@@ -73,9 +74,3 @@ Yacine Si Tayeb
SphereEx Head of International Operations
Apache ShardingSphere Contributor
Passionate about technology and innovation, Yacine moved to Beijing to pursue his Ph.D. in Business Administration and fell in awe of the local startup and tech scene. His career path has so far been shaped by opportunities at the intersection of technology and business. Recently he took on a keen interest in the development of the ShardingSphere database middleware ecosystem and Open-Source community building.
-
-
-
-
-
-
diff --git a/docs/blog/content/material/2022_04_06_A_Holistic_Pluggable_Platform_for_Data_Sharding_ICDE_2022_Understanding_Apache_ShardingSphere.en.md b/docs/blog/content/material/2022_04_06_A_Holistic_Pluggable_Platform_for_Data_Sharding_ICDE_2022_Understanding_Apache_ShardingSphere.en.md
index e3ce7252577..8350558eadb 100644
--- a/docs/blog/content/material/2022_04_06_A_Holistic_Pluggable_Platform_for_Data_Sharding_ICDE_2022_Understanding_Apache_ShardingSphere.en.md
+++ b/docs/blog/content/material/2022_04_06_A_Holistic_Pluggable_Platform_for_Data_Sharding_ICDE_2022_Understanding_Apache_ShardingSphere.en.md
@@ -230,18 +230,21 @@ We also tested the effect of the maximum connections MaxCon on efficiency. The r
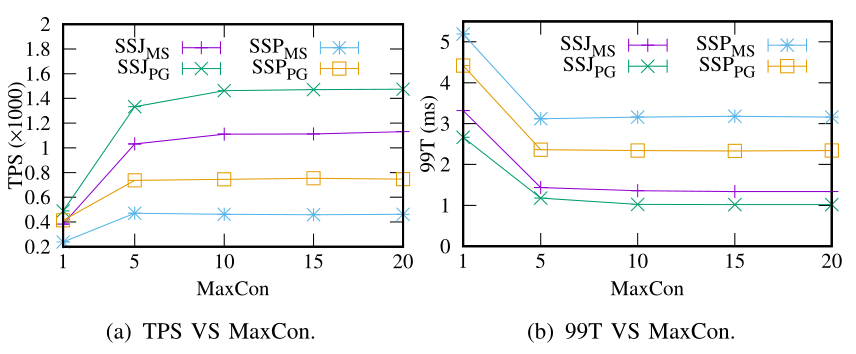
## Conclusion
+
With Extensive experiments completed by using two well-known benchmarking tools, we verify that under such settings, ShardingSphere outperforms other sharding systems and databases with new architectures in most cases.
As more and more companies are adopting ShardingSphere, we will continue to follow the development guidance concept Database Plus and provide more products to build an plugin-oriented ecosystem with enhanced functions.
## Author
+
Zheng LI, Chongqing University Spatio-Temporal Lab (CUST)
## Apache ShardingSphere Project Links:
+
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
diff --git a/docs/blog/content/material/2022_04_13_A_Practical_Guide_to_Apache_ShardingSphere's_HINT.en.md b/docs/blog/content/material/2022_04_13_A_Practical_Guide_to_Apache_ShardingSphere's_HINT.en.md
index 1832b9c3b70..ea70231ed01 100644
--- a/docs/blog/content/material/2022_04_13_A_Practical_Guide_to_Apache_ShardingSphere's_HINT.en.md
+++ b/docs/blog/content/material/2022_04_13_A_Practical_Guide_to_Apache_ShardingSphere's_HINT.en.md
@@ -374,15 +374,17 @@ Below are the relevant statements of DistSQL HINT.
This blog introduced the two methods and basic principles of HINT in detail. Once you develop a basic understanding of HINT, you’ll be able to better select the most appropriate method.
## Apache ShardingSphere Project Links:
+
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
## Author
+
**Chuxin CHEN**
SphereEx Middleware Engineer & Apache ShardingSphere Committer
diff --git a/docs/blog/content/material/2022_04_21_Apache_ShardingSphere_openGauss_Breaking_the Distributed_Database_Performance_Record_with_10_Million_tpmC.en.md b/docs/blog/content/material/2022_04_21_Apache_ShardingSphere_openGauss_Breaking_the Distributed_Database_Performance_Record_with_10_Million_tpmC.en.md
index bdb2d9c6c25..ff488479391 100644
--- a/docs/blog/content/material/2022_04_21_Apache_ShardingSphere_openGauss_Breaking_the Distributed_Database_Performance_Record_with_10_Million_tpmC.en.md
+++ b/docs/blog/content/material/2022_04_21_Apache_ShardingSphere_openGauss_Breaking_the Distributed_Database_Performance_Record_with_10_Million_tpmC.en.md
@@ -91,4 +91,4 @@ Apache ShardingSphere Project Links:
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
diff --git a/docs/blog/content/material/2022_04_26_How_to_Use_ShardingSphere-Proxy_in_Real_Production_Scenarios_Your_Quick_Start_Guide.en.md b/docs/blog/content/material/2022_04_26_How_to_Use_ShardingSphere-Proxy_in_Real_Production_Scenarios_Your_Quick_Start_Guide.en.md
index 0a31220a20e..6daeb070d09 100644
--- a/docs/blog/content/material/2022_04_26_How_to_Use_ShardingSphere-Proxy_in_Real_Production_Scenarios_Your_Quick_Start_Guide.en.md
+++ b/docs/blog/content/material/2022_04_26_How_to_Use_ShardingSphere-Proxy_in_Real_Production_Scenarios_Your_Quick_Start_Guide.en.md
@@ -372,9 +372,10 @@ Since you now have a better understanding of ShardingSphere-Proxy, we believe, i
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
## References
+
[1]Apache ShardingSphere Download Page:
https://shardingsphere.apache.org/document/current/en/downloads/
diff --git "a/docs/blog/content/material/2022_04_29_Apache_ShardingSphere_Enterprise_Applications_Zhuanzhuan\342\200\231s_Transaction_System_with_100s_of_Millions_of_Records.en.md" "b/docs/blog/content/material/2022_04_29_Apache_ShardingSphere_Enterprise_Applications_Zhuanzhuan\342\200\231s_Transaction_System_with_100s_of_Millions_of_Records.en.md"
index bb3e85d5bd9..582d976de16 100644
--- "a/docs/blog/content/material/2022_04_29_Apache_ShardingSphere_Enterprise_Applications_Zhuanzhuan\342\200\231s_Transaction_System_with_100s_of_Millions_of_Records.en.md"
+++ "b/docs/blog/content/material/2022_04_29_Apache_ShardingSphere_Enterprise_Applications_Zhuanzhuan\342\200\231s_Transaction_System_with_100s_of_Millions_of_Records.en.md"
@@ -99,9 +99,9 @@ The following is a comparison of the number of interface calls of the order plac
**Promotion after adopting ShardingSphere**

-
## Summary
+
ShardingSphere simplifies the development of data sharding with its well-designed architecture, highly flexible, pluggable and scalable capabilities, allowing R&D teams to focus only on the business itself, thus enabling flexible scaling of the data architecture.
**Apache ShardingSphere Project Links:**
@@ -112,4 +112,4 @@ ShardingSphere simplifies the development of data sharding with its well-designe
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
\ No newline at end of file
diff --git a/docs/blog/content/material/2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md b/docs/blog/content/material/2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md
index 384ee9d9859..200ded33e51 100644
--- a/docs/blog/content/material/2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md
+++ b/docs/blog/content/material/2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md
@@ -254,6 +254,7 @@ mysql> select * from account;
```
## Future plan
+
Currently, ShardingSphere’s distributed transaction integrates the 2PC implementation scheme of the 3rd party to guarantee atomicity. Isolation depends on the isolation guarantee of the storage DB, providing available transaction functions.
The future implementation of MVCC based on global Timestamp and combined with 2PC, will provide better support for transaction isolation semantics.
@@ -265,7 +266,7 @@ The future implementation of MVCC based on global Timestamp and combined with 2P
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
## Author
@@ -274,4 +275,3 @@ Lu Jingshang
> [Apache ShardingSphere](https://shardingsphere.apache.org/) Committer & Infrastructure R&D Engineer at [SphereEx](https://www.sphere-ex.com/).
> Enthusiastic about open source and database technology.
> Focus on developing Apache ShardingSphere transaction module.
-
diff --git a/docs/blog/content/material/2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md b/docs/blog/content/material/2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
index b2eac41cbb3..856a0d9606c 100644
--- a/docs/blog/content/material/2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
+++ b/docs/blog/content/material/2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
@@ -433,7 +433,7 @@ github.com
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
**Authors**
**Longtao JIANG**
diff --git a/docs/blog/content/material/2022_06_10_Apache_ShardingSphere_Enterprise_Applications_Bilibili.en.md b/docs/blog/content/material/2022_06_10_Apache_ShardingSphere_Enterprise_Applications_Bilibili.en.md
index 1660cf44a61..616e319f0bd 100644
--- a/docs/blog/content/material/2022_06_10_Apache_ShardingSphere_Enterprise_Applications_Bilibili.en.md
+++ b/docs/blog/content/material/2022_06_10_Apache_ShardingSphere_Enterprise_Applications_Bilibili.en.md
@@ -90,4 +90,4 @@ If we both agree that ShardingSphere is suitable for your business scenarios, ou
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
diff --git "a/docs/blog/content/material/2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it\342\200\231s_simpler_than_Dubbo\342\200\231s.en.md" "b/docs/blog/content/material/2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it\342\200\231s_simpler_than_Dubbo\342\200\231s.en.md"
index 3354bc44f22..7eebdcf246f 100644
--- "a/docs/blog/content/material/2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it\342\200\231s_simpler_than_Dubbo\342\200\231s.en.md"
+++ "b/docs/blog/content/material/2022_06_16_Understanding_Apache_ShardingSphere's_SPI_and_why_it\342\200\231s_simpler_than_Dubbo\342\200\231s.en.md"
@@ -250,11 +250,13 @@ public static <T> Collection<T> newServiceInstances(final Class<T> service) {
return result;
}
```
+
You can see that it is also very simple to find all implementations class returns of the interface directly in `SERVICES` registered through the static code block.
Although short, this short walkthrough basically introduced ShardingSphere’s SPI source code. We’re sure that you have already noticed it’s much easier and simpler to work with ShardingSphere’s SPI than Dubbo's SPI mechanism.
## Summary
+
Both ShardingSphere and Dubbo’s SPIs meet the requirement of finding the specified implementation class by key, without having to reload all the implementation classes every time you use it, solving the concurrent loading problem. However, compared to Dubbo, the ShardingSphere SPI is more streamlined and easier to use.
You can refer to the ShardingSphere implementation later on when writing your own SPI extensions, as it is simpler to implement, and elegant to work with. You can write an expandable configuration file parser based on SPI so that we can understand what SPI is capable of as well as its application scenarios.
@@ -267,4 +269,4 @@ You can refer to the ShardingSphere implementation later on when writing your ow
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
diff --git "a/docs/blog/content/material/2022_06_21_Heterogeneous_migration_reducing_Dangdang\342\200\231s_customer_system_RTO_60x_and_increasing_speed_by_20%.en.md" "b/docs/blog/content/material/2022_06_21_Heterogeneous_migration_reducing_Dangdang\342\200\231s_customer_system_RTO_60x_and_increasing_speed_by_20%.en.md"
index 07ca575f588..ec35428273f 100644
--- "a/docs/blog/content/material/2022_06_21_Heterogeneous_migration_reducing_Dangdang\342\200\231s_customer_system_RTO_60x_and_increasing_speed_by_20%.en.md"
+++ "b/docs/blog/content/material/2022_06_21_Heterogeneous_migration_reducing_Dangdang\342\200\231s_customer_system_RTO_60x_and_increasing_speed_by_20%.en.md"
@@ -127,4 +127,4 @@ Apache ShardingSphere provides strong support for enterprise systems, as the pro
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
\ No newline at end of file
diff --git a/docs/blog/content/material/2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new API driver_Apache_ShardingSphere_5.1.2_is_released.en.md b/docs/blog/content/material/2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new API driver_Apache_ShardingSphere_5.1.2_is_released.en.md
index 7aae790320b..731767727db 100644
--- a/docs/blog/content/material/2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new API driver_Apache_ShardingSphere_5.1.2_is_released.en.md
+++ b/docs/blog/content/material/2022_06_28_Cloud_native_deployment_for_a_high-performance_data_gateway_new API driver_Apache_ShardingSphere_5.1.2_is_released.en.md
@@ -393,13 +393,14 @@ Thanks to the efforts made by the 54 ShardingSphere contributors, who submitted
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
[Download Link](https://shardingsphere.apache.org/document/current/cn/downloads/)
[Release Notes](https://github.com/apache/shardingsphere/blob/master/RELEASE-NOTES.md)
## Author
+
**Weijie Wu**
**SphereEx Infrastructure R&D Engineer, Apache ShardingSphere PMC**
diff --git a/docs/blog/content/material/2022_06_30_ShardingSphere_&_Database_Mesh.en.md b/docs/blog/content/material/2022_06_30_ShardingSphere_&_Database_Mesh.en.md
index 1928ede9f65..0f411fb76d4 100644
--- a/docs/blog/content/material/2022_06_30_ShardingSphere_&_Database_Mesh.en.md
+++ b/docs/blog/content/material/2022_06_30_ShardingSphere_&_Database_Mesh.en.md
@@ -102,6 +102,7 @@ If you think of ShardingSphere as a high-performance distributed database, gover
So while it can be governed, ShardingSphere itself does not necessarily require support as its design concept, Database Plus, is to enhance those capabilities that MySQL itself does not inherently possess through connectivity, enhancement, and pluggability. Through ShardingSphere, a native database can be combined with the underlying database to deploy more computing power on the application side, turning it into a high-performance distributed database that avoids wasting resources and p [...]
## Opportunities in cloud-native scenarios
+
Next, let’s take a look at the industry. As we all know, the cloud represents the future, the irreversible direction. Therefore, whether a project, a product, or an idea can serve this cause will directly affect its lifecycle and impact. This is why ShardingSphere is so committed to its cloud-based initiatives.
Guided by the Database Plus concept, Apache ShardingSphere can extend existing features to provide enterprises and cloud computing platforms with more powerful capabilities across different database products. The underlying compatibility with multiple databases and with all kinds of database products in the cloud makes R&D tasks seamless.
@@ -119,7 +120,7 @@ Both can provide solutions based on the existing fragmented ecosystem of databas
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
[Download Link](https://shardingsphere.apache.org/document/current/cn/downloads/)
diff --git a/docs/blog/content/material/2022_07_06_ShardingSphere-JDBC_Driver_Released_A_JDBC_Driver_That_Requires_No_Code_Modifications.en.md b/docs/blog/content/material/2022_07_06_ShardingSphere-JDBC_Driver_Released_A_JDBC_Driver_That_Requires_No_Code_Modifications.en.md
index 9f194dda268..5d1b11fdbeb 100644
--- a/docs/blog/content/material/2022_07_06_ShardingSphere-JDBC_Driver_Released_A_JDBC_Driver_That_Requires_No_Code_Modifications.en.md
+++ b/docs/blog/content/material/2022_07_06_ShardingSphere-JDBC_Driver_Released_A_JDBC_Driver_That_Requires_No_Code_Modifications.en.md
@@ -88,11 +88,13 @@ try (
}
}
```
+
**Reference**
- [JDBC driver](https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/jdbc-driver/)
## Conclusion
+
ShardingSphere-JDBC Driver officially makes ShardingSphere easier to use than ever before.
In the coming future, the JDBC driver can be further simplified by providing the governance center address directly in the `URL`. Apache ShardingSphere has made great strides towards diversified distributed clusters.
@@ -100,7 +102,7 @@ In the coming future, the JDBC driver can be further simplified by providing the
**Relevant Links:**
[GitHub issue](https://github.com/apache/shardingsphere/issues)
-[Contributor Guide](https://shardingsphere.apache.org/community/en/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/en/involved/)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
diff --git a/docs/blog/content/material/2022_07_08_ShardingSphere-Proxy_Front-End_Protocol_Troubleshooting_Guide_and_Examples.en.md b/docs/blog/content/material/2022_07_08_ShardingSphere-Proxy_Front-End_Protocol_Troubleshooting_Guide_and_Examples.en.md
index 60bcec1a2c9..7b559844747 100644
--- a/docs/blog/content/material/2022_07_08_ShardingSphere-Proxy_Front-End_Protocol_Troubleshooting_Guide_and_Examples.en.md
+++ b/docs/blog/content/material/2022_07_08_ShardingSphere-Proxy_Front-End_Protocol_Troubleshooting_Guide_and_Examples.en.md
@@ -280,7 +280,7 @@ The solutions presented in this article have been released with Apache ShardingS
[GitHub issue](https://github.com/apache/shardingsphere/issues)
-[Contributor Guide](https://shardingsphere.apache.org/community/en/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/en/involved/)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
@@ -289,4 +289,5 @@ The solutions presented in this article have been released with Apache ShardingS
[Chinese Community](https://community.sphere-ex.com/)
## Author
+
Weijie Wu, Apache ShardingSphere PMC, R&D Engineer of [SphereEx](https://www.sphere-ex.com/en/) Infrastructure. Weijie focuses on the Apache ShardingSphere access side and the ShardingSphere subproject [ElasticJob](https://shardingsphere.apache.org/elasticjob/).
diff --git a/docs/blog/content/material/2022_07_12_ShardingSphere_Cloud_Applications_ An_out-of-the-box_ShardingSphere-Proxy_Cluster.en.md b/docs/blog/content/material/2022_07_12_ShardingSphere_Cloud_Applications_ An_out-of-the-box_ShardingSphere-Proxy_Cluster.en.md
index 54900e5fc00..e9dddfc6365 100644
--- a/docs/blog/content/material/2022_07_12_ShardingSphere_Cloud_Applications_ An_out-of-the-box_ShardingSphere-Proxy_Cluster.en.md
+++ b/docs/blog/content/material/2022_07_12_ShardingSphere_Cloud_Applications_ An_out-of-the-box_ShardingSphere-Proxy_Cluster.en.md
@@ -7,6 +7,7 @@ chapter = true
The [Apache ShardingSphere v5.1.2](https://shardingsphere.apache.org/document/5.1.2/en/overview/) update introduces three new features, one of which allows using the [ShardingSphere-Proxy](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/) chart to rapidly deploy a set of ShardingSphere-Proxy clusters in a cloud environment. This post takes a closer look at this feature.
## Background and Pain Points
+
In a cloud-native environment, an application can be deployed in batches in multiple different environments. It is difficult to deploy it into a new environment by reusing the original `YAML`.
When deploying [Kubernetes](https://kubernetes.io/) software, you may encounter the following problems:
@@ -21,11 +22,13 @@ Due to the flexibility of Apache ShardingSphere-Proxy, a cluster may require mul
Today, there usually is more than one cluster for enterprises. It is a challenge for the traditional deployment model without version control to reuse configuration across multiple clusters while ensuring configuration consistency when producing and testing clusters as well as guaranteeing the correctness of the test.
## Design objective
+
As Apache ShardingSphere-Proxy officially supports standardized deployment on the cloud for the first time, choosing the deployment mode is crucial. We need to consider the ease of use, reuse, and compatibility with subsequent versions.
After investigating several existing Kubernetes deployment modes, we finally chose to use [Helm](https://helm.sh/) to make a chart for Apache ShardingSphere-Proxy and provide it to users. We aim to manage the deployment of Apache ShardingSphere-Proxy so that it can be versioned and reusable.
## Design content
+
[Helm](https://helm.sh/) manages the tool of the Kubernetes package called `chart`. Helm can do the following things:
Create a new `chart`
@@ -40,6 +43,7 @@ Currently, the deployment of Apache ShardingSphere-Proxy depends on the registry
This provides users with a one-stop and out-of-the-box experience. An Apache ShardingSphere-Proxy cluster with governance nodes can be deployed in Kubernetes with only one command, and the governance node data can be persisted by relying on the functions of Kubernetes.
## Quick start guide
+
A [quick start manual](https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-proxy/startup/helm/) is provided in the V5.1.2 documentation, detailing how to deploy an Apache ShardingSphere cluster with default configuration files.
Below we will use the source code for installation and make a detailed description of the deployment of an Apache ShardingSphere-Proxy cluster in the Kubernetes cluster.
@@ -111,6 +115,7 @@ governance:
For the resmaining configurations, see the [configuration items in the document](https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-proxy/startup/helm/#%E9%85%8D%E7%BD%AE%E9%A1%B9).
## Install Apache ShardingSphere-Proxy & ZooKeeper cluster
+
Now, the folder level is:
```
@@ -156,10 +161,9 @@ Create rule:
Write data and query result:


-
-
## Upgrade
+
Apache ShardingSphere-Proxy can be quickly upgraded with Helm.
`helm upgrade shardingsphere-proxy apache-shardingsphere-proxy`
@@ -167,6 +171,7 @@ Apache ShardingSphere-Proxy can be quickly upgraded with Helm.
## Rollback
+
If an error occurs during the upgrade, you can use the `helm rollback` command to quickly roll back the upgraded `release`.
`helm rollback shardingsphere-proxy`
@@ -174,17 +179,17 @@ If an error occurs during the upgrade, you can use the `helm rollback` command t
## Clean Up
+
After the experience, the `release` can be cleaned up quickly using the helm `uninstall` command:
`helm uninstall shardingsphere-proxy`
All resources installed for Helm will be deleted.

- 
-
-
+
## Conclusion
+
Apache ShardingSphere-Proxy Charts can be used to quickly deploy a set of Apache ShardingSphere-Proxy clusters in the Kubernetes cluster.
This simplifies the configuration of `YAML` for ops & maintenance teams during the migration of Apache ShardingSphere-Proxy to the Kubernetes environment.
@@ -194,10 +199,11 @@ With version control, the Apache ShardingSphere-Proxy cluster can be easily depl
In the future, our community will continue to iterate and improve the Apache ShardingSphere-Proxy chart.
## Project Links:
+
[ShardingSphere Github
](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
diff --git a/docs/blog/content/material/2022_07_20_User_Case_China_Unicom_Digital_Technology_Ensuring_Stability_Efficiency_and_Replicability_at_Scale.en.md b/docs/blog/content/material/2022_07_20_User_Case_China_Unicom_Digital_Technology_Ensuring_Stability_Efficiency_and_Replicability_at_Scale.en.md
index 7b0adf90792..ddad4e2abba 100644
--- a/docs/blog/content/material/2022_07_20_User_Case_China_Unicom_Digital_Technology_Ensuring_Stability_Efficiency_and_Replicability_at_Scale.en.md
+++ b/docs/blog/content/material/2022_07_20_User_Case_China_Unicom_Digital_Technology_Ensuring_Stability_Efficiency_and_Replicability_at_Scale.en.md
@@ -11,6 +11,7 @@ The company integrates with China Unicom’s capabilities such as cloud computin
Unicom Digital Tech has accumulated a large number of industry benchmark cases and successfully provided customers with diverse and professional products & services.
## Background
+
In recent years, dozens of service hotline platforms have been launched with the help of Unicom Digital Tech, in a bid to improve enterprise and government services.
The service hotlines are characterized by high concurrency and large amounts of data. Every time we dial a hotline, a work order record is generated. The business volumes of a hotline during the epidemic have increased several times compared to the past.
@@ -18,6 +19,7 @@ The service hotlines are characterized by high concurrency and large amounts of
In the work order module of the government or emergency services hotlines, to meet the business needs of massive amounts of data and high stability, Unicom Digital Tech adopts [ShardingSphere](https://shardingsphere.apache.org/) to carry out sharding and store work order information.
## Business challenges
+
Government service hotlines are the main channel through which the government interacts with enterprises and the public. It provides 24/7 services for the public through a single telephone number.
In addition to dealing with work orders, it also involves services such as telephone traffic, Wiki, voice chat, etc.
@@ -34,6 +36,7 @@ The hotline service raises the following requirements for database architecture
- Low coupling of business code
## Why did Unicom Digital Technology choose ShardingSphere?
+
The technical team conducted several rounds of research and tests in terms of stability, features, access mode, and product performance, and they finally choose the “ShardingSphere + [MySQL](https://www.mysql.com/)” distributed database solution.
- **Advanced concept**
@@ -71,6 +74,7 @@ In addition to the trade-offs of the above five key considerations, other databa
## Solutions
+
As “ShardingSphere+MySQL” ensures stability, ease of use, and ultimate performance, this configuration has been replicated and used in many government and enterprise service hotline projects of Unicom Digital Tech.
- **Deployment mode**
@@ -113,13 +117,15 @@ The business module of the hotline service adopts the micro-service architecture
- It prevents database binding and provides enough flexibility for future upgrades.
## Conclusion
+
The hotline service cases of China Unicom Digital Tech verified ShardingSphere’s capability to support government service scenarios and further proved that ShardingSphere can be used in any industry.
## Project Links:
+
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
\ No newline at end of file
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
\ No newline at end of file
diff --git a/docs/blog/content/material/2022_07_26_DistSQL_Applications_Building_a_Dynamic_Distributed_Database.en.md b/docs/blog/content/material/2022_07_26_DistSQL_Applications_Building_a_Dynamic_Distributed_Database.en.md
index d249608de45..d91fe70b5f3 100644
--- a/docs/blog/content/material/2022_07_26_DistSQL_Applications_Building_a_Dynamic_Distributed_Database.en.md
+++ b/docs/blog/content/material/2022_07_26_DistSQL_Applications_Building_a_Dynamic_Distributed_Database.en.md
@@ -471,19 +471,21 @@ DistSQL provides flexible syntax to help simplify operations. In addition to the
If you have any questions or suggestions about [Apache ShardingSphere](https://shardingsphere.apache.org/), please feel free to post them on the GitHub Issue list.
## Project Links:
+
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
[ShardingSphere Slack
](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
[GitHub Issues](https://github.com/apache/shardingsphere/issues)
-[Contributor Guide](https://shardingsphere.apache.org/community/en/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/en/involved/)
## References
+
1. [Concept-DistSQL](https://shardingsphere.apache.org/document/current/en/concepts/distsql/)
2. [Concept-Distributed Primary Key](https://shardingsphere.apache.org/document/current/en/features/sharding/concept/key-generator/)
diff --git "a/docs/blog/content/material/2022_07_28_Database_Plus\342\200\231s_Embracing_the_Cloud_ShardingSphere-on-Cloud_Solution_Released.en.md" "b/docs/blog/content/material/2022_07_28_Database_Plus\342\200\231s_Embracing_the_Cloud_ShardingSphere-on-Cloud_Solution_Released.en.md"
index d4f9e519a48..6dc614767ee 100644
--- "a/docs/blog/content/material/2022_07_28_Database_Plus\342\200\231s_Embracing_the_Cloud_ShardingSphere-on-Cloud_Solution_Released.en.md"
+++ "b/docs/blog/content/material/2022_07_28_Database_Plus\342\200\231s_Embracing_the_Cloud_ShardingSphere-on-Cloud_Solution_Released.en.md"
@@ -77,6 +77,7 @@ The ShardingSphere-on-Cloud repository will continue to take in various cloud pr
If you have anything to share with us, please feel free to contact us through GitHub Issue or Apache ShardingSphere Slack.
## Project Links:
+
[ShardingSphere Operator GitHub](https://github.com/SphereEx/shardingsphere-on-cloud)
[ShardingSphere Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
@@ -85,14 +86,15 @@ If you have anything to share with us, please feel free to contact us through Gi
](https://twitter.com/ShardingSphere)
[ShardingSphere Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
[GitHub Issues](https://github.com/apache/shardingsphere/issues)
-[Contributor Guide](https://shardingsphere.apache.org/community/en/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/en/involved/)
[SphereEx Official Website
](https://sphere-ex.com/)
## Author
-SphereEx Cloud & ShardingSphere contributor team. Focus on the R&D of Cloud solutions of ShardingSphere, the Database Mesh open source community, and the SphereEx Cloud business.
\ No newline at end of file
+
+SphereEx Cloud & ShardingSphere contributor team. Focus on the R&D of Cloud solutions of ShardingSphere, the Database Mesh open source community, and the SphereEx Cloud business.
diff --git a/docs/blog/content/material/Feb_18_Apache_ShardingSphere_5.1.0_Now Avaliable.en.md b/docs/blog/content/material/Feb_18_Apache_ShardingSphere_5.1.0_Now Avaliable.en.md
index 606f033d0f6..ee28e76ddee 100644
--- a/docs/blog/content/material/Feb_18_Apache_ShardingSphere_5.1.0_Now Avaliable.en.md
+++ b/docs/blog/content/material/Feb_18_Apache_ShardingSphere_5.1.0_Now Avaliable.en.md
@@ -345,7 +345,7 @@ Read/write-splitting supports static and dynamic configuration
[ShardingSphere Slack Channel](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9%7EI4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
## Author
@@ -357,4 +357,4 @@ Apache ShardingSphere PMC
Previously responsible for the database products R&D at JingDong Technology, he is passionate about Open-Source and database ecosystems. Currently, he focuses on the development of the ShardingSphere database ecosystem and open source community building.
-
\ No newline at end of file
+
diff --git a/docs/blog/content/material/Feb_23_Stack_Overflow.en.md b/docs/blog/content/material/Feb_23_Stack_Overflow.en.md
index 8a5de441ff9..678fa9aeb7f 100644
--- a/docs/blog/content/material/Feb_23_Stack_Overflow.en.md
+++ b/docs/blog/content/material/Feb_23_Stack_Overflow.en.md
@@ -1,76 +1,68 @@
-+++
-title = "Apache ShardingSphere is on the Stack Overflow Podcast, InfoQ and FOSDEM!"
-weight = 36
-chapter = true
-+++
-
-# Apache ShardingSphere is on the Stack Overflow Podcast, InfoQ and FOSDEM!
-
-
-
-Our PMC Trista Pan, and our community contributor Yacine Si Tayeb, joined the [Stack Overflow](https://stackoverflow.blog/2022/02/11/chinas-only-female-apache-member-on-the-rise-of-open-source-in-china-ep-414/?utm_source=twitter&utm_medium=social&utm_campaign=so-podcast&utm_content=pod414.2) podcast to share about the Apache ShardingSphere ecosystem.
-
-They shared the advantages of data sharding and how it splits a database into smaller distributed databases to spread query load across multiple servers.
-
-During the conversation, they introduced the complexities that arise with large databases, the rise of open source in China, and how Trista’s position as the only female Apache member in China can help other women get into technology.
-
-Our community thanks the
-Stack Overflow
- team for this opportunity, and for being such great hosts. Being hosted on such a great platform is both an achievement and an opportunity for us.
-
-Our PMC team’s community building efforts continue on what has so far been a great path that included being published on InfoQ with a piece titled [“The Next Evolution of Data Sharding”](https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/) and also joining fantastic events such as [FOSDEM](http://postgresql%20distributed%20%26%20secure%20database%20ecosystem%20building/). During FOSDEM our community shared how to build a distributed & secure ecosystem with [P [...]
-
-Check out below the episode notes, and the links to the podcast and FOSDEM’s recording of the talk.
-
-## Podcast episode notes
-ShardingSphere builds distributed data systems, making it easier for organizations to load balance massive data stores across multiple servers.
-
-Now that open source software has taken over Western software, it’s China’s turn. Even big companies like [Baidu](https://github.com/baidu) and [Bytedance](https://github.com/bytedance) are opening up their projects.
-
-Trista is the [only female Apache member](https://segmentfault.com/a/1190000040352390) in China, which is both an honor and a demonstration of how much work needs to be done to support women in STEM.
-
-Link: [https://stackoverflow.blog/2022/02/11/chinas-only-female-apache-member-on-the-rise-of-open-source-in-china-ep-414/?utm_source=twitter&utm_medium=social&utm_campaign=so-podcast&utm_content=pod414.2](https://stackoverflow.blog/2022/02/11/chinas-only-female-apache-member-on-the-rise-of-open-source-in-china-ep-414/?utm_source=twitter&utm_medium=social&utm_campaign=so-podcast&utm_content=pod414.2)
-
-## InfoQ article
-We thank the InfoQ editorial team for their support, and offering to share ShardingSphere’s features and architecture with their readers.
-
-In this piece we introduced the strengths of data sharding, and Database Plus — our concept for creating a distributed database system for more than sharding, positioned above DBMS.
-
-Link: [https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/](https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/)
-
-## FOSDEM recording
-The FOSDEM session focused on introducing how to empower PostgreSQL thanks to the ecosystem provided by Apache ShardingSphere.
-
-ShardingSphere’s capability to transform any DBMS into a distributed database system, and enhance it with data sharding, elastic scaling, and encryption features is unique among current open source projects.
-
-Link: [https://fosdem.org/2022/schedule/event/postgresql_postgresql_distributed_secure_database_ecosystem_building/](https://fosdem.org/2022/schedule/event/postgresql_postgresql_distributed_secure_database_ecosystem_building/)
-
-## Apache ShardingSphere Open Source Project Links:
-[ShardingSphere Github](https://github.com/apache/shardingsphere)
-
-[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
-
-[ShardingSphere Slack Channel](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
-
-## Author
-**Yacine Si Tayeb**
-
-> SphereEx Head of International Operations
->
-> Apache ShardingSphere Contributor
->
-> Passionate about technology and innovation, Yacine moved to Beijing to pursue his Ph.D. in Business Administration, and fell in awe of the local startup and tech scene. His career path has so far been shaped by opportunities at the intersection of technology and business. Recently he took on a keen interest in the development of the ShardingSphere database middleware ecosystem and Open-Source community building.
-
-
-
-
-
-
-
-
-
-
-
-
++++
+title = "Apache ShardingSphere is on the Stack Overflow Podcast, InfoQ and FOSDEM!"
+weight = 36
+chapter = true
++++
+
+# Apache ShardingSphere is on the Stack Overflow Podcast, InfoQ and FOSDEM!
+
+
+
+Our PMC Trista Pan, and our community contributor Yacine Si Tayeb, joined the [Stack Overflow](https://stackoverflow.blog/2022/02/11/chinas-only-female-apache-member-on-the-rise-of-open-source-in-china-ep-414/?utm_source=twitter&utm_medium=social&utm_campaign=so-podcast&utm_content=pod414.2) podcast to share about the Apache ShardingSphere ecosystem.
+
+They shared the advantages of data sharding and how it splits a database into smaller distributed databases to spread query load across multiple servers.
+
+During the conversation, they introduced the complexities that arise with large databases, the rise of open source in China, and how Trista’s position as the only female Apache member in China can help other women get into technology.
+
+Our community thanks the
+Stack Overflow
+ team for this opportunity, and for being such great hosts. Being hosted on such a great platform is both an achievement and an opportunity for us.
+
+Our PMC team’s community building efforts continue on what has so far been a great path that included being published on InfoQ with a piece titled [“The Next Evolution of Data Sharding”](https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/) and also joining fantastic events such as [FOSDEM](http://postgresql%20distributed%20%26%20secure%20database%20ecosystem%20building/). During FOSDEM our community shared how to build a distributed & secure ecosystem with [P [...]
+
+Check out below the episode notes, and the links to the podcast and FOSDEM’s recording of the talk.
+
+## Podcast episode notes
+ShardingSphere builds distributed data systems, making it easier for organizations to load balance massive data stores across multiple servers.
+
+Now that open source software has taken over Western software, it’s China’s turn. Even big companies like [Baidu](https://github.com/baidu) and [Bytedance](https://github.com/bytedance) are opening up their projects.
+
+Trista is the [only female Apache member](https://segmentfault.com/a/1190000040352390) in China, which is both an honor and a demonstration of how much work needs to be done to support women in STEM.
+
+Link: [https://stackoverflow.blog/2022/02/11/chinas-only-female-apache-member-on-the-rise-of-open-source-in-china-ep-414/?utm_source=twitter&utm_medium=social&utm_campaign=so-podcast&utm_content=pod414.2](https://stackoverflow.blog/2022/02/11/chinas-only-female-apache-member-on-the-rise-of-open-source-in-china-ep-414/?utm_source=twitter&utm_medium=social&utm_campaign=so-podcast&utm_content=pod414.2)
+
+## InfoQ article
+We thank the InfoQ editorial team for their support, and offering to share ShardingSphere’s features and architecture with their readers.
+
+In this piece we introduced the strengths of data sharding, and Database Plus — our concept for creating a distributed database system for more than sharding, positioned above DBMS.
+
+Link: [https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/](https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/)
+
+## FOSDEM recording
+The FOSDEM session focused on introducing how to empower PostgreSQL thanks to the ecosystem provided by Apache ShardingSphere.
+
+ShardingSphere’s capability to transform any DBMS into a distributed database system, and enhance it with data sharding, elastic scaling, and encryption features is unique among current open source projects.
+
+Link: [https://fosdem.org/2022/schedule/event/postgresql_postgresql_distributed_secure_database_ecosystem_building/](https://fosdem.org/2022/schedule/event/postgresql_postgresql_distributed_secure_database_ecosystem_building/)
+
+## Apache ShardingSphere Open Source Project Links:
+
+[ShardingSphere Github](https://github.com/apache/shardingsphere)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere Slack Channel](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
+
+## Author
+
+**Yacine Si Tayeb**
+
+> SphereEx Head of International Operations
+>
+> Apache ShardingSphere Contributor
+>
+> Passionate about technology and innovation, Yacine moved to Beijing to pursue his Ph.D. in Business Administration, and fell in awe of the local startup and tech scene. His career path has so far been shaped by opportunities at the intersection of technology and business. Recently he took on a keen interest in the development of the ShardingSphere database middleware ecosystem and Open-Source community building.
+
+
diff --git a/docs/blog/content/material/Jan_28_Blog_Apache_ShardingSphere_Enterprise_Applications.en.md b/docs/blog/content/material/Jan_28_Blog_Apache_ShardingSphere_Enterprise_Applications.en.md
index 3867156909c..0d934533881 100644
--- a/docs/blog/content/material/Jan_28_Blog_Apache_ShardingSphere_Enterprise_Applications.en.md
+++ b/docs/blog/content/material/Jan_28_Blog_Apache_ShardingSphere_Enterprise_Applications.en.md
@@ -1,181 +1,181 @@
-+++
-title = "Apache ShardingSphere Enterprise Applications"
-weight = 33
-chapter = true
-+++
-
-# Apache ShardingSphere Enterprise Applications
-
-> To further understand application scenarios, enterprises’ needs, and improve dev teams’ understanding of Apache ShardingSphere, our community launched the “Enterprise Visits” series.
-
-## Keep
-For our community’s first visit, we went to Asia’s leading workout & fitness trainer app maker “[Keep](https://www.keepkeep.com/)” headquarters at Vanke Times Center, and shared our technologies with developers at Keep Co.
-
-Way back in 2018, Keep had already deployed ShardingSphere capabilities such as sharding and read/write splitting in multiple application scenarios for its diversified lines of business.
-
-With the release of Apache ShardingSphere 5.0, the concept of Database Plus and pluggable architecture has to some extent, reshaped the ShardingSphere ecosystem. During our visit, we conducted in-depth exchanges and discussions with our counterparts at Keep.
-
-
-
-Keep engineers expressed great interest in Apache ShardingSphere 5.0. At the event, Juan Pan, Apache ShardingSphere PMC and SphereEx CTO, presented a full overview of the initial ShardingSphere architecture, user-end access, community building and the [Database Plus concept](https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/).
-
-
-<center>Apache SahrdingSphere PMC, Pan Juan</center>
-
-## Database Plus: Freeing DBAs and Developers
-
-Database Plus is a design concept of the distributed database system. By building a standard layer and ecosystem for use and interaction above fragmented heterogeneous databases, and by multiplying and expanding computing capabilities (e.g. data sharing, data encryption and decryption), all the interaction between applications and databases is oriented to the standard layer built by Database Plus. This results in shielding the differentiated impact of database fragmentation on upper laye [...]
-
-Pan believes that the global database industry has boomed thanks in large to the following two reasons:
-
-**- Business side demand:**
-
-In terms of business, to ensure sustained visits and transactions growth, underlying databases must respond to requests as soon as possible. In addition, the breakup of microservices and subsequent modification of corresponding databases also generate demands from the business side.
-
-**- Operations & maintenance side demand:**
-
-DBAs are responsible for running the whole business and data system, including data security, backup, distributed governance, and API smart monitoring of data clusters.
-
-If the middle layer can meet transaction traffic and understand the request, DBAs can modify the request accordingly and then more operations can be performed. Therefore, we need to strike a balance between the two sides of demand to carry transaction traffic and support database capacity building, thus creating an efficient, collaborative ecosystem between the two sides.
-Following the version 5.0 release, the sharding function is no longer at the core of Apache ShardingSphere. Actually, sharding has been “downgraded” to a secondary function in the ShardingSphere ecosystem. Following the Database Plus concept, Apache ShardingSphere has built a pluggable architecture ecosystem, enabling the middle layer to achieve more value-added capabilities.
-
-
-<center>ShardingSphere’s Database Plus Architecture</center>
-
-Taking data encryption and decryption as an example, we can see how they are generally done at the business layer because [MySQL](https://www.mysql.com/) and other databases do not support encrypted algorithms themselves. This means encryption & decryption is only be achievable at application and business layers. However, this poses a problem if we consider complex online businesses that face considerable tasks when they upgrade their encryption algorithms.
-
-The best solution to this problem is to encrypt and decrypt data at the middle layer. [ShardingSphere-Proxy](https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-proxy/) can be directly bound to databases, be placed at the middle layer between applications and underlying databases. ShardingSphere-proxy will feel “DB-like” by taking advantage of protocols that are compatible with different databases, thus deciding which node the SQL quest will fall on, letting [...]
-
-
-<center>ShardingSphere Encryption & Decryption Capability</center>
-
-As such, the ShardingSphere encryption and decryption process can be separated from the existing system of applications and databases and can be linked with special encryption algorithms, especially in the cases where a cipher machine is involved. ShardingSphere capabilities such as encryption can free significant amounts of DBAs’ and developers’ time, allowing them to focus more on businesses.
-
-## iQiyi
-
-> Our second stop took us to the leading online streaming platform in Asia, iQiyi.
-
-In November 2021, a team from the ShardingSphere community visited iQiyi the innovation center of iQiyi for in-depth interactions and discussions with their counterparts from Beijing and Shanghai. During the meetup, Zhang Liang, Apache ShardingSphere PMC Chair and SphereEx Founder, provided details on the latest Apache ShardingSphere community initiatives, its future development and Database Mesh.
-
-
-
-During the meetup, iQiyi was especially interested in the capabilities and future plans of ShardingSphere and Database Mesh. here are some key takeaway questions from the visit:
-
-**- How does ShardingSphere manage its encryption keys?**
-
-[Encryption](https://shardingsphere.apache.org/document/current/en/features/encrypt/) key management is a capability subordinate to the encryption algorithm. When ShardingSphere needs an encryption key in its decryption, the key could be passed through properties configured by the encryption algorithm. In principle, encryption key management is not a capability of ShardingSphere but the job of the encryption algorithm.
-
-**- Is there a built-in cryptographic algorithm in ShardingSphere? Or is it done through outside cooperation?**
-
-Strictly speaking, ShardingSphere is not equipped with built-in capability. That’s because the pluggable architecture of ShardingSphere is divided into multiple layers, and the encryption module itself is only a capability of L2 of the pluggable architecture.
-
-The encryption module only defines the top-layer encryption connector and the detailed encryption algorithm achieves the pluggable part of the connector. Currently, ShardingSphere supports several of the most commonly used open source algorithms, but it does not support any national cryptographic algorithm in particular.
-
-Integrating an encryption algorithm is easy for developers: instead of changing source codes, all they need is a ShardingSphere encryption algorithm connector. ShardingSphere’s data encryption process is completely transparent to users and they very easy to use.
-
-**- What’s the future plan for Database Mesh and SphereEx?**
-
-Database Mesh is another ShardingSphere initiative. We are now planning to integrate Database Mesh through [Sidecar](https://shardingsphere.apache.org/document/legacy/3.x/document/en/manual/sharding-sidecar/). Sidecar will be used to manage traffic, while ShardingSphere will be used to manage to compute, and the underlying databases’ nodes to manage storage.
-
-Sidecar’s and ShardingSphere functions overlap in part, but not completely. ShardingSphere has more than 190 modules, therefore it’s not possible to completely replace ShardingSphere with Sidecar. That’s why ShardingSphere empowers some lightweight capabilities to Sidecar, and Sidecar is equipped with the capabilities to buffer some traffic and requests.
-
-The database computing capability is still processed by ShardingSphere, as it would consume too many application resources to run heavyweight computation via Sidecar for the distributed transaction, query and optimization of heterogeneous databases.
-
-In the future, other Sidecar capabilities, such as management, SQL auditing and authorities, will be developed. In this way, Sidecar and ShardingSphere will have their own focuses, providing a better solution.
-
-**- Sidecar is equivalent to a data plane. Will you combine the control plane with [Istio](https://istio.io/) or will you build the control plane separately?**
-
-ShardingSphere uses [DistSQL](https://opensource.com/article/21/9/distsql) (Distributed SQL) to create rules for sharding, encryption and so on. ShardingSphere is already equipped with the control plane capability of Sidecar. Any capability achieved on Sidecar can be controlled by ShardingSphere’s DistSQL.
-
-In the future, we will consider integrating Sidecar into the Istio ecosystem.
-
-So far, Apache ShardingSphere with the release of a version of 5.0 has officiallyrepositioned itself in a new field with the Database Plus concept at its core. In addition to the powerful incremental capability at the upper layer of databases, the Database Plus architecture also opens a highly extensible database ecosystem to developers and users, charting a new future development course for Apache ShardingSphere.
-
-## Sohu
-
-> The third ShardingSphere community visit took us to Sohu — the advertising, search engine, online multiplayer gaming and other services’ giant.
-
-The Apache ShardingSphere community team visited Sohu.com headquarters for in-depth discussions with their counterparts at the internet giant. At the meet-up, Juan Pan, Apache ShardingSphere PMC and SphereEx CTO, elaborated on Apache ShardingSphere’s capabilities.
-
-Sohu, Inc., an integrated Internet company with a rich history and comprehensive lines of business, uses ShardingSphere products in their multiple lines of business, such as social media and video services.
-
-Driven by ShardingSphere-JDBC and with ShardingSphere-Proxy as the container management platform, ShardingSphere provides support for Sohu in all aspects, helping Sohu relieve database traffic stress.
-
-At the event, engineers from Sohu.com expressed great interest in Apache ShardingSphere 5.0. Juan Pan presented a full overview of ShardingSphere’s architecture, client end access, community building and the Database Plus concept.
-
-**Navigate & Solve Industry Challenges**
-
-Due to the complexity of enterprise database systems, and the heavy cost of databases, service providers are supposed to provide enterprises with mainstream database products as well as products and services that can meet multiple needs.
-
-Facing diverse users' needs and increasingly diversified products in the database market, one viable solution could be database deployment and functions with higher flexibility and scalability.
-
-By creating upper-level standards and ecosystems for heterogeneous databases, Apache ShardingSphere provides diversified functions that can precisely meet enterprise needs. As an ecosystem consisting of multiple adapters, by using a hybrid deployment model of ShardingSphere-JDBC and ShardingSphere-Proxy, Apache ShardingSphere enables users to configure sharding strategies through one console and to flexibly create application systems that suit the needs in different scenarios. This allow [...]
-
-
-<center>ShardingSphere’s Deployment Architecture</center>
-
-Centering around connections, incremental and pluggable features, and based on a pluggable architecture, Apache ShardingSphere creates a powerful kernel architecture in the form of micro-kernel.
-
-Based on its powerful kernel capabilities, Apache ShardingSphere products can provide users with ideal solutions for distributed database, data security, database gateway and [full-link stress testing](https://blog.devgenius.io/full-link-online-stress-testing-for-production-database-apache-shardingsphere-shadow-database-84f7cba56f99), helping increase the efficiency of enterprises and users.
-
-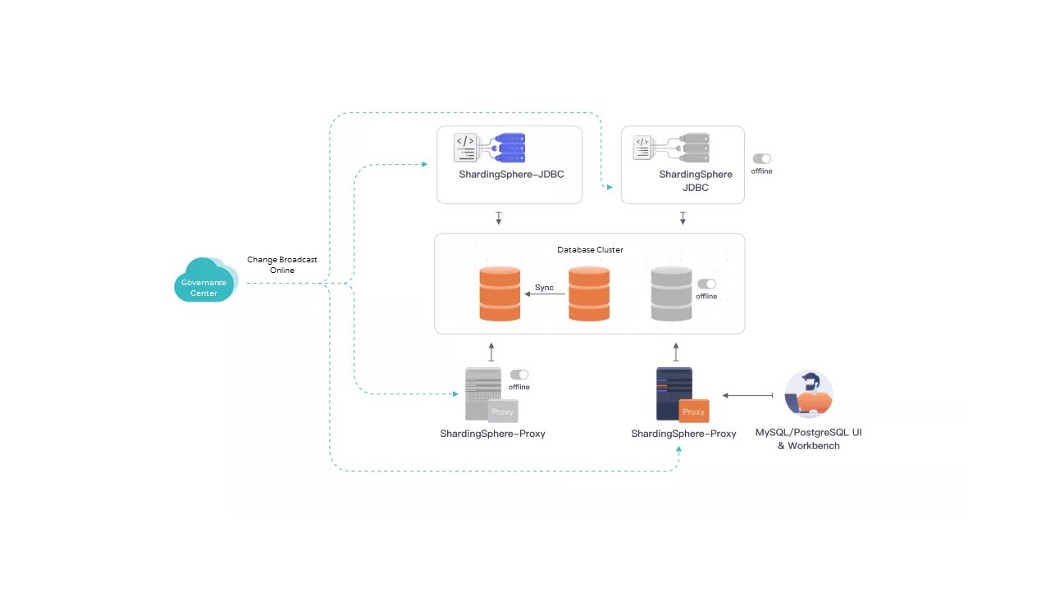
-<center>Overview of Apache ShardingSphere’s Functions</center>
-
-When it comes to future optimization, Pan believes that some deficiencies remain in Apache ShardingSphere’s performance and this is particularly true for ShardingSphere-Proxy’s adaptor. In the future, the community will double down on improving its kernel, minimizing business and data performance loss of the Proxy, improving routing and rewriting logic, reducing creating database objects, and avoiding excess young GC.
-
-## Apache ShardingSphere Open Source Project Links:
-[ShardingSphere Github](https://github.com/apache/shardingsphere)
-
-[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
-
-[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
-
-## Author
-**Yacine Si Tayeb**
-
-SphereEx Head of International Operations
-
-Apache ShardingSphere Contributor
-
-Passionate about technology and innovation, Yacine moved to Beijing to pursue his Ph.D. in Business Administration, and fell in awe of the local startup and tech scene. His career path has so far been shaped by opportunities at the intersection of technology and business. Recently he took on a keen interest in the development of the ShardingSphere database middleware ecosystem and Open-Source community building.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
++++
+title = "Apache ShardingSphere Enterprise Applications"
+weight = 33
+chapter = true
++++
+
+# Apache ShardingSphere Enterprise Applications
+
+> To further understand application scenarios, enterprises’ needs, and improve dev teams’ understanding of Apache ShardingSphere, our community launched the “Enterprise Visits” series.
+
+## Keep
+For our community’s first visit, we went to Asia’s leading workout & fitness trainer app maker “[Keep](https://www.keepkeep.com/)” headquarters at Vanke Times Center, and shared our technologies with developers at Keep Co.
+
+Way back in 2018, Keep had already deployed ShardingSphere capabilities such as sharding and read/write splitting in multiple application scenarios for its diversified lines of business.
+
+With the release of Apache ShardingSphere 5.0, the concept of Database Plus and pluggable architecture has to some extent, reshaped the ShardingSphere ecosystem. During our visit, we conducted in-depth exchanges and discussions with our counterparts at Keep.
+
+
+
+Keep engineers expressed great interest in Apache ShardingSphere 5.0. At the event, Juan Pan, Apache ShardingSphere PMC and SphereEx CTO, presented a full overview of the initial ShardingSphere architecture, user-end access, community building and the [Database Plus concept](https://www.infoq.com/articles/next-evolution-of-database-sharding-architecture/).
+
+
+<center>Apache SahrdingSphere PMC, Pan Juan</center>
+
+## Database Plus: Freeing DBAs and Developers
+
+Database Plus is a design concept of the distributed database system. By building a standard layer and ecosystem for use and interaction above fragmented heterogeneous databases, and by multiplying and expanding computing capabilities (e.g. data sharing, data encryption and decryption), all the interaction between applications and databases is oriented to the standard layer built by Database Plus. This results in shielding the differentiated impact of database fragmentation on upper laye [...]
+
+Pan believes that the global database industry has boomed thanks in large to the following two reasons:
+
+**- Business side demand:**
+
+In terms of business, to ensure sustained visits and transactions growth, underlying databases must respond to requests as soon as possible. In addition, the breakup of microservices and subsequent modification of corresponding databases also generate demands from the business side.
+
+**- Operations & maintenance side demand:**
+
+DBAs are responsible for running the whole business and data system, including data security, backup, distributed governance, and API smart monitoring of data clusters.
+
+If the middle layer can meet transaction traffic and understand the request, DBAs can modify the request accordingly and then more operations can be performed. Therefore, we need to strike a balance between the two sides of demand to carry transaction traffic and support database capacity building, thus creating an efficient, collaborative ecosystem between the two sides.
+Following the version 5.0 release, the sharding function is no longer at the core of Apache ShardingSphere. Actually, sharding has been “downgraded” to a secondary function in the ShardingSphere ecosystem. Following the Database Plus concept, Apache ShardingSphere has built a pluggable architecture ecosystem, enabling the middle layer to achieve more value-added capabilities.
+
+
+<center>ShardingSphere’s Database Plus Architecture</center>
+
+Taking data encryption and decryption as an example, we can see how they are generally done at the business layer because [MySQL](https://www.mysql.com/) and other databases do not support encrypted algorithms themselves. This means encryption & decryption is only be achievable at application and business layers. However, this poses a problem if we consider complex online businesses that face considerable tasks when they upgrade their encryption algorithms.
+
+The best solution to this problem is to encrypt and decrypt data at the middle layer. [ShardingSphere-Proxy](https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-proxy/) can be directly bound to databases, be placed at the middle layer between applications and underlying databases. ShardingSphere-proxy will feel “DB-like” by taking advantage of protocols that are compatible with different databases, thus deciding which node the SQL quest will fall on, letting [...]
+
+
+<center>ShardingSphere Encryption & Decryption Capability</center>
+
+As such, the ShardingSphere encryption and decryption process can be separated from the existing system of applications and databases and can be linked with special encryption algorithms, especially in the cases where a cipher machine is involved. ShardingSphere capabilities such as encryption can free significant amounts of DBAs’ and developers’ time, allowing them to focus more on businesses.
+
+## iQiyi
+
+> Our second stop took us to the leading online streaming platform in Asia, iQiyi.
+
+In November 2021, a team from the ShardingSphere community visited iQiyi the innovation center of iQiyi for in-depth interactions and discussions with their counterparts from Beijing and Shanghai. During the meetup, Zhang Liang, Apache ShardingSphere PMC Chair and SphereEx Founder, provided details on the latest Apache ShardingSphere community initiatives, its future development and Database Mesh.
+
+
+
+During the meetup, iQiyi was especially interested in the capabilities and future plans of ShardingSphere and Database Mesh. here are some key takeaway questions from the visit:
+
+**- How does ShardingSphere manage its encryption keys?**
+
+[Encryption](https://shardingsphere.apache.org/document/current/en/features/encrypt/) key management is a capability subordinate to the encryption algorithm. When ShardingSphere needs an encryption key in its decryption, the key could be passed through properties configured by the encryption algorithm. In principle, encryption key management is not a capability of ShardingSphere but the job of the encryption algorithm.
+
+**- Is there a built-in cryptographic algorithm in ShardingSphere? Or is it done through outside cooperation?**
+
+Strictly speaking, ShardingSphere is not equipped with built-in capability. That’s because the pluggable architecture of ShardingSphere is divided into multiple layers, and the encryption module itself is only a capability of L2 of the pluggable architecture.
+
+The encryption module only defines the top-layer encryption connector and the detailed encryption algorithm achieves the pluggable part of the connector. Currently, ShardingSphere supports several of the most commonly used open source algorithms, but it does not support any national cryptographic algorithm in particular.
+
+Integrating an encryption algorithm is easy for developers: instead of changing source codes, all they need is a ShardingSphere encryption algorithm connector. ShardingSphere’s data encryption process is completely transparent to users and they very easy to use.
+
+**- What’s the future plan for Database Mesh and SphereEx?**
+
+Database Mesh is another ShardingSphere initiative. We are now planning to integrate Database Mesh through [Sidecar](https://shardingsphere.apache.org/document/legacy/3.x/document/en/manual/sharding-sidecar/). Sidecar will be used to manage traffic, while ShardingSphere will be used to manage to compute, and the underlying databases’ nodes to manage storage.
+
+Sidecar’s and ShardingSphere functions overlap in part, but not completely. ShardingSphere has more than 190 modules, therefore it’s not possible to completely replace ShardingSphere with Sidecar. That’s why ShardingSphere empowers some lightweight capabilities to Sidecar, and Sidecar is equipped with the capabilities to buffer some traffic and requests.
+
+The database computing capability is still processed by ShardingSphere, as it would consume too many application resources to run heavyweight computation via Sidecar for the distributed transaction, query and optimization of heterogeneous databases.
+
+In the future, other Sidecar capabilities, such as management, SQL auditing and authorities, will be developed. In this way, Sidecar and ShardingSphere will have their own focuses, providing a better solution.
+
+**- Sidecar is equivalent to a data plane. Will you combine the control plane with [Istio](https://istio.io/) or will you build the control plane separately?**
+
+ShardingSphere uses [DistSQL](https://opensource.com/article/21/9/distsql) (Distributed SQL) to create rules for sharding, encryption and so on. ShardingSphere is already equipped with the control plane capability of Sidecar. Any capability achieved on Sidecar can be controlled by ShardingSphere’s DistSQL.
+
+In the future, we will consider integrating Sidecar into the Istio ecosystem.
+
+So far, Apache ShardingSphere with the release of a version of 5.0 has officiallyrepositioned itself in a new field with the Database Plus concept at its core. In addition to the powerful incremental capability at the upper layer of databases, the Database Plus architecture also opens a highly extensible database ecosystem to developers and users, charting a new future development course for Apache ShardingSphere.
+
+## Sohu
+
+> The third ShardingSphere community visit took us to Sohu — the advertising, search engine, online multiplayer gaming and other services’ giant.
+
+The Apache ShardingSphere community team visited Sohu.com headquarters for in-depth discussions with their counterparts at the internet giant. At the meet-up, Juan Pan, Apache ShardingSphere PMC and SphereEx CTO, elaborated on Apache ShardingSphere’s capabilities.
+
+Sohu, Inc., an integrated Internet company with a rich history and comprehensive lines of business, uses ShardingSphere products in their multiple lines of business, such as social media and video services.
+
+Driven by ShardingSphere-JDBC and with ShardingSphere-Proxy as the container management platform, ShardingSphere provides support for Sohu in all aspects, helping Sohu relieve database traffic stress.
+
+At the event, engineers from Sohu.com expressed great interest in Apache ShardingSphere 5.0. Juan Pan presented a full overview of ShardingSphere’s architecture, client end access, community building and the Database Plus concept.
+
+**Navigate & Solve Industry Challenges**
+
+Due to the complexity of enterprise database systems, and the heavy cost of databases, service providers are supposed to provide enterprises with mainstream database products as well as products and services that can meet multiple needs.
+
+Facing diverse users' needs and increasingly diversified products in the database market, one viable solution could be database deployment and functions with higher flexibility and scalability.
+
+By creating upper-level standards and ecosystems for heterogeneous databases, Apache ShardingSphere provides diversified functions that can precisely meet enterprise needs. As an ecosystem consisting of multiple adapters, by using a hybrid deployment model of ShardingSphere-JDBC and ShardingSphere-Proxy, Apache ShardingSphere enables users to configure sharding strategies through one console and to flexibly create application systems that suit the needs in different scenarios. This allow [...]
+
+
+<center>ShardingSphere’s Deployment Architecture</center>
+
+Centering around connections, incremental and pluggable features, and based on a pluggable architecture, Apache ShardingSphere creates a powerful kernel architecture in the form of micro-kernel.
+
+Based on its powerful kernel capabilities, Apache ShardingSphere products can provide users with ideal solutions for distributed database, data security, database gateway and [full-link stress testing](https://blog.devgenius.io/full-link-online-stress-testing-for-production-database-apache-shardingsphere-shadow-database-84f7cba56f99), helping increase the efficiency of enterprises and users.
+
+
+<center>Overview of Apache ShardingSphere’s Functions</center>
+
+When it comes to future optimization, Pan believes that some deficiencies remain in Apache ShardingSphere’s performance and this is particularly true for ShardingSphere-Proxy’s adaptor. In the future, the community will double down on improving its kernel, minimizing business and data performance loss of the Proxy, improving routing and rewriting logic, reducing creating database objects, and avoiding excess young GC.
+
+## Apache ShardingSphere Open Source Project Links:
+[ShardingSphere Github](https://github.com/apache/shardingsphere)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
+
+## Author
+**Yacine Si Tayeb**
+
+SphereEx Head of International Operations
+
+Apache ShardingSphere Contributor
+
+Passionate about technology and innovation, Yacine moved to Beijing to pursue his Ph.D. in Business Administration, and fell in awe of the local startup and tech scene. His career path has so far been shaped by opportunities at the intersection of technology and business. Recently he took on a keen interest in the development of the ShardingSphere database middleware ecosystem and Open-Source community building.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/blog/content/material/Jan_28_Blog_PG_Create_a_Distributed_Database_Solution_Based_on_PostgreSQL_&_openGauss.en.md b/docs/blog/content/material/Jan_28_Blog_PG_Create_a_Distributed_Database_Solution_Based_on_PostgreSQL_&_openGauss.en.md
index a9d1d8e732d..ea6be7c3ea6 100644
--- a/docs/blog/content/material/Jan_28_Blog_PG_Create_a_Distributed_Database_Solution_Based_on_PostgreSQL_&_openGauss.en.md
+++ b/docs/blog/content/material/Jan_28_Blog_PG_Create_a_Distributed_Database_Solution_Based_on_PostgreSQL_&_openGauss.en.md
@@ -1,176 +1,176 @@
-+++
-title = "Create a Distributed Database Solution Based on PostgreSQL/openGauss"
-weight = 28
-chapter = true
-+++
-
-# Create a Distributed Database Solution Based on PostgreSQL/openGauss
-
-As the MySQL ShardingSphere-Proxy is becoming mature and widely accepted, ShardingSphere is also focusing on the PostgreSQL ShardingSphere-Proxy.
-
-Compared with the alpha and beta, lots of improvements such as PostgreSQL agreement realization, SQL support and control, have been made in ShardingSphere-Proxy 5.0.0. This lays the foundation for full docking with the PostgreSQL ecosystem in the future. The ecosystem integration of ShardingSphere-Proxy and PostgreSQL provides users, on the basis of PostgreSQL database, with transparent and enhanced capabilities, such as: data sharding, read/write splitting, shadow database, data masking [...]
-
-Besides PostgreSQL, the open source database openGauss, which is developed by Huawei, is also gaining increasing popularity. With the capability and ecosystem of Shardingsphere openGauss, which enjoys outstanding standalone performance, it’ll be possible to create distributed database solutions that meet the needs of increasingly diversified scenarios.
-
-Currently, ShardingSphere PostgreSQL and openGauss Proxy supports most capabilities of the Apache ShardingSphere ecosystem, including data sharding, read/write splitting, shadow database, data masking/desensitization and distributed governance. Therefore, it’s almost as mature as the ShardingSphere MySQL Proxy.
-
-This article will introduce improvements to the ShardingSphere-Proxy 5.0.0 built on PostgreSQL and its ecosystem integration with openGauss.
-
-## Introduction to ShardingSphere-Proxy
-
-ShardingSphere-Proxy is an adapter in the ShardingSphere ecosystem and is positioned as a transparent database proxy to users. ShardingSphere Proxy is not limited to Java. Instead, it realizes MySQL and PostgreSQL database protocols, and users can use various clients compatible with MySQL / PostgreSQL protocols to access and manipulate data.
-
-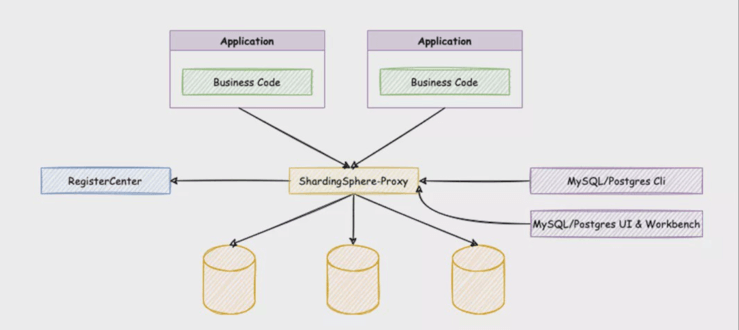
-
-
-| | ShardingSphere-JDBC | ShardingSphere-Proxy |
-| :--- | :----: | ---: |
-| Database | Any | Databases based on MySQL / PostgreSQL protocol |
-| Connected Consumption | High | Low |
-| Heterogeneous Language | Support Java among other JVM-based languages | Any |
-| Performance | Low loss | Relatively high loss |
-| Decentralization | Yes | No |
-| Static Entry | No | Yes |
-
-> ShardingSphere-Proxy is capable of addressing the following problems: with sub-database, sub-table or other rules in place, the data will be distributed to multiple database instances, which will inevitably cause some inconvenience to management; or when non-Java developers need the capabilities provided by ShardingSphere…this is exactly what ShardingSphere-Proxy was built for.
-
-ShardingSphere-Proxy hides the back-end database. For the client, it’s just like using a database. Users don’t need to worry about how ShardingSphere coordinates the databases behind it. Therefore, it is more friendly to non-Java developers or DBAs.
-
-Protocol-wise, ShardingSphere PostgreSQL Proxy realizes most Extended Query protocols and supports heterogeneous languages to drive and connect Proxy through PostgreSQL and openGauss. Based on reusing the PostgreSQL protocol, ShardingSphere openGauss Proxy also supports openGauss’s unique function of batch insertion protocol.
-
-However, since ShardingSphere-Proxy has an extra layer of network interaction compared to ShardingSphere-JDBC, the delay of SQL execution increases, and the loss is slightly higher than that of ShardingSphere-JDBC.
-
-## ShardingSphere-Proxy and PostgreSQL Ecosystem Integration
-
-
-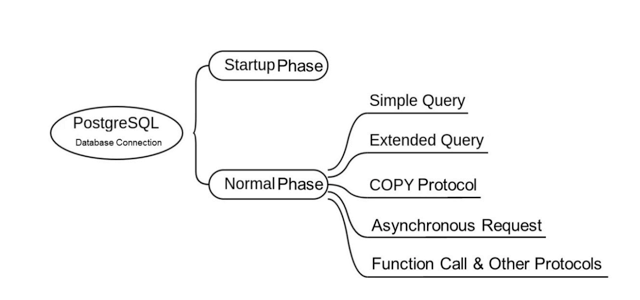
-
-Simple Query and Extended Query are the most common protocols for most users using PostgreSQL. For instance, when using the following command line tool `psql` to connect PostgreSQL for CRUD operation, the Simple Query is often used to interact with the database.
-
-`$ psql -h 127.0.0.1 -U postgres
-psql (14.0 (Debian 14.0-1.pgdg110+1))
-Type "help" for help.
-postgres=# select id, name from person where age < 35;
- id | name
-----+------
- 1 | Foo
-(1 row)`
-
-The protocol interaction diagram of Simple Query is as follows:
-
-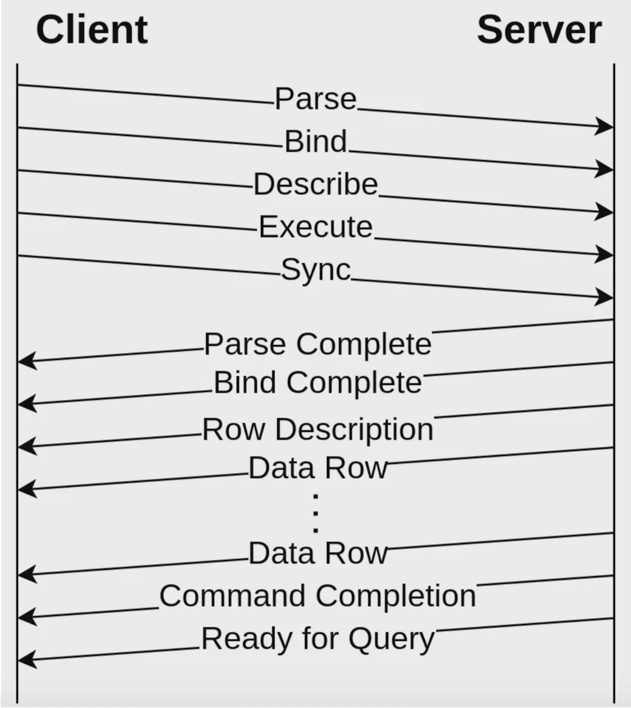
-
-When using PostgreSQL JDBC Driver and other drivers, code is as follows PreparedStatement, which corresponds to the Extended Query protocol in default.
-
-`String sql = "select id, name from person where age > ?";
-PreparedStatement ps = connection.prepareStatement(sql);
-ps.setInt(1, 35);
-ResultSet resultSet = ps.executeQuery();`
-
-The protocol interaction diagram of Extended Query is as follows:
-
-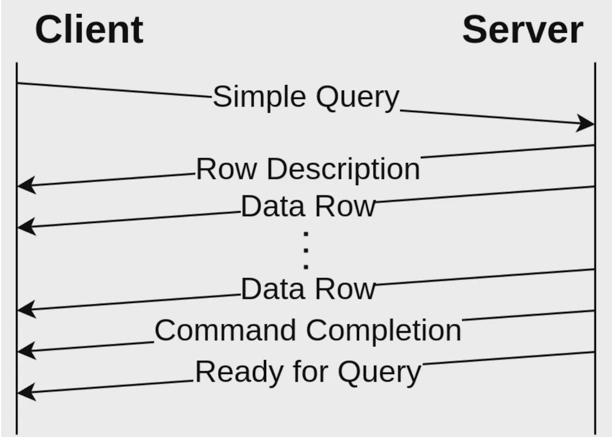
-
-Currently, ShardingSphere PostgreSQL Proxy realizes protocols of Simple Query with the most Extended Query. However, since database client end and driver have encapsulated API for users to use, users do not need to worry about database protocols.
-
-ShardingSphere-Proxy is compatible with Simple Query and Extended Query of PostgreSQL, meaning that users could use commonly used PostgreSQL client ends or drivers to connect with ShardingSphere-Proxy for CRUD operation to make use of the incremental capability provided by ShardingSphere in the databases’ upper layer.
-
-## ShardingSphere-Proxy and openGauss Ecosystem Integration
-
-### Support openGauss JDBC Driver
-
-openGauss database has a corresponding JDBC Driver. The prefix of JDBC URL is `jdbc:opengauss`. Although JDBC drivers using PostgreSQL can also connect with openGauss database, batch insertion and other unique features of openGauss would not be able to function fully. ShardingSphere integrates openGauss database which could recognize openGauss JDBC Driver, **allowing developers to use the openGauss JDBC Driver directly with ShardingSphere.**
-
-### Support openGauss Batch Insertion Protocol
-
-For example, when we prepare an insert sentence such as the following:
-
-`insert into person (id, name, age) values (?, ?, ?)`
-
-Taking JDBC for example, we could use the following method to carry out batch insertion:
-
-`String sql = "insert into person (id, name, age) values (?, ?, ?)";
-PreparedStatement ps = connection.prepareStatement(sql);
-ps.setLong(1, 1);
-ps.setString(2, "Foo");
-ps.setInt(3, 18);
-ps.addBatch();
-ps.setLong(1, 2);
-ps.setString(2, "Bar");
-ps.setInt(3, 36);
-ps.addBatch();
-ps.setLong(1, 3);
-ps.setString(2, "Tom");
-ps.setInt(3, 54);
-ps.addBatch();
-ps.executeBatch();`
-
-At the PostgreSQL protocol layer, `Bind` can transfer one set of parameters to form Portal, and `Execute` can conduct one Portal each time.
-
-Batch insertion could be realized through the repetition of `Bind` and `Execute`. The protocol interaction diagram is as follows:
-
-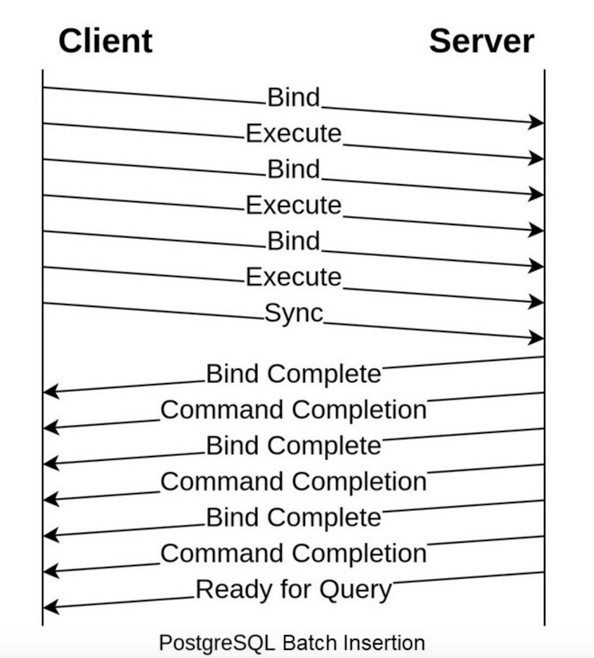
-
-`Batch Bind` is a message exclusive to openGauss. Compared with `Bind`, `Batch Bind` can transfer multiple sets of parameters at a time. The protocol interaction diagram using `Batch Bind` to perform batch insertion is as follows:
-
-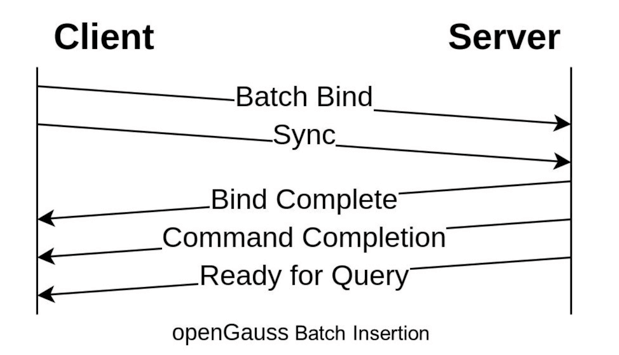
-
-ShardingSphere-Proxy openGauss supports Batch Bind protocol, meaning that **users could use the openGauss client end or driver to perform batch insertion of the ShardingSphere Proxy.**
-
-##Future ShardingSphere-Proxy Developments
-
-###Support ShardingSphere PostgreSQL Proxy Logic Query in MetaData
-
-ShardingSphere-Proxy is a transparent database proxy, which means that users do not need to think about how Proxy coordinates the databases.
-
-In the picture below, when configuring logic database `sharding_db` and logic table `person` ShardingSphere-Proxy, there are four tables in two databases behind Proxy.
-
-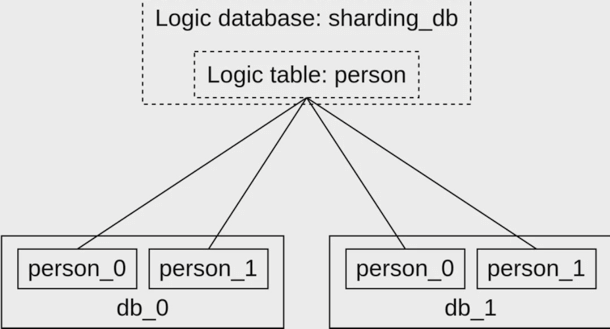
-
-Currently, when executing `show schemas` and `show tables` languages in ShardingSphere MySQL Proxy, the query results are listed as logic database `sharding_db` and logic table `person`.
-
-When using `psql` to connect `PostgreSQL`, users could query databases and tables through `\l`, `\d` and other requests.
-
-However, different from MySQL, `show tables` is a language supported by MySQL, while `\d` used in `psql` actually corresponds to a more complicated SQL. Currently, when using ShardingSphere PostgreSQL Proxy, logic databases or logic tables cannot be queried.
-
-###Describe Prepared Statement Supporting Extended Query
-
-There are two types of Describe message in PostgreSQL protocol, which are Describe Portal and Describe Prepared Statement. Currently, the ShardingSphere Proxy only supports Describe Portal.
-
-An example of the practical application of Describe Prepared Statement:
-
-Get the MetaData of the result set before executing PreparedStatement.
-
-`PreparedStatement preparedStatement = connection.prepareStatement("select * from t_order limit ?");
-ResultSetMetaData metaData = preparedStatement.getMetaData();`
-
-The ecosystem integration of ShardingSphere and PostgreSQL and openGauss is still underway, with some steps left before full completion. If you are interested in what we are doing, you’re welcome to join the ShardingSphere community on GitHub, Twitter, Slack or through the official mailing list.
-
-
-**Reference**
-
-* https://www.postgresql.org/docs/current/protocol.html
-
-* https://gitee.com/opengauss/openGauss-connector-jdbc/blob/master/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java#L1722
-
-* https://gitee.com/opengauss/openGauss-connector-jdbc/blob/master/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java#L1722
-
-**Open Source Project Links:**
-
-ShardingSphere Github: https://github.com/apache/shardingsphere
-
-ShardingSphere Twitter: https://twitter.com/ShardingSphere
-
-ShardingSphere Slack Channel:https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg
-
-GitHub Issues: https://github.com/apache/shardingsphere/issues
-
-Contributor Guide:https://shardingsphere.apache.org/community/cn/contribute/
-
-GitHub: https://github.com/apache/shardingsphere
-
-### Author
-
->Apache ShardingSphere Committer & Middleware Engineer at SphereEx. Contributed to the development of Apache ShardingSphere and Apache ShardingSphere ElasticJob.
-
-
++++
+title = "Create a Distributed Database Solution Based on PostgreSQL/openGauss"
+weight = 28
+chapter = true
++++
+
+# Create a Distributed Database Solution Based on PostgreSQL/openGauss
+
+As the MySQL ShardingSphere-Proxy is becoming mature and widely accepted, ShardingSphere is also focusing on the PostgreSQL ShardingSphere-Proxy.
+
+Compared with the alpha and beta, lots of improvements such as PostgreSQL agreement realization, SQL support and control, have been made in ShardingSphere-Proxy 5.0.0. This lays the foundation for full docking with the PostgreSQL ecosystem in the future. The ecosystem integration of ShardingSphere-Proxy and PostgreSQL provides users, on the basis of PostgreSQL database, with transparent and enhanced capabilities, such as: data sharding, read/write splitting, shadow database, data masking [...]
+
+Besides PostgreSQL, the open source database openGauss, which is developed by Huawei, is also gaining increasing popularity. With the capability and ecosystem of Shardingsphere openGauss, which enjoys outstanding standalone performance, it’ll be possible to create distributed database solutions that meet the needs of increasingly diversified scenarios.
+
+Currently, ShardingSphere PostgreSQL and openGauss Proxy supports most capabilities of the Apache ShardingSphere ecosystem, including data sharding, read/write splitting, shadow database, data masking/desensitization and distributed governance. Therefore, it’s almost as mature as the ShardingSphere MySQL Proxy.
+
+This article will introduce improvements to the ShardingSphere-Proxy 5.0.0 built on PostgreSQL and its ecosystem integration with openGauss.
+
+## Introduction to ShardingSphere-Proxy
+
+ShardingSphere-Proxy is an adapter in the ShardingSphere ecosystem and is positioned as a transparent database proxy to users. ShardingSphere Proxy is not limited to Java. Instead, it realizes MySQL and PostgreSQL database protocols, and users can use various clients compatible with MySQL / PostgreSQL protocols to access and manipulate data.
+
+
+
+
+| | ShardingSphere-JDBC | ShardingSphere-Proxy |
+| :--- | :----: | ---: |
+| Database | Any | Databases based on MySQL / PostgreSQL protocol |
+| Connected Consumption | High | Low |
+| Heterogeneous Language | Support Java among other JVM-based languages | Any |
+| Performance | Low loss | Relatively high loss |
+| Decentralization | Yes | No |
+| Static Entry | No | Yes |
+
+> ShardingSphere-Proxy is capable of addressing the following problems: with sub-database, sub-table or other rules in place, the data will be distributed to multiple database instances, which will inevitably cause some inconvenience to management; or when non-Java developers need the capabilities provided by ShardingSphere…this is exactly what ShardingSphere-Proxy was built for.
+
+ShardingSphere-Proxy hides the back-end database. For the client, it’s just like using a database. Users don’t need to worry about how ShardingSphere coordinates the databases behind it. Therefore, it is more friendly to non-Java developers or DBAs.
+
+Protocol-wise, ShardingSphere PostgreSQL Proxy realizes most Extended Query protocols and supports heterogeneous languages to drive and connect Proxy through PostgreSQL and openGauss. Based on reusing the PostgreSQL protocol, ShardingSphere openGauss Proxy also supports openGauss’s unique function of batch insertion protocol.
+
+However, since ShardingSphere-Proxy has an extra layer of network interaction compared to ShardingSphere-JDBC, the delay of SQL execution increases, and the loss is slightly higher than that of ShardingSphere-JDBC.
+
+## ShardingSphere-Proxy and PostgreSQL Ecosystem Integration
+
+
+
+
+Simple Query and Extended Query are the most common protocols for most users using PostgreSQL. For instance, when using the following command line tool `psql` to connect PostgreSQL for CRUD operation, the Simple Query is often used to interact with the database.
+
+`$ psql -h 127.0.0.1 -U postgres
+psql (14.0 (Debian 14.0-1.pgdg110+1))
+Type "help" for help.
+postgres=# select id, name from person where age < 35;
+ id | name
+----+------
+ 1 | Foo
+(1 row)`
+
+The protocol interaction diagram of Simple Query is as follows:
+
+
+
+When using PostgreSQL JDBC Driver and other drivers, code is as follows PreparedStatement, which corresponds to the Extended Query protocol in default.
+
+`String sql = "select id, name from person where age > ?";
+PreparedStatement ps = connection.prepareStatement(sql);
+ps.setInt(1, 35);
+ResultSet resultSet = ps.executeQuery();`
+
+The protocol interaction diagram of Extended Query is as follows:
+
+
+
+Currently, ShardingSphere PostgreSQL Proxy realizes protocols of Simple Query with the most Extended Query. However, since database client end and driver have encapsulated API for users to use, users do not need to worry about database protocols.
+
+ShardingSphere-Proxy is compatible with Simple Query and Extended Query of PostgreSQL, meaning that users could use commonly used PostgreSQL client ends or drivers to connect with ShardingSphere-Proxy for CRUD operation to make use of the incremental capability provided by ShardingSphere in the databases’ upper layer.
+
+## ShardingSphere-Proxy and openGauss Ecosystem Integration
+
+### Support openGauss JDBC Driver
+
+openGauss database has a corresponding JDBC Driver. The prefix of JDBC URL is `jdbc:opengauss`. Although JDBC drivers using PostgreSQL can also connect with openGauss database, batch insertion and other unique features of openGauss would not be able to function fully. ShardingSphere integrates openGauss database which could recognize openGauss JDBC Driver, **allowing developers to use the openGauss JDBC Driver directly with ShardingSphere.**
+
+### Support openGauss Batch Insertion Protocol
+
+For example, when we prepare an insert sentence such as the following:
+
+`insert into person (id, name, age) values (?, ?, ?)`
+
+Taking JDBC for example, we could use the following method to carry out batch insertion:
+
+`String sql = "insert into person (id, name, age) values (?, ?, ?)";
+PreparedStatement ps = connection.prepareStatement(sql);
+ps.setLong(1, 1);
+ps.setString(2, "Foo");
+ps.setInt(3, 18);
+ps.addBatch();
+ps.setLong(1, 2);
+ps.setString(2, "Bar");
+ps.setInt(3, 36);
+ps.addBatch();
+ps.setLong(1, 3);
+ps.setString(2, "Tom");
+ps.setInt(3, 54);
+ps.addBatch();
+ps.executeBatch();`
+
+At the PostgreSQL protocol layer, `Bind` can transfer one set of parameters to form Portal, and `Execute` can conduct one Portal each time.
+
+Batch insertion could be realized through the repetition of `Bind` and `Execute`. The protocol interaction diagram is as follows:
+
+
+
+`Batch Bind` is a message exclusive to openGauss. Compared with `Bind`, `Batch Bind` can transfer multiple sets of parameters at a time. The protocol interaction diagram using `Batch Bind` to perform batch insertion is as follows:
+
+
+
+ShardingSphere-Proxy openGauss supports Batch Bind protocol, meaning that **users could use the openGauss client end or driver to perform batch insertion of the ShardingSphere Proxy.**
+
+##Future ShardingSphere-Proxy Developments
+
+###Support ShardingSphere PostgreSQL Proxy Logic Query in MetaData
+
+ShardingSphere-Proxy is a transparent database proxy, which means that users do not need to think about how Proxy coordinates the databases.
+
+In the picture below, when configuring logic database `sharding_db` and logic table `person` ShardingSphere-Proxy, there are four tables in two databases behind Proxy.
+
+
+
+Currently, when executing `show schemas` and `show tables` languages in ShardingSphere MySQL Proxy, the query results are listed as logic database `sharding_db` and logic table `person`.
+
+When using `psql` to connect `PostgreSQL`, users could query databases and tables through `\l`, `\d` and other requests.
+
+However, different from MySQL, `show tables` is a language supported by MySQL, while `\d` used in `psql` actually corresponds to a more complicated SQL. Currently, when using ShardingSphere PostgreSQL Proxy, logic databases or logic tables cannot be queried.
+
+###Describe Prepared Statement Supporting Extended Query
+
+There are two types of Describe message in PostgreSQL protocol, which are Describe Portal and Describe Prepared Statement. Currently, the ShardingSphere Proxy only supports Describe Portal.
+
+An example of the practical application of Describe Prepared Statement:
+
+Get the MetaData of the result set before executing PreparedStatement.
+
+`PreparedStatement preparedStatement = connection.prepareStatement("select * from t_order limit ?");
+ResultSetMetaData metaData = preparedStatement.getMetaData();`
+
+The ecosystem integration of ShardingSphere and PostgreSQL and openGauss is still underway, with some steps left before full completion. If you are interested in what we are doing, you’re welcome to join the ShardingSphere community on GitHub, Twitter, Slack or through the official mailing list.
+
+
+**Reference**
+
+* https://www.postgresql.org/docs/current/protocol.html
+
+* https://gitee.com/opengauss/openGauss-connector-jdbc/blob/master/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java#L1722
+
+* https://gitee.com/opengauss/openGauss-connector-jdbc/blob/master/pgjdbc/src/main/java/org/postgresql/core/v3/QueryExecutorImpl.java#L1722
+
+**Open Source Project Links:**
+
+ShardingSphere Github: https://github.com/apache/shardingsphere
+
+ShardingSphere Twitter: https://twitter.com/ShardingSphere
+
+ShardingSphere Slack Channel:https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg
+
+GitHub Issues: https://github.com/apache/shardingsphere/issues
+
+Contributor Guide:https://shardingsphere.apache.org/community/cn/involved/
+
+GitHub: https://github.com/apache/shardingsphere
+
+### Author
+
+>Apache ShardingSphere Committer & Middleware Engineer at SphereEx. Contributed to the development of Apache ShardingSphere and Apache ShardingSphere ElasticJob.
+
+
diff --git a/docs/blog/content/material/Jan_28_Blog_X_Kernel_Optimizations_&_Upgrade_Guide_for_Apache_ShardingSphere_5.0.0_The_Ideal_Database_Management_Ecosystem.en.md b/docs/blog/content/material/Jan_28_Blog_X_Kernel_Optimizations_&_Upgrade_Guide_for_Apache_ShardingSphere_5.0.0_The_Ideal_Database_Management_Ecosystem.en.md
index 6d251348259..360d0f33d96 100644
--- a/docs/blog/content/material/Jan_28_Blog_X_Kernel_Optimizations_&_Upgrade_Guide_for_Apache_ShardingSphere_5.0.0_The_Ideal_Database_Management_Ecosystem.en.md
+++ b/docs/blog/content/material/Jan_28_Blog_X_Kernel_Optimizations_&_Upgrade_Guide_for_Apache_ShardingSphere_5.0.0_The_Ideal_Database_Management_Ecosystem.en.md
@@ -684,7 +684,7 @@ As always, you’re welcome to join us in developing the Apache ShardingSphere p
3. Automatic Sharding Strategies for Databases and Tables:https://github.com/apache/shardingsphere/issues/5937
-4. Contributor Guide:https://shardingsphere.apache.org/community/en/contribute/
+4. Contributor Guide:https://shardingsphere.apache.org/community/en/involved/
5. https://docs.oracle.com/en/
@@ -703,8 +703,7 @@ ShardingSphere Slack Channel:https://join.slack.com/t/apacheshardingsphere/share
GitHub Issues: https://github.com/apache/shardingsphere/issues
-Contributor Guide:https://shardingsphere.apache.org/community/cn/contribute/
-
+Contributor Guide:https://shardingsphere.apache.org/community/cn/involved/
### Author
diff --git "a/docs/blog/content/material/Jan_28_F6_Automobile_Technology\342\200\231s_Multimillion_Rows_of_Data_Sharding_Strategy_Based_on_Apache_ShardingS.md" "b/docs/blog/content/material/Jan_28_F6_Automobile_Technology\342\200\231s_Multimillion_Rows_of_Data_Sharding_Strategy_Based_on_Apache_ShardingS.md"
index 59b148adf23..106cadc6446 100644
--- "a/docs/blog/content/material/Jan_28_F6_Automobile_Technology\342\200\231s_Multimillion_Rows_of_Data_Sharding_Strategy_Based_on_Apache_ShardingS.md"
+++ "b/docs/blog/content/material/Jan_28_F6_Automobile_Technology\342\200\231s_Multimillion_Rows_of_Data_Sharding_Strategy_Based_on_Apache_ShardingS.md"
@@ -1,356 +1,356 @@
-+++
-title = "F6 Automobile Technology’s Multimillion Rows of Data Sharding Strategy Based on Apache ShardingSphere"
-weight = 31
-chapter = true
-+++
-
-# F6 Automobile Technology’s Multimillion Rows of Data Sharding Strategy Based on Apache ShardingSphere
-
-[F6 Automobile Technology](https://www.f6car.com/) is an Internet platform company focusing on the informatization of the automotive aftermarket.
-
-It helps automotive repair companies (clients) build their smart management systems to digitally transform the auto aftermarket.
-The data of different auto repair companies will certainly be isolated from each other, so theoretically the data can be stored in different tables of different databases. However, fast-growing enterprises face increasing data volume challenges: sometimes total data volume in a single table may approach 10 million or even 100 million entries.
-
-
-This issue definitely challenges business growth. Moreover, growing enterprises are now also planning to split their systems into many microservices based on domains or business types, and accordingly, different databases are vertically required for different business cases.
-
-## Why Did We Need Data Sharding?
-Relational databases are bottlenecks when it comes to storage capacity, connection count, and processing capabilities.
-
-
-First, we always prioritize database performance. When the data volume of a single table reaches tens of millions, and there are a relatively large number of query dimensions, system performance would still prove unsatisfactory even if we added more slave databases and optimize indexes. This meant it was time for us to consider data sharding.
-
-The purpose of data sharding is to reduce database load stress and query time. Additionally, since a single database often has a limited number of connections, when Queries Per Second (QPS) indicator of the database is too high, database sharding is certainly needed to share connection stress.
-
-Second, to ensure availability was another important reason. If unfortunately, an accident occurs in a single database, we’d likely lose all data and further affect all services. Database sharding can minimize risk and the negative impact on business services. Generally, when the data volume of a table is greater than 2GB or the number of data rows is greater than 10 million, not to mention that the data is also growing rapidly, we’d better use data sharding.
-## What’s Data Sharding?
-There are four common types of data sharding in the industry:
-
-- Vertical table sharding: split big tables into small ones, field-based, which means less frequently used or relatively long fields are split into extended tables.
-- Vertical database sharding: business-based database sharding is used to solve performance bottlenecks of a single database.
-- Horizontal table sharding: distribute tables’ data rows into different tables according to some rules in order to decrease the data volume of single tables and optimize query performance. In terms of the database layer, it still faces bottlenecks.
-- Horizontal data sharding: based on horizontal table sharding, distribute data into different databases to effectively improve performance, lower stress of stand-alone machine and single databases, and break the shackles of I/O, connections, and hardware resources.
-## Excellent Data Sharding Solutions
-1. [Sharding-JDBC](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-jdbc-quick-start/) (Apache ShardingSphere)
-**Pros:**
-- Supported by an active open source community. Now, Apache ShardingSphere 5.0 version has been released and the development iteration speed is fast.
-- Proven efficacy by many successful enterprise application cases: big companies such as JD Technology and Dangdang.com have applied ShardingSphere.
-- Easy deployment: Sharding-JDBC can be quickly integrated into any project without extra services deployed.
-- Excellent compatibility: it can route to a single data node and perfectly support SQL.
-- Excellent performance and low loss: test results can be found on the Apache ShardingSphere website.
--
-**Cons:**
-
-- Potential increase in operations and maintenance costs, and troublesome field changes and index creation after data sharding. To fix the issue, users need to deploy Sharding-Proxy that supports heterogeneous languages and is more friendly to DBAs.
-- So far, the project doesn’t support data shards dynamic migration yet. Therefore, feature implementation is required.
-
-2. [MyCat](http://mycat.sourceforge.net/)
-
-**Pros:**
-
-- MyCat is a middleware placed between applications and databases to handle data processing and interactions. It cannot be perceived during development, and integrating MyCat does not cost much.
-- Use JDBC to connect databases such as Oracle, DB2, SQL Server, and MySQL.
-- Support multiple languages plus easy deployment and implementation across different platforms.
-- High availability and auto-switch triggered by a crash.
-
-**Cons:**
-
-- High operations and maintenance costs: to use MyCat, it’s required to configure a series of parameters plus HA load balancer.
-- Users have to independently deploy the service, which may increase system risks.
-
-Of course, there are similar solutions such as Cobar, Zebra, MTDDL, and [TiDB](https://en.pingcap.com/tidb/) but honestly, we didn’t spend much time researching other solutions, because we decided to use ShardingSphere as we felt it meets the company’s needs.
-
-## F6 Automobile Technology’s Overall Plan
-Based on our company’s business model, we chose Client ID as Sharding Key to ensure that work order data of one client is stored in the same single table of the same client-specific database. Therefore, performance loss caused by multi-table correlated queries is avoided; plus later, even if multi-databases sharding is required, cross-database transactions and cross-database JOIN can be avoided.
-
-Among client ID databases, the type BIGINT(20) applies UID (Unique Identification Number, or we call it “gene” ) to ensure potential database scaling in the future; the last two digits of a client ID are its UID, so according to the double scaling rule, the maximum reaches 64 databases. The values of left bits can be used for table sharding, which can be split into 32 sharding tables.
-
-Take 10545055917999668983 as the client ID example and the rules are shown as follows:
-
-`105450559179996689 83
-Table sharding uid value % 32 database sharding uid value % 1`
-
-The last two digits (i.e. 83) are used for database sharding, of which temporary data is only sharded into the library f6xxx, so the remainder is 0. Later, increasing data volume can be expanded to multiple libraries. The remaining value 105450559179996689 is used for table sharding. At first time, it is divided into 32 single tables so the modulo remainders correspond to the specific sharding table subscripts are 0~31.
-
-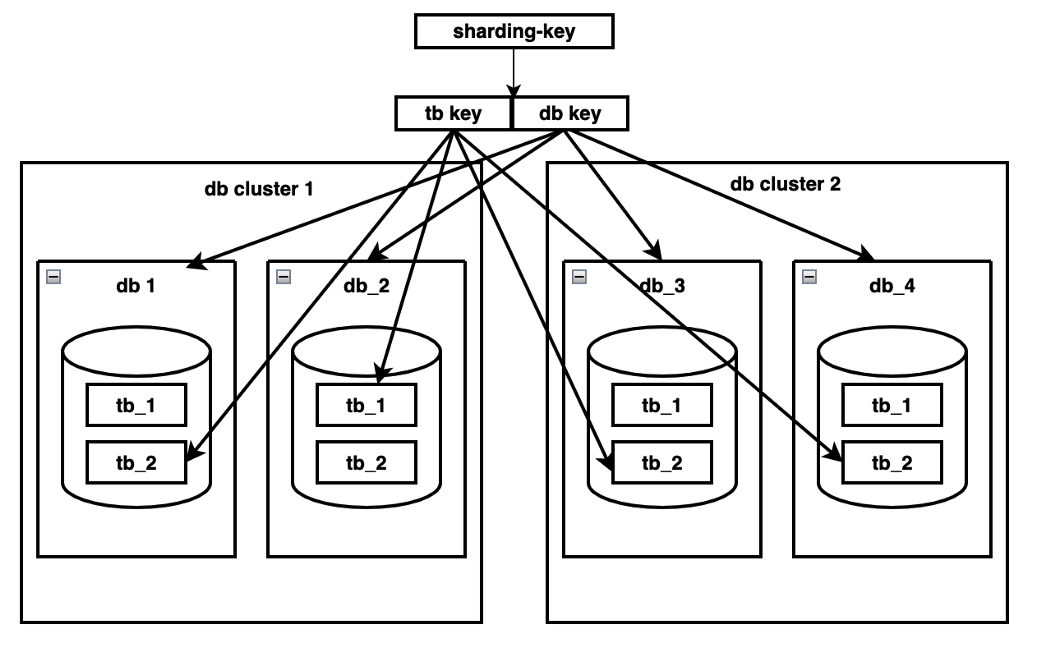
-
-Given that the business system is growing and we adopt rapid iteration method to develop features step by step, we plan to shard tables first and then do database sharding.
-
-Data sharding has a great impact on the system, so we need greyscale release— if unfortunately, an issue occurs, the system can quickly start roll-back, to ensure a functioning business system. The implementation details are given below:
-
-**Table Sharding**
-
-- Switch from JDBC to Sharding-JDBC to connect data sources
-- Decouple the write databases, and then migrate codes
-- Synchronize historical data and incremental data
-- Switch sharding tables
-
-**Database Sharding**
-
-- Migrate the read-only databases
-- Data migration
-- Switch read-only databases
-- Switch write-only databases
-
-## Table Sharding Details
-***Number of Sharding Tables***
-
-In the industry, the data of a single table should usually be limited to 5 million rows, and the number of sharding tables should be a power of two to make them scalable. The exact number of sharding tables is calculated based on business development speed and future data increase as well as the future data archiving plan. After sharding table count and sharding algorithms are defined, it’s OK to assess the current data volume in each sharding table.
-
-***Preparation***
-
-**- Replace the database & auto table ID generator**
-
-After table sharding, we could no longer use the auto database ID generator anymore, so we had to find a feasible solution. We had two plans:
-
-Plan 1: Use other keys such as snowflake
-
-Plan 2: Implement an incremental component (database or Redis) all by ourselves
-
-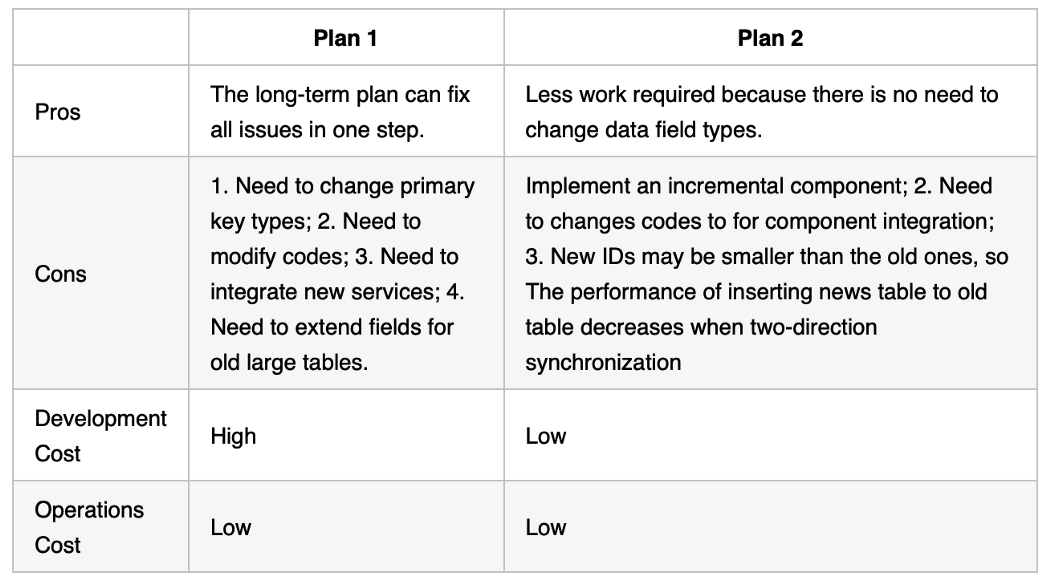
-
-After comparing the two solutions and the business condition, we decided to choose Plan 2 and concurrently, provided a new comprehensive table-level ID generator solution.
-
-**- Check whether all requests are carried with shard keys**
-
-Now, the microservice traffic entrances include:
-- HTTP
-- Dubbo
-- XXLJOB scheduled job
-- Message Queue (MQ)
-
-After table sharding, to quickly locate data shards, all requests must carry their shard keys.
-
-**- Decoupling**
-
-1. Decouple business systems of each domain and use interfaces to interact with read and write data.
-2. Remove Direct Table JOIN and use interfaces instead.
-
-The biggest problem brought by the decoupling is the distributed transaction problem: how to ensure data consistency. Usually, developers introduce distributed transaction components to ensure transaction consistency or they use compensation or other mechanisms to ensure final data consistency.
-
-***Grayscale Release Plan***
-
-In order to ensure quick roll-back when problems caused by new feature releases occur, all online modifications are released step by step based on clients. Our grayscale release plan is shown as follows:
-
-**Plan 1:** Maintain two sets of Mapper interfaces: one uses Sharding-JDBC data sources to connect to databases while the other uses JDBC data sources to connect to databases. At the service layer, it’s necessary to select one of the two interfaces based on the decision workflow diagram below:
-
-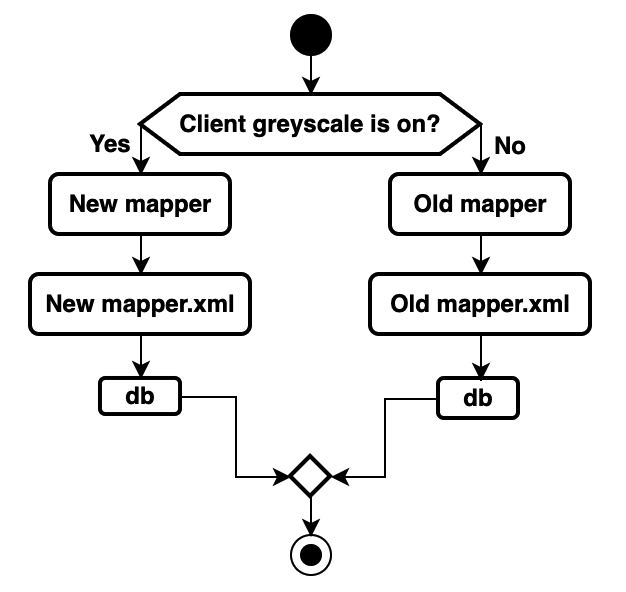
-
-However, the solution causes another problem: all codes visiting the Mapper layer have an if else branch, resulting in major business code changes, potential code intrusion, and harder code maintenance. Therefore, we found another solution and we call it Plan 2.
-
-**Plan 2 — Adaptive Mapper Selection Plan:** one set of Mapper interface is with two data sources and two sets of implementations. Based on the grayscale configuration, different client requests will go through different Mapper implementations, and one service corresponds to two data sources and two sets of transaction managers, and based on the grayscale configuration, different clients’ requests go to different transaction managers. Accordingly, we leverage multiple Mapper scanners of [...]
-
-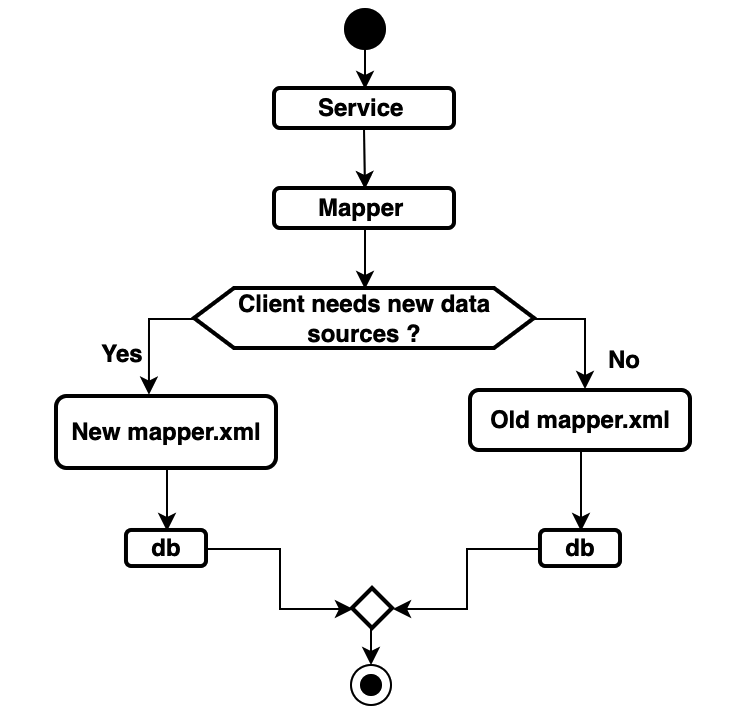
-
-***Data Source Connection Switch***
-
-Apache ShardingSphere already lists some grammars currently not supported by Sharding-JDBC on its website, but we still found the following problematic SQL statements that Sharding-JDBC parser cannot handle:
-
-- A subquery without a shard key.
-- Not support `Insert` statements whose values include cast ifnull now and other functions.
-- Not support `ON DUPLICATE KEY UPDATE`.
-- By default, select for update goes to the slave database (the issue has fixed since 4.0.0.RC3).
-- Sharding-JDBC does not support the statement ResultSet.first () of MySqlMapper with Optimistic Concurrency Control used to query vision.
-- No such statement for batch updates.
-- Even if `UNION ALL` does not support the grayscale release plan, we only need to copy a set of mapper.xml, and modify it based on the syntax of Sharding-JDBC before release.
-
-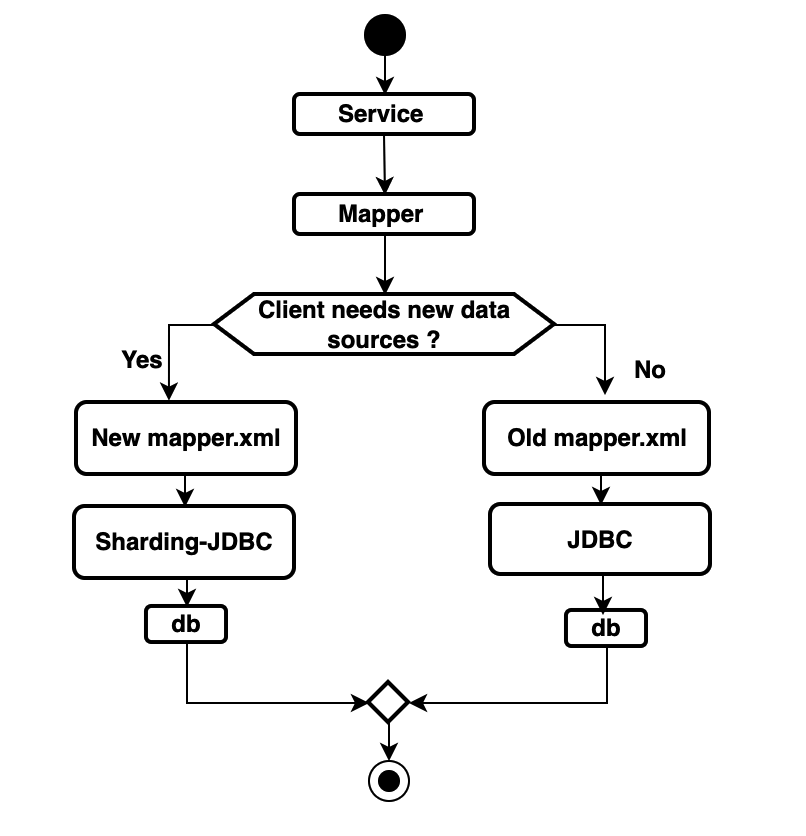
-
-***Historical Data Sync***
-
-[DataX](https://www.alibabacloud.com/help/en/doc-detail/126635.htm) is Alibaba Group’s offline data synchronization tool that can effectively sync heterogeneous data sources such as MySQL, Oracle, SqlServer, Postgre SQL, HDFS, Hive, ADS, HBase, TableStore(OTS), MaxCompute(ODPS) and DRDS.
-
-The data synchronization framework DataX can abstract the synchronization of different data sources as a Reader Plugin that reads data from the data source, and then as a Writer Plugin that writes data to the target. In theory, the DataX framework can support data synchronization of all data source types. Additionally, the DataX plugin ecosystem can allow every newly-added data source to immediately interact with the old data sources.
-
-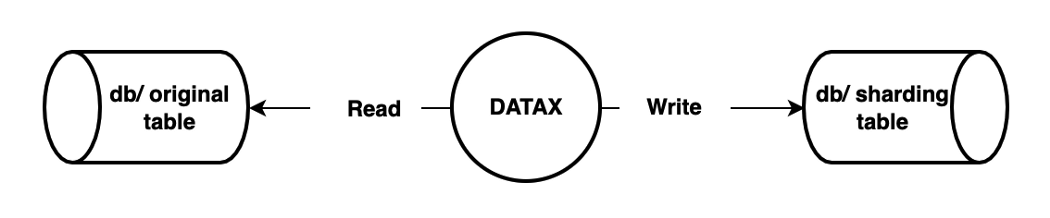
-
-***Verify Data Synchronization***
-
-- Use timed tasks to compare the number of data of the original table and of the sharding table.
-- Use timed tasks to compare the values of key fields.
-
-***Read/write Splitting and Table Sharding***
-
-Before read/write splitting, we needed to configure incremental data synchronization first.
-- Incremental Data Synchronization
-
-We used another open source distributed database sync project named Otter to synchronize incremental data. Based on database incremental log parsing, otter can synchronize data of MySQL/Oracle databases of the local computer room or the remote computer room. To use Otter, we needed to pay extra attention to the following tips:
-
-- For MySQL databases, users must have binlog enabled, and set its mode as ROW.
-- The user must have the query permission of binlog so they need to apply for that as an otter user.
-- Now, the binlog of DMS database is stored for only 3 days. In Otter, users can define the starting position of binlog synchronization and the starting point of incremental synchronization by themselves: first, select slave-testDb on the SQL platform, and use the SQL statement “show master status” to query.
-
-Note: the execution results of `show master status` of master and slave may be different, so if you set it, you need to get the execution result of the master database. We think this function is really useful because when Otter’s data synchronization fails, we can reset points and synchronize again from the beginning.
-
-- When Otter is disabled, it will automatically record the last point of synchronization, and continue to synchronize data from this point next time.
-- Otter allows developers to define their own processing process. For example, we can configure data routing rules and control the direction of client data synchronization data from subtable to parent table or vice versa.
-- Disabling Otter will not invalidate the cache defined in the user-defined Otter processing process. To fix it, the solution is to modify the code comment and save it.
-**- Read/write Splitting Plan**
-
-Our greyscale switch plan is shown below:
-
-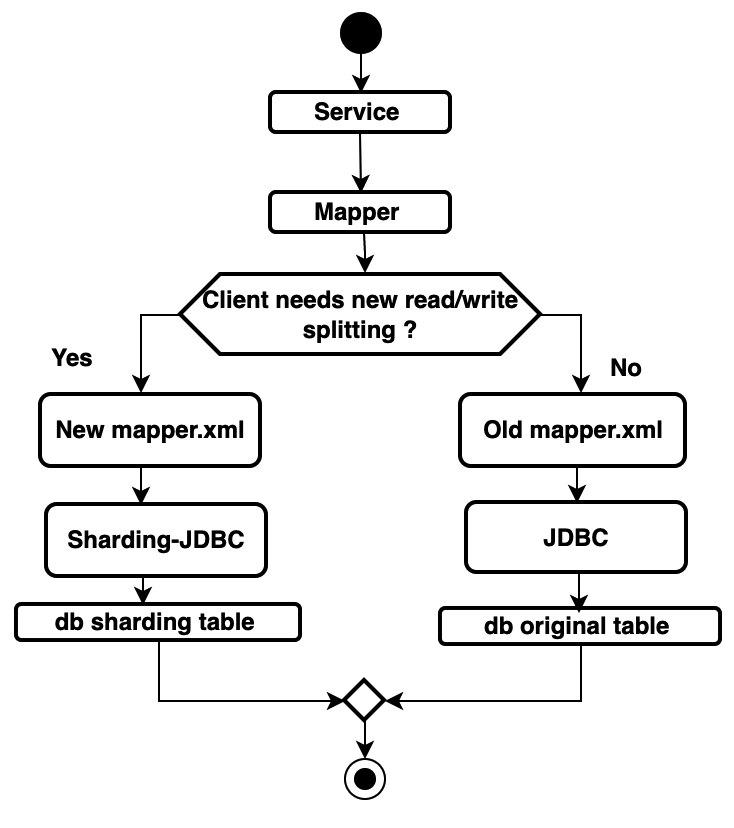
-
-We chose the grayscale release solution, which means it was necessary to ensure real-time data updates in both subtables and parent tables. Therefore, all data was synchronized in two directions: for clients with grayscale release being on, reads and writes went to subtables and the data was synchronized to parent tables in real time via Otter, while for clients with grayscale release being off, reads and writes went to parent tables and the data is synchronized to subtables in real time [...]
-
-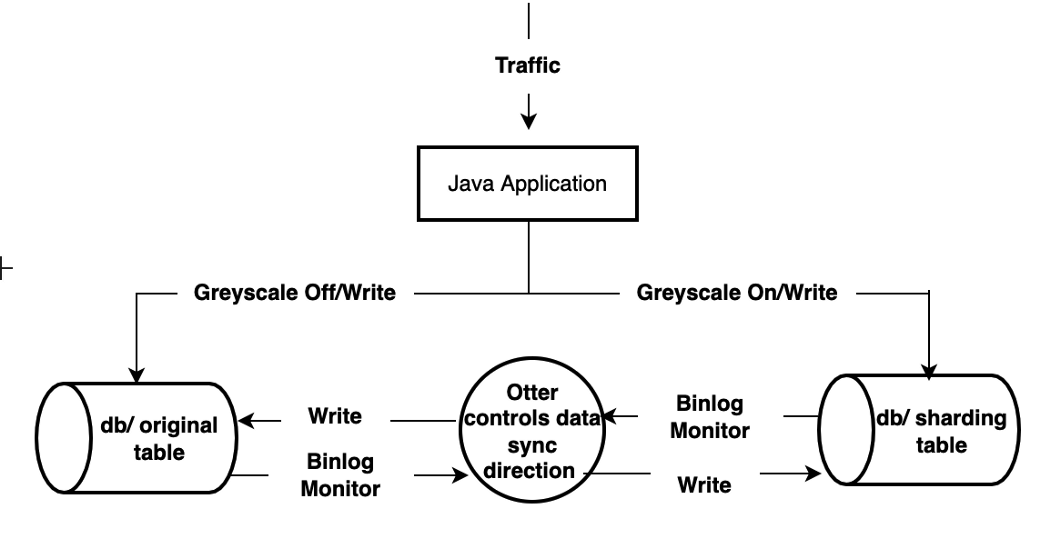
-
-**Database Sharding Details**
-
-***Preparations***
-
-**- Primary Key**
-
-Primary key should be auto increment type (sharding tables should be global auto increment) or access the only primary key numbering service (server_id independent of DB). Table auto increment primary key generation or uuid_short generated key require switching.
-
-**- Storage Procedure, Functions, Trigger and EVENT**
-
-Try to remove them first if present; if they cannot be removed, create them in advance in new databases.
-
-**- Data Synchronization**
-
-Data synchronization uses DTS or sqldump (historical data) + otter (incremental data) for synchronization.
-
-**- Database Change Procedure**
-
-To avoid potential performance and compatibility problems, database change plan must follow two criterion:
-
-- Greyscale switching: traffic is gradually switching to RDS (Alibaba Cloud Relational Database Service, a.k.a. RDS), allowing obervance of database performance at any time.
-- Quick Rollback: achieving quick reversion when problems occur with little impact on user experience.
-
-**Status Quo:** four application instances +one master db and two slave db
-
-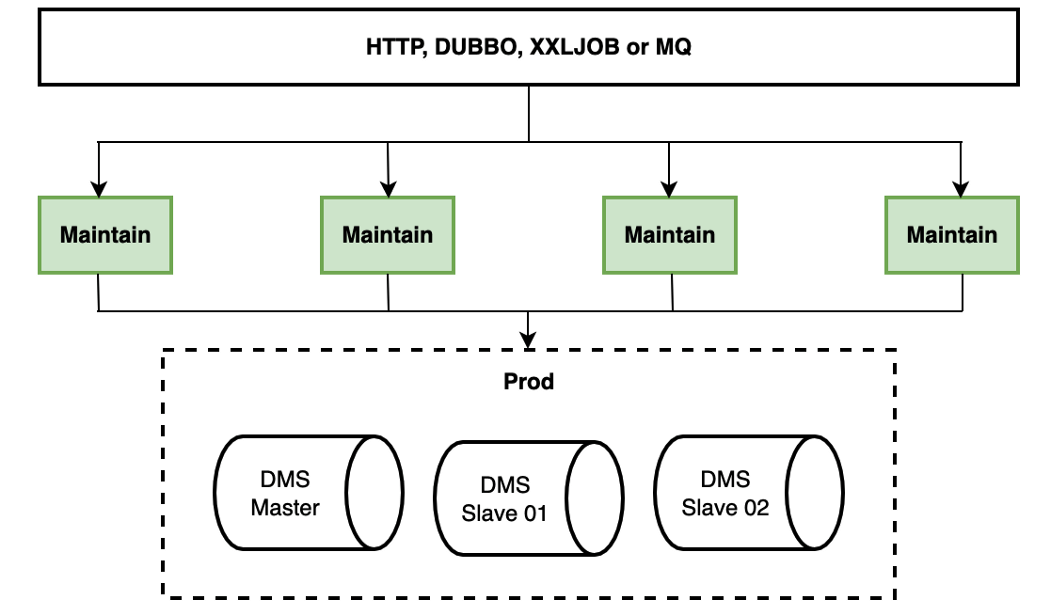
-
-**Step 1:** add a new application instance and switch it to RDS, write into or pass dms master database, and the data in dms master database will be synced to rds in real time
-
-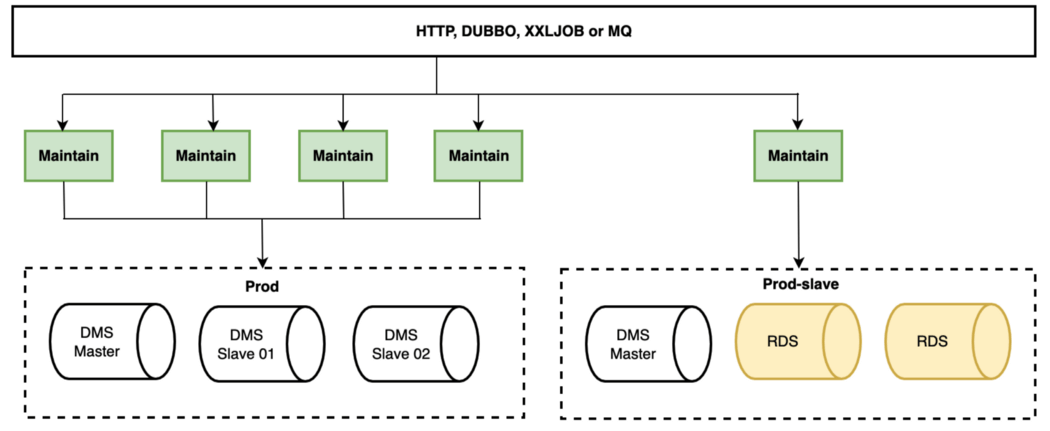
-
-**Step 2:** add three more application instances, and cut 50% of the data to write into rds database
-
-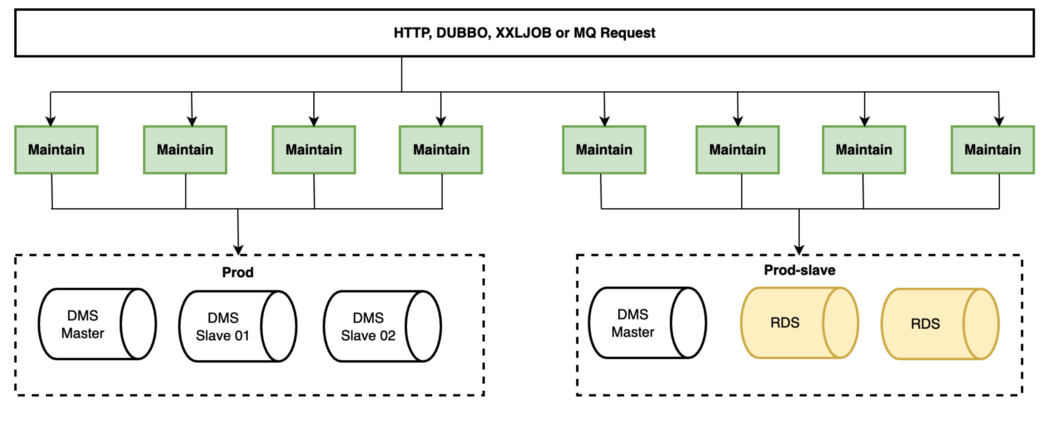
-
-**Step 3:** remove the four original instance traffic, and read them into rds instances while writing still goes into dms master database
-
-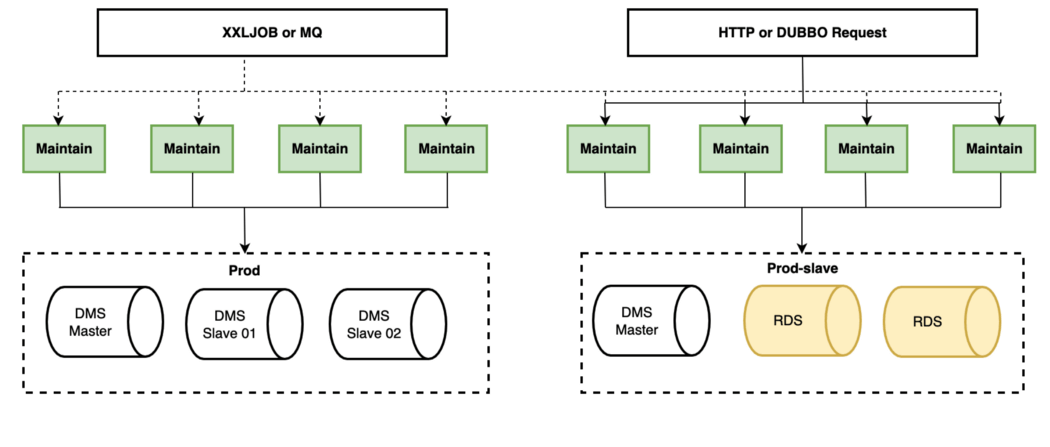
-
-**Step 4:** switch the master database into rds, and rds data will be reversely synced to dms master database to make it easier for the quick rollback of the data
-
-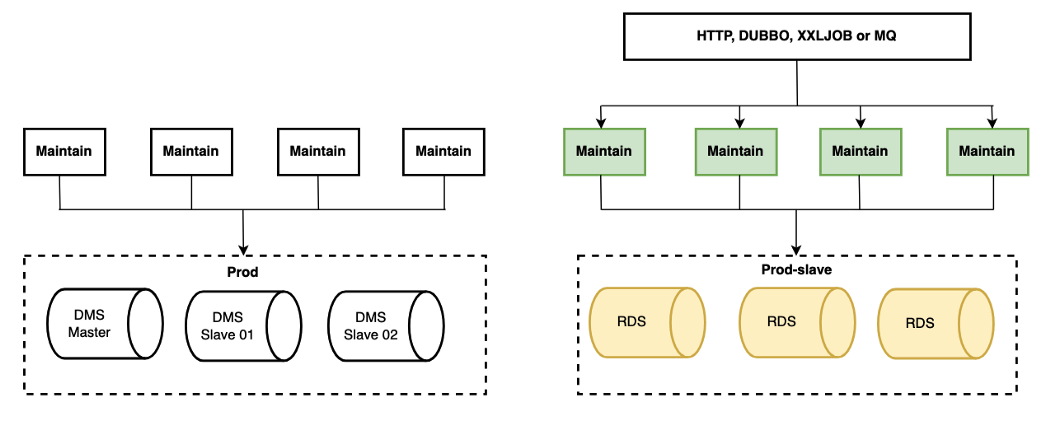
-
-**Step 5:** Completion
-
-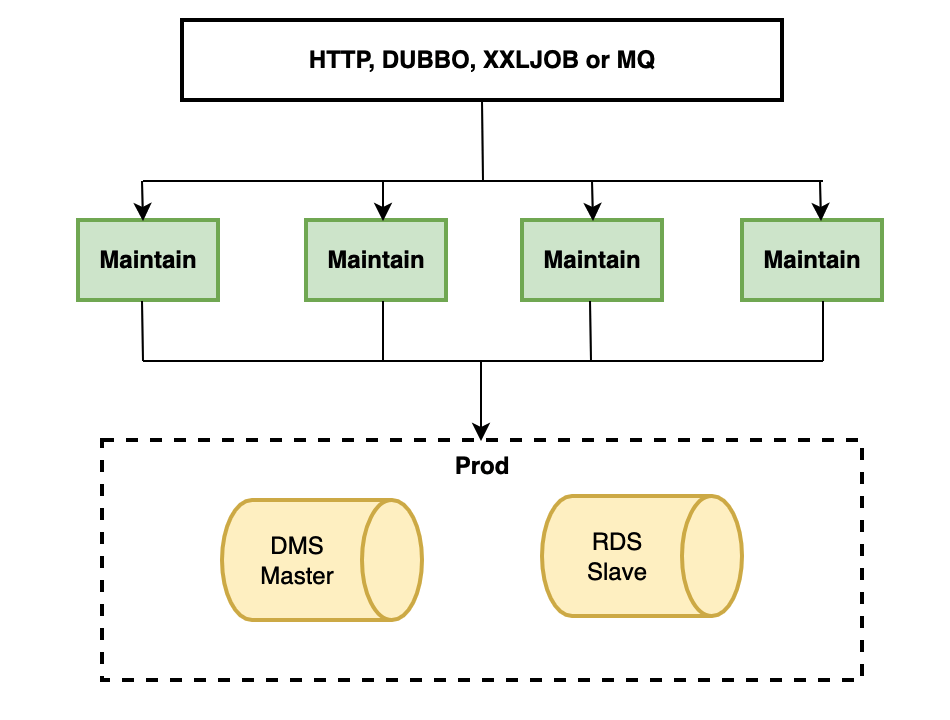
-
-Each step mentioned above can be quickly rolled back through traffic switching so as to ensure the availability and stability of system.
-
-**Sharding & Scaling**
-
-When the performance of a single database reaches a plateau, we can scale out the database by modifying sharding database routing algorithms and migrating data.
-
-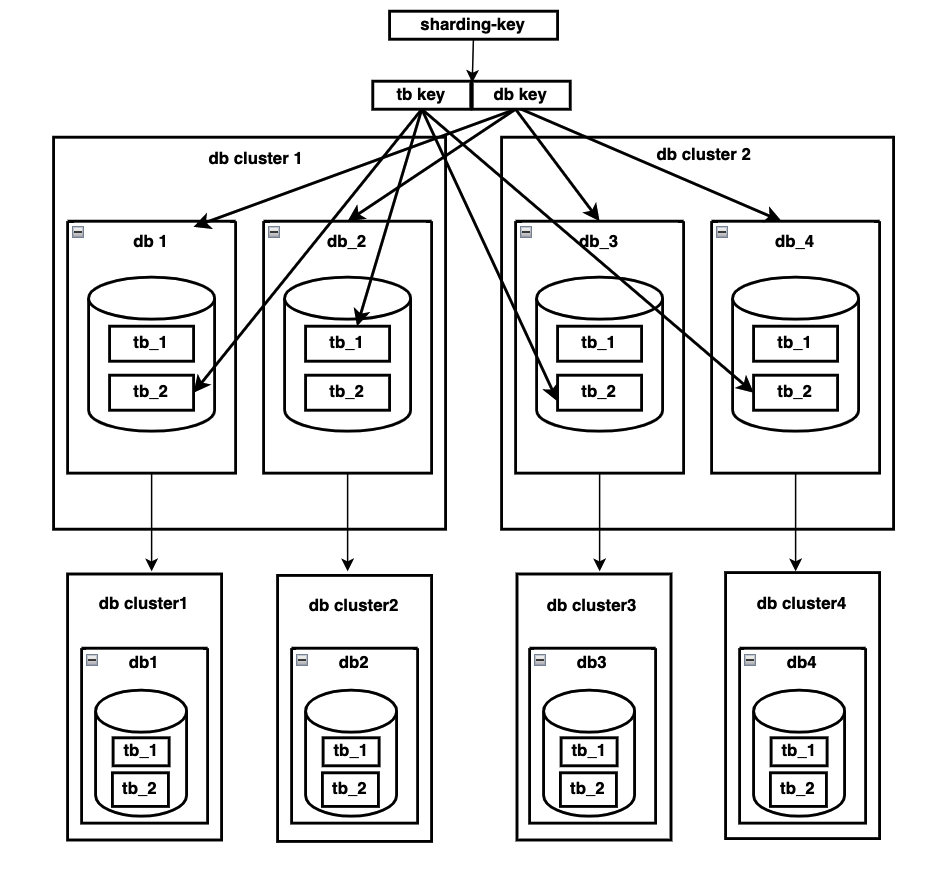
-
-When the capacity of a single table reaches its maximum size, we can scale out the table by modifying sharding table routing algorithms and migrating data.
-
-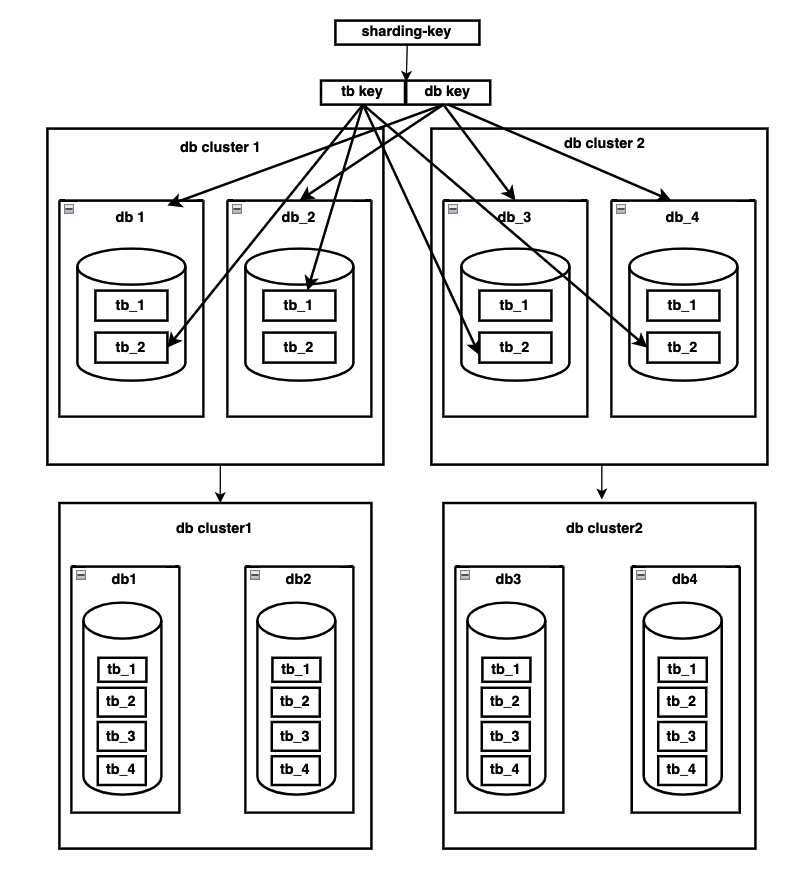
-
-**FAQ**
-
-***Q: Sometimes, Otter receives binlog data but the data cannot be found in the database?***
-**A:** To make our MySQL compatible with replicas of other non-transactional engines, we added binlog at the server layer. Binlog can record all engine modification operations, so it can support replication function for all engines. The problem is a potential inconsistency between redo log and binlog but MySQL uses its internal XA mechanism to fix the issue.
-
-**Step 1:** Not perform operations on InnoDB prepare, write/sync redo log and binlog.
-
-**Step 2:** First, write/sync Binlog and then InnoDB commit (commit in memory).
-
-Of course, group commit has been added since version 5.6. The development improves I/O performance to some degree, but it doesn’t change the execution order.
-
-After write/sync Binlog is done, the binlog has been written, so MySQL considers that the transaction has been committed and persisted (now, the binlog is ready to be sent to subscribers). Even if a database crashes, the transaction can still be recovered correctly after MySQL reboot. However, before this step, any operation failure may cause transaction rollback.
-
-InnoDB commit is centered on memory commit such as killing locks, read views related to multiversion concurrency control release. MySQL believes that no errors occur in this step — once an error really occurs, the database will crash — MySQL itself cannot handle the crash. This step does not have any logic that causes transaction rollback. In terms of program operations, only after this step is completed, the changes caused by the transaction can be shown through the API or queries at th [...]
-
-The reason why the problem may occur is that the binlog is sent first, and then db commit is done. We use query retries to fix this issue.
-
-***Q: When it comes to multi-table queries, sometimes, why some tables cannot get data?***
-**A:** The master/slave routing strategy of Sharding-JDBC is shown below:
-
-Master databases are chosen in the following scenarios:
-
-- SQL statements that include lock such as select for update ( of Version 4.0.0.RC3);
-- Not SELECT statements;
-- Threads that have already gone to master databases;
-- Codes specify the requests for master databases.
-
-Algorithms used to choose from multiple slave databases:
-
-- Polling Strategy
-- Load Balancer Strategy
-The default is the polling strategy.
-
-However, one query may go to different slave databases, or it may go to the master library and slave databases, which occurs when there is time inconsistency between master-slave database latency or multi-slave latency.
-
-***Q: How can we remove network traffic?***
-
-**A:**
-- http: use nginx to remove upstream;
-- dubbo: leverage its qos module to execute offline/online command;
-- xxljob: manually enter execution IP of the executor to specify instances;
-- MQ: use the API provided by Alibaba Cloud to enable or disable consumer bean.
-
-## Apache ShardingSphere Open Source Project Links:
-[ShardingSphere Github](https://github.com/apache/shardingsphere)
-
-[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
-
-[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
-
-## Author
-**Yacine Si Tayeb**
-
-SphereEx Head of International Operations
-
-Apache ShardingSphere Contributor
-
-Passionate about technology and innovation, Yacine moved to Beijing to pursue his Ph.D. in Business Administration, and fell in awe of the local startup and tech scene. His career path has so far been shaped by opportunities at the intersection of technology and business. Recently he took on a keen interest in the development of the ShardingSphere database middleware ecosystem and Open-Source community building.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
++++
+title = "F6 Automobile Technology’s Multimillion Rows of Data Sharding Strategy Based on Apache ShardingSphere"
+weight = 31
+chapter = true
++++
+
+# F6 Automobile Technology’s Multimillion Rows of Data Sharding Strategy Based on Apache ShardingSphere
+
+[F6 Automobile Technology](https://www.f6car.com/) is an Internet platform company focusing on the informatization of the automotive aftermarket.
+
+It helps automotive repair companies (clients) build their smart management systems to digitally transform the auto aftermarket.
+The data of different auto repair companies will certainly be isolated from each other, so theoretically the data can be stored in different tables of different databases. However, fast-growing enterprises face increasing data volume challenges: sometimes total data volume in a single table may approach 10 million or even 100 million entries.
+
+
+This issue definitely challenges business growth. Moreover, growing enterprises are now also planning to split their systems into many microservices based on domains or business types, and accordingly, different databases are vertically required for different business cases.
+
+## Why Did We Need Data Sharding?
+Relational databases are bottlenecks when it comes to storage capacity, connection count, and processing capabilities.
+
+
+First, we always prioritize database performance. When the data volume of a single table reaches tens of millions, and there are a relatively large number of query dimensions, system performance would still prove unsatisfactory even if we added more slave databases and optimize indexes. This meant it was time for us to consider data sharding.
+
+The purpose of data sharding is to reduce database load stress and query time. Additionally, since a single database often has a limited number of connections, when Queries Per Second (QPS) indicator of the database is too high, database sharding is certainly needed to share connection stress.
+
+Second, to ensure availability was another important reason. If unfortunately, an accident occurs in a single database, we’d likely lose all data and further affect all services. Database sharding can minimize risk and the negative impact on business services. Generally, when the data volume of a table is greater than 2GB or the number of data rows is greater than 10 million, not to mention that the data is also growing rapidly, we’d better use data sharding.
+## What’s Data Sharding?
+There are four common types of data sharding in the industry:
+
+- Vertical table sharding: split big tables into small ones, field-based, which means less frequently used or relatively long fields are split into extended tables.
+- Vertical database sharding: business-based database sharding is used to solve performance bottlenecks of a single database.
+- Horizontal table sharding: distribute tables’ data rows into different tables according to some rules in order to decrease the data volume of single tables and optimize query performance. In terms of the database layer, it still faces bottlenecks.
+- Horizontal data sharding: based on horizontal table sharding, distribute data into different databases to effectively improve performance, lower stress of stand-alone machine and single databases, and break the shackles of I/O, connections, and hardware resources.
+## Excellent Data Sharding Solutions
+1. [Sharding-JDBC](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-jdbc-quick-start/) (Apache ShardingSphere)
+**Pros:**
+- Supported by an active open source community. Now, Apache ShardingSphere 5.0 version has been released and the development iteration speed is fast.
+- Proven efficacy by many successful enterprise application cases: big companies such as JD Technology and Dangdang.com have applied ShardingSphere.
+- Easy deployment: Sharding-JDBC can be quickly integrated into any project without extra services deployed.
+- Excellent compatibility: it can route to a single data node and perfectly support SQL.
+- Excellent performance and low loss: test results can be found on the Apache ShardingSphere website.
+-
+**Cons:**
+
+- Potential increase in operations and maintenance costs, and troublesome field changes and index creation after data sharding. To fix the issue, users need to deploy Sharding-Proxy that supports heterogeneous languages and is more friendly to DBAs.
+- So far, the project doesn’t support data shards dynamic migration yet. Therefore, feature implementation is required.
+
+2. [MyCat](http://mycat.sourceforge.net/)
+
+**Pros:**
+
+- MyCat is a middleware placed between applications and databases to handle data processing and interactions. It cannot be perceived during development, and integrating MyCat does not cost much.
+- Use JDBC to connect databases such as Oracle, DB2, SQL Server, and MySQL.
+- Support multiple languages plus easy deployment and implementation across different platforms.
+- High availability and auto-switch triggered by a crash.
+
+**Cons:**
+
+- High operations and maintenance costs: to use MyCat, it’s required to configure a series of parameters plus HA load balancer.
+- Users have to independently deploy the service, which may increase system risks.
+
+Of course, there are similar solutions such as Cobar, Zebra, MTDDL, and [TiDB](https://en.pingcap.com/tidb/) but honestly, we didn’t spend much time researching other solutions, because we decided to use ShardingSphere as we felt it meets the company’s needs.
+
+## F6 Automobile Technology’s Overall Plan
+Based on our company’s business model, we chose Client ID as Sharding Key to ensure that work order data of one client is stored in the same single table of the same client-specific database. Therefore, performance loss caused by multi-table correlated queries is avoided; plus later, even if multi-databases sharding is required, cross-database transactions and cross-database JOIN can be avoided.
+
+Among client ID databases, the type BIGINT(20) applies UID (Unique Identification Number, or we call it “gene” ) to ensure potential database scaling in the future; the last two digits of a client ID are its UID, so according to the double scaling rule, the maximum reaches 64 databases. The values of left bits can be used for table sharding, which can be split into 32 sharding tables.
+
+Take 10545055917999668983 as the client ID example and the rules are shown as follows:
+
+`105450559179996689 83
+Table sharding uid value % 32 database sharding uid value % 1`
+
+The last two digits (i.e. 83) are used for database sharding, of which temporary data is only sharded into the library f6xxx, so the remainder is 0. Later, increasing data volume can be expanded to multiple libraries. The remaining value 105450559179996689 is used for table sharding. At first time, it is divided into 32 single tables so the modulo remainders correspond to the specific sharding table subscripts are 0~31.
+
+
+
+Given that the business system is growing and we adopt rapid iteration method to develop features step by step, we plan to shard tables first and then do database sharding.
+
+Data sharding has a great impact on the system, so we need greyscale release— if unfortunately, an issue occurs, the system can quickly start roll-back, to ensure a functioning business system. The implementation details are given below:
+
+**Table Sharding**
+
+- Switch from JDBC to Sharding-JDBC to connect data sources
+- Decouple the write databases, and then migrate codes
+- Synchronize historical data and incremental data
+- Switch sharding tables
+
+**Database Sharding**
+
+- Migrate the read-only databases
+- Data migration
+- Switch read-only databases
+- Switch write-only databases
+
+## Table Sharding Details
+***Number of Sharding Tables***
+
+In the industry, the data of a single table should usually be limited to 5 million rows, and the number of sharding tables should be a power of two to make them scalable. The exact number of sharding tables is calculated based on business development speed and future data increase as well as the future data archiving plan. After sharding table count and sharding algorithms are defined, it’s OK to assess the current data volume in each sharding table.
+
+***Preparation***
+
+**- Replace the database & auto table ID generator**
+
+After table sharding, we could no longer use the auto database ID generator anymore, so we had to find a feasible solution. We had two plans:
+
+Plan 1: Use other keys such as snowflake
+
+Plan 2: Implement an incremental component (database or Redis) all by ourselves
+
+
+
+After comparing the two solutions and the business condition, we decided to choose Plan 2 and concurrently, provided a new comprehensive table-level ID generator solution.
+
+**- Check whether all requests are carried with shard keys**
+
+Now, the microservice traffic entrances include:
+- HTTP
+- Dubbo
+- XXLJOB scheduled job
+- Message Queue (MQ)
+
+After table sharding, to quickly locate data shards, all requests must carry their shard keys.
+
+**- Decoupling**
+
+1. Decouple business systems of each domain and use interfaces to interact with read and write data.
+2. Remove Direct Table JOIN and use interfaces instead.
+
+The biggest problem brought by the decoupling is the distributed transaction problem: how to ensure data consistency. Usually, developers introduce distributed transaction components to ensure transaction consistency or they use compensation or other mechanisms to ensure final data consistency.
+
+***Grayscale Release Plan***
+
+In order to ensure quick roll-back when problems caused by new feature releases occur, all online modifications are released step by step based on clients. Our grayscale release plan is shown as follows:
+
+**Plan 1:** Maintain two sets of Mapper interfaces: one uses Sharding-JDBC data sources to connect to databases while the other uses JDBC data sources to connect to databases. At the service layer, it’s necessary to select one of the two interfaces based on the decision workflow diagram below:
+
+
+
+However, the solution causes another problem: all codes visiting the Mapper layer have an if else branch, resulting in major business code changes, potential code intrusion, and harder code maintenance. Therefore, we found another solution and we call it Plan 2.
+
+**Plan 2 — Adaptive Mapper Selection Plan:** one set of Mapper interface is with two data sources and two sets of implementations. Based on the grayscale configuration, different client requests will go through different Mapper implementations, and one service corresponds to two data sources and two sets of transaction managers, and based on the grayscale configuration, different clients’ requests go to different transaction managers. Accordingly, we leverage multiple Mapper scanners of [...]
+
+
+
+***Data Source Connection Switch***
+
+Apache ShardingSphere already lists some grammars currently not supported by Sharding-JDBC on its website, but we still found the following problematic SQL statements that Sharding-JDBC parser cannot handle:
+
+- A subquery without a shard key.
+- Not support `Insert` statements whose values include cast ifnull now and other functions.
+- Not support `ON DUPLICATE KEY UPDATE`.
+- By default, select for update goes to the slave database (the issue has fixed since 4.0.0.RC3).
+- Sharding-JDBC does not support the statement ResultSet.first () of MySqlMapper with Optimistic Concurrency Control used to query vision.
+- No such statement for batch updates.
+- Even if `UNION ALL` does not support the grayscale release plan, we only need to copy a set of mapper.xml, and modify it based on the syntax of Sharding-JDBC before release.
+
+
+
+***Historical Data Sync***
+
+[DataX](https://www.alibabacloud.com/help/en/doc-detail/126635.htm) is Alibaba Group’s offline data synchronization tool that can effectively sync heterogeneous data sources such as MySQL, Oracle, SqlServer, Postgre SQL, HDFS, Hive, ADS, HBase, TableStore(OTS), MaxCompute(ODPS) and DRDS.
+
+The data synchronization framework DataX can abstract the synchronization of different data sources as a Reader Plugin that reads data from the data source, and then as a Writer Plugin that writes data to the target. In theory, the DataX framework can support data synchronization of all data source types. Additionally, the DataX plugin ecosystem can allow every newly-added data source to immediately interact with the old data sources.
+
+
+
+***Verify Data Synchronization***
+
+- Use timed tasks to compare the number of data of the original table and of the sharding table.
+- Use timed tasks to compare the values of key fields.
+
+***Read/write Splitting and Table Sharding***
+
+Before read/write splitting, we needed to configure incremental data synchronization first.
+- Incremental Data Synchronization
+
+We used another open source distributed database sync project named Otter to synchronize incremental data. Based on database incremental log parsing, otter can synchronize data of MySQL/Oracle databases of the local computer room or the remote computer room. To use Otter, we needed to pay extra attention to the following tips:
+
+- For MySQL databases, users must have binlog enabled, and set its mode as ROW.
+- The user must have the query permission of binlog so they need to apply for that as an otter user.
+- Now, the binlog of DMS database is stored for only 3 days. In Otter, users can define the starting position of binlog synchronization and the starting point of incremental synchronization by themselves: first, select slave-testDb on the SQL platform, and use the SQL statement “show master status” to query.
+
+Note: the execution results of `show master status` of master and slave may be different, so if you set it, you need to get the execution result of the master database. We think this function is really useful because when Otter’s data synchronization fails, we can reset points and synchronize again from the beginning.
+
+- When Otter is disabled, it will automatically record the last point of synchronization, and continue to synchronize data from this point next time.
+- Otter allows developers to define their own processing process. For example, we can configure data routing rules and control the direction of client data synchronization data from subtable to parent table or vice versa.
+- Disabling Otter will not invalidate the cache defined in the user-defined Otter processing process. To fix it, the solution is to modify the code comment and save it.
+**- Read/write Splitting Plan**
+
+Our greyscale switch plan is shown below:
+
+
+
+We chose the grayscale release solution, which means it was necessary to ensure real-time data updates in both subtables and parent tables. Therefore, all data was synchronized in two directions: for clients with grayscale release being on, reads and writes went to subtables and the data was synchronized to parent tables in real time via Otter, while for clients with grayscale release being off, reads and writes went to parent tables and the data is synchronized to subtables in real time [...]
+
+
+
+**Database Sharding Details**
+
+***Preparations***
+
+**- Primary Key**
+
+Primary key should be auto increment type (sharding tables should be global auto increment) or access the only primary key numbering service (server_id independent of DB). Table auto increment primary key generation or uuid_short generated key require switching.
+
+**- Storage Procedure, Functions, Trigger and EVENT**
+
+Try to remove them first if present; if they cannot be removed, create them in advance in new databases.
+
+**- Data Synchronization**
+
+Data synchronization uses DTS or sqldump (historical data) + otter (incremental data) for synchronization.
+
+**- Database Change Procedure**
+
+To avoid potential performance and compatibility problems, database change plan must follow two criterion:
+
+- Greyscale switching: traffic is gradually switching to RDS (Alibaba Cloud Relational Database Service, a.k.a. RDS), allowing obervance of database performance at any time.
+- Quick Rollback: achieving quick reversion when problems occur with little impact on user experience.
+
+**Status Quo:** four application instances +one master db and two slave db
+
+
+
+**Step 1:** add a new application instance and switch it to RDS, write into or pass dms master database, and the data in dms master database will be synced to rds in real time
+
+
+
+**Step 2:** add three more application instances, and cut 50% of the data to write into rds database
+
+
+
+**Step 3:** remove the four original instance traffic, and read them into rds instances while writing still goes into dms master database
+
+
+
+**Step 4:** switch the master database into rds, and rds data will be reversely synced to dms master database to make it easier for the quick rollback of the data
+
+
+
+**Step 5:** Completion
+
+
+
+Each step mentioned above can be quickly rolled back through traffic switching so as to ensure the availability and stability of system.
+
+**Sharding & Scaling**
+
+When the performance of a single database reaches a plateau, we can scale out the database by modifying sharding database routing algorithms and migrating data.
+
+
+
+When the capacity of a single table reaches its maximum size, we can scale out the table by modifying sharding table routing algorithms and migrating data.
+
+
+
+**FAQ**
+
+***Q: Sometimes, Otter receives binlog data but the data cannot be found in the database?***
+**A:** To make our MySQL compatible with replicas of other non-transactional engines, we added binlog at the server layer. Binlog can record all engine modification operations, so it can support replication function for all engines. The problem is a potential inconsistency between redo log and binlog but MySQL uses its internal XA mechanism to fix the issue.
+
+**Step 1:** Not perform operations on InnoDB prepare, write/sync redo log and binlog.
+
+**Step 2:** First, write/sync Binlog and then InnoDB commit (commit in memory).
+
+Of course, group commit has been added since version 5.6. The development improves I/O performance to some degree, but it doesn’t change the execution order.
+
+After write/sync Binlog is done, the binlog has been written, so MySQL considers that the transaction has been committed and persisted (now, the binlog is ready to be sent to subscribers). Even if a database crashes, the transaction can still be recovered correctly after MySQL reboot. However, before this step, any operation failure may cause transaction rollback.
+
+InnoDB commit is centered on memory commit such as killing locks, read views related to multiversion concurrency control release. MySQL believes that no errors occur in this step — once an error really occurs, the database will crash — MySQL itself cannot handle the crash. This step does not have any logic that causes transaction rollback. In terms of program operations, only after this step is completed, the changes caused by the transaction can be shown through the API or queries at th [...]
+
+The reason why the problem may occur is that the binlog is sent first, and then db commit is done. We use query retries to fix this issue.
+
+***Q: When it comes to multi-table queries, sometimes, why some tables cannot get data?***
+**A:** The master/slave routing strategy of Sharding-JDBC is shown below:
+
+Master databases are chosen in the following scenarios:
+
+- SQL statements that include lock such as select for update ( of Version 4.0.0.RC3);
+- Not SELECT statements;
+- Threads that have already gone to master databases;
+- Codes specify the requests for master databases.
+
+Algorithms used to choose from multiple slave databases:
+
+- Polling Strategy
+- Load Balancer Strategy
+The default is the polling strategy.
+
+However, one query may go to different slave databases, or it may go to the master library and slave databases, which occurs when there is time inconsistency between master-slave database latency or multi-slave latency.
+
+***Q: How can we remove network traffic?***
+
+**A:**
+- http: use nginx to remove upstream;
+- dubbo: leverage its qos module to execute offline/online command;
+- xxljob: manually enter execution IP of the executor to specify instances;
+- MQ: use the API provided by Alibaba Cloud to enable or disable consumer bean.
+
+## Apache ShardingSphere Open Source Project Links:
+[ShardingSphere Github](https://github.com/apache/shardingsphere)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
+
+## Author
+**Yacine Si Tayeb**
+
+SphereEx Head of International Operations
+
+Apache ShardingSphere Contributor
+
+Passionate about technology and innovation, Yacine moved to Beijing to pursue his Ph.D. in Business Administration, and fell in awe of the local startup and tech scene. His career path has so far been shaped by opportunities at the intersection of technology and business. Recently he took on a keen interest in the development of the ShardingSphere database middleware ecosystem and Open-Source community building.
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/blog/content/material/Jan_28_Full_Link_Online_Stress_Testing_for_Production_Database_Apache_ShardingSphere_Shadow_Database_Feature_Upgrade.en.md b/docs/blog/content/material/Jan_28_Full_Link_Online_Stress_Testing_for_Production_Database_Apache_ShardingSphere_Shadow_Database_Feature_Upgrade.en.md
index 402ef7ba799..d23c463396e 100644
--- a/docs/blog/content/material/Jan_28_Full_Link_Online_Stress_Testing_for_Production_Database_Apache_ShardingSphere_Shadow_Database_Feature_Upgrade.en.md
+++ b/docs/blog/content/material/Jan_28_Full_Link_Online_Stress_Testing_for_Production_Database_Apache_ShardingSphere_Shadow_Database_Feature_Upgrade.en.md
@@ -1,244 +1,131 @@
-+++
-title = "Full Link Online Stress Testing for Production Database: Apache ShardingSphere Shadow Database Feature Upgrade"
-weight = 34
-chapter = true
-+++
-
-# Full Link Online Stress Testing for Production Database: Apache ShardingSphere Shadow Database Feature Upgrade
-
-## What is full link stress testing?
-
-As the Internet industry is growing rapidly, businesses that operate with large amounts of data are seeing a rapid expansion.
-
-Predictably, ever changing customer demand is having a significant impact on the stability of their whole systems. For example, online food delivery platforms receive most of their customer orders at noon and in the evening. Online shopping sprees and time-limited sales promotions are also good examples.
-
-All businesses are served by a series of business systems which are distributedly deployed in different machines. “Data Plannig” cannot only ensure systems’ stability but also save costs, which are some of the major problems for technology teams.
-
-To precisely get the right service from a specific machine, stress testing should be conducted in the production environment. This can ensure the authenticity of the environment and the data, significantly improving the precision of “data planning”.
-
-## Shadow Database and Full-Link Stress Testing
-
-Performing a stress test on an online business system is evidently risky. For example, data corruption or performance problems may arise.
-
-Just imagine how it would compromise customer experience, if customers found their order has been lost or an unpaid order popped up?
-
-Full-link online stress testing implies a significant amount of complicated work which requires cooperation between microservices and middlewares. [Apache ShardingSphere](https://shardingsphere.apache.org/) focuses on database-level solutions in full-link stress testing.
-
-With ShardingSphere’s powerful SQL parsing capability, Apache ShardingSphere released the shadow database stress testing feature to determine shadow databases by executing SQL, and to meet the online stress testing needs in complicated business scenarios with the flexible configuration of shadow algorithms. By routing stress testing traffic to shadow databases, and normal online traffic to production database, stress testing data will be isolated and the data corruption problem is solved.
-
-## Shadow Database Function Upgrading
-
-Shadow database function was initially realized in version 4.1.0 by adding a logic shadow column. By parsing, executing, routing and rewriting SQL, Apache ShardingSphere deleted the shadow column and column value. Users do not need to setup or do anything during this process. They only need to modify SQL accordingly, add shadow fields and corresponding configurations.
-
-### Two pain points occur when adding shadow column:
-
-1. Before performing stress testings, users need to modify test-related SQL according to actual business needs.
-2. SQL modification will increase implementation damage and reduce the accuracy of stress testing results. After discussion in the ShardingSphere community, we decided to upgrade shadow database functions. Apache ShardingSphere 4.1.1 GA shadow database API had relatively simple functionaloity. Whether to open shadow database is determined by corresponding values of the logicColumn.
-
-
-
-The upgraded shadow database API of 5.0.0 GA is more powerful. Users can determine whether the shadow database function is enabled through the “enable” attribute. Configurable shadow table can determine what needs to be stress tested by means of a table, and supports multiple shadow algorithms. For example, column value matching algorithm, regular expression matching and SQL comment matching algorithm.
-
-
-
-## Shadow Database in Practice
-
-Online full-link stress testing diagram:
-
-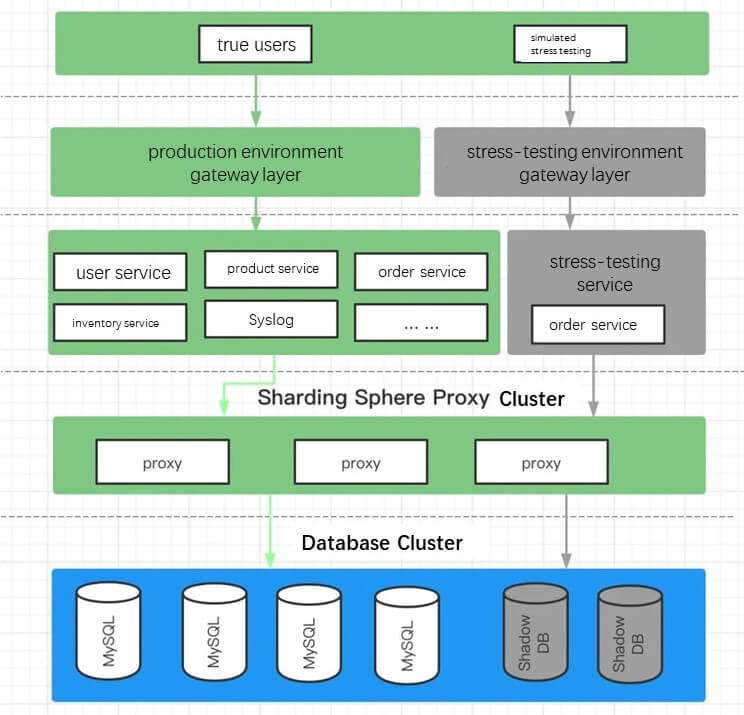
-
-### Prepare stress testing environment:
-Suppose an e-commerce website needs to perform online stress testing for an order (demonstrating how to use stand-alone deployment). Suppose stress testing table `t_order` is an order table, and the ID of the test user is 0.
-
-The data generated by test user order is executed on ds_shadow shadow database, and the production data is executed on ds production database.
-
-**Prepare testing environment:**
-
-1. Download ShardingSphere-Proxy 5.0.0 GA from the [Download Page](https://shardingsphere.apache.org/document/5.0.0/en/downloads/), and for installation configuration details, please refer to [ShardingSphere-Proxy-Quick-Start](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/).
-2. Configure ShardingSphere-Proxy in the hypothetical stress testing scenario mentioned above:
-
-**server.yaml**
-
-
-
-**config-shadow.yaml**
-
-
-
-3. Order service
-
-Order-related businesses are not discussed here. Considering the simplest request taking and order table inserting as an example, the order table structure is as follows:
-
-- Order Table Structure
-
-
-
-### Stress Testing Process Simulation
-- Use `postman` to simulate the order created by test user, which is as follows:
-
-
-
-- SQL executor being routed to and executed in shadow database can be seen in ShardingSphere-Proxy execution log:
-
-
-
-### Verify Stress Testing Results :
-
-- Shadow database `ds_shadow` executes query sentence `SELECT * FROM t_order;`
-
-Query result:
-
-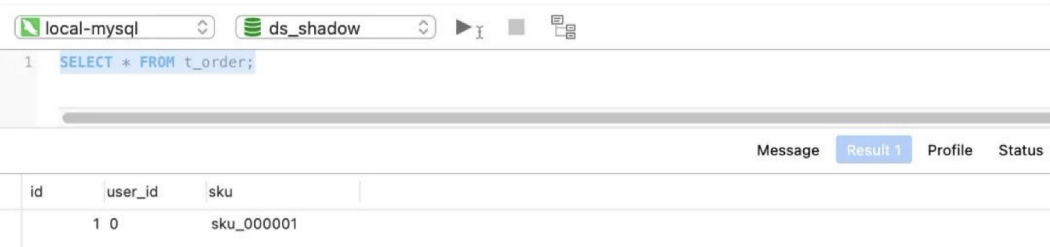
-
-- Production database ds executes query sentence `SELECT * FROM t_order;`
-
-Query result:
-
-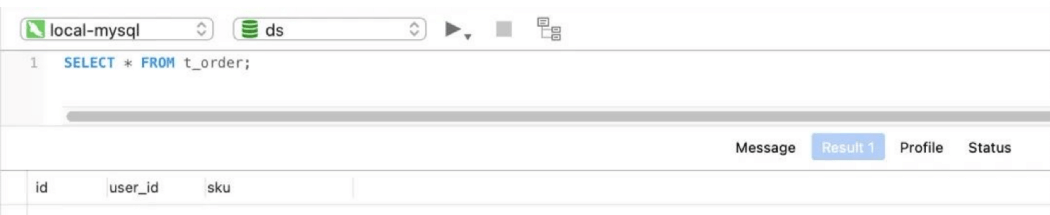
-
-The data generated from test user order creation will be routed to shadow database. For more complicated configurations, please refer to Shadow Database Stress Testing in the [ShardingSphere official document](https://shardingsphere.apache.org/document/5.0.0/cn/features/shadow/).
-
-### Complete Solution for Full-Link Online Stress Testing — CyborgFlow
-
-As mentioned in the introduction, full-link online stress testing is a complicated task that requires collaboration between microservices and middlewares to meet the needs of different traffic and stress testing tag transmissions.
-
-Additonally, the testing service should be stateless and immediately available. [CyborgFlow](https://github.com/SphereEx/CyborgFlow), which is jointly maintained by Apache ShardingSphere, Apache APISIX and Apache SkyWalking provides out-of-the-box (OoTB) solution to run load test in your online system.
-
-[Apache APISIX](https://apisix.apache.org/) is responsible for making tags on testing data at the gateway layer, while [Apache SkyWalking](https://skywalking.apache.org/) is responsible for transmission through the whole scheduling link, and finally, Apache ShardingSphere-Proxy will isolate data and route testing data to the shadow database.
-
-The 0.1.0 version of CyborgFlow has been [released and is available for download](https://github.com/SphereEx/CyborgFlow/releases).
-
-## Apache ShardingSphere Open Source Project Links:
-[ShardingSphere Github](https://github.com/apache/shardingsphere)
-
-[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
-
-[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
-
-## Author
-
-HouYang
-
-> SphereEx Middleware Developer, Apache ShardingSphere Contributor.
->
-> Currently he focuses on the design and development of ShadowDB and full-link stress testing.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
++++
+title = "Full Link Online Stress Testing for Production Database: Apache ShardingSphere Shadow Database Feature Upgrade"
+weight = 34
+chapter = true
++++
+
+# Full Link Online Stress Testing for Production Database: Apache ShardingSphere Shadow Database Feature Upgrade
+
+## What is full link stress testing?
+
+As the Internet industry is growing rapidly, businesses that operate with large amounts of data are seeing a rapid expansion.
+
+Predictably, ever changing customer demand is having a significant impact on the stability of their whole systems. For example, online food delivery platforms receive most of their customer orders at noon and in the evening. Online shopping sprees and time-limited sales promotions are also good examples.
+
+All businesses are served by a series of business systems which are distributedly deployed in different machines. “Data Plannig” cannot only ensure systems’ stability but also save costs, which are some of the major problems for technology teams.
+
+To precisely get the right service from a specific machine, stress testing should be conducted in the production environment. This can ensure the authenticity of the environment and the data, significantly improving the precision of “data planning”.
+
+## Shadow Database and Full-Link Stress Testing
+
+Performing a stress test on an online business system is evidently risky. For example, data corruption or performance problems may arise.
+
+Just imagine how it would compromise customer experience, if customers found their order has been lost or an unpaid order popped up?
+
+Full-link online stress testing implies a significant amount of complicated work which requires cooperation between microservices and middlewares. [Apache ShardingSphere](https://shardingsphere.apache.org/) focuses on database-level solutions in full-link stress testing.
+
+With ShardingSphere’s powerful SQL parsing capability, Apache ShardingSphere released the shadow database stress testing feature to determine shadow databases by executing SQL, and to meet the online stress testing needs in complicated business scenarios with the flexible configuration of shadow algorithms. By routing stress testing traffic to shadow databases, and normal online traffic to production database, stress testing data will be isolated and the data corruption problem is solved.
+
+## Shadow Database Function Upgrading
+
+Shadow database function was initially realized in version 4.1.0 by adding a logic shadow column. By parsing, executing, routing and rewriting SQL, Apache ShardingSphere deleted the shadow column and column value. Users do not need to setup or do anything during this process. They only need to modify SQL accordingly, add shadow fields and corresponding configurations.
+
+### Two pain points occur when adding shadow column:
+
+1. Before performing stress testings, users need to modify test-related SQL according to actual business needs.
+2. SQL modification will increase implementation damage and reduce the accuracy of stress testing results. After discussion in the ShardingSphere community, we decided to upgrade shadow database functions. Apache ShardingSphere 4.1.1 GA shadow database API had relatively simple functionaloity. Whether to open shadow database is determined by corresponding values of the logicColumn.
+
+
+
+The upgraded shadow database API of 5.0.0 GA is more powerful. Users can determine whether the shadow database function is enabled through the “enable” attribute. Configurable shadow table can determine what needs to be stress tested by means of a table, and supports multiple shadow algorithms. For example, column value matching algorithm, regular expression matching and SQL comment matching algorithm.
+
+
+
+## Shadow Database in Practice
+
+Online full-link stress testing diagram:
+
+
+
+### Prepare stress testing environment:
+
+Suppose an e-commerce website needs to perform online stress testing for an order (demonstrating how to use stand-alone deployment). Suppose stress testing table `t_order` is an order table, and the ID of the test user is 0.
+
+The data generated by test user order is executed on ds_shadow shadow database, and the production data is executed on ds production database.
+
+**Prepare testing environment:**
+
+1. Download ShardingSphere-Proxy 5.0.0 GA from the [Download Page](https://shardingsphere.apache.org/document/5.0.0/en/downloads/), and for installation configuration details, please refer to [ShardingSphere-Proxy-Quick-Start](https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/).
+2. Configure ShardingSphere-Proxy in the hypothetical stress testing scenario mentioned above:
+
+**server.yaml**
+
+
+
+**config-shadow.yaml**
+
+
+
+3. Order service
+
+Order-related businesses are not discussed here. Considering the simplest request taking and order table inserting as an example, the order table structure is as follows:
+
+- Order Table Structure
+
+
+
+### Stress Testing Process Simulation
+
+- Use `postman` to simulate the order created by test user, which is as follows:
+
+
+
+- SQL executor being routed to and executed in shadow database can be seen in ShardingSphere-Proxy execution log:
+
+
+
+### Verify Stress Testing Results :
+
+- Shadow database `ds_shadow` executes query sentence `SELECT * FROM t_order;`
+
+Query result:
+
+
+
+- Production database ds executes query sentence `SELECT * FROM t_order;`
+
+Query result:
+
+
+
+The data generated from test user order creation will be routed to shadow database. For more complicated configurations, please refer to Shadow Database Stress Testing in the [ShardingSphere official document](https://shardingsphere.apache.org/document/5.0.0/cn/features/shadow/).
+
+### Complete Solution for Full-Link Online Stress Testing — CyborgFlow
+
+As mentioned in the introduction, full-link online stress testing is a complicated task that requires collaboration between microservices and middlewares to meet the needs of different traffic and stress testing tag transmissions.
+
+Additonally, the testing service should be stateless and immediately available. [CyborgFlow](https://github.com/SphereEx/CyborgFlow), which is jointly maintained by Apache ShardingSphere, Apache APISIX and Apache SkyWalking provides out-of-the-box (OoTB) solution to run load test in your online system.
+
+[Apache APISIX](https://apisix.apache.org/) is responsible for making tags on testing data at the gateway layer, while [Apache SkyWalking](https://skywalking.apache.org/) is responsible for transmission through the whole scheduling link, and finally, Apache ShardingSphere-Proxy will isolate data and route testing data to the shadow database.
+
+The 0.1.0 version of CyborgFlow has been [released and is available for download](https://github.com/SphereEx/CyborgFlow/releases).
+
+## Apache ShardingSphere Open Source Project Links:
+
+[ShardingSphere Github](https://github.com/apache/shardingsphere)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
+
+## Author
+
+HouYang
+
+> SphereEx Middleware Developer, Apache ShardingSphere Contributor.
+>
+> Currently he focuses on the design and development of ShadowDB and full-link stress testing.
+
+
diff --git "a/docs/blog/content/material/Jan_28_YOUR_DETAILED_GUIDE_TO_APACHE_SHARDINGSPHERE\342\200\231S_OPERATING_MODES.en.md" "b/docs/blog/content/material/Jan_28_YOUR_DETAILED_GUIDE_TO_APACHE_SHARDINGSPHERE\342\200\231S_OPERATING_MODES.en.md"
index b35b26bcdec..9d8ed2189e3 100644
--- "a/docs/blog/content/material/Jan_28_YOUR_DETAILED_GUIDE_TO_APACHE_SHARDINGSPHERE\342\200\231S_OPERATING_MODES.en.md"
+++ "b/docs/blog/content/material/Jan_28_YOUR_DETAILED_GUIDE_TO_APACHE_SHARDINGSPHERE\342\200\231S_OPERATING_MODES.en.md"
@@ -1,119 +1,119 @@
-+++
-title = "Your Detailed Guide to Apache ShardingSphere’s Operating Modes"
-weight = 32
-chapter = true
-+++
-
-# Your Detailed Guide to Apache ShardingSphere’s Operating Modes
-
-In [Apache ShardingSphere](https://shardingsphere.apache.org/) 5.0.0 GA version, we added the new concept Operating Mode and provided three configuration methods: Memory, Standalone, and Cluster. Why does ShardingSphere provide these operating modes? What are the differences between them in actual development scenarios?
-
-This article is a guide for you to better understand ShardingSphere’s new operating modes.
-
-## Background: Distributed Governance
-
-Distributed governance is the foundation of cluster deployment in ShardingSphere. In previous versions, users needed to configure the governance tag in the configuration file to enable distributed governance:
-
-
-
-The most important features of distributed governance include persistent user configuration and [metadata](https://dzone.com/articles/shardingshpheres-metadata-loading-process).
-
-
-They are also the basic capabilities supporting [Distribured SQL](https://opensource.com/article/21/9/distsql) (DistSQL). In the previous ShardingSphere 5.0.0 stories, the core developers of DistSQL have shared the concept of [DistSQL](https://medium.com/nerd-for-tech/intro-to-distsql-an-open-source-more-powerful-sql-bada4099211), its syntax, and its usage in detail, and they have showcased how you can [develop your own DistSQL](https://medium.com/codex/how-to-develop-your-distributed-sq [...]
-
-To recap, DistSQL gives ShardingSphere’s users a database-like experience: users can use DistSQL to build and manage the entire ShardingSphere distributed database ecosystem.
-
-Like other standard SQLs, DistSQL, known as the operating language of the distributed database ecosystem, needs to ensure that any configuration and operations metadata can be persisted to keep data consistency when the system is restored.
-
-In previous versions, only when you enabled distributed governance could the feature be implemented. That’s the reason why DistSQL was only available in the distributed governance scenario in its early development stage.
-
-
-
-## Why We Created Operating Modes
-
-Based on the cluster deployment capability given by the current distributed governance function, ShardingSphere now redefines its distribution capability as **Cluster Mode**.
-
-The cluster mode supports ShardingSphere as a stateless compute node for multi-instance deployment and with a register center, it can synchronize metadata of all instances in the cluster in real-time.
-
-The mode naturally supports DistSQL: under the mode, you can use DistSQL to perform operations on computing/storage nodes such as node online/offline or disabled.
-
-In the past, DistSQL was restricted to distributed scenarios. To fix the issue, ShardingSphere first needs to figure out how metadata can be stored in a non-distributed environment. The simplest solution is to write metadata to local files and therefore when a service restarts, metadata can be loaded from local files according to different configurations.
-
-Unlike the cluster mode used in the distributed scenario, local files cannot share configurations among multiple ShardingSphere instances in real-time. In **Standalone Mode**, all configuration updates only work in respective instances.
-
-ShardingSphere 5.0.0 not only provides users with better features but also builds stable and user-friendly APIs to optimize user experiences.
-
-In addition to Cluster Mode and Standalone Mode, another useful mode is called **Memory Mode**. Why did we design it? Because some users need to quickly start the integration of ShardingSphere but don’t need persistent configuration. For example, some may use ShardingSphere to quickly verify some functions, or just want to test integration. Given such a scenario requirement, we created Memory Mode.
-
-So far ShardingSphere has three modes, i.e. Memory, Standalone, and Cluster. The operating modes are not difficult to understand in terms of our API design, and they are perfectly suitable in the actual use case scenarios of ShardingSphere. Additionally, the three operating modes can **support DistSQL** to quickly build and manage distributed database services.
-
-The `governance` configuration method is removed from the 5.0.0 version, and instead, we start to use the different operating modes.
-
-
-
-Next, I’d like to explain the basic concepts of the three operating modes in detail, and show you how to choose the right operating mode when you use ShardingSphere for development.
-
-## Concepts and Application Scenarios
-
-**Memory Mode**
-
-Memory is the default operating mode, so you do not need to configure mode. With this mode, users do not need to configure any persistence components or strategies because any metadata change caused by local initialization configuration or SQL/DistSQL operation, only works in the current thread, and the configurations are restored after the service restarts.
-
-The Memory mode is perfect for integration testing: it’s convenient because developers don’t have to clean running traces after they integrate ShardingSphere and have integration testing.
-
-**Standalone Mode**
-
-ShardingSphere’s Standalone Mode provides local files with a persistence method by default. It can persist metadata information (e.g.data sources and rules) to local files so even when the service restarts, configurations can still be read from the local files to ensure metadata consistency.
-
-The Standalone mode makes it convenient for development engineers to quickly build a local development environment for ShardingSphere, test integration and verify features.
-
-The mode’s configuration is shown as follows:
-
-
-
-The Standalone mode can persist local files by default. Configurations are persisted in the user directory `.shardingsphere` by default, but you can also customize your storage path by configuring `path`.
-
-**Cluster Mode**
-
-We recommend you apply Cluster Mode in a real deployment and production environment. Moreover, if you adopt hybrid deployment architecture with both JDBC and Proxy, you must use the Cluster mode.
-
-The mode can provide distributed governance capability. By integrating an independently-deployed third-party register center, the mode can realize metadata persistence, share data between multiple instances, and implement state coordination in a distributed scenario. Cluster mode is also the reason why ShardingSphere’s horizontal scaling can greatly enhance computing capabilities and lay the foundation of core features like high availability.
-
-We take Zookeeper as the example, to demonstrate mode configuration:
-
-
-
-We also compare the differences between the three modes (shown in the table below). Our suggestion is that you consider your needs first and then choose the right mode.
-
-
-
-## Summary
-ShardingSphere’s three operating modes can meet virtually all user needs in various environments from testing, to development, to deployment.
-
-Combined with ShardingSphere’s remarkable pluggable architecture, developers can also flexibly customize the persistence methods of each mode and create their own operating modes to make operating modes more suitable for their development and business needs. If you are interested in distributed governance, feel free to reach out to the ShardingSphere community.
-
-## Apache ShardingSphere Open Source Project Links:
-[ShardingSphere Github](https://github.com/apache/shardingsphere)
-
-[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
-
-[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
-
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
-
-**Author**
-
-Meng Haoran
-
-> SphereEx Senior Development Engineer & Apache ShardingSphere PMC.
->
-> Previously responsible for the database products R&D at JingDong Technology, he is passionate about Open-Source and database ecosystems. Currently, he focuses on the development of the ShardingSphere database ecosystem and open source community building.
-
-
-
-
-
-
-
-
-
++++
+title = "Your Detailed Guide to Apache ShardingSphere’s Operating Modes"
+weight = 32
+chapter = true
++++
+
+# Your Detailed Guide to Apache ShardingSphere’s Operating Modes
+
+In [Apache ShardingSphere](https://shardingsphere.apache.org/) 5.0.0 GA version, we added the new concept Operating Mode and provided three configuration methods: Memory, Standalone, and Cluster. Why does ShardingSphere provide these operating modes? What are the differences between them in actual development scenarios?
+
+This article is a guide for you to better understand ShardingSphere’s new operating modes.
+
+## Background: Distributed Governance
+
+Distributed governance is the foundation of cluster deployment in ShardingSphere. In previous versions, users needed to configure the governance tag in the configuration file to enable distributed governance:
+
+
+
+The most important features of distributed governance include persistent user configuration and [metadata](https://dzone.com/articles/shardingshpheres-metadata-loading-process).
+
+
+They are also the basic capabilities supporting [Distribured SQL](https://opensource.com/article/21/9/distsql) (DistSQL). In the previous ShardingSphere 5.0.0 stories, the core developers of DistSQL have shared the concept of [DistSQL](https://medium.com/nerd-for-tech/intro-to-distsql-an-open-source-more-powerful-sql-bada4099211), its syntax, and its usage in detail, and they have showcased how you can [develop your own DistSQL](https://medium.com/codex/how-to-develop-your-distributed-sq [...]
+
+To recap, DistSQL gives ShardingSphere’s users a database-like experience: users can use DistSQL to build and manage the entire ShardingSphere distributed database ecosystem.
+
+Like other standard SQLs, DistSQL, known as the operating language of the distributed database ecosystem, needs to ensure that any configuration and operations metadata can be persisted to keep data consistency when the system is restored.
+
+In previous versions, only when you enabled distributed governance could the feature be implemented. That’s the reason why DistSQL was only available in the distributed governance scenario in its early development stage.
+
+
+
+## Why We Created Operating Modes
+
+Based on the cluster deployment capability given by the current distributed governance function, ShardingSphere now redefines its distribution capability as **Cluster Mode**.
+
+The cluster mode supports ShardingSphere as a stateless compute node for multi-instance deployment and with a register center, it can synchronize metadata of all instances in the cluster in real-time.
+
+The mode naturally supports DistSQL: under the mode, you can use DistSQL to perform operations on computing/storage nodes such as node online/offline or disabled.
+
+In the past, DistSQL was restricted to distributed scenarios. To fix the issue, ShardingSphere first needs to figure out how metadata can be stored in a non-distributed environment. The simplest solution is to write metadata to local files and therefore when a service restarts, metadata can be loaded from local files according to different configurations.
+
+Unlike the cluster mode used in the distributed scenario, local files cannot share configurations among multiple ShardingSphere instances in real-time. In **Standalone Mode**, all configuration updates only work in respective instances.
+
+ShardingSphere 5.0.0 not only provides users with better features but also builds stable and user-friendly APIs to optimize user experiences.
+
+In addition to Cluster Mode and Standalone Mode, another useful mode is called **Memory Mode**. Why did we design it? Because some users need to quickly start the integration of ShardingSphere but don’t need persistent configuration. For example, some may use ShardingSphere to quickly verify some functions, or just want to test integration. Given such a scenario requirement, we created Memory Mode.
+
+So far ShardingSphere has three modes, i.e. Memory, Standalone, and Cluster. The operating modes are not difficult to understand in terms of our API design, and they are perfectly suitable in the actual use case scenarios of ShardingSphere. Additionally, the three operating modes can **support DistSQL** to quickly build and manage distributed database services.
+
+The `governance` configuration method is removed from the 5.0.0 version, and instead, we start to use the different operating modes.
+
+
+
+Next, I’d like to explain the basic concepts of the three operating modes in detail, and show you how to choose the right operating mode when you use ShardingSphere for development.
+
+## Concepts and Application Scenarios
+
+**Memory Mode**
+
+Memory is the default operating mode, so you do not need to configure mode. With this mode, users do not need to configure any persistence components or strategies because any metadata change caused by local initialization configuration or SQL/DistSQL operation, only works in the current thread, and the configurations are restored after the service restarts.
+
+The Memory mode is perfect for integration testing: it’s convenient because developers don’t have to clean running traces after they integrate ShardingSphere and have integration testing.
+
+**Standalone Mode**
+
+ShardingSphere’s Standalone Mode provides local files with a persistence method by default. It can persist metadata information (e.g.data sources and rules) to local files so even when the service restarts, configurations can still be read from the local files to ensure metadata consistency.
+
+The Standalone mode makes it convenient for development engineers to quickly build a local development environment for ShardingSphere, test integration and verify features.
+
+The mode’s configuration is shown as follows:
+
+
+
+The Standalone mode can persist local files by default. Configurations are persisted in the user directory `.shardingsphere` by default, but you can also customize your storage path by configuring `path`.
+
+**Cluster Mode**
+
+We recommend you apply Cluster Mode in a real deployment and production environment. Moreover, if you adopt hybrid deployment architecture with both JDBC and Proxy, you must use the Cluster mode.
+
+The mode can provide distributed governance capability. By integrating an independently-deployed third-party register center, the mode can realize metadata persistence, share data between multiple instances, and implement state coordination in a distributed scenario. Cluster mode is also the reason why ShardingSphere’s horizontal scaling can greatly enhance computing capabilities and lay the foundation of core features like high availability.
+
+We take Zookeeper as the example, to demonstrate mode configuration:
+
+
+
+We also compare the differences between the three modes (shown in the table below). Our suggestion is that you consider your needs first and then choose the right mode.
+
+
+
+## Summary
+ShardingSphere’s three operating modes can meet virtually all user needs in various environments from testing, to development, to deployment.
+
+Combined with ShardingSphere’s remarkable pluggable architecture, developers can also flexibly customize the persistence methods of each mode and create their own operating modes to make operating modes more suitable for their development and business needs. If you are interested in distributed governance, feel free to reach out to the ShardingSphere community.
+
+## Apache ShardingSphere Open Source Project Links:
+[ShardingSphere Github](https://github.com/apache/shardingsphere)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere Slack Channel](https://apacheshardingsphere.slack.com/join/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
+
+**Author**
+
+Meng Haoran
+
+> SphereEx Senior Development Engineer & Apache ShardingSphere PMC.
+>
+> Previously responsible for the database products R&D at JingDong Technology, he is passionate about Open-Source and database ecosystems. Currently, he focuses on the development of the ShardingSphere database ecosystem and open source community building.
+
+
+
+
+
+
+
+
+
diff --git a/docs/blog/content/material/Mar_23_DistSQL_Cluster_Governance_Capabilities.en.md b/docs/blog/content/material/Mar_23_DistSQL_Cluster_Governance_Capabilities.en.md
index 467029b4200..264eb8285d1 100644
--- a/docs/blog/content/material/Mar_23_DistSQL_Cluster_Governance_Capabilities.en.md
+++ b/docs/blog/content/material/Mar_23_DistSQL_Cluster_Governance_Capabilities.en.md
@@ -426,7 +426,7 @@ This, then, is the beauty of cluster governance.
[ShardingSphere Slack Channel](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9%7EI4rYcR18bq0SYTg)
-[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/involved/)
## Author
diff --git a/docs/blog/content/material/Nov_23_1_Integrate_SCTL_into_RAL.en.md b/docs/blog/content/material/Nov_23_1_Integrate_SCTL_into_RAL.en.md
index f417d0139e7..a0df0acd7dd 100644
--- a/docs/blog/content/material/Nov_23_1_Integrate_SCTL_into_RAL.en.md
+++ b/docs/blog/content/material/Nov_23_1_Integrate_SCTL_into_RAL.en.md
@@ -389,7 +389,7 @@ That's all folks. If you have any questions or suggestions, feel free to comment
[https://github.com/apache/shardingsphere/issues]()
***Contributor Guide:***
-[https://shardingsphere.apache.org/community/cn/contribute/]()
+[https://shardingsphere.apache.org/community/cn/involved/]()
### References
@@ -410,27 +410,3 @@ Lan Chengxiang

>SphereEx Middleware Development Engineer & Apache ShardingSphere Contributor. He focuses on DisSQL design and development.
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
diff --git a/docs/blog/content/material/Oct_12_4_Updates_and_FAQ_Your_1_Minute_Quick_Start_Guide_to_ShardingSphere.cn.md b/docs/blog/content/material/Oct_12_4_Updates_and_FAQ_Your_1_Minute_Quick_Start_Guide_to_ShardingSphere.cn.md
index fb68ca03eab..68dea33bb98 100644
--- a/docs/blog/content/material/Oct_12_4_Updates_and_FAQ_Your_1_Minute_Quick_Start_Guide_to_ShardingSphere.cn.md
+++ b/docs/blog/content/material/Oct_12_4_Updates_and_FAQ_Your_1_Minute_Quick_Start_Guide_to_ShardingSphere.cn.md
@@ -332,4 +332,4 @@ https://shardingsphere.apache.org/document/current/cn/user-manual/common-config/
https://github.com/apache/shardingsphere/issues
**贡献指南:**
-https://shardingsphere.apache.org/community/cn/contribute/
+https://shardingsphere.apache.org/community/cn/involved/
diff --git a/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler-Like_Sharding_Configuration_Tool.cn.md b/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler-Like_Sharding_Configuration_Tool.cn.md
index 15f48851d05..1a44e09d62f 100644
--- a/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler-Like_Sharding_Configuration_Tool.cn.md
+++ b/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler-Like_Sharding_Configuration_Tool.cn.md
@@ -196,4 +196,4 @@ https://github.com/apache/shardingsphere/issues
**贡献指南:**
-https://shardingsphere.apache.org/community/cn/contribute/
+https://shardingsphere.apache.org/community/cn/involved/
diff --git a/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler_Like_Sharding_Configuration_Tool.en.md b/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler_Like_Sharding_Configuration_Tool.en.md
index 3d75bf95edd..cc22b5d2bda 100644
--- a/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler_Like_Sharding_Configuration_Tool.en.md
+++ b/docs/blog/content/material/Oct_12_6_AutoTable_Your_Butler_Like_Sharding_Configuration_Tool.en.md
@@ -190,7 +190,7 @@ ShardingSphere Twitter: [https://twitter.com/ShardingSphere]()
ShardingSphere Slack Channel: [apacheshardingsphere.slack.com]()
-Contributor Guide:[https://shardingsphere.apache.org/community/en/contribute/]()
+Contributor Guide:[https://shardingsphere.apache.org/community/en/involved/]()
## Author
diff --git a/docs/blog/content/material/committer.cn.md b/docs/blog/content/material/committer.cn.md
index a5df4826762..5c978340233 100644
--- a/docs/blog/content/material/committer.cn.md
+++ b/docs/blog/content/material/committer.cn.md
@@ -38,8 +38,6 @@ Apache软件基金会如今已成为现代开源软件生态系统的基石。
活跃地参与到Apache项目中,比如Apache ShardingSphere(Incubating)即可。
-
-
不如从领个任务练练手开始?目前公布出的任务如下,欢迎领取:
- 实现使用Inline表达式对Sharding-SpringBoot进行规则配置
@@ -53,9 +51,7 @@ Apache软件基金会如今已成为现代开源软件生态系统的基石。
我们以后也会定期在GitHub上以issue的方式发布一些开发功能任务, 欢迎通过订阅我们的邮件列表关注,具体方式可参照官网:
-http://shardingsphere.io/community/cn/contribute/subscribe/
-
-
+http://shardingsphere.io/community/cn/involved/subscribe/
通过订阅Apache ShardingSphere的邮件列表,还可以了解到Apache ShardingSphere的最新项目进展,功能开发计划,Bug列表等;还能与ShardingSphere开发人员直接对话,讨论您遇到的问题,您的想法和建议等,我们一定会积极回复。
diff --git a/docs/blog/content/material/committer.en.md b/docs/blog/content/material/committer.en.md
index 874039fd904..fd699215307 100644
--- a/docs/blog/content/material/committer.en.md
+++ b/docs/blog/content/material/committer.en.md
@@ -53,9 +53,7 @@ How about starting with a task and training hands? The tasks currently announced
We will also regularly publish some development function tasks in the form of issue on GitHub in the future. Welcome to follow us by subscribing to our mailing list. For details, please refer to the official website:
-http://shardingsphere.io/community/cn/contribute/subscribe/
-
-
+http://shardingsphere.io/community/cn/involved/subscribe/
By subscribing to the Apache ShardingSphere mailing list, you can also learn about the latest project progress, function development plans, bug lists, etc. of Apache ShardingSphere; you can also talk directly with ShardingSphere developers to discuss your problems, your ideas and suggestions, etc. We will definitely reply positively.
@@ -68,9 +66,8 @@ Official website (http://shardingsphere.apache.org/)
GitHub (https://github.com/apache/incubator-shardingsphere)
### Conclusion
-Since Apache ShardingSphere (Incubating) was open sourced in 2016, it has been constantly improving and developing, and is recognized by more and more enterprises and individuals: 6000+ stars and 70+ company success stories have been harvested on Github. In addition, more and more enterprises and individuals have joined the open source project of Apache ShardingSphere (Incubating), which has contributed tremendously to its growth and development.
-
+Since Apache ShardingSphere (Incubating) was open sourced in 2016, it has been constantly improving and developing, and is recognized by more and more enterprises and individuals: 6000+ stars and 70+ company success stories have been harvested on Github. In addition, more and more enterprises and individuals have joined the open source project of Apache ShardingSphere (Incubating), which has contributed tremendously to its growth and development.
We have never stopped, listen to the needs and suggestions of community partners, and continue to develop new and powerful functions to make them robust and reliable!
diff --git a/docs/blog/content/material/ss_5.0.0beta.cn.md b/docs/blog/content/material/ss_5.0.0beta.cn.md
index 98ce63820a5..7e0f337329d 100644
--- a/docs/blog/content/material/ss_5.0.0beta.cn.md
+++ b/docs/blog/content/material/ss_5.0.0beta.cn.md
@@ -119,4 +119,4 @@ ShardingSphere 在功能不断完善、新功能不断开发的进程中,一
<https://github.com/apache/shardingsphere>
-**在使用 ShardingSphere 的过程中,如果您发现任何问题,有新的想法、建议,欢迎点击 [链接](https://shardingsphere.apache.org/community/cn/contribute/subscribe/) 通过 Apache 邮件列表参与到 ShardingSphere 的社区建设中。**
\ No newline at end of file
+**在使用 ShardingSphere 的过程中,如果您发现任何问题,有新的想法、建议,欢迎点击 [链接](https://shardingsphere.apache.org/community/cn/involved/subscribe/) 通过 Apache 邮件列表参与到 ShardingSphere 的社区建设中。**
\ No newline at end of file
diff --git a/docs/blog/content/material/ss_5.0.0beta.en.md b/docs/blog/content/material/ss_5.0.0beta.en.md
index 5c835c8c98f..6b74ccbb828 100644
--- a/docs/blog/content/material/ss_5.0.0beta.en.md
+++ b/docs/blog/content/material/ss_5.0.0beta.en.md
@@ -1,196 +1,194 @@
-+++
-title = "Following 6 months of development Apache ShardingSphere 5.0.0-beta has been officially released!"
-weight = 14
-chapter = true
-+++
-
-As an Apache top-level project, ShardingSphere goes through community verification, voting and many other steps before it can be released. Such steps ensure the release is compliant with the Apache Release License specifications, and meeting the users’ expectations set for the 5.0.0-beta milestone. The current version’s architecture has been completed and the version is officially available.
-
-## Release Features:
-
-### 1. Highlight Features
-
-#### DistSQL – A New SQL Type for a Distributed Database Ecosystem
-
-SQL is a database query programming language for accessing, querying, updating, and managing relational database systems. Most of the existing general database systems tend to rewrite and extend SQL to better fit their own database system with higher flexibility and functionality.
-
-DistSQL (Distributed SQL) is a special built-in language proposed by Apache ShardingSphere providing additional functional operation capability in comparison to the standard SQL. Users can use ShardingSphere just like other database systems with DistSQL, therefore no longer positioning ShardingSphere as a middleware architecture for programmers, but also making it transferable to an infrastructure product for operation and maintenance.
-
-ShardingSphere currently includes three types of DistSQL including RDL, RQL and RAL:
-
-* RDL (Resource & Rule Definition Language): create, modify and delete resources and rules.
-* RQL (Resource & Rule Query Language): query and show resources and rules.
-* RAL (Resource & Rule Administration Language): hint, distributed transaction switching, distributed query execution plan and other incremental functions.
-
-ShardingSphere proposes the concept of Database Plus, empowering traditional databases to build a highly secure & enhanced distributed database ecosystem, by leveraging open-source database system software such as MySQL and PostgreSQL, while at the same time meeting practical business needs. The distributed SQL used with this distributed database system converts ShardingSphere-Proxy from a YAML configuration driven middleware to a SQL driven distributed database system.
-
-In the 5.0.0-beta, users can easily initiate ShardingSphere-Proxy and use DistSQL to dynamically create, modify, delete sharding tables, encrypt tables, and dynamically inject instances of database resources, create read-write-splitting strategies, show all the configurations and distributed transaction types, engage in dynamic migration of distributed database tables etc.
-DistSQL allows users to query and manage all database resources and ShardingSphere’s distributed metadata in a standardized and familiar way.
-
-In the future DistSQL will further redefine the boundary between Middleware and database, allowing users to leverage ShardingSphere as if they were using a database natively.
-
-#### Full Join PostgreSQL Open-Source Ecosystem
-
-PostgreSQL is widely considered to be the most powerful enterprise-level open-source database.
-ShardingSphere clients include ShardingSphere-JDBC and ShardingSphere-Proxy, with ShardingSphere-Proxy containing both MySQL and PostgreSQL. As PostgreSQL has greatly matured and become increasingly adopted, the ShardingSphere team has directed its attention to the PostgreSQL proxy.
-
-This release has greatly improved PostgreSQL in its SQL parsing and compatibility layers, protocol access and permission control layers.
-The improved version of ShardingSphere-Proxy PostgreSQL is this release’s main feature and will be continuously improved in the future as it marks the beginning of compatibility with the open-source PostgreSQL.
-
-In the future, ShardingSphere PostgreSQL-Proxy will not only provide sharding and security distributed solutions to users, but also fine-grained authentication, data access control etc.
-
-#### ShardingSphere Pluggable Architecture
-
-Pluggable architecture pursues the independence and non-awareness of each module through a highly flexible, pluggable and extensible kernel. These functions are combined in a super positional manner.
-
-In ShardingSphere, many functional implementation classes are loaded by inserting SPIs (Service Provider Interface). SPI APIs for third party implementation or extension, can be used for architecture extension or component substitution.
-
-Currently data sharding, Readwrite-splitting, data encryption, Shadow databases, instance exploration and other functions including the protocol implementations of MySQL, PostgreSQL, SQLServer, Oracle and other SQL and protocol support can be installed into ShardingSphere as plug-ins. ShardingSphere now offers dozens of SPIs as extension points for the system, and the number is still growing.
-
-Pluggable architecture’s improvement effectively evolves ShardingSphere into a distributed database ecosystem. The pluggable and extensible concepts provide a customized combinational database solution that can be built upon with Lego-like blocks. For example, traditional relational databases can be scaled out and encrypted at the same time, while distributed database solutions can be built independently.
-
-### 2. New Features
-
-#### New Open Observability
-
-ShardingSphere provides automated probes to effectively separate observability from the main functionality. This brings significant convenience for user-customized tracing, metrics, and logging.
-OpenTracing, Jaeger, Zipkin based tracing probes and Prometheus Metrics probes, as well as a default logging implementation also have built-in implementations.
-
-### 3. Enhancements
-
-#### Enhanced Distributed Query Capability
-
-Join and sub queries for cross-database instances are some of the most cumbersome issues. Using traditional database middleware could limit business level functionality - therefore SQL’s application scope needs to be considered by R&D personnel.
-
-This release enhances distributed query functionality which supports join queries and sub-queries across different database instances. At the same time it greatly improves compatibility between supported SQL cases for MySQL/PostgreSQL/Oracle/SQLServer in distributed scenarios through SQL parsing, routing, and execution level enhancements and bug fixing.
-
-The improvements in this release allow users to achieve a smooth transition from a traditional database cluster to a distributed database cluster with low risk, high efficiency and zero transformation by introducing ShardingSphere.
-
-Currently, distributed query capability enhancement is still in the POC stage, with room for improvement in terms of performance. The community is warmly encouraged to participate in the co-development.
-
-#### Enhanced Distributed User and Privilege Control
-
-User security and permission control some of the most important functions in a database field. Although simple password setting and database-level access control at the library level were already provided in the 5.0.0-alpha, these features have now been further upgraded. This update changes the password setting from using configuration file to using standard SQL online to create and update distributed users and their access permissions.
-
-Whether you were using MySQL, PostgreSQL or OpenGauss in your business scenario, you can continue to use your native database SQL dialect. Username, hostname, password, library, table and other free combination of authority control management can be used in ShardingSphere’s distributed system. ShardingSphere-Proxy's Proxy access mode enables users to migrate their original database permissions and user systems seamlessly.
-
-In future releases, access control at the column level, view level, and even the possibility for functions to limit access for each row of data will be provided. ShardingSphere also provides access to third-party business systems or user-specific security systems, allowing ShardingSphere-Proxy to connect with third-party security control systems and provide the most standard database access management mode.
-
-The permission module is currently in the development stage, and the finalized functions will be presented in the next version.
-
-#### Simplified API Changes Capabilities
-
-ShardingSphere's pluggable architecture provides users with rich scalable capabilities with common functions already built-in, to increase ease of use.
-For example, database and table sharding strategy is preset with hash sharding, time range sharding, module sharding and other strategies.
-Data encryption is preset with AES, RC4, MD5 encryption. To further simplify operation, powerful new distSQL capability allows users to dynamically create a sharded or encrypted table online with a single SQL.
-
-To satisfy more complex scenarios, ShardingSphere also provides the strategy interfaces for related algorithms allowing users to implement more complicated functionalities for their own business scenarios. The coexistence philosophy of built-in strategies for users’ general needs, and specific scenarios’ corresponding interfaces has always been the architectural design philosophy of ShardingSphere.
-
-### 4. Other Features
-
-#### Performance Improvements: Optimized Metadata Loading Performance
-
-Startup time issues could be encountered when launching ShardingSphere’s previous versions, especially in the occurrence involving thousands of servers - since ShardingSphere helps users manage all database instances and metadata information.
-
-With this release, significant performance tuning and several architectural tweaks are introduced to specifically address the community's metadata loading issues. Differently from the original JDBC driver loading mode, the parallel SQL query mode for different database dialects takes out all metadata information at a single time, thus greatly improving startup performance.
-
-#### Usability: New Performance Testing System
-
-In the process of constantly improving and developing new functions, ShardingSphere had previously lacked a complete and comprehensive integration & performance testing system, which can ensure that every commit be compiled normally without affecting other modules and can observe upward and downward performance trends.
-
-With this release, integration tests have also been included to ensure data sharding, data encryption, Readwrite-splitting, distributed management and control, access control, SQL support and other functions. The system provides basic guarantees for monitoring and tuning performance across databases, different sharding or encryption strategies, and different versions.
-With this release, relevant performance test reports and dashboard will also be developed for the community, allowing users to observe ShardingSphere’s performance changes. The entire test system source code will be made available to the community to facilitate user test deployment.
-
-In addition to above mentioned features, for a comprehensive list of enhancements, performance optimizations, bug fixes etc. please refer to the list below:
-
-### Other New Features:
-
-1. New DistSQL for loading and presenting ShardingSphere’s configuration.
-2. Support for join queries and sub-queries across different databased instances.
-3. Data gateway is added to support heterogeneous databases.
-4. Support create and modify user permission online or dynamically.
-5. New automated probes module.
-
-### API Changes:
-
-1. API in read and write splitting module configuration changed to read-write-splitting.
-2. API for ShardingProxy user permission configuration changed to Authority.
-3. Using dataSourceClassName to optimize the dataSource configuration of ShardingJDBC.
-4. Automated ShardingTable configuration strategy, provide standard built-in shard table.
-5. Removed ShardingProxy acceptor-size configuration option.
-6. Added built-in shard algorithm SPI so users can set up the shard algorithm through class name like in the version 4.x.
-
-### Enhancements:
-
-1. Startup metadata loading performance has been significantly improved.
-2. Greatly enhanced the parsing abilities for Oracle/SQLServer/PostgreSQL database.
-3. Supporting initialization of the user permission MySQL/PostgreSQL/SQLServer/Oracle.
-4. Supporting DDL language for data encryption.
-5. When sharding and encryption are used together, SQL is supported for modifying the table named owner.
-6. Using SELECT* to rewrite SQL, overwrite columns to add escape characters to avoid column conflicts with keywords.
-7. Supporting PostgreSQL JSON/JSONB/ for pattern matching operator parsing.
-8. Supporting MySQL/PostgreSQL CREATE/ALTER/DROP TABLESPACE.
-9. Supporting PostgreSQL PREPARE, EXECUTE, DEALLOCATE.
-10. Supporting PostgreSQL EXPLAIN.
-11. Supporting PostgreSQL START/END TRANSACTION.
-12. Supporting PostgreSQL ALTER/DROP INDEX.
-13. Supporting PostgreSQL dialect CREATE TABLESPACE.
-14. Supporting MySQL CREATE LOADABLE FUNCTION.
-15. Supporting MySQL/PostgreSQL ALTER TABLE RENAME.
-16. Supporting PostgreSQL protocol Close command.
-
-### Changes:
-
-1. New registry storage structure.
-2. Removed support for NACOS and Apollo's Configuration Centre.
-3. ShardingScaling introduces ElasticJob to handle migration tasks.
-4. Refactoring the storage and online update of the kernel metadata information.
-
-### Bug fixes:
-
-1. Fixed issue where SELECT * wildcard SQL could not be used for read/write separation.
-2. The custom sharding algorithm did not match the configuration type and the class instance did not meet expectations issue is fixed.
-3. Fixed the NoSuchTableException when executing DROP TABLE IF EXISTS.
-4. Fixed UPDATE ... SET ... rewrite error.
-5. Fixed CREATE/ALTER TABLE statement using foreign key to reference TABLE overwrite error.
-6. Fixed the issue when querying subqueries in the temporal table field verification exception.
-7. Fixed Oracle/SQL92 SELECT ... WHERE ... LIKE class cast exception.
-8. Fixed MySQL SELECT EXISTS ... FROM ... parsing exception.
-9. Fixed SHOW INDEX result exception.
-10. Fixed the rewrite and merge result exception for SELECT... GROUP BY ...
-11. Fixed the encryption and decryption error for CREATE TABLE rewrite.
-12. Fixed issue with PostgreSQL Proxy reading text parameter values incorrectly.
-13. Fixed PostgreSQL Proxy support for array objects.
-14. Fixed ShardingProxy Datatype conversion issues.
-15. PostgreSQL Proxy supports the use of the Numeric type.
-16. Fixed the issue with incorrect Tag for PostgreSQL Proxy transactions related to Command Complete.
-17. Fixed the issue that might return packets that were not expected by the client.
-
-**Download Link:** <https://shardingsphere.apache.org/document/current/en/downloads/>
-
-**Update Logs:** <https://github.com/apache/shardingsphere/blob/master/RELEASE-NOTES.md>
-
-**Project Address:** <https://shardingsphere.apache.org/>
-
-**Mailing List:** <https://shardingsphere.apache.org/community/en/contribute/subscribe/>
-
-#### Community Contribution:
-
-The release of Apache ShardingSphere 5.0.0-beta could not have happened without the outstanding support and contribution of the community.
-
-Since the 5.0.0-alpha release until now, 41 contributors have contributed 1574 PR, enhanced the optimization, iteration, and the release of ShardingSphere 5.0.0.
-
-#### About the author:
-
-
-
-> **Pan Juan | Trista**
->
->SphereEx co-founder, Apache member, Apache ShardingSphere PMC, Apache brpc (Incubating) mentor, Release manager.
->
->Senior DBA at JD Technology, she was responsible for the design and development of JD Digital Science and Technology's intelligent database platform. She now focuses on distributed database & middleware ecosystem, and the open-source community.
-Recipient of the "2020 China Open-Source Pioneer" award, she is frequently invited to speak and share her insights at relevant conferences in the fields of database & database architecture.
->
->**GitHub:** <https://tristazero.github.io>
-
-
++++
+title = "Following 6 months of development Apache ShardingSphere 5.0.0-beta has been officially released!"
+weight = 14
+chapter = true
++++
+
+As an Apache top-level project, ShardingSphere goes through community verification, voting and many other steps before it can be released. Such steps ensure the release is compliant with the Apache Release License specifications, and meeting the users’ expectations set for the 5.0.0-beta milestone. The current version’s architecture has been completed and the version is officially available.
+
+## Release Features:
+
+### 1. Highlight Features
+
+#### DistSQL – A New SQL Type for a Distributed Database Ecosystem
+
+SQL is a database query programming language for accessing, querying, updating, and managing relational database systems. Most of the existing general database systems tend to rewrite and extend SQL to better fit their own database system with higher flexibility and functionality.
+
+DistSQL (Distributed SQL) is a special built-in language proposed by Apache ShardingSphere providing additional functional operation capability in comparison to the standard SQL. Users can use ShardingSphere just like other database systems with DistSQL, therefore no longer positioning ShardingSphere as a middleware architecture for programmers, but also making it transferable to an infrastructure product for operation and maintenance.
+
+ShardingSphere currently includes three types of DistSQL including RDL, RQL and RAL:
+
+* RDL (Resource & Rule Definition Language): create, modify and delete resources and rules.
+* RQL (Resource & Rule Query Language): query and show resources and rules.
+* RAL (Resource & Rule Administration Language): hint, distributed transaction switching, distributed query execution plan and other incremental functions.
+
+ShardingSphere proposes the concept of Database Plus, empowering traditional databases to build a highly secure & enhanced distributed database ecosystem, by leveraging open-source database system software such as MySQL and PostgreSQL, while at the same time meeting practical business needs. The distributed SQL used with this distributed database system converts ShardingSphere-Proxy from a YAML configuration driven middleware to a SQL driven distributed database system.
+
+In the 5.0.0-beta, users can easily initiate ShardingSphere-Proxy and use DistSQL to dynamically create, modify, delete sharding tables, encrypt tables, and dynamically inject instances of database resources, create read-write-splitting strategies, show all the configurations and distributed transaction types, engage in dynamic migration of distributed database tables etc.
+DistSQL allows users to query and manage all database resources and ShardingSphere’s distributed metadata in a standardized and familiar way.
+
+In the future DistSQL will further redefine the boundary between Middleware and database, allowing users to leverage ShardingSphere as if they were using a database natively.
+
+#### Full Join PostgreSQL Open-Source Ecosystem
+
+PostgreSQL is widely considered to be the most powerful enterprise-level open-source database.
+ShardingSphere clients include ShardingSphere-JDBC and ShardingSphere-Proxy, with ShardingSphere-Proxy containing both MySQL and PostgreSQL. As PostgreSQL has greatly matured and become increasingly adopted, the ShardingSphere team has directed its attention to the PostgreSQL proxy.
+
+This release has greatly improved PostgreSQL in its SQL parsing and compatibility layers, protocol access and permission control layers.
+The improved version of ShardingSphere-Proxy PostgreSQL is this release’s main feature and will be continuously improved in the future as it marks the beginning of compatibility with the open-source PostgreSQL.
+
+In the future, ShardingSphere PostgreSQL-Proxy will not only provide sharding and security distributed solutions to users, but also fine-grained authentication, data access control etc.
+
+#### ShardingSphere Pluggable Architecture
+
+Pluggable architecture pursues the independence and non-awareness of each module through a highly flexible, pluggable and extensible kernel. These functions are combined in a super positional manner.
+
+In ShardingSphere, many functional implementation classes are loaded by inserting SPIs (Service Provider Interface). SPI APIs for third party implementation or extension, can be used for architecture extension or component substitution.
+
+Currently data sharding, Readwrite-splitting, data encryption, Shadow databases, instance exploration and other functions including the protocol implementations of MySQL, PostgreSQL, SQLServer, Oracle and other SQL and protocol support can be installed into ShardingSphere as plug-ins. ShardingSphere now offers dozens of SPIs as extension points for the system, and the number is still growing.
+
+Pluggable architecture’s improvement effectively evolves ShardingSphere into a distributed database ecosystem. The pluggable and extensible concepts provide a customized combinational database solution that can be built upon with Lego-like blocks. For example, traditional relational databases can be scaled out and encrypted at the same time, while distributed database solutions can be built independently.
+
+### 2. New Features
+
+#### New Open Observability
+
+ShardingSphere provides automated probes to effectively separate observability from the main functionality. This brings significant convenience for user-customized tracing, metrics, and logging.
+OpenTracing, Jaeger, Zipkin based tracing probes and Prometheus Metrics probes, as well as a default logging implementation also have built-in implementations.
+
+### 3. Enhancements
+
+#### Enhanced Distributed Query Capability
+
+Join and sub queries for cross-database instances are some of the most cumbersome issues. Using traditional database middleware could limit business level functionality - therefore SQL’s application scope needs to be considered by R&D personnel.
+
+This release enhances distributed query functionality which supports join queries and sub-queries across different database instances. At the same time it greatly improves compatibility between supported SQL cases for MySQL/PostgreSQL/Oracle/SQLServer in distributed scenarios through SQL parsing, routing, and execution level enhancements and bug fixing.
+
+The improvements in this release allow users to achieve a smooth transition from a traditional database cluster to a distributed database cluster with low risk, high efficiency and zero transformation by introducing ShardingSphere.
+
+Currently, distributed query capability enhancement is still in the POC stage, with room for improvement in terms of performance. The community is warmly encouraged to participate in the co-development.
+
+#### Enhanced Distributed User and Privilege Control
+
+User security and permission control some of the most important functions in a database field. Although simple password setting and database-level access control at the library level were already provided in the 5.0.0-alpha, these features have now been further upgraded. This update changes the password setting from using configuration file to using standard SQL online to create and update distributed users and their access permissions.
+
+Whether you were using MySQL, PostgreSQL or OpenGauss in your business scenario, you can continue to use your native database SQL dialect. Username, hostname, password, library, table and other free combination of authority control management can be used in ShardingSphere’s distributed system. ShardingSphere-Proxy's Proxy access mode enables users to migrate their original database permissions and user systems seamlessly.
+
+In future releases, access control at the column level, view level, and even the possibility for functions to limit access for each row of data will be provided. ShardingSphere also provides access to third-party business systems or user-specific security systems, allowing ShardingSphere-Proxy to connect with third-party security control systems and provide the most standard database access management mode.
+
+The permission module is currently in the development stage, and the finalized functions will be presented in the next version.
+
+#### Simplified API Changes Capabilities
+
+ShardingSphere's pluggable architecture provides users with rich scalable capabilities with common functions already built-in, to increase ease of use.
+For example, database and table sharding strategy is preset with hash sharding, time range sharding, module sharding and other strategies.
+Data encryption is preset with AES, RC4, MD5 encryption. To further simplify operation, powerful new distSQL capability allows users to dynamically create a sharded or encrypted table online with a single SQL.
+
+To satisfy more complex scenarios, ShardingSphere also provides the strategy interfaces for related algorithms allowing users to implement more complicated functionalities for their own business scenarios. The coexistence philosophy of built-in strategies for users’ general needs, and specific scenarios’ corresponding interfaces has always been the architectural design philosophy of ShardingSphere.
+
+### 4. Other Features
+
+#### Performance Improvements: Optimized Metadata Loading Performance
+
+Startup time issues could be encountered when launching ShardingSphere’s previous versions, especially in the occurrence involving thousands of servers - since ShardingSphere helps users manage all database instances and metadata information.
+
+With this release, significant performance tuning and several architectural tweaks are introduced to specifically address the community's metadata loading issues. Differently from the original JDBC driver loading mode, the parallel SQL query mode for different database dialects takes out all metadata information at a single time, thus greatly improving startup performance.
+
+#### Usability: New Performance Testing System
+
+In the process of constantly improving and developing new functions, ShardingSphere had previously lacked a complete and comprehensive integration & performance testing system, which can ensure that every commit be compiled normally without affecting other modules and can observe upward and downward performance trends.
+
+With this release, integration tests have also been included to ensure data sharding, data encryption, Readwrite-splitting, distributed management and control, access control, SQL support and other functions. The system provides basic guarantees for monitoring and tuning performance across databases, different sharding or encryption strategies, and different versions.
+With this release, relevant performance test reports and dashboard will also be developed for the community, allowing users to observe ShardingSphere’s performance changes. The entire test system source code will be made available to the community to facilitate user test deployment.
+
+In addition to above mentioned features, for a comprehensive list of enhancements, performance optimizations, bug fixes etc. please refer to the list below:
+
+### Other New Features:
+
+1. New DistSQL for loading and presenting ShardingSphere’s configuration.
+2. Support for join queries and sub-queries across different databased instances.
+3. Data gateway is added to support heterogeneous databases.
+4. Support create and modify user permission online or dynamically.
+5. New automated probes module.
+
+### API Changes:
+
+1. API in read and write splitting module configuration changed to read-write-splitting.
+2. API for ShardingProxy user permission configuration changed to Authority.
+3. Using dataSourceClassName to optimize the dataSource configuration of ShardingJDBC.
+4. Automated ShardingTable configuration strategy, provide standard built-in shard table.
+5. Removed ShardingProxy acceptor-size configuration option.
+6. Added built-in shard algorithm SPI so users can set up the shard algorithm through class name like in the version 4.x.
+
+### Enhancements:
+
+1. Startup metadata loading performance has been significantly improved.
+2. Greatly enhanced the parsing abilities for Oracle/SQLServer/PostgreSQL database.
+3. Supporting initialization of the user permission MySQL/PostgreSQL/SQLServer/Oracle.
+4. Supporting DDL language for data encryption.
+5. When sharding and encryption are used together, SQL is supported for modifying the table named owner.
+6. Using SELECT* to rewrite SQL, overwrite columns to add escape characters to avoid column conflicts with keywords.
+7. Supporting PostgreSQL JSON/JSONB/ for pattern matching operator parsing.
+8. Supporting MySQL/PostgreSQL CREATE/ALTER/DROP TABLESPACE.
+9. Supporting PostgreSQL PREPARE, EXECUTE, DEALLOCATE.
+10. Supporting PostgreSQL EXPLAIN.
+11. Supporting PostgreSQL START/END TRANSACTION.
+12. Supporting PostgreSQL ALTER/DROP INDEX.
+13. Supporting PostgreSQL dialect CREATE TABLESPACE.
+14. Supporting MySQL CREATE LOADABLE FUNCTION.
+15. Supporting MySQL/PostgreSQL ALTER TABLE RENAME.
+16. Supporting PostgreSQL protocol Close command.
+
+### Changes:
+
+1. New registry storage structure.
+2. Removed support for NACOS and Apollo's Configuration Centre.
+3. ShardingScaling introduces ElasticJob to handle migration tasks.
+4. Refactoring the storage and online update of the kernel metadata information.
+
+### Bug fixes:
+
+1. Fixed issue where SELECT * wildcard SQL could not be used for read/write separation.
+2. The custom sharding algorithm did not match the configuration type and the class instance did not meet expectations issue is fixed.
+3. Fixed the NoSuchTableException when executing DROP TABLE IF EXISTS.
+4. Fixed UPDATE ... SET ... rewrite error.
+5. Fixed CREATE/ALTER TABLE statement using foreign key to reference TABLE overwrite error.
+6. Fixed the issue when querying subqueries in the temporal table field verification exception.
+7. Fixed Oracle/SQL92 SELECT ... WHERE ... LIKE class cast exception.
+8. Fixed MySQL SELECT EXISTS ... FROM ... parsing exception.
+9. Fixed SHOW INDEX result exception.
+10. Fixed the rewrite and merge result exception for SELECT... GROUP BY ...
+11. Fixed the encryption and decryption error for CREATE TABLE rewrite.
+12. Fixed issue with PostgreSQL Proxy reading text parameter values incorrectly.
+13. Fixed PostgreSQL Proxy support for array objects.
+14. Fixed ShardingProxy Datatype conversion issues.
+15. PostgreSQL Proxy supports the use of the Numeric type.
+16. Fixed the issue with incorrect Tag for PostgreSQL Proxy transactions related to Command Complete.
+17. Fixed the issue that might return packets that were not expected by the client.
+
+**Download Link:** <https://shardingsphere.apache.org/document/current/en/downloads/>
+
+**Update Logs:** <https://github.com/apache/shardingsphere/blob/master/RELEASE-NOTES.md>
+
+**Project Address:** <https://shardingsphere.apache.org/>
+
+**Mailing List:** <https://shardingsphere.apache.org/community/en/involved/subscribe/>
+
+#### Community Contribution:
+
+The release of Apache ShardingSphere 5.0.0-beta could not have happened without the outstanding support and contribution of the community.
+
+Since the 5.0.0-alpha release until now, 41 contributors have contributed 1574 PR, enhanced the optimization, iteration, and the release of ShardingSphere 5.0.0.
+
+#### About the author:
+
+
+
+> **Pan Juan | Trista**
+>
+>SphereEx co-founder, Apache member, Apache ShardingSphere PMC, Apache brpc (Incubating) mentor, Release manager.
+>
+>Senior DBA at JD Technology, she was responsible for the design and development of JD Digital Science and Technology's intelligent database platform. She now focuses on distributed database & middleware ecosystem, and the open-source community.
+Recipient of the "2020 China Open-Source Pioneer" award, she is frequently invited to speak and share her insights at relevant conferences in the fields of database & database architecture.
+>
+>**GitHub:** <https://tristazero.github.io>
diff --git a/docs/community/content/contribute/2FA.cn.md b/docs/community/content/involved/2FA.cn.md
similarity index 100%
rename from docs/community/content/contribute/2FA.cn.md
rename to docs/community/content/involved/2FA.cn.md
diff --git a/docs/community/content/contribute/2FA.en.md b/docs/community/content/involved/2FA.en.md
similarity index 100%
rename from docs/community/content/contribute/2FA.en.md
rename to docs/community/content/involved/2FA.en.md
diff --git a/docs/community/content/contribute/_index.cn.md b/docs/community/content/involved/_index.cn.md
similarity index 59%
rename from docs/community/content/contribute/_index.cn.md
rename to docs/community/content/involved/_index.cn.md
index 562d35f9703..21a00e4fe00 100644
--- a/docs/community/content/contribute/_index.cn.md
+++ b/docs/community/content/involved/_index.cn.md
@@ -7,14 +7,14 @@ chapter = true
ShardingSphere 是一个开放且活跃的社区,非常欢迎高质量的参与者与我们共建开源之路。
-您可以从[订阅官方邮件列表](/cn/contribute/subscribe/)开始参与社区。
+您可以从[订阅官方邮件列表](/cn/involved/subscribe/)开始参与社区。
-如果您是刚接触 ShardingSphere,请您先阅读[开发环境搭建指南](/cn/contribute/dev-env/)。
+如果您是刚接触 ShardingSphere,请您先阅读[开发环境搭建指南](/cn/involved/dev-env/)。
-在成为一个贡献者之前,请您阅读[贡献规范](/cn/contribute/conduct/)。
+在成为一个贡献者之前,请您阅读[贡献规范](/cn/involved/conduct/)。
-如果您想成为官方提交者,请您阅读[提交者指南](/cn/contribute/committer/)。官方提交者需要通过开启 [2FA](/cn/contribute/2fa/) 后,才能够行使 Apache 官方代码仓库权限。
+如果您想成为官方提交者,请您阅读[提交者指南](/cn/involved/committer/)。官方提交者需要通过开启 [2FA](/cn/involved/2fa/) 后,才能够行使 Apache 官方代码仓库权限。
-如果您想成为官方版本发布经理,请您阅读[发布指南](/cn/contribute/release/)。
+如果您想成为官方版本发布经理,请您阅读[发布指南](/cn/involved/release/)。
感谢您关注 ShardingSphere。
diff --git a/docs/community/content/contribute/_index.en.md b/docs/community/content/involved/_index.en.md
similarity index 57%
rename from docs/community/content/contribute/_index.en.md
rename to docs/community/content/involved/_index.en.md
index d2b87851bdf..f7511c5c629 100644
--- a/docs/community/content/contribute/_index.en.md
+++ b/docs/community/content/involved/_index.en.md
@@ -7,15 +7,15 @@ chapter = true
First off, thank you for your interest in ShardingSphere. We are a very open and active community, where dedicated contributors of all levels are welcome to join in the pursuit of the `Apache Way`.
-You may participate in the community through the [Mailing-list Subscription](/en/contribute/subscribe/), or simply by interacting with other members in the [ShardingSphere Slack channel](https://app.slack.com/client/T026JKU2DPF/C026MLH7F34)
+You may participate in the community through the [Mailing-list Subscription](/en/involved/subscribe/), or simply by interacting with other members in the [ShardingSphere Slack channel](https://app.slack.com/client/T026JKU2DPF/C026MLH7F34)
-If you are just getting started, please read the [Environment Set Up Guide](/en/contribute/dev-env/) to set up the development environment for ShardingSphere.
+If you are just getting started, please read the [Environment Set Up Guide](/en/involved/dev-env/) to set up the development environment for ShardingSphere.
-Please read the [Contributor Conduct](/en/contribute/conduct/) before becoming a contributor.
+Please read the [Contributor Conduct](/en/involved/conduct/) before becoming a contributor.
-If you want to become a committer, please read the [Committers' Guide](/en/contribute/committer/).
-Committers can be granted authority by the Apache repo after [2FA](/en/contribute/2fa/) enabled.
+If you want to become a committer, please read the [Committers' Guide](/en/involved/committer/).
+Committers can be granted authority by the Apache repo after [2FA](/en/involved/2fa/) enabled.
-If you want to be a release manager, please read the [Release Guide](/en/contribute/release/).
+If you want to be a release manager, please read the [Release Guide](/en/involved/release/).
Thank you for attend ShardingSphere.
diff --git a/docs/community/content/contribute/committer.cn.md b/docs/community/content/involved/committer.cn.md
similarity index 100%
rename from docs/community/content/contribute/committer.cn.md
rename to docs/community/content/involved/committer.cn.md
diff --git a/docs/community/content/contribute/committer.en.md b/docs/community/content/involved/committer.en.md
similarity index 100%
rename from docs/community/content/contribute/committer.en.md
rename to docs/community/content/involved/committer.en.md
diff --git a/docs/community/content/contribute/conduct/_index.cn.md b/docs/community/content/involved/conduct/_index.cn.md
similarity index 100%
rename from docs/community/content/contribute/conduct/_index.cn.md
rename to docs/community/content/involved/conduct/_index.cn.md
diff --git a/docs/community/content/contribute/conduct/_index.en.md b/docs/community/content/involved/conduct/_index.en.md
similarity index 100%
rename from docs/community/content/contribute/conduct/_index.en.md
rename to docs/community/content/involved/conduct/_index.en.md
diff --git a/docs/community/content/contribute/conduct/code.cn.md b/docs/community/content/involved/conduct/code.cn.md
similarity index 100%
rename from docs/community/content/contribute/conduct/code.cn.md
rename to docs/community/content/involved/conduct/code.cn.md
diff --git a/docs/community/content/contribute/conduct/code.en.md b/docs/community/content/involved/conduct/code.en.md
similarity index 100%
rename from docs/community/content/contribute/conduct/code.en.md
rename to docs/community/content/involved/conduct/code.en.md
diff --git a/docs/community/content/contribute/conduct/document.cn.md b/docs/community/content/involved/conduct/document.cn.md
similarity index 100%
rename from docs/community/content/contribute/conduct/document.cn.md
rename to docs/community/content/involved/conduct/document.cn.md
diff --git a/docs/community/content/contribute/conduct/document.en.md b/docs/community/content/involved/conduct/document.en.md
similarity index 100%
rename from docs/community/content/contribute/conduct/document.en.md
rename to docs/community/content/involved/conduct/document.en.md
diff --git a/docs/community/content/contribute/conduct/issue.cn.md b/docs/community/content/involved/conduct/issue.cn.md
similarity index 100%
rename from docs/community/content/contribute/conduct/issue.cn.md
rename to docs/community/content/involved/conduct/issue.cn.md
diff --git a/docs/community/content/contribute/conduct/issue.en.md b/docs/community/content/involved/conduct/issue.en.md
similarity index 100%
rename from docs/community/content/contribute/conduct/issue.en.md
rename to docs/community/content/involved/conduct/issue.en.md
diff --git a/docs/community/content/contribute/contributor.cn.md b/docs/community/content/involved/contributor.cn.md
similarity index 97%
rename from docs/community/content/contribute/contributor.cn.md
rename to docs/community/content/involved/contributor.cn.md
index 5c7a27a6040..ca3fb7926a9 100644
--- a/docs/community/content/contribute/contributor.cn.md
+++ b/docs/community/content/involved/contributor.cn.md
@@ -66,7 +66,7 @@ git checkout -b issueNo
**4. 编码**
- - 请您在开发过程中遵循 ShardingSphere 的[开发规范](/cn/contribute/conduct/code/)。并在准备提交 pull request 之前完成相应的检查。
+ - 请您在开发过程中遵循 ShardingSphere 的[开发规范](/cn/involved/conduct/code/)。并在准备提交 pull request 之前完成相应的检查。
- 将修改的代码 push 到 fork 库的分支上。
```shell
diff --git a/docs/community/content/contribute/contributor.en.md b/docs/community/content/involved/contributor.en.md
similarity index 96%
rename from docs/community/content/contribute/contributor.en.md
rename to docs/community/content/involved/contributor.en.md
index 3949d1247a5..2681075f6ab 100644
--- a/docs/community/content/contribute/contributor.en.md
+++ b/docs/community/content/involved/contributor.en.md
@@ -66,7 +66,7 @@ git checkout -b issueNo
**4. Coding**
- - Please obey the [Code of Conduct](/en/contribute/conduct/code/) during the process of development and finish the check before submitting the pull request.
+ - Please obey the [Code of Conduct](/en/involved/conduct/code/) during the process of development and finish the check before submitting the pull request.
- push code to your fork repo.
```shell
diff --git a/docs/community/content/contribute/dev-env.cn.md b/docs/community/content/involved/dev-env.cn.md
similarity index 95%
rename from docs/community/content/contribute/dev-env.cn.md
rename to docs/community/content/involved/dev-env.cn.md
index d0e91cc178f..263359ba0f1 100644
--- a/docs/community/content/contribute/dev-env.cn.md
+++ b/docs/community/content/involved/dev-env.cn.md
@@ -75,7 +75,7 @@ git config --global core.longpaths true
以下是一些常用插件:
- Lombok:必须。最新版 IntelliJ IDEA 已自带。
-- CheckStyle:可选。可以实时或根据需要扫描 Java 文件,找出不符合代码规范的地方并提示。**注意**:不是所有不符合 [代码规范](/cn/contribute/conduct/code/) 的地方都可以被检查出来。
+- CheckStyle:可选。可以实时或根据需要扫描 Java 文件,找出不符合代码规范的地方并提示。**注意**:不是所有不符合 [代码规范](/cn/involved/conduct/code/) 的地方都可以被检查出来。
- ANTLR v4:可选。做 SQL 语法扩展任务的时候可能有用。
### CheckStyle 插件配置
diff --git a/docs/community/content/contribute/dev-env.en.md b/docs/community/content/involved/dev-env.en.md
similarity index 97%
rename from docs/community/content/contribute/dev-env.en.md
rename to docs/community/content/involved/dev-env.en.md
index c0896b979ad..3021279fff4 100644
--- a/docs/community/content/contribute/dev-env.en.md
+++ b/docs/community/content/involved/dev-env.en.md
@@ -75,7 +75,7 @@ You could use any of them:
These plugins might be useful for you:
- Lombok : Required. It's already preinstalled in the latest IntelliJ IDEA.
-- CheckStyle : Optional. It provides both real-time and on-demand scanning of Java files. **Notice**: Not all [Code of Conduct](/en/contribute/conduct/code/) could be checked.
+- CheckStyle : Optional. It provides both real-time and on-demand scanning of Java files. **Notice**: Not all [Code of Conduct](/en/involved/conduct/code/) could be checked.
- ANTLR v4 : Optional. It's recommended if you contribute to SQL extension.
### CheckStyle Settings
diff --git a/docs/community/content/contribute/document-contributor.cn.md b/docs/community/content/involved/document-contributor.cn.md
similarity index 98%
rename from docs/community/content/contribute/document-contributor.cn.md
rename to docs/community/content/involved/document-contributor.cn.md
index ffc2cf71426..456b9ee5dbd 100644
--- a/docs/community/content/contribute/document-contributor.cn.md
+++ b/docs/community/content/involved/document-contributor.cn.md
@@ -82,7 +82,7 @@ shardingsphere
ShardingSphere 文档使用 Markdown 编写,并使用 Hugo 进行处理生成 html,部署于 [asf-site](https://github.com/apache/shardingsphere-doc/tree/asf-site) 分支,源代码位于 [Github](https://github.com/apache/shardingsphere/tree/master)。
- [官方教程最新版本](https://shardingsphere.apache.org/document/current/cn/overview/) 源存储在 `/document/`
-- [社区介绍及贡献](https://shardingsphere.apache.org/community/cn/contribute/) 相关文档源都储存在 `/community/content/`
+- [社区介绍及贡献](https://shardingsphere.apache.org/community/cn/involved/) 相关文档源都储存在 `/community/content/`
您可以从 [Github](https://github.com/apache/shardingsphere/issues) 网站上提交问题,编辑内容和查看其他人的更改。
diff --git a/docs/community/content/contribute/document-contributor.en.md b/docs/community/content/involved/document-contributor.en.md
similarity index 97%
rename from docs/community/content/contribute/document-contributor.en.md
rename to docs/community/content/involved/document-contributor.en.md
index e89cb1faa8f..fda46cb5d13 100644
--- a/docs/community/content/contribute/document-contributor.en.md
+++ b/docs/community/content/involved/document-contributor.en.md
@@ -81,7 +81,7 @@ shardingsphere
The ShardingSphere document is written in markdown, processed in Hugo, generated HTML, deployed in [asf-site](https://github.com/apache/shardingsphere-doc/tree/asf-site) branch, and the source code is located in [Github](https://github.com/apache/shardingsphere/tree/master).
- [Latest version Official course](https://shardingsphere.apache.org/document/current/en/overview/) source is stored in `/document/`.
-- [Community introduction and contribution](https://shardingsphere.apache.org/community/en/contribute/) related document sources are stored in `/community/content/`.
+- [Community introduction and contribution](https://shardingsphere.apache.org/community/en/involved/) related document sources are stored in `/community/content/`.
You can submit questions, edit content, and view other people's changes from [Github](https://github.com/apache/shardingsphere/issues).
diff --git a/docs/community/content/contribute/icla.cn.md b/docs/community/content/involved/icla.cn.md
similarity index 100%
rename from docs/community/content/contribute/icla.cn.md
rename to docs/community/content/involved/icla.cn.md
diff --git a/docs/community/content/contribute/icla.en.md b/docs/community/content/involved/icla.en.md
similarity index 100%
rename from docs/community/content/contribute/icla.en.md
rename to docs/community/content/involved/icla.en.md
diff --git a/docs/community/content/contribute/release/_index.cn.md b/docs/community/content/involved/release/_index.cn.md
similarity index 100%
rename from docs/community/content/contribute/release/_index.cn.md
rename to docs/community/content/involved/release/_index.cn.md
diff --git a/docs/community/content/contribute/release/_index.en.md b/docs/community/content/involved/release/_index.en.md
similarity index 100%
rename from docs/community/content/contribute/release/_index.en.md
rename to docs/community/content/involved/release/_index.en.md
diff --git a/docs/community/content/contribute/release/elasticjob-ui.cn.md b/docs/community/content/involved/release/elasticjob-ui.cn.md
similarity index 99%
rename from docs/community/content/contribute/release/elasticjob-ui.cn.md
rename to docs/community/content/involved/release/elasticjob-ui.cn.md
index fa2141b4875..3b7ec5cbb60 100644
--- a/docs/community/content/contribute/release/elasticjob-ui.cn.md
+++ b/docs/community/content/involved/release/elasticjob-ui.cn.md
@@ -6,7 +6,7 @@ chapter = true
## GPG 设置
-详情请参见[发布指南](/cn/contribute/release/shardingsphere/)。
+详情请参见[发布指南](/cn/involved/release/shardingsphere/)。
## 发布 Apache Maven 中央仓库
@@ -279,7 +279,7 @@ Keys to verify the Release Candidate:
https://dist.apache.org/repos/dist/dev/shardingsphere/KEYS
Look at here for how to verify this release candidate:
-https://shardingsphere.apache.org/community/en/contribute/release/elasticjob-ui/
+https://shardingsphere.apache.org/community/en/involved/release/elasticjob-ui/
GPG user ID:
${YOUR.GPG.USER.ID}
diff --git a/docs/community/content/contribute/release/elasticjob-ui.en.md b/docs/community/content/involved/release/elasticjob-ui.en.md
similarity index 99%
rename from docs/community/content/contribute/release/elasticjob-ui.en.md
rename to docs/community/content/involved/release/elasticjob-ui.en.md
index d6ccd847704..aa15e6db947 100644
--- a/docs/community/content/contribute/release/elasticjob-ui.en.md
+++ b/docs/community/content/involved/release/elasticjob-ui.en.md
@@ -6,7 +6,7 @@ chapter = true
## GPG Settings
-Please refer to [Release Guide](/en/contribute/release/shardingsphere/).
+Please refer to [Release Guide](/en/involved/release/shardingsphere/).
## Apache Maven Central Repository Release
@@ -285,7 +285,7 @@ Keys to verify the Release Candidate:
https://dist.apache.org/repos/dist/dev/shardingsphere/KEYS
Look at here for how to verify this release candidate:
-https://shardingsphere.apache.org/community/en/contribute/release/elasticjob-ui/
+https://shardingsphere.apache.org/community/en/involved/release/elasticjob-ui/
GPG user ID:
${YOUR.GPG.USER.ID}
diff --git a/docs/community/content/contribute/release/elasticjob.cn.md b/docs/community/content/involved/release/elasticjob.cn.md
similarity index 99%
rename from docs/community/content/contribute/release/elasticjob.cn.md
rename to docs/community/content/involved/release/elasticjob.cn.md
index c61489a43f4..aaf65add7f5 100644
--- a/docs/community/content/contribute/release/elasticjob.cn.md
+++ b/docs/community/content/involved/release/elasticjob.cn.md
@@ -8,7 +8,7 @@ chapter = true
### GPG 设置
-详情请参见[发布指南](/cn/contribute/release/shardingsphere/)。
+详情请参见[发布指南](/cn/involved/release/shardingsphere/)。
### 设置 settings.xml 文件
@@ -302,7 +302,7 @@ Keys to verify the Release Candidate:
https://dist.apache.org/repos/dist/dev/shardingsphere/KEYS
Look at here for how to verify this release candidate:
-https://shardingsphere.apache.org/community/en/contribute/release/elasticjob/
+https://shardingsphere.apache.org/community/en/involved/release/elasticjob/
GPG user ID:
${YOUR.GPG.USER.ID}
diff --git a/docs/community/content/contribute/release/elasticjob.en.md b/docs/community/content/involved/release/elasticjob.en.md
similarity index 99%
rename from docs/community/content/contribute/release/elasticjob.en.md
rename to docs/community/content/involved/release/elasticjob.en.md
index 3c0acda439a..080da3792f1 100644
--- a/docs/community/content/contribute/release/elasticjob.en.md
+++ b/docs/community/content/involved/release/elasticjob.en.md
@@ -8,7 +8,7 @@ chapter = true
### GPG Setup
-Please refer to [Release Guide](/en/contribute/release/shardingsphere/).
+Please refer to [Release Guide](/en/involved/release/shardingsphere/).
### Setting settings.xml
@@ -304,7 +304,7 @@ Keys to verify the Release Candidate:
https://dist.apache.org/repos/dist/dev/shardingsphere/KEYS
Look at here for how to verify this release candidate:
-https://shardingsphere.apache.org/community/en/contribute/release/elasticjob/
+https://shardingsphere.apache.org/community/en/involved/release/elasticjob/
GPG user ID:
${YOUR.GPG.USER.ID}
diff --git a/docs/community/content/contribute/release/shardingsphere.cn.md b/docs/community/content/involved/release/shardingsphere.cn.md
similarity index 99%
rename from docs/community/content/contribute/release/shardingsphere.cn.md
rename to docs/community/content/involved/release/shardingsphere.cn.md
index 318e34f3cc6..8dc97fa57a9 100644
--- a/docs/community/content/contribute/release/shardingsphere.cn.md
+++ b/docs/community/content/involved/release/shardingsphere.cn.md
@@ -452,7 +452,7 @@ Keys to verify the Release Candidate:
https://dist.apache.org/repos/dist/dev/shardingsphere/KEYS
Look at here for how to verify this release candidate:
-https://shardingsphere.apache.org/community/en/contribute/release/shardingsphere/
+https://shardingsphere.apache.org/community/en/involved/release/shardingsphere/
GPG user ID:
${YOUR.GPG.USER.ID}
diff --git a/docs/community/content/contribute/release/shardingsphere.en.md b/docs/community/content/involved/release/shardingsphere.en.md
similarity index 99%
rename from docs/community/content/contribute/release/shardingsphere.en.md
rename to docs/community/content/involved/release/shardingsphere.en.md
index 96d0413f01c..d361d252802 100644
--- a/docs/community/content/contribute/release/shardingsphere.en.md
+++ b/docs/community/content/involved/release/shardingsphere.en.md
@@ -458,7 +458,7 @@ Keys to verify the Release Candidate:
https://dist.apache.org/repos/dist/dev/shardingsphere/KEYS
Look at here for how to verify this release candidate:
-https://shardingsphere.apache.org/community/en/contribute/release/shardingsphere/
+https://shardingsphere.apache.org/community/en/involved/release/shardingsphere/
GPG user ID:
${YOUR.GPG.USER.ID}
diff --git a/docs/community/content/contribute/subscribe.cn.md b/docs/community/content/involved/subscribe.cn.md
similarity index 100%
rename from docs/community/content/contribute/subscribe.cn.md
rename to docs/community/content/involved/subscribe.cn.md
diff --git a/docs/community/content/contribute/subscribe.en.md b/docs/community/content/involved/subscribe.en.md
similarity index 100%
rename from docs/community/content/contribute/subscribe.en.md
rename to docs/community/content/involved/subscribe.en.md
diff --git a/docs/community/content/contribute/vote.cn.md b/docs/community/content/involved/vote.cn.md
similarity index 97%
rename from docs/community/content/contribute/vote.cn.md
rename to docs/community/content/involved/vote.cn.md
index 5413fe59d9b..1feb58fab67 100644
--- a/docs/community/content/contribute/vote.cn.md
+++ b/docs/community/content/involved/vote.cn.md
@@ -136,9 +136,10 @@ Just as before you became a committer, participation in any ASF community requir
https://www.apache.org/foundation/policies/conduct.html
Here is the guideline for all of the ShardingSphere committers:
-https://shardingsphere.apache.org/community/en/contribute/committer/
+https://shardingsphere.apache.org/community/en/involved/committer/
```
-**8. 准 Committer 签署 iCLA 具体步骤参考[签署 iCLA 指南](https://shardingsphere.apache.org/community/cn/contribute/icla/)。**
+
+**8. 准 Committer 签署 iCLA 具体步骤参考[签署 iCLA 指南](https://shardingsphere.apache.org/community/cn/involved/icla/)。**
**9. 等待 Secretary 通知创建账户。**
diff --git a/docs/community/content/contribute/vote.en.md b/docs/community/content/involved/vote.en.md
similarity index 97%
rename from docs/community/content/contribute/vote.en.md
rename to docs/community/content/involved/vote.en.md
index d11baba43e1..dc8a7cd94f7 100644
--- a/docs/community/content/contribute/vote.en.md
+++ b/docs/community/content/involved/vote.en.md
@@ -136,9 +136,9 @@ Just as before you became a committer, participation in any ASF community requir
https://www.apache.org/foundation/policies/conduct.html
Here is the guideline for all of the ShardingSphere committers:
-https://shardingsphere.apache.org/community/en/contribute/committer/
+https://shardingsphere.apache.org/community/en/involved/committer/
```
-**8. New committer signs iCLA, this step refers to [Sign ICLA Guide](https://shardingsphere.apache.org/community/en/contribute/icla/).**
+**8. New committer signs iCLA, this step refers to [Sign ICLA Guide](https://shardingsphere.apache.org/community/en/involved/icla/).**
**9. New committer waits for secretary to create a new account.**
diff --git a/docs/community/content/team/_index.cn.md b/docs/community/content/team/_index.cn.md
index 613d94e9bc2..e218cd78140 100644
--- a/docs/community/content/team/_index.cn.md
+++ b/docs/community/content/team/_index.cn.md
@@ -445,4 +445,4 @@ chapter = true
ShardingSphere 社区遵循 [Apache 社区流程](http://community.apache.org/newcommitter.html)来接收新的提交者。
当您积极参地与 ShardingSphere 社区之后,项目管理委员会和项目官方提交者会根据您的表现发起吸纳您成为官方提交者和项目管理委员会成员的流程。
-您可以阅读[贡献者指南](/cn/contribute/contributor/)来参与社区,并通过[提交者指南](/cn/contribute/committer/)获取更多信息。
+您可以阅读[贡献者指南](/cn/involved/contributor/)来参与社区,并通过[提交者指南](/cn/involved/committer/)获取更多信息。
diff --git a/docs/community/content/team/_index.en.md b/docs/community/content/team/_index.en.md
index 0fca4f9714c..2b0436aeb43 100644
--- a/docs/community/content/team/_index.en.md
+++ b/docs/community/content/team/_index.en.md
@@ -445,7 +445,7 @@ You can find all of the ShardingSphere contributors directly in GitHub's contrib
The ShardingSphere community follows the [Apache Community’s process](http://community.apache.org/newcommitter.html) on accepting a new committer.
Contributors that actively participate in ShardingSphere's community will be invited by the project's (P)PMC and Committers to join them by becoming a committer.
-You can read the [Contributor Guide](/en/contribute/contributor/) for more information on how you can contribute to the community, as well as the [Committer Guide](/en/contribute/committer/) for more details on how to become a committer.
+You can read the [Contributor Guide](/en/involved/contributor/) for more information on how you can contribute to the community, as well as the [Committer Guide](/en/involved/committer/) for more details on how to become a committer.
### How Can I Become a Contributor
diff --git a/docs/community/layouts/index.html b/docs/community/layouts/index.html
index 1c3ff897e9a..26b532ec480 100644
--- a/docs/community/layouts/index.html
+++ b/docs/community/layouts/index.html
@@ -2,7 +2,7 @@
<html lang="en">
<head>
<meta charset="UTF-8">
- <meta http-equiv="refresh" content="0; url=https://shardingsphere.apache.org/community/en/contribute">
+ <meta http-equiv="refresh" content="0; url=https://shardingsphere.apache.org/community/en/involved">
<title>Index</title>
</head>
<body>
diff --git a/shardingsphere-distribution/shardingsphere-jdbc-distribution/src/main/release-docs/README.txt b/shardingsphere-distribution/shardingsphere-jdbc-distribution/src/main/release-docs/README.txt
index 760615a0896..63f55cb51c9 100644
--- a/shardingsphere-distribution/shardingsphere-jdbc-distribution/src/main/release-docs/README.txt
+++ b/shardingsphere-distribution/shardingsphere-jdbc-distribution/src/main/release-docs/README.txt
@@ -36,7 +36,7 @@ Getting Started
https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-jdbc-quick-start/
We welcome contributions of all kinds, for details of how you can help
- https://shardingsphere.apache.org/community/en/contribute/
+ https://shardingsphere.apache.org/community/en/involved/
Find the issue tracker from here
https://github.com/apache/shardingsphere/issues
diff --git a/shardingsphere-distribution/shardingsphere-proxy-distribution/src/main/release-docs/README.txt b/shardingsphere-distribution/shardingsphere-proxy-distribution/src/main/release-docs/README.txt
index 1989894fb98..76f5b3fa93b 100644
--- a/shardingsphere-distribution/shardingsphere-proxy-distribution/src/main/release-docs/README.txt
+++ b/shardingsphere-distribution/shardingsphere-proxy-distribution/src/main/release-docs/README.txt
@@ -36,7 +36,7 @@ Getting Started
https://shardingsphere.apache.org/document/current/en/quick-start/shardingsphere-proxy-quick-start/
We welcome contributions of all kinds, for details of how you can help
- https://shardingsphere.apache.org/community/en/contribute/
+ https://shardingsphere.apache.org/community/en/involved/
Find the issue tracker from here
https://github.com/apache/shardingsphere/issues