You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by GitBox <gi...@apache.org> on 2020/09/01 17:12:51 UTC
[GitHub] [incubator-mxnet] anko-intel opened a new pull request #19067: [WIP] Fix compilation for large tensor with MKL
anko-intel opened a new pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067
POC for compilation with:
-DMKL_USE_ILP64=ON -DUSE_INT64_TENSOR_SIZE=ON -DUSE_BLAS=mkl
Later I will try to set MKL_USE_ILP64 to ON when USE_INT64_TENSOR_SIZE is ON
in cmake rules.
## Description ##
Work in progress for issue #18954
it allows to avoid issue with MKL/Mxnet 64 bits integer definition difference.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723382296
Jenkins CI successfully triggered : [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 removed a comment on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 removed a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693572287
@mxnet-bot run ci [centos-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693655228
Jenkins CI successfully triggered : [unix-gpu, centos-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] leezu merged pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
leezu merged pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] leezu edited a comment on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
leezu edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723382236
@Zha0q1 yes, that's the bug. NVCC is non-deterministically producing invalid output causing the MSVC to fail. You can find more details at https://github.com/thrust/thrust/issues/1090 Unfortunately NVidia does not want to fix this in Cuda 10 but only Cuda 11..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-708557683
Jenkins CI successfully triggered : [centos-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 edited a comment on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723394792
Regarding the type conversion on the gpu path for operator `det` and `slogdet`, maybe we can use a kernel like this:
```c++
struct CopyArray {
template<typename SType, typename DType>
MSHADOW_XINLINE static void Map(size_t i, SType* src, DType* dest) {
dest[i] = src[i];
}
};
......
// in det forward
if (std::is_same<xpu, gpu>::value && !std::is_same<IndexT, int>::value) {
using IndexInternalT = typename LapackIndex<xpu>::IndexT;
Tensor<xpu, 2, IndexInternalT> workspace =
ctx.requested[0].get_space_typed<xpu, 2, IndexInternalT>(pivot.shape_, s);
linalg_batch_getrf(LU, workspace, false, s);
Kernel<CopyArray, xpu>::Launch(s, pivot.shape_.Size(), workspace.dptr_, pivot.dptr_);
} else {
linalg_batch_getrf(LU, pivot, false, s);
}
```
POC https://github.com/apache/incubator-mxnet/pull/19489/files
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722802693
Jenkins CI successfully triggered : [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 edited a comment on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723394792
Regarding the type conversion on the gpu path for operator `det` and `slogdet`, maybe we can use a kernel like this:
```c++
struct CopyArray {
template<typename SType, typename DType>
MSHADOW_XINLINE static void Map(size_t i, SType* src, DType* dest) {
dest[i] = src[i];
}
};
......
// in det forward
if (std::is_same<xpu, gpu>::value && !std::is_same<IndexT, int>::value) {
using IndexInternalT = typename LapackIndex<xpu>::IndexT;
Tensor<xpu, 2, IndexInternalT> workspace =
ctx.requested[0].get_space_typed<xpu, 2, IndexInternalT>(pivot.shape_, s);
linalg_batch_getrf(LU, workspace, false, s);
Kernel<CopyArray, xpu>::Launch(s, pivot.shape_.Size(), workspace.dptr_, pivot.dptr_);
} else {
linalg_batch_getrf(LU, pivot, false, s);
}
......
// in det backward
if (std::is_same<xpu, gpu>::value && !std::is_same<IndexT, int>::value) {
using IndexInternalT = typename LapackIndex<xpu>::IndexT;
Tensor<xpu, 2, IndexInternalT> workspace =
ctx.requested[0].get_space_typed<xpu, 2, IndexInternalT>(pivot.shape_, s);
Kernel<CopyArray, xpu>::Launch(s, pivot.shape_.Size(), pivot.dptr_, workspace.dptr_);
linalg_batch_det_backward_helper(LU, workspace, det, dA, DType(0), ctx);
} else {
linalg_batch_det_backward_helper(LU, pivot, det, dA, DType(0), ctx);
}
```
POC https://github.com/apache/incubator-mxnet/pull/19489/files
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-685008431
Hey @anko-intel , Thanks for submitting the PR
All tests are already queued to run once. If tests fail, you can trigger one or more tests again with the following commands:
- To trigger all jobs: @mxnet-bot run ci [all]
- To trigger specific jobs: @mxnet-bot run ci [job1, job2]
***
**CI supported jobs**: [unix-cpu, website, windows-gpu, sanity, edge, centos-gpu, clang, miscellaneous, windows-cpu, centos-cpu, unix-gpu]
***
_Note_:
Only following 3 categories can trigger CI :PR Author, MXNet Committer, Jenkins Admin.
All CI tests must pass before the PR can be merged.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722793082
@anko-intel could you check the windows build? Thanks!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-729854828
PR is ready! Would you review @leezu
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693572287
@mxnet-bot run ci [centos-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 edited a comment on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723395187
```c++
template<
typename xpu,
typename IndexT,
std::enable_if_t<!std::is_same<IndexT, lapack_index_t>::value, int> = 0>
inline void convert_to_int_if_needed(
Stream<xpu> *s,
const Tensor<xpu, 2, IndexT>& tensor) {
}
// convertion to int is required only for GPU when IndexT is equal lapack_index_t (int64_t)
template<
typename xpu,
typename IndexT,
std::enable_if_t<std::is_same<IndexT, lapack_index_t>::value, int> = 0>
inline void convert_to_int_if_needed(
Stream<xpu> *s,
const Tensor<xpu, 2, IndexT>& tensor) {
#ifdef __CUDACC__
CHECK_LE(tensor.shape_[0], std::numeric_limits<int>::max())
<< "Tensor has size greater than supported.";
CHECK_LE(tensor.shape_[1], std::numeric_limits<int>::max())
<< "Tensor has size greater than supported.";
cudaStream_t stream = Stream<xpu>::GetStream(s);
size_t elements = tensor.shape_.Size();
std::vector<IndexT> vec(elements, 0);
IndexT* ptr = vec.data();
int* ptr_int = reinterpret_cast<int*>(vec.data());
CUDA_CALL(cudaMemcpyAsync(ptr, reinterpret_cast<IndexT*>(tensor.dptr_),
tensor.MSize() * sizeof(IndexT),
cudaMemcpyDeviceToHost, stream));
for (IndexT i = 0; i < elements; ++i) {
ptr_int[i] = static_cast<int>(ptr[i]);
}
CUDA_CALL(cudaMemcpyAsync(tensor.dptr_, ptr,
tensor.MSize() * sizeof(IndexT),
cudaMemcpyHostToDevice, stream));
#endif
}
```
This might be the trigger of the windows build issue if I were to take a guess.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on a change in pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on a change in pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#discussion_r519839681
##########
File path: src/operator/tensor/la_op-inl.h
##########
@@ -931,15 +1020,20 @@ struct det_backward {
if (dA.shape_.Size() == 0U) {
return;
}
- // compute inverse(A) and stores it to LU
- linalg_batch_det_backward_helper(LU, pivot, det, dA, DType(0), ctx);
+ Stream<xpu> *s = ctx.get_stream<xpu>();
+ convert_to_int_if_needed(s, pivot);
+ // Calculations on the GPU path are internally done on int type.
+ using IndexInternalT = typename LapackIndex<xpu>::IndexT;
+ linalg_batch_det_backward_helper(LU,
+ reinterpret_cast<const Tensor<xpu, 2, IndexInternalT>&>(pivot),
+ det, dA, DType(0), ctx);
const_cast<Tensor<xpu, 3, DType>&>(dA) = broadcast_to(reshape(det * ddet, \
Shape3(det.size(0), 1, 1)), mxnet::TShape(LU.shape_)) * \
transpose(LU, Shape3(0, 2, 1));
- Stream<xpu> *s = ctx.get_stream<xpu>();
// stop grad for zero det temporarily
Kernel<StopZeroDetGrad, xpu>::Launch(s, dA.shape_.Size(), dA.size(1) * dA.size(2), \
dA.dptr_, det.dptr_, DType(0));
+ convert_to_int64_if_needed(s, pivot);
Review comment:
You are right. I had doubt if we can modify memory pointed by the input tensor. I will remove this line
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-694950064
Jenkins CI successfully triggered : [centos-cpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722804488
Unauthorized access detected.
Only following 3 categories can trigger CI :
PR Author, MXNet Committer, Jenkins Admin.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693724509
> @mxnet-bot run ci [centos-gpu, unix-gpu]
Looks like it was just being flacky
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-694950003
@mxnet-bot run ci [centos-cpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722679329
@mxnet-bot run ci [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-724729577
@mxnet-bot run ci [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723394792
Regarding the type conversion on the gpu path for operator `det` and `slogdet`, maybe we can use a kernel like this:
```c++
struct CopyArray {
template<typename SType, typename DType>
MSHADOW_XINLINE static void Map(size_t i, SType* src, DType* dest) {
dest[i] = src[i];
}
};
......
// in det forward
if (std::is_same<xpu, gpu>::value && !std::is_same<IndexT, int>::value) {
using IndexInternalT = typename LapackIndex<xpu>::IndexT;
Tensor<xpu, 2, IndexInternalT> workspace =
ctx.requested[0].get_space_typed<xpu, 2, IndexInternalT>(pivot.shape_, s);
linalg_batch_getrf(LU, workspace, false, s);
Kernel<CopyArray, xpu>::Launch(s, pivot.shape_.Size(), workspace.dptr_, pivot.dptr_);
} else {
linalg_batch_getrf(LU, pivot, false, s);
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723395187
```c++
template<
typename xpu,
typename IndexT,
std::enable_if_t<!std::is_same<IndexT, lapack_index_t>::value, int> = 0>
inline void convert_to_int_if_needed(
Stream<xpu> *s,
const Tensor<xpu, 2, IndexT>& tensor) {
}
// convertion to int is required only for GPU when IndexT is equal lapack_index_t (int64_t)
template<
typename xpu,
typename IndexT,
std::enable_if_t<std::is_same<IndexT, lapack_index_t>::value, int> = 0>
inline void convert_to_int_if_needed(
Stream<xpu> *s,
const Tensor<xpu, 2, IndexT>& tensor) {
#ifdef __CUDACC__
CHECK_LE(tensor.shape_[0], std::numeric_limits<int>::max())
<< "Tensor has size greater than supported.";
CHECK_LE(tensor.shape_[1], std::numeric_limits<int>::max())
<< "Tensor has size greater than supported.";
cudaStream_t stream = Stream<xpu>::GetStream(s);
size_t elements = tensor.shape_.Size();
std::vector<IndexT> vec(elements, 0);
IndexT* ptr = vec.data();
int* ptr_int = reinterpret_cast<int*>(vec.data());
CUDA_CALL(cudaMemcpyAsync(ptr, reinterpret_cast<IndexT*>(tensor.dptr_),
tensor.MSize() * sizeof(IndexT),
cudaMemcpyDeviceToHost, stream));
for (IndexT i = 0; i < elements; ++i) {
ptr_int[i] = static_cast<int>(ptr[i]);
}
CUDA_CALL(cudaMemcpyAsync(tensor.dptr_, ptr,
tensor.MSize() * sizeof(IndexT),
cudaMemcpyHostToDevice, stream));
#endif
}
```
This might be the cause of the windows build issue if I were to take a guess.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] leezu commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
leezu commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723382379
@anko-intel can you try to rebase and force-push?
I'm concerned about merging this PR as for unknown reason it makes the nvcc bug more frequent. Maybe @josephevans can provide an ETA for the Windows Cuda 11 work and we may be able to wait for that?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-708557604
@mxnet-bot run ci [centos-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693572335
Unauthorized access detected.
Only following 3 categories can trigger CI :
PR Author, MXNet Committer, Jenkins Admin.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-724852789
Jenkins CI successfully triggered : [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] leezu commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
leezu commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722802641
@Zha0q1 @anko-intel the windows gpu failure is to an infamous bug in Cuda 10. It is usually mitigated by retrying compilation for 5 times, but your PR was unlucky or the code change has increased the probability of the Cuda compiler bug.
@josephevans is helping to update the CI to Cuda 11 to finally get rid of the bug. CC @sandeep-krishnamurthy
@mxnet-bot run ci [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 edited a comment on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693625762
@mxnet_bot run ci [centos-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723039439
@mxnet-bot run ci [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] leezu commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
leezu commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723382236
@Zha0q1 yes, that's the bug. NVCC is non-deterministically producing invalid output causing the MSVC to fail. You can find more details at https://github.com/thrust/thrust/issues/1090
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722912739
> @Zha0q1 @anko-intel the windows gpu failure is to an infamous bug in Cuda 10. It is usually mitigated by retrying compilation for 5 times, but your PR was unlucky or the code change has increased the probability of the Cuda compiler bug.
It's failing again. We are talking about this issue right?
```
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2993: 'T': illegal type for non-type template parameter '__formal'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): note: see reference to class template instantiation 'thrust::detail::allocator_traits_detail::has_system_type<T>' being compiled
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2065: 'U1': undeclared identifier
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2923: 'std::_Select<__formal>::_Apply': 'U1' is not a valid template type argument for parameter '<unnamed-symbol>'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C4430: missing type specifier - int assumed. Note: C++ does not support default-int
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2144: syntax error: 'unknown-type' should be preceded by ')'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2144: syntax error: 'unknown-type' should be preceded by ';'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2238: unexpected token(s) preceding ';'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2059: syntax error: ')'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2988: unrecognizable template declaration/definition
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2059: syntax error: '<end Parse>'
[2020-11-06T06:14:35.175Z] ../3rdparty/tvm/nnvm/include\nnvm/symbolic.h(73): warning C4251: 'nnvm::Symbol::outputs': class 'std::vector<nnvm::NodeEntry,std::allocator<nnvm::NodeEntr
```
that's really an interesting bug :p
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723039484
Jenkins CI successfully triggered : [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-724729648
Jenkins CI successfully triggered : [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on a change in pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on a change in pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#discussion_r518975411
##########
File path: src/operator/tensor/la_op-inl.h
##########
@@ -931,15 +1020,20 @@ struct det_backward {
if (dA.shape_.Size() == 0U) {
return;
}
- // compute inverse(A) and stores it to LU
- linalg_batch_det_backward_helper(LU, pivot, det, dA, DType(0), ctx);
+ Stream<xpu> *s = ctx.get_stream<xpu>();
+ convert_to_int_if_needed(s, pivot);
+ // Calculations on the GPU path are internally done on int type.
+ using IndexInternalT = typename LapackIndex<xpu>::IndexT;
+ linalg_batch_det_backward_helper(LU,
+ reinterpret_cast<const Tensor<xpu, 2, IndexInternalT>&>(pivot),
+ det, dA, DType(0), ctx);
const_cast<Tensor<xpu, 3, DType>&>(dA) = broadcast_to(reshape(det * ddet, \
Shape3(det.size(0), 1, 1)), mxnet::TShape(LU.shape_)) * \
transpose(LU, Shape3(0, 2, 1));
- Stream<xpu> *s = ctx.get_stream<xpu>();
// stop grad for zero det temporarily
Kernel<StopZeroDetGrad, xpu>::Launch(s, dA.shape_.Size(), dA.size(1) * dA.size(2), \
dA.dptr_, det.dptr_, DType(0));
+ convert_to_int64_if_needed(s, pivot);
Review comment:
I think the only output is dA? In that case we might not need to convert the results back to int64
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-724852740
@mxnet-bot run ci [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-729802457
Jenkins CI successfully triggered : [windows-cpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] leezu commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
leezu commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723382290
@mxnet-bot run ci [windows-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] access2rohit commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
access2rohit commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-703843530
re-triggerred sanity
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-724057472
Thank you @Zha0q1 for your comments. I measured performance with your kernel from commit: https://github.com/apache/incubator-mxnet/pull/19489/commits/31e07c4421aaa58a4812d42e9964af7986356b45 and it gives better results that my original https://github.com/apache/incubator-mxnet/pull/19067/commits/fd624bea7f2a9d38605a275e75c6112a71cdd0d2:
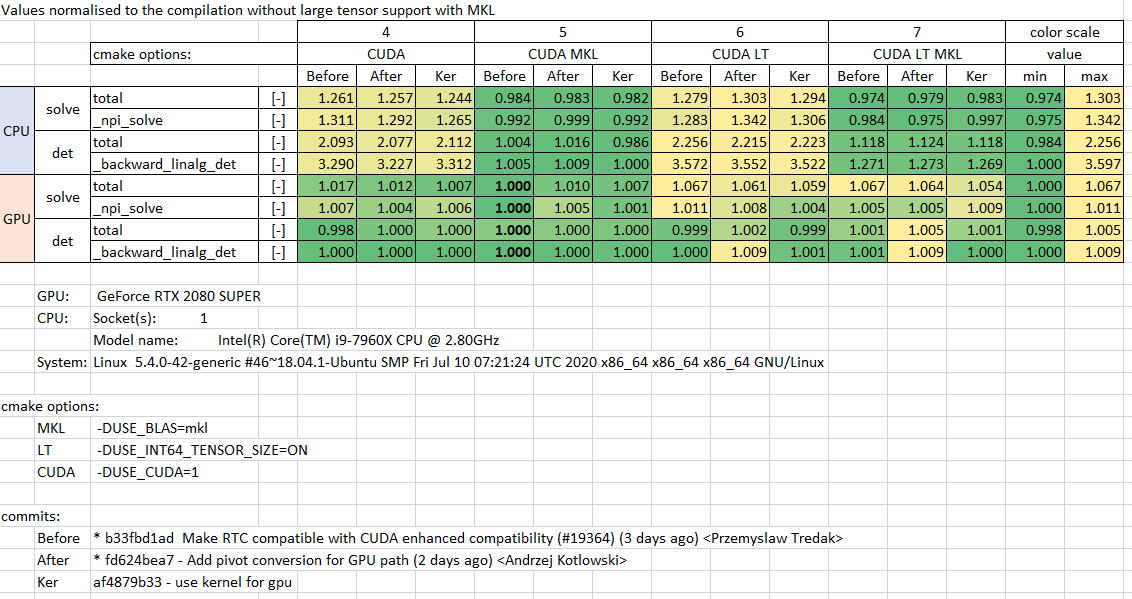
So I put it as solution for dot and slogdet on GPU path.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693625762
@mxnet_bot run ci [centos_gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 edited a comment on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722912739
> @Zha0q1 @anko-intel the windows gpu failure is to an infamous bug in Cuda 10. It is usually mitigated by retrying compilation for 5 times, but your PR was unlucky or the code change has increased the probability of the Cuda compiler bug.
It's failing again. We are talking about this issue right?
```
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2993: 'T': illegal type for non-type template parameter '__formal'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): note: see reference to class template instantiation 'thrust::detail::allocator_traits_detail::has_system_type<T>' being compiled
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2065: 'U1': undeclared identifier
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2923: 'std::_Select<__formal>::_Apply': 'U1' is not a valid template type argument for parameter '<unnamed-symbol>'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C4430: missing type specifier - int assumed. Note: C++ does not support default-int
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2144: syntax error: 'unknown-type' should be preceded by ')'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2144: syntax error: 'unknown-type' should be preceded by ';'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2238: unexpected token(s) preceding ';'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2059: syntax error: ')'
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2988: unrecognizable template declaration/definition
[2020-11-06T06:14:35.175Z] C:/Windows/TEMP/tmpkffgnho0/thrust-1.9.8\thrust/detail/allocator/allocator_traits.h(54): error C2059: syntax error: '<end Parse>'
[2020-11-06T06:14:35.175Z] ../3rdparty/tvm/nnvm/include\nnvm/symbolic.h(73): warning C4251: 'nnvm::Symbol::outputs': class 'std::vector<nnvm::NodeEntry,std::allocator<nnvm::NodeEntr
```
that's really an interesting bug :p
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693724530
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 edited a comment on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722804472
> @Zha0q1 @anko-intel the windows gpu failure is to an infamous bug in Cuda 10. It is usually mitigated by retrying compilation for 5 times, but your PR was unlucky or the code change has increased the probability of the Cuda compiler bug.
>
Ohh I see. Thanks for the clarification!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693655181
@mxnet-bot run ci [centos-gpu, unix-gpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] mxnet-bot commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
mxnet-bot commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722679350
Unauthorized access detected.
Only following 3 categories can trigger CI :
PR Author, MXNet Committer, Jenkins Admin.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-722804472
> @Zha0q1 @anko-intel the windows gpu failure is to an infamous bug in Cuda 10. It is usually mitigated by retrying compilation for 5 times, but your PR was unlucky or the code change has increased the probability of the Cuda compiler bug.
>
> @josephevans is helping to update the CI to Cuda 11 to finally get rid of the bug. CC @sandeep-krishnamurthy
>
> @mxnet-bot run ci [windows-gpu]
Ohh I see. Thanks for the clarification!
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] leezu edited a comment on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
leezu edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-723382379
@anko-intel can you try to rebase and force-push if windows-gpu fails again?
I'm concerned about merging this PR as for unknown reason it makes the nvcc bug more frequent. Maybe @josephevans can provide an ETA for the Windows Cuda 11 work and we may be able to wait for that?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] anko-intel commented on pull request #19067: Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
anko-intel commented on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-729802415
@mxnet-bot run ci [windows-cpu]
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [incubator-mxnet] Zha0q1 edited a comment on pull request #19067: [WIP] Fix compilation for large tensor with MKL
Posted by GitBox <gi...@apache.org>.
Zha0q1 edited a comment on pull request #19067:
URL: https://github.com/apache/incubator-mxnet/pull/19067#issuecomment-693724509
> @mxnet-bot run ci [centos-gpu, unix-gpu]
Test passed. Looks like it was just being flaky
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org