You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2020/09/04 10:38:20 UTC
[GitHub] [spark] sandeep-katta opened a new pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
sandeep-katta opened a new pull request #29649:
URL: https://github.com/apache/spark/pull/29649
### What changes were proposed in this pull request?
No need of using database name in `loadPartition` API of Shim_v3_0 to get the hive table, already in hive there is a overloaded method which gives hive table using table name. Using this approach dependency on `SessionCatalog` can be in removed in Shim layer
### Why are the changes needed?
To avoid deadlock when communicating with Hive metastore 3.1.x
```
Found one Java-level deadlock:
=============================
"worker3":
waiting to lock monitor 0x00007faf0be602b8 (object 0x00000007858f85f0, a org.apache.spark.sql.hive.HiveSessionCatalog),
which is held by "worker0"
"worker0":
waiting to lock monitor 0x00007faf0be5fc88 (object 0x0000000785c15c80, a org.apache.spark.sql.hive.HiveExternalCatalog),
which is held by "worker3"
Java stack information for the threads listed above:
===================================================
"worker3":
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.getCurrentDatabase(SessionCatalog.scala:256)
- waiting to lock <0x00000007858f85f0> (a org.apache.spark.sql.hive.HiveSessionCatalog)
at org.apache.spark.sql.hive.client.Shim_v3_0.loadPartition(HiveShim.scala:1332)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$loadPartition$1(HiveClientImpl.scala:870)
at org.apache.spark.sql.hive.client.HiveClientImpl$$Lambda$4459/1387095575.apply$mcV$sp(Unknown Source)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$withHiveState$1(HiveClientImpl.scala:294)
at org.apache.spark.sql.hive.client.HiveClientImpl$$Lambda$2227/313239499.apply(Unknown Source)
at org.apache.spark.sql.hive.client.HiveClientImpl.liftedTree1$1(HiveClientImpl.scala:227)
at org.apache.spark.sql.hive.client.HiveClientImpl.retryLocked(HiveClientImpl.scala:226)
- locked <0x0000000785ef9d78> (a org.apache.spark.sql.hive.client.IsolatedClientLoader)
at org.apache.spark.sql.hive.client.HiveClientImpl.withHiveState(HiveClientImpl.scala:276)
at org.apache.spark.sql.hive.client.HiveClientImpl.loadPartition(HiveClientImpl.scala:860)
at org.apache.spark.sql.hive.HiveExternalCatalog.$anonfun$loadPartition$1(HiveExternalCatalog.scala:911)
at org.apache.spark.sql.hive.HiveExternalCatalog$$Lambda$4457/2037578495.apply$mcV$sp(Unknown Source)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:99)
- locked <0x0000000785c15c80> (a org.apache.spark.sql.hive.HiveExternalCatalog)
at org.apache.spark.sql.hive.HiveExternalCatalog.loadPartition(HiveExternalCatalog.scala:890)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.loadPartition(ExternalCatalogWithListener.scala:179)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.loadPartition(SessionCatalog.scala:512)
at org.apache.spark.sql.execution.command.LoadDataCommand.run(tables.scala:383)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
- locked <0x00000007b1690ff8> (a org.apache.spark.sql.execution.command.ExecutedCommandExec)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:229)
at org.apache.spark.sql.Dataset$$Lambda$2084/428667685.apply(Unknown Source)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3616)
at org.apache.spark.sql.Dataset$$Lambda$2085/559530590.apply(Unknown Source)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$$$Lambda$2093/139449177.apply(Unknown Source)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.execution.SQLExecution$$$Lambda$2086/1088974677.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3614)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:229)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:100)
at org.apache.spark.sql.Dataset$$$Lambda$1959/1977822284.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:97)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:606)
at org.apache.spark.sql.SparkSession$$Lambda$1899/424830920.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:601)
at $line14.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$anon$1.run(<console>:45)
at java.lang.Thread.run(Thread.java:748)
"worker0":
at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:99)
- waiting to lock <0x0000000785c15c80
> (a org.apache.spark.sql.hive.HiveExternalCatalog)
at org.apache.spark.sql.hive.HiveExternalCatalog.tableExists(HiveExternalCatalog.scala:851)
at org.apache.spark.sql.catalyst.catalog.ExternalCatalogWithListener.tableExists(ExternalCatalogWithListener.scala:146)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.tableExists(SessionCatalog.scala:432)
- locked <0x00000007858f85f0> (a org.apache.spark.sql.hive.HiveSessionCatalog)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.requireTableExists(SessionCatalog.scala:185)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.loadPartition(SessionCatalog.scala:509)
at org.apache.spark.sql.execution.command.LoadDataCommand.run(tables.scala:383)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:70)
- locked <0x00000007b529af58> (a org.apache.spark.sql.execution.command.ExecutedCommandExec)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:68)
at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:79)
at org.apache.spark.sql.Dataset.$anonfun$logicalPlan$1(Dataset.scala:229)
at org.apache.spark.sql.Dataset$$Lambda$2084/428667685.apply(Unknown Source)
at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3616)
at org.apache.spark.sql.Dataset$$Lambda$2085/559530590.apply(Unknown Source)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:100)
at org.apache.spark.sql.execution.SQLExecution$$$Lambda$2093/139449177.apply(Unknown Source)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:160)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:87)
at org.apache.spark.sql.execution.SQLExecution$$$Lambda$2086/1088974677.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64)
at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3614)
at org.apache.spark.sql.Dataset.<init>(Dataset.scala:229)
at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:100)
at org.apache.spark.sql.Dataset$$$Lambda$1959/1977822284.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:97)
at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:606)
at org.apache.spark.sql.SparkSession$$Lambda$1899/424830920.apply(Unknown Source)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:763)
at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:601)
at $line14.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$anon$1.run(<console>:45)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Tested using below script by executing in spark-shell and I found no dead lock
launch spark-shell using ./bin/spark-shell --conf "spark.sql.hive.metastore.jars=maven" --conf spark.sql.hive.metastore.version=3.1 --conf spark.hadoop.datanucleus.schema.autoCreateAll=true
**code**
```
def testHiveDeadLock = {
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
println("test hive DeadLock")
spark.sql("drop database if exists testDeadLock cascade")
spark.sql("create database testDeadLock")
spark.sql("use testDeadLock")
val tableCount = 100
val tableNamePrefix = "testdeadlock"
for (i <- 0 until tableCount) {
val tableName = s"$tableNamePrefix${i + 1}"
spark.sql(s"drop table if exists $tableName")
spark.sql(s"create table $tableName (a bigint) partitioned by (b bigint) stored as orc")
}
val threads = new ArrayBuffer[Thread]
for (i <- 0 until tableCount) {
threads.append(new Thread( new Runnable {
override def run: Unit = {
val tableName = s"$tableNamePrefix${i + 1}"
val rand = Random
val df = spark.range(0, 20000).toDF("a")
val location = s"/tmp/${rand.nextLong.abs}"
df.write.mode("overwrite").orc(location)
spark.sql(
s"""
LOAD DATA LOCAL INPATH '$location' INTO TABLE $tableName partition (b=$i)""")
}
}, s"worker$i"))
threads(i).start()
}
for (i <- 0 until tableCount) {
println(s"Joining with thread $i")
threads(i).join()
}
for (i <- 0 until tableCount) {
val tableName = s"$tableNamePrefix${i + 1}"
spark.sql(s"select count(*) from $tableName").show(false)
}
println("All done")
}
for(i <- 0 until 100) {
testHiveDeadLock
println(s"completed {$i}th iteration")
}
}
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687124058
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-691182433
Thank you, @sandeep-katta and all.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687124058
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r487371742
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484189537
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
> If the question is why `Shim.loadPartition` doesn't take database as an argument, yes I think we can change to take. But looks like it's to match with `Hive.loadPartition`'s signature.
+1 for this , I will update the API signature to take the database name
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484188369
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
`Hive.loadPartition` for Hive-3.1.x it takes `Table`, but other Hive version such as 2.1.x takes `tablename` as `string`
Hive-3.1.0
```
public Partition loadPartition(Path loadPath, Table tbl, Map<String, String> partSpec,
LoadFileType loadFileType, boolean inheritTableSpecs, boolean isSkewedStoreAsSubdir,
boolean isSrcLocal, boolean isAcidIUDoperation, boolean hasFollowingStatsTask, Long writeId,
int stmtId, boolean isInsertOverwrite)
```
Hive-2.1.0
```
public void loadPartition(Path loadPath, String tableName,
Map<String, String> partSpec, boolean replace,
boolean inheritTableSpecs, boolean isSkewedStoreAsSubdir,
boolean isSrcLocal, boolean isAcid, boolean hasFollowingStatsTask)
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-691182433
Thank you, @sandeep-katta and all.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r487372485
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-688059047
Merged to master and branch-3.0.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687068936
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484183375
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
just for curiosity, why can't we use `hive.getTable(dbName, tblName)` here? It looks weird that the `loadPartition` method in `HiveShim` takes a single `tableName` parameter which is a qualified name.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687804218
CC @dongjoon-hyun
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r487140171
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484183880
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
We can use. The problem is when we get the `database` here from `session.get.sessionState.catalog.getCurrentDatabase `.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r487371742
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r487371742
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
Ah!! sorry, I missed that will raise follow-up
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
I raised the follow-up PR [29736](https://github.com/apache/spark/pull/29736). Sorry for the trouble
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-691182433
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687068936
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-691182433
Thank you, @sandeep-katta and all.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r487140171
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687123099
**[Test build #128298 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/128298/testReport)** for PR 29649 at commit [`8d45542`](https://github.com/apache/spark/commit/8d45542e915bea1b321f42988b407091065a2539).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484004644
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
What if a different database has the same name of table?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484186429
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
If the question is why `Shim.loadPartition` doesn't take database as an argument, yes I think we can change to take. But looks like it's to match with `Hive.loadPartition`'s signature.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687068769
cc @wangyum @cloud-fan
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687068418
**[Test build #128298 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/128298/testReport)** for PR 29649 at commit [`8d45542`](https://github.com/apache/spark/commit/8d45542e915bea1b321f42988b407091065a2539).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r487140171
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
Review comment:
In this case, it seems that we can remove the above two lines together, doesn't it?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
sandeep-katta commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484018660
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
This should not be a problem, reason as per below
Spark prefixes the database name to the table name, so hive can resolve the database from tablename
**Spark Code** https://github.com/apache/spark/blob/master/sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala#L855-L873
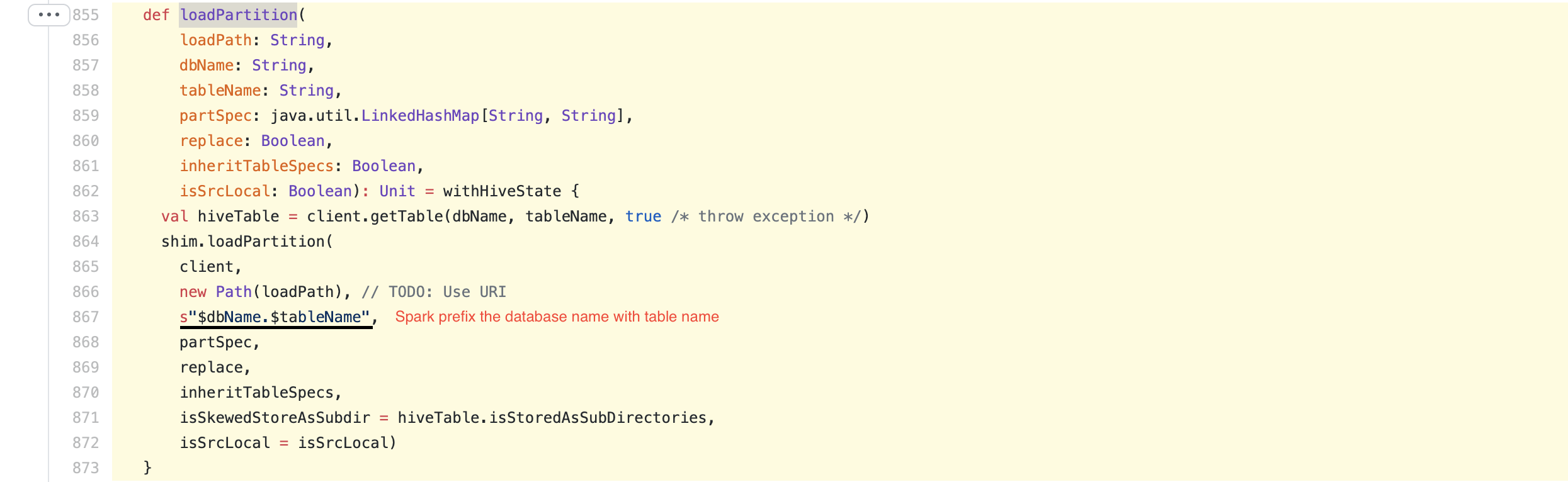
**Hive Code**
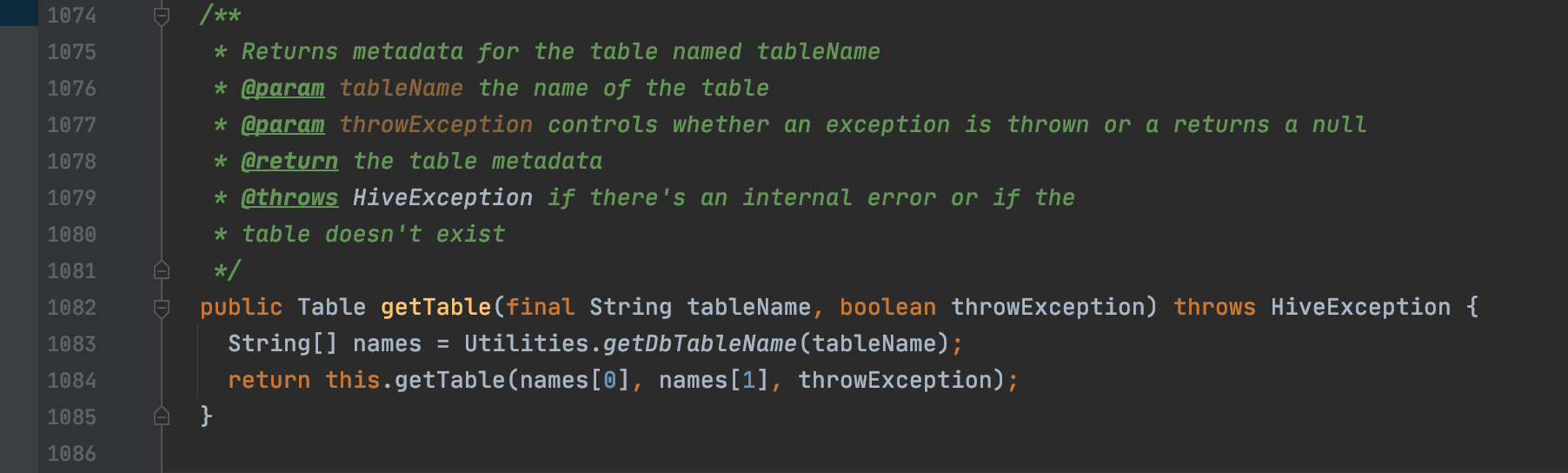
https://github.com/apache/hive/blob/rel/release-3.1.0/ql/src/java/org/apache/hadoop/hive/ql/exec/Utilities.java#L2145-L2169
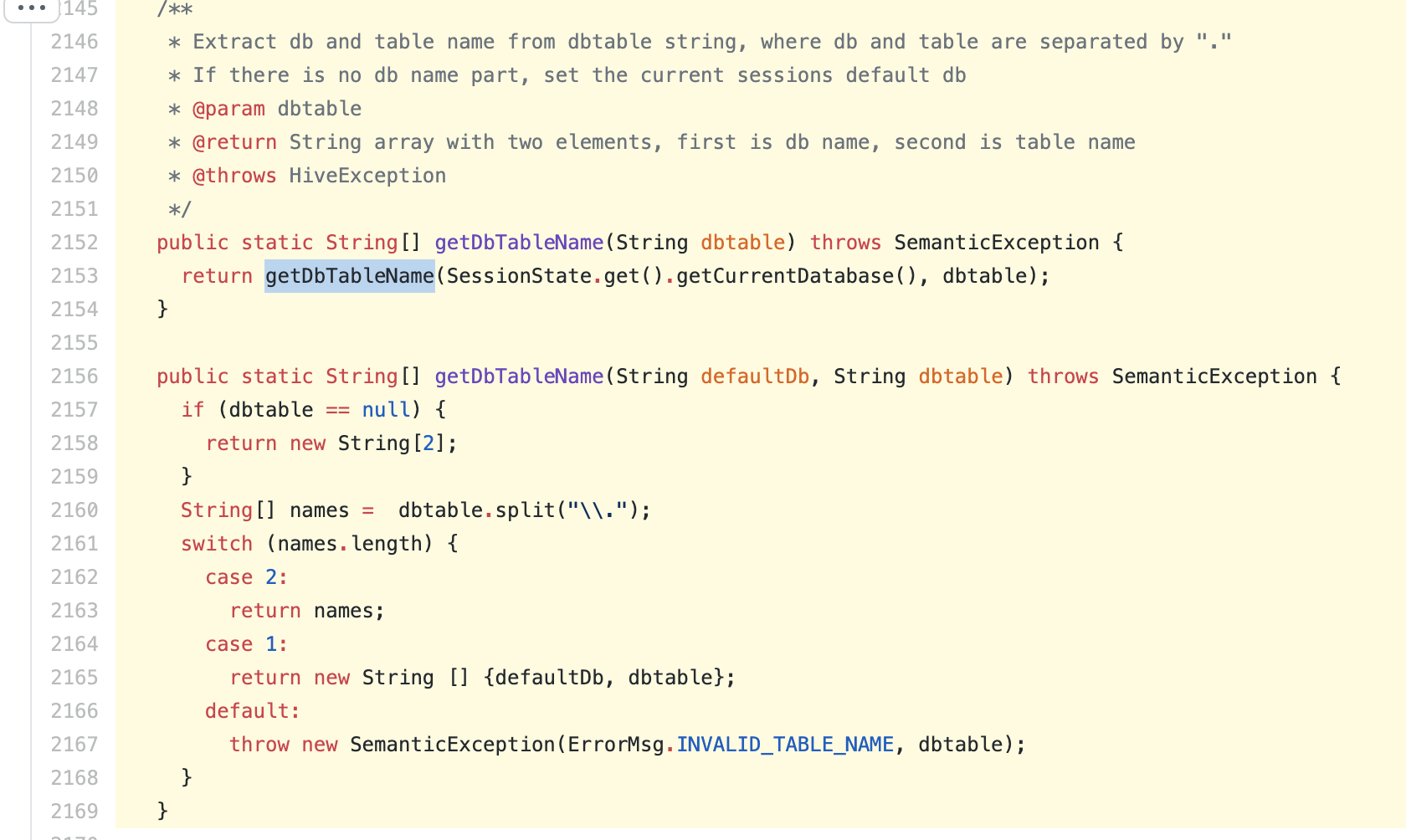
P.S : Above mentioned logic is already working with Hive-2.1 support
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #29649:
URL: https://github.com/apache/spark/pull/29649#issuecomment-687068418
**[Test build #128298 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/128298/testReport)** for PR 29649 at commit [`8d45542`](https://github.com/apache/spark/commit/8d45542e915bea1b321f42988b407091065a2539).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484187110
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
The `Hive.loadPartition` API we are using here takes a `Table` instance as a parameter, not a single table name.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
HyukjinKwon closed pull request #29649:
URL: https://github.com/apache/spark/pull/29649
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #29649: [SPARK-32779][SQL] Avoid using synchronized API of SessionCatalog in withClient flow, this leads to DeadLock
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #29649:
URL: https://github.com/apache/spark/pull/29649#discussion_r484189882
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveShim.scala
##########
@@ -1329,8 +1329,7 @@ private[client] class Shim_v3_0 extends Shim_v2_3 {
isSrcLocal: Boolean): Unit = {
val session = SparkSession.getActiveSession
assert(session.nonEmpty)
- val database = session.get.sessionState.catalog.getCurrentDatabase
- val table = hive.getTable(database, tableName)
+ val table = hive.getTable(tableName)
Review comment:
I think it's okay to don't change at least in this PR since this PR will likely be ported back. Minimised change here looks good.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org