You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@tvm.apache.org by GitBox <gi...@apache.org> on 2021/01/11 11:32:49 UTC
[GitHub] [tvm] zhuwenxi opened a new issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
zhuwenxi opened a new issue #7246:
URL: https://github.com/apache/tvm/issues/7246
### Problem Statement
This bug was encountered when I was trying to use external as "micro-kernel" to optimize the Matmul op. Basically I was just following the [TVM Tensorize Tutorial](https://tvm.apache.org/docs/tutorials/language/tensorize.html), and did a little modification by replacing the `tvm.tir.call_extern('int32', 'gemv_update'` with `tvm.tir.call_packed("tvm.contrib.cblas.matmul"...`, which of course because I'm trying to leverage existing blas library to do tensorize. The code works pretty well, until I add a `s[C].parallel(xo)`, It crashed:
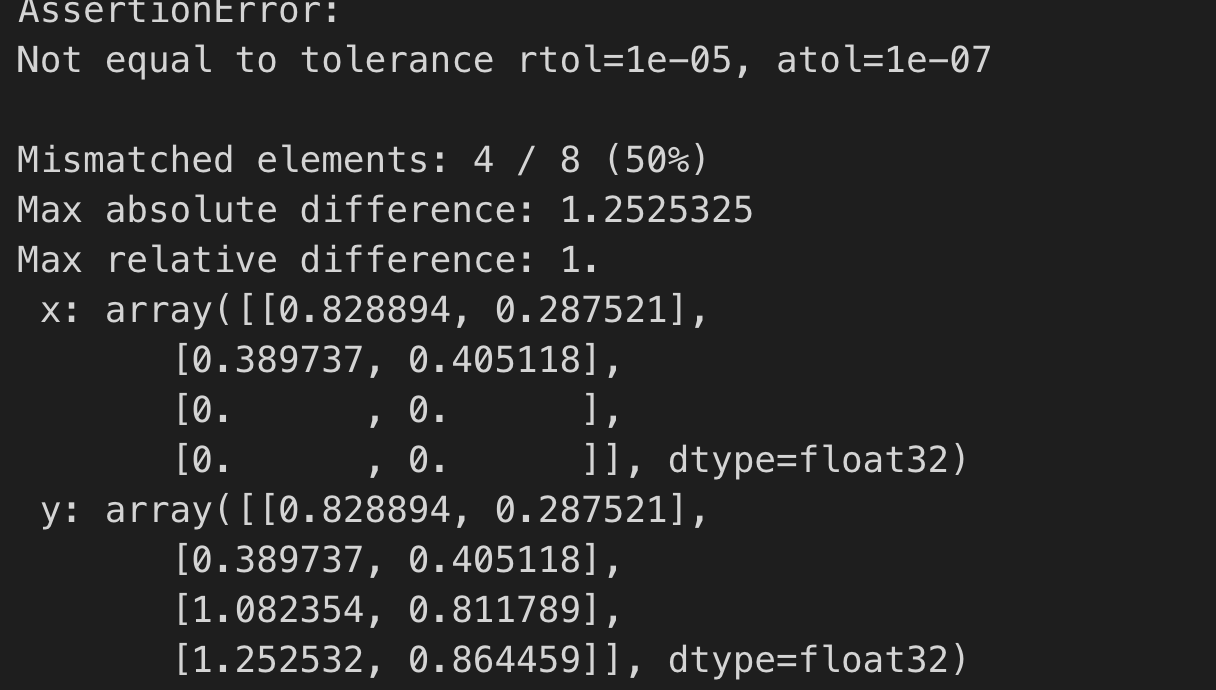
### Environment
* CPU: CacadeLake-X
* OS: CentOS 7.0
* TVM: 0.7
* LLVM: 9.0
### Code to reproduce this bug
<pre>import tvm
from tvm import te
import numpy as np
import sys
from tvm import testing
# Fail case:
M, K, N = 4, 4, 2
A = te.placeholder((M, K), name='A')
B = te.placeholder((K, N), name='B')
k = te.reduce_axis((0, K), name='k')
C = te.compute((M, N), lambda i, j: te.sum(A[i, k] * B[k, j], axis=k), name='C')
s = te.create_schedule(C.op)
bn = 2
xo, yo, xi, yi = s[C].tile(C.op.axis[0], C.op.axis[1], bn, bn)
s[C].reorder(xo, yo, xi, yi, k)
s[C].parallel(xo)
def intrin_libxsmm(m, k, n):
a = te.placeholder((m, k), name='a')
b = te.placeholder((k, n), name='b')
k = te.reduce_axis((0, k), name='k')
c = te.compute((m, n), lambda i, j: te.sum(a[i, k] * b[k, j], axis=k), name='c')
a_buffer = tvm.tir.decl_buffer(a.shape, a.dtype, name='a_buffer', offset_factor=1, strides=[te.var('s1'), 1])
b_buffer = tvm.tir.decl_buffer(b.shape, b.dtype, name='b_buffer', offset_factor=1, strides=[te.var('s2'), 1])
c_buffer = tvm.tir.decl_buffer(c.shape, c.dtype, name='c_buffer', offset_factor=1, strides=[te.var('s3'), 1])
def intrin_func(ins, outs):
ib = tvm.tir.ir_builder.create()
ib.emit(
tvm.tir.call_packed(
"tvm.contrib.cblas.matmul", ins[0], ins[1], outs[0], False, False, 1.0, 0.0
)
)
return ib.get()
return te.decl_tensor_intrin(c.op, intrin_func, binds={a: a_buffer, b: b_buffer, c: c_buffer})
micro_kernel = intrin_libxsmm(bn, K, bn)
s[C].tensorize(xi, micro_kernel)
ctx = tvm.cpu(0)
func = tvm.build(s, [A, B, C], target='llvm')
a = tvm.nd.array(np.random.uniform(size=(M, K)).astype(A.dtype), ctx)
b = tvm.nd.array(np.random.uniform(size=(K, N)).astype(B.dtype), ctx)
c = tvm.nd.array(np.zeros((M, N), dtype=C.dtype), ctx)
func(a, b, c)
tvm.testing.assert_allclose(c.asnumpy(), np.dot(a.asnumpy(), b.asnumpy()), rtol=1e-5)</pre>
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-787769062
@tqchen Do you know the specific LLVM API to create a variable-length array with thread-local storage?
I'm starting from the LLVM backend, and I found existing code uses `builder_->CreateAlloca()` to do codegen for the `tvm_stack_alloc`instrinsic: https://github.com/apache/tvm/blob/main/src/target/llvm/codegen_cpu.cc#L892
To make the allocation thread-local, I searched over all the llvm document but have no luck. The only TLS related thread I get from llvm form is this: https://llvm.discourse.group/t/jit-execution-with-thread-local-global-variable/1081, which demos how to create a thread-local llvm::GlobalVariable.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-762573994
I'm happy to contribute this patch :) I will start from writing a prototype to do POC, and I'll keep you posted.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-776946615
ping @zhuwenxi please let us know about the status and anything we can help
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-760285952
Thanks @zhuwenxi. I still think the original proposal is better. Especially in the case of (rare) nested parallel loops(parallel inside parallel). Notably performance-wise we are allocating the stack at the beginning of the current function(rather than the calling site), so it comes from the thread-local stack. I don't think there will be a performance issue.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-788768727
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-790248073
@tqchen Update some of my findings in C and StackVM backends.
1. In the C backend, "tvm_call_packed" crashes: https://discuss.tvm.apache.org/t/bug-codegenc-tvm-call-packed-crashes-when-build-with-target-c/9291, I'm wondering if it is a known issue?
2. For the StackVM side, I didn't find any facilities for parallel execution. If I understand correctly, that means we don't need to do anything for this backend?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-791095757
Would you prefer me to fire a PR of llvm/stackvm fix first, for you to review? Since it seems there are some issues in C backend.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-784226148
Assuming we will use use `tir.tvm_stack_alloca`, here is the new semantics:
- Retrieve a constant-sized temp memory allocated during the function entry for packed argument calls, this memory is only alive within the current basic block.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759474760
Thank you @zhuwenxi! this is indeed an issue that we need to work to resolve. The main problem was the stack used for parallel packed call being raised into outside of the parallel for block during PackedCall lowering.
We will need to think about ways to improve the packed call handling to avoid lifting such allocation to outside of the parallel for block
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-788780343
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-791120967
I see, if the old c backend does not support the packed. Please feel free to send a PR. In the meantime, let us look into a fix together. cc @areusch @ZihengJiang
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-762314809
Please let me know if you are interested in contributing a patch :) Would be more than happy to shepherd the PR
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-785664712
Make sense. So no new intrinsic required, what we need to do is merely to change the semantics of `tvm_stack_alloca` and its corresponding implementations in those 3 backends. Got it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] areusch commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
areusch commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-791784931
fixing call_packed in c sounds good, I believe it is a bug. there has been some parallel discussion on the [AOT proposal](https://discuss.tvm.apache.org/t/implementing-aot-in-tvm/9206/9) about whether the C backend should implement PackedFunc calls similar to `tir.call_extern`. Also, I don't _think_ threading or parallel tasks has been tested with C runtime, so we should take that into account too.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-784223136
The function will looks like
```
fn myfunc() {
for i in range(10):
stack_tcode = @tir.packed_arg_alloca("arg_tcode", 8)
stack_value = @tir.packed_arg_alloca("arg_value", 8)
tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_1)
}
```
In the LLVM code generator, we want the compiled code to look like
```
fn myfunc() {
begin:
stack_tcode0 = alloca("arg_tcode", 8)
stack_value1 = alloca("arg_value", 8)
loop:
for i in range(10):
tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_1)
}
```
This can be done by jumping to the function begin basic block for insertion. https://github.com/apache/tvm/blob/81d9f11ab87dc3ef5fc906aa6ca23737885f7b27/src/target/llvm/codegen_llvm.h#L173
Note that this is a restriction of LLVM IR(alloca always happens in the beginning of the function). Additionally, we could certainly coleasce the stack of multiple calls, although LLVM could do that for us so we do not need to do so.
Note that in the case of parallel, a new function will be created for the parallel body, and WithFunctionEntry will get the alloca inserted at the beginning of that function. This is the benefit of delaying the alloca location move until the code gen point.
For the case of StackVM, we could certainly directly grow the stack at callsite. For the case of C generator, depending on the restriction of language, we might also need to create allocation in the beginning (e.g. create a init fragement stream of a function that is separated from the rest).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759957921
> Thank you @zhuwenxi! this is indeed an issue that we need to work to resolve. The main problem was the stack used for parallel packed call being raised into outside of the parallel for block during PackedCall lowering.
>
> We will need to think about ways to improve the packed call handling to avoid lifting such allocation to outside of the parallel for block
@tqchen , thanks for the reply!
Despite the race condition in a parallel schedule, I think the approach that allocate stack outside of (parallel) loops does have some sort of performance advantages, that it makes stack shared between multiple packed func call which could help save tremendous re-allocation time.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759957921
> Thank you @zhuwenxi! this is indeed an issue that we need to work to resolve. The main problem was the stack used for parallel packed call being raised into outside of the parallel for block during PackedCall lowering.
>
> We will need to think about ways to improve the packed call handling to avoid lifting such allocation to outside of the parallel for block
@tqchen , thanks for the reply!
Despite the race condition in a parallel schedule, I think the approach that allocate stack outside of (parallel) loops does have some sort of performance advantages, that it makes a shared stack which can be used by multiple packed func calls thus they don't need to create and allocate their own stacks.
So my point is, put stack allocation outside of for-loop is OK, we just need to take special treatments to those packed func in parallel for loops.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759479891
Possible way to resolve the issue:
- Introduce the packed_arg_alloca intrinsic that is only gauranteed to be valid for the specific packed func call
- Skip the lifting alloca step, and keep alloca always next to the func call
- Update LLVM codegen to insert alloca always to the beginning of the current function block
- Update StackVM and C codegen to support things accordingly
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759476975
related issue https://github.com/apache/tvm/issues/4387
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759474760
Thanks @zhuwenxi this is indeed an issue that we need to work to resolve
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-784223136
The function will looks like
```
fn myfunc() {
for i in range(10):
stack_tcode = @tir.packed_arg_alloca("arg_tcode", 8)
stack_value = @tir.packed_arg_alloca("arg_value", 8)
tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_1)
}
```
In the LLVM code generator, we want the compiled code to look like
```
fn myfunc() {
begin:
stack_tcode0 = alloca("arg_tcode", 8)
stack_value1 = alloca("arg_value", 8)
loop:
for i in range(10):
tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_1)
}
```
Actually, the main thing is that we could lift the semantics of the `tir.tvm_stack_alloca` to allow it to appear in most places, but allocation happens in the beginning of the function.
This can be done by jumping to the function begin basic block for insertion. https://github.com/apache/tvm/blob/81d9f11ab87dc3ef5fc906aa6ca23737885f7b27/src/target/llvm/codegen_llvm.h#L173
Note that this is a restriction of LLVM IR(alloca always happens in the beginning of the function). Additionally, we could certainly coleasce the stack of multiple calls, although LLVM could do that for us so we do not need to do so.
Note that in the case of parallel, a new function will be created for the parallel body, and WithFunctionEntry will get the alloca inserted at the beginning of that function. This is the benefit of delaying the alloca location move until the code gen point.
For the case of C generator, depending on the restriction of language, we might also need to create allocation in the beginning (e.g. create a init fragement stream of a function that is separated from the rest).
For the case of StackVM, we could need to have the ability to insert into the beginning of instruction stream that allocates, and stores the value into a few global heap which can be referred later.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-784226148
semantics of packed_arg_alloca:
- retrieve temp memory allocated during the function entry for packed argument calls, this memory is only alive within the current basic block.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-762573994
I'm happy to contribute a patch :) I will start from making some prototype code to do POC, and I'll keep you posted.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-757894841
And by digging into TVM source code, I believe I've already root cause this bug.
Short answer: the TIR generated for "@tvm.tir.call_packed()" is not thread-safe, thus causes a race condition in a multi-threads environment.
For detail explanations, please see my analysis here: https://discuss.tvm.apache.org/t/tensorize-tensorize-couldnt-work-properly-with-parallel-schedule/8752
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-785095353
Right, as a matter of fact, we should simply change the semantics of tvm_stack_alloca.S ince stack should always be thread local
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-784712542
The function looks pretty much like the fix I proposed. In my proposal "reallocate the stack in parallel for loop", the function looks like this:
<pre>
fn myfunc() {
stack_tcode = @tir.tvm_stack_alloca("arg_tcode", 8)
stack_value = @tir.tvm_stack_alloca("arg_value", 8)
for i in range(10):
stack_tcode = @tir.tvm_stack_alloca("arg_tcode", 8) // Do reallocation if current loop is parallel
stack_value = @tir.tvm_stack_alloca("arg_value", 8) // Do reallocation if current loop is parallel
tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_1)
}
</pre>
So from this point of view, is it true that the only difference between "packed_arg_alloca" and "tvm_stack_alloca" is the former one uses thread-local storage allocation?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-787769062
@tqchen Do you know the specific LLVM API to create a variable-length array with thread-local storage?
I'm starting from the LLVM backend, and I found existing code uses `builder_->CreateAlloca()` to do codegen for the `tvm_stack_alloc`instrinsic: https://github.com/apache/tvm/blob/main/src/target/llvm/codegen_cpu.cc#L892
To make the allocation thread-local, I searched over the llvm document but have no luck. The only TLS related thread I get from llvm forum is this: https://llvm.discourse.group/t/jit-execution-with-thread-local-global-variable/1081, which demos how to create a thread-local llvm::GlobalVariable.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-790260125
Thanks @zhuwenxi . StackVM does not support parallel execution. So we just need to make sure it works as originally intended. We might need to look into what is happening in the C backend. We should be able to just translate that into a function array
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-784712542
The function looks pretty much like the fix I proposed. In my proposal "reallocate the stack in parallel for loop", the function looks like this:
<pre>
fn myfunc() {
stack_tcode = @tir.tvm_stack_alloca("arg_tcode", 8)
stack_value = @tir.tvm_stack_alloca("arg_value", 8)
for i in range(10):
stack_tcode = @tir.tvm_stack_alloca("arg_tcode", 8) // Do reallocation if current loop is parallel
stack_value = @tir.tvm_stack_alloca("arg_value", 8) // Do reallocation if current loop is parallel
tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_1)
}
</pre>
So if I understand correctly, the only difference between "packed_arg_alloca" and "tvm_stack_alloca" is the former one uses thread-local storage allocation?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759976432
> Possible way to resolve the issue:
>
> * Introduce the packed_arg_alloca intrinsic that is only gauranteed to be valid for the specific packed func call
>
> * Skip the lifting alloca step, and keep alloca always next to the func call
> * Update LLVM codegen to insert alloca always to the beginning of the current function block
> * Update StackVM and C codegen to support things accordingly
If I understand correctly, you wanna introduce a special "packed_arg_alloca" tir and make sure all backends implement it? Correct me if I'm wrong :)
As I mentioned above, the root cause of this problem is the **tir** lowering for packed func in a parallel for is not thread-safe. So have you considered to fix it on tir level, utilizing existing TVM IRs? Thus no new tir type introduction and corresponding backend codegen implementations are required.
This is what I propose to fix the problem: re-allocation the stack next to the packed func call, but only in the parallel for loop.
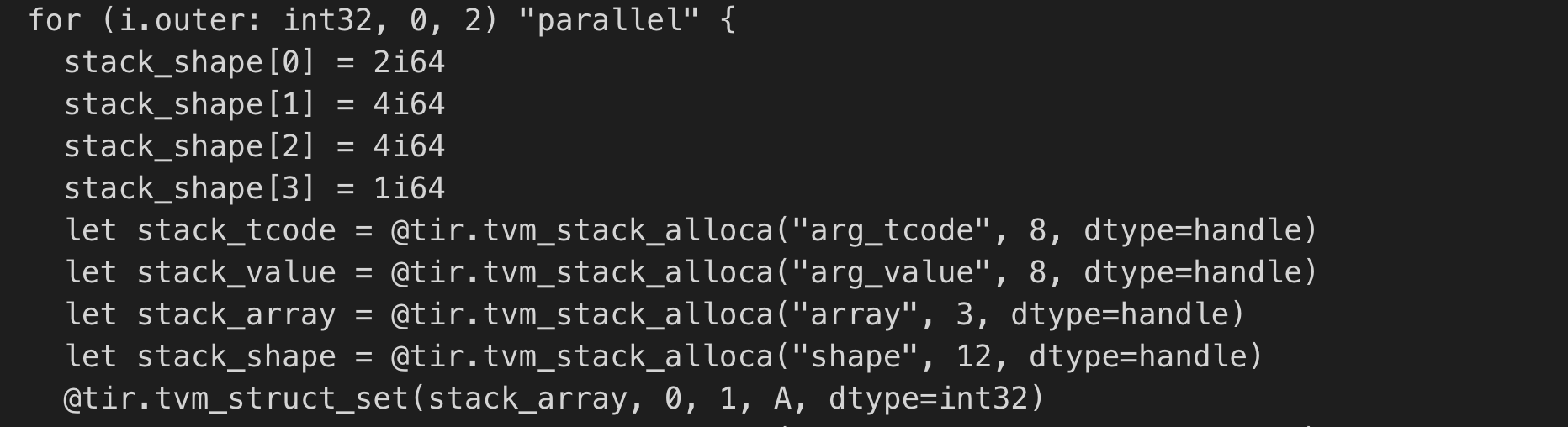
I've already tired the fix and confirmed this approach does work.
(I understand the re-allocation is against the SSA constrain, but it can be avoid easily, by making re-allocated stacks have distinct names, such as "stack_value_1", "stack_value_2")
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-817875927
The original issue was fixed by https://github.com/apache/tvm/pull/7619 thanks to @zhuwenxi !
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen closed issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen closed issue #7246:
URL: https://github.com/apache/tvm/issues/7246
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-788202176
I do not want to create variable length array `builder_->CreateAlloca()` is fine, as long as we do alloca at the beginning of the function using with WithFunctionEntry. Stack will always be allocated as thread local
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-780990510
> ping @zhuwenxi please let us know about the status and anything we can help
Sorry for the late response, @tqchen .
Haven't got time to look into this bug fix before Chinese New Year. I suppose I can start this work as soon as I come back to office.
Sorry again. :)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759474760
Thanks @zhuwenxi this is indeed an issue that we need to work to resolve. The main problem was the stack used for parallel packed call being raised into outside of the parallel for block during PackedCall lowering.
We will need to think about ways to improve the packed call handling to avoid lifting such allocation to outside of the parallel for block
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-760623570
@tqchen
Just curious, as far as I know nested parallel loops are not allowed in CPU backend: https://github.com/apache/tvm/blob/main/src/target/llvm/codegen_cpu.cc#L994, so I suppose you mean other backends such GPU?
Thread-local stack does make sense. Is it true that the `packed_arg_alloca` tir will only be generated, when current function is in a "parallel" for loop?
If so, there will be no performance issue. Otherwise, there could be a performance degradation in a pure single-thread schedule (no "parallel()" at all), because there will be multiple thread-local stacks, while they could have shared a single global stack in the first place.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759477485
also cc @junrushao1994 @ZihengJiang @vinx13
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-760623570
@tqchen
Just curious, as far as I know nested parallel loops are not allowed in CPU backend: https://github.com/apache/tvm/blob/main/src/target/llvm/codegen_cpu.cc#L994, so I suppose you mean other backends such GPU?
Thread-local stack does make sense. Is it true that the `packed_arg_alloca` tir will only be generated, when current function is in a "parallel" for loop?
If so, there will be no performance issue. Otherwise, there could be a performance degradation in a pure single-thread schedule (no "parallel()" at all), because there will be multiple thread-local stacks, while they could have shared a global solely stack in the first place.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-760623570
@tqchen
Just curious, nested parallel loops are not allowed in CPU backend: https://github.com/apache/tvm/blob/main/src/target/llvm/codegen_cpu.cc#L994 as far as I know, so I suppose you mean other backends such GPU?
Thread-local stack does make sense. Is it true that the `packed_arg_alloca` tir will only be generated, when current function is in a "parallel" for loop?
If so, there will be no performance issue. Otherwise, there could be a performance degradation in a pure single-thread schedule (no "parallel()" at all), because there will be multiple thread-local stacks, while they could have shared a global solely stack in the first place.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-784226148
Assuming we will use use `tir.tvm_stack_alloca`, here is the new semantics:
- Retrieve a constant-sized temp memory allocated during the function entry for packed argument calls.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] tqchen commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
tqchen commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-760961517
It will be generated in singele threaded as well. In that case the space will be allocated in the begining of the function, and i believe LLVM optimization should be able to collapse them via liveness analysis
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-762059838
Thanks for the explanation, @tqchen . May I know when will this bug be fixed? And please let me know if I can help.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-783849908
> Possible way to resolve the issue:
>
> * Introduce the packed_arg_alloca intrinsic that is only gauranteed to be valid for the specific packed func call
>
> * Skip the lifting alloca step, and keep alloca always next to the func call
> * Update LLVM codegen to insert alloca always to the beginning of the current function block
> * Update StackVM and C codegen to support things accordingly
@tqchen , I have a few questions about the implementation detail of your proposal. That is:
1. What is the detailed definition or semantic of `packed_arg_alloca` intrinsic, and how to guarantee it is valid only for the specific packed func call?
How does the generated tir look like? Something like:
`let stack_1 = @tir.packed_arg_alloca(...)`
`tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_1)`
`let stack_2 = @tir.packed_arg_alloca(...)`
`tir.tvm_call_packed_lowered("tvm.contrib.cblas.matmul", stack_2)`
2. How does "insert alloca always to the beginning of the current function block" work?
According to my understanding, stack is used to communicate parameters between caller and callee, so it is definitely required to be allocated & assigned parameters at the call-site. Allocating stack at the beginning of a function does not make sense according to my point of view. Could you further explain this a little bit more?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-791095757
Would you prefer me to fire a PR for llvm/stackvm fix, so you can start review first? Since it seems there are some issues in C backend.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi commented on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi commented on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759976432
> Possible way to resolve the issue:
>
> * Introduce the packed_arg_alloca intrinsic that is only gauranteed to be valid for the specific packed func call
>
> * Skip the lifting alloca step, and keep alloca always next to the func call
> * Update LLVM codegen to insert alloca always to the beginning of the current function block
> * Update StackVM and C codegen to support things accordingly
If I understand correctly, you wanna introduce a special "packed_arg_alloca" tir and make sure all backends implement it? Correct me if I'm wrong :)
As I mentioned above, the root cause of this problem is the **tir** lowering for packed func in a parallel for is not thread-safe. So have you considered to fix it on tir level, utilizing existing TVM IRs? Thus no new tir type introduction and corresponding backend codegen implementations are required.
This is what I propose to fix the problem: re-allocation the stack next to the packed func call, but only in the parallel for loop.

I've already tired the fix and confirmed this approach does work.
(I understand the re-allocation is against the SSA constrain, but it can be avoid easily, by make re-allocated stacks have distinct names, such as "stack_value_1", "stack_value_2")
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [tvm] zhuwenxi edited a comment on issue #7246: [BUG][Tensorize] race condition when using "tvm.tir.call_packed()" in a parallel schedule.
Posted by GitBox <gi...@apache.org>.
zhuwenxi edited a comment on issue #7246:
URL: https://github.com/apache/tvm/issues/7246#issuecomment-759976432
> Possible way to resolve the issue:
>
> * Introduce the packed_arg_alloca intrinsic that is only gauranteed to be valid for the specific packed func call
>
> * Skip the lifting alloca step, and keep alloca always next to the func call
> * Update LLVM codegen to insert alloca always to the beginning of the current function block
> * Update StackVM and C codegen to support things accordingly
If I understand correctly, you wanna introduce a special "packed_arg_alloca" tir and make sure all backends implement it? Correct me if I'm wrong :)
As I mentioned above, the root cause of this problem is the **tir** lowering for packed func in a parallel for is not thread-safe. So have you considered to fix it on tir level, utilizing existing TVM IRs? Thus no new tir type introduction and corresponding backend codegen implementations are required.
This is what I propose to fix the problem: re-allocation the stack next to the packed func call, but only in the parallel for loop.

I've already tried this fix and confirmed this approach does work.
(I understand the re-allocation is against the SSA constrain, but it can be avoid easily, by making re-allocated stacks have distinct names, such as "stack_value_1", "stack_value_2")
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org