You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/09/27 13:05:27 UTC
[GitHub] [iceberg] zhangminglei opened a new pull request #3186: Spark: read compound constant type exception (#3139)
zhangminglei opened a new pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186
Detailed information can be viewed #3139
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745324162
##########
File path: spark/v3.0/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,39 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
Review comment:
I will only make this pr to spark3.2
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r716689327
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
Review comment:
actually, we can use the original map instead.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] lirui-apache commented on a change in pull request #3186: Spark: read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
lirui-apache commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r716679524
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
Review comment:
Why do we need a new map here?
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ private final Map<Integer, Object> moreConstants = new HashMap<>();
+
+ protected Map<Integer, Object> visitCompoundTypesByDFS(Types.NestedField nestedField, Map<Integer, ?> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField :childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i =0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ moreConstants.put(nestedField.fieldId(), new GenericInternalRow(objects));
Review comment:
Why not just reuse `idToConstant`
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
Review comment:
I don't think we need this. `visitCompoundTypesByDFS` skips primitive types anyway.
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/RowDataReader.java
##########
@@ -78,6 +89,81 @@
return deletes.filter(open(task, requiredSchema, idToConstant)).iterator();
}
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
Review comment:
I think we can extract this into some util method. No need to have separate implementations for vectorized/non-vectorized readers.
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ private final Map<Integer, Object> moreConstants = new HashMap<>();
+
+ protected Map<Integer, Object> visitCompoundTypesByDFS(Types.NestedField nestedField, Map<Integer, ?> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField :childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i =0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ moreConstants.put(nestedField.fieldId(), new GenericInternalRow(objects));
+ }
+ break;
+ case MAP:
+ int keyId = nestedField.type().asMapType().keyId();
+ int valueId = nestedField.type().asMapType().valueId();
+ visitCompoundTypesByDFS(nestedField, idToConstant);
Review comment:
Will this lead to infinite recursion?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r748883894
##########
File path: spark/v3.2/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
public ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
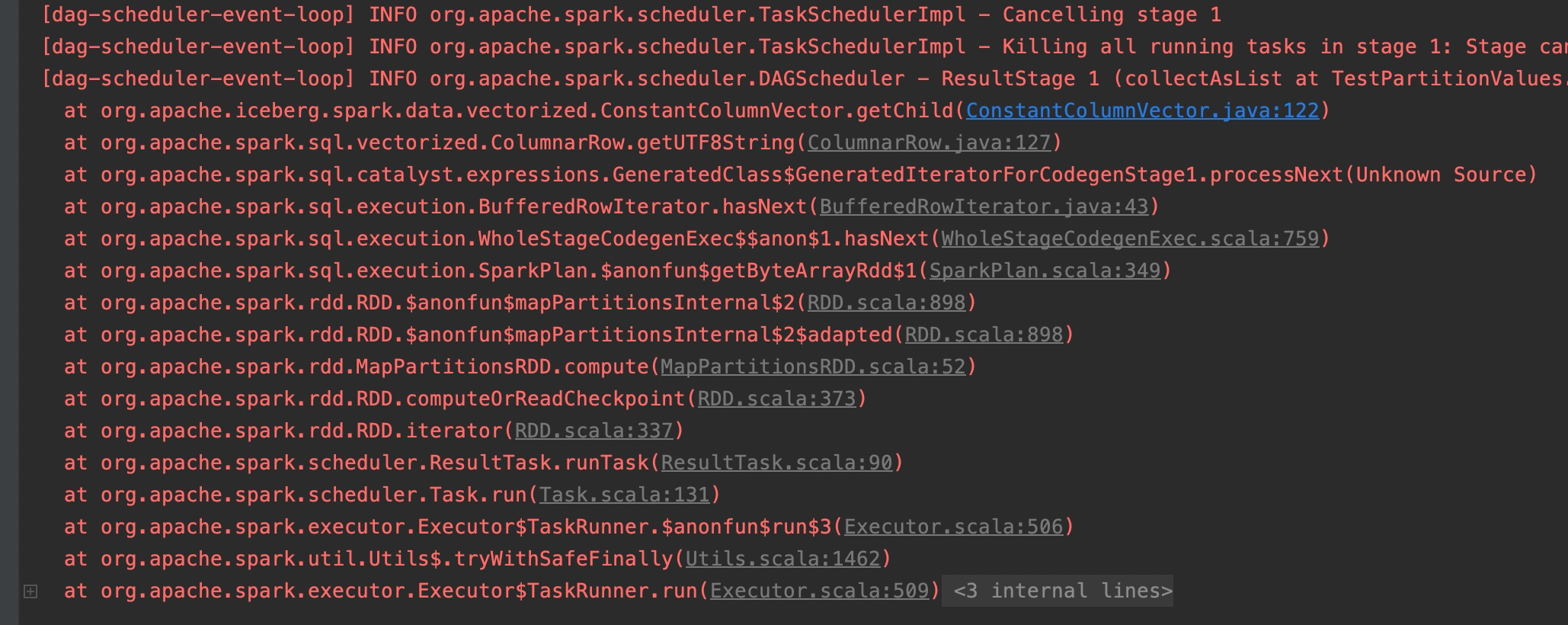
It looks like the approach in this PR is to use existing constant handling to fix nested column construction. I'm not sure that this is the right approach. There isn't anything specific to ORC here, so I'm not convinced that the ORC readers handle nested constant values correctly. Avoiding a problem is an okay solution as long as we're confident that it is always avoided.
At a minimum, I think we should have tests for partitioning by nested fields in structs that are not constants and would not get created by `findMoreCompoundConstants`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745332266
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
protected ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
I think the code can be removed for now, because previous the ORC constant reading generates a StructReader that needs to be retrieved from the child node, there should be no such problem now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-940990282
I did an end to end test for this change. And spark sql can show the correct value.
```
CREATE TABLE table13 (col struct<field:string>)
USING iceberg
PARTITIONED BY (col.field)
TBLPROPERTIES ('write.format.default'='orc')
insert into table13 select named_struct('col1','20211012');
select * from table13;
```
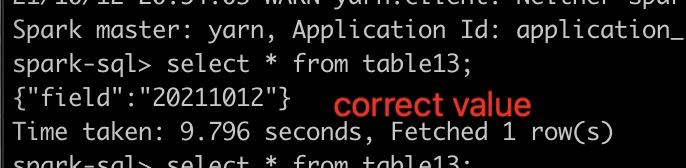

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-956929157
Running CI.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745374480
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
protected ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
```
ColumnarRow #
@Override
public UTF8String getUTF8String(int ordinal) {
return data.getChild(ordinal).getUTF8String(rowId);
}
```
To get a column value in a row use `getChild` when performing spark vectorization reads to fetch each column element.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r731441502
##########
File path: spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -418,17 +418,19 @@ public void testPartitionedByNestedString() throws Exception {
// write into iceberg
sourceDF.write()
- .format("iceberg")
- .mode(SaveMode.Append)
- .save(baseLocation);
+ .format("iceberg")
+ .option(WRITE_FORMAT, format)
+ .mode(SaveMode.Append)
+ .save(baseLocation);
// verify
List<Row> actual = spark.read()
- .format("iceberg")
- .option(SparkReadOptions.VECTORIZATION_ENABLED, String.valueOf(vectorized))
- .load(baseLocation)
- .collectAsList();
+ .format("iceberg")
+ .option(SparkReadOptions.VECTORIZATION_ENABLED, String.valueOf(vectorized))
+ .load(baseLocation)
+ .collectAsList();
Review comment:
Thank you for review this and I've revert that code. 👍
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r717525854
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/RowDataReader.java
##########
@@ -78,6 +89,81 @@
return deletes.filter(open(task, requiredSchema, idToConstant)).iterator();
}
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
Review comment:
will change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r717189093
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ private final Map<Integer, Object> moreConstants = new HashMap<>();
+
+ protected Map<Integer, Object> visitCompoundTypesByDFS(Types.NestedField nestedField, Map<Integer, ?> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField :childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i =0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ moreConstants.put(nestedField.fieldId(), new GenericInternalRow(objects));
Review comment:
will change. thanks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-972441018
@rdblue Could you take a look again when you have a chance ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-939534238
Running CI. Can you update the summary/description to note that this fixes a bug with ORC?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r725961379
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +199,71 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i = 0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ idToConstant.put(nestedField.fieldId(), new GenericInternalRow(objects));
+ }
+ break;
+ case MAP:
+ int keyId = nestedField.type().asMapType().keyId();
+ int valueId = nestedField.type().asMapType().valueId();
+ Types.NestedField nestedKeyField = nestedField.type().asMapType().field(keyId);
+ Types.NestedField nestedValueField = nestedField.type().asMapType().field(valueId);
+ List<Integer> kvFieldIds = new ArrayList<>();
+ kvFieldIds.add(nestedKeyField.fieldId());
+ kvFieldIds.add(nestedValueField.fieldId());
+ visitCompoundTypesByDFS(nestedKeyField, idToConstant);
+ visitCompoundTypesByDFS(nestedValueField, idToConstant);
+ if (idToConstant.keySet().containsAll(kvFieldIds)) {
+ Object keyValue = idToConstant.get(keyId);
+ Object valueValue = idToConstant.get(valueId);
+ GenericArrayData keys = new GenericArrayData(new Object[]{keyValue});
+ GenericArrayData values = new GenericArrayData(new Object[]{valueValue});
+ idToConstant.put(keyId, keys);
+ idToConstant.put(valueId, values);
+ }
+ break;
+ case LIST:
+ List<Types.NestedField> childFieldsInList = nestedField.type().asListType().fields();
+ List<Integer> childIDsList = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInList) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childIDsList.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childIDsList)) {
+ Object[] objects = new Object[childIDsList.size()];
+ for (int i = 0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childIDsList.get(i));
+ }
+ idToConstant.put(nestedField.fieldId(), new GenericArrayData(objects));
Review comment:
I do a test and we can not get the element in the array by index.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r725956770
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +199,71 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i = 0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ idToConstant.put(nestedField.fieldId(), new GenericInternalRow(objects));
+ }
+ break;
+ case MAP:
+ int keyId = nestedField.type().asMapType().keyId();
+ int valueId = nestedField.type().asMapType().valueId();
+ Types.NestedField nestedKeyField = nestedField.type().asMapType().field(keyId);
+ Types.NestedField nestedValueField = nestedField.type().asMapType().field(valueId);
+ List<Integer> kvFieldIds = new ArrayList<>();
+ kvFieldIds.add(nestedKeyField.fieldId());
+ kvFieldIds.add(nestedValueField.fieldId());
+ visitCompoundTypesByDFS(nestedKeyField, idToConstant);
+ visitCompoundTypesByDFS(nestedValueField, idToConstant);
+ if (idToConstant.keySet().containsAll(kvFieldIds)) {
+ Object keyValue = idToConstant.get(keyId);
+ Object valueValue = idToConstant.get(valueId);
+ GenericArrayData keys = new GenericArrayData(new Object[]{keyValue});
+ GenericArrayData values = new GenericArrayData(new Object[]{valueValue});
+ idToConstant.put(keyId, keys);
+ idToConstant.put(valueId, values);
Review comment:
Yes. I've fix it done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-957145086
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-956929157
Running CI.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745258347
##########
File path: spark/v2.4/spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -402,14 +402,13 @@ public void testPartitionedByNestedString() throws Exception {
// input data frame
StructField[] structFields = {
- new StructField("struct",
- DataTypes.createStructType(
- new StructField[] {
- new StructField("string", DataTypes.StringType, false, Metadata.empty())
- }
- ),
- false, Metadata.empty()
- )
+ new StructField("col1",
+ DataTypes.createStructType(
+ new StructField[] {
+ new StructField("f1", DataTypes.StringType, false, Metadata.empty())
+ }
+ ), false, Metadata.empty()
+ )
Review comment:
Yes. I will change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r748611061
##########
File path: spark/v3.2/spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -392,8 +393,7 @@ public void testPartitionedByNestedString() throws Exception {
// schema and partition spec
Schema nestedSchema = new Schema(
Types.NestedField.required(1, "struct",
- Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get()))
- )
+ Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get())))
Review comment:
Please revert the non-functional changes in this file.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-967118009
@rdblue I updated the code again. Could you please take a look when you have a chance ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r749096922
##########
File path: spark/v3.2/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
public ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
> There isn't anything specific to ORC here,so I'm not convinced that the ORC readers handle nested constant values correctly
Ans: The change itself is not specific to ORC here, but ORC is currently used that way, and Parquet's vectorization read do not use this, and this is a general practice, not to ORC itself.
> I'm not sure that this is the right approach.
Ans: When doing the vectorization read for orc, ```VectorizedSparkOrcReaders#StructConverter```use ```idToConstant``` and will convert constant values to ```ConstantColumnVector```, but```ConstantColumnVector``` cannot represent a Struct Type currently. So I need a struct constant.
According to Spark's API, a ```ColumnVector``` that represents a struct must implement the ```getChild``` method.
https://github.com/apache/spark/blob/v3.2.0/sql/catalyst/src/main/java/org/apache/spark/sql/vectorized/ColumnVector.java#L219
https://github.com/apache/spark/blob/v3.2.0/sql/catalyst/src/main/java/org/apache/spark/sql/vectorized/ColumnVector.java#L302
Since ```getChild``` returns a ```ColumnVector```, and each child in a struct type is a constant also, so it can return a ```ConstantColumnVector``` I think.
Besides , I will add more tests.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r741526482
##########
File path: spark/v2.4/spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -402,14 +402,13 @@ public void testPartitionedByNestedString() throws Exception {
// input data frame
StructField[] structFields = {
- new StructField("struct",
- DataTypes.createStructType(
- new StructField[] {
- new StructField("string", DataTypes.StringType, false, Metadata.empty())
- }
- ),
- false, Metadata.empty()
- )
+ new StructField("col1",
+ DataTypes.createStructType(
+ new StructField[] {
+ new StructField("f1", DataTypes.StringType, false, Metadata.empty())
+ }
+ ), false, Metadata.empty()
+ )
Review comment:
Nearly all of the changes in this file are to formatting or names. Can you remove any changes that are not strictly necessary for what you're trying to fix?
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,40 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
Review comment:
Looks like this is creating any struct that it can when all of the struct's children are present in the constants map.
I think this would need to be refactored so that the method is clear about what it is doing. Simply "visit" doesn't really describe what is going on here. It is updating the constants map.
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,40 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
Review comment:
I'm not sure that this should alter the incoming map. It would be better to build a new constants map with the extra fields.
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,40 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
Review comment:
In Iceberg, we separate schema traversal logic from other logic using visitors. I think that you should use a type visitor to implement this rather than traversing a type tree and doing some task in the same recursive function.
##########
File path: spark/v3.0/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,39 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
Review comment:
Can you please update just one version of Spark and then we'll port the changes to the other versions in separate PRs? That way, each PR is smaller and we don't have to review identical code multiple times.
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
protected ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
How are these changes related to ORC?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] lirui-apache commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
lirui-apache commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r725845244
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +199,71 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i = 0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ idToConstant.put(nestedField.fieldId(), new GenericInternalRow(objects));
+ }
+ break;
+ case MAP:
+ int keyId = nestedField.type().asMapType().keyId();
+ int valueId = nestedField.type().asMapType().valueId();
+ Types.NestedField nestedKeyField = nestedField.type().asMapType().field(keyId);
+ Types.NestedField nestedValueField = nestedField.type().asMapType().field(valueId);
+ List<Integer> kvFieldIds = new ArrayList<>();
+ kvFieldIds.add(nestedKeyField.fieldId());
+ kvFieldIds.add(nestedValueField.fieldId());
+ visitCompoundTypesByDFS(nestedKeyField, idToConstant);
+ visitCompoundTypesByDFS(nestedValueField, idToConstant);
+ if (idToConstant.keySet().containsAll(kvFieldIds)) {
+ Object keyValue = idToConstant.get(keyId);
+ Object valueValue = idToConstant.get(valueId);
+ GenericArrayData keys = new GenericArrayData(new Object[]{keyValue});
+ GenericArrayData values = new GenericArrayData(new Object[]{valueValue});
+ idToConstant.put(keyId, keys);
+ idToConstant.put(valueId, values);
+ }
+ break;
+ case LIST:
+ List<Types.NestedField> childFieldsInList = nestedField.type().asListType().fields();
+ List<Integer> childIDsList = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInList) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childIDsList.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childIDsList)) {
+ Object[] objects = new Object[childIDsList.size()];
+ for (int i = 0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childIDsList.get(i));
+ }
+ idToConstant.put(nestedField.fieldId(), new GenericArrayData(objects));
Review comment:
I guess we can't handle array type because we don't know the length of the array
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745332886
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,40 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
Review comment:
This is a good idea for refactoring, thanks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r731293338
##########
File path: spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -418,17 +418,19 @@ public void testPartitionedByNestedString() throws Exception {
// write into iceberg
sourceDF.write()
- .format("iceberg")
- .mode(SaveMode.Append)
- .save(baseLocation);
+ .format("iceberg")
+ .option(WRITE_FORMAT, format)
+ .mode(SaveMode.Append)
+ .save(baseLocation);
// verify
List<Row> actual = spark.read()
- .format("iceberg")
- .option(SparkReadOptions.VECTORIZATION_ENABLED, String.valueOf(vectorized))
- .load(baseLocation)
- .collectAsList();
+ .format("iceberg")
+ .option(SparkReadOptions.VECTORIZATION_ENABLED, String.valueOf(vectorized))
+ .load(baseLocation)
+ .collectAsList();
Review comment:
Nit: Can you revert the formatting changes that are unrelated / unchanged lines of code?
Added unnecessary line changes in the patch make it harder for people that support forks to continue to do so. Thank you 👍
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] lirui-apache commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
lirui-apache commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r725798841
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +199,71 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i = 0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ idToConstant.put(nestedField.fieldId(), new GenericInternalRow(objects));
+ }
+ break;
+ case MAP:
+ int keyId = nestedField.type().asMapType().keyId();
+ int valueId = nestedField.type().asMapType().valueId();
+ Types.NestedField nestedKeyField = nestedField.type().asMapType().field(keyId);
+ Types.NestedField nestedValueField = nestedField.type().asMapType().field(valueId);
+ List<Integer> kvFieldIds = new ArrayList<>();
+ kvFieldIds.add(nestedKeyField.fieldId());
+ kvFieldIds.add(nestedValueField.fieldId());
+ visitCompoundTypesByDFS(nestedKeyField, idToConstant);
+ visitCompoundTypesByDFS(nestedValueField, idToConstant);
+ if (idToConstant.keySet().containsAll(kvFieldIds)) {
+ Object keyValue = idToConstant.get(keyId);
+ Object valueValue = idToConstant.get(valueId);
+ GenericArrayData keys = new GenericArrayData(new Object[]{keyValue});
+ GenericArrayData values = new GenericArrayData(new Object[]{valueValue});
+ idToConstant.put(keyId, keys);
+ idToConstant.put(valueId, values);
Review comment:
I think we need a `MapData` to represent a constant map value, no?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei edited a comment on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei edited a comment on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-940990282
I did an end to end test for this change. And spark sql can show the correct value. @rdblue @openinx Any other comments ?
```
CREATE TABLE table13 (col struct<field:string>)
USING iceberg
PARTITIONED BY (col.field)
TBLPROPERTIES ('write.format.default'='orc')
insert into table13 select named_struct('col1','20211012');
select * from table13;
```


--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-953431499
Hi, @rdblue @openinx , Could you take a look at the code when you have a moment ?
Thanks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r741528577
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,40 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
Review comment:
In Iceberg, we separate schema traversal logic from other logic using visitors. I think that you should use a type visitor to implement this rather than traversing a type tree and doing some task in the same recursive function.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r717381879
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ private final Map<Integer, Object> moreConstants = new HashMap<>();
+
+ protected Map<Integer, Object> visitCompoundTypesByDFS(Types.NestedField nestedField, Map<Integer, ?> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField :childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i =0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ moreConstants.put(nestedField.fieldId(), new GenericInternalRow(objects));
+ }
+ break;
+ case MAP:
+ int keyId = nestedField.type().asMapType().keyId();
+ int valueId = nestedField.type().asMapType().valueId();
+ visitCompoundTypesByDFS(nestedField, idToConstant);
Review comment:
Fixed done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-939686414
@rdblue Thanks, I've done it and fix the check style as well.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r741528067
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,40 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField : childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
Review comment:
Looks like this is creating any struct that it can when all of the struct's children are present in the constants map.
I think this would need to be refactored so that the method is clear about what it is doing. Simply "visit" doesn't really describe what is going on here. It is updating the constants map.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r741528220
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,40 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField : columns) {
+ visitCompoundTypesByDFS(nestedField, (Map<Integer, Object>) idToConstant);
+ }
+ }
+
+ protected void visitCompoundTypesByDFS(
+ Types.NestedField nestedField,
+ Map<Integer, Object> idToConstant) {
Review comment:
I'm not sure that this should alter the incoming map. It would be better to build a new constants map with the extra fields.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-956929157
Running CI.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745374480
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
protected ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
This change is made so that vectorization mode can read constant struct.
The mainly code is as follow
```
ColumnarRow #
@Override
public UTF8String getUTF8String(int ordinal) {
return data.getChild(ordinal).getUTF8String(rowId);
}
```
To get a column value in a row use `getChild` when performing spark vectorization reads to fetch each column element.

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745374480
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
protected ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
This change is made so that vectorization mode can read constant struct.
The mainly code is as follow
```
ColumnarRow #
@Override
public UTF8String getUTF8String(int ordinal) {
return data.getChild(ordinal).getUTF8String(rowId);
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r749030834
##########
File path: spark/v3.2/spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -392,8 +393,7 @@ public void testPartitionedByNestedString() throws Exception {
// schema and partition spec
Schema nestedSchema = new Schema(
Types.NestedField.required(1, "struct",
- Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get()))
- )
+ Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get())))
Review comment:
Please see the latest code ~
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r716696946
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
Review comment:
you are right. i add this for a easy way to view. will remove this soon.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r748671010
##########
File path: spark/v3.2/spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -392,8 +393,7 @@ public void testPartitionedByNestedString() throws Exception {
// schema and partition spec
Schema nestedSchema = new Schema(
Types.NestedField.required(1, "struct",
- Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get()))
- )
+ Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get())))
Review comment:
Sorry, I miss the code specification, now it has been updated, Could you have a look again ? Thank you.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-945710063
Hi @rdblue , Could you please take a look on this ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r741529125
##########
File path: spark/v3.0/spark/src/main/java/org/apache/iceberg/spark/source/BaseDataReader.java
##########
@@ -196,4 +198,39 @@ protected static Object convertConstant(Type type, Object value) {
}
return value;
}
+
+ protected void findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
Review comment:
Can you please update just one version of Spark and then we'll port the changes to the other versions in separate PRs? That way, each PR is smaller and we don't have to review identical code multiple times.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-957145086
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-957145086
@rdblue I will port these changes to spark2.4/3.0/3.2 respectively.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r717189093
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ private final Map<Integer, Object> moreConstants = new HashMap<>();
+
+ protected Map<Integer, Object> visitCompoundTypesByDFS(Types.NestedField nestedField, Map<Integer, ?> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField :childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i =0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ moreConstants.put(nestedField.fieldId(), new GenericInternalRow(objects));
Review comment:
will change. thanks.
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/BatchDataReader.java
##########
@@ -59,6 +66,80 @@
this.batchSize = size;
}
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
+ Map<Integer, Object> compoundTypeConstants = new HashMap<>();
+ List<Types.NestedField> columns = tableSchema.columns();
+
+ for (Types.NestedField nestedField: columns) {
+ compoundTypeConstants = visitCompoundTypesByDFS(nestedField, idToConstant);
+ }
+ compoundTypeConstants.putAll(idToConstant);
+ return compoundTypeConstants;
+ }
+
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ private final Map<Integer, Object> moreConstants = new HashMap<>();
+
+ protected Map<Integer, Object> visitCompoundTypesByDFS(Types.NestedField nestedField, Map<Integer, ?> idToConstant) {
+ switch (nestedField.type().typeId()) {
+ case STRUCT:
+ List<Types.NestedField> childFieldsInStruct = nestedField.type().asStructType().fields();
+ List<Integer> childFieldID = new ArrayList<>();
+ for (Types.NestedField childField :childFieldsInStruct) {
+ visitCompoundTypesByDFS(childField, idToConstant);
+ childFieldID.add(childField.fieldId());
+ }
+ if (idToConstant.keySet().containsAll(childFieldID)) {
+ Object[] objects = new Object[childFieldID.size()];
+ for (int i =0; i < objects.length; i++) {
+ objects[i] = idToConstant.get(childFieldID.get(i));
+ }
+ moreConstants.put(nestedField.fieldId(), new GenericInternalRow(objects));
+ }
+ break;
+ case MAP:
+ int keyId = nestedField.type().asMapType().keyId();
+ int valueId = nestedField.type().asMapType().valueId();
+ visitCompoundTypesByDFS(nestedField, idToConstant);
Review comment:
Fixed done.
##########
File path: spark/src/main/java/org/apache/iceberg/spark/source/RowDataReader.java
##########
@@ -78,6 +89,81 @@
return deletes.filter(open(task, requiredSchema, idToConstant)).iterator();
}
+ protected boolean containsCompoundType(Schema tableSchema) {
+ List<Types.NestedField> columns = tableSchema.columns();
+ for(Types.NestedField nestedField: columns) {
+ if (nestedField.type().isStructType() || nestedField.type().isMapType() || nestedField.type().isListType()) {
+ return true;
+ }
+ }
+ return false;
+ }
+
+ protected Map<Integer, ?> findMoreCompoundConstants(Schema tableSchema, Map<Integer, ?> idToConstant) {
Review comment:
will change.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#issuecomment-957703156
Hi, @rdblue Could you please review that again ? Thanks.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r741530230
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
protected ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
How are these changes related to ORC?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r741526482
##########
File path: spark/v2.4/spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -402,14 +402,13 @@ public void testPartitionedByNestedString() throws Exception {
// input data frame
StructField[] structFields = {
- new StructField("struct",
- DataTypes.createStructType(
- new StructField[] {
- new StructField("string", DataTypes.StringType, false, Metadata.empty())
- }
- ),
- false, Metadata.empty()
- )
+ new StructField("col1",
+ DataTypes.createStructType(
+ new StructField[] {
+ new StructField("f1", DataTypes.StringType, false, Metadata.empty())
+ }
+ ), false, Metadata.empty()
+ )
Review comment:
Nearly all of the changes in this file are to formatting or names. Can you remove any changes that are not strictly necessary for what you're trying to fix?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] rdblue commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
rdblue commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r748903159
##########
File path: spark/v3.2/spark/src/test/java/org/apache/iceberg/spark/source/TestPartitionValues.java
##########
@@ -392,8 +393,7 @@ public void testPartitionedByNestedString() throws Exception {
// schema and partition spec
Schema nestedSchema = new Schema(
Types.NestedField.required(1, "struct",
- Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get()))
- )
+ Types.StructType.of(Types.NestedField.required(2, "string", Types.StringType.get())))
Review comment:
Looks like this is still a problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] zhangminglei commented on a change in pull request #3186: Spark: vectorized/non-vectorized read compound constant type exception (#3139)
Posted by GitBox <gi...@apache.org>.
zhangminglei commented on a change in pull request #3186:
URL: https://github.com/apache/iceberg/pull/3186#discussion_r745332266
##########
File path: spark/v2.4/spark/src/main/java/org/apache/iceberg/spark/data/vectorized/ConstantColumnVector.java
##########
@@ -119,6 +122,8 @@ public UTF8String getUTF8String(int rowId) {
@Override
protected ColumnVector getChild(int ordinal) {
- throw new UnsupportedOperationException("ConstantColumnVector only supports primitives");
+ DataType sparkType = ((StructType) type).fields()[ordinal].dataType();
+ Type childType = SparkSchemaUtil.convert(sparkType);
+ return new ConstantColumnVector(childType, batchSize, ((InternalRow) constant).get(ordinal, sparkType));
Review comment:
I think the code can be removed for now, because previous the ORC constant reading generates a StructReader that needs to be retrieved from the child node, there should be no such problem now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org