You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@druid.apache.org by GitBox <gi...@apache.org> on 2021/04/01 11:57:39 UTC
[GitHub] [druid] zhangyouxun opened a new issue #11061: How to improving ingestion performance
zhangyouxun opened a new issue #11061:
URL: https://github.com/apache/druid/issues/11061
peon config :
-Xms10g -Xmx10g -XX:+UseG1GC -XX:MaxDirectMemorySize=10g -Duser.timezone=UTC -Dfile.encoding=UTF-8 -XX:+ExitOnOutOfMemoryError -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
druid.peon.defaultSegmentWriteOutMediumFactory.type=offHeapMemory
druid.indexer.fork.property.druid.processing.numThreads=2
spec:
"tuningConfig": {
"maxRowsInMemory": 1000000,
"maxBytesInMemory": 0,
"maxRowsPerSegment": 5000000
}
row size: 300bytes
peon ingest speed: 50k/s
taskCount:30
is there any wrong param leading low ingestion?
How to improve the speed of ingestion?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] zhangyouxun commented on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
zhangyouxun commented on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-812331476
> > the num of partitions is 270.
>
> It's better to check whether your messages are evenly distributed among these partitions. If not, some peons will process more messages than others, there might be some lags for these peons.
>
> > The maxBytesInMemory is about 300Mb, is it not make full use of heap?
>
> In your spec, this parameter is 0, which will be default to 1/6 of JVM max heap size during running. Persistence happens when either `maxRowsInMemory` or `maxBytesInMemory` is reached. But persistence is running in a separated thread, I don't think these two affect the ingestion speed.
>
> For Kafka, generally speaking, there're 2 parameters which I usually highly recommend to use to improve throughput
>
> 1. set `compression.type` to lz4 at producer side. This would greatly reduce network traffic without introducing extra CPU usage at producer and consumer side.
> 2. set `fetch.min.bytes` to a large number(such as 4096) to tell brokers return more messages in a single fetch response to a consumer . This would greatly reduce network requests/responses between consumers and brokers.
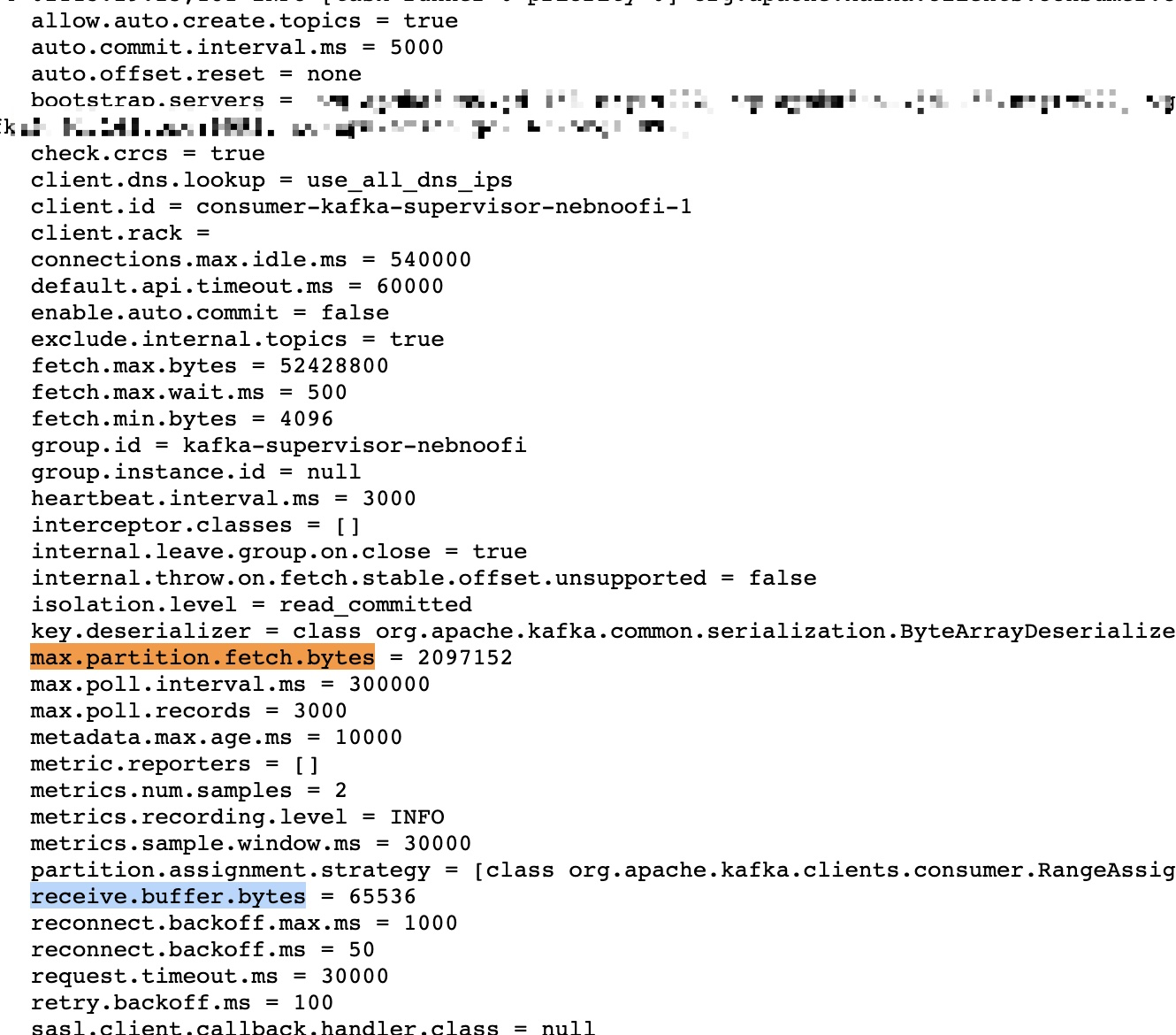
还有其他参数可以优化吗?
is there any parameter needed adjust?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] zhangyouxun commented on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
zhangyouxun commented on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-811954109
> Your task count is 30, does that mean there're 30 partitions of your topic ? And is the ingestion speed 5K/s of per peon ? Even it's 5K/s per peon, it's not a very high speed that it needs 10G heap size for each peon. 4G is enough in our clusters to handle messages at much higher speed.
>
> Since streaming ingestion speed is more relevant to streaming middleware, tuning producer and consumer may help. Are you using Kafka ? And what parameters you have adopted to configure Kafka producers and consumers ?
the num of partitions is 270.
The maxBytesInMemory is about 300Mb, is it not make full use of heap?
we use Kafka
max.poll.records = 500
max.partition.fetch.bytes = 1048576
fetch.max.bytes = 52428800
fetch.max.wait.ms = 500
fetch.min.bytes = 1
metadata.max.age.ms = 10000
which parameter needs to be adjusted?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] zhangyouxun edited a comment on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
zhangyouxun edited a comment on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-812302787
> set compression.type
After verification, modify this parameter to increase the consumption speed to 7.5k/s.
Use 10G heap, how to make full use of memory to increase speed?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] FrankChen021 commented on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
FrankChen021 commented on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-811988987
> the num of partitions is 270.
It's better to check whether your messages are evenly distributed among these partitions. If not, some peons will process more messages than others, there might be some lags for these peons.
> The maxBytesInMemory is about 300Mb, is it not make full use of heap?
In your spec, this parameter is 0, which will be default to 1/6 of JVM max heap size during running. Persistence happens when either `maxRowsInMemory` or `maxBytesInMemory` is reached. But persistence is running in a separated thread, I don't think these two affect the ingestion speed.
For Kafka, generally speaking, there're 2 parameters which I usually highly recommend to use to improve throughput
1. set `compression.type` to lz4 at producer side. This would greatly reduce network traffic without introducing extra CPU usage at producer and consumer side.
2. set `fetch.min.bytes` to a large number(such as 4096) to tell brokers return more messages in a single fetch response to a consumer . This would greatly reduce network requests/responses between consumers and brokers.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] FrankChen021 commented on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
FrankChen021 commented on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-812470398
> is there any parameter needed adjust?
I have no other advices for you on other parameters since most of them are not relevant to throughput.
Because there're 270 partitions of your topic, have you checked that network bandwidth among producers/kafka brokers/consumers is enough ? And if it's enough, I think you could increase task count to improve parallelism. But considering your heap size configuration, it's better to lower down it before you increase the task count.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] FrankChen021 commented on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
FrankChen021 commented on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-811912104
Your task count is 30, does that mean there're 30 partitions of your topic ? And is the ingestion speed 5K/s of per peon ? Even it's 5K/s per peon, it's not a very high speed that it needs 10G heap size for each peon. 4G is enough in our clusters to handle messages at much higher speed.
Since streaming ingestion speed is more relevant to streaming middleware, tuning producer and consumer may help. Are you using Kafka ? And what parameters you have adopted to configure Kafka producers and consumers ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] FrankChen021 commented on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
FrankChen021 commented on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-812467720
> After verification, modify this parameter to increase the consumption speed to 7.5k/s.
Glad to see that it helps.
> Use 10G heap, how to make full use of memory to increase speed?
You could try to increase `maxRowsInMemory`, `maxBytesInMemory` `maxRowsPerSegment`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] zhangyouxun commented on issue #11061: How to improving ingestion performance
Posted by GitBox <gi...@apache.org>.
zhangyouxun commented on issue #11061:
URL: https://github.com/apache/druid/issues/11061#issuecomment-812302787
> set compression.type
After verification, modify this parameter to increase the consumption speed to 7.5k/s.
Use 10G heap, how to make full use of memory to increase speed?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org