You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@bookkeeper.apache.org by GitBox <gi...@apache.org> on 2021/06/03 18:34:43 UTC
[GitHub] [bookkeeper] RaulGracia opened a new issue #2728: Entry Log GC may get blocked when using entryLogPerLedgerEnabled option
RaulGracia opened a new issue #2728:
URL: https://github.com/apache/bookkeeper/issues/2728
**BUG REPORT**
***Describe the bug***
_Summary_: We use `entryLogPerLedgerEnabled:"true"` option in environments that have SSDs/NVMes to exploit drive parallelism and it provides significant improvements (as suggested in documentation). However, under high throughput workloads (1GBps, 6 Bookies, 3 replicas), our experiments showed us that there is a consistent problem with this option in which, at some point, makes the ledger volume to run out of storage space. Concretely, at some point one entry log file does not get rotated (i.e., `flushRotatedLogs()` method does not get invoked in `EntryLogManagerForEntryLogPerLedger`) while the system continues writing data and generating more entry log files. When this happens, and given that the removal of unnecessary (truncated) entry logs is sequential by entry log id, the GC Thread cannot continue progressing deleting entry logs. This eventually leads to the ledger volume to fill up. This problem was first detected on Bookkeeper 4.11.1 but we also reproduced it in Bookkeep
er 4.14.0.
Next, we expose a more detailed explanation with real logs of the issue. Everything works well for some time (minutes or hours, depending on the load) until we detect some ledger activity like this:
```
(ENTRY LOG ID 1261)
λ grep "Created new entry log file\|Synced" bookkeeper-server-0.log | grep "1261"
2021-05-09 14:35:25,364 - INFO - [pool-4-thread-1:EntryLoggerAllocator@181] - Created new entry log file /bk/ledgers/current/4ed.log for logId 1261.
2021-05-09 14:37:32,800 - INFO - [SyncThread-14-1:EntryLogManagerForEntryLogPerLedger@693] - Synced entry logger 1261 to disk.
(ENTRY LOG ID 1262)
λ grep "Created new entry log file\|Synced" bookkeeper-server-0.log | grep "1262"
2021-05-09 14:35:26,152 - INFO - [pool-4-thread-1:EntryLoggerAllocator@181] - Created new entry log file /bk/ledgers/current/4ee.log for logId 1262.
(ENTRY LOG ID 1263)
λ grep "Created new entry log file\|Synced" bookkeeper-server-0.log | grep "1263"
2021-05-09 14:35:26,419 - INFO - [pool-4-thread-1:EntryLoggerAllocator@181] - Created new entry log file /bk/ledgers/current/4ef.log for logId 1263.
2021-05-09 14:36:33,031 - INFO - [SyncThread-14-1:EntryLogManagerForEntryLogPerLedger@693] - Synced entry logger 1263 to disk.
```
So, as we can see, there is no `Synced entry logger XXX` for entry log id `1262`, but the subsequent entry logs are rotated. The problem is that it seems that one entry log file not being "rotated" impacts GC for all the subsequent files. That is, if we look at the code that calculates the `entryLogger.getLeastUnflushedLogId()`, is as follows: https://github.com/apache/bookkeeper/blob/8dc108b862db7aa11c557695ea4beffcf21cece4/bookkeeper-server/src/main/java/org/apache/bookkeeper/bookie/EntryLogger.java#L1240
```
synchronized void flushRotatedEntryLog(Long entryLogId) {
entryLogsStatusMap.replace(entryLogId, true);
while ((!entryLogsStatusMap.isEmpty()) &&(entryLogsStatusMap.get(entryLogsStatusMap.firstKey()))) {
long leastFlushedLogId = entryLogsStatusMap.firstKey();
entryLogsStatusMap.remove(leastFlushedLogId);
leastUnflushedLogId = leastFlushedLogId + 1;
}
}
```
As you can see, `flushRotatedEntryLog` is only going to make progress assuming that each an every of the entry log files have been rotated. If just one of them is not rotated, then it stops updating `leastUnflushedLogId`, which makes the GC not deleting entry logs beyond that point: https://github.com/apache/bookkeeper/blob/25264f997ef22d9f456a9b88832dfa6634927b60/bookkeeper-server/src/main/java/org/apache/bookkeeper/bookie/GarbageCollectorThread.java#L589
For that entry log `1262`, we see this message multiple times along the experiment:
```
2021-05-09 14:35:31,942 - DEBUG - [SyncThread-14-1:EntryLogManagerBase@129] - Flush and sync current entry logger 1262
...
2021-05-09 15:07:31,831 - DEBUG - [SyncThread-14-1:EntryLogManagerBase@129] - Flush and sync current entry logger 1262
```
Again, there is no sign of the message `Synced entry logger XXXX` to disk for that entry log file. This explains why the GC stopped, which makes sense given the current logic. But we don't know why the rotation of that entry log `1262` did not complete. Another question is whether GC for any subsequent entry log file should be stuck just because one of them is making slower progress in getting rotated.
Note that this problem only appears when `entryLogPerLedgerEnabled:"true"`, so disabling that option solves the problem but at the cost of not being able to exploit the parallelism of SSDs/NVMe drives.
***To Reproduce***
Inducing a high load (+500MBps) on a Bookie with `entryLogPerLedgerEnabled:"true"`, we normally get this error.
***Expected behavior***
A Bookie with `entryLogPerLedgerEnabled:"true"` should be able to continue garbage collecting entry log files even though one of the previous entry log files has not been yet rotated.
***Screenshots***
In this screenshot you can see the behavior related to this issue. As you can see, the Disk Usage of the ledger volume for few Bookies continues to grow until they get in read-only mode, whereas others are still handling properly GC activity:
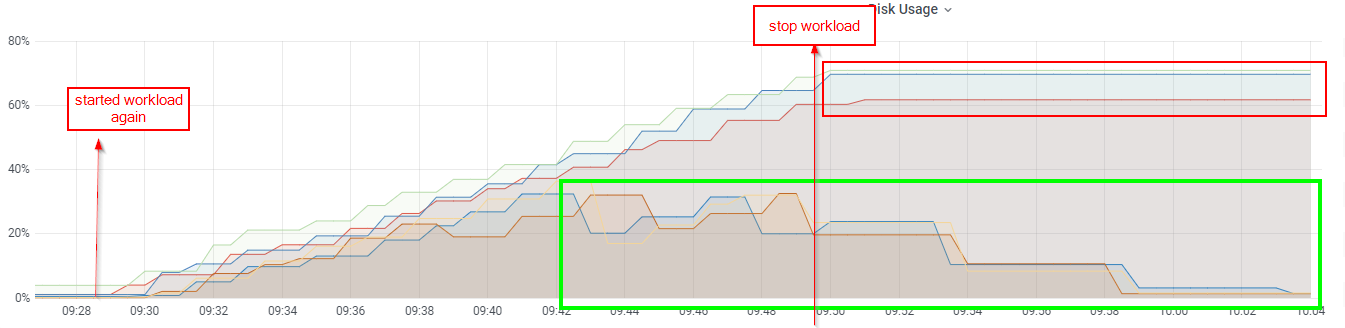
***Additional context***
n/a
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [bookkeeper] dlg99 commented on issue #2728: Entry Log GC may get blocked when using entryLogPerLedgerEnabled option
Posted by GitBox <gi...@apache.org>.
dlg99 commented on issue #2728:
URL: https://github.com/apache/bookkeeper/issues/2728#issuecomment-859173284
@fpj ELPL gets tricky if you don't know size/number of ledgers. I.e. in multi tenants cluster tenants can end up with too many small ledgers (or many tenants/topics in pulsar with ledger rotation policy on the schedule) + large disk.
I don't remember all the context from the time when ELPL was implemented, I think the following factors should be considered:
* File system doesn't always handle too many files gracefully.
* Then there are more entry logs open for write -> more fsyncs/parallel fsyncs (suboptimal on rotational disks, sometimes on SSDs)
* potentially too many file handles
* checkpoint on flush interval and perf considerations when journal(s) is co-located with entry logs
maybe something else.
I do agree that reduced write amplification (no compaction) helps (helped in the env it was developed for - large ledgers of predictable sizes, multiple SSDs, etc).
If you are looking for the lessons learned with ELPL, I'd suggest reaching out to @reddycharan and @jvrao
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [bookkeeper] OlegKashtanov commented on issue #2728: Entry Log GC may get blocked when using entryLogPerLedgerEnabled option
Posted by GitBox <gi...@apache.org>.
OlegKashtanov commented on issue #2728:
URL: https://github.com/apache/bookkeeper/issues/2728#issuecomment-862169887
I reproduced that issue using Bookkeeper benchmark tool.
The following deployment and test steps:
#### Configuration
- Kubernetes cluster
- 3 ZKs
- 6 BKs. 1 NVME drive per BK (both for Ledger and Journal).
- 1 BK benchmark tool
#### Deployment steps
- Deploy ZK operator:
```
git clone https://github.com/pravega/zookeeper-operator.git
helm install zk zookeeper-operator/charts/zookeeper-operator --set image.tag=0.2.8
```
- Deploy bookkeeper operator
```
kubectl create -f https://raw.githubusercontent.com/pravega/bookkeeper-operator/master/deploy/certificate.yaml
git clone https://github.com/pravega/bookkeeper-operator.git
helm install bk bookkeeper-operator/charts/bookkeeper-operator --set image.tag=0.1.3 --set testmode.enabled=true
```
- Apply the following configmap:
```
kind: ConfigMap
apiVersion: v1
metadata:
name: bk-config-map
data:
# Configuration values can be set as key-value properties
PRAVEGA_CLUSTER_NAME: "pravega"
WAIT_FOR: zookeeper-client:2181
```
- Build Bookie image using docker file https://github.com/pravega/pravega/blob/master/docker/bookkeeper/Dockerfile
- Create Bookie pods using the below manifest. Don't forget to indicate Bookie's image and change Storage classes:
```
apiVersion: "bookkeeper.pravega.io/v1alpha1"
kind: "BookkeeperCluster"
metadata:
name: "bookkeeper"
spec:
version: <BK_VERSION>
zookeeperUri: zookeeper-client:2181
blockOwnerDeletion: false
envVars: bk-config-map
image:
imageSpec:
repository: "<BK_REPOSITORY>"
pullPolicy: IfNotPresent
replicas: 6
resources:
requests:
memory: 4Gi
cpu: 2000m
limits:
memory: 20Gi
cpu: 8000m
storage:
ledgerVolumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "localfile-bk-ledger"
resources:
requests:
storage: 700Gi
journalVolumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "localfile-bk-journal"
resources:
requests:
storage: 700Gi
indexVolumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "ocs-storagecluster-cephfs"
resources:
requests:
storage: 10Gi
autoRecovery: true
options:
useHostNameAsBookieID: "true"
enableStatistics: "true"
statsProviderClass: "org.apache.bookkeeper.stats.prometheus.PrometheusMetricsProvider"
isForceGCAllowWhenNoSpace: "true"
minorCompactionThreshold: "0.4"
minorCompactionInterval: "1800"
majorCompactionThreshold: "0.8"
majorCompactionInterval: "43200"
numAddWorkerThreads: "8"
entryLogPerLedgerEnabled: "true"
flushInterval: "60000"
gcWaitTime: "600000"
readBufferSizeBytes: "4096"
writeBufferSizeBytes: "524288"
ledgerStorageClass: "org.apache.bookkeeper.bookie.InterleavedLedgerStorage"
journalDirectories: "/bk/journal/j0,/bk/journal/j1,/bk/journal/j2,/bk/journal/j3,/bk/journal/j4,/bk/journal/j5,/bk/journal/j6,/bk/journal/j7"
ledgerDirectories: "/bk/ledgers/"
flushEntrylogBytes: "0"
jvmOptions:
memoryOpts: ["-Xms2g","-Xmx12g","-XX:MaxDirectMemorySize=8g","-XX:+IgnoreUnrecognizedVMOptions","-XX:+UseContainerSupport","-XX:+UnlockDiagnosticVMOptions"]
```
- Build Bookkeeper benchmark image using docker file:
```
FROM ubuntu:18.04
RUN apt-get update
RUN echo deb http://ppa.launchpad.net/openjdk-r/ppa/ubuntu bionic main >| /etc/apt/sources.list.d/openjdk-r-ubuntu-ppa-bionic.list
RUN apt-get -y install openjdk-8-jdk
RUN apt-get -y install git
RUN apt-get -y install maven
RUN apt-get -y install vim
RUN cd /opt; git clone https://github.com/apache/bookkeeper.git --branch release-4.11.1
WORKDIR /opt/bookkeeper
RUN mvn -pl .,bookkeeper-benchmark clean install -Dmaven.test.skip=true
WORKDIR /root
USER root
RUN cd /root
CMD ["/bin/sh", "-c", "while true; do sleep 1; done"]
```
- Deploy Bookkeeper benchmark pod using the below manifest. Don't forget to indicate Image name:
```
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: benchmark-bookkeeper
spec:
# modify replicas according to your case
replicas: 1
selector:
matchLabels:
app: benchmark-bookkeeper
serviceName: "benchmark-bookkeeper"
template:
metadata:
labels:
app: benchmark-bookkeeper
spec:
containers:
- name: benchmark-bookkeeper
image: bk-bmrk:4.11.1
imagePullPolicy: IfNotPresent
resources:
limits:
cpu: "16"
memory: "20Gi"
requests:
cpu: "2"
memory: "4Gi"
env:
- name: BENCHMARK_EXTRA_OPTS
value: -Dorg.apache.bookkeeper.conf.readsystemproperties=true -DzkLedgersRootPath=/pravega/pravega/bookkeeper/ledgers -Xmx7g -XX:MaxDirectMemorySize=8g
#value: -Dorg.apache.bookkeeper.conf.readsystemproperties=true -DzkLedgersRootPath=/pravega/prvg-pravega/bookkeeper/ledgers
- name: BENCHMARK_EXTRA_CLASSPATH
value: /opt/bookkeeper/bookkeeper-benchmark/target/bookkeeper-benchmark-4.11.1.jar
```
- Run Bookkeeper benchmark:
```
kubectl exec -i benchmark-bookkeeper-0 -- /opt/bookkeeper/bookkeeper-benchmark/bin/benchmark writes -zookeeper zookeeper-client:2181 -quorum 3 -ensemble 3 -ackQuorum 3 -entrysize 300000 -ledgers 300 -throttle 10 -skipwarmup true -time 3600
```
- Monitor in any way the Ledger's drive capacity utilization. You will see the permanent increasing of used space. Here the screenshot from Prometheus monitoring (Ledger's drives capacity utilization):

- When Ledger's capacity utilization is 95%, you'll see the following events in Bookkeeper logs:
`2021-06-11 08:10:19,837 - WARN - [BookieWriteThreadPool-OrderedExecutor-7-0:WriteEntryProcessorV3@73] - BookieServer is running as readonly mode, so rejecting the request from the client!`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [bookkeeper] fpj commented on issue #2728: Entry Log GC may get blocked when using entryLogPerLedgerEnabled option
Posted by GitBox <gi...@apache.org>.
fpj commented on issue #2728:
URL: https://github.com/apache/bookkeeper/issues/2728#issuecomment-858510104
@dlg99 any particular why you and others don't use this option? We are observing much higher performance with `entryLogPerLedgerEnabled:"true"` in the hardware we are testing with. I'm curious to know why this is not popular given the performance benefit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [bookkeeper] eolivelli commented on issue #2728: Entry Log GC may get blocked when using entryLogPerLedgerEnabled option
Posted by GitBox <gi...@apache.org>.
eolivelli commented on issue #2728:
URL: https://github.com/apache/bookkeeper/issues/2728#issuecomment-858569126
@diegosalvi @nicoloboschi are you enabling this option in production for BlobIt/EmailSuccess ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [bookkeeper] dlg99 commented on issue #2728: Entry Log GC may get blocked when using entryLogPerLedgerEnabled option
Posted by GitBox <gi...@apache.org>.
dlg99 commented on issue #2728:
URL: https://github.com/apache/bookkeeper/issues/2728#issuecomment-856158555
@reddycharan any suggestions here? Do you still use ELPL?
@RaulGracia I don't remember all details of the ELPL/compaction and work that happened afterwards, I'd start with checking:
major/minor compaction intervals, and [flushInterval](https://github.com/apache/bookkeeper/blob/16e8ba772bb5cf4c7546fb559bd9d455d4e42625/conf/bk_server.conf#L430). I am not sure if ledgerStorageClass affects this, but I think SortedLedgerStorage and InterleavedLedgerStorage should work.
In case you are trying to repro it in unit tests, I am curious if ledgers with TTL < flushInterval are the reason for this somehow..
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [bookkeeper] eolivelli commented on issue #2728: Entry Log GC may get blocked when using entryLogPerLedgerEnabled option
Posted by GitBox <gi...@apache.org>.
eolivelli commented on issue #2728:
URL: https://github.com/apache/bookkeeper/issues/2728#issuecomment-858568965
@fpj I believe that the problem is that no one knows about it :-)
In general in BK we have the problem that there is no advertising about new features
We are doing some internal testing at DataStax for this option, especially for the fact that with this option it is easier that when you delete a ledger it is deleted from disk more promptly (see BP-45).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org