You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@openwhisk.apache.org by GitBox <gi...@apache.org> on 2018/03/29 05:34:39 UTC
[GitHub] style95 commented on issue #3501: Performance issue with multiple actions
style95 commented on issue #3501: Performance issue with multiple actions
URL: https://github.com/apache/incubator-openwhisk/issues/3501#issuecomment-377126909
I have tested OpenWhisk in terms of performance for last few months.
I want to share my experience on performance of OpenWhisk and discuss the right direction to go further.
I hope this would be a good starting point to improve performance and helps someone facing similar issue with me.
As per my observation, there are three big parts which have performance issue, akka-http, couchdb, dockerd.
In this thread, I will only focus on dockerd.
Since OpenWhisk can serve many different kinds of actions from different namespaces with different runtimes and container sizes, it would be more precise to assume many heterogenous requests come to OpenWhisk.
In this sense, to use a single action to measure performance of OpenWhisk may not be realistic in the production environment.
With current code base, if we run benchmark with many different number of actions, performance is severely degraded.
When I tested with 100 actions, I got about 30~40 TPS with 3 invoker machines with 40 cores, 128GB memory, 2TB ssd.
(There were 3 invoker containers on each hosts, so total 9 invokers were running)

There could be some differences based on deployment, configuration, the number of components and so on.
But I got about 20K TPS with same setup using 1 action, it seems obvious there is a huge performance degradation along different number of actions.

After deep investigation, I found the main reason is reuse of containers.
When we use only 1 action, logically all containers are reused.
But if we use 100 actions, containers are not fully reused and deletion and creation of containers are occurred. (Contianers are reused only if namespace and action name are same.)
Since performance of docker daemon is not good, it causes TPS dropping.
When one of my colleagues did benchmark against Docker daemon directly, we observed only 30
~ 40 TPS with `pause/unpause`.
(He also performed similar `pause/unpause` test with runc and only got about 300 TPS.)
When we included `run/rm` as well, TPS dropped to 1 ~ 10 TPS.
It means if containers are not reused well, it makes dockerd create/remote/unpause/pause containers and TPS is dropped due to poor performance of docker daemon.
I think this issue exists in all serverless frameworks which are based on docker.
So docker daemon is surely performance bottleneck in OpenWhisk, and it's not that simple to resolve it.
Even though huge performance improvement is made on docker daemon, I doubt it can support more than 1K ~ 2K TPS.
(Because docker is not designed to support this kind of traffic, creating about 1K containers in a second is not that plausible.)
Then, in OpenWhisk, main key factor of performance is reuse of containers, in other word, reducing loads to docker daemon.
With 1 actions, there were not many docker traffics, invoker just called `/run` requests against running containers again and again.
However, with 100 actions, many containers should be deleted and created, this caused huge performance degradation.
**Reuse rate: 95%**
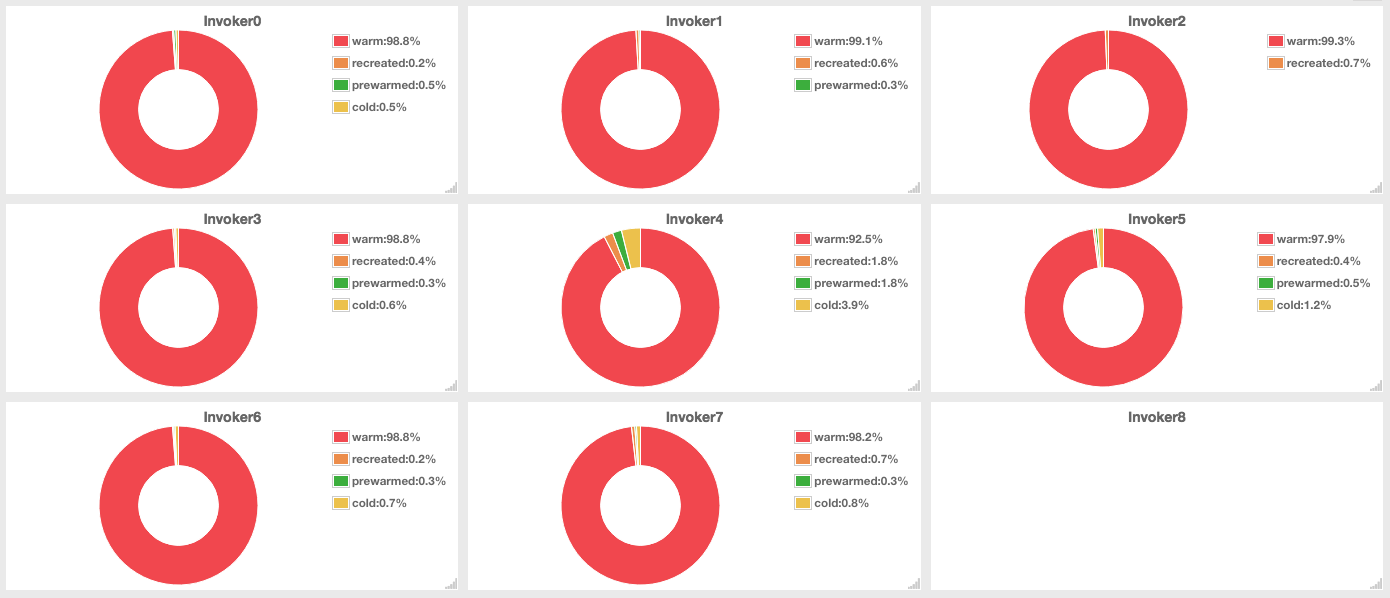
In above graph, the red part in a circle is the ratio of reused(warmed) containers.
Reuse rate was more than 95%, but I got only 6K TPS.
**5 namespaces + 2 actions each with 100 threads**

As reuse rate is decreased, TPS is getting worse.
**Reuse rate: 60%**

**10 namespaces + 10 actions each with 400 threads**

I changed `ContinerProxy` code to reuse container based on runtime and container memory size, and also changed `gracePause` time to 10 mins.
So once container is created, it is not paused in 10 minutes. No matter requests come from any namespaces, if runtime and memory size are same, containers are reused.
And I got about 20K TPS back with this changes.
**100 actions with 740 threads**

There could be some side effects and hidden defects of this implementation.
But anyway I got about 20K TPS with 100 actions.
This is because all 100 actions are nodejs6 actions and require same container memory size, accordingly all containers are reused.
In current code, TPS is decreased as the number of actions or number of namespaces are increasing.
Since there is no limit on the number of namespaces and the number of actions in them, more and more namespace and actions are used, performance is getting worse.
With this change, now container reuse rate only depends on runtime and container memory size.
OpenWhisk has 6 runtimes(nodejs6, nodejs8, python, php, swift, java), it can vastly increase reuse rate.
And even if more and more actions and namespaces are created, there is no performance degradation if same runtime is used.
One more good thing of this implementation is, it reduces the traffic against dockerd, I could run benchmark for long-term without any docker daemon problem under heavy loads.
Since I am not that an expert on OpenWhisk, I want to discuss whether there could be any issues or side effects with this change.
With my shallow understanding on OpenWhisk, one security issue could happen when user accesses files in a container.
If user creates any files in the code, files could be exposed to other users as same container can be reused among many users.
(But I am not sure OpenWhisk should also guarantee such kinds of stateful approach because serverless is intrinsically stateless.)
Other than that, I have no idea currently.
Apart from my suggestion, I think one more thing worth to try is this one:
https://github.com/apache/incubator-openwhisk/pull/2795
I want to listen any opinions and feedback.
Thanks in advance
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services