You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@druid.apache.org by GitBox <gi...@apache.org> on 2021/07/06 20:52:43 UTC
[GitHub] [druid] harinirajendran opened a new issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
harinirajendran opened a new issue #11414:
URL: https://github.com/apache/druid/issues/11414
### Affected Version
0.21
### Description
We have a druid cluster in which we are ingesting about 2.5M events/second. We have 90 ingestion tasks for 1 of our data sources with task duration set to 1 hr. Whenever the tasks roll every hour, Kafka ingestion lag spikes up anywhere from 3M to even 15M `druid.ingest.kafka.lag`. On further analysis, we noted that while tasks are rolling, some of the active ingestion tasks are stuck in `pause` state for a long time (sometimes up to 1.5-2 minutes) during which those tasks aren't ingesting any data resulting in ingestion lag spike.
Logs from MM tasks with a huge gap between `pause` and `resume`
```
{"@timestamp":"2021-06-21T17:34:51.628Z", "log.level":"DEBUG", "message":"Received pause command, pausing ingestion until resumed.", "service.name":"druid/middleManager","event.dataset":"druid/middleManager.log","process.thread.name":"task-runner-0-priority-0","log.logger":"org.apache.druid.indexing.seekablestream.SeekableStreamIndexTaskRunner"}
{"@timestamp":"2021-06-21T17:36:27.089Z", "log.level":"DEBUG", "message":"Received pause command, pausing ingestion until resumed.", "service.name":"druid/middleManager","event.dataset":"druid/middleManager.log","process.thread.name":"task-runner-0-priority-0","log.logger":"org.apache.druid.indexing.seekablestream.SeekableStreamIndexTaskRunner"}
{"@timestamp":"2021-06-21T17:36:27.097Z", "log.level":"DEBUG", "message":"Received resume command, resuming ingestion.", "service.name":"druid/middleManager","event.dataset":"druid/middleManager.log","process.thread.name":"task-runner-0-priority-0","log.logger":"org.apache.druid.indexing.seekablestream.SeekableStreamIndexTaskRunner"}
```
In the above loglines, we can see that that task was in `pause` state from `17:34:51` to `17:36:27`.
On further analysis, we figured out that the MM taskRunner goes to a pause state when it is requesting a `checkpoint` notice [here](https://github.com/apache/druid/blob/8264203cee688607091232897749e959e7706010/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/SeekableStreamIndexTaskRunner.java#L729).
From the time the taskRunner submits the checkpoint notice, it actually takes around 1.5 minutes for the coordinator to actually process this checkpoint notice. We can see it in the coordinator logs below for a specific task.
Note that this long pause of ingestion task happens **only** when tasks are rolling. Not during other times.
Our guess here is that, while tasks are rolling, the [notices queue](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L752) has a lot of notices in them and each notice takes a long time to be processed thus causing significant delay in the `checkpoint` notice as well to be processed once its added to the queue.
Currently, we do not have logs in place to figure out how many notices are there in this queue at any point and how long does each notice takes to get executed.
Spent some more time analyzing further and we saw that some of following functions [here](https://github.com/apache/druid/blob/master/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1214) are taking multiple seconds when tasks are rolling as opposed to few milliseconds when tasks aren't.
```
discoverTasks();
updateTaskStatus();
checkTaskDuration();
checkPendingCompletionTasks();
checkCurrentTaskState();
```
And this could be the reason why each notice is taking a long time to get processed. This is as far as we got wrt debugging.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jihoonson commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jihoonson commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875797722
I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing :slightly_smiling_face:
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] FrankChen021 commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
FrankChen021 commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-898845854
We have a similar problem in our cluster. There's a topic with 12 partitions, and its peak incoming message rate is up to 120K/s. Once it reaches the peak message rate, Druid ingestion tasks seems stuck temporarily. I have not investigated the problem if it's related to this issue, but leave a comment here so that I could find this issue once I needed it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1026275109
> I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing 🙂
@jihoonson @jasonk000 @gianm : I have some more updates wrt this issue. The supervisor actually is spending a lot of time in processing `runNotices` which is causing the `checkpointNotice` to wait in notices queue for a long time causing tasks to be stuck which results in ingestion lag.
In our case, we have seen run notices take ~7s as shown in the graph below.

As a result of this, the notices queue gets backed up when the number of tasks are huge as each `runNotice ` takes a long time to process.

On further analysis, we realized that the bulk of 7s in `run_notice` processing is being spent in the [getAsyncStatus()](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1442) call in `discoverTasks` function. When the task boots up, it roughly takes ~5s to start the JVM and start the HTTP server. So, as a result [this](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1593) `Futures` take about ~6s to get the status of tasks that are just bootstrapping with retries resulting in `runNotice` taking such a long time.
So, it's the tasks bootstrap time and hence its inability to respond to `/status` call from the supervisor that is causing `run_notice` to take ~6s causing notices queue to be backed up causing starvation of `checkpoint_ notice` causing ingestion lag. Does it make sense?
Have you seen something similar on your end? How long do Kafka real-time tasks take to bootstrap on your deployments? (Also, we use Middle Managers as of today instead of Indexers).
Having said this, @jasonk000 : I don't think the PRs you listed earlier (#12096 #12097 #12099) would solve the issue we are encountering, right?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] FrankChen021 edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
FrankChen021 edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-898845854
We have a similar problem in our cluster. There's a topic with 12 partitions, and its peak incoming message rate is up to 120K/s. Once it reaches the peak message rate, Druid ingestion tasks seems stuck temporarily. I have not investigated the problem if it's related to this issue, but leave a comment here so that I could find this issue once I need it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1042321413
> Our ingestion tasks run on MM nodes - I had a look, and it seems to take about 8-10 seconds to go from JVM start to reading Kafka.
Great! In my case, I looked at the point when the httpServer was started by the task so that it can respond to `/status` calls from overlord.
The log line I searched was something like `Started ServerConnector@6e475994{HTTP/1.1, (http/1.1)}{0.0.0.0:8102}` which happens roughly at the 4th second after the tasks start. And runNotice at the overlord gets stuck [here](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1442) for that duration until task can respond to the `/status` call. This is my observation. Does it make sense?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875819653
> I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing 🙂
I am working on a couple small PRs to add more visibility into this. hopefully that helps us get to the bottom of this 🤞
https://github.com/apache/druid/pull/11415
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jihoonson commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jihoonson commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875766720
@harinirajendran interesting. Are any logs omitted between the second and the third lines (checkpointing and pause)? Or Is there no log between those two? If there is no log between them, it seems a bit strange to me because I think the overlord usually prints something unless it is stuck especially when you have debug logging enabled. If the overlord was processing other notices for 2 min before it sent pause requests, it would likely print something in the logs.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875601615
> Hi @harinirajendran, thank you for your report. Was it only one task being paused or all tasks for the same datasource? If it's the first case, then maybe your guess is correct that there were lots of notices in the queue because the task who initiated the checkpoint process pauses itself after it sends the checkpoint request to the supervisor. If it's the second case, it means the supervisor was already in processing of the checkpoint notice but hadn't finished it yet. It was probably waiting for all tasks to respond to the pause request or waiting for tasks to respond to the setEndOffset request (see `SeekableStreamSupervisor.checkpointTaskGroup()`. One of our customers had a similar issue at Imply before and the cause was frequent HTTP communication failures which were retried with backoff.
@jihoonson : This long pause happens whenever a task requests a checkpoint notice while task roll is happening for the same data source. So it happens with all tasks requesting checkpoint notice while task roll is going on. In our case, the tasks roll happens over a span of 5-6 minutes. Also, this ingestion lag spike consistently only happens around task rolls which makes me think these aren't because of HTTP communication issues.
Also, the timeline is as follows
time t1: task x pauses itself and initiates a checkpoint request to the coordinator
time t1: coordinator receives the checkpoint notice and adds it to the notices queue
time t1+2 minutes: coordinator sends a pause to the task
time t1+2 minutes: coordinator gets response to pause and then calls setEndOffset(which in turn resumes the task)
So the coordinator processes the checkpoint notice and sends a pause only after about 2 minutes.
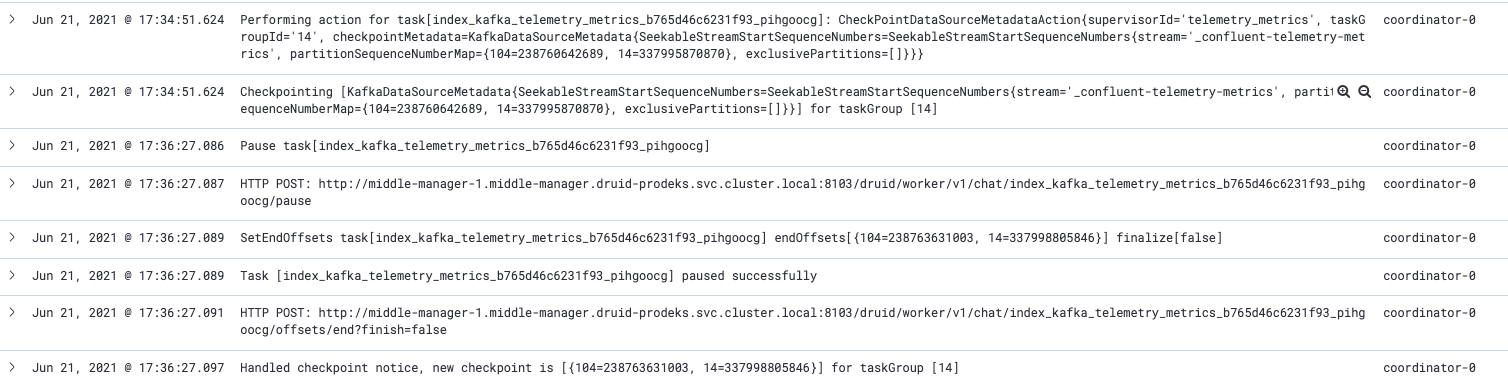
Following is the log sequence for the same. Notice the gap between **17:34:51.624** and **17:36:27.086** timestamp
```
Jun 21, 2021 @ 17:34:51.624 Performing action for task[<task_id>]: CheckPointDataSourceMetadataAction{supervisorId='<supervisor_id>', taskGroupId='14', checkpointMetadata=KafkaDataSourceMetadata{SeekableStreamStartSequenceNumbers=SeekableStreamStartSequenceNumbers{stream='<kafka-topic>', partitionSequenceNumberMap={104=238760642689, 14=337995870870}, exclusivePartitions=[]}}} coordinator-0
Jun 21, 2021 @ 17:34:51.624 Checkpointing [KafkaDataSourceMetadata{SeekableStreamStartSequenceNumbers=SeekableStreamStartSequenceNumbers{stream='<kafka-topic>', partitionSequenceNumberMap={104=238760642689, 14=337995870870}, exclusivePartitions=[]}}] for taskGroup [14] coordinator-0
Jun 21, 2021 @ 17:36:27.086 Pause task[<task_id>] coordinator-0
Jun 21, 2021 @ 17:36:27.087 HTTP POST: http://<MMHost:MMport>/druid/worker/v1/chat/<task_id>/pause coordinator-0
Jun 21, 2021 @ 17:36:27.089 SetEndOffsets task[<task_id>] endOffsets[{104=238763631003, 14=337998805846}] finalize[false] coordinator-0
Jun 21, 2021 @ 17:36:27.089 Task [<task_id>] paused successfully coordinator-0
Jun 21, 2021 @ 17:36:27.091 HTTP POST: http://<MMHost:MMport>/druid/worker/v1/chat/<task_id>/offsets/end?finish=false coordinator-0
Jun 21, 2021 @ 17:36:27.097 Handled checkpoint notice, new checkpoint is [{104=238763631003, 14=337998805846}] for taskGroup [14] coordinator-0
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1026275109
> I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing 🙂
@jihoonson @jasonk000 : I have some more updates wrt this issue. The supervisor actually is spending a lot of time in processing `runNotices` which is causing the `checkpointNotice` to wait in notices queue for a long time causing tasks to be stuck which results in ingestion lag.
In our case, we have seen run notices take ~7s as shown in the graph below.

As a result of this, the notices queue gets backed up when the number of tasks are huge as each `runNotice ` takes a long time to process.

On further analysis, we realized that the bulk of 7s in `run_notice` processing is being spent in the [getAsyncStatus()](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1442) call in `discoverTasks` function. When the task boots up, it roughly takes ~5s to start the JVM and start the HTTP server. So, as a result [this](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1593) `Futures` take about ~6s to get the status of tasks that are just bootstrapping with retries resulting in `runNotice` taking such a long time.
So, it's the tasks bootstrap time and hence its inability to respond to `/status` call from the supervisor that is causing `run_notice` to take ~6s causing notices queue to be backed up causing starvation of `checkpoint_ notice` causing ingestion lag. Does it make sense?
Have you seen something similar on your end? How long do Kafka real-time tasks take to bootstrap on your deployments? (Also, we use Middle Managers as of today instead of Indexers).
Having said this, @jasonk000 : I don't think the PRs you listed earlier (#12096 #12097 #12099) would solve the issue we are encountering, right?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1026275109
> I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing 🙂
@jihoonson @jasonk000 : I have some more updates wrt this issue. The supervisor actually is spending a lot of time in processing `runNotices` which is causing the `checkpointNotice` to wait in notices queue for a long time causing tasks to be stuck which results in ingestion lag.
In our case, we have seen run notices take ~7s as shown in the graph below.

As a result of this, the notices queue gets backed up when the number of tasks are huge as each `runNotice ` takes a long time to process.

On further analysis, we realized that the bulk of 7s in `run_notice` processing is being spent in the [getAsyncStatus()](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1442) call in `discoverTasks` function. When the task boots up, it roughly takes ~5s to start the JVM and start the HTTP server. So, as a result [this](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1593) `Futures` take about ~6s to get the status of tasks that are just bootstrapping with retries resulting in `runNotice` taking such a long time.
So, it's the tasks bootstrap time and hence its inability to respond to `/status` call from the supervisor that is causing `run_notice` to take ~6s causing notices queue to be backed up causing starvation of `checkpoint_ notice` causing ingestion lag. Does it make sense?
Have you seen something similar on your end? How long do Kafka real-time tasks take to bootstrap on your deployments? (Also, we use Middle Managers as of today instead of Indexers).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1041883825
> majority of wall clock time in the KafkaSupervisor thread was waiting on SQL queries executing as part of the RunNotice
In our case, it wasn't the SQL queries that were causing RunNotice to take more time. But rather, the tasks bootstrap time(~5s). @gianm's fix certainly helped bring this down. But with time as task rollovers started getting spread out over a few minutes, there weren't many runNotices next to each other to coalesce, resulting in the same problem again. To bring the time for task bootstrap down, we switched from MMs to Indexers as it doesn't involve jvm restart for every task and actually helped.
@jasonk000: Do you use MMs or indexers for your ingestion tasks? How long does it take for the ingestion tasks to bootstrap in your environment?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jasonk000 commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jasonk000 commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1042304007
Our ingestion tasks run on MM nodes - I had a look, and it seems to take about 8-10 seconds to go from JVM start to reading Kafka.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875601615
> Hi @harinirajendran, thank you for your report. Was it only one task being paused or all tasks for the same datasource? If it's the first case, then maybe your guess is correct that there were lots of notices in the queue because the task who initiated the checkpoint process pauses itself after it sends the checkpoint request to the supervisor. If it's the second case, it means the supervisor was already in processing of the checkpoint notice but hadn't finished it yet. It was probably waiting for all tasks to respond to the pause request or waiting for tasks to respond to the setEndOffset request (see `SeekableStreamSupervisor.checkpointTaskGroup()`. One of our customers had a similar issue at Imply before and the cause was frequent HTTP communication failures which were retried with backoff.
@jihoonson : This long pause happens whenever a task requests a checkpoint notice while task roll is happening for the same data source. So it happens with all tasks requesting checkpoint notice while task roll is going on. In our case, the tasks roll happens over a span of 5-6 minutes. Also, this ingestion lag spike consistently only happens around task rolls which makes me think these aren't because of HTTP communication issues.
Also, the timeline is as follows
time t1: task x pauses itself and initiates a checkpoint request to the coordinator
time t1: coordinator receives the checkpoint notice and adds it to the notices queue
time t1+2 minutes: coordinator sends a pause to the task
time t1+2 minutes: coordinator gets response to pause and then calls setEndOffset(which in turn resumes the task)
So the coordinator processes the checkpoint notice and sends a pause only after about 2 minutes.
Following is the log sequence for the same
```
Jun 21, 2021 @ 17:34:51.624 Performing action for task[<task_id>]: CheckPointDataSourceMetadataAction{supervisorId='<supervisor_id>', taskGroupId='14', checkpointMetadata=KafkaDataSourceMetadata{SeekableStreamStartSequenceNumbers=SeekableStreamStartSequenceNumbers{stream='<kafka-topic>', partitionSequenceNumberMap={104=238760642689, 14=337995870870}, exclusivePartitions=[]}}} coordinator-0
Jun 21, 2021 @ 17:34:51.624 Checkpointing [KafkaDataSourceMetadata{SeekableStreamStartSequenceNumbers=SeekableStreamStartSequenceNumbers{stream='<kafka-topic>', partitionSequenceNumberMap={104=238760642689, 14=337995870870}, exclusivePartitions=[]}}] for taskGroup [14] coordinator-0
Jun 21, 2021 @ 17:36:27.086 Pause task[<task_id>] coordinator-0
Jun 21, 2021 @ 17:36:27.087 HTTP POST: http://<MMHost:MMport>/druid/worker/v1/chat/<task_id>/pause coordinator-0
Jun 21, 2021 @ 17:36:27.089 SetEndOffsets task[<task_id>] endOffsets[{104=238763631003, 14=337998805846}] finalize[false] coordinator-0
Jun 21, 2021 @ 17:36:27.089 Task [<task_id>] paused successfully coordinator-0
Jun 21, 2021 @ 17:36:27.091 HTTP POST: http://<MMHost:MMport>/druid/worker/v1/chat/<task_id>/offsets/end?finish=false coordinator-0
Jun 21, 2021 @ 17:36:27.097 Handled checkpoint notice, new checkpoint is [{104=238763631003, 14=337998805846}] for taskGroup [14] coordinator-0
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875819653
> I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing 🙂
I am working on a couple small PRs to add more visibility into this. hopefully that helps us get to the bottom of this 🤞
https://github.com/apache/druid/pull/11415
https://github.com/apache/druid/pull/11417
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1030512254
> I'm not sure whether the proposed PRs would fix your issue. I'd have to see stack traces during the 1.5-2mins pause time you refer, is that how you determined they were waiting on the future?
I determined it is the task bootstrap time that's causing `run_notice` to take ~8s by reading through the run_notice handle code and also correlating the timestamps in the logs.
<img width="1467" alt="Screen Shot 2022-02-04 at 9 18 51 PM" src="https://user-images.githubusercontent.com/9054348/152626992-926dd6be-5cc8-4b20-a3f8-77c14460827e.png">
For example, here you can see that the kafkasupervisor_<datasource> thread was stuck for 13 seconds without logging anything. So I went through the code path between these 2 log statements and that's where I hit the futures. And I found logs from other async threads in that gap trying to get `task_status` but were stuck in a retry loop as the tasks were bootstrapping and hence wasn't accepting connections for 5-6s.
To prove this theory, I switched one of our lab environments to use indexers instead of MMs for real-time ingestion tasks and as I doubted, the `run_notice` handle time fell down from 8s to under 2s as there are no jvm restarts involved for every task bootstrap with indexers.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jasonk000 commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jasonk000 commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1041961923
Our ingestion tasks run on MM nodes, I haven't investigated bootstrap time at this point.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jasonk000 commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jasonk000 commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1041876818
@harinirajendran I went looking for this, and I agree with your analysis. Stack traces showed that majority of wall clock time in the KafkaSupervisor thread was waiting on SQL queries executing as part of the RunNotice. I backported the changes in https://github.com/apache/druid/pull/12018 to our environment and they worked perfectly. A class histogram showed ~500 CheckpointNotice tasks sitting idle and ~2500 RunNotice tasks.
There are two ways you can confirm this is happening at any time you have slow checkpoint. Replace $pid and $supervisorname as appropriate.
1. Look for a count of class instances that are `SeekableStreamSupervisor$RunNotice`
```
jcmd $pid GC.class_histogram | grep SeekableStreamSupervisor
```
2. Look for supervisor thread performing RunNotice calls
```
jstack $pid | grep -A60 KafkaSupervisor-$supervisorname\"
```
Thank you to @gianm, your solution was simple and worked perfectly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1026275109
> I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing 🙂
@jihoonson @jasonk000 : I have some more updates wrt this issue. The supervisor actually is spending a lot of time in processing `runNotices` which is causing the `checkpointNotice` to wait in notices queue for a long time causing tasks to be stuck which results in ingestion lag. In our case
In our case, we have seen run notices take ~7s as shown in the graph below.

As a result of this, the notices queue gets backed up when the number of tasks are huge as each `runNotice ` takes a long time to process.

On further analysis, we realized that the bulk of 7s in `run_notice` processing is being spent in the [getAsyncStatus()](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1442) call in `discoverTasks` function. When the task boots up, it roughly takes ~5s to start the JVM and start the HTTP server. So, as a result [this](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1593) `Futures` take about ~6s to get the status of tasks that are just bootstrapping with retries resulting in `runNotice` taking such a long time.
So, it's the tasks bootstrap time and hence its inability to respond to `/status` call from the supervisor that is causing `run_notice` to take ~6s causing notices queue to be backed up causing starvation of `checkpoint_ notice` causing ingestion lag. Does it make sense?
Have you seen something similar on your end? How long do Kafka real-time tasks take to bootstrap on your deployments? (Also, we use Middle Managers as of today instead of Indexers).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jasonk000 commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jasonk000 commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1032958437
It seems like you're on the right path. If you can run `jstack $pid` during the period of concern, and capture what's happening to the thread, or even introduce some extra logging lines, this might narrow it down more quickly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1041883825
> majority of wall clock time in the KafkaSupervisor thread was waiting on SQL queries executing as part of the RunNotice
In our case, it wasn't the SQL queries that were causing RunNotice to take more time. But rather, the tasks bootstrap time(~5s). @gianm's fix certainly helped bring this down. But with time as task rollovers started getting spread out over a few minutes, there weren't many runNotices next to each other to coalesce, resulting in the same problem again. To bring the time for task bootstrap down, we switched from MMs to Indexers as it doesn't involve jvm restart for every task and that actually helped.
@jasonk000: Do you use MMs or indexers for your ingestion tasks? How long does it take for the ingestion tasks to bootstrap in your environment?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jasonk000 removed a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jasonk000 removed a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1041961923
Our ingestion tasks run on MM nodes, I haven't investigated bootstrap time at this point.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jasonk000 commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jasonk000 commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1029595612
I'm not sure whether the proposed PRs would fix your issue. I'd have to see stack traces during the 1.5-2mins pause time you refer, is that how you determined they were waiting on the future?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jihoonson commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jihoonson commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875125389
Hi @harinirajendran, thank you for your report. Was it only one task being paused or all tasks for the same datasource? If the first is the case, then maybe your guess is correct that there were lots of notices in the queue. If the second is the case, it means the supervisor was already in processing of the checkpoint notice but hadn't finished it yet. It was probably waiting for all tasks to respond to the pause request or waiting for tasks to respond to the setEndOffset request (see `SeekableStreamSupervisor.checkpointTaskGroup()`. One of our customers had a similar issue at Imply before and the cause was frequent HTTP communication failures which were retried with backoff.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jihoonson edited a comment on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jihoonson edited a comment on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875125389
Hi @harinirajendran, thank you for your report. Was it only one task being paused or all tasks for the same datasource? If it's the first case, then maybe your guess is correct that there were lots of notices in the queue because the task who initiated the checkpoint process pauses itself after it sends the checkpoint request to the supervisor. If it's the second case, it means the supervisor was already in processing of the checkpoint notice but hadn't finished it yet. It was probably waiting for all tasks to respond to the pause request or waiting for tasks to respond to the setEndOffset request (see `SeekableStreamSupervisor.checkpointTaskGroup()`. One of our customers had a similar issue at Imply before and the cause was frequent HTTP communication failures which were retried with backoff.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1026275109
> I see. Thank you for confirming it. Your analysis seems correct to me. Now I'm curious what notices the supervisor was processing 🙂
@jihoonson @jasonk000 : I have some more updates wrt this issue. The supervisor actually is spending a lot of time in processing `runNotices` which is causing the `checkpointNotice` to wait in notices queue for a long time causing tasks to be stuck which results in ingestion lag. In our case
In our case, we have seen run notices take ~7s as shown in the graph below.

As a result of this, the notices queue gets backed up when the number of tasks are huge resulting in more runNotices every hour.

On further analysis, we realized that the bulk of 7s in `run_notice` processing is being spent in the [getAsyncStatus()](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1442) call in `discoverTasks` function. When the task boots up, it roughly takes ~5s to start the JVM and start the HTTP server. So, as a result [this](https://github.com/confluentinc/druid/blob/0.21.0-confluent/indexing-service/src/main/java/org/apache/druid/indexing/seekablestream/supervisor/SeekableStreamSupervisor.java#L1593) `Futures` take about ~6s to get the status of tasks that are just bootstrapping with retries resulting in `runNotice` taking such a long time.
So, it's the tasks bootstrap time and hence its inability to respond to `/status` call from the supervisor that is causing `run_notice` to take ~6s causing notices queue to be backed up causing starvation of `checkpoint_ notice` causing ingestion lag. Does it make sense?
Have you seen something similar on your end? How long do Kafka real-time tasks take to bootstrap on your deployments? (Also, we use Middle Managers as of today instead of Indexers).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] jasonk000 commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
jasonk000 commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-1003452368
@harinirajendran I recommend you experiment running the overlord with these three PRs pulled to your code: #12096 #12097 #12099, and let us know how it goes.
I reviewed your analysis, and some of the code, and took a profile on our cluster here.
You are correct that during task rollover the overlord gets busy processing `RunNotice` notices. I can identify two codepaths where RunNotice hits the TaskQueue (in purple):
On our system, with above fixes, TaskQueue is only a fraction of the time

- `SeekableStreamSupervisor.RunNotice::handle -> SeekableStreamSupervisor::runInternal -> SeekableStreamSupervisor::createNewTasks -> SeekableStreamSupervisor::createTasksForGroup -> TaskQueue::add`
- `SeekableStreamSupervisor.RunNotice::handle -> SeekableStreamSupervisor::runInternal -> SeekableStreamSupervisor::checkPendingCompletionTasks -> SeekableStreamSupervisor::killTasksInGroup -> SeekableStreamSupervisor::killTask -> TaskQueue::shutdown`
Both of these paths hit the lock in TaskQueue; the fixes I present above have improved scalability of TaskQueue on our system.
It might also help if you can share which metadata task storage engine you are using (SQL vs heap).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org
[GitHub] [druid] harinirajendran commented on issue #11414: Kafka ingestion lag spikes up whenever tasks are rolling
Posted by GitBox <gi...@apache.org>.
harinirajendran commented on issue #11414:
URL: https://github.com/apache/druid/issues/11414#issuecomment-875787805
> @harinirajendran interesting. Are any logs omitted between the second and the third lines (checkpointing and pause)? Or Is there no log between those two? If there is no log between them, it seems a bit strange to me because I think the overlord usually prints something unless it is stuck especially when you have debug logging enabled. If the overlord was processing other notices for 2 min before it sent pause requests, it would likely print something in the logs.
@jihoonson oh yeah. there are lots of log lines between the 2 timestamps. The coordinator continues to process other notices and spews out lots of logs. Here, I explicitly filtered out the log lines for this specific task which was paused for about 2 minutes.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: commits-unsubscribe@druid.apache.org
For additional commands, e-mail: commits-help@druid.apache.org