You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by justinuang <gi...@git.apache.org> on 2018/11/29 15:53:21 UTC
[GitHub] spark pull request #23179: Fix the rat excludes on .policy.yml
GitHub user justinuang opened a pull request:
https://github.com/apache/spark/pull/23179
Fix the rat excludes on .policy.yml
## What changes were proposed in this pull request?
Fix the rat excludes on .policy.yml
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/palantir/spark juang/fix-rat-policy-yml
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/23179.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #23179
----
commit 78b34b40a7e034dd641418b804e6e2606b216ba4
Author: Robert Kruszewski <ro...@...>
Date: 2018-04-01T12:41:47Z
Fix publish after k8s rebase (#347)
commit 2788441fb6f945d1d945caa4675c97b8b2f5a472
Author: Patrick Woody <pa...@...>
Date: 2018-04-02T17:54:15Z
Revert "transformexpression with origin" (#350)
commit 4cc4dee11883bf1954181ec808f0f57a9ee55c55
Author: Patrick Woody <pa...@...>
Date: 2018-04-02T17:54:25Z
Add reminder for upstream ticket/PR to github template (#351)
commit 078066bdc9a77dd0c241fae544806d043cb0b167
Author: Robert Kruszewski <ro...@...>
Date: 2018-03-31T14:25:56Z
resolve conflicts
commit fe35b58a9e8b1bdde111b542371123907686ba97
Author: mcheah <mc...@...>
Date: 2018-04-02T21:37:23Z
Empty commit to clear Circle cache.
commit 1264fb5908d3eab2cccfaf9b22b6975c7afd20d4
Author: mcheah <mc...@...>
Date: 2018-04-03T00:29:36Z
Empty commit to tag 2.4.0-palantir.12 and trigger publish.
commit b7410ba819d4e3e37f59e8f5df0d47e78c92a362
Author: Robert Kruszewski <ro...@...>
Date: 2018-04-03T14:02:21Z
Fix circle checkout for tags (#352)
commit 6da0b8266906f3e1c804627c9a009a18ed102874
Author: Robert Kruszewski <ro...@...>
Date: 2018-04-03T17:32:23Z
Merge pull request #346 from palantir/rk/upstream
Update to upstream
commit 7b12f6367dbf5d5b1da06aa0cf204658de2ebbe7
Author: Bryan Cutler <cu...@...>
Date: 2018-04-02T16:53:37Z
[SPARK-15009][PYTHON][FOLLOWUP] Add default param checks for CountVectorizerModel
## What changes were proposed in this pull request?
Adding test for default params for `CountVectorizerModel` constructed from vocabulary. This required that the param `maxDF` be added, which was done in SPARK-23615.
## How was this patch tested?
Added an explicit test for CountVectorizerModel in DefaultValuesTests.
Author: Bryan Cutler <cu...@gmail.com>
Closes #20942 from BryanCutler/pyspark-CountVectorizerModel-default-param-test-SPARK-15009.
commit 60e1bd62d72cc5fadbfc96ad6b1f3b84bd36335e
Author: David Vogelbacher <dv...@...>
Date: 2018-04-02T19:00:37Z
[SPARK-23825][K8S] Requesting memory + memory overhead for pod memory
## What changes were proposed in this pull request?
Kubernetes driver and executor pods should request `memory + memoryOverhead` as their resources instead of just `memory`, see https://issues.apache.org/jira/browse/SPARK-23825
## How was this patch tested?
Existing unit tests were adapted.
Author: David Vogelbacher <dv...@palantir.com>
Closes #20943 from dvogelbacher/spark-23825.
commit 08f64b4048072a97a92dca94ded78f2de46525f2
Author: Yinan Li <yn...@...>
Date: 2018-04-02T19:20:55Z
[SPARK-23285][K8S] Add a config property for specifying physical executor cores
## What changes were proposed in this pull request?
As mentioned in SPARK-23285, this PR introduces a new configuration property `spark.kubernetes.executor.cores` for specifying the physical CPU cores requested for each executor pod. This is to avoid changing the semantics of `spark.executor.cores` and `spark.task.cpus` and their role in task scheduling, task parallelism, dynamic resource allocation, etc. The new configuration property only determines the physical CPU cores available to an executor. An executor can still run multiple tasks simultaneously by using appropriate values for `spark.executor.cores` and `spark.task.cpus`.
## How was this patch tested?
Unit tests.
felixcheung srowen jiangxb1987 jerryshao mccheah foxish
Author: Yinan Li <yn...@google.com>
Author: Yinan Li <li...@gmail.com>
Closes #20553 from liyinan926/master.
commit 8a307d1b4db5ed9e6634142002139945ff3a79bd
Author: Kazuaki Ishizaki <is...@...>
Date: 2018-04-02T19:48:44Z
[SPARK-23713][SQL] Cleanup UnsafeWriter and BufferHolder classes
## What changes were proposed in this pull request?
This PR implemented the following cleanups related to `UnsafeWriter` class:
- Remove code duplication between `UnsafeRowWriter` and `UnsafeArrayWriter`
- Make `BufferHolder` class internal by delegating its accessor methods to `UnsafeWriter`
- Replace `UnsafeRow.setTotalSize(...)` with `UnsafeRowWriter.setTotalSize()`
## How was this patch tested?
Tested by existing UTs
Author: Kazuaki Ishizaki <is...@jp.ibm.com>
Closes #20850 from kiszk/SPARK-23713.
commit 83c1da39bae0887f463a4ea157fc50e1071d2dd2
Author: Marcelo Vanzin <va...@...>
Date: 2018-04-02T21:35:07Z
[SPARK-23834][TEST] Wait for connection before disconnect in LauncherServer test.
It was possible that the disconnect() was called on the handle before the
server had received the handshake messages, so no connection was yet
attached to the handle. The fix waits until we're sure the handle has been
mapped to a client connection.
Author: Marcelo Vanzin <va...@cloudera.com>
Closes #20950 from vanzin/SPARK-23834.
commit f9927a5db3ccf24fe62bc9c6e840f45d36974269
Author: Yogesh Garg <yogesh(dot)garg()databricks(dot)com>
Date: 2018-04-02T23:41:26Z
[SPARK-23690][ML] Add handleinvalid to VectorAssembler
## What changes were proposed in this pull request?
Introduce `handleInvalid` parameter in `VectorAssembler` that can take in `"keep", "skip", "error"` options. "error" throws an error on seeing a row containing a `null`, "skip" filters out all such rows, and "keep" adds relevant number of NaN. "keep" figures out an example to find out what this number of NaN s should be added and throws an error when no such number could be found.
## How was this patch tested?
Unit tests are added to check the behavior of `assemble` on specific rows and the transformer is called on `DataFrame`s of different configurations to test different corner cases.
Author: Yogesh Garg <yogesh(dot)garg()databricks(dot)com>
Author: Bago Amirbekian <ba...@databricks.com>
Author: Yogesh Garg <10...@users.noreply.github.com>
Closes #20829 from yogeshg/rformula_handleinvalid.
commit baa6b3b38cb18860f02c3cd4cdbc9019061fa448
Author: Marcelo Vanzin <va...@...>
Date: 2018-04-03T01:31:47Z
[SPARK-19964][CORE] Avoid reading from remote repos in SparkSubmitSuite.
These tests can fail with a timeout if the remote repos are not responding,
or slow. The tests don't need anything from those repos, so use an empty
ivy config file to avoid setting up the defaults.
The tests are passing reliably for me locally now, and failing more often
than not today without this change since http://dl.bintray.com/spark-packages/maven
doesn't seem to be loading from my machine.
Author: Marcelo Vanzin <va...@cloudera.com>
Closes #20916 from vanzin/SPARK-19964.
commit 33b5849132707b8606605b608aadb1bc9886d221
Author: lemonjing <93...@...>
Date: 2018-04-03T01:36:44Z
[MINOR][DOC] Fix a few markdown typos
## What changes were proposed in this pull request?
Easy fix in the markdown.
## How was this patch tested?
jekyII build test manually.
Please review http://spark.apache.org/contributing.html before opening a pull request.
Author: lemonjing <93...@qq.com>
Closes #20897 from Lemonjing/master.
commit cf547b3d79569fcec7caa9acf764a1c07d8d491a
Author: Xingbo Jiang <xi...@...>
Date: 2018-04-03T13:26:49Z
[MINOR][CORE] Show block manager id when remove RDD/Broadcast fails.
## What changes were proposed in this pull request?
Address https://github.com/apache/spark/pull/20924#discussion_r177987175, show block manager id when remove RDD/Broadcast fails.
## How was this patch tested?
N/A
Author: Xingbo Jiang <xi...@databricks.com>
Closes #20960 from jiangxb1987/bmid.
commit b72b84838d6caefc9e9c641ab0bf612310e940c6
Author: Jose Torres <to...@...>
Date: 2018-04-03T18:05:29Z
[SPARK-23099][SS] Migrate foreach sink to DataSourceV2
## What changes were proposed in this pull request?
Migrate foreach sink to DataSourceV2.
Since the previous attempt at this PR #20552, we've changed and strictly defined the lifecycle of writer components. This means we no longer need the complicated lifecycle shim from that PR; it just naturally works.
## How was this patch tested?
existing tests
Author: Jose Torres <to...@gmail.com>
Closes #20951 from jose-torres/foreach.
commit 0bcf7e485c9e2858f9009c5d8c2f93f8ad995680
Author: Liang-Chi Hsieh <vi...@...>
Date: 2018-04-03T23:36:58Z
[SPARK-23587][SQL] Add interpreted execution for MapObjects expression
## What changes were proposed in this pull request?
Add interpreted execution for `MapObjects` expression.
## How was this patch tested?
Added unit test.
Author: Liang-Chi Hsieh <vi...@gmail.com>
Closes #20771 from viirya/SPARK-23587.
commit c7814542a74ffebefc33939f871eed9b0de9958c
Author: Eric Liang <ek...@...>
Date: 2018-04-04T00:09:12Z
[SPARK-23809][SQL] Active SparkSession should be set by getOrCreate
## What changes were proposed in this pull request?
Currently, the active spark session is set inconsistently (e.g., in createDataFrame, prior to query execution). Many places in spark also incorrectly query active session when they should be calling activeSession.getOrElse(defaultSession) and so might get None even if a Spark session exists.
The semantics here can be cleaned up if we also set the active session when the default session is set.
Related: https://github.com/apache/spark/pull/20926/files
## How was this patch tested?
Unit test, existing test. Note that if https://github.com/apache/spark/pull/20926 merges first we should also update the tests there.
Author: Eric Liang <ek...@databricks.com>
Closes #20927 from ericl/active-session-cleanup.
commit 150b653c86e9f0a9e45602675c5dd4257505d60f
Author: Robert Kruszewski <ro...@...>
Date: 2018-04-04T00:25:54Z
[SPARK-23802][SQL] PropagateEmptyRelation can leave query plan in unresolved state
## What changes were proposed in this pull request?
Add cast to nulls introduced by PropagateEmptyRelation so in cases they're part of coalesce they will not break its type checking rules
## How was this patch tested?
Added unit test
Author: Robert Kruszewski <ro...@palantir.com>
Closes #20914 from robert3005/rk/propagate-empty-fix.
commit d22e12e4c07fc4727565d3612eb32028edd673e3
Author: gatorsmile <ga...@...>
Date: 2018-04-04T06:31:03Z
[SPARK-23826][TEST] TestHiveSparkSession should set default session
## What changes were proposed in this pull request?
In TestHive, the base spark session does this in getOrCreate(), we emulate that behavior for tests.
## How was this patch tested?
N/A
Author: gatorsmile <ga...@gmail.com>
Closes #20969 from gatorsmile/setDefault.
commit 33658e4a4c39cd47e6ab376d0fdbcdd20d6e8bc3
Author: Takeshi Yamamuro <ya...@...>
Date: 2018-04-04T06:39:19Z
[SPARK-21351][SQL] Update nullability based on children's output
## What changes were proposed in this pull request?
This pr added a new optimizer rule `UpdateNullabilityInAttributeReferences ` to update the nullability that `Filter` changes when having `IsNotNull`. In the master, optimized plans do not respect the nullability when `Filter` has `IsNotNull`. This wrongly generates unnecessary code. For example:
```
scala> val df = Seq((Some(1), Some(2))).toDF("a", "b")
scala> val bIsNotNull = df.where($"b" =!= 2).select($"b")
scala> val targetQuery = bIsNotNull.distinct
scala> val targetQuery.queryExecution.optimizedPlan.output(0).nullable
res5: Boolean = true
scala> targetQuery.debugCodegen
Found 2 WholeStageCodegen subtrees.
== Subtree 1 / 2 ==
*HashAggregate(keys=[b#19], functions=[], output=[b#19])
+- Exchange hashpartitioning(b#19, 200)
+- *HashAggregate(keys=[b#19], functions=[], output=[b#19])
+- *Project [_2#16 AS b#19]
+- *Filter isnotnull(_2#16)
+- LocalTableScan [_1#15, _2#16]
Generated code:
...
/* 124 */ protected void processNext() throws java.io.IOException {
...
/* 132 */ // output the result
/* 133 */
/* 134 */ while (agg_mapIter.next()) {
/* 135 */ wholestagecodegen_numOutputRows.add(1);
/* 136 */ UnsafeRow agg_aggKey = (UnsafeRow) agg_mapIter.getKey();
/* 137 */ UnsafeRow agg_aggBuffer = (UnsafeRow) agg_mapIter.getValue();
/* 138 */
/* 139 */ boolean agg_isNull4 = agg_aggKey.isNullAt(0);
/* 140 */ int agg_value4 = agg_isNull4 ? -1 : (agg_aggKey.getInt(0));
/* 141 */ agg_rowWriter1.zeroOutNullBytes();
/* 142 */
// We don't need this NULL check because NULL is filtered out in `$"b" =!=2`
/* 143 */ if (agg_isNull4) {
/* 144 */ agg_rowWriter1.setNullAt(0);
/* 145 */ } else {
/* 146 */ agg_rowWriter1.write(0, agg_value4);
/* 147 */ }
/* 148 */ append(agg_result1);
/* 149 */
/* 150 */ if (shouldStop()) return;
/* 151 */ }
/* 152 */
/* 153 */ agg_mapIter.close();
/* 154 */ if (agg_sorter == null) {
/* 155 */ agg_hashMap.free();
/* 156 */ }
/* 157 */ }
/* 158 */
/* 159 */ }
```
In the line 143, we don't need this NULL check because NULL is filtered out in `$"b" =!=2`.
This pr could remove this NULL check;
```
scala> val targetQuery.queryExecution.optimizedPlan.output(0).nullable
res5: Boolean = false
scala> targetQuery.debugCodegen
...
Generated code:
...
/* 144 */ protected void processNext() throws java.io.IOException {
...
/* 152 */ // output the result
/* 153 */
/* 154 */ while (agg_mapIter.next()) {
/* 155 */ wholestagecodegen_numOutputRows.add(1);
/* 156 */ UnsafeRow agg_aggKey = (UnsafeRow) agg_mapIter.getKey();
/* 157 */ UnsafeRow agg_aggBuffer = (UnsafeRow) agg_mapIter.getValue();
/* 158 */
/* 159 */ int agg_value4 = agg_aggKey.getInt(0);
/* 160 */ agg_rowWriter1.write(0, agg_value4);
/* 161 */ append(agg_result1);
/* 162 */
/* 163 */ if (shouldStop()) return;
/* 164 */ }
/* 165 */
/* 166 */ agg_mapIter.close();
/* 167 */ if (agg_sorter == null) {
/* 168 */ agg_hashMap.free();
/* 169 */ }
/* 170 */ }
```
## How was this patch tested?
Added `UpdateNullabilityInAttributeReferencesSuite` for unit tests.
Author: Takeshi Yamamuro <ya...@apache.org>
Closes #18576 from maropu/SPARK-21351.
commit b15a6fdd7776ba539009daf80a83032b6b806b23
Author: Robert Kruszewski <ro...@...>
Date: 2018-04-03T18:05:07Z
fix ExecutorPodFactorySuite
commit 3bf80553f1c4c659de22dd1ac020bcb473a18a2f
Author: Robert Kruszewski <ro...@...>
Date: 2018-04-04T16:50:55Z
Merge pull request #353 from palantir/rk/upstream-bump
Small upstream bump
commit 80052c8831aba31c6437a90aa9ca10ee14c154f1
Author: Kazuaki Ishizaki <is...@...>
Date: 2018-04-04T16:36:15Z
[SPARK-23583][SQL] Invoke should support interpreted execution
## What changes were proposed in this pull request?
This pr added interpreted execution for `Invoke`.
## How was this patch tested?
Added tests in `ObjectExpressionsSuite`.
Author: Kazuaki Ishizaki <is...@jp.ibm.com>
Closes #20797 from kiszk/SPARK-28583.
commit 5178d0c6e33db10df837779d47a82454a71f22b0
Author: Andrew Korzhuev <an...@...>
Date: 2018-04-04T19:30:52Z
[SPARK-23668][K8S] Add config option for passing through k8s Pod.spec.imagePullSecrets
## What changes were proposed in this pull request?
Pass through the `imagePullSecrets` option to the k8s pod in order to allow user to access private image registries.
See https://kubernetes.io/docs/tasks/configure-pod-container/pull-image-private-registry/
## How was this patch tested?
Unit tests + manual testing.
Manual testing procedure:
1. Have private image registry.
2. Spark-submit application with no `spark.kubernetes.imagePullSecret` set. Do `kubectl describe pod ...`. See the error message:
```
Error syncing pod, skipping: failed to "StartContainer" for "spark-kubernetes-driver" with ErrImagePull: "rpc error: code = 2 desc = Error: Status 400 trying to pull repository ...: \"{\\n \\\"errors\\\" : [ {\\n \\\"status\\\" : 400,\\n \\\"message\\\" : \\\"Unsupported docker v1 repository request for '...'\\\"\\n } ]\\n}\""
```
3. Create secret `kubectl create secret docker-registry ...`
4. Spark-submit with `spark.kubernetes.imagePullSecret` set to the new secret. See that deployment was successful.
Author: Andrew Korzhuev <an...@klarna.com>
Author: Andrew Korzhuev <ko...@andrusha.me>
Closes #20811 from andrusha/spark-23668-image-pull-secrets.
commit 1f01d81aa9aae5d37cfcebddd2a213db85c80128
Author: Gengliang Wang <ge...@...>
Date: 2018-04-04T22:43:58Z
[SPARK-23838][WEBUI] Running SQL query is displayed as "completed" in SQL tab
## What changes were proposed in this pull request?
A running SQL query would appear as completed in the Spark UI:

We can see the query in "Completed queries", while in in the job page we see it's still running Job 132.
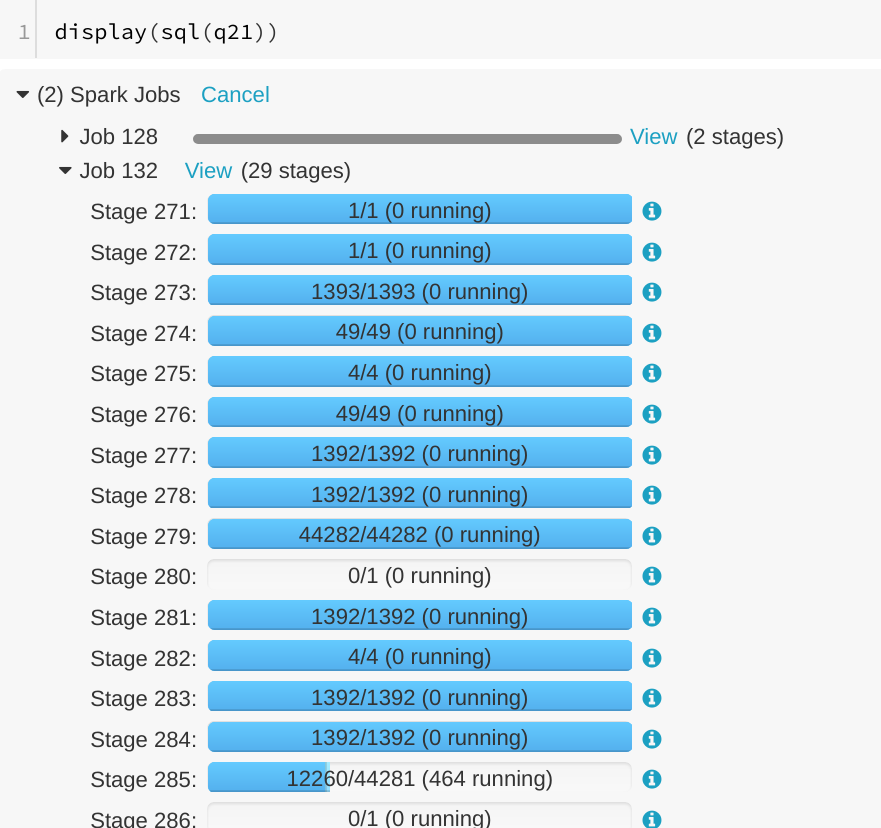
After some time in the query still appears in "Completed queries" (while it's still running), but the "Duration" gets increased.

To reproduce, we can run a query with multiple jobs. E.g. Run TPCDS q6.
The reason is that updates from executions are written into kvstore periodically, and the job start event may be missed.
## How was this patch tested?
Manually run the job again and check the SQL Tab. The fix is pretty simple.
Author: Gengliang Wang <ge...@databricks.com>
Closes #20955 from gengliangwang/jobCompleted.
commit ff98d78881177bb48acc33615b8708a0e473b102
Author: jinxing <ji...@...>
Date: 2018-04-04T22:51:27Z
[SPARK-23637][YARN] Yarn might allocate more resource if a same executor is killed multiple times.
## What changes were proposed in this pull request?
`YarnAllocator` uses `numExecutorsRunning` to track the number of running executor. `numExecutorsRunning` is used to check if there're executors missing and need to allocate more.
In current code, `numExecutorsRunning` can be negative when driver asks to kill a same idle executor multiple times.
## How was this patch tested?
UT added
Author: jinxing <ji...@126.com>
Closes #20781 from jinxing64/SPARK-23637.
commit 63ea8773f617aaf249ebf0bb69587ed06c397caa
Author: Liang-Chi Hsieh <vi...@...>
Date: 2018-04-05T11:39:45Z
[SPARK-23593][SQL] Add interpreted execution for InitializeJavaBean expression
## What changes were proposed in this pull request?
Add interpreted execution for `InitializeJavaBean` expression.
## How was this patch tested?
Added unit test.
Author: Liang-Chi Hsieh <vi...@gmail.com>
Closes #20756 from viirya/SPARK-23593.
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #23179: Fix the rat excludes on .policy.yml
Posted by justinuang <gi...@git.apache.org>.
Github user justinuang closed the pull request at:
https://github.com/apache/spark/pull/23179
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org