You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2021/02/20 03:25:42 UTC
[GitHub] [spark] AngersZhuuuu opened a new pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
AngersZhuuuu opened a new pull request #31598:
URL: https://github.com/apache/spark/pull/31598
### What changes were proposed in this pull request?
Some user who not so clear about spark when build SparkSession
```
SparkSession.builder().config()
```
In this method user may config `spark.driver.memory` then he will think when submit job, spark driver's memory is change. But when we run this code, JVM has been started, so this configuration won't work at all. And in Spark UI, it will show `spark.driver.memory` as this configuration set by `SparkSession.builder().config()`. This makes user and administer confuse.
So we should ignore such as wrong way and logwarn.
### Why are the changes needed?
Make usage more clear
### Does this PR introduce _any_ user-facing change?
No, this pr only handle wrong use case.
### How was this patch tested?
WIP
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787729731
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40158/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787632493
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40156/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-788093819
**[Test build #135597 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135597/testReport)** for PR 31598 at commit [`7cee11e`](https://github.com/apache/spark/commit/7cee11e564cc2fb794ca77b664e8c9bf0673514f).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581643234
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
Review comment:
We can document first, and then link the documentation URL in the warning message.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785622024
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40031/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584236782
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,22 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+
+ 1. configuration used to submit application, such as "spark.driver.memory", "spark.driver.extraclassPath",
Review comment:
> This text needs a fair bit of cleanup - capitalization, punctuation, syntax. Break lists of configs into a list and code quote, and so on
How about current? Make it as a list I think it will be more clear.
Also cc @dongjoon-hyun @maropu @HyukjinKwon , hope for your suggest to make it more clear and accurate.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787661428
**[Test build #135574 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135574/testReport)** for PR 31598 at commit [`c1d9aa7`](https://github.com/apache/spark/commit/c1d9aa736a592b883abebd285ad981ec787f78c6).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787011403
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135529/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787988407
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40178/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
srowen commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787605028
I don't see what that column adds that the description cannot? it also squishes the horizontal space for the description.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584393540
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
Review comment:
`Remark` -> `Examples`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r586110532
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
yea, something like `.scope`.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785643448
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40035/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582541755
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
+ " https://spark.apache.org/docs/latest/configuration.html" +
Review comment:
Is it okay to always refer to the `latest` page?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-788095929
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135597/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581642779
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
Review comment:
@AngersZhuuuu, I would first document this explicitly and what happen for each configuration before taking an action to show a warning. Also, shouldn't we do this in `SparkContext`?
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
Review comment:
`spark.master` seems not here?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581642779
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
Review comment:
@AngersZhuuuu, I would first document this explicitly and what happen for each configuration before taking an action to show a warning. Also, shouldn't we do this in `SparkContext` too?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584394455
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
Review comment:
`Scope` is a correct word here? `Effective Timing` instead?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782591823
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39880/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782578304
**[Test build #135299 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135299/testReport)** for PR 31598 at commit [`4db4c05`](https://github.com/apache/spark/commit/4db4c0599f1db93bbf87969f449ffe69f8dda4c1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
srowen commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584313063
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
Review comment:
_an_ application
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
Review comment:
Lauch -> Launch
I think this is better as "Configurations needed at driver launch"?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
+ `spark.driver.extraLibraryPath`<br/>
+ `spark.driver.resource.*`<br/>
+ `spark.pyspark.driver.python`<br/>
+ `spark.pyspark.python`<br/>
+ `spark.r.shell.command`<br/>
+ `spark.launcher.childProcLoggerName`<br/>
+ `spark.launcher.childConnectionTimeout`<br/>
+ `spark.yarn.driver.*`
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>Effect before start SparkContext.</td>
+ <td>
+ Like "spark.master", "spark.executor.instances", this kind of properties may not
+ be affected when setting programmatically through `SparkConf` in runtime after SparkContext has been started,
+ or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to
+ set through configuration file, `spark-submit` command line options, or setting programmatically through `SparkConf`
+ in runtime before start SparkContext.
+ </td>
+ <td>
+
+ </td>
+</tr>
+<tr>
+ <td><code>Spark Runtime Control Related Configuration</code></td>
+ <td>Effect when runtime.</td>
Review comment:
I am not sure this extra column helps. Move this into the description.
##########
File path: docs/configuration.md
##########
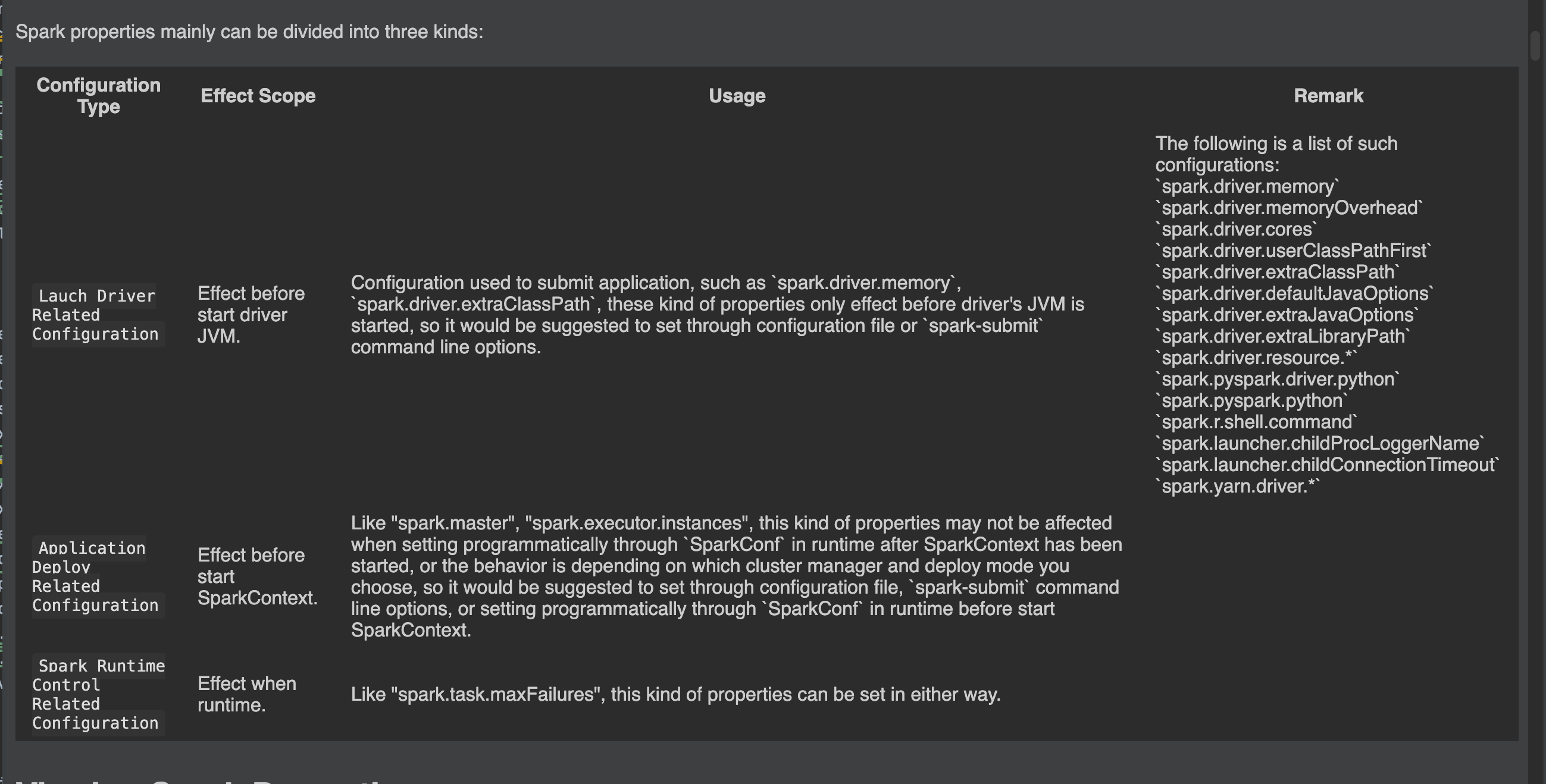
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
Review comment:
Can you use a `<ul>` here?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
Review comment:
Start a new sentence.
It's not suggested, it's required, right?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
+ `spark.driver.extraLibraryPath`<br/>
+ `spark.driver.resource.*`<br/>
+ `spark.pyspark.driver.python`<br/>
+ `spark.pyspark.python`<br/>
+ `spark.r.shell.command`<br/>
+ `spark.launcher.childProcLoggerName`<br/>
+ `spark.launcher.childConnectionTimeout`<br/>
+ `spark.yarn.driver.*`
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>Effect before start SparkContext.</td>
+ <td>
+ Like "spark.master", "spark.executor.instances", this kind of properties may not
Review comment:
Back-tick quote for consistency
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
+ `spark.driver.extraLibraryPath`<br/>
+ `spark.driver.resource.*`<br/>
+ `spark.pyspark.driver.python`<br/>
+ `spark.pyspark.python`<br/>
+ `spark.r.shell.command`<br/>
+ `spark.launcher.childProcLoggerName`<br/>
+ `spark.launcher.childConnectionTimeout`<br/>
+ `spark.yarn.driver.*`
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>Effect before start SparkContext.</td>
+ <td>
+ Like "spark.master", "spark.executor.instances", this kind of properties may not
+ be affected when setting programmatically through `SparkConf` in runtime after SparkContext has been started,
+ or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to
+ set through configuration file, `spark-submit` command line options, or setting programmatically through `SparkConf`
+ in runtime before start SparkContext.
+ </td>
+ <td>
+
+ </td>
+</tr>
+<tr>
+ <td><code>Spark Runtime Control Related Configuration</code></td>
+ <td>Effect when runtime.</td>
+ <td>
+ Like "spark.task.maxFailures", this kind of properties can be set in either way.
Review comment:
Just say "all other properties can be set either way"
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584417267
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
Review comment:
Done
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
Review comment:
Done
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
+ `spark.driver.extraLibraryPath`<br/>
+ `spark.driver.resource.*`<br/>
+ `spark.pyspark.driver.python`<br/>
+ `spark.pyspark.python`<br/>
+ `spark.r.shell.command`<br/>
+ `spark.launcher.childProcLoggerName`<br/>
+ `spark.launcher.childConnectionTimeout`<br/>
+ `spark.yarn.driver.*`
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>Effect before start SparkContext.</td>
+ <td>
+ Like "spark.master", "spark.executor.instances", this kind of properties may not
Review comment:
Dne
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584450921
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Spark Runtime Control Related Configuration</code></td>
Review comment:
> Or even we can just remove this section.
Remove LCTM, since this part may make user confused.
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Spark Runtime Control Related Configuration</code></td>
Review comment:
> Or even we can just remove this section.
Remove LGTM, since this part may make user confused.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787608522
**[Test build #135574 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135574/testReport)** for PR 31598 at commit [`c1d9aa7`](https://github.com/apache/spark/commit/c1d9aa736a592b883abebd285ad981ec787f78c6).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r586056526
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
> It seems like something we should build into our config library. It's hard to maintain this list here.
You mean like what I have said in https://github.com/apache/spark/pull/31598#discussion_r581689593.
We should add a new tag in ConfigEntry? like `.version()` we add `.type()` or `.scope()` ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787411244
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40131/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782599593
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39878/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584021940
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
+ " https://spark.apache.org/docs/latest/configuration.html" +
Review comment:
It seems you need to drop the suffix: `3.2.0-SNAPSHOT` -> `3.2.0`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785625515
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40033/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-799926468
Any more suggestion @cloud-fan ?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-799942236
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584417333
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
+ `spark.driver.extraLibraryPath`<br/>
+ `spark.driver.resource.*`<br/>
+ `spark.pyspark.driver.python`<br/>
+ `spark.pyspark.python`<br/>
+ `spark.r.shell.command`<br/>
+ `spark.launcher.childProcLoggerName`<br/>
+ `spark.launcher.childConnectionTimeout`<br/>
+ `spark.yarn.driver.*`
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>Effect before start SparkContext.</td>
+ <td>
+ Like "spark.master", "spark.executor.instances", this kind of properties may not
+ be affected when setting programmatically through `SparkConf` in runtime after SparkContext has been started,
+ or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to
+ set through configuration file, `spark-submit` command line options, or setting programmatically through `SparkConf`
+ in runtime before start SparkContext.
+ </td>
+ <td>
+
+ </td>
+</tr>
+<tr>
+ <td><code>Spark Runtime Control Related Configuration</code></td>
+ <td>Effect when runtime.</td>
+ <td>
+ Like "spark.task.maxFailures", this kind of properties can be set in either way.
Review comment:
Done
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
Review comment:
Done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r586168932
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
> I'm not good at naming. Basically there are 3 effective timing:
>
> 1. when launching the JVM
> 2. when building the spark context
> 3. completely dynamic (sql session configs)
So here should I add back the third type configuration? Since I have remove that section https://github.com/apache/spark/pull/31598#discussion_r584449917
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787658567
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40156/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787401855
**[Test build #135550 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135550/testReport)** for PR 31598 at commit [`a61f2d6`](https://github.com/apache/spark/commit/a61f2d6bfa9f5d4d77fe879944438fe719c54cd0).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785649478
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787615144
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40155/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584707419
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
eh, `Effective Timing`? cc: @srowen @HyukjinKwon
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785637349
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40033/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782586207
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39880/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584450385
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
Review comment:
> Can we actually list all of them if there are not so many of them?
too many, and we need to check them one by one..
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782585748
**[Test build #135302 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135302/testReport)** for PR 31598 at commit [`02a1c9b`](https://github.com/apache/spark/commit/02a1c9b0b000243d459376161575f57817768a2c).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782602215
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39882/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787976978
**[Test build #135597 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135597/testReport)** for PR 31598 at commit [`7cee11e`](https://github.com/apache/spark/commit/7cee11e564cc2fb794ca77b664e8c9bf0673514f).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
srowen commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584136599
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,22 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+
+ 1. configuration used to submit application, such as "spark.driver.memory", "spark.driver.extraclassPath",
Review comment:
This text needs a fair bit of cleanup - capitalization, punctuation, syntax. Break lists of configs into a list and code quote, and so on
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787781965
**[Test build #135577 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135577/testReport)** for PR 31598 at commit [`8e637b8`](https://github.com/apache/spark/commit/8e637b81a6970656f49521e1e82c9a86ffd99221).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782596809
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39878/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584685902
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
Review comment:
`Application Deployment` -> `Deploying Application` according to `Launching Driver`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
Review comment:
`Configuration` -> `Configurations`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
Review comment:
`through configuration file` -> `through a configuration file`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
Review comment:
`configuration file` -> `a configuration file`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
Review comment:
`these kind` -> `these kinds`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
Review comment:
`SparkContext` -> `<code>SparkContext</code>`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
Is this title "`Configuration Type`" suitable for `Launching Driver` and `Application Deployment`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
Review comment:
`driver's JVM` -> `a driver JVM`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
Review comment:
`before start SparkContext. ` -> `before starting SparkContext. `
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
Review comment:
`and deploy mode` -> `and the deploy mode`?
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
Review comment:
`is depending` -> `depends`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r579603890
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,36 @@ object SparkSession extends Logging {
this
}
+ // These submit configuration only effect when config before submit app.
+ private val SUBMIT_LAUNCHER_CONFIG =
+ Seq(SPARK_MASTER, DEPLOY_MODE, DRIVER_MEMORY, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL, CHILD_PROCESS_LOGGER_NAME,
+ CHILD_CONNECTION_TIMEOUT)
+
+ // These configuration can effect when SparkContext is not started.
+ private val EXECUTOR_LAUNCHER_CONFIG =
+ Seq(EXECUTOR_MEMORY, EXECUTOR_EXTRA_CLASSPATH, EXECUTOR_DEFAULT_JAVA_OPTIONS,
+ EXECUTOR_EXTRA_JAVA_OPTIONS, EXECUTOR_EXTRA_LIBRARY_PATH, EXECUTOR_CORES)
+
+ def checkAndSetConfig(key: String, value: String): Unit = {
+ if (SparkContext.getActive.isEmpty) {
+ if (SUBMIT_LAUNCHER_CONFIG.contains(key)) {
+ logWarning(s"Since spark has been started, configuration ${key} won't work" +
+ s" when set it here")
Review comment:
> Can we have a directional guide instead of `xxx won't work when set it here`?
Yea, I will make it more clear according to the doc you refer to.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785672583
**[Test build #135453 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135453/testReport)** for PR 31598 at commit [`f61dd66`](https://github.com/apache/spark/commit/f61dd66aa8b7c0da0606a5df550d00e78b451fbc).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787009803
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40110/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582542903
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
+ " https://spark.apache.org/docs/latest/configuration.html" +
Review comment:
> Is it okay to always refer to the `latest` page?
Hmmmm, for current spark version maybe better?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582544162
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
+ " https://spark.apache.org/docs/latest/configuration.html" +
Review comment:
yea, I think so if possible.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584448955
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
Review comment:
Can we actually list all of them?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785621017
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40031/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584022314
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
Review comment:
nit: for following the other formats in this file, could you move the leading single space into the previous line?
```
logWarning("Using an existing SparkContext; some configuration may not take effect. " +
"For how to set these configuration correctly, you can refer to" +
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785622024
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40031/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582554110
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
+ " https://spark.apache.org/docs/latest/configuration.html" +
Review comment:
Yea, updated.
Current demo warn log is
```
13:23:48.133 WARN org.apache.spark.sql.SparkSession$Builder: Since spark has been submitted, such configurations `spark.driver.memory -> 1g` may not take effect. For how to set these configuration correctly, you can refer to https://spark.apache.org/docs/3.2.0-SNAPSHOT/configuration.html#dynamically-loading-spark-properties.
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787411244
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40131/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782557550
**[Test build #135288 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135288/testReport)** for PR 31598 at commit [`675d35f`](https://github.com/apache/spark/commit/675d35f1ce978930c760d173e04c7c38a9e77526).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782606138
**[Test build #135302 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135302/testReport)** for PR 31598 at commit [`02a1c9b`](https://github.com/apache/spark/commit/02a1c9b0b000243d459376161575f57817768a2c).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582443088
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -914,7 +933,34 @@ object SparkSession extends Logging {
*/
def getOrCreate(): SparkSession = synchronized {
val sparkConf = new SparkConf()
- options.foreach { case (k, v) => sparkConf.set(k, v) }
+ val (nonEffectConfigurations, mayEffectConfigurations) =
+ options.partition((DRIVER_RELATED_LAUNCHER_CONFIG).contains)
+
+ if (nonEffectConfigurations.nonEmpty) {
+ logWarning(
+ s"""Since spark has been started, such configuration
+ | `${nonEffectConfigurations.mkString(", ")}` may not be affected when setting
+ | programmatically through SparkConf in runtime, or the behavior is depending
+ | on which cluster manager and deploy mode you choose, so it would be suggested to
+ | set through configuration file or spark-submit command line options.
+ |""".stripMargin)
+ }
+
+ val (scAlreadySetConfigurations, normalConfigs) =
+ mayEffectConfigurations.partition(EXECUTOR_LAUNCHER_CONFIG.contains)
+
+ if (SparkContext.getActive.isDefined) {
Review comment:
> I think `SparkConf` is immutable and we cannot change configuration once `SparkContext` is launched?
Yea, we don't add this check.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782593590
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39882/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787662639
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135574/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787417275
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135550/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787658567
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40156/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787810973
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135577/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-786568356
Any more update?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782583567
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135299/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-802461832
You've already opened a new PR to address the @cloud-fan comment? https://github.com/apache/spark/pull/31598#discussion_r586155367 The direction looks reasonable to me, too. That should be resolved first.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582506824
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
Review comment:
> I think you can just add some docs for each configuration like from `blah blah` to `(Launcher scope) blah blah` or something like this.
Updated, how about current?
Warn message like
```
11:38:42.540 WARN org.apache.spark.sql.SparkSession$Builder: Since spark has been submitted, such configurations
`spark.driver.memory -> 1g` may not take effect.
For how to set these configuration correctly, you can refer to
https://spark.apache.org/docs/latest/configuration.html#dynamically-loading-spark-properties.
```
Aslo ping @dongjoon-hyun @maropu
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-796503821
> Add the `scope` sounds good! Another usage is about `SetCommand` which used in SQL server like `ThirftServer` , some poeple might execute `set spark.app.name=xx` which seems like Hive command `set mapred.job.name=xxx`.
>
> If we have such a tag, it would be easy to give friendly reminder for user.
Yea, nice case. I meet such concerns too before.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785657948
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40035/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-805552780
> You've already opened a new PR to address the @cloud-fan comment? [#31598 (comment)](https://github.com/apache/spark/pull/31598#discussion_r586155367) The direction looks reasonable to me, too. That should be resolved first.
Not completed, Still working on this.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782583567
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135299/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787645721
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40156/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r586116354
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
> yea, something like `.scope`.
yea. should we do it in this pr or a new one? since add tag and check is different things
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584450435
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
Review comment:
> I think you can remove etc ...
Ok, remove `etc`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787608522
**[Test build #135574 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135574/testReport)** for PR 31598 at commit [`c1d9aa7`](https://github.com/apache/spark/commit/c1d9aa736a592b883abebd285ad981ec787f78c6).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584393002
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
Review comment:
`Usage` -> `Meaning`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787401855
**[Test build #135550 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135550/testReport)** for PR 31598 at commit [`a61f2d6`](https://github.com/apache/spark/commit/a61f2d6bfa9f5d4d77fe879944438fe719c54cd0).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584022481
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -914,7 +927,21 @@ object SparkSession extends Logging {
*/
def getOrCreate(): SparkSession = synchronized {
val sparkConf = new SparkConf()
- options.foreach { case (k, v) => sparkConf.set(k, v) }
+ val (nonEffectConfigurations, mayEffectConfigurations) =
+ options.partition { case (key: String, _) =>
+ DRIVER_RELATED_LAUNCHER_CONFIG.exists(keys => key.startsWith(keys))
+ }
+
+ if (nonEffectConfigurations.nonEmpty) {
+ logWarning(
+ "Since spark has been submitted, such configurations" +
+ s" `${nonEffectConfigurations.mkString(", ")}` may not take effect." +
Review comment:
ditto
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782560941
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39867/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787991491
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40178/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787729731
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40158/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785605854
**[Test build #135453 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135453/testReport)** for PR 31598 at commit [`f61dd66`](https://github.com/apache/spark/commit/f61dd66aa8b7c0da0606a5df550d00e78b451fbc).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
github-actions[bot] closed pull request #31598:
URL: https://github.com/apache/spark/pull/31598
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785609910
**[Test build #135451 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135451/testReport)** for PR 31598 at commit [`8a0defc`](https://github.com/apache/spark/commit/8a0defc5b55f24fd9e375a7846871da6b62f4182).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787615152
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40155/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-786996892
**[Test build #135529 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135529/testReport)** for PR 31598 at commit [`1f1e2ed`](https://github.com/apache/spark/commit/1f1e2eddb0b016897b2267c9a0dab9cb7855043a).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782582371
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39880/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r585666704
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
It seems like something we should build into our config library. It's hard to maintain this list here.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584450825
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
@AngersZhuuuu, are they all configurations to include? is it just a subset of them?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787603527
> For reviews, could you add the screenshot of the updated doc part?
Done. Update it in PR desc.
@srowen I haven't remove `effect timing` column yet. @maropu Do you think we should remove that column?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785609025
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40031/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787005938
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40110/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787615152
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40155/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584027706
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
Review comment:
> nit: for following the other formats in this file, could you move the leading single space into the previous line?
>
> ```
> logWarning("Using an existing SparkContext; some configuration may not take effect. " +
> "For how to set these configuration correctly, you can refer to" +
> ```
Done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584449917
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Spark Runtime Control Related Configuration</code></td>
Review comment:
Or even we can just remove this section.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-783006685
ping @dongjoon-hyun Any suggestion?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584448955
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
Review comment:
Can we actually list all of them if there are not so many of them?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584392480
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
Review comment:
Could you wrap these configs with `<code>` to follow the other formats in this page?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787622956
**[Test build #135575 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135575/testReport)** for PR 31598 at commit [`3f795f5`](https://github.com/apache/spark/commit/3f795f575d4fc783358cd134500edd6f78545155).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785681017
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r586168512
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
> We can do that in a new PR, and merge that PR first.
Ok, I think it's a very usage improvement, since many user don't understand spark's configuration very well.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782607577
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584027678
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
+ " https://spark.apache.org/docs/latest/configuration.html" +
Review comment:
> It seems you need to drop the suffix: `3.2.0-SNAPSHOT` -> `3.2.0`
Done
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -914,7 +927,21 @@ object SparkSession extends Logging {
*/
def getOrCreate(): SparkSession = synchronized {
val sparkConf = new SparkConf()
- options.foreach { case (k, v) => sparkConf.set(k, v) }
+ val (nonEffectConfigurations, mayEffectConfigurations) =
+ options.partition { case (key: String, _) =>
+ DRIVER_RELATED_LAUNCHER_CONFIG.exists(keys => key.startsWith(keys))
+ }
+
+ if (nonEffectConfigurations.nonEmpty) {
+ logWarning(
+ "Since spark has been submitted, such configurations" +
+ s" `${nonEffectConfigurations.mkString(", ")}` may not take effect." +
Review comment:
Done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r579613517
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,36 @@ object SparkSession extends Logging {
this
}
+ // These submit configuration only effect when config before submit app.
+ private val SUBMIT_LAUNCHER_CONFIG =
+ Seq(SPARK_MASTER, DEPLOY_MODE, DRIVER_MEMORY, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL, CHILD_PROCESS_LOGGER_NAME,
+ CHILD_CONNECTION_TIMEOUT)
+
+ // These configuration can effect when SparkContext is not started.
+ private val EXECUTOR_LAUNCHER_CONFIG =
+ Seq(EXECUTOR_MEMORY, EXECUTOR_EXTRA_CLASSPATH, EXECUTOR_DEFAULT_JAVA_OPTIONS,
+ EXECUTOR_EXTRA_JAVA_OPTIONS, EXECUTOR_EXTRA_LIBRARY_PATH, EXECUTOR_CORES)
+
+ def checkAndSetConfig(key: String, value: String): Unit = {
+ if (SparkContext.getActive.isEmpty) {
+ if (SUBMIT_LAUNCHER_CONFIG.contains(key)) {
+ logWarning(s"Since spark has been started, configuration ${key} won't work" +
+ s" when set it here")
Review comment:
> Can we have a directional guide instead of `xxx won't work when set it here`?
Change
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785674056
**[Test build #135451 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135451/testReport)** for PR 31598 at commit [`8a0defc`](https://github.com/apache/spark/commit/8a0defc5b55f24fd9e375a7846871da6b62f4182).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782561703
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39867/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787662639
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135574/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r586155367
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
We can do that in a new PR, and merge that PR first.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584417524
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
Review comment:
Done
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
+ `spark.driver.extraLibraryPath`<br/>
+ `spark.driver.resource.*`<br/>
+ `spark.pyspark.driver.python`<br/>
+ `spark.pyspark.python`<br/>
+ `spark.r.shell.command`<br/>
+ `spark.launcher.childProcLoggerName`<br/>
+ `spark.launcher.childConnectionTimeout`<br/>
+ `spark.yarn.driver.*`
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>Effect before start SparkContext.</td>
+ <td>
+ Like "spark.master", "spark.executor.instances", this kind of properties may not
+ be affected when setting programmatically through `SparkConf` in runtime after SparkContext has been started,
+ or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to
+ set through configuration file, `spark-submit` command line options, or setting programmatically through `SparkConf`
+ in runtime before start SparkContext.
+ </td>
+ <td>
+
Review comment:
Add some example
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
Review comment:
Done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787612915
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40155/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782607577
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782584041
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39878/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782578304
**[Test build #135299 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135299/testReport)** for PR 31598 at commit [`4db4c05`](https://github.com/apache/spark/commit/4db4c0599f1db93bbf87969f449ffe69f8dda4c1).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581775404
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
Review comment:
I think you can just add some docs for each configuration like from `blah blah` to `(Launcher scope) blah blah` or something like this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582548018
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect." +
+ " For how to set these configuration correctly, you can refer to" +
+ " https://spark.apache.org/docs/latest/configuration.html" +
Review comment:
Yeah, if possible that would be great. See also `SparkVersion` expression.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r586111020
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
I'm not good at naming. Basically there are 3 effective timing:
1. when launching the JVM
2. when building the spark context
3. completely dynamic (sql session configs)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782571943
**[Test build #135288 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135288/testReport)** for PR 31598 at commit [`675d35f`](https://github.com/apache/spark/commit/675d35f1ce978930c760d173e04c7c38a9e77526).
* This patch **fails Spark unit tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787406022
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40131/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584450407
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
Review comment:
I would use titles, for example as below instead of "Configurations needed at driver launch" or "Application Deploy Related Configuration"
- Configuration: Launching Driver
- Configuration: Application Deployment
We could also think about having a parent group "Configuration" and place them under it.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-788001455
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40178/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584453075
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
Review comment:
Update to
```
Configuration: Launching Driver
Configuration: Application Deployment
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787698217
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40158/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r585205109
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
Hmm any result? also cc @cloud-fan
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584700846
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
`Effect Timing`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782568954
> Although [we had a similar document since Apache Spark 2.3.0](https://github.com/apache/spark/commit/457dc9ccbf8404fef6c1ebf8f82e59e4ba480a0e), I agree with @AngersZhuuuu 's suggestion because these are very frequent Q&A.
To be honest, not all user will read all usage document and they even not know too much about the whole process of spark, then they don't understand what is saying in the document .
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r579613517
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,36 @@ object SparkSession extends Logging {
this
}
+ // These submit configuration only effect when config before submit app.
+ private val SUBMIT_LAUNCHER_CONFIG =
+ Seq(SPARK_MASTER, DEPLOY_MODE, DRIVER_MEMORY, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL, CHILD_PROCESS_LOGGER_NAME,
+ CHILD_CONNECTION_TIMEOUT)
+
+ // These configuration can effect when SparkContext is not started.
+ private val EXECUTOR_LAUNCHER_CONFIG =
+ Seq(EXECUTOR_MEMORY, EXECUTOR_EXTRA_CLASSPATH, EXECUTOR_DEFAULT_JAVA_OPTIONS,
+ EXECUTOR_EXTRA_JAVA_OPTIONS, EXECUTOR_EXTRA_LIBRARY_PATH, EXECUTOR_CORES)
+
+ def checkAndSetConfig(key: String, value: String): Unit = {
+ if (SparkContext.getActive.isEmpty) {
+ if (SUBMIT_LAUNCHER_CONFIG.contains(key)) {
+ logWarning(s"Since spark has been started, configuration ${key} won't work" +
+ s" when set it here")
Review comment:
> Can we have a directional guide instead of `xxx won't work when set it here`?
Change code to check these in `getOrCreate` to check all case together, avoid to log too much information.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782560441
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/39867/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787660281
**[Test build #135577 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135577/testReport)** for PR 31598 at commit [`8e637b8`](https://github.com/apache/spark/commit/8e637b81a6970656f49521e1e82c9a86ffd99221).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782599593
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39878/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787415281
**[Test build #135550 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135550/testReport)** for PR 31598 at commit [`a61f2d6`](https://github.com/apache/spark/commit/a61f2d6bfa9f5d4d77fe879944438fe719c54cd0).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
srowen commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584712926
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
I don't know, "Configuration Time"?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-793286274
> This might get a little hard to remember to maintain, but pretty OK. @cloud-fan WDYT?
After https://github.com/apache/spark/pull/31598#discussion_r586110532, I think it will be easier.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787009803
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40110/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787003244
Kubernetes integration test starting
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40110/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-788095929
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135597/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584421357
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
Review comment:
Done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787698737
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135575/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782557550
**[Test build #135288 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135288/testReport)** for PR 31598 at commit [`675d35f`](https://github.com/apache/spark/commit/675d35f1ce978930c760d173e04c7c38a9e77526).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785609910
**[Test build #135451 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135451/testReport)** for PR 31598 at commit [`8a0defc`](https://github.com/apache/spark/commit/8a0defc5b55f24fd9e375a7846871da6b62f4182).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782585748
**[Test build #135302 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135302/testReport)** for PR 31598 at commit [`02a1c9b`](https://github.com/apache/spark/commit/02a1c9b0b000243d459376161575f57817768a2c).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782576170
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135288/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
dongjoon-hyun commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r579602687
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,36 @@ object SparkSession extends Logging {
this
}
+ // These submit configuration only effect when config before submit app.
+ private val SUBMIT_LAUNCHER_CONFIG =
+ Seq(SPARK_MASTER, DEPLOY_MODE, DRIVER_MEMORY, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL, CHILD_PROCESS_LOGGER_NAME,
+ CHILD_CONNECTION_TIMEOUT)
+
+ // These configuration can effect when SparkContext is not started.
+ private val EXECUTOR_LAUNCHER_CONFIG =
+ Seq(EXECUTOR_MEMORY, EXECUTOR_EXTRA_CLASSPATH, EXECUTOR_DEFAULT_JAVA_OPTIONS,
+ EXECUTOR_EXTRA_JAVA_OPTIONS, EXECUTOR_EXTRA_LIBRARY_PATH, EXECUTOR_CORES)
+
+ def checkAndSetConfig(key: String, value: String): Unit = {
+ if (SparkContext.getActive.isEmpty) {
+ if (SUBMIT_LAUNCHER_CONFIG.contains(key)) {
+ logWarning(s"Since spark has been started, configuration ${key} won't work" +
+ s" when set it here")
Review comment:
Can we have a directional guide instead of `xxx won't work when set it here`?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-799942237
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787810973
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135577/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581689593
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
Review comment:
> @AngersZhuuuu, I would first document this explicitly and what happen for each configuration before taking an action to show a warning. Also, shouldn't we do this in `SparkContext` too?
How about we add a new section in https://spark.apache.org/docs/latest/configuration.html to collect and show configuration's usage scope.
Also we can add a `scope` tag in ConfigBuilder for these special configuration.
Then in this pr, we can just check the config type and warn message.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782578463
**[Test build #135299 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135299/testReport)** for PR 31598 at commit [`4db4c05`](https://github.com/apache/spark/commit/4db4c0599f1db93bbf87969f449ffe69f8dda4c1).
* This patch **fails Scala style tests**.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584449845
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Spark Runtime Control Related Configuration</code></td>
Review comment:
Can we explicitly say we only allow this when creating SparkContext? SparkContext should not set SparkConf.
I think we don't need to mention about SQL configurations here.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582558041
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
Review comment:
> `spark.master` seems not here?
Remove this.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787410249
Kubernetes integration test status failure
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40131/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-788001455
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/40178/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787622956
**[Test build #135575 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135575/testReport)** for PR 31598 at commit [`3f795f5`](https://github.com/apache/spark/commit/3f795f575d4fc783358cd134500edd6f78545155).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787608231
> I don't see what that column adds that the description cannot? it also squishes the horizontal space for the description.
Remove it .
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787660281
**[Test build #135577 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135577/testReport)** for PR 31598 at commit [`8e637b8`](https://github.com/apache/spark/commit/8e637b81a6970656f49521e1e82c9a86ffd99221).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787562300
For reviews, could you add the screenshot of the updated doc part?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
github-actions[bot] commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-873311100
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable.
If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785605854
**[Test build #135453 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135453/testReport)** for PR 31598 at commit [`f61dd66`](https://github.com/apache/spark/commit/f61dd66aa8b7c0da0606a5df550d00e78b451fbc).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584451204
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,18 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
+ private val DRIVER_RELATED_LAUNCHER_CONFIG = Seq(DRIVER_MEMORY, DRIVER_CORES.key,
+ DRIVER_MEMORY_OVERHEAD.key, DRIVER_EXTRA_CLASSPATH,
+ DRIVER_DEFAULT_JAVA_OPTIONS, DRIVER_EXTRA_JAVA_OPTIONS, DRIVER_EXTRA_LIBRARY_PATH,
+ "spark.driver.resource", PYSPARK_DRIVER_PYTHON, PYSPARK_PYTHON, SPARKR_R_SHELL,
+ CHILD_PROCESS_LOGGER_NAME, CHILD_CONNECTION_TIMEOUT, DRIVER_USER_CLASS_PATH_FIRST.key,
+ "spark.yarn.*")
Review comment:
> @AngersZhuuuu, are they all configurations to include? is it just a subset of them?
That's what I found through configuration page. I am not sure if there is configurations in code that I missed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785649478
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787011403
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135529/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584447955
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,67 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Configurations needed at driver launch</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
+ </td>
+ <td>
+ The following is a example such configurations:
+ <ul>
+ <li><code>spark.master</code></li>
+ <li><code>spark.app.name</code></li>
+ <li><code>spark.executor.memory</code></li>
+ <li><code>spark.submit.deployMode</code></li>
+ <li><code>spark.eventLog.enabled</code></li>
+ <li><code>etc...</code></li>
Review comment:
I think you can remove etc ...
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584395887
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
Review comment:
How about saying `Spark properties mainly can be divided into three kinds: ` -> `Note that Spark properties have different effective timing and they can be divided into three kinds:`
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-786996892
**[Test build #135529 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135529/testReport)** for PR 31598 at commit [`1f1e2ed`](https://github.com/apache/spark/commit/1f1e2eddb0b016897b2267c9a0dab9cb7855043a).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r587460001
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
Review comment:
Gentle ping @cloud-fan
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
ulysses-you commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-796500577
Add the `scope` sounds good! Another usage is about `SetCommand` which used in SQL server like `ThirftServer` , some poeple might execute `set spark.app.name=xx` which seems like Hive command `set mapred.job.name=xxx`.
If we have such a tag, it would be easy to give friendly reminder for user.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787417275
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135550/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu edited a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787608231
> I don't see what that column adds that the description cannot? it also squishes the horizontal space for the description.
Remove it . And pr desc updated
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r585663562
##########
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##########
@@ -2690,7 +2690,10 @@ object SparkContext extends Logging {
setActiveContext(new SparkContext(config))
} else {
if (config.getAll.nonEmpty) {
- logWarning("Using an existing SparkContext; some configuration may not take effect.")
+ logWarning("Using an existing SparkContext; some configuration may not take effect. " +
+ "For how to set these configuration correctly, you can refer to " +
+ s"https://spark.apache.org/docs/${SPARK_VERSION.replace("-SNAPSHOT", "")}" +
+ s"/configuration.html#dynamically-loading-spark-properties.")
Review comment:
This doesn't match the PR title. So now this PR just improves the error message and doc?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r582506824
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -897,6 +898,24 @@ object SparkSession extends Logging {
this
}
+ // These configurations related to driver when deploy like `spark.master`,
+ // `spark.driver.memory`, this kind of properties may not be affected when
+ // setting programmatically through SparkConf in runtime, or the behavior is
+ // depending on which cluster manager and deploy mode you choose, so it would
+ // be suggested to set through configuration file or spark-submit command line options.
Review comment:
> I think you can just add some docs for each configuration like from `blah blah` to `(Launcher scope) blah blah` or something like this.
Updated, how about current?
Warn message like
```
11:38:42.540 WARN org.apache.spark.sql.SparkSession$Builder: Since spark has been submitted, such configurations
`spark.driver.memory -> 1g` may not take effect.
For how to set these configuration correctly, you can refer to
https://spark.apache.org/docs/latest/configuration.html#dynamically-loading-spark-properties.
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787714868
Kubernetes integration test status success
URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/40158/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782561703
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39867/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782591823
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/39880/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787698737
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135575/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-785681017
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787697464
**[Test build #135575 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135575/testReport)** for PR 31598 at commit [`3f795f5`](https://github.com/apache/spark/commit/3f795f575d4fc783358cd134500edd6f78545155).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787976978
**[Test build #135597 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135597/testReport)** for PR 31598 at commit [`7cee11e`](https://github.com/apache/spark/commit/7cee11e564cc2fb794ca77b664e8c9bf0673514f).
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
maropu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584394589
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,61 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Spark properties mainly can be divided into three kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Effect Scope</th><th>Usage</th><th>Remark</th></tr>
+<tr>
+ <td><code>Lauch Driver Related Configuration</code></td>
+ <td>Effect before start driver JVM.</td>
+ <td>
+ Configuration used to submit application, such as `spark.driver.memory`, `spark.driver.extraClassPath`,
+ these kind of properties only effect before driver's JVM is started, so it would be suggested to set through
+ configuration file or `spark-submit` command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:<br/>
+ `spark.driver.memory`<br/>
+ `spark.driver.memoryOverhead`<br/>
+ `spark.driver.cores`<br/>
+ `spark.driver.userClassPathFirst`<br/>
+ `spark.driver.extraClassPath`<br/>
+ `spark.driver.defaultJavaOptions`<br/>
+ `spark.driver.extraJavaOptions`<br/>
+ `spark.driver.extraLibraryPath`<br/>
+ `spark.driver.resource.*`<br/>
+ `spark.pyspark.driver.python`<br/>
+ `spark.pyspark.python`<br/>
+ `spark.r.shell.command`<br/>
+ `spark.launcher.childProcLoggerName`<br/>
+ `spark.launcher.childConnectionTimeout`<br/>
+ `spark.yarn.driver.*`
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deploy Related Configuration</code></td>
+ <td>Effect before start SparkContext.</td>
+ <td>
+ Like "spark.master", "spark.executor.instances", this kind of properties may not
+ be affected when setting programmatically through `SparkConf` in runtime after SparkContext has been started,
+ or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to
+ set through configuration file, `spark-submit` command line options, or setting programmatically through `SparkConf`
+ in runtime before start SparkContext.
+ </td>
+ <td>
+
Review comment:
This cell is empty?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AngersZhuuuu commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r584700541
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
Review comment:
Done
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
Review comment:
Done
##########
File path: docs/configuration.md
##########
@@ -114,12 +114,52 @@ in the `spark-defaults.conf` file. A few configuration keys have been renamed si
versions of Spark; in such cases, the older key names are still accepted, but take lower
precedence than any instance of the newer key.
-Spark properties mainly can be divided into two kinds: one is related to deploy, like
-"spark.driver.memory", "spark.executor.instances", this kind of properties may not be affected when
-setting programmatically through `SparkConf` in runtime, or the behavior is depending on which
-cluster manager and deploy mode you choose, so it would be suggested to set through configuration
-file or `spark-submit` command line options; another is mainly related to Spark runtime control,
-like "spark.task.maxFailures", this kind of properties can be set in either way.
+Note that Spark properties have different effective timing and they can be divided into two kinds:
+<table class="table">
+<tr><th>Configuration Type</th><th>Meaning</th><th>Examples</th></tr>
+<tr>
+ <td><code>Launching Driver</code></td>
+ <td>
+ Configuration used to submit an application, such as <code>spark.driver.memory</code>, <code>spark.driver.extraClassPath</code>, these kind of properties only effect before driver's JVM is started, so it would be suggested to set through configuration file or <code>spark-submit</code> command line options.
+ </td>
+ <td>
+ The following is a list of such configurations:
+ <ul>
+ <li><code>spark.driver.memory</code></li>
+ <li><code>spark.driver.memoryOverhead</code></li>
+ <li><code>spark.driver.cores</code></li>
+ <li><code>spark.driver.userClassPathFirst</code></li>
+ <li><code>spark.driver.extraClassPath</code></li>
+ <li><code>spark.driver.defaultJavaOptions</code></li>
+ <li><code>spark.driver.extraJavaOptions</code></li>
+ <li><code>spark.driver.extraLibraryPath</code></li>
+ <li><code>spark.driver.resource.*</code></li>
+ <li><code>spark.pyspark.driver.python</code></li>
+ <li><code>spark.pyspark.python</code></li>
+ <li><code>spark.r.shell.command</code></li>
+ <li><code>spark.launcher.childProcLoggerName</code></li>
+ <li><code>spark.launcher.childConnectionTimeout</code></li>
+ <li><code>spark.yarn.driver.*</code></li>
+ </ul>
+ </td>
+</tr>
+<tr>
+ <td><code>Application Deployment</code></td>
+ <td>
+ Like <code>spark.master</code>, <code>spark.executor.instances</code>, this kind of properties may not be affected when setting programmatically through <code>SparkConf</code> in runtime after SparkContext has been started, or the behavior is depending on which cluster manager and deploy mode you choose, so it would be suggested to set through configuration file, <code>spark-submit</code> command line options, or setting programmatically through <code>SparkConf</code> in runtime before start SparkContext.
Review comment:
Done
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
AmplabJenkins removed a comment on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-782576170
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/135288/
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
SparkQA commented on pull request #31598:
URL: https://github.com/apache/spark/pull/31598#issuecomment-787011218
**[Test build #135529 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/135529/testReport)** for PR 31598 at commit [`1f1e2ed`](https://github.com/apache/spark/commit/1f1e2eddb0b016897b2267c9a0dab9cb7855043a).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #31598: [SPARK-34478][SQL] When build SparkSession, we should check config keys
Posted by GitBox <gi...@apache.org>.
HyukjinKwon commented on a change in pull request #31598:
URL: https://github.com/apache/spark/pull/31598#discussion_r581776970
##########
File path: sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala
##########
@@ -914,7 +933,34 @@ object SparkSession extends Logging {
*/
def getOrCreate(): SparkSession = synchronized {
val sparkConf = new SparkConf()
- options.foreach { case (k, v) => sparkConf.set(k, v) }
+ val (nonEffectConfigurations, mayEffectConfigurations) =
+ options.partition((DRIVER_RELATED_LAUNCHER_CONFIG).contains)
+
+ if (nonEffectConfigurations.nonEmpty) {
+ logWarning(
+ s"""Since spark has been started, such configuration
+ | `${nonEffectConfigurations.mkString(", ")}` may not be affected when setting
+ | programmatically through SparkConf in runtime, or the behavior is depending
+ | on which cluster manager and deploy mode you choose, so it would be suggested to
+ | set through configuration file or spark-submit command line options.
+ |""".stripMargin)
+ }
+
+ val (scAlreadySetConfigurations, normalConfigs) =
+ mayEffectConfigurations.partition(EXECUTOR_LAUNCHER_CONFIG.contains)
+
+ if (SparkContext.getActive.isDefined) {
Review comment:
I think `SparkConf` is immutable and we cannot change configuration once `SparkContext` is launched?
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org