You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/06/24 06:51:57 UTC
[GitHub] [hudi] glory9211 opened a new issue, #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
glory9211 opened a new issue, #5952:
URL: https://github.com/apache/hudi/issues/5952
### Optimize DeltaStreamer S3EventSource Implementation for reading files in parallel fashion
Following this [guide](https://hudi.apache.org/docs/0.10.1/quick-start-guide/) we are trying to read incoming event files from Hudi DeltaStreamer [S3EventsSource.java](https://github.com/apache/hudi/blob/6456bd3a5199d60ff55d6c576e139025a1c940c7/hudi-utilities/src/main/java/org/apache/hudi/utilities/sources/S3EventsSource.java#L77) which uses spark default _spark.read.format('json').load()_ function to read the paths from meta table created by consuming SQS which holds the filepaths events.
In case of a huge number of incremental loads i.e. 50,000 small JSON files are read using _spark.read.format().load()_ in a non-parallel fashion on Driver Node which takes a lot of time.
**Feature Request**
Instead of passing an Array of Filepaths to the _spark.read.format().load()_, we can perfrom the following steps we can use the power of spark parallelism better.
1. Convert the Filepath Array to RDD using sc.parallelize()
2. Create a function def readContents(file): return file.read.content
3. Call my_rdd.flatMap(readContents) function to read the contents of the files in a parallel method
The Inspiration source of this solution along with many other methods and performance benchmarks is [here](https://joshua-robinson.medium.com/sparks-missing-parallelism-loading-large-datasets-6746906899f5)
**Documentation Update**
In case someone stumbles into the same problem of reading large number of files using the original guide, we should update the heading [Conclusion and Future Work](https://hudi.apache.org/blog/2021/08/23/s3-events-source/#conclusion-and-future-work) mentioning this solution or workaround
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] glory9211 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1195592065
>
I'm referring to these lines https://github.com/apache/hudi/blob/6456bd3a5199d60ff55d6c576e139025a1c940c7/hudi-utilities/src/main/java/org/apache/hudi/utilities/sources/S3EventsSource.java#L77 as shared in my original question
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] glory9211 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1229574382
In the second part, when we go to read the files from S3. For large number of entries in SQS the S3List operation will be very slow using the default ```spark.read.json()``` method
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] rmahindra123 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
rmahindra123 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1191118443
@glory9211 could you please provide more details on your setup to reproduce. Also, if possible please provide the Spark UI screenshot where you saw the sequential behavior. spark.read.format().load() does actually parallelize and would create 50K tasks in your case.
Also, are you talking about S3EventsSource.java or S3EventsHoodieIncrSource.java because S3EventsHoodieIncrSource actually reads the file contents.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1302873977
Since we have a patch addressing the proposed fix, closing out the issue. Feel free to reach out to us if you need any further assistance.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1244959102
@glory9211 : got it. can you check if this is what you suggested
https://github.com/apache/hudi/pull/6661/files
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1216258288
@rmahindra123 : can you follow up when you can .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1229347594
looks like there is some confusion here. S3EventsSource actually reads events from SQS and populates the data into Hudi metadata table. this is the first stage which does not look into your S3 data directory at all.
Its the 2nd stage where we read the actual source files from S3 path in S3EventsHoodieIncrSource. Can you help clarify where you are seeing the perf hit.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] rmahindra123 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
rmahindra123 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1195096821
> @rmahindra123 is it possible to run multiple instances of both **S3EventsSource.java** and **S3EventsHoodieIncrSource.java** in parallel (i.e. across different clusters for high availability) without concurrency issues? Thanks in advance.
No, that may not be possible if you are using a single SQS/SNS. S3EventsSource deletes the events in SQS after it commits them to the hudi table
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] glory9211 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1198302501
Providing Screenshots for spark UI
for the said command
`df=spark.read.json('s3://rz.auto.billing/RealTime/EXS.ResponseJSON/2022-07-12/*')
`

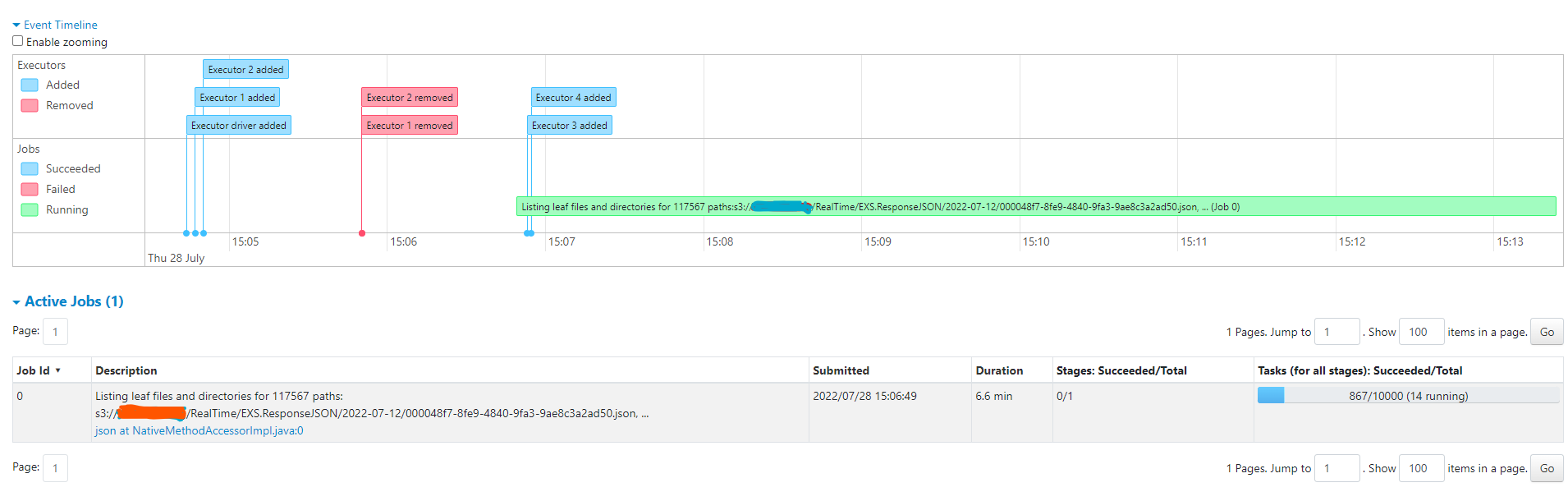
As you can see only a single job with a single task is created to list and fetch all the s3 files (as expected according to Spark Docs/Architecture). Until the listing is completed there will be a single task running.
I have shared some suggestions in my original question so we can avoid and improve the Hudi S3EventSource implementation
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan closed issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
nsivabalan closed issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
URL: https://github.com/apache/hudi/issues/5952
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] glory9211 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1169048385
The function for reading the json files into a dataframe (not from SQS, the actual content of files) is not a parallel process. spark.read.json only runs on driver node
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] jonslo commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
jonslo commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1192618160
@rmahindra123 is it possible to run **S3EventsHoodieIncrSource.java** in parallel across different nodes (i.e. in a k8s cluster) without concurrency issues? Thanks in advance.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] nsivabalan commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
nsivabalan commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1244960649
again, just to clarify. the code you have referenced
```
sparkSession.read().json(eventRecords)
```
is actually reading data from SQS and does not involve reading from S3. Only S3EventsIncrSource reads from S3. and hence my fix.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] yihua commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
yihua commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1168986618
Thanks for the feature request.
The referenced code you mentioned in `S3EventsSource` converts the Json records already in Dataset to Dataframe for further processing. Do you actually refer to the optimization of reading events from SQS (which should not actually involve file reading)?
```
Dataset<String> eventRecords = sparkSession.createDataset(selectPathsWithLatestSqsMessage.getLeft(), Encoders.STRING());
return Pair.of(
Option.of(sparkSession.read().json(eventRecords)),
selectPathsWithLatestSqsMessage.getRight());
```
Feel free to create a Jira ticket for the feature request and I encourage you to put up a PR.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] rmahindra123 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
rmahindra123 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1191144994
@glory9211 also could you verify if hoodie.deltastreamer.source.s3incr.check.file.exists is set to true. If yes, could you re-run the pipeline with hoodie.deltastreamer.source.s3incr.check.file.exists=false and see if the performance issue is resolved.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] glory9211 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1192956876
> @rmahindra123 is it possible to run multiple instances of both **S3EventsSource.java** and **S3EventsHoodieIncrSource.java** in parallel (i.e. across different clusters for high availability) without concurrency issues? Thanks in advance.
If you are writing to same table, using multiple jobs at the same time then you can use zookeeper to achieve concurrent hoodie writing tasks. This feature and related config is documented in the hudi docs
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] glory9211 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1192955654
>
Using this as default. Providing with false solve the issue.
Also the task for listing and fetching the file is not parallelized. The serializing, re-partitioning part is parallel. As discussed in links shared.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] rmahindra123 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
rmahindra123 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1195099857
@glory9211 Are you refering to `S3EventsHoodieIncrSource.java`, could you reference the code?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] glory9211 commented on issue #5952: [SUPPORT] HudiDeltaStreamer S3EventSource SQS optimize for reading large number of files in parallel fashion
Posted by GitBox <gi...@apache.org>.
glory9211 commented on issue #5952:
URL: https://github.com/apache/hudi/issues/5952#issuecomment-1246615855
I'm understanding that now instead of reading the files list, you are parallelizing the array and using multiple executors to read the split arrays of files.
If yes, (Correct me if I'm wrong 😎 ) then
This is a better approach than the previous one, but the significance can be verified by running this scenario and comparing it with the previous implementation.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org