You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@mxnet.apache.org by GitBox <gi...@apache.org> on 2018/12/01 02:34:30 UTC
[GitHub] twmht closed pull request #13475: the parameter for training
Stanford Online Product
twmht closed pull request #13475: the parameter for training Stanford Online Product
URL: https://github.com/apache/incubator-mxnet/pull/13475
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/example/gluon/embedding_learning/README.md b/example/gluon/embedding_learning/README.md
new file mode 100644
index 00000000000..e7821619a38
--- /dev/null
+++ b/example/gluon/embedding_learning/README.md
@@ -0,0 +1,72 @@
+# Image Embedding Learning
+
+This example implements embedding learning based on a Margin-based Loss with distance weighted sampling [(Wu et al, 2017)](http://www.philkr.net/papers/2017-10-01-iccv/2017-10-01-iccv.pdf). The model obtains a validation Recall@1 of ~64% on the [Caltech-UCSD Birds-200-2011](http://www.vision.caltech.edu/visipedia/CUB-200-2011.html) dataset.
+
+
+## Usage
+Download the data
+```bash
+./get_cub200_data.sh
+```
+
+Example runs and the results:
+```
+python3 train.py --data-path=data/CUB_200_2011 --gpus=0,1 --use-pretrained
+```
+
+<br>
+
+`python train.py --help` gives the following arguments:
+```
+optional arguments:
+ -h, --help show this help message and exit
+ --data-path DATA_PATH
+ path of data.
+ --embed-dim EMBED_DIM
+ dimensionality of image embedding. default is 128.
+ --batch-size BATCH_SIZE
+ training batch size per device (CPU/GPU). default is
+ 70.
+ --batch-k BATCH_K number of images per class in a batch. default is 5.
+ --gpus GPUS list of gpus to use, e.g. 0 or 0,2,5. empty means
+ using cpu.
+ --epochs EPOCHS number of training epochs. default is 20.
+ --optimizer OPTIMIZER
+ optimizer. default is adam.
+ --lr LR learning rate. default is 0.0001.
+ --lr-beta LR_BETA learning rate for the beta in margin based loss.
+ default is 0.1.
+ --margin MARGIN margin for the margin based loss. default is 0.2.
+ --beta BETA initial value for beta. default is 1.2.
+ --nu NU regularization parameter for beta. default is 0.0.
+ --factor FACTOR learning rate schedule factor. default is 0.5.
+ --steps STEPS epochs to update learning rate. default is
+ 12,14,16,18.
+ --wd WD weight decay rate. default is 0.0001.
+ --seed SEED random seed to use. default=123.
+ --model MODEL type of model to use. see vision_model for options.
+ --save-model-prefix SAVE_MODEL_PREFIX
+ prefix of models to be saved.
+ --use-pretrained enable using pretrained model from gluon.
+ --kvstore KVSTORE kvstore to use for trainer.
+ --log-interval LOG_INTERVAL
+ number of batches to wait before logging.
+```
+
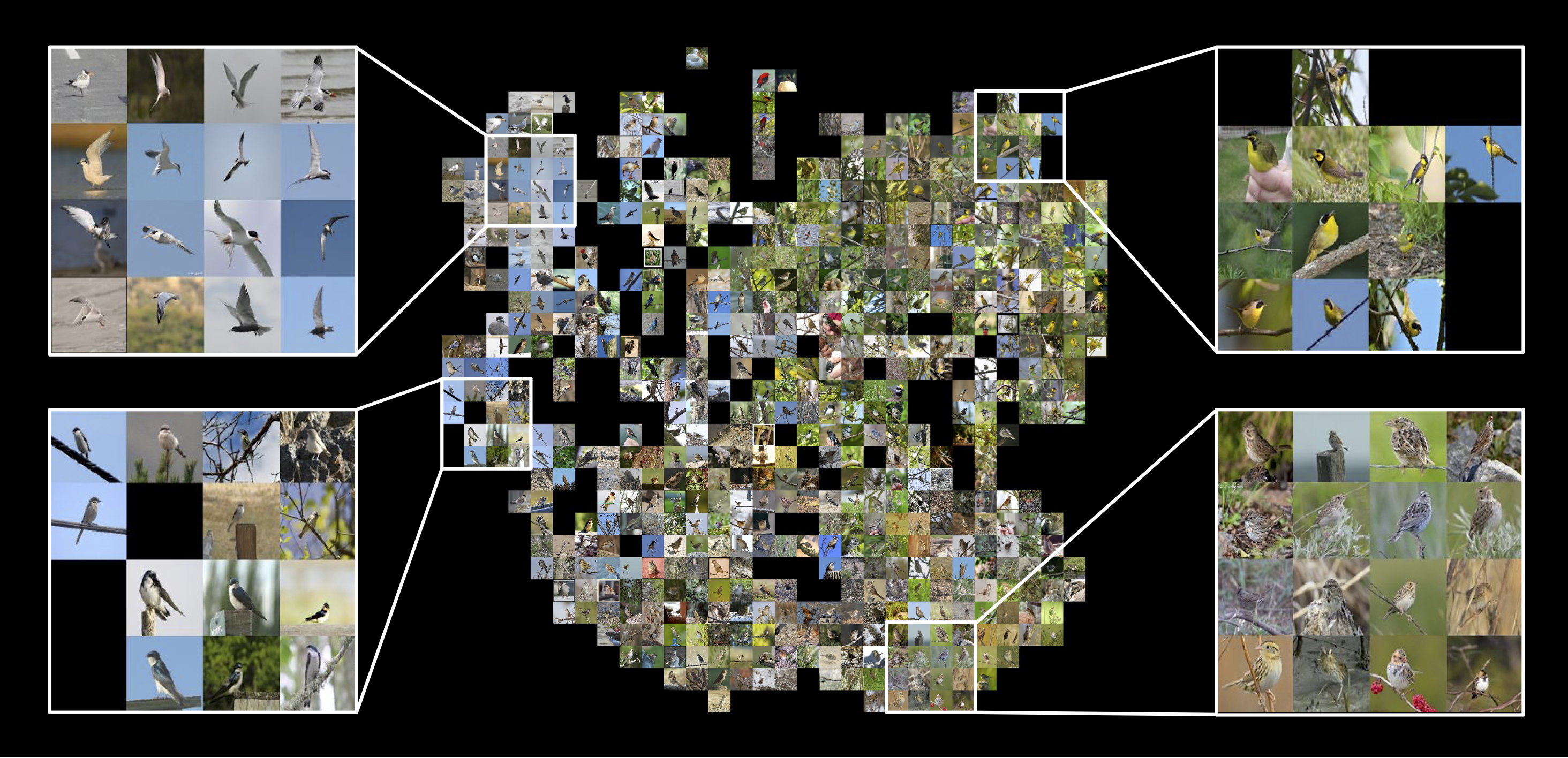
+## Learned embeddings
+The following visualizes the learned embeddings with t-SNE.
+
+
+
+
+## Citation
+<b>Sampling Matters in Deep Embedding Learning</b> [<a href="https://arxiv.org/abs/1706.07567">paper</a>] [<a href="https://www.cs.utexas.edu/~cywu/projects/sampling_matters/">project</a>] <br>
+ Chao-Yuan Wu, R. Manmatha, Alexander J. Smola and Philipp Krähenbühl
+<pre>
+@inproceedings{wu2017sampling,
+ title={Sampling Matters in Deep Embedding Learning},
+ author={Wu, Chao-Yuan and Manmatha, R and Smola, Alexander J and Kr{\"a}henb{\"u}hl, Philipp},
+ booktitle={ICCV},
+ year={2017}
+}
+</pre>
diff --git a/example/gluon/embedding_learning/data.py b/example/gluon/embedding_learning/data.py
new file mode 100644
index 00000000000..e3b96d6c7dd
--- /dev/null
+++ b/example/gluon/embedding_learning/data.py
@@ -0,0 +1,158 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+import os
+import random
+
+import numpy as np
+
+import mxnet as mx
+from mxnet import nd
+
+def transform(data, target_wd, target_ht, is_train, box):
+ """Crop and normnalize an image nd array."""
+ if box is not None:
+ x, y, w, h = box
+ data = data[y:min(y+h, data.shape[0]), x:min(x+w, data.shape[1])]
+
+ # Resize to target_wd * target_ht.
+ data = mx.image.imresize(data, target_wd, target_ht)
+
+ # Normalize in the same way as the pre-trained model.
+ data = data.astype(np.float32) / 255.0
+ data = (data - mx.nd.array([0.485, 0.456, 0.406])) / mx.nd.array([0.229, 0.224, 0.225])
+
+ if is_train:
+ if random.random() < 0.5:
+ data = nd.flip(data, axis=1)
+ data, _ = mx.image.random_crop(data, (224, 224))
+ else:
+ data, _ = mx.image.center_crop(data, (224, 224))
+
+ # Transpose from (target_wd, target_ht, 3)
+ # to (3, target_wd, target_ht).
+ data = nd.transpose(data, (2, 0, 1))
+
+ # If image is greyscale, repeat 3 times to get RGB image.
+ if data.shape[0] == 1:
+ data = nd.tile(data, (3, 1, 1))
+ return data.reshape((1,) + data.shape)
+
+
+class CUB200Iter(mx.io.DataIter):
+ """Iterator for the CUB200-2011 dataset.
+ Parameters
+ ----------
+ data_path : str,
+ The path to dataset directory.
+ batch_k : int,
+ Number of images per class in a batch.
+ batch_size : int,
+ Batch size.
+ batch_size : tupple,
+ Data shape. E.g. (3, 224, 224).
+ is_train : bool,
+ Training data or testig data. Training batches are randomly sampled.
+ Testing batches are loaded sequentially until reaching the end.
+ """
+ def __init__(self, data_path, batch_k, batch_size, data_shape, is_train):
+ super(CUB200Iter, self).__init__(batch_size)
+ self.data_shape = (batch_size,) + data_shape
+ self.batch_size = batch_size
+ self.provide_data = [('data', self.data_shape)]
+ self.batch_k = batch_k
+ self.is_train = is_train
+
+ self.train_image_files = [[] for _ in range(100)]
+ self.test_image_files = []
+ self.test_labels = []
+ self.boxes = {}
+ self.test_count = 0
+
+ with open(os.path.join(data_path, 'images.txt'), 'r') as f_img, \
+ open(os.path.join(data_path, 'image_class_labels.txt'), 'r') as f_label, \
+ open(os.path.join(data_path, 'bounding_boxes.txt'), 'r') as f_box:
+ for line_img, line_label, line_box in zip(f_img, f_label, f_box):
+ fname = os.path.join(data_path, 'images', line_img.strip().split()[-1])
+ label = int(line_label.strip().split()[-1]) - 1
+ box = [int(float(v)) for v in line_box.split()[-4:]]
+ self.boxes[fname] = box
+
+ # Following "Deep Metric Learning via Lifted Structured Feature Embedding" paper,
+ # we use the first 100 classes for training, and the remaining for testing.
+ if label < 100:
+ self.train_image_files[label].append(fname)
+ else:
+ self.test_labels.append(label)
+ self.test_image_files.append(fname)
+
+ self.n_test = len(self.test_image_files)
+
+ def get_image(self, img, is_train):
+ """Load and transform an image."""
+ img_arr = mx.image.imread(img)
+ img_arr = transform(img_arr, 256, 256, is_train, self.boxes[img])
+ return img_arr
+
+ def sample_train_batch(self):
+ """Sample a training batch (data and label)."""
+ batch = []
+ labels = []
+ num_groups = self.batch_size // self.batch_k
+
+ # For CUB200, we use the first 100 classes for training.
+ sampled_classes = np.random.choice(100, num_groups, replace=False)
+ for i in range(num_groups):
+ img_fnames = np.random.choice(self.train_image_files[sampled_classes[i]],
+ self.batch_k, replace=False)
+ batch += [self.get_image(img_fname, is_train=True) for img_fname in img_fnames]
+ labels += [sampled_classes[i] for _ in range(self.batch_k)]
+
+ return nd.concatenate(batch, axis=0), labels
+
+ def get_test_batch(self):
+ """Sample a testing batch (data and label)."""
+
+ batch_size = self.batch_size
+ batch = [self.get_image(self.test_image_files[(self.test_count*batch_size + i)
+ % len(self.test_image_files)],
+ is_train=False) for i in range(batch_size)]
+ labels = [self.test_labels[(self.test_count*batch_size + i)
+ % len(self.test_image_files)] for i in range(batch_size)]
+ return nd.concatenate(batch, axis=0), labels
+
+ def reset(self):
+ """Reset an iterator."""
+ self.test_count = 0
+
+ def next(self):
+ """Return a batch."""
+ if self.is_train:
+ data, labels = self.sample_train_batch()
+ else:
+ if self.test_count * self.batch_size < len(self.test_image_files):
+ data, labels = self.get_test_batch()
+ self.test_count += 1
+ else:
+ self.test_count = 0
+ raise StopIteration
+ return mx.io.DataBatch(data=[data], label=[labels])
+
+def cub200_iterator(data_path, batch_k, batch_size, data_shape):
+ """Return training and testing iterator for the CUB200-2011 dataset."""
+ return (CUB200Iter(data_path, batch_k, batch_size, data_shape, is_train=True),
+ CUB200Iter(data_path, batch_k, batch_size, data_shape, is_train=False))
diff --git a/example/gluon/embedding_learning/get_cub200_data.sh b/example/gluon/embedding_learning/get_cub200_data.sh
new file mode 100755
index 00000000000..c2f2fe45a4d
--- /dev/null
+++ b/example/gluon/embedding_learning/get_cub200_data.sh
@@ -0,0 +1,30 @@
+#!/usr/bin/env bash
+
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+
+EMB_DIR=$(cd `dirname $0`; pwd)
+DATA_DIR="${EMB_DIR}/data/"
+
+if [[ ! -d "${DATA_DIR}" ]]; then
+ echo "${DATA_DIR} doesn't exist, will create one.";
+ mkdir -p ${DATA_DIR}
+fi
+
+wget -P ${DATA_DIR} http://www.vision.caltech.edu/visipedia-data/CUB-200-2011/CUB_200_2011.tgz
+cd ${DATA_DIR}; tar -xf CUB_200_2011.tgz
\ No newline at end of file
diff --git a/example/gluon/embedding_learning/model.py b/example/gluon/embedding_learning/model.py
new file mode 100644
index 00000000000..0f041bc1fc4
--- /dev/null
+++ b/example/gluon/embedding_learning/model.py
@@ -0,0 +1,224 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+
+from mxnet import gluon
+from mxnet.gluon import nn, Block, HybridBlock
+import numpy as np
+
+class L2Normalization(HybridBlock):
+ r"""Applies L2 Normalization to input.
+
+ Parameters
+ ----------
+ mode : str
+ Mode of normalization.
+ See :func:`~mxnet.ndarray.L2Normalization` for available choices.
+
+ Inputs:
+ - **data**: input tensor with arbitrary shape.
+
+ Outputs:
+ - **out**: output tensor with the same shape as `data`.
+ """
+ def __init__(self, mode, **kwargs):
+ self._mode = mode
+ super(L2Normalization, self).__init__(**kwargs)
+
+ def hybrid_forward(self, F, x):
+ return F.L2Normalization(x, mode=self._mode, name='l2_norm')
+
+ def __repr__(self):
+ s = '{name}({_mode})'
+ return s.format(name=self.__class__.__name__,
+ **self.__dict__)
+
+
+def get_distance(F, x):
+ """Helper function for margin-based loss. Return a distance matrix given a matrix."""
+ n = x.shape[0]
+
+ square = F.sum(x ** 2.0, axis=1, keepdims=True)
+ distance_square = square + square.transpose() - (2.0 * F.dot(x, x.transpose()))
+
+ # Adding identity to make sqrt work.
+ return F.sqrt(distance_square + F.array(np.identity(n)))
+
+class DistanceWeightedSampling(HybridBlock):
+ r"""Distance weighted sampling. See "sampling matters in deep embedding learning"
+ paper for details.
+
+ Parameters
+ ----------
+ batch_k : int
+ Number of images per class.
+
+ Inputs:
+ - **data**: input tensor with shape (batch_size, embed_dim).
+ Here we assume the consecutive batch_k examples are of the same class.
+ For example, if batch_k = 5, the first 5 examples belong to the same class,
+ 6th-10th examples belong to another class, etc.
+
+ Outputs:
+ - a_indices: indices of anchors.
+ - x[a_indices]: sampled anchor embeddings.
+ - x[p_indices]: sampled positive embeddings.
+ - x[n_indices]: sampled negative embeddings.
+ - x: embeddings of the input batch.
+ """
+ def __init__(self, batch_k, cutoff=0.5, nonzero_loss_cutoff=1.4, **kwargs):
+ self.batch_k = batch_k
+ self.cutoff = cutoff
+
+ # We sample only from negatives that induce a non-zero loss.
+ # These are negatives with a distance < nonzero_loss_cutoff.
+ # With a margin-based loss, nonzero_loss_cutoff == margin + beta.
+ self.nonzero_loss_cutoff = nonzero_loss_cutoff
+ super(DistanceWeightedSampling, self).__init__(**kwargs)
+
+ def hybrid_forward(self, F, x):
+ k = self.batch_k
+ n, d = x.shape
+
+ distance = get_distance(F, x)
+ # Cut off to avoid high variance.
+ distance = F.maximum(distance, self.cutoff)
+
+ # Subtract max(log(distance)) for stability.
+ log_weights = ((2.0 - float(d)) * F.log(distance)
+ - (float(d - 3) / 2) * F.log(1.0 - 0.25 * (distance ** 2.0)))
+ weights = F.exp(log_weights - F.max(log_weights))
+
+ # Sample only negative examples by setting weights of
+ # the same-class examples to 0.
+ mask = np.ones(weights.shape)
+ for i in range(0, n, k):
+ mask[i:i+k, i:i+k] = 0
+
+ weights = weights * F.array(mask) * (distance < self.nonzero_loss_cutoff)
+ weights = weights / F.sum(weights, axis=1, keepdims=True)
+
+ a_indices = []
+ p_indices = []
+ n_indices = []
+
+ np_weights = weights.asnumpy()
+ for i in range(n):
+ block_idx = i // k
+
+ try:
+ n_indices += np.random.choice(n, k-1, p=np_weights[i]).tolist()
+ except:
+ n_indices += np.random.choice(n, k-1).tolist()
+ for j in range(block_idx * k, (block_idx + 1) * k):
+ if j != i:
+ a_indices.append(i)
+ p_indices.append(j)
+
+ return a_indices, x[a_indices], x[p_indices], x[n_indices], x
+
+ def __repr__(self):
+ s = '{name}({batch_k})'
+ return s.format(name=self.__class__.__name__,
+ **self.__dict__)
+
+
+class MarginNet(Block):
+ r"""Embedding network with distance weighted sampling.
+ It takes a base CNN and adds an embedding layer and a
+ sampling layer at the end.
+
+ Parameters
+ ----------
+ base_net : Block
+ Base network.
+ emb_dim : int
+ Dimensionality of the embedding.
+ batch_k : int
+ Number of images per class in a batch. Used in sampling.
+
+ Inputs:
+ - **data**: input tensor with shape (batch_size, channels, width, height).
+ Here we assume the consecutive batch_k images are of the same class.
+ For example, if batch_k = 5, the first 5 images belong to the same class,
+ 6th-10th images belong to another class, etc.
+
+ Outputs:
+ - The output of DistanceWeightedSampling.
+ """
+ def __init__(self, base_net, emb_dim, batch_k, **kwargs):
+ super(MarginNet, self).__init__(**kwargs)
+ with self.name_scope():
+ self.base_net = base_net
+ self.dense = nn.Dense(emb_dim)
+ self.normalize = L2Normalization(mode='instance')
+ self.sampled = DistanceWeightedSampling(batch_k=batch_k)
+
+ def forward(self, x):
+ z = self.base_net(x)
+ z = self.dense(z)
+ z = self.normalize(z)
+ z = self.sampled(z)
+ return z
+
+
+class MarginLoss(gluon.loss.Loss):
+ r"""Margin based loss.
+
+ Parameters
+ ----------
+ margin : float
+ Margin between positive and negative pairs.
+ nu : float
+ Regularization parameter for beta.
+
+ Inputs:
+ - anchors: sampled anchor embeddings.
+ - positives: sampled positive embeddings.
+ - negatives: sampled negative embeddings.
+ - beta_in: class-specific betas.
+ - a_indices: indices of anchors. Used to get class-specific beta.
+
+ Outputs:
+ - Loss.
+ """
+ def __init__(self, margin=0.2, nu=0.0, weight=None, batch_axis=0, **kwargs):
+ super(MarginLoss, self).__init__(weight, batch_axis, **kwargs)
+ self._margin = margin
+ self._nu = nu
+
+ def hybrid_forward(self, F, anchors, positives, negatives, beta_in, a_indices=None):
+ if a_indices is not None:
+ # Jointly train class-specific beta.
+ beta = beta_in.data()[a_indices]
+ beta_reg_loss = F.sum(beta) * self._nu
+ else:
+ # Use a constant beta.
+ beta = beta_in
+ beta_reg_loss = 0.0
+
+ d_ap = F.sqrt(F.sum(F.square(positives - anchors), axis=1) + 1e-8)
+ d_an = F.sqrt(F.sum(F.square(negatives - anchors), axis=1) + 1e-8)
+
+ pos_loss = F.maximum(d_ap - beta + self._margin, 0.0)
+ neg_loss = F.maximum(beta - d_an + self._margin, 0.0)
+
+ pair_cnt = float(F.sum((pos_loss > 0.0) + (neg_loss > 0.0)).asscalar())
+
+ # Normalize based on the number of pairs.
+ loss = (F.sum(pos_loss + neg_loss) + beta_reg_loss) / pair_cnt
+ return gluon.loss._apply_weighting(F, loss, self._weight, None)
diff --git a/example/gluon/embedding_learning/train.py b/example/gluon/embedding_learning/train.py
new file mode 100644
index 00000000000..269caff414c
--- /dev/null
+++ b/example/gluon/embedding_learning/train.py
@@ -0,0 +1,255 @@
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+
+from __future__ import division
+
+import argparse
+import logging
+import time
+
+import numpy as np
+from bottleneck import argpartition
+
+import mxnet as mx
+from data import cub200_iterator
+from mxnet import gluon
+from mxnet.gluon.model_zoo import vision as models
+from mxnet import autograd as ag, nd
+from model import MarginNet, MarginLoss
+
+logging.basicConfig(level=logging.INFO)
+
+# CLI
+parser = argparse.ArgumentParser(description='train a model for image classification.')
+parser.add_argument('--data-path', type=str, default='data/CUB_200_2011',
+ help='path of data.')
+parser.add_argument('--embed-dim', type=int, default=128,
+ help='dimensionality of image embedding. default is 128.')
+parser.add_argument('--batch-size', type=int, default=70,
+ help='training batch size per device (CPU/GPU). default is 70.')
+parser.add_argument('--batch-k', type=int, default=5,
+ help='number of images per class in a batch. default is 5.')
+parser.add_argument('--gpus', type=str, default='',
+ help='list of gpus to use, e.g. 0 or 0,2,5. empty means using cpu.')
+parser.add_argument('--epochs', type=int, default=20,
+ help='number of training epochs. default is 20.')
+parser.add_argument('--optimizer', type=str, default='adam',
+ help='optimizer. default is adam.')
+parser.add_argument('--lr', type=float, default=0.0001,
+ help='learning rate. default is 0.0001.')
+parser.add_argument('--lr-beta', type=float, default=0.1,
+ help='learning rate for the beta in margin based loss. default is 0.1.')
+parser.add_argument('--margin', type=float, default=0.2,
+ help='margin for the margin based loss. default is 0.2.')
+parser.add_argument('--beta', type=float, default=1.2,
+ help='initial value for beta. default is 1.2.')
+parser.add_argument('--nu', type=float, default=0.0,
+ help='regularization parameter for beta. default is 0.0.')
+parser.add_argument('--factor', type=float, default=0.5,
+ help='learning rate schedule factor. default is 0.5.')
+parser.add_argument('--steps', type=str, default='12,14,16,18',
+ help='epochs to update learning rate. default is 12,14,16,18.')
+parser.add_argument('--wd', type=float, default=0.0001,
+ help='weight decay rate. default is 0.0001.')
+parser.add_argument('--seed', type=int, default=123,
+ help='random seed to use. default=123.')
+parser.add_argument('--model', type=str, default='resnet50_v2',
+ help='type of model to use. see vision_model for options.')
+parser.add_argument('--save-model-prefix', type=str, default='margin_loss_model',
+ help='prefix of models to be saved.')
+parser.add_argument('--use-pretrained', action='store_true',
+ help='enable using pretrained model from gluon.')
+parser.add_argument('--kvstore', type=str, default='device',
+ help='kvstore to use for trainer.')
+parser.add_argument('--log-interval', type=int, default=20,
+ help='number of batches to wait before logging.')
+opt = parser.parse_args()
+
+logging.info(opt)
+
+# Settings.
+mx.random.seed(opt.seed)
+np.random.seed(opt.seed)
+
+batch_size = opt.batch_size
+
+gpus = [] if opt.gpus is None or opt.gpus is '' else [
+ int(gpu) for gpu in opt.gpus.split(',')]
+num_gpus = len(gpus)
+
+batch_size *= max(1, num_gpus)
+context = [mx.gpu(i) for i in gpus] if num_gpus > 0 else [mx.cpu()]
+steps = [int(step) for step in opt.steps.split(',')]
+
+# Construct model.
+kwargs = {'ctx': context, 'pretrained': opt.use_pretrained}
+net = models.get_model(opt.model, **kwargs)
+
+if opt.use_pretrained:
+ # Use a smaller learning rate for pre-trained convolutional layers.
+ for v in net.collect_params().values():
+ if 'conv' in v.name:
+ setattr(v, 'lr_mult', 0.01)
+
+net.hybridize()
+net = MarginNet(net.features, opt.embed_dim, opt.batch_k)
+beta = mx.gluon.Parameter('beta', shape=(100,))
+
+# Get iterators.
+train_data, val_data = cub200_iterator(opt.data_path, opt.batch_k, batch_size, (3, 224, 224))
+
+
+def get_distance_matrix(x):
+ """Get distance matrix given a matrix. Used in testing."""
+ square = nd.sum(x ** 2.0, axis=1, keepdims=True)
+ distance_square = square + square.transpose() - (2.0 * nd.dot(x, x.transpose()))
+ return nd.sqrt(distance_square)
+
+
+def evaluate_emb(emb, labels):
+ """Evaluate embeddings based on Recall@k."""
+ d_mat = get_distance_matrix(emb)
+ d_mat = d_mat.asnumpy()
+ labels = labels.asnumpy()
+
+ names = []
+ accs = []
+ for k in [1, 2, 4, 8, 16]:
+ names.append('Recall@%d' % k)
+ correct, cnt = 0.0, 0.0
+ for i in range(emb.shape[0]):
+ d_mat[i, i] = 1e10
+ nns = argpartition(d_mat[i], k)[:k]
+ if any(labels[i] == labels[nn] for nn in nns):
+ correct += 1
+ cnt += 1
+ accs.append(correct/cnt)
+ return names, accs
+
+
+def test(ctx):
+ """Test a model."""
+ val_data.reset()
+ outputs = []
+ labels = []
+ for batch in val_data:
+ data = gluon.utils.split_and_load(batch.data[0], ctx_list=ctx, batch_axis=0)
+ label = gluon.utils.split_and_load(batch.label[0], ctx_list=ctx, batch_axis=0)
+ for x in data:
+ outputs.append(net(x)[-1])
+ labels += label
+
+ outputs = nd.concatenate(outputs, axis=0)[:val_data.n_test]
+ labels = nd.concatenate(labels, axis=0)[:val_data.n_test]
+ return evaluate_emb(outputs, labels)
+
+
+def get_lr(lr, epoch, steps, factor):
+ """Get learning rate based on schedule."""
+ for s in steps:
+ if epoch >= s:
+ lr *= factor
+ return lr
+
+
+def train(epochs, ctx):
+ """Training function."""
+ if isinstance(ctx, mx.Context):
+ ctx = [ctx]
+ net.initialize(mx.init.Xavier(magnitude=2), ctx=ctx)
+
+ opt_options = {'learning_rate': opt.lr, 'wd': opt.wd}
+ if opt.optimizer == 'sgd':
+ opt_options['momentum'] = 0.9
+ if opt.optimizer == 'adam':
+ opt_options['epsilon'] = 1e-7
+ trainer = gluon.Trainer(net.collect_params(), opt.optimizer,
+ opt_options,
+ kvstore=opt.kvstore)
+ if opt.lr_beta > 0.0:
+ # Jointly train class-specific beta.
+ # See "sampling matters in deep embedding learning" paper for details.
+ beta.initialize(mx.init.Constant(opt.beta), ctx=ctx)
+ trainer_beta = gluon.Trainer([beta], 'sgd',
+ {'learning_rate': opt.lr_beta, 'momentum': 0.9},
+ kvstore=opt.kvstore)
+
+ loss = MarginLoss(margin=opt.margin, nu=opt.nu)
+
+ best_val = 0.0
+ for epoch in range(epochs):
+ tic = time.time()
+ prev_loss, cumulative_loss = 0.0, 0.0
+
+ # Learning rate schedule.
+ trainer.set_learning_rate(get_lr(opt.lr, epoch, steps, opt.factor))
+ logging.info('Epoch %d learning rate=%f', epoch, trainer.learning_rate)
+ if opt.lr_beta > 0.0:
+ trainer_beta.set_learning_rate(get_lr(opt.lr_beta, epoch, steps, opt.factor))
+ logging.info('Epoch %d beta learning rate=%f', epoch, trainer_beta.learning_rate)
+
+ # Inner training loop.
+ for i in range(200):
+ batch = train_data.next()
+ data = gluon.utils.split_and_load(batch.data[0], ctx_list=ctx, batch_axis=0)
+ label = gluon.utils.split_and_load(batch.label[0], ctx_list=ctx, batch_axis=0)
+
+ Ls = []
+ with ag.record():
+ for x, y in zip(data, label):
+ a_indices, anchors, positives, negatives, _ = net(x)
+
+ if opt.lr_beta > 0.0:
+ L = loss(anchors, positives, negatives, beta, y[a_indices])
+ else:
+ L = loss(anchors, positives, negatives, opt.beta, None)
+
+ # Store the loss and do backward after we have done forward
+ # on all GPUs for better speed on multiple GPUs.
+ Ls.append(L)
+ cumulative_loss += nd.mean(L).asscalar()
+
+ for L in Ls:
+ L.backward()
+
+ # Update.
+ trainer.step(batch.data[0].shape[0])
+ if opt.lr_beta > 0.0:
+ trainer_beta.step(batch.data[0].shape[0])
+
+ if (i+1) % opt.log_interval == 0:
+ logging.info('[Epoch %d, Iter %d] training loss=%f' % (
+ epoch, i+1, cumulative_loss - prev_loss))
+ prev_loss = cumulative_loss
+
+ logging.info('[Epoch %d] training loss=%f'%(epoch, cumulative_loss))
+ logging.info('[Epoch %d] time cost: %f'%(epoch, time.time()-tic))
+
+ names, val_accs = test(ctx)
+ for name, val_acc in zip(names, val_accs):
+ logging.info('[Epoch %d] validation: %s=%f'%(epoch, name, val_acc))
+
+ if val_accs[0] > best_val:
+ best_val = val_accs[0]
+ logging.info('Saving %s.' % opt.save_model_prefix)
+ net.collect_params().save('%s.params' % opt.save_model_prefix)
+ return best_val
+
+
+if __name__ == '__main__':
+ best_val_recall = train(opt.epochs, context)
+ print('Best validation Recall@1: %.2f.' % best_val_recall)
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services