You are viewing a plain text version of this content. The canonical link for it is here.
Posted to notifications@skywalking.apache.org by wu...@apache.org on 2022/04/01 09:53:03 UTC
[skywalking] branch doc created (now b3cd779)
This is an automated email from the ASF dual-hosted git repository.
wusheng pushed a change to branch doc
in repository https://gitbox.apache.org/repos/asf/skywalking.git.
at b3cd779 Add profiling doc
This branch includes the following new commits:
new b3cd779 Add profiling doc
The 1 revisions listed above as "new" are entirely new to this
repository and will be described in separate emails. The revisions
listed as "add" were already present in the repository and have only
been added to this reference.
[skywalking] 01/01: Add profiling doc
Posted by wu...@apache.org.
This is an automated email from the ASF dual-hosted git repository.
wusheng pushed a commit to branch doc
in repository https://gitbox.apache.org/repos/asf/skywalking.git
commit b3cd779e8c7f524cce0cb19f18a2e3a19456ac27
Author: Wu Sheng <wu...@foxmail.com>
AuthorDate: Fri Apr 1 17:52:38 2022 +0800
Add profiling doc
---
CHANGES.md | 1 +
docs/en/concepts-and-designs/probe-introduction.md | 56 +++++----
docs/en/concepts-and-designs/sdk-profiling.md | 140 +++++++++++++++++++++
docs/en/concepts-and-designs/service-mesh-probe.md | 28 -----
docs/menu.yml | 6 +-
5 files changed, 178 insertions(+), 53 deletions(-)
diff --git a/CHANGES.md b/CHANGES.md
index 33672d7..c6eec71 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -178,6 +178,7 @@ NOTICE, this sharding concept is NOT just for splitting data into different data
* Add Academy menu for recommending articles.
* Remove `All` source relative document and examples.
* Update Booster UI's dependency licenses.
+* Add profiling doc, and remove service mesh intro doc(not necessary).
All issues and pull requests are [here](https://github.com/apache/skywalking/milestone/112?closed=1)
diff --git a/docs/en/concepts-and-designs/probe-introduction.md b/docs/en/concepts-and-designs/probe-introduction.md
index 01ba32f..d0b9fae 100644
--- a/docs/en/concepts-and-designs/probe-introduction.md
+++ b/docs/en/concepts-and-designs/probe-introduction.md
@@ -1,36 +1,48 @@
# Probe Introduction
-In SkyWalking, probe means an agent or SDK library integrated into a target system that takes charge of
-collecting telemetry data, including tracing and metrics. Depending on the target system tech stack, there are very different ways how the probe performs such tasks. But ultimately, they all work towards the same goal — to collect and reformat data, and then to send them to the backend.
+
+In SkyWalking, probe means an agent or SDK library integrated into a target system that takes charge of collecting
+telemetry data, including tracing and metrics. Depending on the target system tech stack, there are very different ways
+how the probe performs such tasks. But ultimately, they all work towards the same goal — to collect and reformat data,
+and then to send them to the backend.
On a high level, there are three typical categories in all SkyWalking probes.
-- **Language based native agent**. These agents run in target service user spaces, such as a part of user codes. For example,
-the SkyWalking Java agent uses the `-javaagent` command line argument to manipulate codes in runtime, where `manipulate` means to change and inject
-user's codes. Another kind of agents uses certain hook or intercept mechanism provided by target libraries. As you can see, these agents are based on languages and libraries.
-
-- **Service Mesh probes**. Service Mesh probes collect data from sidecar, control plane in service mesh or proxy. In the old days, proxy
-is only used as an ingress of the whole cluster, but with the Service Mesh and sidecar, we can now perform observability functions.
-
-- **3rd-party instrument library**. SkyWalking accepts many widely used instrument libraries data formats. It analyzes the
-data, transfers it to SkyWalking's formats of trace, metrics or both. This feature starts with accepting Zipkin span data. See
-[Receiver for Zipkin traces](../setup/backend/zipkin-trace.md) for more information.
-
-You don't need to use **Language based native agent** and **Service Mesh probe** at the same time, since they both serve to collect
-metrics data. Otherwise, your system will suffer twice the payload, and the analytic numbers will be doubled.
+
+- **Language based native agent**. These agents run in target service user spaces, such as a part of user codes. For
+ example, the SkyWalking Java agent uses the `-javaagent` command line argument to manipulate codes in runtime,
+ where `manipulate` means to change and inject user's codes. Another kind of agents uses certain hook or intercept
+ mechanism provided by target libraries. As you can see, these agents are based on languages and libraries.
+
+- **Service Mesh probes**. Service Mesh probes collect data from sidecar, control plane in service mesh or proxy. In the
+ old days, proxy is only used as an ingress of the whole cluster, but with the Service Mesh and sidecar, we can now
+ perform observability functions.
+
+- **3rd-party instrument library**. SkyWalking accepts many widely used instrument libraries data formats. It analyzes
+ the data, transfers it to SkyWalking's formats of trace, metrics or both. This feature starts with accepting Zipkin
+ span data. See
+ [Receiver for Zipkin traces](../setup/backend/zipkin-trace.md) for more information.
+
+You don't need to use **Language based native agent** and **Service Mesh probe** at the same time, since they both serve
+to collect metrics data. Otherwise, your system will suffer twice the payload, and the analytic numbers will be doubled.
There are several recommended ways on how to use these probes:
+
1. Use **Language based native agent** only.
1. Use **3rd-party instrument library** only, like the Zipkin instrument ecosystem.
1. Use **Service Mesh probe** only.
-1. Use **Service Mesh probe** with **Language based native agent** or **3rd-party instrument library** in tracing status. (Advanced usage)
+1. Use **Service Mesh probe** with **Language based native agent** or **3rd-party instrument library** in tracing
+ status. (Advanced usage)
What is the meaning of **in tracing status**?
-By default, **Language based native agent** and **3rd-party instrument library** both send distributed traces to the backend,
-where analyses and aggregation on those traces are performed. **In tracing status** means that the backend considers these traces as something
-like logs. In other words, the backend saves them, and builds the links between traces and metrics, like `which endpoint and service does the trace belong?`.
+By default, **Language based native agent** and **3rd-party instrument library** both send distributed traces to the
+backend, where analyses and aggregation on those traces are performed. **In tracing status** means that the backend
+considers these traces as something like logs. In other words, the backend saves them, and builds the links between
+traces and metrics, like `which endpoint and service does the trace belong?`.
## What is next?
-- Learn more about the probes supported by SkyWalking in [Service auto instrument agent](service-agent.md), [Manual instrument SDK](manual-sdk.md),
-[Service Mesh probe](service-mesh-probe.md) and [Zipkin receiver](../setup/backend/zipkin-trace.md).
-- After understanding how the probe works, see the [backend overview](backend-overview.md) for more on analysis and persistence.
+
+- Learn more about the probes supported by SkyWalking in [Service auto instrument agent](service-agent.md)
+ , [Manual instrument SDK](manual-sdk.md) and [Zipkin receiver](../setup/backend/zipkin-trace.md).
+- After understanding how the probe works, see the [backend overview](backend-overview.md) for more on analysis and
+ persistence.
diff --git a/docs/en/concepts-and-designs/sdk-profiling.md b/docs/en/concepts-and-designs/sdk-profiling.md
new file mode 100644
index 0000000..81c72c3
--- /dev/null
+++ b/docs/en/concepts-and-designs/sdk-profiling.md
@@ -0,0 +1,140 @@
+# Use Profiling to Fix the Blind Spot of Distributed Tracing
+
+> This post introduces a way to automatically profile code in production with Apache SkyWalking.
+> We believe the profile method helps reduce maintenance and overhead while increasing the precision in root cause analysis.
+
+This post introduces a way to automatically profile code in production
+with [Apache SkyWalking](https://skywalking.apache.org). We believe the profile method helps reduce maintenance and
+overhead while increasing the precision in root cause analysis.
+
+### Limitations of the Distributed Tracing
+
+In the early days, metrics and logging systems were the key solutions in monitoring platforms. With the adoption of
+microservice and distributed system-based architecture, distributed tracing has become more important. Distributed
+tracing provides relevant service context, such as system topology map and RPC parent-child relationships.
+
+Some claim that distributed tracing is the best way to discover the cause of performance issues in a distributed system.
+It’s good at finding issues at the RPC abstraction, or in the scope of components instrumented with spans. However, it
+isn’t that perfect.
+
+Have you been surprised to find a span duration longer than expected, but no insight into why? What should you do next?
+Some may think that the next step is to add more instrumentation, more spans into the trace, thinking that you would
+eventually find the root cause, with more data points. We’ll argue this is not a good option within a production
+environment. Here’s why:
+
+1. There is a risk of application overhead and system overload. Ad-hoc spans measure the performance of specific scopes
+ or methods, but picking the right place can be difficult. To identify the precise cause, you can “instrument” (add
+ spans to) many suspicious places. The additional instrumentation costs more CPU and memory in the production
+ environment. Next, ad-hoc instrumentation that didn’t help is often forgotten, not deleted. This creates a valueless
+ overhead load. In the worst case, excess instrumentation can cause performance problems in the production app or
+ overload the tracing system.
+2. The process of ad-hoc (manual) instrumentation usually implies at least a restart. Trace instrumentation libraries,
+ like Zipkin Brave, are integrated into many framework libraries. To instrument a method’s performance typically
+ implies changing code, even if only an annotation. This implies a re-deploy. Even if you have the way to do auto
+ instrumentation, like Apache SkyWalking, you still need to change the configuration and reboot the app. Otherwise,
+ you take the risk of GC caused by hot dynamic instrumentation.
+3. Injecting instrumentation into an uninstrumented third party library is hard and complex. It takes more time and many
+ won’t know how to do this.
+4. Usually, we don’t have code line numbers in the distributed tracing. Particularly when lambdas are in use, it can be
+ difficult to identify the line of code associated with a span. Regardless of the above choices, to dive deeper
+ requires collaboration with your Ops or SRE team, and a shared deep level of knowledge in distributed tracing.
+
+Regardless of the above choices, to dive deeper requires collaboration with your Ops or SRE team, and a shared deep
+level of knowledge in distributed tracing.
+
+### Profiling in Production
+
+#### Introduction
+
+To reuse distributed tracing to achieve method scope precision requires an understanding of the above limitations and a
+different approach. We called it PROFILE.
+
+Most high-level languages build and run on a thread concept. The profile approach takes continuous thread dumps. We
+merge the thread dumps to estimate the execution time of every method shown in the thread dumps. The key for distributed
+tracing is the tracing context, identifiers active (or current) for the profiled method. Using this trace context, we
+can weave data harvested from profiling into existing traces. This allows the system to automate otherwise ad-hoc
+instrumentation. Let’s dig deeper into how profiling works:
+
+We consider a method invocation with the same stack depth and signature (method, line number etc), the same operation.
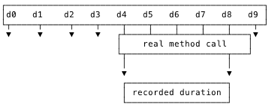
+We derive span timestamps from the thread dumps the same operation is in. Let’s put this visually:
+
+
+
+Above, represents 10 successive thread dumps. If this method is in dumps 4-8, we assume it started before dump 4 and
+finished after dump 8. We can’t tell exactly when the method started and stopped. but the timestamps of thread dumps are
+close enough.
+
+To reduce overhead caused by thread dumps, we only profile methods enclosed by a specific entry point, such as a URI or
+MVC Controller method. We identify these entry points through the trace context and the APM system.
+
+The profile does thread dump analysis and gives us:
+
+1. The root cause, precise to the line number in the code.
+2. Reduced maintenance as ad-hoc instrumentation is obviated.
+3. Reduced overload risk caused by ad-hoc instrumentation.
+4. Dynamic activation: only when necessary and with a very clear profile target.
+
+### Implementing Precise Profiling
+
+Distributed profiling is built-into Apache SkyWalking application performance monitoring (APM). Let’s demonstrate how
+the profiling approach locates the root cause of the performance issue.
+
+```
+final CountDownLatchcountDownLatch= new CountDownLatch(2);
+
+threadPool.submit(new Task1(countDownLatch));
+threadPool.submit(new Task2(countDownLatch));
+
+try {
+ countDownLatch.await(500, TimeUnit.MILLISECONDS);
+} catch (InterruptedExceptione) {
+}
+```
+
+Task1 and Task2 have a race condition and unstable execution time: they will impact the performance of each other and
+anything calling them. While this code looks suspicious, it is representative of real life. People in the OPS/SRE team
+are not usually aware of all code changes and who did them. They only know something in the new code is causing a
+problem.
+
+To make matters interesting, the above code is not always slow: it only happens when the condition is locked. In
+SkyWalking APM, we have metrics of endpoint p99/p95 latency, so, we are easy to find out the p99 of this endpoint is far
+from the avg response time. However, this is not the same as understanding the cause of the latency. To locate the root
+cause, add a profile condition to this endpoint: duration greater than 500ms. This means faster executions will not add
+profiling load.
+
+
+
+This is a typical profiled trace segment (part of the whole distributed trace) shown on the SkyWalking UI. We now notice
+the “service/processWithThreadPool” span is slow as we expected, but why? This method is the one we added the faulty
+code to. As the UI shows that method, we know the profiler is working. Now, let’s see what the profile analysis result
+say.
+
+
+
+This is the profile analysis stack view. We see the stack element names, duration (include/exclude the children) and
+slowest methods have been highlighted. It shows clearly, “sun.misc.Unsafe.park” costs the most time. If we look for the
+caller, it is the code we added: **CountDownLatch.await**.
+
+### The Limitations of the Profile Method
+
+No diagnostic tool can fit all cases, not even the profile method.
+
+The first consideration is mistaking a repeatedly called method for a slow method. Thread dumps are periodic. If there
+is a loop of calling one method, the profile analysis result would say the target method is slow because it is captured
+every time in the dump process. There could be another reason. A method called many times can also end up captured in
+each thread dump. Even so, the profile did what it is designed for. It still helps the OPS/SRE team to locate the code
+having the issue.
+
+The second consideration is overhead, the impact of repeated thread dumps is real and can’t be ignored. In SkyWalking,
+we set the profile dump period to at least 10ms. This means we can’t locate method performance issues if they complete
+in less than 10ms. SkyWalking has a threshold to control the maximum parallel degree as well.
+
+The third consideration is profiling wouldn't work for a low latency trace. Because the trace could be completed before
+profiling starts. But in reality, this is not an issue, profiling targets slow requests.
+
+Understanding the above keeps distributed tracing and APM systems useful for your OPS/SRE team.
+
+### Supported Agents
+
+This feature was first implemented in Java agent since 7.0. The Python agent supported this since 0.7.0.
+Read [this](https://skywalking.apache.org/blog/2021-09-12-skywalking-python-profiling/) for more details
\ No newline at end of file
diff --git a/docs/en/concepts-and-designs/service-mesh-probe.md b/docs/en/concepts-and-designs/service-mesh-probe.md
deleted file mode 100644
index 0c7f0de..0000000
--- a/docs/en/concepts-and-designs/service-mesh-probe.md
+++ /dev/null
@@ -1,28 +0,0 @@
-# Service Mesh Probe
-Service Mesh probes use the extendable mechanism provided in the Service Mesh implementor, like Istio.
-
-## What is Service Mesh?
-The following explanation comes from Istio's documentation.
-> The term "service mesh" is often used to describe the networks of microservices that make up such applications and the interactions between them.
-As a service mesh grows in size and complexity, it can become harder to understand and manage.
-Its requirements can include discovery, load balancing, failure recovery, metrics, and monitoring, and often more complex operational requirements
-such as A/B testing, canary releases, rate limiting, access control, and end-to-end authentication.
-
-## Where does the probe collect data from?
-Istio is a typical Service Mesh design and implementor. It defines **Control Plane** and **Data Plane**,
-which are widely used. Here is the Istio Architecture:
-
-
-
-The Service Mesh probe can choose to collect data from **Data Plane**. In Istio, it means collecting telemetry data from
-Envoy sidecar (Data Plane). The probe collects two telemetry entities from the client end and the server end per request.
-
-## How does Service Mesh make backend work?
-In this kind of probes, you can see that there is no trace related to them. So how does the SkyWalking
-platform manage to work?
-
-The Service Mesh probe collects telemetry data from each request, so they know about information such as the source, destination,
-endpoint, latency and status. From these information, the backend can tell the whole topology map by combining these calls
-into lines, as well as the metrics of each node through their incoming requests. The backend requests for the same
-metrics data by parsing the trace data. In short:
-**The Service Mesh metrics work exactly the same way as the metrics that are generated by trace parsers.**
diff --git a/docs/menu.yml b/docs/menu.yml
index d4939e3..7d93562 100644
--- a/docs/menu.yml
+++ b/docs/menu.yml
@@ -26,7 +26,7 @@ catalog:
path: "/en/concepts-and-designs/overview"
- name: "Project Goals"
path: "/en/concepts-and-designs/project-goals"
- - name: "Probe"
+ - name: "Agents"
catalog:
- name: "Introduction"
path: "/en/concepts-and-designs/probe-introduction"
@@ -34,10 +34,10 @@ catalog:
path: "/en/concepts-and-designs/service-agent"
- name: "Manual Instrument SDK"
path: "/en/concepts-and-designs/manual-sdk"
- - name: "Service Mesh probe"
- path: "/en/concepts-and-designs/service-mesh-probe"
- name: "STAM Paper, Streaming Topology Analysis Method"
path: "/en/papers/stam"
+ - name: "SDK Profiling to Fix the Blind Spot"
+ path: "/en/concepts-and-designs/sdk-profiling"
- name: "Backend"
catalog:
- name: "Overview"