You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2022/08/22 07:37:52 UTC
[GitHub] [spark] caican00 opened a new pull request, #37609: 3.3 master optimize to map
caican00 opened a new pull request, #37609:
URL: https://github.com/apache/spark/pull/37609
### What changes were proposed in this pull request?
`Traversable.toMap` changed to `collections.breakOut`, that eliminates intermediate tuple collection creation.
I optimized it with reference to this pr:https://github.com/apache/spark/pull/18693
An introduction to `Collections. BreakOut` can be found at [Stack Overflow article](https://stackoverflow.com/questions/1715681/scala-2-8-breakout).
### Why are the changes needed?
When `DeserializeToObject` is executed, converting Tuple2 to Scala Map via `. ToMap` takes a lot of cpu time.
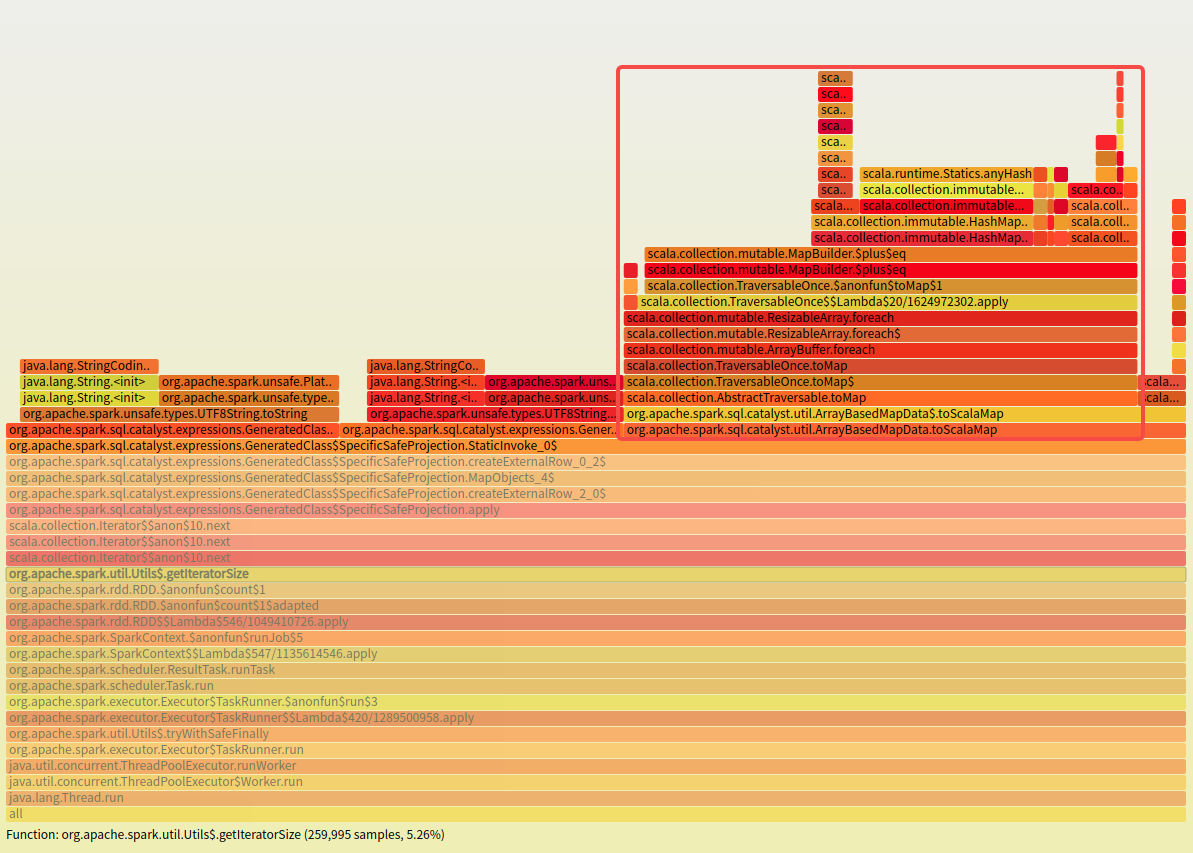

### How was this patch tested?
Unit tests run.
No performance tests performed yet.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1246533235
start this work : https://github.com/apache/spark/pull/37876
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1245153126
To check `val map: Map[K, V] = data.zip(data)(collection.breakOut)`, update bench result
```
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 1: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 16 18 2 6.4 155.5 1.0X
Use zip + collection.breakOut 3 4 1 29.3 34.1 4.6X
Use Manual builder 3 3 1 33.3 30.0 5.2X
Use Manual map 3 3 1 39.1 25.6 6.1X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 5: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 91 98 6 1.1 910.1 1.0X
Use zip + collection.breakOut 74 77 3 1.4 737.3 1.2X
Use Manual builder 72 77 4 1.4 722.1 1.3X
Use Manual map 43 46 1 2.3 426.1 2.1X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 10: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 114 120 4 0.9 1138.3 1.0X
Use zip + collection.breakOut 95 100 3 1.0 954.1 1.2X
Use Manual builder 94 101 4 1.1 942.4 1.2X
Use Manual map 85 91 4 1.2 851.7 1.3X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 20: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 156 162 4 0.6 1560.9 1.0X
Use zip + collection.breakOut 136 140 3 0.7 1356.4 1.2X
Use Manual builder 132 143 8 0.8 1317.6 1.2X
Use Manual map 166 170 3 0.6 1657.2 0.9X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 50: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 628 636 10 0.2 6277.4 1.0X
Use zip + collection.breakOut 572 583 10 0.2 5720.1 1.1X
Use Manual builder 574 584 16 0.2 5741.6 1.1X
Use Manual map 466 477 12 0.2 4660.8 1.3X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 100: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 1127 1138 15 0.1 11269.1 1.0X
Use zip + collection.breakOut 1060 1073 18 0.1 10600.8 1.1X
Use Manual builder 1050 1073 32 0.1 10500.7 1.1X
Use Manual map 1004 1017 19 0.1 10039.2 1.1X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 500: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 4634 4665 44 0.0 46338.7 1.0X
Use zip + collection.breakOut 4772 4792 28 0.0 47723.3 1.0X
Use Manual builder 4517 4597 112 0.0 45173.1 1.0X
Use Manual map 6473 6487 20 0.0 64726.3 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 1000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
--------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 12355 12366 16 0.0 123550.7 1.0X
Use zip + collection.breakOut 12585 12593 11 0.0 125846.1 1.0X
Use Manual builder 12076 12101 35 0.0 120764.3 1.0X
Use Manual map 14641 14664 34 0.0 146406.5 0.8X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 5000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
--------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 68054 68354 425 0.0 680539.3 1.0X
Use zip + collection.breakOut 73307 73316 13 0.0 733073.3 0.9X
Use Manual builder 70887 71129 342 0.0 708867.4 1.0X
Use Manual map 91936 91980 63 0.0 919357.2 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 10000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
---------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 142306 142993 971 0.0 1423062.3 1.0X
Use zip + collection.breakOut 148545 148635 127 0.0 1485454.3 1.0X
Use Manual builder 143287 144215 1313 0.0 1432866.1 1.0X
Use Manual map 198459 198995 758 0.0 1984586.7 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
Test zip to map with collectionSize = 20000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
---------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 318022 318528 716 0.0 3180223.5 1.0X
Use zip + collection.breakOut 333891 337354 2352 0.0 3338910.7 1.0X
Use Manual builder 319468 320649 1670 0.0 3194676.5 1.0X
Use Manual map 423019 423164 204 0.0 4230194.5 0.8X
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
srowen commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222261405
breakOut was removed or something in scala 2.13, I think? https://www.scala-lang.org/blog/2017/02/28/collections-rework.html
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222298867
The idea is still valid: we can write a while loop manually to build the map, instead of `zip(...).toMap`, if this code path is proven to be performance critical.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222292851
> breakOut was removed or something in scala 2.13, I think? https://www.scala-lang.org/blog/2017/02/28/collections-rework.html
Yes, Scala 2.13 already build failed seems as follows:
<img width="966" alt="image" src="https://user-images.githubusercontent.com/1475305/185921636-cfeb91bf-a170-43a6-b62c-450c96c21b6e.png">
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen closed pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
srowen closed pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
URL: https://github.com/apache/spark/pull/37609
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1244888743
interesting, we need to understand why `zip + collection.breakOut` is so fast.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] srowen commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
srowen commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1250083017
OK to continue the work here after a rebase? #37876 is merged
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1244867478
> The idea is still valid: we can write a while loop manually to build the map, instead of `zip(...).toMap`, if this code path is proven to be performance critical.
@cloud-fan Do you mean like follows?
```scala
private def zipToMapUseMapBuilder[A, B, K, V](keys: Seq[A], values: Seq[B]): Map[K, V] = {
import scala.collection.immutable
val builder = immutable.Map.newBuilder[K, V]
val keyIter = keys.iterator
val valueIter = values.iterator
while (keyIter.hasNext && valueIter.hasNext) {
builder += (keyIter.next(), valueIter.next()).asInstanceOf[(K, V)]
}
builder.result()
}
private def zipToMapUseMap[A, B, K, V](keys: Seq[A], values: Seq[B]): Map[K, V] = {
var elems: Map[K, V] = Map.empty[K, V]
val keyIter = keys.iterator
val valueIter = values.iterator
while (keyIter.hasNext && valueIter.hasNext) {
elems += (keyIter.next().asInstanceOf[K] -> valueIter.next().asInstanceOf[V])
}
elems
}
```
I write a microben to compare `data.zip(data).toMap`, `data.zip(data)(collection.breakOut)` and above methods, the result as follows:
```
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 1: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 22 22 1 4.6 217.6 1.0X
Use zip + collection.breakOut 8 9 1 11.9 84.4 2.6X
Use Manual builder 3 3 0 32.1 31.2 7.0X
Use Manual map 3 3 0 36.5 27.4 7.9X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 5: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 100 100 1 1.0 998.8 1.0X
Use zip + collection.breakOut 11 11 1 9.1 110.5 9.0X
Use Manual builder 76 76 1 1.3 755.6 1.3X
Use Manual map 47 47 1 2.1 468.1 2.1X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 10: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 123 123 1 0.8 1226.3 1.0X
Use zip + collection.breakOut 16 16 1 6.2 160.9 7.6X
Use Manual builder 95 95 1 1.1 947.2 1.3X
Use Manual map 92 94 1 1.1 922.5 1.3X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 20: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 162 162 1 0.6 1615.7 1.0X
Use zip + collection.breakOut 26 27 1 3.8 261.3 6.2X
Use Manual builder 132 133 1 0.8 1321.4 1.2X
Use Manual map 185 186 1 0.5 1846.3 0.9X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 50: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 604 606 2 0.2 6042.7 1.0X
Use zip + collection.breakOut 76 77 2 1.3 759.9 8.0X
Use Manual builder 534 537 2 0.2 5335.6 1.1X
Use Manual map 510 513 2 0.2 5102.1 1.2X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 100: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 1087 1087 0 0.1 10865.5 1.0X
Use zip + collection.breakOut 134 135 1 0.7 1336.2 8.1X
Use Manual builder 1000 1002 3 0.1 9996.8 1.1X
Use Manual map 1081 1083 2 0.1 10813.0 1.0X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 500: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 4536 4544 10 0.0 45364.9 1.0X
Use zip + collection.breakOut 778 784 5 0.1 7783.8 5.8X
Use Manual builder 4347 4347 0 0.0 43470.2 1.0X
Use Manual map 6775 6785 15 0.0 67745.2 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 1000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
--------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 11813 11822 13 0.0 118125.2 1.0X
Use zip + collection.breakOut 1590 1601 15 0.1 15898.3 7.4X
Use Manual builder 11431 11450 27 0.0 114312.3 1.0X
Use Manual map 14801 14812 16 0.0 148005.2 0.8X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 5000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
--------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 64917 65007 127 0.0 649172.0 1.0X
Use zip + collection.breakOut 8127 8130 5 0.0 81265.8 8.0X
Use Manual builder 63836 63959 174 0.0 638356.4 1.0X
Use Manual map 88139 88308 239 0.0 881392.4 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 10000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
---------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 130985 131331 489 0.0 1309847.7 1.0X
Use zip + collection.breakOut 16133 16142 13 0.0 161325.8 8.1X
Use Manual builder 136655 136916 369 0.0 1366553.8 1.0X
Use Manual map 190525 190794 380 0.0 1905252.4 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 20000: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
---------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 306207 306628 595 0.0 3062071.9 1.0X
Use zip + collection.breakOut 32482 32498 23 0.0 324818.3 9.4X
Use Manual builder 336547 337705 1637 0.0 3365473.0 0.9X
Use Manual map 410734 411271 758 0.0 4107344.5 0.7X
```
From the results, the performance of `while loop manually to build the map` is not fast enough. Is there a problem with my test code?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1245374210
Great! Seems we can always do `while loop manually`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222629183
```
git grep "zip" | grep ".toMap"| grep -v Suite | grep -v examples | awk -F ':' '{print $1}' | uniq | wc -l
31
```
31 file has `zip(...).toMap` or `zipWithIndex.toMap`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
AmplabJenkins commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222161075
Can one of the admins verify this patch?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] caican00 commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
caican00 commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222240163
> Nice try! Do we have some perf numbers?
@cloud-fan Thanks for your reply. I don't have any perf numbers right now but I'm going to do some performance tests to provide some perf numbers.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1244919208
I seem to know the reason, `data.zip(data)(collection.breakOut)` returns `CanBuildFrom[From, T, To]` instead of `Map[Any, Any]`, so what we should actually test is `val map:Map[K, V] = data.zip(data)(collection.breakOut)`, let me re-run the bench
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1253464163
> OK to continue the work here after a rebase? #37876 is merged
Hmm... I think we can close this pr, https://github.com/apache/spark/pull/37876 is the replacement of this one
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] caican00 commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
caican00 commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1221982822
gently ping @srowen
Can you help to verify this patch?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222622931
> I think we can test the performance of this api in Scala 2.13 to check if there is targeted optimization in Scala 2.13
Checked, Scala 2.13 has the same problem.
@caican00 Does `zipWithIndex.toMap` have the same problem?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1245286689
```
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 150: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 1407 1408 1 0.1 14071.2 1.0X
Use zip + collection.breakOut 1327 1328 2 0.1 13270.1 1.1X
Use Manual builder 1282 1282 0 0.1 12815.3 1.1X
Use Manual map 1734 1735 1 0.1 17339.8 0.8X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 200: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 1769 1769 1 0.1 17688.7 1.0X
Use zip + collection.breakOut 1595 1598 5 0.1 15949.0 1.1X
Use Manual builder 1544 1546 3 0.1 15440.0 1.1X
Use Manual map 2416 2418 2 0.0 24161.1 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 300: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 2701 2705 6 0.0 27007.0 1.0X
Use zip + collection.breakOut 2472 2475 4 0.0 24719.1 1.1X
Use Manual builder 2379 2384 8 0.0 23787.5 1.1X
Use Manual map 3803 3807 5 0.0 38031.9 0.7X
OpenJDK 64-Bit Server VM 1.8.0_345-b01 on Linux 5.15.0-1019-azure
Intel(R) Xeon(R) Platinum 8272CL CPU @ 2.60GHz
Test zip to map with collectionSize = 400: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
-------------------------------------------------------------------------------------------------------------------------
Use zip + toMap 3757 3758 2 0.0 37565.1 1.0X
Use zip + collection.breakOut 3446 3447 3 0.0 34455.1 1.1X
Use Manual builder 3314 3318 5 0.0 33139.8 1.1X
Use Manual map 5283 5287 5 0.0 52832.3 0.7X
```
Add results of input size 150, 200, 300, 400.
@cloud-fan , from bench results:
- If input data size < 500, the performance of using `zip + collection.breakOut` and `while loop manually to build the map with mapbuilder` are close, 10%+ faster than `zip(...).toMap`.
- If input data size >= 500, will be no significant performance gap
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
cloud-fan commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222013683
Nice try! Do we have some perf numbers?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1222305586
I think we can test the performance of this api in Scala 2.13 to check if there is targeted optimization in Scala 2.13
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1227076112
Are you still interested in this pr @caican00
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #37609: [SPARK-40175][SQL]Speed up conversion of Tuple2 to Scala Map
Posted by GitBox <gi...@apache.org>.
LuciferYang commented on PR #37609:
URL: https://github.com/apache/spark/pull/37609#issuecomment-1245413079
> Great! Seems we can always do `while loop manually`?
Yes, there should be many similar case and I think this should be a valuable optimization
However, before I doing something, I still want to ask @caican00 , will you continue this optimization?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org