You are viewing a plain text version of this content. The canonical link for it is here.
Posted to github@arrow.apache.org by GitBox <gi...@apache.org> on 2021/07/26 15:36:11 UTC
[GitHub] [arrow] romgrk-comparative opened a new issue #10803: Reading strings efficiently in C++
romgrk-comparative opened a new issue #10803:
URL: https://github.com/apache/arrow/issues/10803
I'm writing a tool that needs to ingest parquet files, and the most expensive item right now are string columns. I'm trying to ensure that the C++ code deals with dictionary indexes rather than actual strings as it's more efficient.
The first thing I'm wondering is, is the output from `parquet-meta` below saying that this column is a string with `PLAIN_DICTIONARY` encoding?
```
period: BINARY SNAPPY DO:32017278 FPO:32017306 SZ:80/76/0.95 VC:1116674 ENC:PLAIN,RLE,PLAIN_DICTIONARY ST:[min: CP, max: OP, num_nulls: 0]
```
Because the code I've been using to access those strings doesn't return indexes, it returns actual strings:
```c++
// std::shared_ptr<arrow::ArrayData> array
const int64_t length = array->length;
const int32_t *index = array->GetValues<int32_t>(1, 0);
const char *view = array->GetValues<char>(2, 0);
// ...use view[index]...
```
I'm probably accessing string wrong here but I'd be happy to be corrected on the usage of the C++ API.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
westonpace commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887174376
Ah, I see the issue now. Reading the data as a dictionary is indeed possible. You will need to inform the reader that you wish to read the column as a dictionary. In `pyarrow` you can see this exposed as the `read_dictionary` property described [here](https://arrow.apache.org/docs/python/generated/pyarrow.parquet.read_table.html).
A short (well, for C++) C++ example is here:
```
arrow::fs::LocalFileSystem file_system;
ARROW_ASSIGN_OR_RAISE(auto input, file_system.OpenInputFile("/tmp/foo.parquet"));
parquet::ArrowReaderProperties arrow_reader_properties =
parquet::default_arrow_reader_properties();
// Here we configure the reader to read the first column as a dictionary
arrow_reader_properties.set_read_dictionary(0, true);
parquet::ReaderProperties reader_properties =
parquet::default_reader_properties();
// Open Parquet file reader
std::unique_ptr<parquet::arrow::FileReader> arrow_reader;
auto reader_builder = parquet::arrow::FileReaderBuilder();
reader_builder.properties(arrow_reader_properties);
ARROW_RETURN_NOT_OK(reader_builder.Open(std::move(input), reader_properties));
ARROW_RETURN_NOT_OK(reader_builder.Build(&arrow_reader));
std::shared_ptr<arrow::Table> table;
ARROW_RETURN_NOT_OK(arrow_reader->ReadTable(&table));
std::shared_ptr<arrow::Array> arr = table->column(0)->chunk(0);
std::shared_ptr<arrow::DictionaryArray> dict_arr = std::dynamic_pointer_cast<arrow::DictionaryArray>(arr);
std::shared_ptr<arrow::Int32Array> dict_indices_arr = std::dynamic_pointer_cast<arrow::Int32Array>(dict_arr->indices());
std::shared_ptr<arrow::StringArray> dict_values_arr = std::dynamic_pointer_cast<arrow::StringArray>(dict_arr->dictionary());
const int32_t* dict_indices = dict_indices_arr->raw_values();
const int32_t* string_offsets = dict_values_arr->raw_value_offsets();
const char* string_values = (char*)(dict_values_arr->raw_data());
std::cout << "There are " << arr->length() << " items in the array" << std::endl;
std::cout << "There are " << dict_values_arr->length() << " values in the dictionary" << std::endl;
std::cout << "Offsets length: " << dict_values_arr->value_offsets()->size() << std::endl;
for (int i = 0; i < arr->length(); i++) {
std::cout << "Item: " << i << std::endl;
std::cout << " Dictionary Index: " << dict_indices[i] << std::endl;
std::cout << " Values Start: " << string_offsets[dict_indices[i]] << std::endl;
std::cout << " Values End: " << string_offsets[dict_indices[i]+1] << std::endl;
std::cout << " First Char: " << string_values[string_offsets[dict_indices[i]]] << std::endl;
}
```
What you will get back in Arrow is an `arrow::DictionaryArray` which is represented by one parent array, two child arrays, and a total of 5 possible buffers.
`arr->indices()` is an `Int32Array` of the offsets (with two buffers, one for values and one optional validity map).
`arr->dictionary()` is a `StringArray` of the values (with three buffers, one for values, one for offsets, and one optional validity map).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative edited a comment on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative edited a comment on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887064126
> I'm a little confused by this point. In the code below you are creating two pointers, index should be a pointer to the indices and view should be a pointer to the data.
You're right, I haven't described everything.
When I inspect the actual data, each string is repeated as many times as it appears in the data. The offsets `index` don't point to the same string even if it's the same value, they point to different strings.
```c++
const int64_t length = array->length;
const int32_t *index = array->GetValues<int32_t>(1, 0);
const char *view = array->GetValues<char>(2, 0);
for (int64_t i = 0; i < length; ++i) {
auto valueStart = index[i];
auto valueEnd = index[i + 1]; // <-- Because the offset is retrieved from
// the next value's start offset, it's also
// impossible to point to the same memory
// region for multiple rows :[
auto valueData = view + valueStart;
auto valueLength = valueEnd - valueStart;
std::string value(valueData, valueLength);
printf("%s: %i \n", value.c_str(), valueStart);
}
```
Example output:
```bash
a: 0
b: 1
c: 2
a: 3 # Here, I'd want the offset to point to the same memory as the first line
...
```
I'm wondering if there is something here that I should be doing differently to retrieve the dictionary indexes instead of the raw data. Or maybe my file isn't even PLAIN_DICTIONARY encoded? The output of parquet-meta lists 3 different encoding types for the column, not sure why.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887069676
Furthermore, if I inspect the file offset given by python above, the table in question, which has only 2 values in it (`android` and `ios`), seems to be very small and concise in the parquet file:
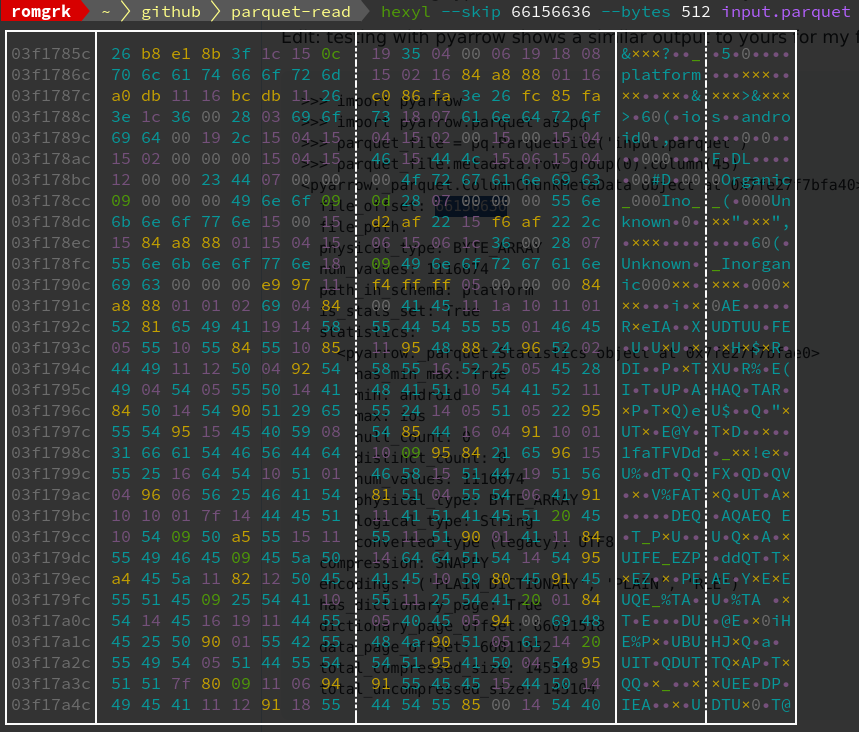
So I really wonder why apache arrow comes up with this huge and unnecessary string array, and if I can do something to avoid that.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
westonpace commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887046168
> The first thing I'm wondering is, is the output from parquet-meta below saying that this column is a string with PLAIN_DICTIONARY encoding?
I'm not familiar with `parquet-meta` but yes, that would be my interpretation. I get similar output from pyarrow when looking at a file I know is dictionary encoded:
```
>>> import pyarrow
>>> import pyarrow.parquet as pq
>>> long_str = 'x' * 10000000
>>> arr = pyarrow.array([long_str, long_str, long_str])
>>> table = pyarrow.Table.from_arrays([arr], ["data"])
>>> pq.write_table(table, "/tmp/foo.parquet")
>>> parquet_file = pq.ParquetFile('/tmp/foo.parquet')
>>> parquet_file.metadata.row_group(0).column(0)
<pyarrow._parquet.ColumnChunkMetaData object at 0x7f55b7d6aa80>
file_offset: 469121
file_path:
physical_type: BYTE_ARRAY
num_values: 3
path_in_schema: data
is_stats_set: True
statistics:
<pyarrow._parquet.Statistics object at 0x7f55dfc66e40>
has_min_max: False
min: None
max: None
null_count: 0
distinct_count: 0
num_values: 3
physical_type: BYTE_ARRAY
logical_type: String
converted_type (legacy): UTF8
compression: SNAPPY
encodings: ('PLAIN_DICTIONARY', 'PLAIN', 'RLE', 'PLAIN')
has_dictionary_page: True
dictionary_page_offset: 4
data_page_offset: 469089
total_compressed_size: 469117
total_uncompressed_size: 10000053
```
Here I know it is dictionary encoded because the total uncompressed size is 10MB (and there are 3 values in my array each of which should be 10MB on its own).
> Because the code I've been using to access those strings doesn't return indexes, it returns actual strings:
I'm a little confused by this point. In the code below you are creating two pointers, `index` should be a pointer to the indices and `view` should be a pointer to the data. This is how dictionary arrays are typically stored. One buffer (usually with lots of elements) for indices and another buffer (usually with a small number of elements) for values.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace edited a comment on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
westonpace edited a comment on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-893106284
Sorry, it seems I missed this.
> If the schema isn't known upfront, is it possible to set the read_dictionary flag after opening the file?
I think you can get away with this. If you can't then it shouldn't be too much overhead to open the file twice. First, open it and read the metadata to determine the columns. Second, open it and read everything.
> How can one differentiate when an Array is a DynamicArray and when it's not?
I'll assume you mean `DictionaryArray`? You can determine this from the Array's type (`arr->type()->id() == arrow::Type::DICTIONARY` I think)
> Are the dictionaries the same for all chunks of a column, or can different chunks have different dictionaries?
I'm fairly certain both Arrow and Parquet support having different dictionaries in different chunks. It's something of a nuisance and there are some internal utilities in Arrow for unifying dictionaries.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace edited a comment on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
westonpace edited a comment on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-893106284
Sorry, it seems I missed this.
> If the schema isn't known upfront, is it possible to set the read_dictionary flag after opening the file?
I think you can get away with this. If you can't then it shouldn't be too much overhead to open the file twice. First, open it and read the metadata to determine the columns. Second, open it and read everything.
> How can one differentiate when an Array is a DynamicArray and when it's not?
I'll assume you mean `DictionaryArray`? You can determine this from the Array's type (`arr->type()->id() == arrow::Type::DICTIONARY` I think)
> Are the dictionaries the same for all chunks of a column, or can different chunks have different dictionaries?
I'm fairly certain both Arrow and Parquet support having different dictionaries in different chunks. It's something of a nuisance and there are some internal utilities in Arrow for unifying dictionaries.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
westonpace commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-893106284
Sorry, it seems I missed this.
> If the schema isn't known upfront, is it possible to set the read_dictionary flag after opening the file?
I think you can get away with this. If you can't then it shouldn't be too much overhead to open the file twice. First, open it and read the metadata to determine the columns. Second, open it and read everything.
> How can one differentiate when an Array is a DynamicArray and when it's not?
I'll assume you mean `DictionaryArray`? You can determine this from the Array's type (`arr->type()->id() == 1arrow::Type::DICTIONARY` I think)
> Are the dictionaries the same for all chunks of a column, or can different chunks have different dictionaries?
I'm fairly certain both Arrow and Parquet support having different dictionaries in different chunks. It's something of a nuisance and there are some internal utilities in Arrow for unifying dictionaries.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace edited a comment on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
westonpace edited a comment on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887174376
Ah, I see the issue now. Reading the data as a dictionary is indeed possible. You will need to inform the reader that you wish to read the column as a dictionary. In `pyarrow` you can see this exposed as the `read_dictionary` property described [here](https://arrow.apache.org/docs/python/generated/pyarrow.parquet.read_table.html).
A short (well, for C++) C++ example is here:
```
arrow::fs::LocalFileSystem file_system;
ARROW_ASSIGN_OR_RAISE(auto input, file_system.OpenInputFile("/tmp/foo.parquet"));
parquet::ArrowReaderProperties arrow_reader_properties =
parquet::default_arrow_reader_properties();
// Here we configure the reader to read the first column as a dictionary
arrow_reader_properties.set_read_dictionary(0, true);
parquet::ReaderProperties reader_properties =
parquet::default_reader_properties();
// Open Parquet file reader
std::unique_ptr<parquet::arrow::FileReader> arrow_reader;
auto reader_builder = parquet::arrow::FileReaderBuilder();
reader_builder.properties(arrow_reader_properties);
ARROW_RETURN_NOT_OK(reader_builder.Open(std::move(input), reader_properties));
ARROW_RETURN_NOT_OK(reader_builder.Build(&arrow_reader));
std::shared_ptr<arrow::Table> table;
ARROW_RETURN_NOT_OK(arrow_reader->ReadTable(&table));
std::shared_ptr<arrow::Array> arr = table->column(0)->chunk(0);
std::shared_ptr<arrow::DictionaryArray> dict_arr = std::dynamic_pointer_cast<arrow::DictionaryArray>(arr);
std::shared_ptr<arrow::Int32Array> dict_indices_arr = std::dynamic_pointer_cast<arrow::Int32Array>(dict_arr->indices());
std::shared_ptr<arrow::StringArray> dict_values_arr = std::dynamic_pointer_cast<arrow::StringArray>(dict_arr->dictionary());
const int32_t* dict_indices = dict_indices_arr->raw_values();
const int32_t* string_offsets = dict_values_arr->raw_value_offsets();
const char* string_values = (char*)(dict_values_arr->raw_data());
std::cout << "There are " << arr->length() << " items in the array" << std::endl;
std::cout << "There are " << dict_values_arr->length() << " values in the dictionary" << std::endl;
for (int i = 0; i < arr->length(); i++) {
std::cout << "Item: " << i << std::endl;
std::cout << " Dictionary Index: " << dict_indices[i] << std::endl;
std::cout << " Values Start: " << string_offsets[dict_indices[i]] << std::endl;
std::cout << " Values End: " << string_offsets[dict_indices[i]+1] << std::endl;
std::cout << " First Char: " << string_values[string_offsets[dict_indices[i]]] << std::endl;
}
```
What you will get back in Arrow is an `arrow::DictionaryArray` which is represented by one parent array, two child arrays, and a total of 5 possible buffers.
`arr->indices()` is an `Int32Array` of the offsets (with two buffers, one for values and one optional validity map).
`arr->dictionary()` is a `StringArray` of the values (with three buffers, one for values, one for offsets, and one optional validity map).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887196040
Thanks a lot, that's super useful!
A few questions before I close the issue:
- If the schema isn't known upfront, is it possible to set the `read_dictionary` flag after opening the file?
- How can one differentiate when an `Array` is a `DynamicArray` and when it's not?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887064126
> I'm a little confused by this point. In the code below you are creating two pointers, index should be a pointer to the indices and view should be a pointer to the data.
You're right, I haven't described everything.
When I inspect the actual data, each string is repeated as many times as it appears in the data. The offsets `index` don't point to the same string even if it's the same value, they point to different strings.
```c++
const int64_t length = array->length;
const int32_t *index = array->GetValues<int32_t>(1, 0);
const char *view = array->GetValues<char>(2, 0);
for (int64_t i = 0; i < length; ++i) {
auto valueStart = index[i];
auto valueEnd = index[i + 1]; // <-- Because the offset is retrieved from
// the next value's start offset, it's also
// impossible to point to the same memory
// region for multiple rows :[
auto valueData = view + valueStart;
auto valueLength = valueEnd - valueStart;
std::string value(valueData, valueLength);
printf("%s: %i \n", value.c_str(), valueStart);
}
```
Example output:
```bash
a: 0
b: 1
c: 2
a: 3 # Here, I'd want the offset to point to the same memory as the first line
...
```
I'm wondering if there is something here that I should be doing differently to retrieve the dictionary indexes instead of the raw data.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative edited a comment on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative edited a comment on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887196040
Thanks a lot, that's super useful!
A few questions before I close the issue:
- If the schema isn't known upfront, is it possible to set the `read_dictionary` flag after opening the file?
- How can one differentiate when an `Array` is a `DynamicArray` and when it's not?
- Are the dictionaries the same for all chunks of a column, or can different chunks have different dictionaries?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative closed issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative closed issue #10803:
URL: https://github.com/apache/arrow/issues/10803
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative edited a comment on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative edited a comment on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-887064126
> I'm a little confused by this point. In the code below you are creating two pointers, index should be a pointer to the indices and view should be a pointer to the data.
You're right, I haven't described everything.
When I inspect the actual data, each string is repeated as many times as it appears in the data. The offsets `index` don't point to the same string even if it's the same value, they point to different strings.
```c++
const int64_t length = array->length;
const int32_t *index = array->GetValues<int32_t>(1, 0);
const char *view = array->GetValues<char>(2, 0);
for (int64_t i = 0; i < length; ++i) {
auto valueStart = index[i];
auto valueEnd = index[i + 1]; // <-- Because the offset is retrieved from
// the next value's start offset, it's also
// impossible to point to the same memory
// region for multiple rows :[
auto valueData = view + valueStart;
auto valueLength = valueEnd - valueStart;
std::string value(valueData, valueLength);
printf("%s: %i \n", value.c_str(), valueStart);
}
```
Example output:
```bash
a: 0
b: 1
c: 2
a: 3 # Here, I'd want the offset to point to the same memory as the first line
...
```
I'm wondering if there is something here that I should be doing differently to retrieve the dictionary indexes instead of the raw data. Or maybe my file isn't even PLAIN_DICTIONARY encoded? The output of parquet-meta lists 3 different encoding types for the column, not sure why.
Edit: testing with pyarrow shows a similar output to yours for my file, so it seems to be PLAIN_DICTIONARY:
```
>>> import pyarrow
>>> import pyarrow.parquet as pq
>>> parquet_file = pq.ParquetFile('input.parquet')
>>> parquet_file.metadata.row_group(0).column(45)
<pyarrow._parquet.ColumnChunkMetaData object at 0x7fe27f7bfa40>
file_offset: 66156636
file_path:
physical_type: BYTE_ARRAY
num_values: 1116674
path_in_schema: platform
is_stats_set: True
statistics:
<pyarrow._parquet.Statistics object at 0x7fe27f7bfae0>
has_min_max: True
min: android
max: ios
null_count: 0
distinct_count: 0
num_values: 1116674
physical_type: BYTE_ARRAY
logical_type: String
converted_type (legacy): UTF8
compression: SNAPPY
encodings: ('PLAIN_DICTIONARY', 'PLAIN', 'RLE')
has_dictionary_page: True
dictionary_page_offset: 66011518
data_page_offset: 66011552
total_compressed_size: 145118
total_uncompressed_size: 145104
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] westonpace commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
westonpace commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-893106284
Sorry, it seems I missed this.
> If the schema isn't known upfront, is it possible to set the read_dictionary flag after opening the file?
I think you can get away with this. If you can't then it shouldn't be too much overhead to open the file twice. First, open it and read the metadata to determine the columns. Second, open it and read everything.
> How can one differentiate when an Array is a DynamicArray and when it's not?
I'll assume you mean `DictionaryArray`? You can determine this from the Array's type (`arr->type()->id() == 1arrow::Type::DICTIONARY` I think)
> Are the dictionaries the same for all chunks of a column, or can different chunks have different dictionaries?
I'm fairly certain both Arrow and Parquet support having different dictionaries in different chunks. It's something of a nuisance and there are some internal utilities in Arrow for unifying dictionaries.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [arrow] romgrk-comparative commented on issue #10803: Reading strings efficiently in C++
Posted by GitBox <gi...@apache.org>.
romgrk-comparative commented on issue #10803:
URL: https://github.com/apache/arrow/issues/10803#issuecomment-893651302
Alright, yes that was `DictionaryArray`, thanks for the precisions!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: github-unsubscribe@arrow.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org