You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2022/11/16 03:01:12 UTC
[GitHub] [spark] zhengruifeng opened a new pull request, #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
zhengruifeng opened a new pull request, #34367:
URL: https://github.com/apache/spark/pull/34367
### What changes were proposed in this pull request?
introduce a new node `RankLimit` to filter out uncessary rows based on rank computed on partial dataset.
it supports following pattern:
```
select (... (row_number|rank|dense_rank)() over ( [partition by ...] order by ... ) as rn)
where rn (==|<|<=) k and other conditions
```
For these three rank functions (row_number|rank|dense_rank), the rank of a key computed on partitial dataset always <= its final rank computed on the whole dataset,so we can safely discard rows with partitial rank > `k`, anywhere.
### Why are the changes needed?
1, reduce the shuffle write;
2, solve skewed-window problem, a practical case was optimized from 2.5h to 26min
### Does this PR introduce _any_ user-facing change?
a new config is added
### How was this patch tested?
1, added testsuits, practical cases on our production system
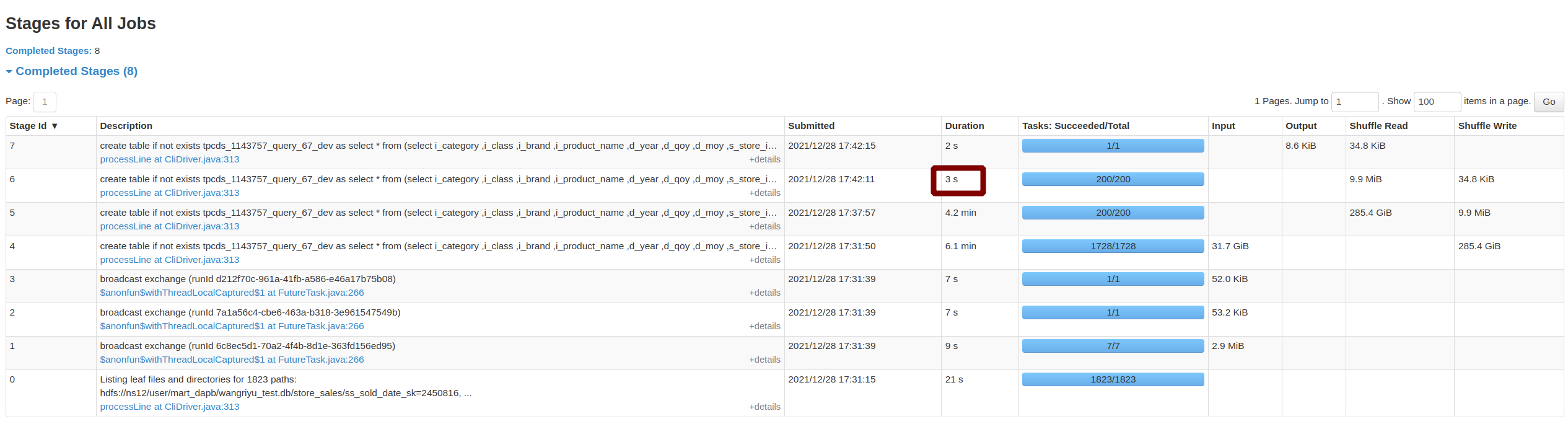
2, 10TiB TPC-DS - q67:
Before this PR | After this PR
--- | ---
Job Duration=58min|Job Duration=11min
Stage Duration=50min|Stage Duration=3sec
Stage Shuffle=58.0 GiB|Stage Shuffle=9.9 MiB
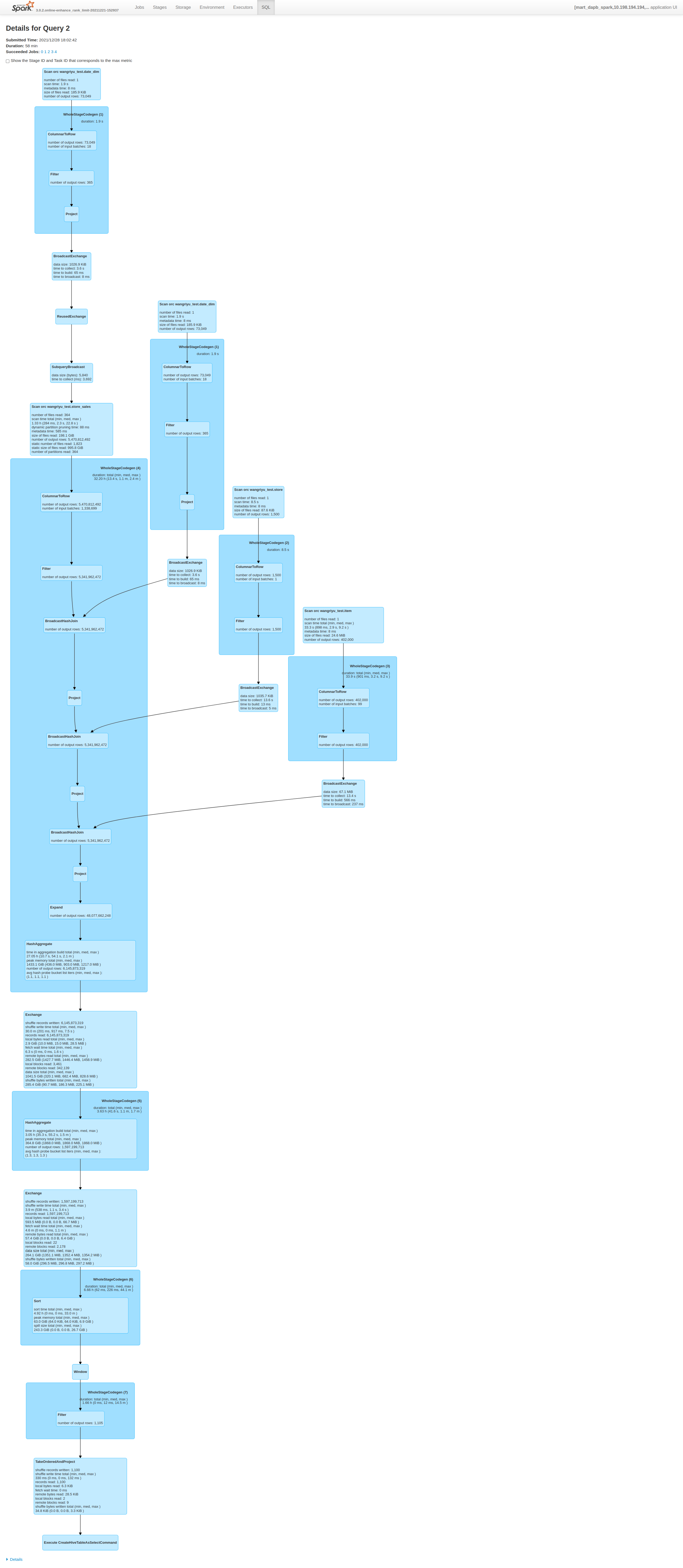|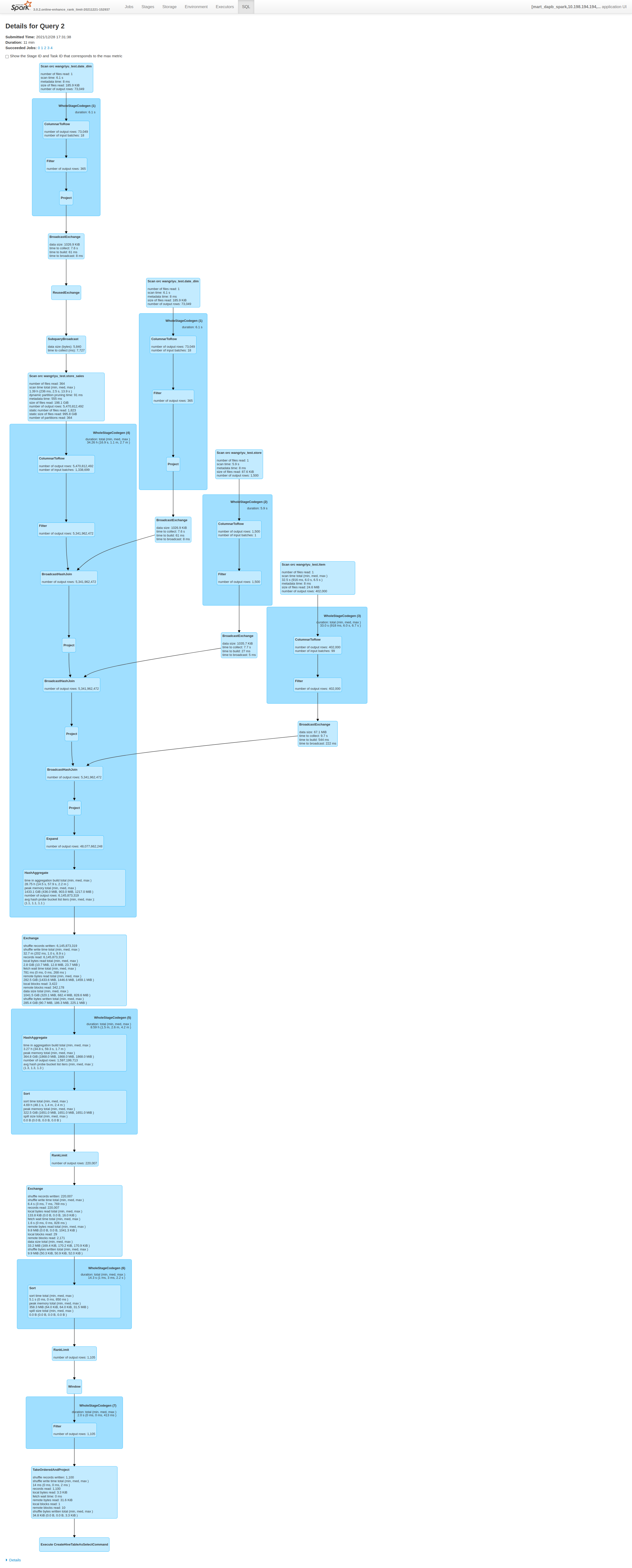
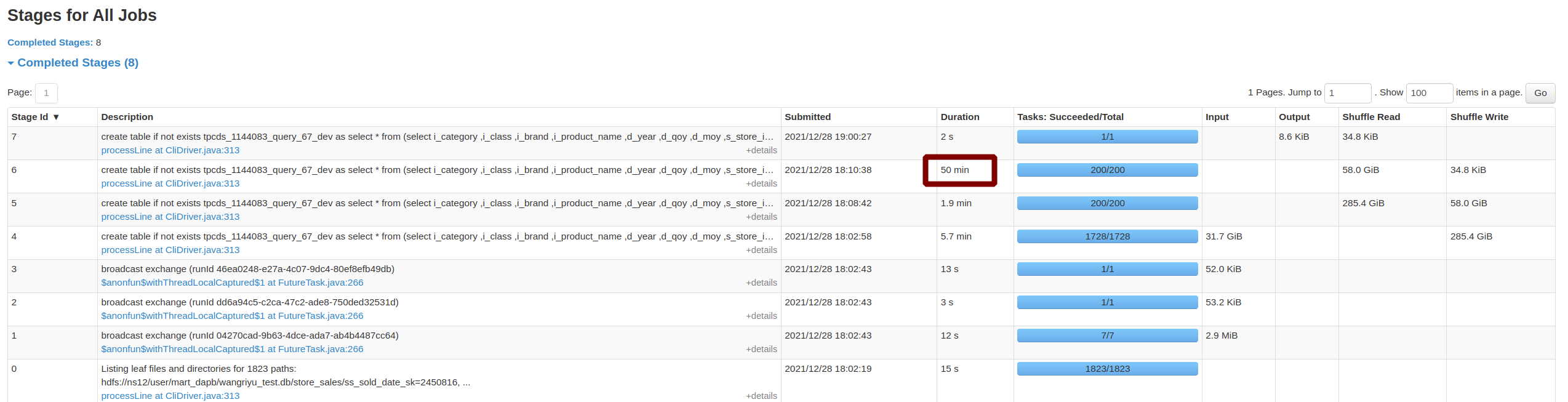|
3, added benchmark:
```
[info] Java HotSpot(TM) 64-Bit Server VM 1.8.0_301-b09 on Linux 5.11.0-41-generic
[info] Intel(R) Core(TM) i7-8850H CPU @ 2.60GHz
[info] Benchmark Top-K: Best Time(ms) Avg Time(ms) Stdev(ms) Rate(M/s) Per Row(ns) Relative
[info] ------------------------------------------------------------------------------------------------------------------------------------
[info] ROW_NUMBER WITHOUT PARTITION 10688 11377 664 2.0 509.6 1.0X
[info] ROW_NUMBER WITHOUT PARTITION (RANKLIMIT Sorting) 2678 2962 137 7.8 127.7 4.0X
[info] ROW_NUMBER WITHOUT PARTITION (RANKLIMIT TakeOrdered) 1585 1611 19 13.2 75.6 6.7X
[info] RANK WITHOUT PARTITION 11504 12056 406 1.8 548.6 0.9X
[info] RANK WITHOUT PARTITION (RANKLIMIT) 3020 3148 89 6.9 144.0 3.5X
[info] DENSE_RANK WITHOUT PARTITION 11728 11915 216 1.8 559.3 0.9X
[info] DENSE_RANK WITHOUT PARTITION (RANKLIMIT) 2632 2906 182 8.0 125.5 4.1X
[info] ROW_NUMBER WITH PARTITION 23139 24025 500 0.9 1103.4 0.5X
[info] ROW_NUMBER WITH PARTITION (RANKLIMIT Sorting) 7034 7575 361 3.0 335.4 1.5X
[info] ROW_NUMBER WITH PARTITION (RANKLIMIT TakeOrdered) 5958 6391 311 3.5 284.1 1.8X
[info] RANK WITH PARTITION 24942 26005 795 0.8 1189.4 0.4X
[info] RANK WITH PARTITION (RANKLIMIT) 7217 7517 219 2.9 344.1 1.5X
[info] DENSE_RANK WITH PARTITION 24843 26726 221 0.8 1184.6 0.4X
[info] DENSE_RANK WITH PARTITION (RANKLIMIT) 7455 7978 560 2.8 355.5 1.4X
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
github-actions[bot] commented on PR #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-1261602326
We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable.
If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
github-actions[bot] closed pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
URL: https://github.com/apache/spark/pull/34367
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
beliefer commented on PR #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-1316464454
> It is a long time since I initially sent this PR, and I don't have time to work on it, if any guys are interested in this optimization, feel free to take over it. cc @beliefer
OK. Let me see.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
zhengruifeng commented on PR #34367:
URL: https://github.com/apache/spark/pull/34367#issuecomment-1316354088
It is a long time since I initially sent this PR, and I don't have time to work on it, if any guys are interested in this optimization, feel free to take over it. cc @beliefer
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
Posted by GitBox <gi...@apache.org>.
github-actions[bot] closed pull request #34367: [SPARK-37099][SQL] Introduce a rank-based filter to optimize top-k computation
URL: https://github.com/apache/spark/pull/34367
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org