You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@zeppelin.apache.org by zj...@apache.org on 2020/10/29 01:58:28 UTC
[zeppelin] branch branch-0.9 updated: [ZEPPELIN-5102]. Simplify
spark sql error message
This is an automated email from the ASF dual-hosted git repository.
zjffdu pushed a commit to branch branch-0.9
in repository https://gitbox.apache.org/repos/asf/zeppelin.git
The following commit(s) were added to refs/heads/branch-0.9 by this push:
new 2b8341e [ZEPPELIN-5102]. Simplify spark sql error message
2b8341e is described below
commit 2b8341e8a8585fbe68d252140ab1f90251cd7d17
Author: Jeff Zhang <zj...@apache.org>
AuthorDate: Fri Oct 23 10:35:09 2020 +0800
[ZEPPELIN-5102]. Simplify spark sql error message
### What is this PR for?
In this PR, we only print the error message when it is `AnalysisException`, this would make the error message more clear for users.
### What type of PR is it?
[Improvement]
### Todos
* [ ] - Task
### What is the Jira issue?
* https://issues.apache.org/jira/browse/ZEPPELIN-5102
### How should this be tested?
* Manually tested
### Screenshots (if appropriate)
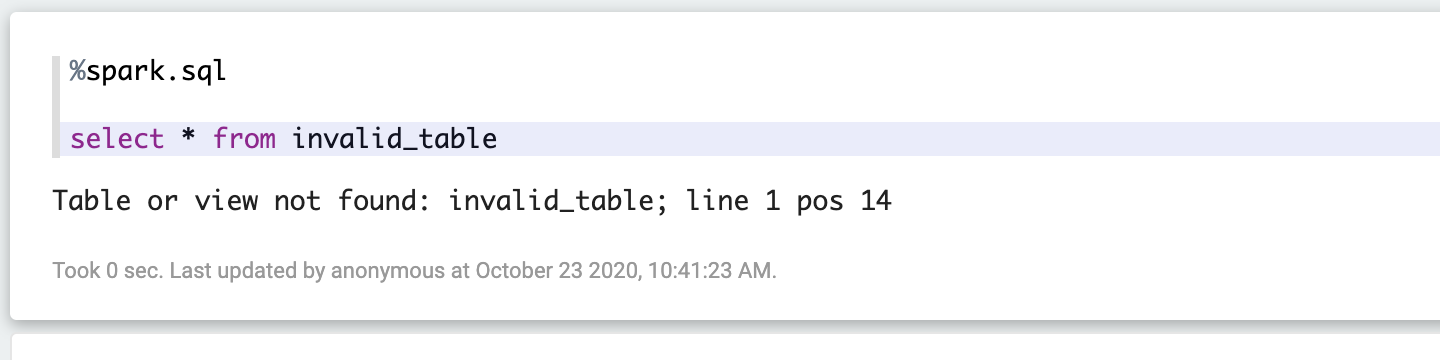
### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? No
Author: Jeff Zhang <zj...@apache.org>
Closes #3951 from zjffdu/ZEPPELIN-5102 and squashes the following commits:
a912b219e [Jeff Zhang] [ZEPPELIN-5102]. Simplify spark sql error message
(cherry picked from commit fa1469927f59cc0ec7ead1b07502348a8d28bee3)
Signed-off-by: Jeff Zhang <zj...@apache.org>
---
.../apache/zeppelin/spark/SparkSqlInterpreter.java | 39 +++++++++-----
.../zeppelin/spark/SparkSqlInterpreterTest.java | 61 +++++++++++-----------
.../integration/ZSessionIntegrationTest.java | 4 +-
3 files changed, 60 insertions(+), 44 deletions(-)
diff --git a/spark/interpreter/src/main/java/org/apache/zeppelin/spark/SparkSqlInterpreter.java b/spark/interpreter/src/main/java/org/apache/zeppelin/spark/SparkSqlInterpreter.java
index d440da1..4161f1a 100644
--- a/spark/interpreter/src/main/java/org/apache/zeppelin/spark/SparkSqlInterpreter.java
+++ b/spark/interpreter/src/main/java/org/apache/zeppelin/spark/SparkSqlInterpreter.java
@@ -19,6 +19,7 @@ package org.apache.zeppelin.spark;
import org.apache.commons.lang3.exception.ExceptionUtils;
import org.apache.spark.SparkContext;
+import org.apache.spark.sql.AnalysisException;
import org.apache.zeppelin.interpreter.AbstractInterpreter;
import org.apache.zeppelin.interpreter.ZeppelinContext;
import org.apache.zeppelin.interpreter.InterpreterContext;
@@ -32,6 +33,7 @@ import org.apache.zeppelin.scheduler.SchedulerFactory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
+import java.io.IOException;
import java.lang.reflect.Method;
import java.util.List;
import java.util.Properties;
@@ -84,7 +86,6 @@ public class SparkSqlInterpreter extends AbstractInterpreter {
Object sqlContext = sparkInterpreter.getSQLContext();
SparkContext sc = sparkInterpreter.getSparkContext();
- StringBuilder builder = new StringBuilder();
List<String> sqls = sqlSplitter.splitSql(st);
int maxResult = Integer.parseInt(context.getLocalProperties().getOrDefault("limit",
"" + sparkInterpreter.getZeppelinContext().getMaxResult()));
@@ -103,19 +104,33 @@ public class SparkSqlInterpreter extends AbstractInterpreter {
curSql = sql;
String result = sparkInterpreter.getZeppelinContext()
.showData(method.invoke(sqlContext, sql), maxResult);
- builder.append(result);
+ context.out.write(result);
}
+ context.out.flush();
} catch (Exception e) {
- builder.append("\n%text Error happens in sql: " + curSql + "\n");
- if (Boolean.parseBoolean(getProperty("zeppelin.spark.sql.stacktrace", "false"))) {
- builder.append(ExceptionUtils.getStackTrace(e));
- } else {
- LOGGER.error("Invocation target exception", e);
- String msg = e.getMessage()
- + "\nset zeppelin.spark.sql.stacktrace = true to see full stacktrace";
- builder.append(msg);
+ try {
+ if (e.getCause() instanceof AnalysisException) {
+ // just return the error message from spark if it is AnalysisException
+ context.out.write(e.getCause().getMessage());
+ context.out.flush();
+ return new InterpreterResult(Code.ERROR);
+ } else {
+ context.out.write("\nError happens in sql: " + curSql + "\n");
+ if (Boolean.parseBoolean(getProperty("zeppelin.spark.sql.stacktrace", "false"))) {
+ context.out.write(ExceptionUtils.getStackTrace(e.getCause()));
+ } else {
+ LOGGER.error("Invocation target exception", e);
+ String msg = e.getCause().getMessage()
+ + "\nset zeppelin.spark.sql.stacktrace = true to see full stacktrace";
+ context.out.write(msg);
+ }
+ context.out.flush();
+ return new InterpreterResult(Code.ERROR);
+ }
+ } catch (IOException ex) {
+ LOGGER.error("Fail to write output", ex);
+ return new InterpreterResult(Code.ERROR);
}
- return new InterpreterResult(Code.ERROR, builder.toString());
} finally {
sc.clearJobGroup();
if (!sparkInterpreter.isScala212()) {
@@ -123,7 +138,7 @@ public class SparkSqlInterpreter extends AbstractInterpreter {
}
}
- return new InterpreterResult(Code.SUCCESS, builder.toString());
+ return new InterpreterResult(Code.SUCCESS);
}
@Override
diff --git a/spark/interpreter/src/test/java/org/apache/zeppelin/spark/SparkSqlInterpreterTest.java b/spark/interpreter/src/test/java/org/apache/zeppelin/spark/SparkSqlInterpreterTest.java
index d32964f..843ee77 100644
--- a/spark/interpreter/src/test/java/org/apache/zeppelin/spark/SparkSqlInterpreterTest.java
+++ b/spark/interpreter/src/test/java/org/apache/zeppelin/spark/SparkSqlInterpreterTest.java
@@ -31,6 +31,7 @@ import org.junit.AfterClass;
import org.junit.BeforeClass;
import org.junit.Test;
+import java.io.IOException;
import java.util.LinkedList;
import java.util.Properties;
@@ -88,7 +89,7 @@ public class SparkSqlInterpreterTest {
}
@Test
- public void test() throws InterpreterException {
+ public void test() throws InterpreterException, IOException {
InterpreterResult result = sparkInterpreter.interpret("case class Test(name:String, age:Int)", context);
assertEquals(InterpreterResult.Code.SUCCESS, result.code());
result = sparkInterpreter.interpret("val test = sc.parallelize(Seq(Test(\"moon\\t1\", 33), Test(\"jobs\", 51), Test(\"gates\", 51), Test(\"park\\n1\", 34)))", context);
@@ -98,12 +99,12 @@ public class SparkSqlInterpreterTest {
InterpreterResult ret = sqlInterpreter.interpret("select name, age from test where age < 40", context);
assertEquals(InterpreterResult.Code.SUCCESS, ret.code());
- assertEquals(Type.TABLE, ret.message().get(0).getType());
- assertEquals("name\tage\nmoon 1\t33\npark 1\t34\n", ret.message().get(0).getData());
+ assertEquals(Type.TABLE, context.out.toInterpreterResultMessage().get(0).getType());
+ assertEquals("name\tage\nmoon 1\t33\npark 1\t34\n", context.out.toInterpreterResultMessage().get(0).getData());
ret = sqlInterpreter.interpret("select wrong syntax", context);
assertEquals(InterpreterResult.Code.ERROR, ret.code());
- assertTrue(ret.message().get(0).getData().length() > 0);
+ assertTrue(context.out.toInterpreterResultMessage().get(0).getData().length() > 0);
assertEquals(InterpreterResult.Code.SUCCESS, sqlInterpreter.interpret("select case when name='aa' then name else name end from test", context).code());
}
@@ -152,7 +153,7 @@ public class SparkSqlInterpreterTest {
}
@Test
- public void testMaxResults() throws InterpreterException {
+ public void testMaxResults() throws InterpreterException, IOException {
sparkInterpreter.interpret("case class P(age:Int)", context);
sparkInterpreter.interpret(
"val gr = sc.parallelize(Seq(P(1),P(2),P(3),P(4),P(5),P(6),P(7),P(8),P(9),P(10),P(11)))",
@@ -162,19 +163,19 @@ public class SparkSqlInterpreterTest {
InterpreterResult ret = sqlInterpreter.interpret("select * from gr", context);
assertEquals(InterpreterResult.Code.SUCCESS, ret.code());
// the number of rows is 10+1, 1 is the head of table
- assertEquals(11, ret.message().get(0).getData().split("\n").length);
- assertTrue(ret.message().get(1).getData().contains("alert-warning"));
+ assertEquals(11, context.out.toInterpreterResultMessage().get(0).getData().split("\n").length);
+ assertTrue(context.out.toInterpreterResultMessage().get(1).getData().contains("alert-warning"));
// test limit local property
context.getLocalProperties().put("limit", "5");
ret = sqlInterpreter.interpret("select * from gr", context);
assertEquals(InterpreterResult.Code.SUCCESS, ret.code());
// the number of rows is 5+1, 1 is the head of table
- assertEquals(6, ret.message().get(0).getData().split("\n").length);
+ assertEquals(6, context.out.toInterpreterResultMessage().get(0).getData().split("\n").length);
}
@Test
- public void testSingleRowResult() throws InterpreterException {
+ public void testSingleRowResult() throws InterpreterException, IOException {
sparkInterpreter.interpret("case class P(age:Int)", context);
sparkInterpreter.interpret(
"val gr = sc.parallelize(Seq(P(1),P(2),P(3),P(4),P(5),P(6),P(7),P(8),P(9),P(10)))",
@@ -195,12 +196,12 @@ public class SparkSqlInterpreterTest {
InterpreterResult ret = sqlInterpreter.interpret("select count(1), sum(age) from gr", context);
context.getLocalProperties().remove("template");
assertEquals(InterpreterResult.Code.SUCCESS, ret.code());
- assertEquals(Type.HTML, ret.message().get(0).getType());
- assertEquals("Total count: <h1>10</h1>, Total age: <h1>55</h1>", ret.message().get(0).getData());
+ assertEquals(Type.HTML, context.out.toInterpreterResultMessage().get(0).getType());
+ assertEquals("Total count: <h1>10</h1>, Total age: <h1>55</h1>", context.out.toInterpreterResultMessage().get(0).getData());
}
@Test
- public void testMultipleStatements() throws InterpreterException {
+ public void testMultipleStatements() throws InterpreterException, IOException {
sparkInterpreter.interpret("case class P(age:Int)", context);
sparkInterpreter.interpret(
"val gr = sc.parallelize(Seq(P(1),P(2),P(3),P(4)))",
@@ -211,33 +212,33 @@ public class SparkSqlInterpreterTest {
InterpreterResult ret = sqlInterpreter.interpret(
"select * --comment_1\nfrom gr;select count(1) from gr", context);
assertEquals(InterpreterResult.Code.SUCCESS, ret.code());
- assertEquals(ret.message().toString(), 2, ret.message().size());
- assertEquals(ret.message().toString(), Type.TABLE, ret.message().get(0).getType());
- assertEquals(ret.message().toString(), Type.TABLE, ret.message().get(1).getType());
+ assertEquals(context.out.toString(), 2, context.out.toInterpreterResultMessage().size());
+ assertEquals(context.out.toString(), Type.TABLE, context.out.toInterpreterResultMessage().get(0).getType());
+ assertEquals(context.out.toString(), Type.TABLE, context.out.toInterpreterResultMessage().get(1).getType());
// One correct sql + One invalid sql
ret = sqlInterpreter.interpret("select * from gr;invalid_sql", context);
assertEquals(InterpreterResult.Code.ERROR, ret.code());
- assertEquals(ret.message().toString(), 2, ret.message().size());
- assertEquals(ret.message().toString(), Type.TABLE, ret.message().get(0).getType());
+ assertEquals(context.out.toString(), 2, context.out.toInterpreterResultMessage().size());
+ assertEquals(context.out.toString(), Type.TABLE, context.out.toInterpreterResultMessage().get(0).getType());
if (!sparkInterpreter.getSparkVersion().isSpark1()) {
- assertTrue(ret.message().toString(), ret.message().get(1).getData().contains("ParseException"));
+ assertTrue(context.out.toString(), context.out.toInterpreterResultMessage().get(1).getData().contains("mismatched input"));
}
// One correct sql + One invalid sql + One valid sql (skipped)
ret = sqlInterpreter.interpret("select * from gr;invalid_sql; select count(1) from gr", context);
assertEquals(InterpreterResult.Code.ERROR, ret.code());
- assertEquals(ret.message().toString(), 2, ret.message().size());
- assertEquals(ret.message().toString(), Type.TABLE, ret.message().get(0).getType());
+ assertEquals(context.out.toString(), 2, context.out.toInterpreterResultMessage().size());
+ assertEquals(context.out.toString(), Type.TABLE, context.out.toInterpreterResultMessage().get(0).getType());
if (!sparkInterpreter.getSparkVersion().isSpark1()) {
- assertTrue(ret.message().toString(), ret.message().get(1).getData().contains("ParseException"));
+ assertTrue(context.out.toString(), context.out.toInterpreterResultMessage().get(1).getData().contains("mismatched input"));
}
// Two 2 comments
ret = sqlInterpreter.interpret(
"--comment_1\n--comment_2", context);
assertEquals(InterpreterResult.Code.SUCCESS, ret.code());
- assertEquals(ret.message().toString(), 0, ret.message().size());
+ assertEquals(context.out.toString(), 0, context.out.toInterpreterResultMessage().size());
}
@Test
@@ -285,7 +286,7 @@ public class SparkSqlInterpreterTest {
}
@Test
- public void testDDL() throws InterpreterException {
+ public void testDDL() throws InterpreterException, IOException {
InterpreterResult ret = sqlInterpreter.interpret("create table t1(id int, name string)", context);
assertEquals(InterpreterResult.Code.SUCCESS, ret.code());
// spark 1.x will still return DataFrame with non-empty columns.
@@ -300,20 +301,20 @@ public class SparkSqlInterpreterTest {
// create the same table again
ret = sqlInterpreter.interpret("create table t1(id int, name string)", context);
assertEquals(InterpreterResult.Code.ERROR, ret.code());
- assertEquals(1, ret.message().size());
- assertEquals(Type.TEXT, ret.message().get(0).getType());
- assertTrue(ret.message().get(0).getData().contains("already exists"));
+ assertEquals(1, context.out.toInterpreterResultMessage().size());
+ assertEquals(Type.TEXT, context.out.toInterpreterResultMessage().get(0).getType());
+ assertTrue(context.out.toInterpreterResultMessage().get(0).getData().contains("already exists"));
// invalid DDL
ret = sqlInterpreter.interpret("create temporary function udf1 as 'org.apache.zeppelin.UDF'", context);
assertEquals(InterpreterResult.Code.ERROR, ret.code());
- assertEquals(1, ret.message().size());
- assertEquals(Type.TEXT, ret.message().get(0).getType());
+ assertEquals(1, context.out.toInterpreterResultMessage().size());
+ assertEquals(Type.TEXT, context.out.toInterpreterResultMessage().get(0).getType());
// spark 1.x could not detect the root cause correctly
if (!sparkInterpreter.getSparkContext().version().startsWith("1.")) {
- assertTrue(ret.message().get(0).getData().contains("ClassNotFoundException") ||
- ret.message().get(0).getData().contains("Can not load class"));
+ assertTrue(context.out.toInterpreterResultMessage().get(0).getData().contains("ClassNotFoundException") ||
+ context.out.toInterpreterResultMessage().get(0).getData().contains("Can not load class"));
}
}
}
diff --git a/zeppelin-interpreter-integration/src/test/java/org/apache/zeppelin/integration/ZSessionIntegrationTest.java b/zeppelin-interpreter-integration/src/test/java/org/apache/zeppelin/integration/ZSessionIntegrationTest.java
index 12042c8..2ec61bd 100644
--- a/zeppelin-interpreter-integration/src/test/java/org/apache/zeppelin/integration/ZSessionIntegrationTest.java
+++ b/zeppelin-interpreter-integration/src/test/java/org/apache/zeppelin/integration/ZSessionIntegrationTest.java
@@ -206,7 +206,7 @@ public class ZSessionIntegrationTest extends AbstractTestRestApi {
assertEquals(Status.ERROR, result.getStatus());
assertEquals(1, result.getResults().size());
assertEquals("TEXT", result.getResults().get(0).getType());
- assertTrue(result.getResults().get(0).getData(), result.getResults().get(0).getData().contains("NoSuchTableException"));
+ assertTrue(result.getResults().get(0).getData(), result.getResults().get(0).getData().contains("Table or view not found"));
assertEquals(0, result.getJobUrls().size());
} finally {
@@ -279,7 +279,7 @@ public class ZSessionIntegrationTest extends AbstractTestRestApi {
assertEquals(Status.ERROR, result.getStatus());
assertEquals(1, result.getResults().size());
assertEquals("TEXT", result.getResults().get(0).getType());
- assertTrue(result.getResults().get(0).getData(), result.getResults().get(0).getData().contains("NoSuchTableException"));
+ assertTrue(result.getResults().get(0).getData(), result.getResults().get(0).getData().contains("Table or view not found"));
assertEquals(0, result.getJobUrls().size());
// cancel