You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by tdas <gi...@git.apache.org> on 2018/01/13 02:50:52 UTC
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
GitHub user tdas opened a pull request:
https://github.com/apache/spark/pull/20255
[SPARK-23064][DOCS][SS] Added documentation for stream-stream joins
## What changes were proposed in this pull request?
Added documentation for stream-stream joins
## How was this patch tested?
N/a
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/tdas/spark join-docs
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/20255.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #20255
----
commit 1335a6d3c00ccc04e7a2943ce041994150e8f9db
Author: Tathagata Das <ta...@...>
Date: 2018-01-13T02:48:30Z
Join docs
----
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86214 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86214/testReport)** for PR 20255 at commit [`b8381ef`](https://github.com/apache/spark/commit/b8381ef4bbd05de718f8097d136ed332de136346).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86215/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by tdas <gi...@git.apache.org>.
Github user tdas commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r161925337
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -2142,6 +2452,7 @@ write.stream(aggDF, "memory", outputMode = "complete", checkpointLocation = "pat
**Talks**
-- Spark Summit 2017 Talk - [Easy, Scalable, Fault-tolerant Stream Processing with Structured Streaming in Apache Spark](https://spark-summit.org/2017/events/easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-in-apache-spark/)
+- Spark Summit Europe 2017 Talks -
+ - [Easy, Scalable, Fault-tolerant Stream Processing with Structured Streaming in Apache Spark](https://spark-summit.org/2017/events/easy-scalable-fault-tolerant-stream-processing-with-structured-streaming-in-apache-spark/)
--- End diff --
TODO: this link needs to be updated. blocked on some links not working on the spark summit website.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86073/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86219 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86219/testReport)** for PR 20255 at commit [`68f30d0`](https://github.com/apache/spark/commit/68f30d02a7b66a56ba438f9a21e222149509d174).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by tdas <gi...@git.apache.org>.
Github user tdas commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r161920813
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -1089,6 +1098,224 @@ streamingDf.join(staticDf, "type", "right_join") # right outer join with a stat
</div>
</div>
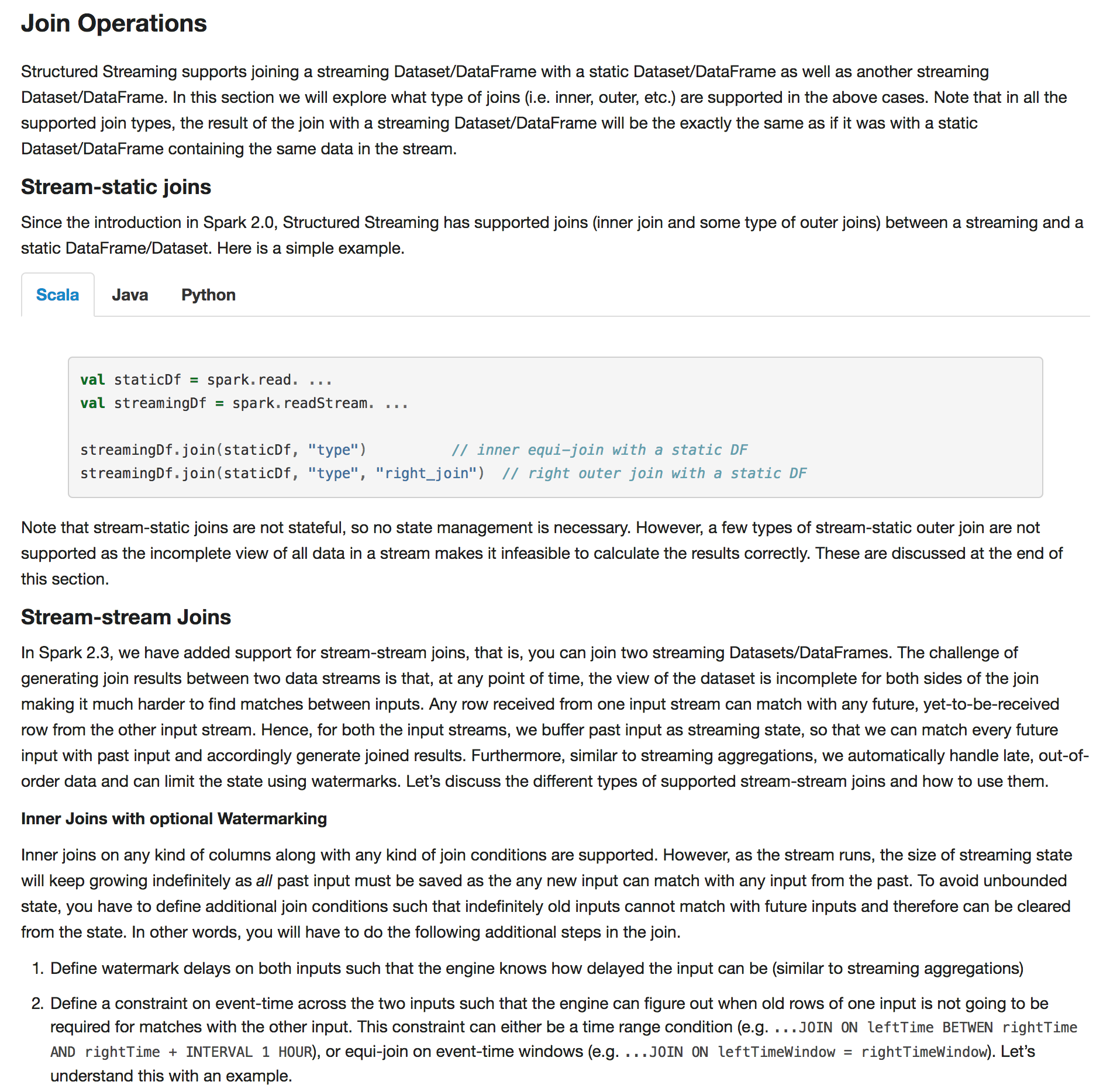
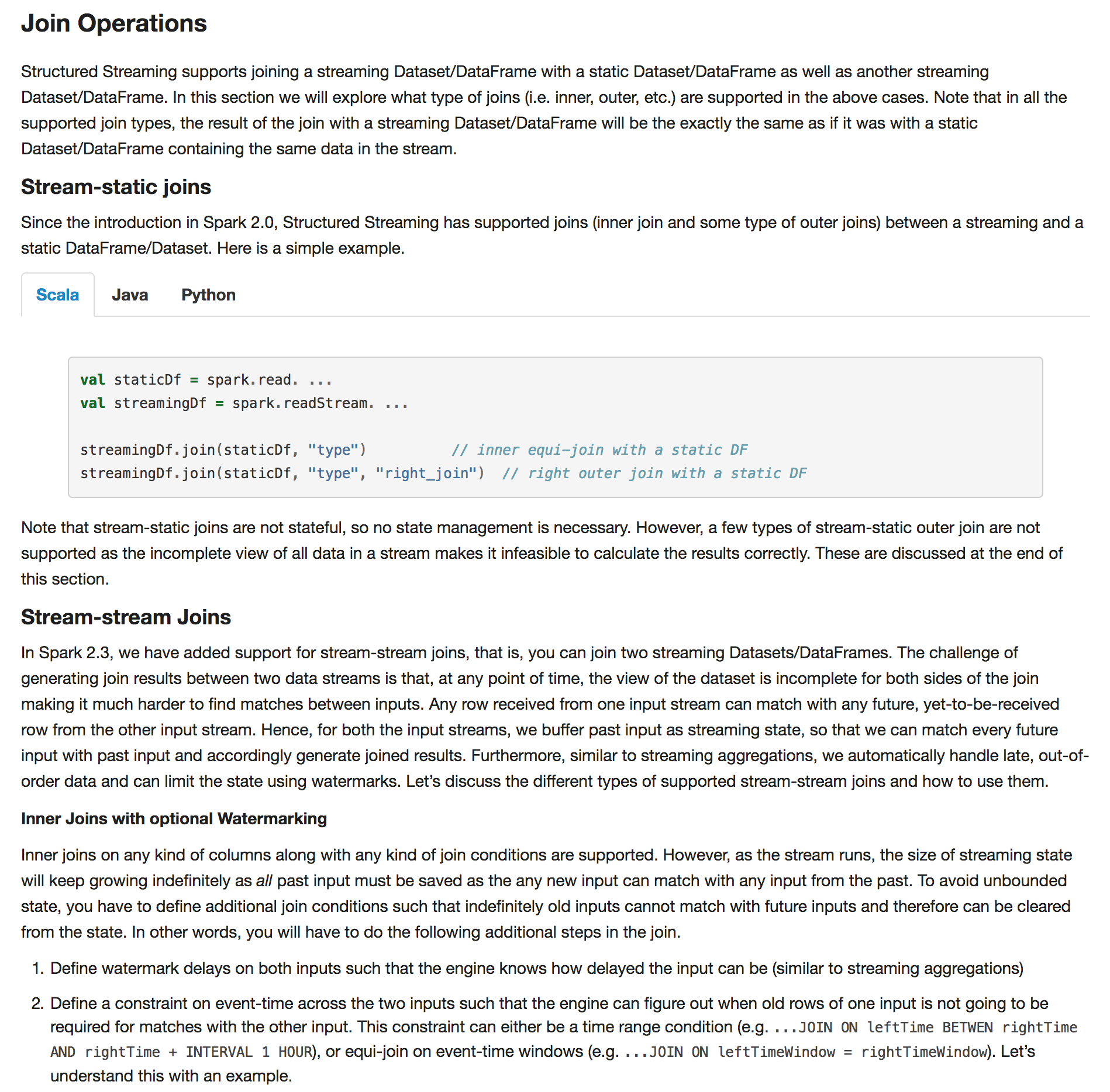
+Note that stream-static joins are not stateful, so no state management is necessary.
+However, a few types of stream-static outer join are not supported as the incomplete view of
+all data in a stream makes it infeasible to calculate the results correctly.
+These are discussed at the end of this section.
+
+#### Stream-stream Joins
+In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming
+Datasets/DataFrames. The challenge of generating join results between two data streams is that,
+at any point of time, the view of the dataset is incomplete for both sides of the join making
+it much harder to find matches between inputs. Any row received from one input stream can match
+with any future, yet-to-be-received row from the other input stream. Hence, for both the input
+streams, we buffer past input as streaming state, so that we can match every future input with
+past input and accordingly generate joined results. Furthermore, similar to streaming aggregations,
+we automatically handle late, out-of-order data and can limit the state using watermarks.
+Let’s discuss the different types of supported stream-stream joins and how to use them.
+
+##### Inner Joins with optional Watermarking
+Inner joins on any kind of columns along with any kind of join conditions are supported.
+However, as the stream runs, the size of streaming state will keep growing indefinitely as
+*all* past input must be saved as the any new input can match with any input from the past.
+To avoid unbounded state, you have to define additional join conditions such that indefinitely
+old inputs cannot match with future inputs and therefore can be cleared from the state.
+In other words, you will have to do the following additional steps in the join.
+
+1. Define watermark delays on both inputs such that the engine knows how delayed the input can be
+(similar to streaming aggregations)
+
+1. Define a constraint on event-time across the two inputs such that the engine can figure out when
+old rows of one input is not going to be required for matches with the other input. This constraint
+can either be a time range condition (e.g. `...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR`),
+or equi-join on event-time windows (e.g. `...JOIN ON leftTimeWindow = rightTimeWindow`).
+Let’s understand this with an example.
+
+Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with
+another stream of user clicks on advertisements to correlate when impressions led to
+monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to
+specify the watermarking delays and the time constraints as follows.
+
+1. Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order
+in event-time by at most 2 and 3 hours, respectively.
+
+1. Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour
+after the corresponding impression.
+
+The code would look like this.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+import org.apache.spark.sql.functions.expr
+
+val impressions = spark.readStream. ...
+val clicks = spark.readStream. ...
+
+// Apply watermarks on event-time columns
+val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+import static org.apache.spark.sql.functions.expr
+
+Dataset<Row> impressions = spark.readStream(). ...
+Dataset<Row> clicks = spark.readStream(). ...
+
+// Apply watermarks on event-time columns
+Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
+Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "
+ ));
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+from pyspark.sql.functions import expr
+
+impressions = spark.readStream. ...
+clicks = spark.readStream. ...
+
+# Apply watermarks on event-time columns
+impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+# Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
--- End diff --
Thank you!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86214 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86214/testReport)** for PR 20255 at commit [`b8381ef`](https://github.com/apache/spark/commit/b8381ef4bbd05de718f8097d136ed332de136346).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86303 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86303/testReport)** for PR 20255 at commit [`e39b0a6`](https://github.com/apache/spark/commit/e39b0a63010e5ac1372966c2d7b8fc8eefa821c3).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86219 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86219/testReport)** for PR 20255 at commit [`68f30d0`](https://github.com/apache/spark/commit/68f30d02a7b66a56ba438f9a21e222149509d174).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r162261740
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -1089,6 +1098,224 @@ streamingDf.join(staticDf, "type", "right_join") # right outer join with a stat
</div>
</div>
+Note that stream-static joins are not stateful, so no state management is necessary.
+However, a few types of stream-static outer join are not supported as the incomplete view of
+all data in a stream makes it infeasible to calculate the results correctly.
+These are discussed at the end of this section.
+
+#### Stream-stream Joins
+In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming
+Datasets/DataFrames. The challenge of generating join results between two data streams is that,
+at any point of time, the view of the dataset is incomplete for both sides of the join making
+it much harder to find matches between inputs. Any row received from one input stream can match
+with any future, yet-to-be-received row from the other input stream. Hence, for both the input
+streams, we buffer past input as streaming state, so that we can match every future input with
+past input and accordingly generate joined results. Furthermore, similar to streaming aggregations,
+we automatically handle late, out-of-order data and can limit the state using watermarks.
+Let’s discuss the different types of supported stream-stream joins and how to use them.
+
+##### Inner Joins with optional Watermarking
+Inner joins on any kind of columns along with any kind of join conditions are supported.
+However, as the stream runs, the size of streaming state will keep growing indefinitely as
+*all* past input must be saved as the any new input can match with any input from the past.
+To avoid unbounded state, you have to define additional join conditions such that indefinitely
+old inputs cannot match with future inputs and therefore can be cleared from the state.
+In other words, you will have to do the following additional steps in the join.
+
+1. Define watermark delays on both inputs such that the engine knows how delayed the input can be
+(similar to streaming aggregations)
+
+1. Define a constraint on event-time across the two inputs such that the engine can figure out when
+old rows of one input is not going to be required for matches with the other input. This constraint
+can either be a time range condition (e.g. `...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR`),
+or equi-join on event-time windows (e.g. `...JOIN ON leftTimeWindow = rightTimeWindow`).
+Let’s understand this with an example.
+
+Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with
+another stream of user clicks on advertisements to correlate when impressions led to
+monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to
+specify the watermarking delays and the time constraints as follows.
+
+1. Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order
+in event-time by at most 2 and 3 hours, respectively.
+
+1. Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour
+after the corresponding impression.
+
+The code would look like this.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+import org.apache.spark.sql.functions.expr
+
+val impressions = spark.readStream. ...
+val clicks = spark.readStream. ...
+
+// Apply watermarks on event-time columns
+val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+import static org.apache.spark.sql.functions.expr
+
+Dataset<Row> impressions = spark.readStream(). ...
+Dataset<Row> clicks = spark.readStream(). ...
+
+// Apply watermarks on event-time columns
+Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
+Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "
+ ));
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+from pyspark.sql.functions import expr
+
+impressions = spark.readStream. ...
+clicks = spark.readStream. ...
+
+# Apply watermarks on event-time columns
+impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+# Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
--- End diff --
sure!
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r161366935
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -1089,6 +1098,224 @@ streamingDf.join(staticDf, "type", "right_join") # right outer join with a stat
</div>
</div>
+Note that stream-static joins are not stateful, so no state management is necessary.
+However, a few types of stream-static outer join are not supported as the incomplete view of
+all data in a stream makes it infeasible to calculate the results correctly.
+These are discussed at the end of this section.
+
+#### Stream-stream Joins
+In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming
+Datasets/DataFrames. The challenge of generating join results between two data streams is that,
+at any point of time, the view of the dataset is incomplete for both sides of the join making
+it much harder to find matches between inputs. Any row received from one input stream can match
+with any future, yet-to-be-received row from the other input stream. Hence, for both the input
+streams, we buffer past input as streaming state, so that we can match every future input with
+past input and accordingly generate joined results. Furthermore, similar to streaming aggregations,
+we automatically handle late, out-of-order data and can limit the state using watermarks.
+Let’s discuss the different types of supported stream-stream joins and how to use them.
+
+##### Inner Joins with optional Watermarking
+Inner joins on any kind of columns along with any kind of join conditions are supported.
+However, as the stream runs, the size of streaming state will keep growing indefinitely as
+*all* past input must be saved as the any new input can match with any input from the past.
+To avoid unbounded state, you have to define additional join conditions such that indefinitely
+old inputs cannot match with future inputs and therefore can be cleared from the state.
+In other words, you will have to do the following additional steps in the join.
+
+1. Define watermark delays on both inputs such that the engine knows how delayed the input can be
+(similar to streaming aggregations)
+
+1. Define a constraint on event-time across the two inputs such that the engine can figure out when
+old rows of one input is not going to be required for matches with the other input. This constraint
+can either be a time range condition (e.g. `...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR`),
+or equi-join on event-time windows (e.g. `...JOIN ON leftTimeWindow = rightTimeWindow`).
+Let’s understand this with an example.
+
+Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with
+another stream of user clicks on advertisements to correlate when impressions led to
+monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to
+specify the watermarking delays and the time constraints as follows.
+
+1. Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order
+in event-time by at most 2 and 3 hours, respectively.
+
+1. Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour
+after the corresponding impression.
+
+The code would look like this.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+import org.apache.spark.sql.functions.expr
+
+val impressions = spark.readStream. ...
+val clicks = spark.readStream. ...
+
+// Apply watermarks on event-time columns
+val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+import static org.apache.spark.sql.functions.expr
+
+Dataset<Row> impressions = spark.readStream(). ...
+Dataset<Row> clicks = spark.readStream(). ...
+
+// Apply watermarks on event-time columns
+Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
+Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "
+ ));
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+from pyspark.sql.functions import expr
+
+impressions = spark.readStream. ...
+clicks = spark.readStream. ...
+
+# Apply watermarks on event-time columns
+impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+# Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
--- End diff --
this *should* just work for R, like this:
(I added withWatermark in 2.3)
```
impressions <- read.stream( ...
clicks <- read.stream( ...
# Apply watermarks on event-time columns
impressionsWithWatermark <- withWatermark(impressions, "impressionTime", "2 hours")
clicksWithWatermark <- withWatermark(clicks, "clickTime", "3 hours")
# Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr(
"clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour"
))
```
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by felixcheung <gi...@git.apache.org>.
Github user felixcheung commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r161366948
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -1089,6 +1098,224 @@ streamingDf.join(staticDf, "type", "right_join") # right outer join with a stat
</div>
</div>
+Note that stream-static joins are not stateful, so no state management is necessary.
+However, a few types of stream-static outer join are not supported as the incomplete view of
+all data in a stream makes it infeasible to calculate the results correctly.
+These are discussed at the end of this section.
+
+#### Stream-stream Joins
+In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming
+Datasets/DataFrames. The challenge of generating join results between two data streams is that,
+at any point of time, the view of the dataset is incomplete for both sides of the join making
+it much harder to find matches between inputs. Any row received from one input stream can match
+with any future, yet-to-be-received row from the other input stream. Hence, for both the input
+streams, we buffer past input as streaming state, so that we can match every future input with
+past input and accordingly generate joined results. Furthermore, similar to streaming aggregations,
+we automatically handle late, out-of-order data and can limit the state using watermarks.
+Let’s discuss the different types of supported stream-stream joins and how to use them.
+
+##### Inner Joins with optional Watermarking
+Inner joins on any kind of columns along with any kind of join conditions are supported.
+However, as the stream runs, the size of streaming state will keep growing indefinitely as
+*all* past input must be saved as the any new input can match with any input from the past.
+To avoid unbounded state, you have to define additional join conditions such that indefinitely
+old inputs cannot match with future inputs and therefore can be cleared from the state.
+In other words, you will have to do the following additional steps in the join.
+
+1. Define watermark delays on both inputs such that the engine knows how delayed the input can be
+(similar to streaming aggregations)
+
+1. Define a constraint on event-time across the two inputs such that the engine can figure out when
+old rows of one input is not going to be required for matches with the other input. This constraint
+can either be a time range condition (e.g. `...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR`),
+or equi-join on event-time windows (e.g. `...JOIN ON leftTimeWindow = rightTimeWindow`).
+Let’s understand this with an example.
+
+Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with
+another stream of user clicks on advertisements to correlate when impressions led to
+monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to
+specify the watermarking delays and the time constraints as follows.
+
+1. Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order
+in event-time by at most 2 and 3 hours, respectively.
+
+1. Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour
+after the corresponding impression.
+
+The code would look like this.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+import org.apache.spark.sql.functions.expr
+
+val impressions = spark.readStream. ...
+val clicks = spark.readStream. ...
+
+// Apply watermarks on event-time columns
+val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+import static org.apache.spark.sql.functions.expr
+
+Dataset<Row> impressions = spark.readStream(). ...
+Dataset<Row> clicks = spark.readStream(). ...
+
+// Apply watermarks on event-time columns
+Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
+Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "
+ ));
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+from pyspark.sql.functions import expr
+
+impressions = spark.readStream. ...
+clicks = spark.readStream. ...
+
+# Apply watermarks on event-time columns
+impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+# Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
+
+{% endhighlight %}
+
+</div>
+</div>
+
+##### Outer Joins with Watermarking
+While the watermark + event-time constraints is optional for inner joins, for left and right outer
+joins they must be specified. This is because for generating the NULL results in outer join, the
+engine must know when an input row is not going to match with anything in future. Hence, the
+watermark + event-time constraints must be specified for generating correct results.
+
+However, note that the outer NULL results will be generated with a delay (depends on the specified
+watermark delay and the time range condition) because the engine has to wait for that long to ensure
+ there were no matches and there will be no more matches in future.
--- End diff --
extra space?
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86215 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86215/testReport)** for PR 20255 at commit [`0af12a3`](https://github.com/apache/spark/commit/0af12a3e63d9394ae9b86f7757d4d85828b4ce0b).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86219/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86073 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86073/testReport)** for PR 20255 at commit [`1335a6d`](https://github.com/apache/spark/commit/1335a6d3c00ccc04e7a2943ce041994150e8f9db).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by asfgit <gi...@git.apache.org>.
Github user asfgit closed the pull request at:
https://github.com/apache/spark/pull/20255
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by zsxwing <gi...@git.apache.org>.
Github user zsxwing commented on the issue:
https://github.com/apache/spark/pull/20255
Merging to master and 2.3.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86215 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86215/testReport)** for PR 20255 at commit [`0af12a3`](https://github.com/apache/spark/commit/0af12a3e63d9394ae9b86f7757d4d85828b4ce0b).
* This patch passes all tests.
* This patch merges cleanly.
* This patch adds no public classes.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by zsxwing <gi...@git.apache.org>.
Github user zsxwing commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r162212307
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -1089,6 +1101,300 @@ streamingDf.join(staticDf, "type", "right_join") # right outer join with a stat
</div>
</div>
+Note that stream-static joins are not stateful, so no state management is necessary.
+However, a few types of stream-static outer joins are not yet supported.
+These are listed at the [end of this Join section](#support-matrix-for-joins-in-streaming-queries).
+
+#### Stream-stream Joins
+In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming
+Datasets/DataFrames. The challenge of generating join results between two data streams is that,
+at any point of time, the view of the dataset is incomplete for both sides of the join making
+it much harder to find matches between inputs. Any row received from one input stream can match
+with any future, yet-to-be-received row from the other input stream. Hence, for both the input
+streams, we buffer past input as streaming state, so that we can match every future input with
+past input and accordingly generate joined results. Furthermore, similar to streaming aggregations,
+we automatically handle late, out-of-order data and can limit the state using watermarks.
+Let’s discuss the different types of supported stream-stream joins and how to use them.
+
+##### Inner Joins with optional Watermarking
+Inner joins on any kind of columns along with any kind of join conditions are supported.
+However, as the stream runs, the size of streaming state will keep growing indefinitely as
+*all* past input must be saved as the any new input can match with any input from the past.
+To avoid unbounded state, you have to define additional join conditions such that indefinitely
+old inputs cannot match with future inputs and therefore can be cleared from the state.
+In other words, you will have to do the following additional steps in the join.
+
+1. Define watermark delays on both inputs such that the engine knows how delayed the input can be
+(similar to streaming aggregations)
+
+1. Define a constraint on event-time across the two inputs such that the engine can figure out when
+old rows of one input is not going to be required (i.e. will not satisfy the time constraint) for
+matches with the other input. This constraint can be defined in one of the two ways.
+
+ 1. Time range join conditions (e.g. `...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR`),
+
+ 1. Join on event-time windows (e.g. `...JOIN ON leftTimeWindow = rightTimeWindow`).
+
+Let’s understand this with an example.
+
+Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with
+another stream of user clicks on advertisements to correlate when impressions led to
+monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to
+specify the watermarking delays and the time constraints as follows.
+
+1. Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order
+in event-time by at most 2 and 3 hours, respectively.
+
+1. Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour
+after the corresponding impression.
+
+The code would look like this.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+import org.apache.spark.sql.functions.expr
+
+val impressions = spark.readStream. ...
+val clicks = spark.readStream. ...
+
+// Apply watermarks on event-time columns
+val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """)
+)
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+import static org.apache.spark.sql.functions.expr
+
+Dataset<Row> impressions = spark.readStream(). ...
+Dataset<Row> clicks = spark.readStream(). ...
+
+// Apply watermarks on event-time columns
+Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
+Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour ")
+);
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+from pyspark.sql.functions import expr
+
+impressions = spark.readStream. ...
+clicks = spark.readStream. ...
+
+# Apply watermarks on event-time columns
+impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+# Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """)
+)
+
+{% endhighlight %}
+
+</div>
+</div>
+
+##### Outer Joins with Watermarking
+While the watermark + event-time constraints is optional for inner joins, for left and right outer
+joins they must be specified. This is because for generating the NULL results in outer join, the
+engine must know when an input row is not going to match with anything in future. Hence, the
+watermark + event-time constraints must be specified for generating correct results. Therefore,
+a query with outer-join will look quite like the ad-monetization example earlier, except that
+there will be an additional parameter specifying it to be an outer-join.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """),
+ joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter"
+ )
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "),
+ "leftOuter" // can be "inner", "leftOuter", "rightOuter"
+);
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """),
+ "leftOuter" # can be "inner", "leftOuter", "rightOuter"
+)
+
+{% endhighlight %}
+
+</div>
+</div>
+
+However, note that the outer NULL results will be generated with a delay (depends on the specified
+watermark delay and the time range condition) because the engine has to wait for that long to ensure
+there were no matches and there will be no more matches in future.
+
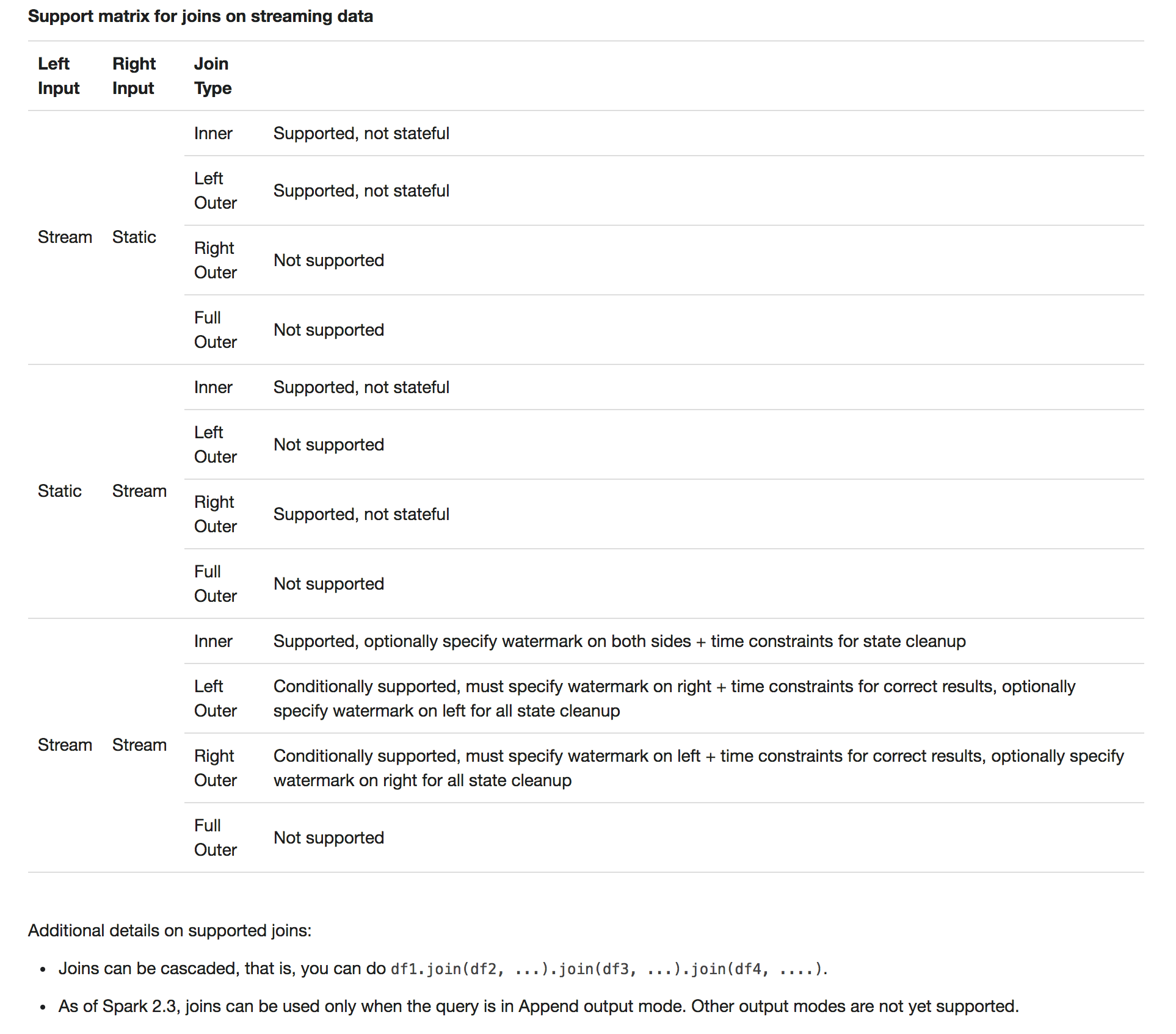
+##### Support matrix for joins in streaming queries
+
+<table class ="table">
+ <tr>
+ <th>Left Input</th>
+ <th>Right Input</th>
+ <th>Join Type</th>
+ <th></th>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Static</td>
+ <td style="vertical-align: middle;">Static</td>
+ <td style="vertical-align: middle;">All types</td>
+ <td style="vertical-align: middle;">
+ Supported, since its not on streaming data even though it
+ can be present in a streaming query
+ </td>
+ </tr>
+ <tr>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td rowspan="4" style="vertical-align: middle;">Static</td>
+ <td style="vertical-align: middle;">Inner</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Left Outer</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Right Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Full Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td rowspan="4" style="vertical-align: middle;">Static</td>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td style="vertical-align: middle;">Inner</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Left Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Right Outer</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Full Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td style="vertical-align: middle;">Inner</td>
+ <td style="vertical-align: middle;">
+ Supported, optionally specify watermark on both sides +
+ time constraints for state cleanup<
--- End diff --
nit" remove `<`
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86214/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by tdas <gi...@git.apache.org>.
Github user tdas commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r161920893
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -1089,6 +1098,224 @@ streamingDf.join(staticDf, "type", "right_join") # right outer join with a stat
</div>
</div>
+Note that stream-static joins are not stateful, so no state management is necessary.
+However, a few types of stream-static outer join are not supported as the incomplete view of
+all data in a stream makes it infeasible to calculate the results correctly.
+These are discussed at the end of this section.
+
+#### Stream-stream Joins
+In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming
+Datasets/DataFrames. The challenge of generating join results between two data streams is that,
+at any point of time, the view of the dataset is incomplete for both sides of the join making
+it much harder to find matches between inputs. Any row received from one input stream can match
+with any future, yet-to-be-received row from the other input stream. Hence, for both the input
+streams, we buffer past input as streaming state, so that we can match every future input with
+past input and accordingly generate joined results. Furthermore, similar to streaming aggregations,
+we automatically handle late, out-of-order data and can limit the state using watermarks.
+Let’s discuss the different types of supported stream-stream joins and how to use them.
+
+##### Inner Joins with optional Watermarking
+Inner joins on any kind of columns along with any kind of join conditions are supported.
+However, as the stream runs, the size of streaming state will keep growing indefinitely as
+*all* past input must be saved as the any new input can match with any input from the past.
+To avoid unbounded state, you have to define additional join conditions such that indefinitely
+old inputs cannot match with future inputs and therefore can be cleared from the state.
+In other words, you will have to do the following additional steps in the join.
+
+1. Define watermark delays on both inputs such that the engine knows how delayed the input can be
+(similar to streaming aggregations)
+
+1. Define a constraint on event-time across the two inputs such that the engine can figure out when
+old rows of one input is not going to be required for matches with the other input. This constraint
+can either be a time range condition (e.g. `...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR`),
+or equi-join on event-time windows (e.g. `...JOIN ON leftTimeWindow = rightTimeWindow`).
+Let’s understand this with an example.
+
+Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with
+another stream of user clicks on advertisements to correlate when impressions led to
+monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to
+specify the watermarking delays and the time constraints as follows.
+
+1. Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order
+in event-time by at most 2 and 3 hours, respectively.
+
+1. Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour
+after the corresponding impression.
+
+The code would look like this.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+import org.apache.spark.sql.functions.expr
+
+val impressions = spark.readStream. ...
+val clicks = spark.readStream. ...
+
+// Apply watermarks on event-time columns
+val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+import static org.apache.spark.sql.functions.expr
+
+Dataset<Row> impressions = spark.readStream(). ...
+Dataset<Row> clicks = spark.readStream(). ...
+
+// Apply watermarks on event-time columns
+Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
+Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "
+ ));
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+from pyspark.sql.functions import expr
+
+impressions = spark.readStream. ...
+clicks = spark.readStream. ...
+
+# Apply watermarks on event-time columns
+impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+# Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """
+ ))
--- End diff --
Could you add tests for joins in R as well? :)
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Merged build finished. Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark pull request #20255: [SPARK-23064][DOCS][SS] Added documentation for s...
Posted by zsxwing <gi...@git.apache.org>.
Github user zsxwing commented on a diff in the pull request:
https://github.com/apache/spark/pull/20255#discussion_r162199330
--- Diff: docs/structured-streaming-programming-guide.md ---
@@ -1089,6 +1101,300 @@ streamingDf.join(staticDf, "type", "right_join") # right outer join with a stat
</div>
</div>
+Note that stream-static joins are not stateful, so no state management is necessary.
+However, a few types of stream-static outer joins are not yet supported.
+These are listed at the [end of this Join section](#support-matrix-for-joins-in-streaming-queries).
+
+#### Stream-stream Joins
+In Spark 2.3, we have added support for stream-stream joins, that is, you can join two streaming
+Datasets/DataFrames. The challenge of generating join results between two data streams is that,
+at any point of time, the view of the dataset is incomplete for both sides of the join making
+it much harder to find matches between inputs. Any row received from one input stream can match
+with any future, yet-to-be-received row from the other input stream. Hence, for both the input
+streams, we buffer past input as streaming state, so that we can match every future input with
+past input and accordingly generate joined results. Furthermore, similar to streaming aggregations,
+we automatically handle late, out-of-order data and can limit the state using watermarks.
+Let’s discuss the different types of supported stream-stream joins and how to use them.
+
+##### Inner Joins with optional Watermarking
+Inner joins on any kind of columns along with any kind of join conditions are supported.
+However, as the stream runs, the size of streaming state will keep growing indefinitely as
+*all* past input must be saved as the any new input can match with any input from the past.
+To avoid unbounded state, you have to define additional join conditions such that indefinitely
+old inputs cannot match with future inputs and therefore can be cleared from the state.
+In other words, you will have to do the following additional steps in the join.
+
+1. Define watermark delays on both inputs such that the engine knows how delayed the input can be
+(similar to streaming aggregations)
+
+1. Define a constraint on event-time across the two inputs such that the engine can figure out when
+old rows of one input is not going to be required (i.e. will not satisfy the time constraint) for
+matches with the other input. This constraint can be defined in one of the two ways.
+
+ 1. Time range join conditions (e.g. `...JOIN ON leftTime BETWEN rightTime AND rightTime + INTERVAL 1 HOUR`),
+
+ 1. Join on event-time windows (e.g. `...JOIN ON leftTimeWindow = rightTimeWindow`).
+
+Let’s understand this with an example.
+
+Let’s say we want to join a stream of advertisement impressions (when an ad was shown) with
+another stream of user clicks on advertisements to correlate when impressions led to
+monetizable clicks. To allow the state cleanup in this stream-stream join, you will have to
+specify the watermarking delays and the time constraints as follows.
+
+1. Watermark delays: Say, the impressions and the corresponding clicks can be late/out-of-order
+in event-time by at most 2 and 3 hours, respectively.
+
+1. Event-time range condition: Say, a click can occur within a time range of 0 seconds to 1 hour
+after the corresponding impression.
+
+The code would look like this.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+import org.apache.spark.sql.functions.expr
+
+val impressions = spark.readStream. ...
+val clicks = spark.readStream. ...
+
+// Apply watermarks on event-time columns
+val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """)
+)
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+import static org.apache.spark.sql.functions.expr
+
+Dataset<Row> impressions = spark.readStream(). ...
+Dataset<Row> clicks = spark.readStream(). ...
+
+// Apply watermarks on event-time columns
+Dataset<Row> impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours");
+Dataset<Row> clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours");
+
+// Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour ")
+);
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+from pyspark.sql.functions import expr
+
+impressions = spark.readStream. ...
+clicks = spark.readStream. ...
+
+# Apply watermarks on event-time columns
+impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
+clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
+
+# Join with event-time constraints
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """)
+)
+
+{% endhighlight %}
+
+</div>
+</div>
+
+##### Outer Joins with Watermarking
+While the watermark + event-time constraints is optional for inner joins, for left and right outer
+joins they must be specified. This is because for generating the NULL results in outer join, the
+engine must know when an input row is not going to match with anything in future. Hence, the
+watermark + event-time constraints must be specified for generating correct results. Therefore,
+a query with outer-join will look quite like the ad-monetization example earlier, except that
+there will be an additional parameter specifying it to be an outer-join.
+
+<div class="codetabs">
+<div data-lang="scala" markdown="1">
+
+{% highlight scala %}
+
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """),
+ joinType = "leftOuter" // can be "inner", "leftOuter", "rightOuter"
+ )
+
+{% endhighlight %}
+
+</div>
+<div data-lang="java" markdown="1">
+
+{% highlight java %}
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr(
+ "clickAdId = impressionAdId AND " +
+ "clickTime >= impressionTime AND " +
+ "clickTime <= impressionTime + interval 1 hour "),
+ "leftOuter" // can be "inner", "leftOuter", "rightOuter"
+);
+
+{% endhighlight %}
+
+
+</div>
+<div data-lang="python" markdown="1">
+
+{% highlight python %}
+impressionsWithWatermark.join(
+ clicksWithWatermark,
+ expr("""
+ clickAdId = impressionAdId AND
+ clickTime >= impressionTime AND
+ clickTime <= impressionTime + interval 1 hour
+ """),
+ "leftOuter" # can be "inner", "leftOuter", "rightOuter"
+)
+
+{% endhighlight %}
+
+</div>
+</div>
+
+However, note that the outer NULL results will be generated with a delay (depends on the specified
+watermark delay and the time range condition) because the engine has to wait for that long to ensure
+there were no matches and there will be no more matches in future.
+
+##### Support matrix for joins in streaming queries
+
+<table class ="table">
+ <tr>
+ <th>Left Input</th>
+ <th>Right Input</th>
+ <th>Join Type</th>
+ <th></th>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Static</td>
+ <td style="vertical-align: middle;">Static</td>
+ <td style="vertical-align: middle;">All types</td>
+ <td style="vertical-align: middle;">
+ Supported, since its not on streaming data even though it
+ can be present in a streaming query
+ </td>
+ </tr>
+ <tr>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td rowspan="4" style="vertical-align: middle;">Static</td>
+ <td style="vertical-align: middle;">Inner</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Left Outer</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Right Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Full Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td rowspan="4" style="vertical-align: middle;">Static</td>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td style="vertical-align: middle;">Inner</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Left Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Right Outer</td>
+ <td style="vertical-align: middle;">Supported, not stateful</td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Full Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td rowspan="4" style="vertical-align: middle;">Stream</td>
+ <td style="vertical-align: middle;">Inner</td>
+ <td style="vertical-align: middle;">
+ Supported, optionally specify watermark on both sides +
+ time constraints for state cleanup<
+ </td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Left Outer</td>
+ <td style="vertical-align: middle;">
+ Conditionally supported, must specify watermark on right + time constraints for correct
+ results, optionally specify watermark on left for all state cleanup
+ </td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Right Outer</td>
+ <td style="vertical-align: middle;">
+ Conditionally supported, must specify watermark on left + time constraints for correct
+ results, optionally specify watermark on right for all state cleanup
+ </td>
+ </tr>
+ <tr>
+ <td style="vertical-align: middle;">Full Outer</td>
+ <td style="vertical-align: middle;">Not supported</td>
+ </tr>
+ <tr>
+ <td></td>
+ <td></td>
+ <td></td>
+ <td></td>
+ </tr>
+</table>
+
+Additional details on supported joins:
+
+- Joins can be cascaded, that is, you can do `df1.join(df2, ...).join(df3, ...).join(df4, ....)`.
+
+- As of Spark 2.3, you can use joins only when the query is in Append output mode. Other output modes are not yet supported.
+
+- As of Spark 2.3, you cannot use other non-map-like operations before joins. Here are a few examples of
+ what cannot be used.
+
+ - Cannot use streaming aggregations before joins.
+
+ - Cannot use mapGroupsWithState and flatMapGroupsWithState in Update mode cannot before joins.
--- End diff --
nit: ~~cannot~~ before joins.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86303 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86303/testReport)** for PR 20255 at commit [`e39b0a6`](https://github.com/apache/spark/commit/e39b0a63010e5ac1372966c2d7b8fc8eefa821c3).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by SparkQA <gi...@git.apache.org>.
Github user SparkQA commented on the issue:
https://github.com/apache/spark/pull/20255
**[Test build #86073 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/86073/testReport)** for PR 20255 at commit [`1335a6d`](https://github.com/apache/spark/commit/1335a6d3c00ccc04e7a2943ce041994150e8f9db).
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org
[GitHub] spark issue #20255: [SPARK-23064][DOCS][SS] Added documentation for stream-s...
Posted by AmplabJenkins <gi...@git.apache.org>.
Github user AmplabJenkins commented on the issue:
https://github.com/apache/spark/pull/20255
Test PASSed.
Refer to this link for build results (access rights to CI server needed):
https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/86303/
Test PASSed.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org