You are viewing a plain text version of this content. The canonical link for it is here.
Posted to reviews@spark.apache.org by GitBox <gi...@apache.org> on 2019/02/01 04:22:07 UTC
[GitHub] liupc commented on issue #23438: [SPARK-26525][SHUFFLE]Fast release
ShuffleBlockFetcherIterator on completion of the iteration
liupc commented on issue #23438: [SPARK-26525][SHUFFLE]Fast release ShuffleBlockFetcherIterator on completion of the iteration
URL: https://github.com/apache/spark/pull/23438#issuecomment-459600935
@cloud-fan I verified this patch with some hacked code, it does work well.
```
override def compute(partition: Partition, context: TaskContext): Iterator[T] = {
partition.asInstanceOf[CoalescedRDDPartition].parents.iterator.flatMap { parentPartition =>
if (parentPartition.index !=
partition.asInstanceOf[CoalescedRDDPartition].parents.head.index) {
logInfo(s"First parent iterator already exhausted, just wait for heap dump...")
Thread.sleep(Long.MaxValue)
}
firstParent[T].iterator(parentPartition, context)
}
}
```
First, start a spark-shell app
```
liupengcheng@dev:~/work/git/github-me/spark/bin$ ./spark-shell --master local-cluster[1,1,1024]
19/02/01 12:04:48 WARN Utils: Your hostname, dev resolves to a loopback address: 127.0.1.1; using 10.239.35.194 instead (on interface eno1)
19/02/01 12:04:48 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
19/02/01 12:04:49 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://10.239.35.194:4040
Spark context available as 'sc' (master = local-cluster[1,1,1024], app id = app-20190201120456-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-SNAPSHOT
/_/
Using Scala version 2.12.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_144)
Type in expressions to have them evaluated.
Type :help for more information.
scala> sc.parallelize((1 to 1000), 1000).repartition(1000).coalesce(1).collect()
[Stage 1:> (0 + 1) / 1]
```
Second, when sleep at the hacked code, then do heapdump.
`jmap -dump:alive,format=b,file=./a.hrpof 22551`
// Notice that the `alive` would trigger full gc before heapdump
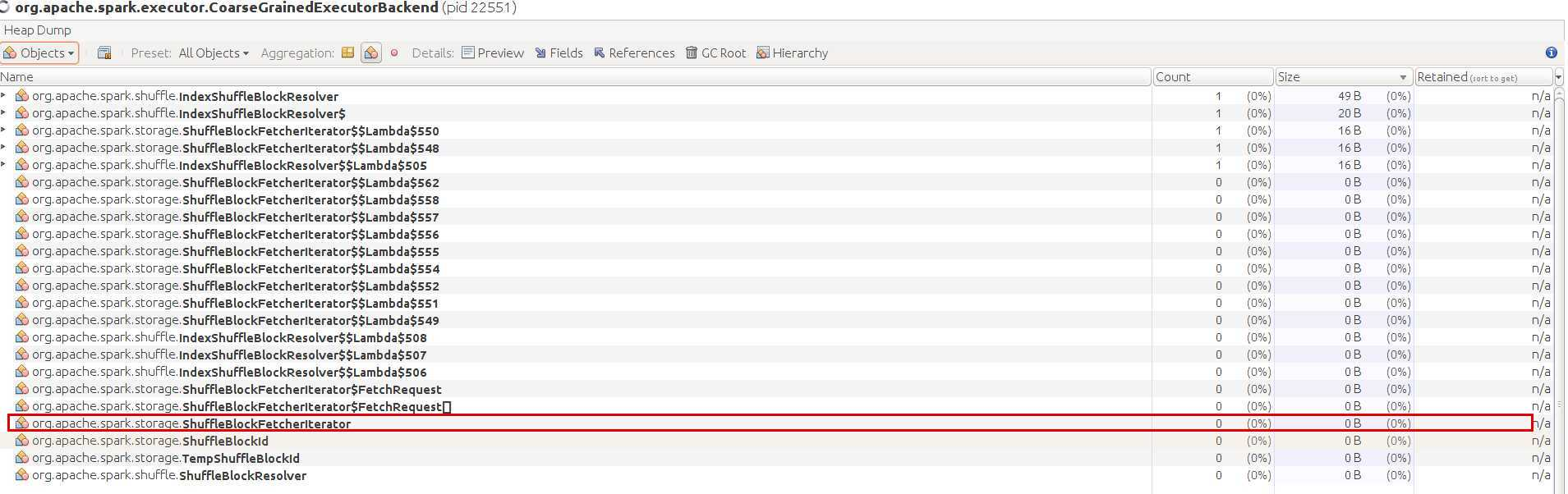
Third, use visualVm to check the ShuffleBlockFetcherIterator refcount in the heap.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscribe@spark.apache.org
For additional commands, e-mail: reviews-help@spark.apache.org