You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@flink.apache.org by GitBox <gi...@apache.org> on 2022/06/02 15:51:14 UTC
[GitHub] [flink] godfreyhe commented on pull request #19286: [FLINK-25931] Add projection pushdown support for CsvFormatFactory
godfreyhe commented on PR #19286:
URL: https://github.com/apache/flink/pull/19286#issuecomment-1145020743
> @AHeise I am not sure that the proposed alternative approach makes things much easier. I personally find the implementation of the projection specification as an array of arrays somewhat confusing and would prefer not to spread this abstraction to the lower level interfaces, if possible. I find the code of the `CsvRowDataDeserializationSchema` that just operates on input (read from source) and output (converted/projected) data types easier to understand. That way someone who needs to maintain this class does not need to decipher what exactly ` int[][] projections` means. @godfreyhe please let me know if you also think it is worth pursuing the proposed alternative approach to what is currently implemented in the PR.
Thanks @afedulov for the contribution. I find there is no any difference of the json node after deserialized from the message between changing the `csvSchema` or not. See the debug info with original schema:
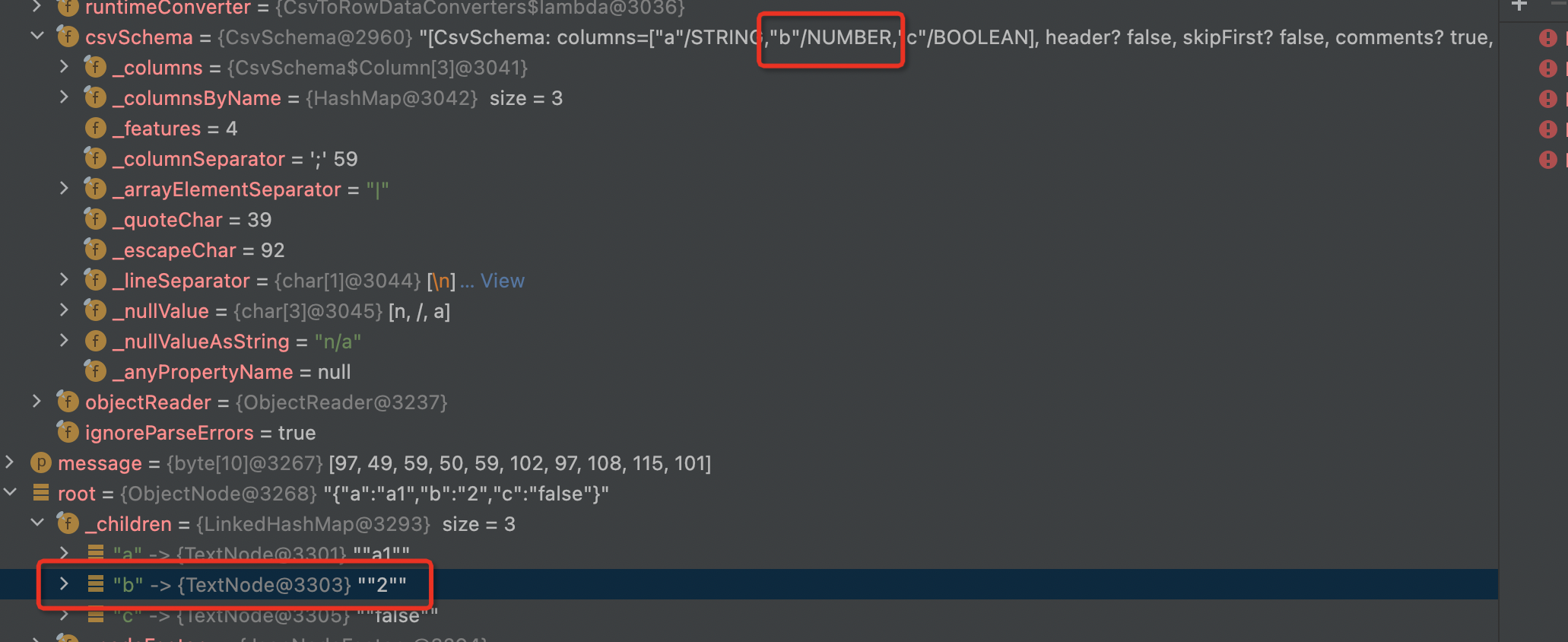
Do you have any performance test to verify the change?
One more thing about the code in `optimizeCsvRead` method, I find `filteredFieldsNames` and `filteredFieldsIndices` are not needed. The code can be `
final VarCharType varCharType = new VarCharType();
final List<RowType.RowField> optimizedRowFields =
fields.stream()
.map(
field -> {
if (rowResultTypeFields.contains(field.getName())) {
return field;
} else {
return new RowType.RowField(
field.getName(),
varCharType,
field.getDescription().orElse(null));
}
})
.collect(Collectors.toList());
`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@flink.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org