You are viewing a plain text version of this content. The canonical link for it is here.
Posted to commits@hudi.apache.org by GitBox <gi...@apache.org> on 2022/06/14 02:34:18 UTC
[GitHub] [hudi] yangzhiyue opened a new issue, #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
yangzhiyue opened a new issue, #5857:
URL: https://github.com/apache/hudi/issues/5857
**_Tips before filing an issue_**
- Have you gone through our [FAQs](https://hudi.apache.org/learn/faq/)? yes
- Join the mailing list to engage in conversations and get faster support at dev-subscribe@hudi.apache.org. yes
- If you have triaged this as a bug, then file an [issue](https://issues.apache.org/jira/projects/HUDI/issues) directly.
**Describe the problem you faced**
We recently put hudi into production, and encountered a problem with a big task. He has hundreds of millions of binlog data every day, including insert and update, and has a joint primary key defined by us. These binlog data will be updated to more historical partitions and the latest partition.We use dynamoDb as a distributed lock, flink is used for incremental updates, spark tasks to write the previous historical hive partition data to this hudi table for data completion
The specific version and configuration are
flink 1.13.1
hudi 0.10.1
spark 3.0.1
table.type = MOR
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.SimpleAvroKeyGenerator'
hoodie.index.type' = 'SIMPLE'
problems encountered
1. When updating through insert into, there will be a problem of two records with a primary key, that is, data duplication
2. Update through insert into. When querying, sometimes there is a problem in the picture below. It feels that the data has been written badly.
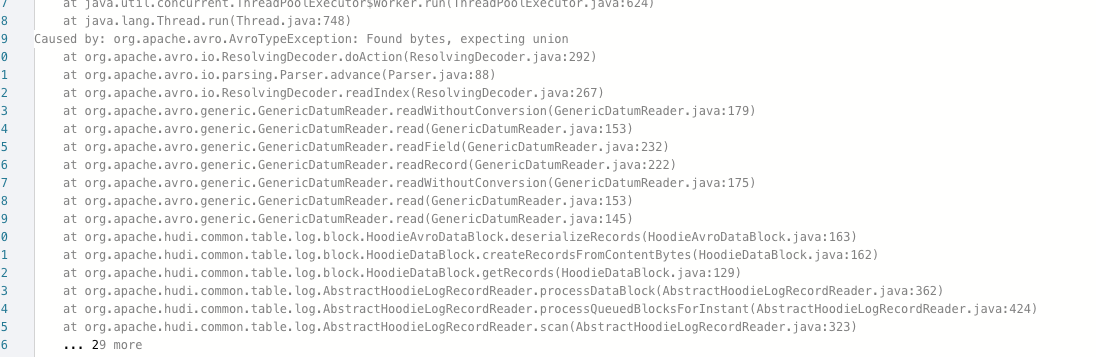
chinese description(我们最近把hudi放到了生产,有个大任务遇到了问题,他每天有上亿条的binlog数据,包括insert和update,有一个我们定义的联合主键,这些binlog数据会去更新较多的历史分区和最新分区,我们使用dynamoDb作为分布式锁,flink用来进行增量更新,spark的任务从来将以前历史的hive分区数据写入到这个hudi表用于数据补全
具体的版本和配置是
flink 1.13.1
hudi 0.10.1
spark 3.0.1
table.type = MOR
'hoodie.datasource.write.keygenerator.class' = 'org.apache.hudi.keygen.SimpleAvroKeyGenerator'
hoodie.index.type' = 'SIMPLE'
遇到的问题
1.通过insert into进行更新,会出现一个主键两条记录的问题,就是数据重复
2.通过insert into进行更新,查询的时候有时候下图的问题,感觉是数据被写坏了)
**To Reproduce**
Steps to reproduce the behavior:
it is in description
**Expected behavior**
A clear and concise description of what you expected to happen.
**Environment Description**
* Hudi version : 0.10.1
* Spark version : 3.0.1
* Hive version :
* Hadoop version : 3.1.2
* Storage (HDFS/S3/GCS..) : s3
* Flink: 1.13.1
* Running on Docker? (yes/no) : no
**Additional context**
Add any other context about the problem here.
**Stacktrace**
```Add the stacktrace of the error.```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] xushiyan commented on issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by GitBox <gi...@apache.org>.
xushiyan commented on issue #5857:
URL: https://github.com/apache/hudi/issues/5857#issuecomment-1296323395
> More clues for data duplication issue: I noticed two exactly the same records, one in avro log file, the other in merged parquet file after spark insert.
Spark and flink writers diverge when writing to MOR: spark writes updates to log files and inserts (new records) to base files directly, while flink writes all updates and inserts to log files. So in your pipeline setup, it is possible for flink writer writes all new data in logs and before compaction kicks in, spark writes some overlapping data in base files.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by "danny0405 (via GitHub)" <gi...@apache.org>.
danny0405 commented on issue #5857:
URL: https://github.com/apache/hudi/issues/5857#issuecomment-1510652578
> > Flink multi writers (OCC) is not supported yet.
>
> Do you mean if there are two flink writer to write hudi, there would have error?
Yes, we are trying to support lockless multi-writer for next release.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] MountHuang commented on issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by GitBox <gi...@apache.org>.
MountHuang commented on issue #5857:
URL: https://github.com/apache/hudi/issues/5857#issuecomment-1154677892
More clues for data duplication issue: I noticed two exactly the same records, one in avro log file, the other in merged parquet file after spark insert. I highly doubted that the spark writer doesn't finish a complete compaction, at least doesn't delete the avro log files properly, because if it does, then there will be no avro log files under this partition at all, and we shouldn't have the chance to meet the problem 2 described in this issue.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by GitBox <gi...@apache.org>.
danny0405 commented on issue #5857:
URL: https://github.com/apache/hudi/issues/5857#issuecomment-1369409251
Flink multi writers (OCC) is not supported yet.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by GitBox <gi...@apache.org>.
danny0405 commented on issue #5857:
URL: https://github.com/apache/hudi/issues/5857#issuecomment-1154652937
The stack trace you pasted seems a data type error, the details is that in `Avro`, if a data type is nullable true, it would be a `Union` type, for example a `string nullable` type in Avro is `Union(string, null)`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 closed issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by "danny0405 (via GitHub)" <gi...@apache.org>.
danny0405 closed issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
URL: https://github.com/apache/hudi/issues/5857
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] danny0405 commented on issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by "danny0405 (via GitHub)" <gi...@apache.org>.
danny0405 commented on issue #5857:
URL: https://github.com/apache/hudi/issues/5857#issuecomment-1531077294
Close because we already have plan to support the lockless multi-writer feature.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
[GitHub] [hudi] chenbodeng719 commented on issue #5857: [SUPPORT]Problem using Multiple writers(flink spark) to write to hudi
Posted by "chenbodeng719 (via GitHub)" <gi...@apache.org>.
chenbodeng719 commented on issue #5857:
URL: https://github.com/apache/hudi/issues/5857#issuecomment-1509853518
> Flink multi writers (OCC) is not supported yet.
Do you mean if there are two flink writer to write hudi, there would have error?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: commits-unsubscribe@hudi.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org