You are viewing a plain text version of this content. The canonical link for it is here.
Posted to issues@iceberg.apache.org by GitBox <gi...@apache.org> on 2021/07/10 15:36:29 UTC
[GitHub] [iceberg] southernriver opened a new pull request #2803: Spark: Add Multi-thread to construct ReadTask
southernriver opened a new pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803
For Spark2/Spark3, It always takes about 30 minutes to enter the Job Submitted state for over 100000 files, the more files, the longer waiting time for driver to scan. This piece of current code takes into account the locality strategy of the data, and will call getBlockLocations sequentially in a single thread.
Here is the thread log :
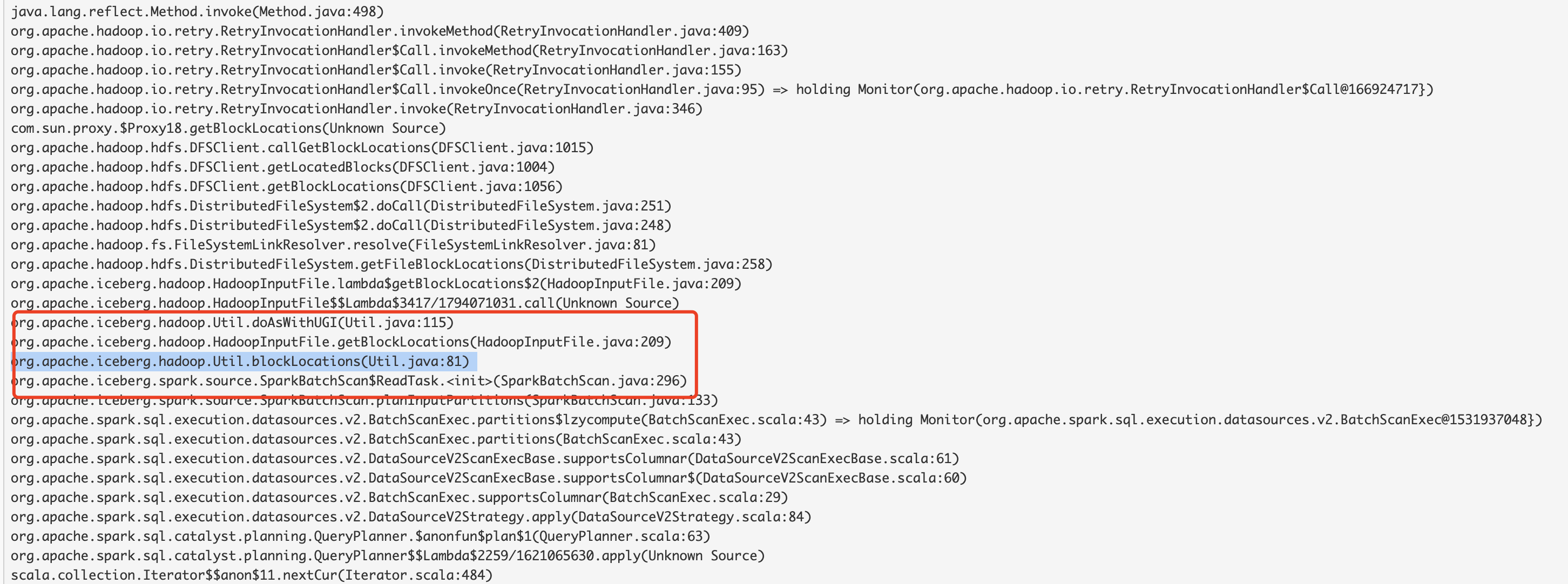
We can use multithreading to solve this problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] southernriver commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
southernriver commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667572467
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, new BatchReaderFactory(batchSize));
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
}
- LOG.info("Batching input partitions with {} tasks.", readTasks.size());
-
- return readTasks;
+ Long endTime = System.currentTimeMillis();
+ LOG.info("Batching input partitions with {} tasks.", readTasks.length);
+ LOG.info("It took {} s to construct {} readTasks with localityPreferred = {}.", (endTime - startTime) / 1000,
+ taskSize, localityPreferred);
+ return Arrays.asList(readTasks.clone());
}
/**
* This is called in the Spark Driver when data is to be materialized into {@link InternalRow}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
@Override
public List<InputPartition<InternalRow>> planInputPartitions() {
String expectedSchemaString = SchemaParser.toJson(lazySchema());
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
-
- List<InputPartition<InternalRow>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, InternalRowReaderFactory.INSTANCE));
+ int taskSize = tasks().size();
+ InputPartition<InternalRow>[] readTasks = new InputPartition[taskSize];
+ Long start_time = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, InternalRowReaderFactory.INSTANCE);
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
Review comment:
Thank you for reviewing this! I wanted to throw exception out at first, and if I did this, I also need to change code of
`org.apache.spark.sql.connector.read.Batch` and so on which is outside of iceberg. Here is the err msg:
> planInputPartitions()' in 'org.apache.iceberg.spark.source.SparkBatchScan' clashes with 'planInputPartitions()' in 'org.apache.spark.sql.connector.read.Batch'; overridden method does not throw 'java.lang.Exception'
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick edited a comment on pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick edited a comment on pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#issuecomment-879251100
@southernriver I was mistaken about the existence of distributed job planning (and hence my initial concern about how necessary this PR was).
I thought that there was distributed job planning already, but the PR is still open: https://github.com/apache/iceberg/pull/1421
I do know that this is being reprioritized again, but I'm not sure of any official timeline on that. Wanted to let you know. 🙂
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667567397
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
Review comment:
Should the construction of all read tasks be done in a single `submit` to the thread pool? I don’t see any way to slow the parallelism down here so as to not potentially overwhelm the name node.
For example, I would have expected that each of the ranges in the int stream we’re submitted to the pool invidually, so that tasks queue up waiting for their turn. Here, it looks like the parallelism is rather unbounded. Totally open to reading this wrong (it is Sunday for me after all!).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667568889
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, new BatchReaderFactory(batchSize));
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
}
- LOG.info("Batching input partitions with {} tasks.", readTasks.size());
-
- return readTasks;
+ Long endTime = System.currentTimeMillis();
+ LOG.info("Batching input partitions with {} tasks.", readTasks.length);
+ LOG.info("It took {} s to construct {} readTasks with localityPreferred = {}.", (endTime - startTime) / 1000,
+ taskSize, localityPreferred);
+ return Arrays.asList(readTasks.clone());
}
/**
* This is called in the Spark Driver when data is to be materialized into {@link InternalRow}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
@Override
public List<InputPartition<InternalRow>> planInputPartitions() {
String expectedSchemaString = SchemaParser.toJson(lazySchema());
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
-
- List<InputPartition<InternalRow>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, InternalRowReaderFactory.INSTANCE));
+ int taskSize = tasks().size();
+ InputPartition<InternalRow>[] readTasks = new InputPartition[taskSize];
+ Long start_time = System.currentTimeMillis();
Review comment:
We don't use snake case (outside of the python code). This should be startTime.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick edited a comment on pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick edited a comment on pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#issuecomment-877896139
Thank you for your submission @southernriver!
This seems like a somewhat large behavior change. Can you open a GitHub issue to track this / for general discussion? Or possibly this has been discussed on the mailing list (in which case possibly you can open an issue and link to the dev list discussion)? Also, an example query / situation you encounter this in could be added there and that would help greatly. I might be thinking of something else, but I thought that at a certain point, planning is distributed once a certain heuristic is passed.
One thing I'd like to see discussed is the abilitu to opt-into this behavior. I'd be more comfortaenwitj this change if we could (at least initially) allow users to opt into or out of using the thread pool to do the planning. I imagine there are scenarios in which it's a detriment. An issue (and then either the dev list or that issue) would be a much better place to discuss that in my opinion.
I’m not necessarily adverse to this change, but I do think having an issue to track a relatively large change in functionality (single threaded to multithreaded) would be nice as this is a pretty large change in behavior with no way to really opt out (or any documentation on the new table property).
Also, if you could more completely describe what the query is that you're encountering these times and what your dataset looks like (ideally in the issue), that would be great. It's possible that with so many files, OPTIMIZE and other table maintenance tasks need to be fun.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667564758
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -193,6 +202,7 @@ public StructType readSchema() {
/**
* This is called in the Spark Driver when data is to be materialized into {@link ColumnarBatch}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
Review comment:
What variable names are causing these checkstyle issues? Would it be possible to simply change them, instead of suppressing the warning for the whole function?
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, new BatchReaderFactory(batchSize));
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
Review comment:
Instead of simply dumping the stack trace, I think it would be helpful to users to use the logging function to log some information about the exception. Also, does `printStackTrace` respect the users logging configuration (or even desired log output) the same way that using the normal logger would? Seems to me like this call to printStackTrace could easily get swallowed / go unseen if users are logging to a file and have a logging pipeline to access logs (assuming this call prints to stdout or similar).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] jshmchenxi commented on pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
jshmchenxi commented on pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#issuecomment-877734510
@southernriver Hi, you can refer to the comments in #2577 if you are interested, like using `org.apache.iceberg.util.ThreadPools` instead of creating a thread pool from scratch.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667570449
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, new BatchReaderFactory(batchSize));
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
}
- LOG.info("Batching input partitions with {} tasks.", readTasks.size());
-
- return readTasks;
+ Long endTime = System.currentTimeMillis();
+ LOG.info("Batching input partitions with {} tasks.", readTasks.length);
+ LOG.info("It took {} s to construct {} readTasks with localityPreferred = {}.", (endTime - startTime) / 1000,
+ taskSize, localityPreferred);
+ return Arrays.asList(readTasks.clone());
}
/**
* This is called in the Spark Driver when data is to be materialized into {@link InternalRow}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
@Override
public List<InputPartition<InternalRow>> planInputPartitions() {
String expectedSchemaString = SchemaParser.toJson(lazySchema());
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
-
- List<InputPartition<InternalRow>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, InternalRowReaderFactory.INSTANCE));
+ int taskSize = tasks().size();
+ InputPartition<InternalRow>[] readTasks = new InputPartition[taskSize];
+ Long start_time = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
Review comment:
It seems that `tasks()` is called several times in this version. In the other function definition, the result of `tasks()` is saved as a variable `scanTasks`. Would it make sense to do the same here instead of calling `tasks()` many times?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667567397
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
Review comment:
Should the construction of all read tasks be done in a single `submit` to the thread pool? I don’t see any way to slow the parallelism down here so as to not potentially overwhelm the name node.
For example, I would have expected that each of the ranges in the int stream were submitted to the pool invidually, so that tasks queue up waiting for their turn. Here, it looks like the parallelism is rather unbounded. Totally open to reading this wrong (it is Sunday for me after all!).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667569657
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, new BatchReaderFactory(batchSize));
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
}
- LOG.info("Batching input partitions with {} tasks.", readTasks.size());
-
- return readTasks;
+ Long endTime = System.currentTimeMillis();
+ LOG.info("Batching input partitions with {} tasks.", readTasks.length);
+ LOG.info("It took {} s to construct {} readTasks with localityPreferred = {}.", (endTime - startTime) / 1000,
+ taskSize, localityPreferred);
+ return Arrays.asList(readTasks.clone());
}
/**
* This is called in the Spark Driver when data is to be materialized into {@link InternalRow}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
@Override
public List<InputPartition<InternalRow>> planInputPartitions() {
String expectedSchemaString = SchemaParser.toJson(lazySchema());
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
-
- List<InputPartition<InternalRow>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, InternalRowReaderFactory.INSTANCE));
+ int taskSize = tasks().size();
+ InputPartition<InternalRow>[] readTasks = new InputPartition[taskSize];
+ Long start_time = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, InternalRowReaderFactory.INSTANCE);
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
Review comment:
I would avoid explicitly calling System.exit and instead let the exception bubble up (possibly catching it and then rethrowing it with additional information added or as another exception type). This would make it easier for end users to track down their exceptions, particularly when working in a notebook where there's limited space to display stack traces already.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667569043
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, new BatchReaderFactory(batchSize));
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
}
- LOG.info("Batching input partitions with {} tasks.", readTasks.size());
-
- return readTasks;
+ Long endTime = System.currentTimeMillis();
+ LOG.info("Batching input partitions with {} tasks.", readTasks.length);
+ LOG.info("It took {} s to construct {} readTasks with localityPreferred = {}.", (endTime - startTime) / 1000,
+ taskSize, localityPreferred);
+ return Arrays.asList(readTasks.clone());
}
/**
* This is called in the Spark Driver when data is to be materialized into {@link InternalRow}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
@Override
public List<InputPartition<InternalRow>> planInputPartitions() {
String expectedSchemaString = SchemaParser.toJson(lazySchema());
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
-
- List<InputPartition<InternalRow>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, InternalRowReaderFactory.INSTANCE));
+ int taskSize = tasks().size();
+ InputPartition<InternalRow>[] readTasks = new InputPartition[taskSize];
+ Long start_time = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, InternalRowReaderFactory.INSTANCE);
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
}
- return readTasks;
+ Long end_time = System.currentTimeMillis();
Review comment:
Same note about snake case variable names.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] southernriver commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
southernriver commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667587287
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -193,6 +202,7 @@ public StructType readSchema() {
/**
* This is called in the Spark Driver when data is to be materialized into {@link ColumnarBatch}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
Review comment:
`"Long startTime = System.currentTimeMillis();"` would cause "checkstyle:LocalVariableName".
And I will solve another checkstyle of "RegexpSinglelineJava"
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r668320572
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -193,6 +202,7 @@ public StructType readSchema() {
/**
* This is called in the Spark Driver when data is to be materialized into {@link ColumnarBatch}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
Review comment:
Ah. In that case, possibly changing `startTime` to another name to not shadow the external would be potentially preferable.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] southernriver commented on pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
southernriver commented on pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#issuecomment-877736543
> @southernriver Hi, you can refer to the comments in #2577 if you are interested, like using `org.apache.iceberg.util.ThreadPools` instead of creating a thread pool from scratch.
Get it, I'm new to iceberg, thank you .
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] southernriver commented on pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
southernriver commented on pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#issuecomment-877667514
cc @StefanXiepj
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#issuecomment-877896139
Can you please provide an example query where you see this @southernriver?
Or better yet, open a GitHub issue to track this / for general discussion? An example query / situation you encounter this in could be added there.
For example, this seems like behavior that we should (at least initially) allow users to opt into given that it’s a rather large change from the current behavior. An issue (and then either the dev list or that issue) would be a much better place to discuss that in my opinion.
I’m not adverse to this change by any means, but I do think having an issue to track a relatively large change in functionality (single threaded to multithreaded) would be nice.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#issuecomment-879251100
@southernriver I was mistaken. I thought that there was distributed job planning already, but the PR is still open: https://github.com/apache/iceberg/pull/1421
I do know that this is being reprioritized again.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org
[GitHub] [iceberg] kbendick commented on a change in pull request #2803: Spark: Add Multi-thread to construct ReadTask
Posted by GitBox <gi...@apache.org>.
kbendick commented on a change in pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803#discussion_r667569657
##########
File path: spark2/src/main/java/org/apache/iceberg/spark/source/Reader.java
##########
@@ -205,35 +215,62 @@ public StructType readSchema() {
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
- List<InputPartition<ColumnarBatch>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, new BatchReaderFactory(batchSize)));
+ int taskSize = tasks().size();
+ InputPartition<ColumnarBatch>[] readTasks = new InputPartition[taskSize];
+ Long startTime = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, new BatchReaderFactory(batchSize));
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
}
- LOG.info("Batching input partitions with {} tasks.", readTasks.size());
-
- return readTasks;
+ Long endTime = System.currentTimeMillis();
+ LOG.info("Batching input partitions with {} tasks.", readTasks.length);
+ LOG.info("It took {} s to construct {} readTasks with localityPreferred = {}.", (endTime - startTime) / 1000,
+ taskSize, localityPreferred);
+ return Arrays.asList(readTasks.clone());
}
/**
* This is called in the Spark Driver when data is to be materialized into {@link InternalRow}
*/
+ @SuppressWarnings({"checkstyle:LocalVariableName", "checkstyle:RegexpSinglelineJava"})
@Override
public List<InputPartition<InternalRow>> planInputPartitions() {
String expectedSchemaString = SchemaParser.toJson(lazySchema());
// broadcast the table metadata as input partitions will be sent to executors
Broadcast<Table> tableBroadcast = sparkContext.broadcast(SerializableTable.copyOf(table));
-
- List<InputPartition<InternalRow>> readTasks = Lists.newArrayList();
- for (CombinedScanTask task : tasks()) {
- readTasks.add(new ReadTask<>(
- task, tableBroadcast, expectedSchemaString, caseSensitive,
- localityPreferred, InternalRowReaderFactory.INSTANCE));
+ int taskSize = tasks().size();
+ InputPartition<InternalRow>[] readTasks = new InputPartition[taskSize];
+ Long start_time = System.currentTimeMillis();
+ try {
+ pool.submit(() -> IntStream.range(0, taskSize).parallel()
+ .mapToObj(taskId -> {
+ LOG.trace("The size of scanTasks is {}, current taskId is {}, current thread id is {}",
+ taskSize, taskId, Thread.currentThread().getName());
+ readTasks[taskId] = new ReadTask<>(
+ tasks().get(taskId), tableBroadcast, expectedSchemaString, caseSensitive,
+ localityPreferred, InternalRowReaderFactory.INSTANCE);
+ return true;
+ }).collect(Collectors.toList())).get();
+ } catch (Exception e) {
+ e.printStackTrace();
+ System.exit(-1);
Review comment:
I would avoid explicitly calling System.exit and instead let the exception bubble up (possibly catching it and then rethrowing it with additional information added or as another exception type). This would make it easier for end users to track down their exceptions, particularly when working in a notebook where there's limited space to display stack traces already.
Is there a specific reason you chose to call `System.exit` that possibly I'm not aware of?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For queries about this service, please contact Infrastructure at:
users@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: issues-unsubscribe@iceberg.apache.org
For additional commands, e-mail: issues-help@iceberg.apache.org